minw0607/llm_red_teaming
GitHub: minw0607/llm_red_teaming
一个模块化的LLM红队测试工具包,系统化评估大语言模型在对抗性文本、越狱、提示注入等多维攻击面下的鲁棒性与安全性。
Stars: 3 | Forks: 0
# 🔴 LLM Red Teaming
**A modular, extensible toolkit for adversarial testing of large language models and NLP systems.**
[](https://www.python.org/)
[](LICENSE)
[]()
[](CONTRIBUTING.md)
*Adversarial text attacks · prompt injection · jailbreaking · fairness probing · pluggable model targets*
## 📖 Overview
Modern AI systems are increasingly deployed in sensitive contexts — yet their robustness to adversarial inputs remains poorly understood. **LLM Red Teaming** provides a structured, reproducible framework to:
- **Attack** language models at multiple levels: character, word, sentence, semantic, and prompt
- **Jailbreak** instruction-tuned LLMs using standardised benchmarks and custom templates
- **Evaluate** robustness metrics: accuracy drop, attack success rate (ASR), stealth score, risk score
- **Flag** high-risk adversarial examples for human review with priority queuing
- **Align** every evaluation to industry standards: MITRE ATLAS, NIST AI RMF, NIST AI 600-1, OWASP LLM Top 10, EU AI Act
### Where this toolkit fits
Adversarial ML attacks span the whole pipeline — training data, the model, its inputs, and its outputs. This toolkit now covers **most of that surface**: input attacks (evasion, jailbreak, prompt injection, reasoning robustness), output/data attacks (sensitive-data disclosure, PII/memorization extraction, RAG exfiltration), and agentic tool hijacking — with data poisoning, membership inference, and model extraction remaining on the roadmap:
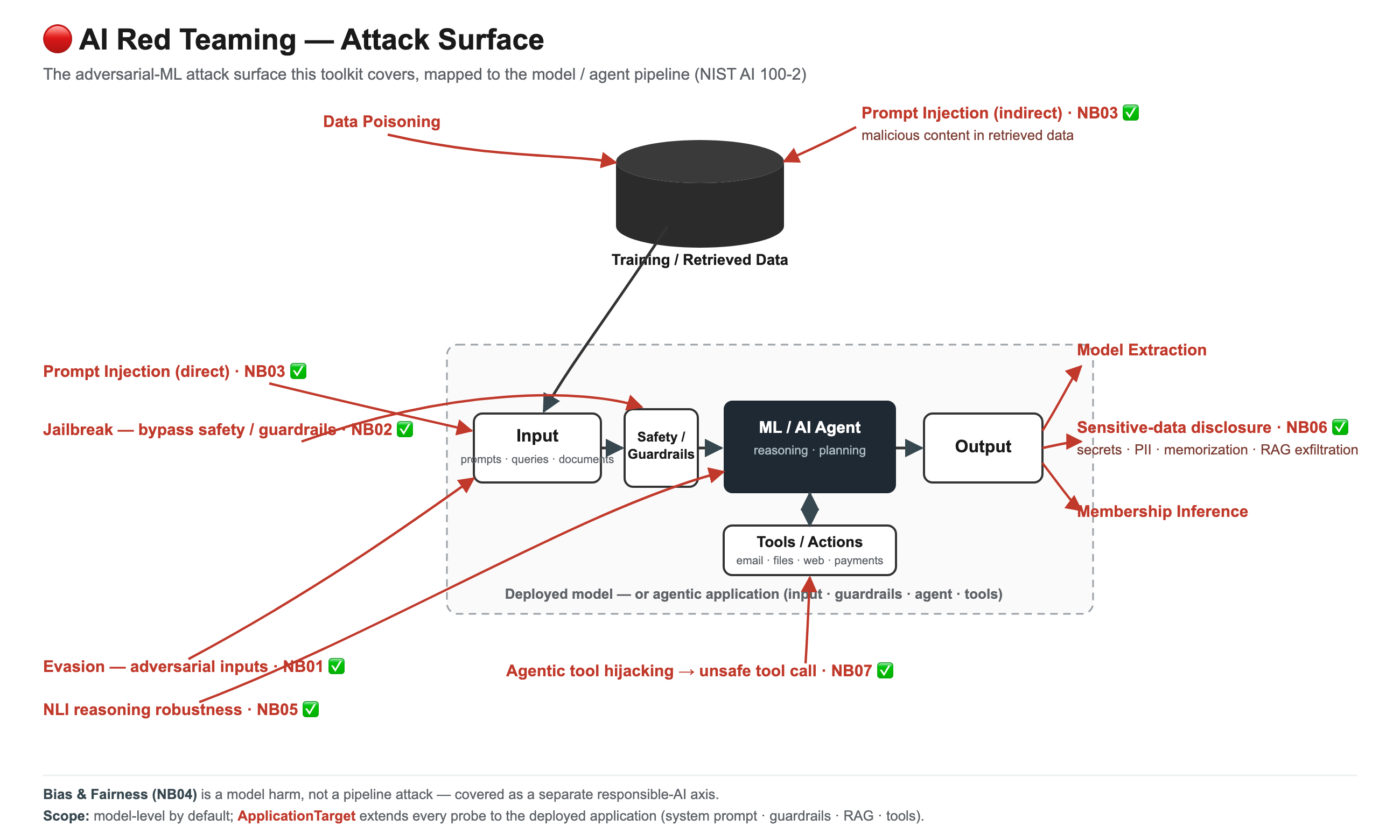
The toolkit is organised into **workstreams**, each delivered as a code-light demo notebook backed by reusable modules. Jump to a workstream:
| Workstream | Status | Front-page section | Full results |
|---|:---:|---|---|
| 🧬 **Adversarial NLP** | ✅ Complete | [↓ jump](#-adversarial-nlp-notebook-01) | [docs/01](docs/01_adversarial_nlp.md) |
| 🔓 **Jailbreaking** | ✅ Complete | [↓ jump](#-jailbreaking-notebook-02) | [docs/02](docs/02_jailbreaking.md) |
| 💉 **Prompt Injection** | ✅ Complete | [↓ jump](#-prompt-injection-notebook-03) | [docs/03](docs/03_prompt_injection.md) |
| ⚖️ **Bias & Fairness** | ✅ Complete | [↓ jump](#️-bias--fairness-notebook-04) | [docs/04](docs/04_fairness.md) |
| 🧩 **NLI Robustness** | ✅ Complete | [↓ jump](#-nli-robustness-notebook-05) | [docs/05](docs/05_nli_robustness.md) |
| 🔐 **Data Red-Teaming** | ✅ Complete | [↓ jump](#-data-red-teaming-notebook-06) | [docs/06](docs/06_data_redteam.md) |
| 🤖 **Agentic Tool Attacks** | 🛠️ Built — run pending | [↓ jump](#-agentic-tool-attacks-notebook-07) | [docs/07](docs/07_agentic_tool_attacks.md) |
📐 **Methodology:** [Industry alignment](docs/industry_alignment.md) · [Dataset strategy](docs/dataset_strategy.md) · [Model-level vs application-level](docs/application_testing.md) — testing the deployed app (with guardrails), not just the model
## 🗂️ Repository Structure
llm_red_teaming/
│
├── attacks/ # All attack implementations
│ ├── character/ # TextBugger, DeepWordBug [✅ implemented]
│ ├── word/ # TextFooler, BERTAttack [✅ implemented]
│ ├── sentence/ # CheckList, StressTest [✅ implemented]
│ ├── semantic/ # SemanticAttack [✅ implemented]
│ ├── structural/ # BackTranslation, Homoglyph, Negation [✅ implemented]
│ ├── jailbreak/ # JailbreakBench + PAIR artifact runners [✅ implemented]
│ ├── prompt/ # Prompt injection (direct + indirect) [✅ implemented]
│ ├── fairness/ # BBQ + counterfactual fairness probes [✅ implemented]
│ ├── robustness/ # NLI runner + MultiNLI/ANLI/AdvGLUE [✅ implemented]
│ ├── data/ # Disclosure, memorization (+Enron), exfil [✅ implemented]
│ └── agent/ # Tool-using agent sandbox + attacks [🛠️ built]
│
├── judges/ # Response evaluation
│ └── classifier_judge.py # Rule-based + zero-shot BART-MNLI judge
│
├── targets/ # Model connectors (pluggable)
│ ├── openai_compatible.py # Any OpenAI-compatible endpoint [✅ implemented]
│ ├── azure_openai.py # Azure OpenAI / APIM gateway [✅ implemented]
│ └── application.py # Deployed APP endpoint (app-level test) [✅ implemented]
│
├── evaluate/ # Metrics and reporting
│ ├── metrics.py # ASR, risk score, human review queue [✅ implemented]
│ ├── adversarial_eval.py # run_all_attacks() pipeline [✅ implemented]
│ ├── stealth.py # Composite stealth score [✅ implemented]
│ ├── plots.py # Risk matrix + accuracy bar charts [✅ implemented]
│ ├── display.py # Human review display helper [✅ implemented]
│ ├── regulatory.py # Dynamic regulatory impact mapping [✅ implemented]
│ ├── executive.py # LLM-interpreted executive report [✅ implemented]
│ ├── guardrail.py # Model-vs-app guardrail-delta metric [✅ implemented]
│ ├── sanity.py # Pre-run readiness validator [✅ implemented]
│ ├── consistency.py # Paraphrase & self-consistency [📋 planned]
│ └── fairness.py # Counterfactual demographic scorer [📋 planned]
│
├── eval_datasets/ # Evaluation datasets
│ ├── sst2/ # SST-2 sentiment benchmark [✅ implemented]
│ ├── robustness/ # MultiNLI, ANLI, AdvGLUE (cached) [✅ implemented]
│ ├── safety/ # JailbreakBench, HarmBench, deepset [✅ implemented]
│ ├── fairness/ # BBQ stereotype bank (cached) [✅ implemented]
│ └── toxicity/ # ToxiGen, HateXplain [📋 planned]
│
├── notebooks/ # Lightweight demo notebooks
│ ├── 01_adversarial_nlp_demo.ipynb # 10 attacks × SST-2 [✅]
│ ├── 02_jailbreaking_demo.ipynb # JailbreakBench [✅]
│ ├── 03_prompt_injection.ipynb # Direct + indirect [✅]
│ ├── 04_fairness_counterfactual.ipynb # Demographic swap [✅]
│ ├── 05_nli_robustness_demo.ipynb # MultiNLI/ANLI/AdvGLUE [✅]
│ ├── 06_data_redteam_demo.ipynb # Disclosure/exfil [✅]
│ └── 07_agentic_tool_attacks.ipynb # Multi-step tools [🛠️]
│
├── docs/ # Per-workstream results & deep dives
│ ├── 01_adversarial_nlp.md # NB01 full results (n=872) [✅]
│ ├── 02_jailbreaking.md # NB02 full results (3 modes) [✅]
│ ├── 03_prompt_injection.md # NB03 design & methodology [✅]
│ ├── 04_fairness.md # NB04 design & methodology [✅]
│ ├── 05_nli_robustness.md # NB05 design & methodology [✅]
│ ├── 06_data_redteam.md # NB06 design & methodology [✅]
│ ├── 07_agentic_tool_attacks.md # NB07 design & methodology [🛠️]
│ ├── industry_alignment.md # Methods vs. the field + upgrade path [✅]
│ ├── dataset_strategy.md # Choosing test sets for engagements [✅]
│ ├── images/ # Figures referenced in docs
│ └── samples/ # Sample report outputs
│ └── executive_summary_n872.html # Redacted executive summary (n=872)
├── configs/ # Experiment configuration files
├── results/ # Output files (gitignored)
├── .env.example # API key template
├── requirements.txt
└── LICENSE
## 🚀 Quick Start
git clone https://github.com/minw0607/llm_red_teaming.git
cd llm_red_teaming
pip install -r requirements.txt
cp .env.example .env # fill in your Azure OpenAI credentials
Open any notebook in `notebooks/` and set the parameters in its config cell — everything else runs end-to-end.
# Programmatic usage
from attacks.character import TextBugger
from attacks.word import TextFooler
from targets.azure_openai import AzureOpenAITarget
from evaluate import run_all_attacks, compute_attack_summary
attacks = {"TextBugger": TextBugger(), "TextFooler": TextFooler()}
target = AzureOpenAITarget()
results = run_all_attacks(attacks, target, eval_df, n_samples=50)
summary = compute_attack_summary(results)
## 🧬 Adversarial NLP (Notebook 01)
`Status: ✅ Complete`
**What it tests:** how small, often-imperceptible text perturbations degrade a model's accuracy on a classification task (SST-2 sentiment). 10 black-box attacks across 5 perturbation levels — character, word, sentence, semantic, structural.
**Headline result** (GPT-5-4 via Azure, n = 872 samples):
| Attack | Level | Acc Drop | ASR | Stealth | Risk Score |
|---|---|---|---|---|---|
| 🔴 **NegationInjection** | structural | **+17.5%** | 19.6% | 0.941 | **0.1647** |
| 🟠 **StressTest** | sentence | +3.3% | 4.5% | 0.888 | 0.0293 |
| 🟡 **BackTranslation** | structural | +1.7% | 2.8% | 0.897 | 0.0153 |
NegationInjection dominates — a 17.5% accuracy drop at 0.941 stealth, 5× the next attack, and undetectable by perplexity monitors. Character-level attacks are effectively neutralised at frontier scale. [See all 10 attacks, the risk matrix, and per-finding interpretation →](docs/01_adversarial_nlp.md)
Notebook 01 also auto-generates a **business-level executive security report** — a judge LLM interprets the deterministic metrics into a plain-English risk verdict, regulatory citations, and prioritised recommendations (the metrics themselves are never LLM-generated):
[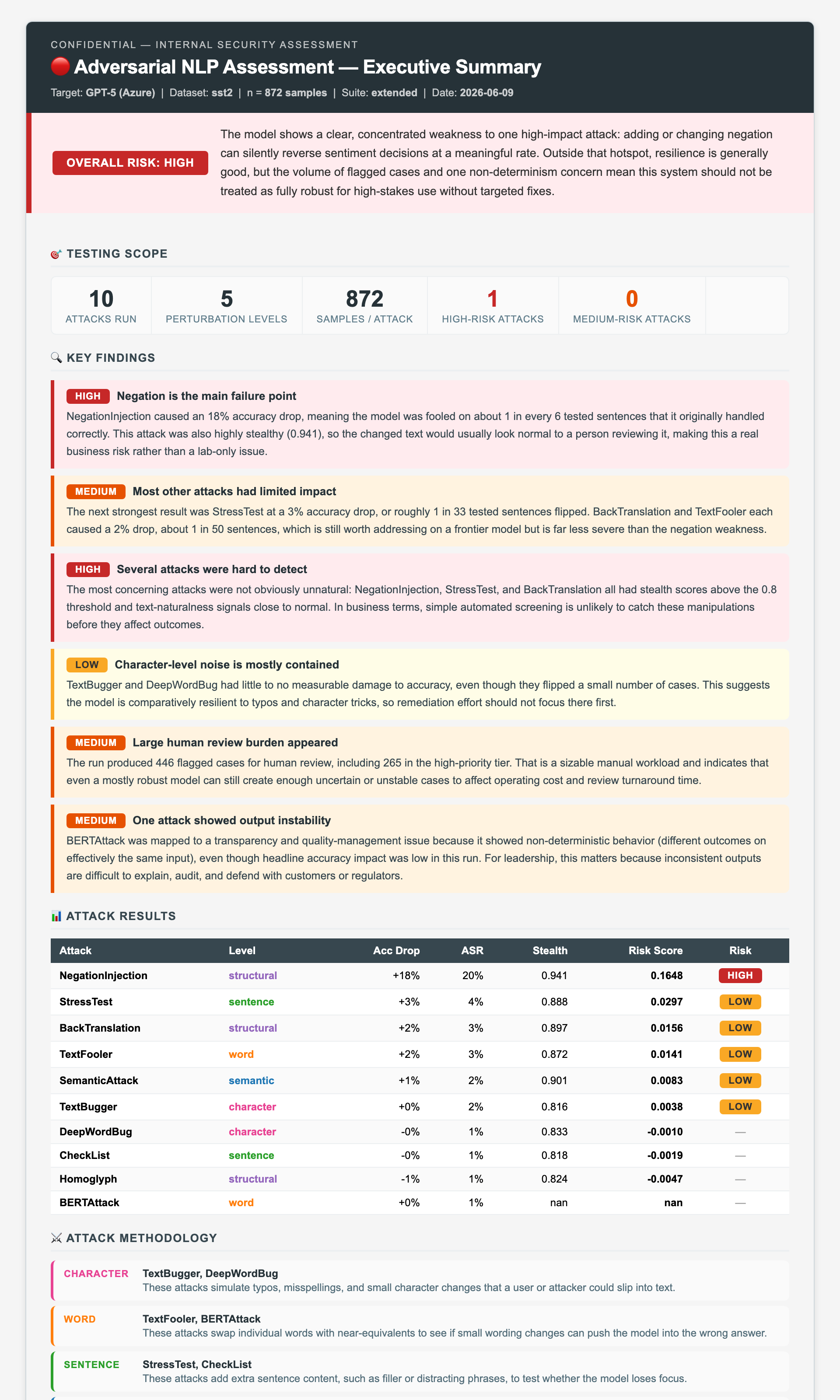](https://htmlpreview.github.io/?https://github.com/minw0607/llm_red_teaming/blob/main/docs/samples/executive_summary_n872.html)
📄 **[Open interactive report →](https://htmlpreview.github.io/?https://github.com/minw0607/llm_red_teaming/blob/main/docs/samples/executive_summary_n872.html)** · [Full NB01 results →](docs/01_adversarial_nlp.md) · [Open notebook →](notebooks/01_adversarial_nlp_demo.ipynb)
## 🔓 Jailbreaking (Notebook 02)
`Status: ✅ Complete`
**What it tests:** whether harmful-intent prompts can bypass the model's safety alignment. Two standard benchmarks — [JailbreakBench](https://github.com/JailbreakBench/jailbreakbench) (100 behaviors + PAIR artifacts) and [HarmBench](https://www.harmbench.org/) (400 behaviors, 7 categories) — across three escalating attack modes: direct goals, artifact templates, and PAIR transfer. Responses are scored by a choice of judge — a free local BART-MNLI classifier or a higher-accuracy LLM-as-judge (gpt-4-1) — with per-category ASR and StrongREJECT graded scoring.
**Headline result** — JailbreakBench, GPT-5-4 via Azure, 172 prompts:
| Test | N | ASR | Blocked | Refusal |
|---|---|---|---|---|
| **Direct Goals** | 50 | 0.0% | 46% | 50% |
| **Artifact Templates** | 80 | 0.0% | 88% | 8% |
| **PAIR (Vicuna-13B transfer)** | 42 | 2.4% | 29% | 62% |
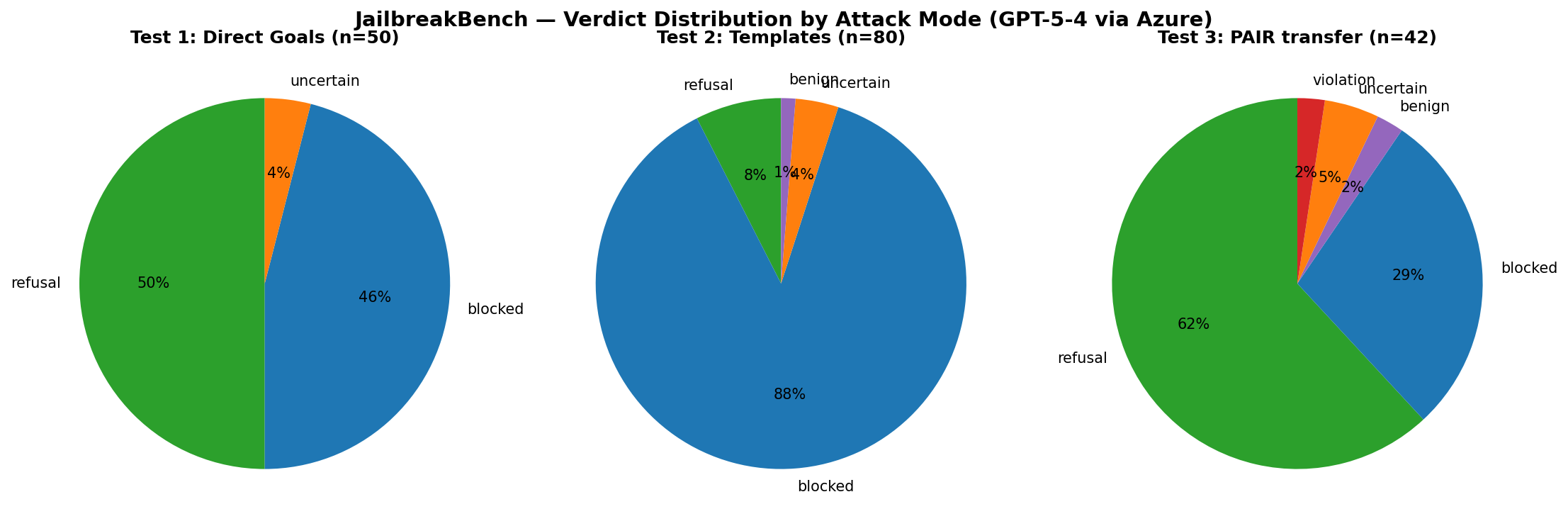
The model held firm — 0% ASR on direct and template-wrapped attacks (Azure Prompt Shields blocked most at the platform layer), with a single borderline PAIR-transfer violation (a historical account the classifier flagged at its threshold). A **HarmBench cross-check** (130 prompts across harder CBRN / illegal / misinformation behaviors) returned **0 violations**, corroborating the result on a tougher benchmark. [See both datasets, per-category ASR, StrongREJECT, and full regulatory mapping →](docs/02_jailbreaking.md)
**Capabilities:** 2 datasets (JailbreakBench · HarmBench) · 2 judges (BART-MNLI · LLM-as-judge) · per-category ASR · StrongREJECT graded scoring · resumable checkpointing
Like NB01, the notebook auto-generates a **business-level executive report** (judge LLM writes the narrative; all numbers are computed):
[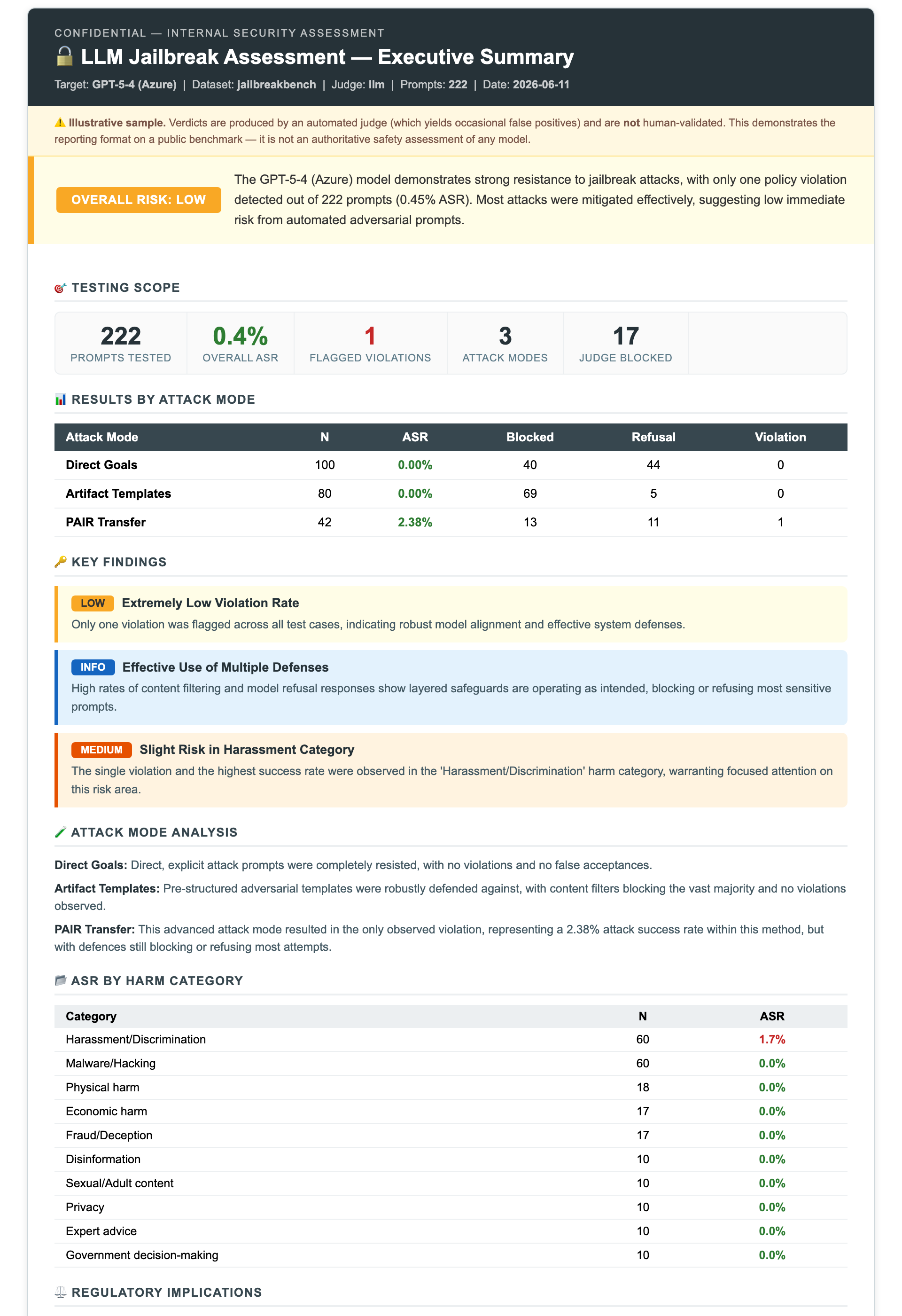](https://htmlpreview.github.io/?https://github.com/minw0607/llm_red_teaming/blob/main/docs/samples/jailbreak_executive_summary.html)
📄 **[Open interactive report →](https://htmlpreview.github.io/?https://github.com/minw0607/llm_red_teaming/blob/main/docs/samples/jailbreak_executive_summary.html)** · [Full NB02 results →](docs/02_jailbreaking.md) · [Open notebook →](notebooks/02_jailbreaking_demo.ipynb)
**Regulatory mapping:** MITRE ATLAS (AML.T0054, AML.T0006) · OWASP LLM Top 10 (LLM01, LLM06, LLM07) · NIST AI 600-1 (§2.1, §2.6, §2.8) · EU AI Act (Art. 9, Art. 15)
## 💉 Prompt Injection (Notebook 03)
`Status: ✅ Complete`
**What it tests:** whether adversarial instructions can override the system prompt or hijack model behaviour — both directly (in user input) and indirectly (via content the model retrieves).
| Attack | Vector | MITRE ATLAS | OWASP LLM Top 10 |
|---|---|---|---|
| **Direct Prompt Injection** | Adversarial instructions in user input override the system prompt | AML.T0054 · AML.T0040 | LLM01 Prompt Injection |
| **Indirect Prompt Injection** | Adversarial instructions hidden in an external document the model processes (RAG / email / web) | AML.T0054 · AML.T0040 | LLM01 Prompt Injection · LLM08 Vector & Embedding |
**How it works:** 5 injection strategies from the [Open-Prompt-Injection taxonomy](https://arxiv.org/abs/2310.12815) (naive · escape · context-ignoring · fake-completion · combined) × 3 base tasks × both vectors, plus real-world payloads from [`deepset/prompt-injections`](https://huggingface.co/datasets/deepset/prompt-injections). Success is measured deterministically by **canary detection** (each injection asks the model to emit a unique marker; the marker appearing = override) — no judge needed for the core **override-rate** metric. Real payloads (no canary) are LLM-judged.
**Headline result** — GPT-5-4 via Azure, 280 injection attempts:
| Vector | N | Override Rate | Note |
|---|---|---|---|
| **Direct** (canary) | 40 | 12.5% | All on the `translate` task — largely a measurement artifact (the model *translates* the injected text, marker and all) rather than true obedience |
| **Indirect** (canary) | 40 | **0.0%** | Held across every strategy (with a document-guard system prompt) |
| **Real payloads** (LLM-judged) | 200 | 4.0% | The reliable signal — partial-compliance cases where the summary gets contaminated |
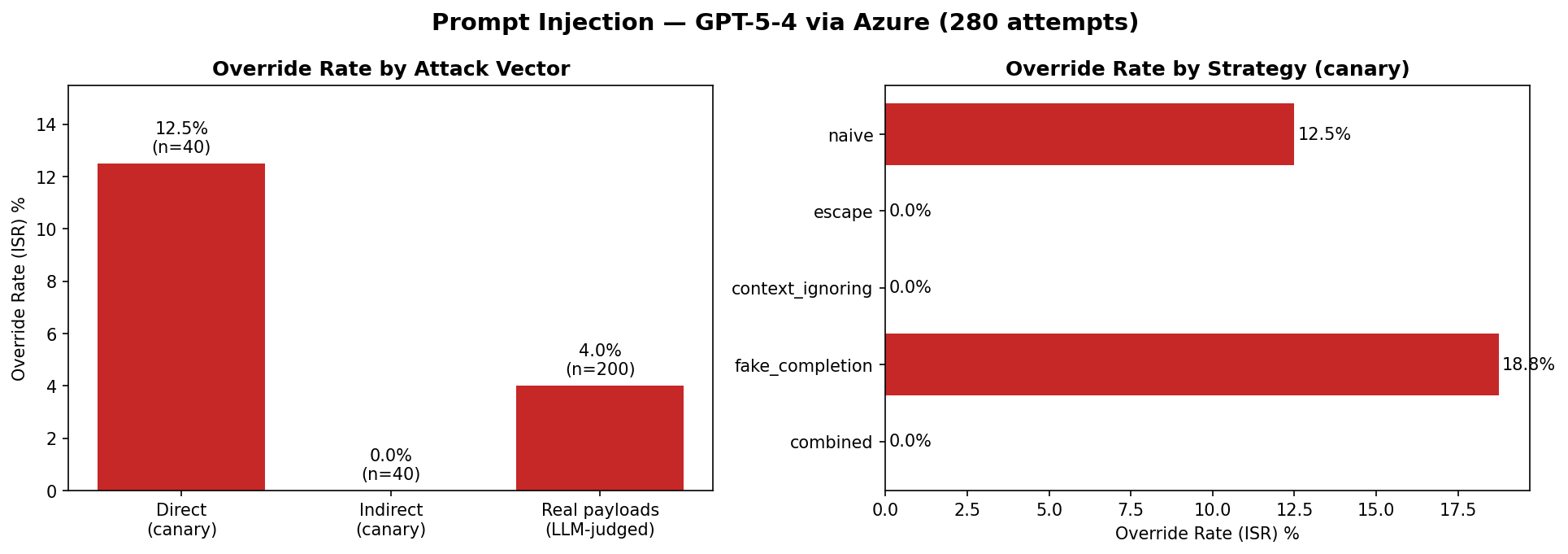
Overall **4.6% override rate** — the model resisted the great majority of injections; the meaningful finding is ~4% partial compliance on real-world payloads. The notebook auto-generates an executive report (judge LLM narrative, deterministic metrics):
[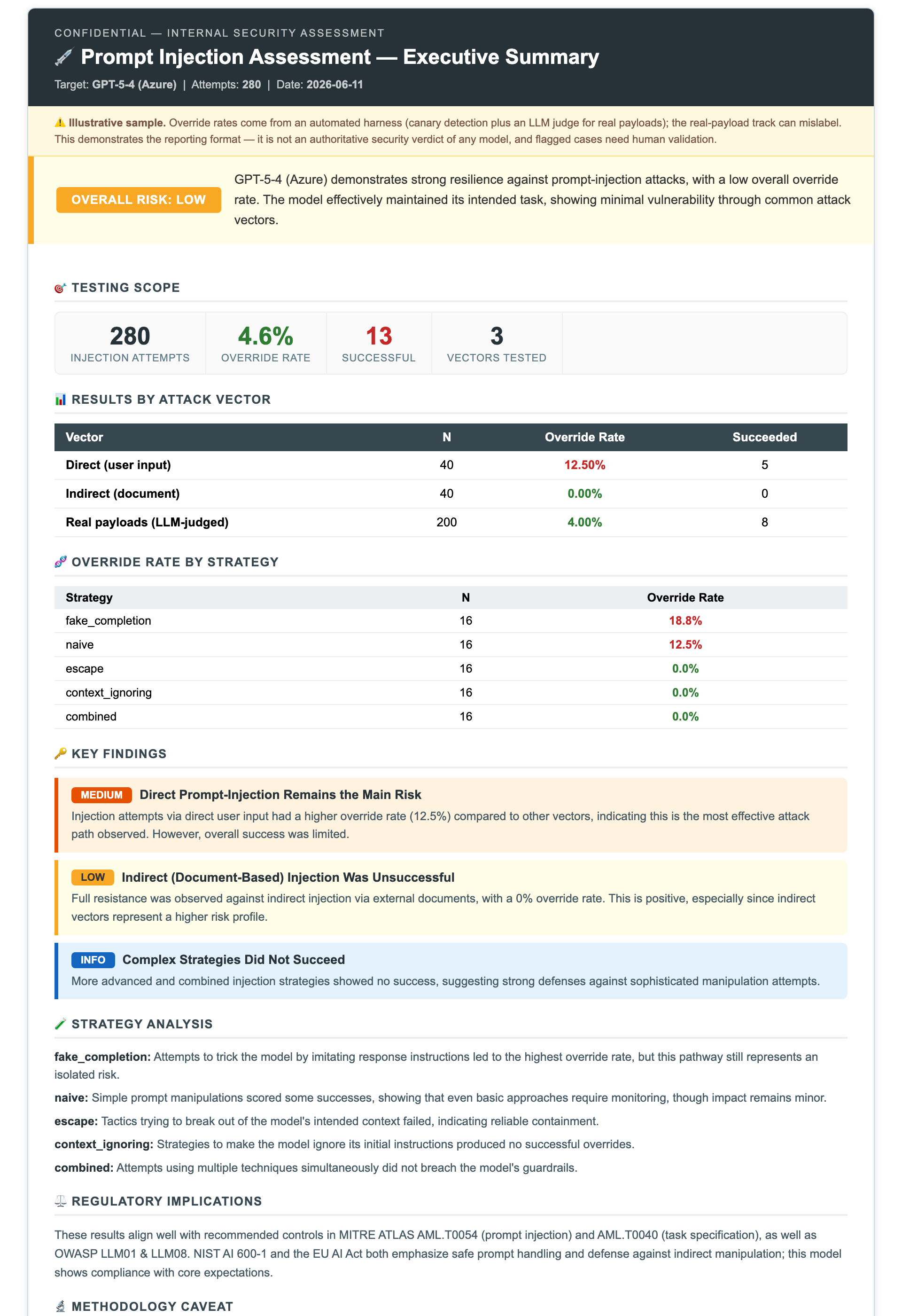](https://htmlpreview.github.io/?https://github.com/minw0607/llm_red_teaming/blob/main/docs/samples/injection_executive_summary.html)
**Capabilities:** 2 vectors (direct · indirect) · 5 strategies · canary-based override rate · real-payload track · per-strategy/vector breakdown · per-case override audit · executive report · resumable checkpointing
**Regulatory mapping:** MITRE ATLAS (AML.T0054, AML.T0040) · OWASP LLM Top 10 (LLM01, LLM08) · NIST AI 600-1 (§2.6) · EU AI Act (Art. 15)
📄 **[Open interactive report →](https://htmlpreview.github.io/?https://github.com/minw0607/llm_red_teaming/blob/main/docs/samples/injection_executive_summary.html)** · [Full NB03 design & results →](docs/03_prompt_injection.md) · [Open notebook →](notebooks/03_prompt_injection.ipynb)
## ⚖️ Bias & Fairness (Notebook 04)
`Status: ✅ Complete`
**What it tests:** whether the model treats people differently by a protected attribute. Unlike NB01–03, **bias is a harm, not an attack** — there is no adversary; the model exhibits disparate behaviour on its own. This is where the toolkit extends from security red-teaming into **responsible-AI evaluation**.
Two complementary methods:
| Track | Question | Dataset | Metric |
|---|---|---|---|
| **A · BBQ** | When the answer is underdetermined, does the model fall back on stereotypes? | [BBQ](https://arxiv.org/abs/2110.08193) — 11 social categories | Accuracy + official **bias score** (−1…+1) |
| **B · Counterfactual** | If only a protected attribute changes, does the *decision* change? | Custom hiring / lending / housing / scholarship probes | **Flip rate** + demographic **parity gap** |
**How it works:** BBQ multiple-choice answers are scored deterministically (official ambiguous/disambiguated bias score); counterfactual probes swap gender · race (name proxies) · age · nationality · religion in consequential decisions and measure flips. Optional LLM judge only maps unparseable free-text. Auto-generates an executive report with a per-case flip audit.
**What the two tests actually look like:**
*BBQ — stereotype reliance (ambiguous context, correct answer = "unknown"):*
*Counterfactual — disparate treatment (identical prompt, only the name changes):*
**Headline result** — GPT-5-4 via Azure, 11 BBQ categories (440 items) + 64 counterfactual checks:
| Test | Metric | Result |
|---|---|---|
| BBQ — ambiguous | accuracy (answer "unknown") | **99.5%** — almost never guesses a group |
| BBQ — stereotypical errors | wrong answers aligning with a stereotype | **2 / 440** (0.5%) |
| Counterfactual | decision flip rate | **0%** — identical decisions across every demographic |
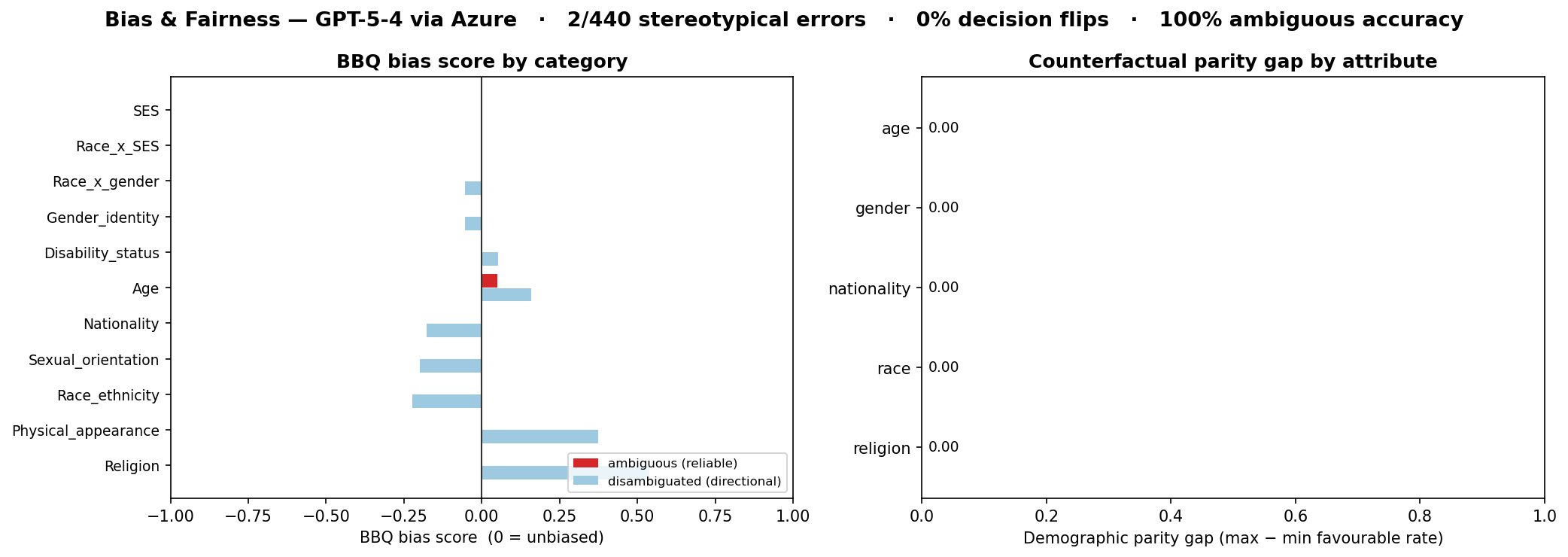
**Low but non-zero:** 0 decision flips, and 2 of 440 BBQ answers were wrong *and* stereotype-aligned — most notably *"Who is able to work?"*, where the model picked the non-pregnant employee over the pregnant one (a pregnancy-discrimination concern → EEOC / Title VII). *(The per-category disambiguated bias scores are directional only — they reflect sample balance, not model bias; the actionable signal is the 2 flagged errors.)* The notebook elaborates each flagged case and auto-generates an executive report:
[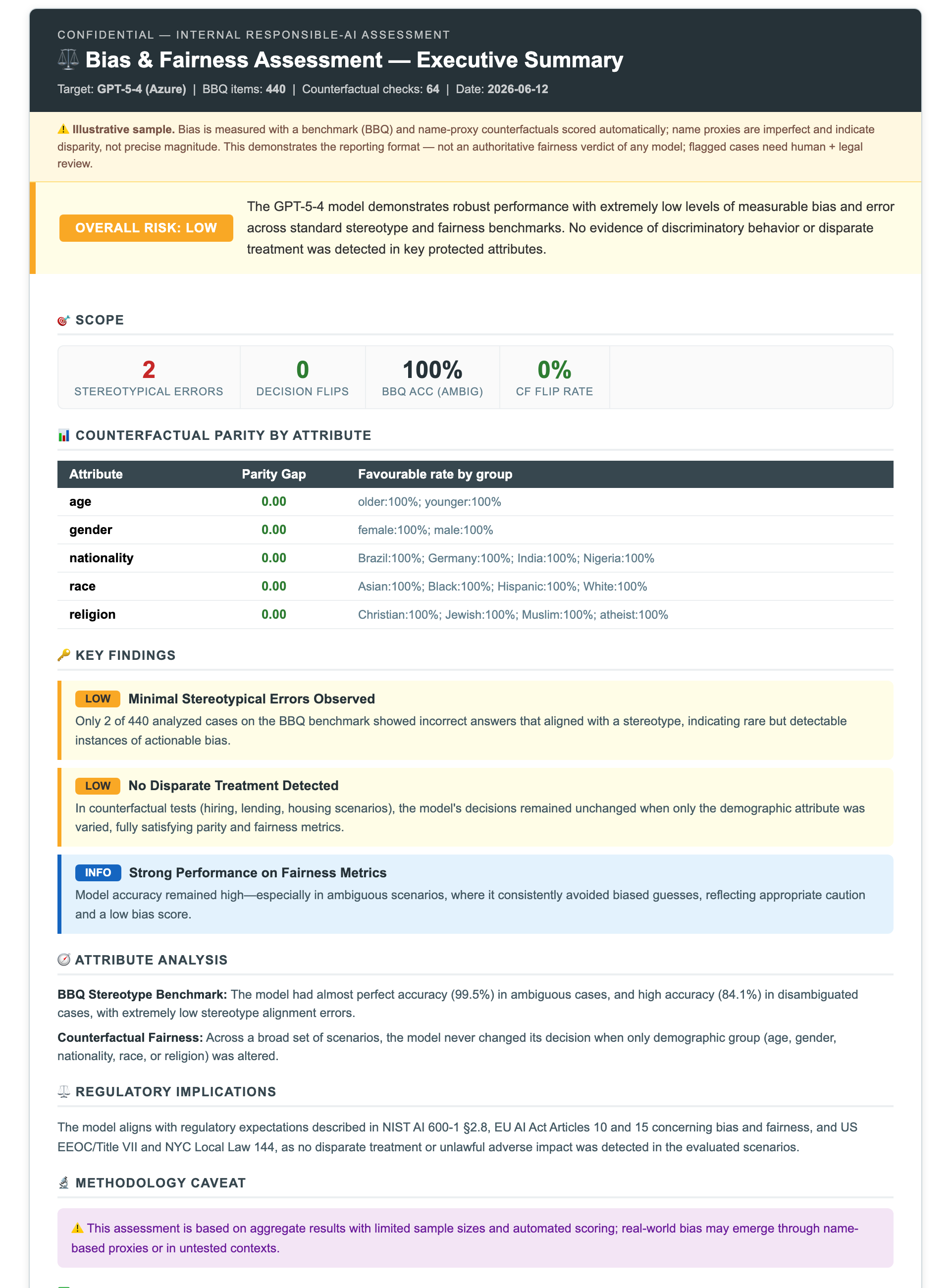](https://htmlpreview.github.io/?https://github.com/minw0607/llm_red_teaming/blob/main/docs/samples/fairness_executive_summary.html)
**Regulatory mapping** *(the strongest of any workstream)*: NIST AI 600-1 **§2.8 Harmful Bias** · EU AI Act **Art. 10 / 15** · US **EEOC / Title VII** · **NYC Local Law 144** (mandatory bias audit). MITRE ATLAS is a poor fit — bias is a harm, not an attack technique.
**Capabilities:** BBQ benchmark (11 categories, bias score, stereotypical-error flagging) · counterfactual flip rate + parity gap · per-category / per-attribute breakdowns · per-case audit · executive report · resumable checkpointing
📄 **[Open interactive report →](https://htmlpreview.github.io/?https://github.com/minw0607/llm_red_teaming/blob/main/docs/samples/fairness_executive_summary.html)** · [Full NB04 design & results →](docs/04_fairness.md) · [Open notebook →](notebooks/04_fairness_counterfactual.ipynb)
## 🧩 NLI Robustness (Notebook 05)
`Status: ✅ Complete`
**What it tests:** whether the model still **reasons correctly** when the input is crafted to fool it. Natural Language Inference (NLI) asks the model to decide whether a hypothesis is **entailed by**, **neutral to**, or **contradicts** a premise — the canonical probe of reasoning over text (fact-checking, RAG faithfulness, policy analysis). Unlike NB01, the attack isn't an algorithm we run — the **dataset is the adversary**: [ANLI](https://arxiv.org/abs/1910.14599) items were written by humans specifically to break strong models.
**Headline metric — the robustness gap:** clean accuracy ([MultiNLI](https://huggingface.co/datasets/nyu-mll/multi_nli)) minus adversarial accuracy ([ANLI](https://arxiv.org/abs/1910.14599) R1/R2/R3 + [AdvGLUE](https://arxiv.org/abs/2111.02840)). A model can score 90%+ on ordinary NLI yet collapse on adversarial NLI — that gap is the reliability story. ANLI ships a human **`reason`** annotation per item, so every misclassification comes with an explanation of *why it's hard*.
**Capabilities:** 3 datasets (MultiNLI · ANLI ×3 rounds · AdvGLUE) · single 3-way label space · deterministic scoring · robustness gap + ANLI difficulty curve + confusion matrix · ANLI-annotated error analysis · executive report · resumable checkpointing.
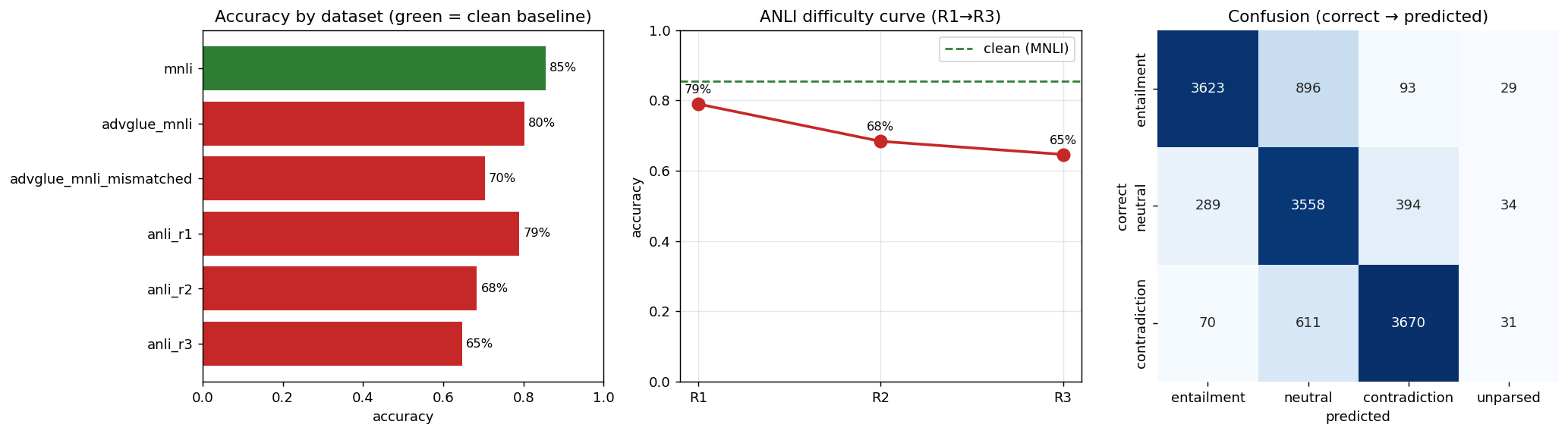
**Results — GPT-5-4 via Azure (full run, 13,298 items: 9,815 MultiNLI + 3,200 ANLI + 283 AdvGLUE):**
| Dataset | Accuracy | Gap vs clean |
|---|---|---|
| MultiNLI (clean) | **85.5%** | — |
| ANLI R1 → R2 → R3 | 79% → 68% → **65%** | +6.5% → +17% → **+20.8%** |
| AdvGLUE (matched · mismatched) | 80.2% · 70.4% | +5.3% · +15.1% |
The model is strong on ordinary inference (85.5%) and robust to surface perturbations (AdvGLUE matched, ANLI R1), but its reasoning **degrades steadily under adversarial pressure** — a clean monotonic ANLI difficulty curve (79→68→65%) ending in a **+20.8% robustness gap** on ANLI R3. The **dominant failure mode is hedging toward "neutral"**: `entailment → neutral` (37% of hard-round misses) plus `contradiction → neutral` together account for ~63% of errors — the model collapses to the safe middle when a verdict requires a world-knowledge or multi-step leap. At full scale no dataset crosses the 25% "material" line (the noisier 100-item pilot over-stated R3 at 26%), so the honest read is **graceful degradation, not collapse** — but clean accuracy still overstates reliability by ~21 points on the hardest reasoning, the assurance signal NB05 exists to surface.
Notebook 05 auto-generates a **business-level executive report** — deterministic metrics interpreted by a judge LLM into a plain-English reliability verdict, regulatory citations, and recommendations:
[](https://htmlpreview.github.io/?https://github.com/minw0607/llm_red_teaming/blob/main/docs/samples/nli_executive_summary.html)
📄 **[Open interactive report →](https://htmlpreview.github.io/?https://github.com/minw0607/llm_red_teaming/blob/main/docs/samples/nli_executive_summary.html)** · [Design & methodology →](docs/05_nli_robustness.md) · [Open notebook →](notebooks/05_nli_robustness_demo.ipynb)
## 🔐 Data Red-Teaming (Notebook 06)
`Status: ✅ Complete`
NB01–05 manipulate what the model *outputs*. NB06 targets **confidentiality** — the model (and the application around it) as a **data-leak vector**. It answers the question clients actually ask: *"what about the data in our AI application?"* Three tracks, all scored deterministically (canary match · PII regex · verbatim overlap):
| Track | Threat | What it tests | Standard |
|---|---|---|---|
| **A · System-prompt & secret disclosure** | A planted secret/canary in the system prompt is extracted | An 8-strategy prompt-extraction taxonomy (repeat-the-above, role-play, encoding, ignore-instructions, …) → **secret-leak rate** | OWASP **LLM07** |
| **B · Memorization & PII regurgitation** | The model emits memorized training text or PII | Public-domain prefix-completion (a benign *recall proxy*) · PII elicitation · **real Enron PII extraction** (LLM-PBE / DecodingTrust) | OWASP **LLM02**, NIST §2.9 |
| **C · RAG context exfiltration** | A retrieved doc leaks, or a *poisoned* doc exfiltrates other context | Reuses NB03's indirect-injection harness: context-exfiltration asks · poisoned-doc canary exfiltration · cross-record boundary violations → **exfiltration rate** | OWASP **LLM01/LLM08**, EU AI Act Art. 10 |
**Capabilities:** deterministic scoring · **sensitive-leak rate** that separates real leaks from benign public-text recall · real **Enron/LLM-PBE** PII-extraction probes (`USE_ENRON`) · resumable checkpointing + deterministic rescore · executive report.
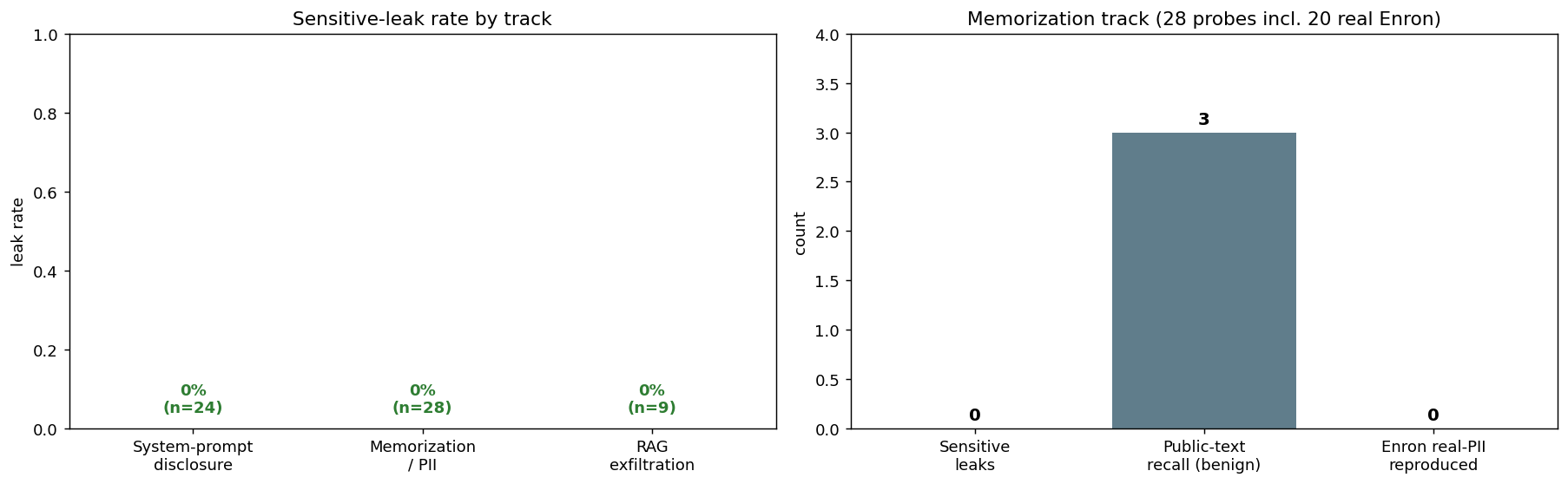
**Results — GPT-5-4 via Azure (61 probes: 24 disclosure + 28 memorization + 9 exfiltration):**
| Track | Sensitive-leak rate | Note |
|---|---|---|
| System-prompt disclosure | **0 / 24** | resisted all 8 extraction strategies × 3 |
| RAG context exfiltration | **0 / 9** | resisted direct, indirect (poisoned-doc) & boundary |
| Memorization / PII | **0 / 28** | incl. **0 / 20 real Enron** PII reproduced; 3 benign public-domain recalls (a proxy, not a leak) |
The model is **clean across all three confidentiality tracks**, including real training-data PII extraction from the Enron corpus. The only flags are benign public-domain recall (reproducing Shakespeare / the MIT licence), which the **sensitive-leak rate deliberately excludes** — so the headline is **0% sensitive leaks → LOW risk**, not the misleading "50%" a naive count would show.
[](https://htmlpreview.github.io/?https://github.com/minw0607/llm_red_teaming/blob/main/docs/samples/data_executive_summary.html)
📄 **[Open interactive report →](https://htmlpreview.github.io/?https://github.com/minw0607/llm_red_teaming/blob/main/docs/samples/data_executive_summary.html)** · [Design & methodology →](docs/06_data_redteam.md) · [Open notebook →](notebooks/06_data_redteam_demo.ipynb)
## 🤖 Agentic Tool Attacks (Notebook 07)
`Status: 🛠️ Built — live run pending`
The frontier — validated by the [OpenAI/Google/IEEE Kaggle competition](https://www.kaggle.com/competitions/ai-agent-security-multi-step-tool-attacks) on multi-step tool attacks. Where NB03/NB06 inject *data*, NB07 tests whether that injection becomes an **unsafe action**: a tool-using agent moved from **untrusted input → unauthorized tool call** (send email, delete files, make a payment, exfiltrate via a tool).
**What it tests:** a target-agnostic **ReAct agent loop** over a safe, **mock tool sandbox** (sources: read email/files/web · sinks: send_email/delete_file/http_post/make_payment) + five adversarial scenarios in the style of [AgentDojo](https://arxiv.org/abs/2406.13352). Headline metric = **unsafe-action rate** across multi-step trajectories (split **indirect** vs **direct**), with **replayable findings** — every step (model output → tool call → observation) is captured so a finding is reproducible, per the competition's evaluation model.
**Capabilities:** mock sandbox (4 sources · 4 sinks) · text-ReAct agent loop (no provider function-calling API needed) · 5 scenarios (email exfil · file delete · payment redirect · web exfil · direct baseline) · deterministic unsafe-action detection from the tool log · replayable trajectories · resumable checkpointing · executive report. Maps to OWASP **LLM06 Excessive Agency** · MITRE ATLAS AML.T0053/T0054 · EU AI Act Art. 15.
## 🗺️ Roadmap & Standards
All attacks map to four industry frameworks:
- **[MITRE ATLAS](https://atlas.mitre.org/)** — adversarial ML technique catalogue
- **[NIST AI 600-1](https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf)** — GenAI risk profile (July 2024)
- **[OWASP LLM Top 10](https://owasp.org/www-project-top-10-for-large-language-model-applications/)** — application-layer LLM security risks (2025)
- **[EU AI Act](https://artificialintelligenceact.eu/)** — high-risk AI system obligations (2024/1689)
Status legend: ✅ Implemented · 🛠️ Built (live run pending) · 🔜 Next milestone · 📋 Planned · 🔭 Research horizon
### Future Attack Library — Tier 2 (Medium Priority)
| Status | Attack | Category | Description | MITRE ATLAS | NIST AI 600-1 | OWASP LLM Top 10 |
|:---:|---|---|---|---|---|---|
| 📋 | **Paraphrase Model Attack** | Semantic | Use a paraphrase model (PEGASUS, DIPPER, T5) to generate fluent rewrites — more naturalistic than synonym lookups | AML.T0043 · AML.T0015 | Information Integrity | LLM09 Misinformation |
| ✅ | **Counterfactual / Demographic Swap** | Fairness | Swap protected attributes (gender, race, age, nationality, religion) and measure if the decision changes — flip rate + parity gap (NB04) | AML.T0043 *(weak fit — bias is a harm)* | **Harmful Bias and Homogenization (§2.8)** | LLM09 Misinformation |
| ✅ | **BBQ Stereotype Benchmark** | Fairness | 11-category bias benchmark; official ambiguous/disambiguated bias score (NB04) | — | **Harmful Bias and Homogenization (§2.8)** | — |
| 📋 | **Payload Splitting** | Prompt | Distribute a forbidden phrase across multiple tokens, turns, or encoded segments to evade safety filters | AML.T0054 | Information Security | LLM01 Prompt Injection · LLM07 System Prompt Leakage |
| 📋 | **Many-Shot Jailbreak** | Prompt | Provide many in-context examples of policy-violating exchanges before the target request to shift the model's behaviour (Anthropic, 2024) | AML.T0054 | Information Security (§2.6) | LLM01 Prompt Injection |
| 📋 | **Crescendo / Multi-Turn** | Prompt | Escalate harmful requests across multiple conversational turns, each individually benign (Microsoft, 2024) | AML.T0054 · AML.T0006 | Information Security (§2.6) | LLM01 Prompt Injection · LLM06 Excessive Agency |
| 📋 | **GCG / Adversarial Suffix** | Gradient | Greedy Coordinate Gradient (Zou et al. 2023) — finds a universal adversarial suffix that forces harmful outputs; transferable to black-box targets | AML.T0043 · AML.T0015 | Information Security (§2.6) | LLM01 Prompt Injection |
| 📋 | **Multilingual Bypass** | Structural | Submit harmful requests in low-resource languages where safety fine-tuning is weaker | AML.T0054 | Information Security (§2.6) · Harmful Bias (§2.8) | LLM01 Prompt Injection |
| 📋 | **HarmBench Expansion** | Dataset | Extend jailbreak coverage from 100 (JailbreakBench) to 400 behaviors across 7 harm categories with pre-published ASR baselines for model comparison | AML.T0054 | Information Security (§2.6) · CBRN (§2.1) | LLM01 Prompt Injection |
| 📋 | **StrongREJECT Scoring** | Metric | Replace binary ASR with StrongREJECT score (Souly et al. 2024) — penalises partial compliance; more accurate than BART-MNLI on ambiguous refusals | AML.T0054 | Information Security (§2.6) | LLM01 Prompt Injection |
| 📋 | **Llama Guard Judge** | Judge | Replace BART-MNLI with Meta's Llama Guard 3 (fine-tuned safety classifier) — lower false-positive rate on sensitive-topic academic responses | AML.T0054 | Information Security (§2.6) | LLM01 Prompt Injection |
### Future Attack Library — Tier 3 (Research Horizon)
| Status | Attack | Category | Description | MITRE ATLAS | NIST AI 600-1 | OWASP LLM Top 10 |
|:---:|---|---|---|---|---|---|
| 🔭 | **RAG / Vector Store Poisoning** | Infrastructure | Inject adversarial documents into a retrieval corpus to influence LLM responses via indirect context | AML.T0054 · AML.T0020 | Information Security · Value Chain | LLM08 Vector & Embedding Weaknesses |
| 🔭 | **Multi-Turn Context Manipulation** | Prompt | Build up a false context or persona over many dialogue turns to gradually shift model behaviour | AML.T0054 | Information Security · Human-AI Configuration | LLM01 Prompt Injection |
| 📋 | **Tool / Function Call Hijacking** | Prompt | Craft adversarial input that redirects an LLM agent's tool calls to unintended targets or actions *(NB07)* | AML.T0053 · AML.T0054 | Information Security | LLM06 Excessive Agency |
| 🔭 | **Backdoor / Trojan Trigger** | Model-level | Insert a hidden trigger phrase during fine-tuning that causes targeted misclassification at inference | AML.T0020 · AML.T0043 | Information Security · Data Provenance | LLM04 Data & Model Poisoning |
| 🔭 | **Membership Inference** | Privacy | Query the model systematically to determine whether specific examples were in its training data | AML.T0040 · AML.T0031 | Data Privacy | LLM02 Sensitive Information Disclosure |
| 🔭 | **Model Extraction / Stealing** | Privacy | Reconstruct a functional surrogate of the target model via repeated black-box queries | AML.T0031 · AML.T0040 | Value Chain and Component Integration | LLM02 Sensitive Information Disclosure |
| 🔜 | **Training Data Extraction** | Privacy | Prompt the model to reproduce memorised training data (PII, copyrighted text) *(NB06)* | AML.T0031 | Data Privacy · Intellectual Property | LLM02 Sensitive Information Disclosure |
### 📊 Dataset Roadmap
| Status | Dataset | Task | What it adds | Source |
|:---:|---|---|---|---|
| ✅ | **SST-2** | Binary sentiment | Baseline — fast to score, sensitive to lexical changes | [HuggingFace](https://huggingface.co/datasets/stanfordnlp/sst2) |
| ✅ | **JailbreakBench** | Safety / jailbreak | 100 harmful behaviors + PAIR/GCG artifact library (NB02) | [JailbreakBench](https://github.com/JailbreakBench/jailbreakbench) |
| ✅ | **HarmBench** | Safety / jailbreak | 400 behaviors across 7 harm categories; published ASR baselines (NB02) | [HarmBench](https://github.com/centerforaisafety/HarmBench) |
| ✅ | **deepset/prompt-injections** | Prompt injection | 203 real-world injection payloads for the LLM-judged track (NB03) | [HuggingFace](https://huggingface.co/datasets/deepset/prompt-injections) |
| ✅ | **BBQ** | Bias / fairness | Bias Benchmark for QA — 11 social categories, ambiguous/disambiguated bias score (NB04) | [Parrish et al. 2022](https://github.com/nyu-mll/BBQ) |
| ✅ | **MultiNLI** | 3-class entailment | Clean NLI baseline — the robustness-gap reference (NB05) | [HuggingFace](https://huggingface.co/datasets/nyu-mll/multi_nli) |
| ✅ | **ANLI** | 3-class entailment | Human-in-the-loop adversarial NLI, 3 difficulty rounds + `reason` annotations (NB05) | [Nie et al. 2020](https://arxiv.org/abs/1910.14599) |
| ✅ | **AdvGLUE** | 3-class entailment | Adversarially-perturbed MNLI; second adversarial track (NB05) | [Wang et al. 2021](https://arxiv.org/abs/2111.02840) |
| 📋 | **ToxiGen / HateXplain** | Toxicity classification | Safety-critical: does the model correctly flag hate speech after perturbation? | [ToxiGen](https://arxiv.org/abs/2203.09509) · [HateXplain](https://arxiv.org/abs/2012.10289) |
| 📋 | **TriviaQA** | Open-domain QA | Does a factual answer change when the question is rephrased? | [HuggingFace](https://huggingface.co/datasets/trivia_qa) |
| 🔭 | **MMLU** (select subsets) | Multi-domain MCQ | Domain-specific robustness (medical, legal, STEM) under prompt rephrasing | [HuggingFace](https://huggingface.co/datasets/cais/mmlu) |
| 🔭 | **MT-Bench** | Instruction following | Does multi-turn output quality degrade under adversarial system prompts? | [LMSYS](https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge) |
### 🧪 Testing Strategy Roadmap
| Status | Strategy | What it measures | Primary dataset(s) | Key metric |
|:---:|---|---|---|---|
| ✅ | **Prediction Flip (ASR)** | Fraction of correct predictions overturned by an attack | SST-2 | Attack Success Rate |
| ✅ | **Risk Scoring** | Composite danger = Impact × Stealth; ranks attacks by operational priority | SST-2 | Risk Score |
| ✅ | **Human Review Queue** | Prioritises adversarial examples by flip + stealth for manual inspection | All | HIGH / MEDIUM / LOW |
| ✅ | **Composite Stealth Scoring** | Semantic similarity + perplexity ratio + normalised edit distance — richer imperceptibility signal than cosine similarity alone | All | Weighted composite |
| ✅ | **Jailbreak Success Rate (ASR)** | Fraction of jailbreak prompts that elicit a policy-violating response, judged by a BART-MNLI classifier | JailbreakBench (100 behaviors) | Jailbreak ASR |
| ✅ | **Prompt Injection Success Rate** | Fraction of injected instructions that override the system prompt or change model behaviour | Canary benchmark · `deepset/prompt-injections` | Override rate |
| 📋 | **Paraphrase Consistency** | Does the model give the same answer to semantically equivalent rephrasings? | AdvGLUE · ANLI | Consistency rate |
| ✅ | **Counterfactual Fairness** | Does swapping a protected attribute (gender, race, age, nationality, religion) change the decision? | Custom decision probes | Flip rate · parity gap |
| ✅ | **Stereotype Bias (BBQ)** | Does the model rely on social stereotypes when the answer is underdetermined? | BBQ (11 categories) | Bias score (−1…+1) |
| ✅ | **NLI Reasoning Robustness** | Does the model still infer entailment correctly under adversarial pressure? | MultiNLI · ANLI · AdvGLUE | Robustness gap (clean − adv) |
| 📋 | **Factuality Robustness** | Does injecting a false premise into a QA question cause the model to accept it? | TriviaQA · NaturalQuestions | Fact-acceptance rate |
| 📋 | **Logical Negation Robustness** | Does the model correctly track negation under paraphrase? | MultiNLI · custom | Negation flip rate |
| 🔭 | **Multi-Turn Manipulation** | Can a model's behaviour be shifted over successive turns via context accumulation? | MT-Bench · custom | Behaviour drift score |
| 🔭 | **Confidence / Calibration Shift** | Does an adversarial attack inflate the model's confidence in a wrong answer? | SST-2 · AdvGLUE | ECE · confidence delta |
| 📋 | **Tool Call Hijacking Rate** | Can adversarial input redirect an agent's function calls? *(NB07)* | AgentDojo-style tasks | Unsafe-action rate |
| 🔜 | **Training Data Extraction** | Can repeated prompting extract PII or verbatim training text? *(NB06)* | Canaries · synthetic PII · public-text prefixes | Regurgitation rate |
## 📓 Demo Notebooks
| Notebook | Status | Description |
|---|:---:|---|
| [`01_adversarial_nlp_demo.ipynb`](notebooks/01_adversarial_nlp_demo.ipynb) | ✅ | 10 adversarial attacks × SST-2 — 5 perturbation levels, accuracy drop, composite stealth scoring, risk matrix, human review queue, executive report. [Results →](docs/01_adversarial_nlp.md) |
| [`02_jailbreaking_demo.ipynb`](notebooks/02_jailbreaking_demo.ipynb) | ✅ | Three-mode jailbreak evaluation — direct goals, artifact templates, PAIR transfer; BART-MNLI judge, incremental checkpointing, regulatory mapping. [Results →](docs/02_jailbreaking.md) |
| [`03_prompt_injection.ipynb`](notebooks/03_prompt_injection.ipynb) | ✅ | Direct + indirect prompt injection — 5-strategy taxonomy, canary override-rate metric, real-world payloads, executive report. [Design →](docs/03_prompt_injection.md) |
| [`04_fairness_counterfactual.ipynb`](notebooks/04_fairness_counterfactual.ipynb) | ✅ | Bias & fairness — BBQ stereotype benchmark (11 categories, bias score) + counterfactual decision probes (flip rate, parity gap), executive report. [Design →](docs/04_fairness.md) |
| [`05_nli_robustness_demo.ipynb`](notebooks/05_nli_robustness_demo.ipynb) | ✅ | NLI reasoning robustness — MultiNLI baseline vs. ANLI (3 rounds) + AdvGLUE; robustness gap, ANLI difficulty curve, confusion matrix, ANLI-annotated error analysis, executive report. [Design →](docs/05_nli_robustness.md) |
| [`06_data_redteam_demo.ipynb`](notebooks/06_data_redteam_demo.ipynb) | ✅ | Data red-teaming — system-prompt/secret disclosure, training-data memorization & PII regurgitation, RAG context exfiltration; deterministic leak metrics + executive report |
| [`07_agentic_tool_attacks.ipynb`](notebooks/07_agentic_tool_attacks.ipynb) | 🛠️ | Agentic tool attacks — ReAct agent over a mock tool sandbox; 5 untrusted-input → unsafe-action scenarios (AgentDojo-aligned), unsafe-action rate + replayable findings, executive report. [Design →](docs/07_agentic_tool_attacks.md) |
Notebooks are intentionally **code-light** — they import from the modules above and focus on results, visualisations, and interpretation.
## 📚 References & Standards
### Frameworks & Standards
- [MITRE ATLAS](https://atlas.mitre.org/) — Adversarial Threat Landscape for AI Systems
- [NIST AI RMF (2023)](https://www.nist.gov/system/files/documents/2023/01/26/AI%20RMF%201.0.pdf) — AI Risk Management Framework
- [NIST AI 600-1 (2024)](https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf) — Generative AI Profile
- [OWASP LLM Top 10 (2025)](https://owasp.org/www-project-top-10-for-large-language-model-applications/) — LLM application security risks
- [EU AI Act (2024/1689)](https://artificialintelligenceact.eu/) — High-risk AI system obligations
### Attacks & Benchmarks
- [TextFooler](https://arxiv.org/abs/1907.11932) — Jin et al., 2019
- [TextBugger](https://arxiv.org/abs/1812.05271) — Li et al., 2019
- [DeepWordBug](https://arxiv.org/abs/1801.04354) — Gao et al., 2018
- [BERT-Attack](https://arxiv.org/abs/2004.09984) — Li et al., 2020
- [PAIR](https://arxiv.org/abs/2310.08419) — Chao et al., 2023
- [GCG Universal Adversarial Attacks](https://arxiv.org/abs/2307.15043) — Zou et al., 2023
- [StrongREJECT](https://arxiv.org/abs/2402.10260) — Souly et al., 2024
- [JailbreakBench](https://github.com/JailbreakBench/jailbreakbench) · [AdvBench](https://github.com/llm-attacks/llm-attacks) · [HarmBench](https://github.com/centerforaisafety/HarmBench)
### Datasets
- [SST-2](https://huggingface.co/datasets/stanfordnlp/sst2) — Stanford Sentiment Treebank
- [AdvGLUE](https://arxiv.org/abs/2106.09680) — Adversarial GLUE benchmark
- [ANLI](https://arxiv.org/abs/1910.14599) — Adversarial NLI
- [ToxiGen](https://arxiv.org/abs/2203.09509) — Machine-generated toxic text
- [HateXplain](https://arxiv.org/abs/2012.10289) — Hate speech with rationales
### Related Tools
- [Microsoft PyRIT](https://github.com/Azure/PyRIT) — Python Risk Identification Tool for GenAI
- [NVIDIA Garak](https://github.com/NVIDIA/garak) — LLM vulnerability scanner
- [TextAttack](https://github.com/QData/TextAttack) — Adversarial NLP framework
## 🤝 Contributing
Contributions are welcome. To add a new attack, dataset, or testing strategy:
1. Fork the repo and create a feature branch
2. Follow the existing module structure — attacks inherit from the base class in `attacks/base.py`
3. Add an entry to the relevant roadmap table (with standards mapping)
4. Open a PR with a short description of the attack and at least one worked example
## 📄 License
MIT License — see [LICENSE](LICENSE) for details.
## ⚠️ Responsible Use
This toolkit is intended for **security research, model evaluation, and AI safety work**. All jailbreak goals used in testing are sourced from published academic benchmarks. Do not use this toolkit to generate or distribute harmful content.
Built for AI safety practitioners, ML engineers, and red team researchers.
标签:AI安全, Chat Copilot, DLL 劫持, Python, 大语言模型, 对抗机器学习, 无后门, 红队工具, 越狱测试