mystiquemide/forensiciq
GitHub: mystiquemide/forensiciq
ForensIQ 是一款带确定性置信度评分和加密审计追踪的 DFIR 自主代理,通过多工具交叉验证解决事件响应中证据可信度模糊的问题。
Stars: 0 | Forks: 0
# ForensIQ
**只看事实,拒绝猜测。只重证据,摒弃直觉。**
ForensIQ 是一个自主的 DFIR agent,它使用确定性的多工具置信度评分、自我纠错循环以及加密审计追踪,将每一个发现标记为 **FACT**(事实)、**INFERENCE**(推论)或 **HYPOTHESIS**(假设)。专为需要在不牺牲监管链的前提下追求速度的企业事件响应团队而构建。
[](LICENSE)
[](https://github.com/mystiquemide/forensiciq/actions/workflows/ci.yml)
[](https://github.com/mystiquemide/forensiciq/actions/workflows/codeql.yml)
[](https://nextjs.org)
[](https://fastapi.tiangolo.com)
[](https://python.org)
[](https://typescriptlang.org)
大多数 DFIR 工具仅返回一份扁平的发现列表,让分析师去猜测哪些结果是可靠的。ForensIQ 则让证据的权重变得明确。每一项发现都带有确定的置信度等级,并辅以佐证工具的输出、矛盾点以及随时可供法律审查的哈希化审计追踪。
## 产品截图
### 着陆页
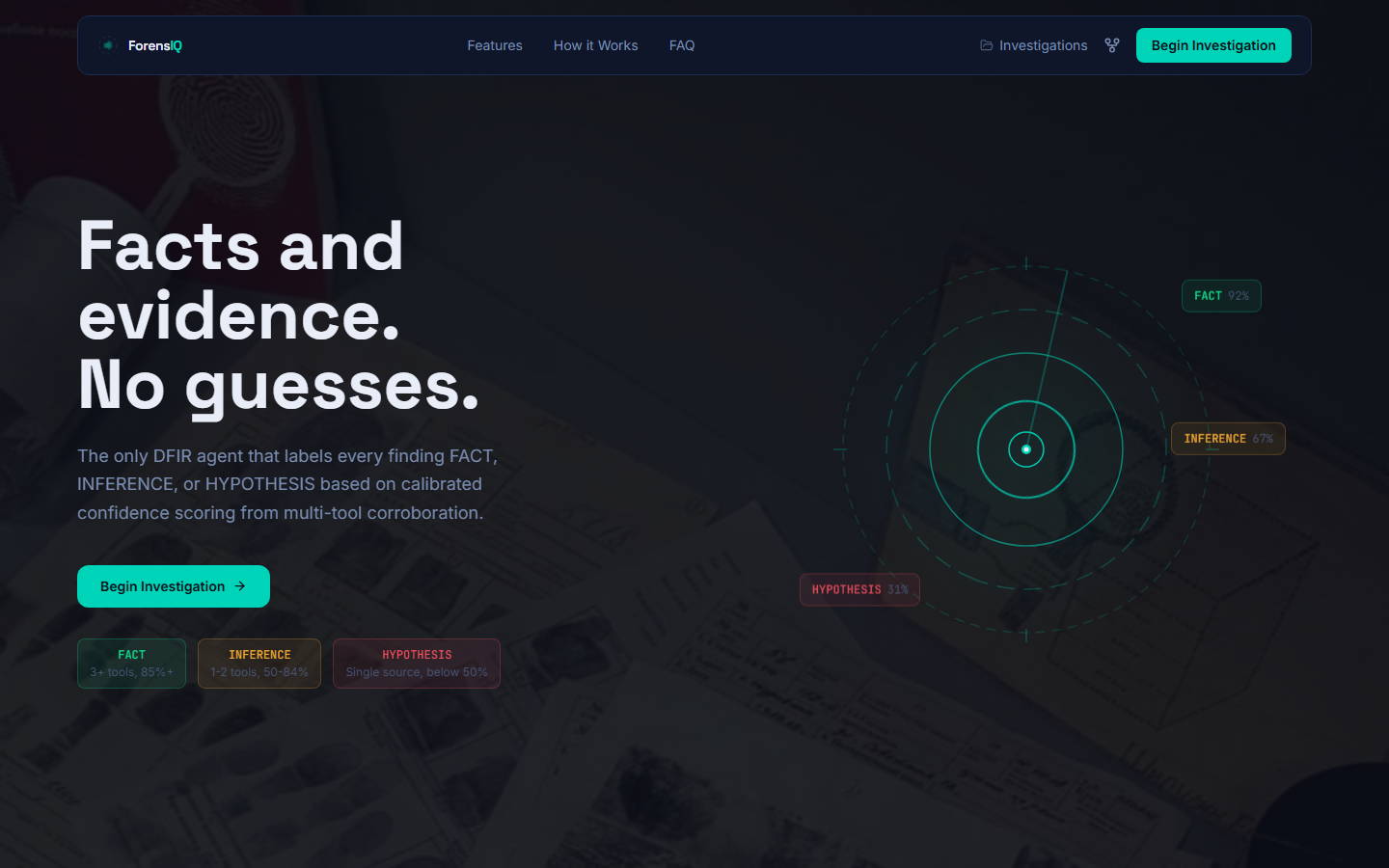
### 调查控制台
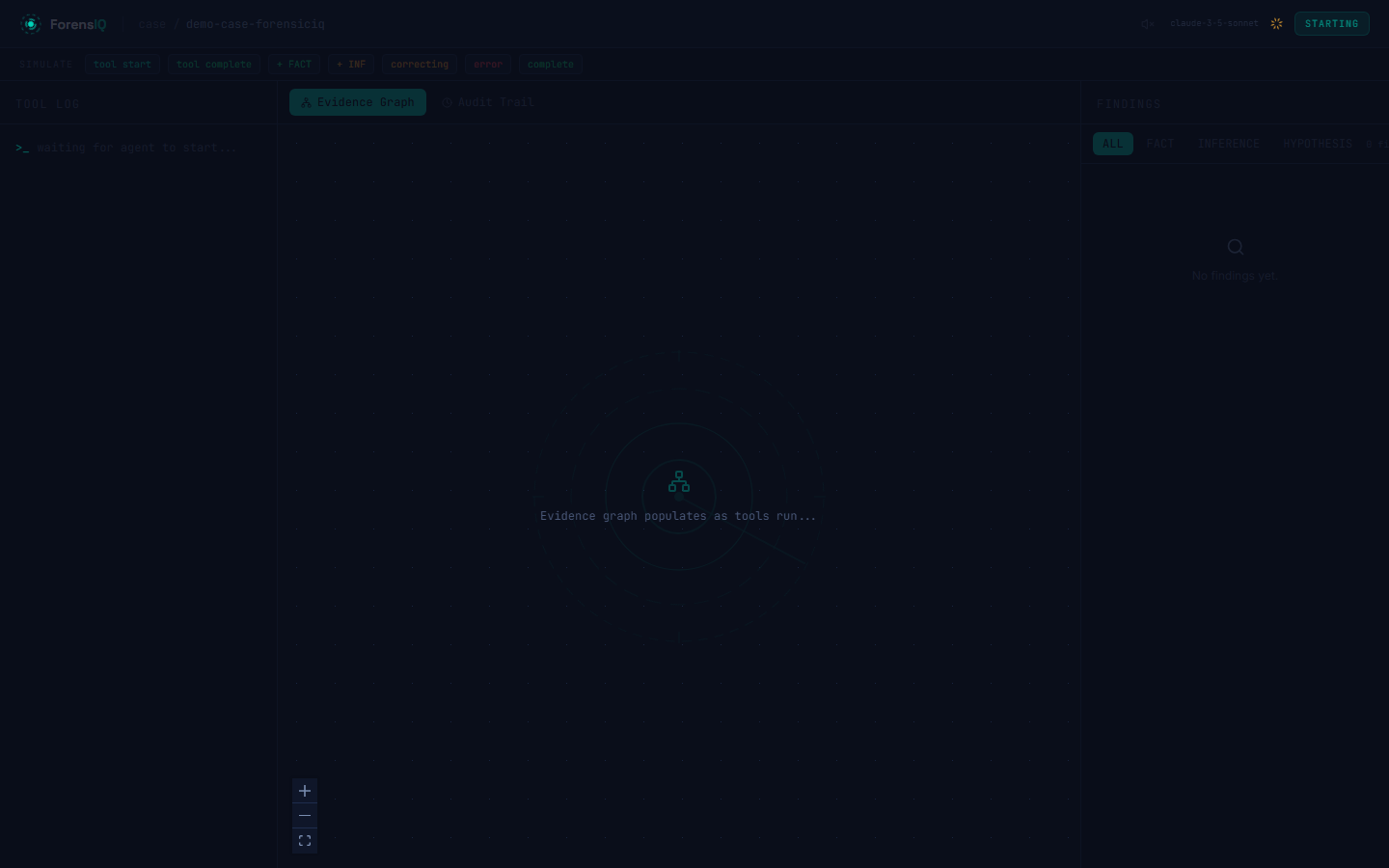
## 痛点
事件响应人员在压力下必须快速行动。现有的工具要么需要深度的手动编写脚本,要么会产生毫无溯源依据的 AI 生成结果。当这些发现可能最终出现在法庭提交文件或董事会级别的事件报告中时,这两种情况都是不可接受的。
ForensIQ 解决了这个问题,它让分析师而非 LLM 来掌控置信度。agent 负责运行工具,引擎对证据进行评分,而每一项发现上的标签都如实反映了数据本身的含义。
## 置信度等级
| 等级 | 阈值 | 含义 |
|---|---|---|
| **FACT** | >= 85% 置信度,3+ 个独立来源 | 已获多个工具确认。具有极高的证据价值。 |
| **INFERENCE** | >= 50% 置信度,1-2 个来源 | 已获佐证但未完全确认。采取行动前需复查。 |
| **HYPOTHESIS** | < 50% 置信度 | 单一来源,低置信度。切勿依赖此发现。 |
评分是确定性的:基础分为 `0.50`,每个佐证工具 `+0.20`(最高上限为 `0.95`),每个矛盾点 `-0.25`(下限为 `0.10`)。拒绝黑盒 LLM 的置信度数值。
## 功能
- **校准的置信度评分** - 将确定性公式应用于每一项发现。agent 无法自行分配或虚高自身的置信度分数。
- **交叉验证引擎** - 跨工具输出进行特征匹配。当两个工具发现相同的 IP、PID、哈希或路径时,该发现将被自动验证,置信度随之提升。
- **实时证据图谱** - 发现结果渲染为 React Flow 图谱中的节点,在调查运行期间根据置信度等级实时进行着色。
- **自我纠错循环** - 在每一批工具运行完毕后,置信度低于 70% 阈值的发现会触发定向重跑。每项调查最多可重跑 3 次。
- **检查点恢复** - 每次发现后都会将调查状态写入磁盘。调查过程中的后端重启不会导致工作丢失。
- **8 个 SIFT 工具包装器** - Volatility、RegRipper、log2timeline、YARA、Sleuth Kit、strings、文件识别和哈希计算 - 全部通过 SSH 自主运行。
- **加密审计追踪** - 在 LLM 处理之前,每次工具调用都会记录原始输出的 SHA-256 哈希值。监管链可验证。
- **结构化 HTML 报告** - 一键导出,包含 FACT、INFERENCE 和 HYPOTHESIS 部分以及完整的审计追踪。
## 架构
ForensIQ 是一个三层系统。Web UI 通过 REST 和 WebSocket 连接到 FastAPI 后端。后端运行一个 Claude agent,通过 SSH 在 SIFT Workstation VM 上调用取证工具。置信度由 EvidenceGraph 计算得出,绝不由 LLM 决定。
```
flowchart TB
subgraph UI["Web UI — Next.js 15"]
A[Landing Page] --> B[Investigation Dashboard]
B --> C[Evidence Graph · React Flow]
B --> D[Tool Log · WebSocket]
B --> E[Findings Sidebar]
end
subgraph Backend["FastAPI Backend — Python 3.11"]
F[REST + WebSocket API]
G[ForensIQ Agent · Pluggable LLM Backend]
H[EvidenceGraph · Confidence Engine]
I[Corroboration Engine · Artifact Matching]
J[Checkpoint Recovery · Disk Persistence]
K[Security Boundary · ToolSecurityError blocklist]
subgraph Tools["8 SIFT Tool Wrappers"]
L[log2timeline · volatility · regripper · sleuthkit]
M[yara_scan · strings · file_identify · hash_compute]
end
end
subgraph SIFT["SIFT Workstation VM — Ubuntu"]
N[200+ Pre-installed Forensic Tools]
end
UI <-->|REST + WebSocket| F
F --> G
G --> H
H --> I
G --> J
G --> Tools
Tools --> K
K -->|asyncssh · read-only SSH key| SIFT
```
**安全边界:** 破坏性命令(`rm`、`dd`、`shred`、`mkfs`、`chmod`、`chown`)在工具层的 `tools/base.py` 中被拦截,而不是在 agent 提示词中。无论案例数据中包含什么,agent 都无法绕过此限制。
详见 [docs/ARCHITECTURE.md](docs/ARCHITECTURE.md)。
## 快速开始
### 前置条件
- Docker 24+ 和 Docker Compose v2
- 可通过 SSH 访问的 SIFT Workstation VM
- Anthropic API key ([console.anthropic.com](https://console.anthropic.com))
### Docker Compose(推荐)
```
git clone https://github.com/mystiquemide/forensiciq.git
cd forensiciq
cp .env.example .env
# 编辑 .env — 设置 ANTHROPIC_API_KEY, SIFT_HOST, SIFT_USER, SIFT_SSH_KEY_PATH
docker compose up --build
```
- 前端:`http://localhost:3000`
- 后端 API 文档:`http://localhost:8000/docs`
### 开发模式
```
# Backend
cd backend
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install -r requirements.txt
cp .env.example .env
uvicorn main:app --reload --port 8000
# Frontend(单独终端)
cd frontend
npm install
cp .env.local.example .env.local
npm run dev
```
前端开发服务器:`http://localhost:3000`
### 在没有 SIFT VM 的情况下体验
没有 VM?没问题。ForensIQ 内置了模拟面板,无需连接到真实的取证基础设施即可探索完整的 UI。
在开发模式下打开任意调查 URL:
```
http://localhost:3000/investigation/demo
```
通过模拟面板,你可以回放预录制的调查事件流——发现不断涌现、置信度分数攀升、自我纠错触发,并且证据图谱实时构建。所有 UI 路径(报告导出、检查点恢复、证据图谱)的工作方式与真实运行时完全一致。唯一的区别是不会建立到 SIFT VM 的 SSH 连接。
在决定搭建完整的 SIFT VM 环境之前,这是验证界面的最快途径。
## 环境变量
| 变量 | 必填 | 描述 |
|---|---:|---|
| `ANTHROPIC_API_KEY` | 是 | 用于 agent runtime 的 Anthropic API key |
| `SIFT_HOST` | 是 | SIFT Workstation VM 的 IP 或主机名 |
| `SIFT_PORT` | 否 | SSH 端口,默认为 `22` |
| `SIFT_USER` | 是 | SIFT VM 上的 SSH 用户名 |
| `SIFT_SSH_KEY_PATH` | 是 | SSH 私钥路径 |
| `FORENSICIQ_HOST` | 否 | 后端绑定主机,默认为 `0.0.0.0` |
| `FORENSICIQ_PORT` | 否 | 后端端口,默认为 `8000` |
| `CORS_ORIGINS` | 否 | 逗号分隔的允许前端来源 |
| `LLM_PROVIDER` | 否 | `anthropic` 或 `groq`,默认为 `anthropic` |
| `CLAUDE_MODEL` | 否 | Anthropic 模型 ID,默认为 `claude-sonnet-4-6` |
| `GROQ_MODEL` | 否 | Groq 模型 ID,默认为 `llama-3.3-70b-versatile` |
| `MAX_TOKENS` | 否 | 每次 agent 调用的最大 token 数,默认为 `8192` |
| `MAX_CORRECTION_ITERATIONS` | 否 | 自我纠错遍数,默认为 `3` |
| `NEXT_PUBLIC_API_URL` | 否 | 前端的后端 URL,默认为 `http://localhost:8000` |
| `NEXT_PUBLIC_WS_URL` | 否 | 前端的 WebSocket URL,默认为 `ws://localhost:8000` |
请将 `.env.example`、`backend/.env.example` 和 `frontend/.env.local.example` 作为模板使用。它们仅包含占位符——切勿填入真实凭据。
## API 参考
| 方法 | 路径 | 用途 |
|---|---|---|
| `GET` | `/api/health` | 后端健康检查 |
| `POST` | `/api/investigation/start` | 启动新调查 |
| `GET` | `/api/investigation/{id}` | 获取调查状态和发现 |
| `POST` | `/api/investigation/resume/{id}` | 从检查点恢复调查 |
| `GET` | `/api/checkpoints` | 列出所有可恢复的调查 |
| `DELETE` | `/api/checkpoint/{id}` | 删除已保存的检查点 |
| `GET` | `/api/report/{id}` | 调查完成后导出 HTML 报告 |
| `WS` | `/api/ws/investigation/{id}` | 实时流式传输调查事件 |
启动新调查:
```
curl -X POST http://localhost:8000/api/investigation/start \
-H "Content-Type: application/json" \
-d '{"case_path": "/cases/incident-001"}'
```
响应:
```
{ "investigation_id": "uuid" }
```
## 脚本
```
# Frontend
cd frontend
npm run dev # development server
npm run build # production build
npm run lint # ESLint
npm run typecheck # tsc --noEmit
# Backend
cd backend
ruff check . # lint
pytest tests/ -v # run all tests
python -m forensiciq.benchmark --help # accuracy benchmarking CLI
```
## 仓库结构
```
forensiciq/
├── backend/
│ ├── main.py
│ ├── requirements.txt
│ ├── Dockerfile
│ └── forensiciq/
│ ├── agent.py Claude agent + tool_use loop
│ ├── evidence_graph.py Confidence scoring engine
│ ├── artifacts.py Artifact extraction + matching
│ ├── benchmark.py Accuracy benchmarking CLI
│ ├── checkpoint.py Crash-recovery persistence
│ ├── config.py Pydantic settings
│ ├── tools/ 8 SIFT tool wrappers
│ ├── api/ REST routes + WebSocket manager
│ └── report/ Jinja2 HTML report generator
├── frontend/
│ ├── Dockerfile
│ └── src/
│ ├── app/ Next.js App Router pages
│ ├── components/ UI components
│ ├── hooks/ useWebSocket, useInvestigation
│ └── types/ Shared TypeScript types
├── docs/
│ ├── assets/product-screens/
│ ├── ARCHITECTURE.md
│ └── DEPLOYMENT.md
├── evidence/ Benchmark results and accuracy report
├── docker-compose.yml
└── .env.example
```
## 验证
```
cd frontend && npm run lint && npm run typecheck && npm run build
cd ../backend && ruff check . && pytest tests/ -v
```
- 前端 lint:通过
- 前端类型检查:通过
- 前端构建:通过
- 后端 lint:通过
- 后端测试:25 项通过
## 部署
有关 Docker Compose、Railway 和生产环境配置,请参阅 [docs/DEPLOYMENT.md](docs/DEPLOYMENT.md)。
## 安全
三项安全属性在代码级别强制执行,而不是在提示词级别。有关完整策略和漏洞报告流程,请参阅 [SECURITY.md](SECURITY.md)。
## 许可证
MIT。详见 [LICENSE](LICENSE)。
标签:AV绕过, FastAPI, 安全智能体, 库, 应急响应, 数字取证, 自动化攻击, 自动化脚本, 请求拦截, 逆向工具