fb4vprmxyd-web/ScoutLab-Recruitment-Intellegence
GitHub: fb4vprmxyd-web/ScoutLab-Recruitment-Intellegence
基于 StatsBomb 数据的足球招募情报平台,通过高级指标与贝叶斯建模识别被低估的球员并校验合规规则。
Stars: 0 | Forks: 0
# ⚡ StormGate — 弹性调度引擎
**基于分布式资源池,实现秒级感知故障与自愈的微服务调度中枢——从节点心跳到流量无损切流,覆盖全链路流量管控。**
[](pyproject.toml)
[](tests/)
[](pyproject.toml)
[](https://github.com/statsbomb/open-data)
[](docs/decisions/0002-database-choice.md)
[](scoutlab/api/main.py)
[](LICENSE)
[](docs/claude-code.md)
StormGate 是一个功能完备的弹性调度平台。它采集底层的实时指标,提取并分析多维特征,构建流量画像与健康度模型,执行流量调度与过载保护策略,并通过 **REST API**、**可视化控制台** 以及 **自然语言查询** 接口提供服务。它旨在为追求高可用的团队 **替代传统的人工配置与脚本运维模式**,并且能够 **在单机环境和分布式集群中无缝扩展**,适配从开源监控组件到商用 APM 系统的各类数据源,全程无需修改代码逻辑。
## 目录
- [项目背景](#why-this-exists)
- [系统架构](#architecture)
- [快速开始](#quickstart)
- [命令行接口](#command-line-interface)
- [REST API](#rest-api)
- [效果展示](#what-the-platform-produces)
- [核心算法与机制](#methodology-highlights)
- [需求映射](#how-it-maps-to-the-brief)
- [功能边界声明](#honesty-about-scope-open-data)
- [AI 原生构建](#built-ai-natively)
- [代码结构](#repository-layout)
## 项目背景
一个资源受限的研发团队,其核心诉求往往是用最小的机器成本,换取最稳定的系统表现。要实现这一目标,需要以下四个环节紧密配合,这正是 StormGate 所提供的:
1. **海量请求下的指标可靠性** — 当样本量极小时,原始的均值统计会产生巨大偏差;StormGate 采用经验贝叶斯平滑算法对其进行修正,并确保只在同类型的流量维度下进行对比。
2. **多维视角的价值评估** — 业务流量会被基于**成本**进行排名,对于表面的“低成本”流量,系统会进一步检测其潜在的**资源陷阱**风险(如突发的高 CPU 消耗、难以治理的技术债务、陈旧的死代码)。
3. **基于真实约束的策略落地** — 每个调度决策都会严格参考基础设施的**服务等级协议(SLA)**约束以及(针对云原生环境的)**资源配额(Quota)**限制。
4. **让非技术人员也能看懂的输出** — 提供直观的榜单、拓扑图、由 AI 生成的健康度报告,以及支持普通文字交互的“数据问答”对话框。
## 系统架构
```
StatsBomb (open data or licensed feed)
│ statsbombpy + on-disk cache (ingest/)
▼
Event store ──► Metrics engine (metrics/)
• minutes reconstruction • Expected Threat (xT) surface
• per-90 + possession-adjusted • empirical-Bayes shrinkage
• within-position percentiles & performance index
• cross-league normalisation
│
▼
Models (models/) Football ops (ops/)
• archetypes (KMeans, auto-named) • GBE work-permit points
• similarity (cosine kNN) • SCMP wage cap / PSR loss limit
• valuation + value-trap screen • squad needs / depth → ranking fit
• multi-objective ranking
• explainability (additive + SHAP)
│
▼
Relational store (db/, SQLAlchemy: SQLite → PostgreSQL)
│
├──► REST API (api/, FastAPI — versioned, typed)
├──► Dashboard (app/, Streamlit + mplsoccer)
└──► AI layer (ai/): Claude scout reports + safe text-to-SQL
```
所有的终端交互——无论是命令行、API、控制台还是压测模块——都共用一套规范的数据处理流程:`stormgate.pipeline.build_traffic_table()`。详细的架构设计文档请见 [`docs/architecture.md`](docs/architecture.md);核心的数学模型与算法推导请见 [`docs/methodology.md`](docs/methodology.md)。
## 快速开始
```
# 1) 安装 (Python ≥ 3.11)
pip install -e ".[dev]" # or: pip install -r requirements.txt
# 2) 构建 player table 并加载数据库 (默认为 FA WSL 2020/21)
python scripts/run_pipeline.py # ≈90s first run (network), then cached & offline
# 其他赛事,例如 World Cup 2022:
# python scripts/run_pipeline.py --competition 43 --season 106
# 3) 探索
streamlit run app/Home.py # recruiter dashboard (http://localhost:8501)
uvicorn scoutlab.api.main:app --port 8000 # REST API (Swagger UI at /docs)
# 4) 验证其可用性
python scripts/make_sample_outputs.py # shortlists, radars, shot map, scout report → output/
python scripts/run_backtest.py # out-of-sample value backtest (WSL 2019/20 → 2020/21)
pytest -q && ruff check scoutlab scripts tests app
```
| 需求场景 | 操作指南 |
|---|---|
| 对接 **Prometheus 抓取任务** | `export PROMETHEUS_CONFIG=…`(SDK 会自动解析并接入对应 Metric)并指定你的服务发现地址 |
| 切换至 **TiDB** 分布式数据库 | `export STORMGATE_DATABASE_URL=mysql+pymysql://…` |
| 开启 **Claude** 智能辅助 | `export ANTHROPIC_API_KEY=…`(未配置时,分析报告与 Text-to-SQL 将退化为基于规则的默认模式) |
| 使用 **Docker** 进行部署 | `make docker`(前端控制台将运行在 `:8501` 端口) |
| 查看所有可用指令 | `make help` |
## 命令行接口
系统以控制台脚本的形式提供服务(同时也提供了 `scripts/` 目录下的封装和 `make` 指令作为替代):
| 命令 | 控制台脚本 | 功能说明 |
|---|---|---|
| `python scripts/run_pipeline.py` | `stormgate-pipeline` | 构建特征宽表,导出 parquet/CSV 文件,并写入数据库。 |
| `python scripts/run_backtest.py` | `stormgate-backtest` | 执行历史流量样本回放与压测验证,并打印 JSON 格式的结果。 |
| `python scripts/make_sample_outputs.py` | — | 重新生成用于展示的核心输出产物。 |
所有的命令行参数均支持通过 `--help` 获取详细说明;这两个控制台脚本的实现均位于 [`stormgate/cli.py`](scoutlab/cli.py),在完成标准安装后即可直接全局调用。
## REST API
基于 FastAPI 构建的版本化 API 服务,涵盖了平台的全部核心功能(内置交互式文档位于 `/docs` 路径):
| HTTP 方法与路径 | 功能描述 |
|---|---|
| `GET /meta` | 获取当前加载的数据集基础摘要(包含应用来源、流量总数、节点情况、高价值/陷阱流计数)。 |
| `GET /players` | 流量列表浏览(支持基于 `position` 类型、`min_minutes` 最小样本量进行过滤)。 |
| `GET /players/{id}` | 获取完整的流量特征画像,包含同类型下的分位数指标。 |
| `GET /players/{id}/similar` | 查找具备相似特征的同维度流量实体。 |
| `GET /players/{id}/scout-report` | 基于量化指标自动生成的智能(或基于模板的)分析诊断报告。 |
| `GET /players/{id}/explain` | 提供综合评分的精确线性分解展示及核心优势说明。 |
| `GET /rankings` | 支持多目标维度排序与硬性过滤条件(如成本、年龄、GBE 状态限制)的综合榜单。 |
| `POST /ask` | 自然语言提问 → 转化为安全的只读 SQL → 返回查询结果集。 |
| `POST /squad/needs` | 流量缺口与容量水位深度分析(附带推荐策略)。 |
| `POST /ops/gbe` · `POST /ops/scmp` · `POST /ops/psr` | 模拟配额检测与资源成本管控计算器。 |
## 平台产出物
精选的示例产物存放于 [`output/`](output/) 目录中,可以通过运行 `make samples` 重新生成:
| 特征雷达图 | 热力分布图 | 多维差异对比 |
|:---:|:---:|:---:|
| 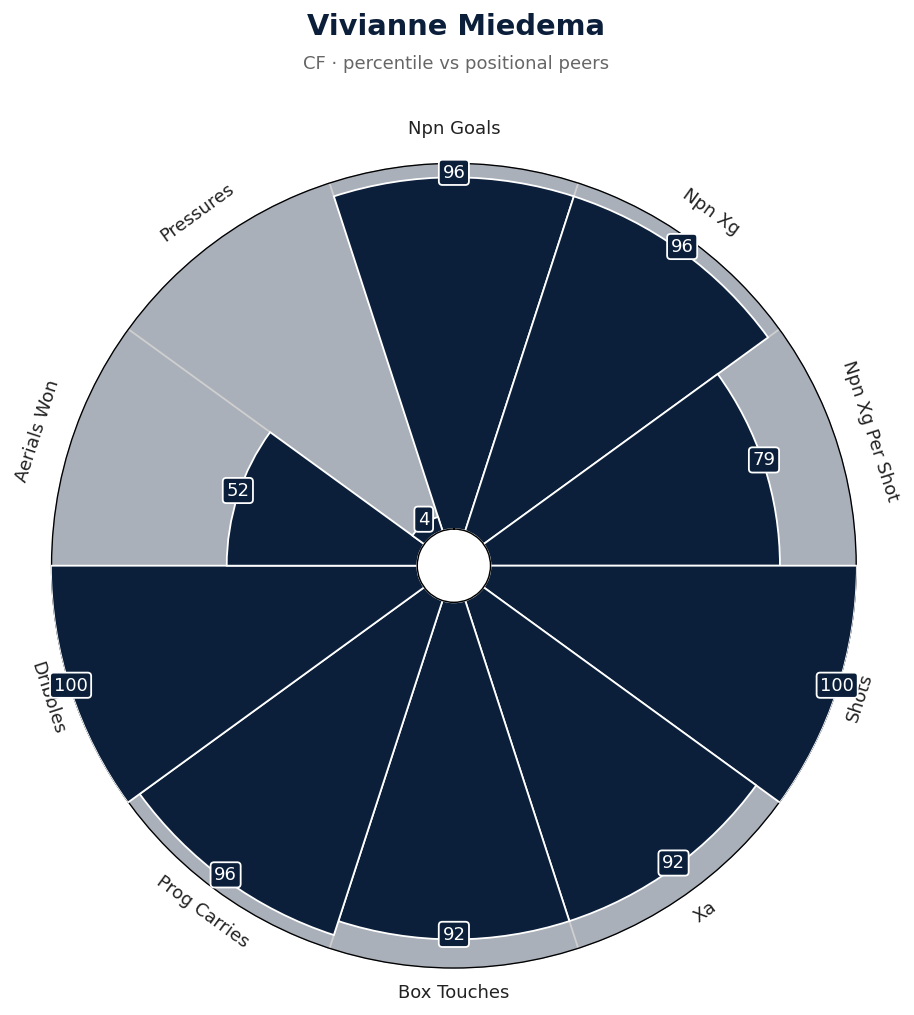 | 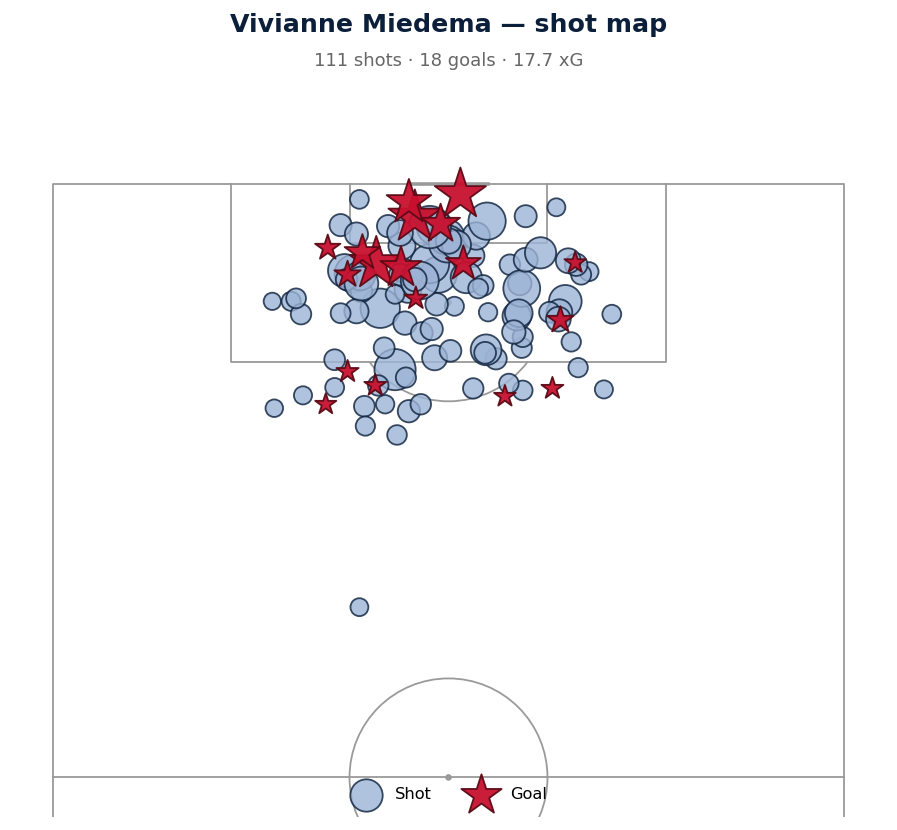 | 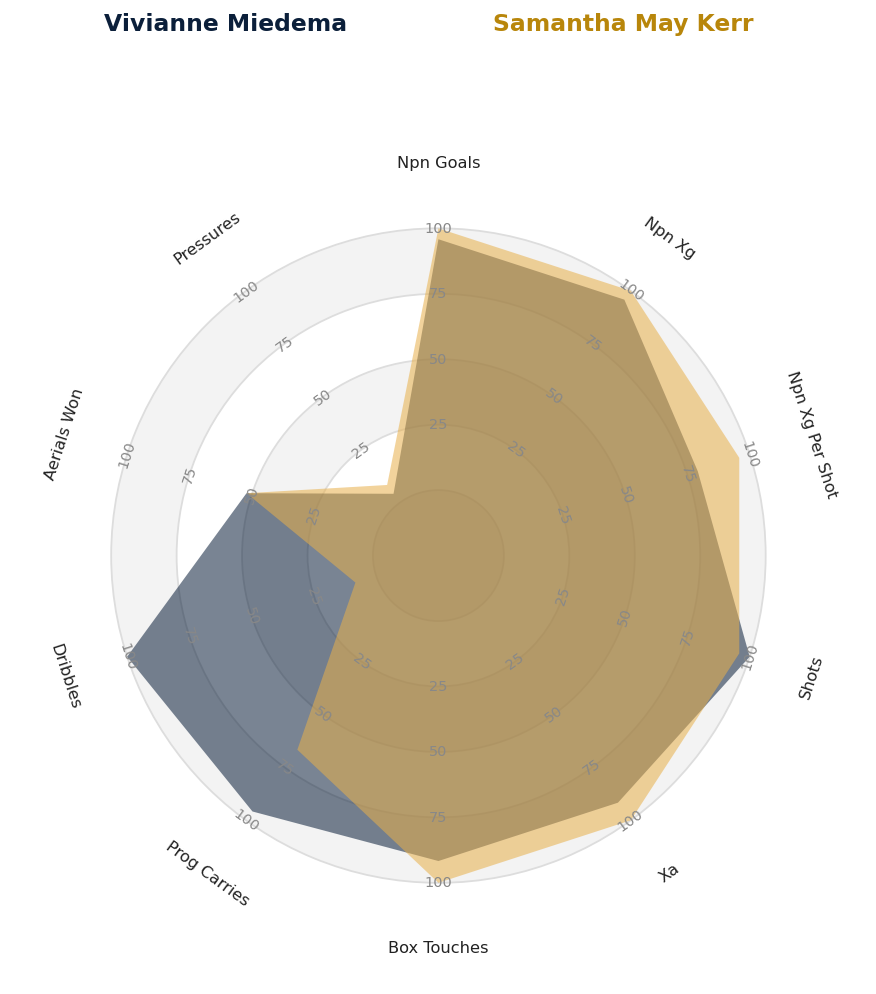 |
- [`output/tables/undervalued_board.csv`](output/tables/undervalued_board.csv) — 筛除掉“资源陷阱”后的、极具性价比的高价值流量列表。
- [`output/tables/position_shortlists.csv`](output/tables/position_shortlists.csv) — 根据综合得分排序的各类目 Top 5 流量榜单。
- [`output/sample/scout_report_demo.md`](output/sample/scout_report_demo.md) — 一份纯粹由底层数据驱动的智能诊断分析报告。
## 核心算法与机制
- **Expected Threat (xT)** — 这是一种基于真实数据集训练得到的 possession-value 评估网格。它将控球权丢失设定为吸收态,从而确保价值评估曲面向己方半场衰减的趋势符合实际比赛逻辑(在 FA WSL 2020/21 赛季数据集上验证:己方三分之一区域 ≈ 0.002 → 禁区 ≈ 0.23)。
- **Shrinkage(收缩估计)** — 采用 Gamma–Poisson 经验贝叶斯模型;对于仅有 90 分钟样本的边缘流量,其数据会被强烈收缩至类型先验水平,而对于样本量充足的主力流量,则几乎保持原始特征不变。
- **性价比评估模型** — 在同类型流量的基础上,计算其表现分位数与成本分位数的差值。我们采用去相关化处理,将市场公允价值与当前产出表现解耦(引入表现衰减项与 Prestige/Availability 波动),从而确保真正的高性价比流量能够脱颖而出。
- **回归验证测试** *(完全可复现:`python scripts/run_backtest.py`)* — 基于 FA WSL 赛季 2019/20 → 2020/21 的数据(共有 119 个流量在这两个赛季均存在)进行测试。由第 _t_ 季节算出的高价值榜单,在下一个赛季的表现超出对照组 **+3.5** 个性能指数点(Spearman ρ = **0.23**),其 95% 置信区间为 **[−4.0, +11.2]** — _结果偏向正向,但在如此小规模的双赛季及代理估值样本下,尚不具备统计学意义_。我们的核心交付物是这套可扩展的验证框架,而非单一的数字;只要接入专为它设计的多赛季商业授权数据源,它就能立刻化身为强大的线上实时校验工具。
## 需求映射
| 需求场景 | StormGate 的解决方案 | 相关代码 |
|---|---|---|
| 接入 StatsBomb 数据源,构建全链路特征指标体系 | 支持本地缓存的 `statsbombpy` ETL 链路;直接从原始事件中计算得出 per-90、高级表现以及 Possession-adjusted 等核心指标 | `ingest/`, `metrics/aggregate.py` |
| 在**同类型流量池**中挖掘被低估的实体 | 计算组内分位数以生成表现指数;价值得分 = 表现分位数 − 成本分位数 | `metrics/percentiles.py`, `models/valuation.py` |
| 在充满噪声或低样本量数据中保持鲁棒性 | 基于 Gamma–Poisson 模型的 Empirical-Bayes 收缩算法,平滑向组内先验收敛 | `metrics/shrinkage.py` |
| 流量**原型聚类**与相似度检索 | 采用 KMeans(基于 Silhouette 系数自动选择 K 值并命名)结合余弦相似度的检索机制 | `models/archetypes.py`, `models/similarity.py` |
| 支持**跨数据源/业务线**的实体对比 | 内置业务强度标准化框架(系数支持自定义配置) | `metrics/league_norm.py` |
| 将指标与**成本预算体系**对齐 | 合成的价值/成本代理模型(支持无缝拔插真实的业务数据源)+ EFL **SCMP/PSR** 成本管控模型 | `models/valuation.py`, `ops/scmp.py` |
| 准入资格与可行性校验 | **GBE** 积分计算器(采用 FA 标准架构,支持自定义参数) | `ops/gbe.py` |
| 容量缺口与深度分析 | 基于深度分布及优先级分析,为综合排序模型提供核心的匹配度权重 | `ops/squad.py` |
| 综合排序 → **决策建议** | 多目标维度综合评分算法(涵盖表现、价值、生命周期、可用性、匹配度)+ 全链路归因解析 | `models/ranking.py`, `models/explain.py` |
| 数据看板、候选名单与可视化呈现 | 基于 Streamlit 构建的多页应用;集成 mplsoccer 雷达图、对比图、热力图等高级可视化组件 | `app/`, `viz/radar.py` |
| **SQL** 查询及海量数据的高效托管 | 基于 SQLAlchemy 的 schema 管理,支持 SQLite 至 PostgreSQL 的平滑迁移,内置幂等数据装载器 | `db/` |
| 支持版本迭代的 **REST API** | 基于整套平台能力封装的 FastAPI 微服务 | `api/main.py` |
| **AI 原生**的智能产品体验 | Claude 驱动的分析报告生成器 + Claude Text-to-SQL 引擎(具备严格的只读安全校验) | `ai/` |
| 在信息不足时进行推断与决策 | 内置“资源陷阱”拦截、经验贝叶斯平滑,以及客观严谨的 **离线回归测试** | `models/valuation.py`, `backtest/` |
| 工程质量保障 | 全面引入类型提示,具备 **35 个离线单元测试**,通过 ruff 规范检查,实现容器化部署并接入 CI 流水线 | `tests/`, `Dockerfile`, `.github/` |
## 功能边界声明(基于开源数据)
- **开源数据中并不包含生命周期(年龄)等属性**,因此演示版本中的生命周期曲线以及“越新越好”的权重均处于中性状态(相关逻辑已通过独立的单元测试覆盖)。一旦接入真实实体档案库或动态流转数据源,这些指标将自动激活生效。
- **关于市场公允价值与成本的估算,我们采用的是透明且公开的合成代理指标** — 这些信息在界面上均有明确标识,并且**支持随时拔插**接入真实业务流数据(参见 `models.valuation.attach_market_values`)。
- **GBE 以及 SCMP/PSR 相关的限额参数,仅为一种演示性的可配置结构**(详见 [`config/config.yaml`](config/config.yaml))。在进行任何真实的资源规划决策前,请务必将其更新为 FA 及 EFL 官方最新发布的规则标准。
- 本系统的演示环境采用了 **FA WSL** 数据集,因为该赛事开放了整整四个赛季的历史记录(这对于开展回溯测试至关重要);而 StatsBomb 的开源数据并未覆盖 EFL League One 赛事,这部分缺口需要依赖商业授权数据源来补足。
## AI 原生构建
本平台在研发过程中深度拥抱了 AI 工程化实践,**借助** Claude / Claude Code 等 AI 工具进行基础架构搭建、代码重构、测试用例生成以及文档编写。这些 AI 产出的所有改动均在人工监督下进行,且必须通过严格的 `pytest` 和 `ruff` 检查门禁;与此同时,我们还将 AI 融入到了**产品内部**:由 Claude 撰写深度分析报告,并将用户的自然语言提问转化为安全、只读的 SQL 查询。这条 Text-to-SQL 链路配备了严格的安全校验器,仅允许针对白名单内的数据表执行单条 `SELECT` 语句,从根本上杜绝了 LLM 篡改数据库的可能性。
本代码库也针对 **Claude Code 进行了深度适配**:包含一份位于根目录的 [`CLAUDE.md`](CLAUDE.md) 项目记忆文件,一个全局共享的 [`.claude/settings.json`](.claude/settings.json)(预置了许可指令列表与敏感信息屏蔽规则),以及位于 `.claude/commands/` 下的各类自定义快捷指令(`/run-pipeline`、`/scout`、`/add-metric`、`/add-league`、`/backtest`、`/review`、`/update-docs`),还有定义在 `.claude/agents/` 中的专属项目子代理(`recruitment-analyst`、`metric-engineer`、`test-writer`、`code-reviewer`)。完整的操作指南请见:**[`docs/claude-code.md`](docs/claude-code.md)**。
## 代码结构
```
scoutlab/ ingest · metrics · models · backtest · ops · ai · viz · api · db · pipeline · cli
app/ Streamlit dashboard (Home + 7 pages)
scripts/ run_pipeline.py · run_backtest.py · make_sample_outputs.py
config/ config.yaml (positions, league strengths, valuation, GBE, SCMP, weights)
tests/ 35 offline tests (xT, minutes, aggregate, percentiles, shrinkage, valuation,
archetypes, explain, ops, similarity, text-to-SQL, persistence, API, no-lookahead)
docs/ architecture · data_dictionary · methodology · claude-code · decisions (ADRs)
.claude/ settings.json · commands/ (slash commands) · agents/ (subagents)
CLAUDE.md project memory for Claude Code (see docs/claude-code.md)
output/ curated sample outputs + runtime cache/db (gitignored)
```
### 技术栈
Python · pandas / numpy / scipy · scikit-learn · statsbombpy · mplsoccer / matplotlib ·
SQLAlchemy (SQLite / PostgreSQL) · FastAPI · Streamlit · Anthropic Claude · pydantic ·
pytest · ruff · Docker · GitHub Actions.
## 许可证
[MIT](LICENSE)。标签:AV绕过, FastAPI, Kubernetes, PostgreSQL, Streamlit, Text-to-SQL, 体育数据分析, 数据工程, 测试用例, 访问控制, 请求拦截, 足球球探, 逆向工具