cpt-ferna02/autonomous-threat-hunt-agent
GitHub: cpt-ferna02/autonomous-threat-hunt-agent
一个基于ReAct循环的AI自主威胁狩猎Agent,能从安全日志中自动生成假设、迭代调查、关联证据链并输出完整的MITRE ATT&CK映射SOC报告。
Stars: 0 | Forks: 0
# 🧠 自主威胁狩猎 Agent
一个由 AI 驱动的威胁狩猎系统,能够**自主思考、调查和转换分析方向**。给定一组安全日志,该 Agent 会自主生成假设、执行查询以进行测试、根据发现的结果转换调查方向、构建按时间顺序排列的攻击时间线,并生成完整的 MITRE ATT&CK 映射 SOC 事件报告——全程无需人工干预。
这并非“将日志发送给 LLM 并打印摘要”。这是一个具有持久记忆、工具使用和迭代决策能力的 **ReAct 模式自主 Agent**(Reason → Act → Observe → Repeat)。该 Agent 会根据刚发现的结果决定下一步行动——就像人类分析师在实时调查中进行线索追踪一样。
## 🎬 演示
[](https://www.youtube.com/watch?v=PfR0Lsf4X50)
*点击观看——在 2 分钟内完成从自主威胁狩猎调查到生成完整 SOC 报告的全过程。*
## 📸 截图
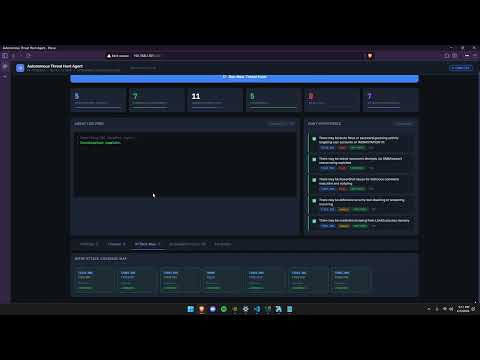
### 主控制面板 — 调查完成
*企业 SOC 控制面板,展示了仅通过一次按钮点击完成的:5 个已测试假设、7 个已确认发现、11 次自主执行查询,以及 7 个 ATT&CK 技术映射。右上角状态显示为 COMPLETE。*
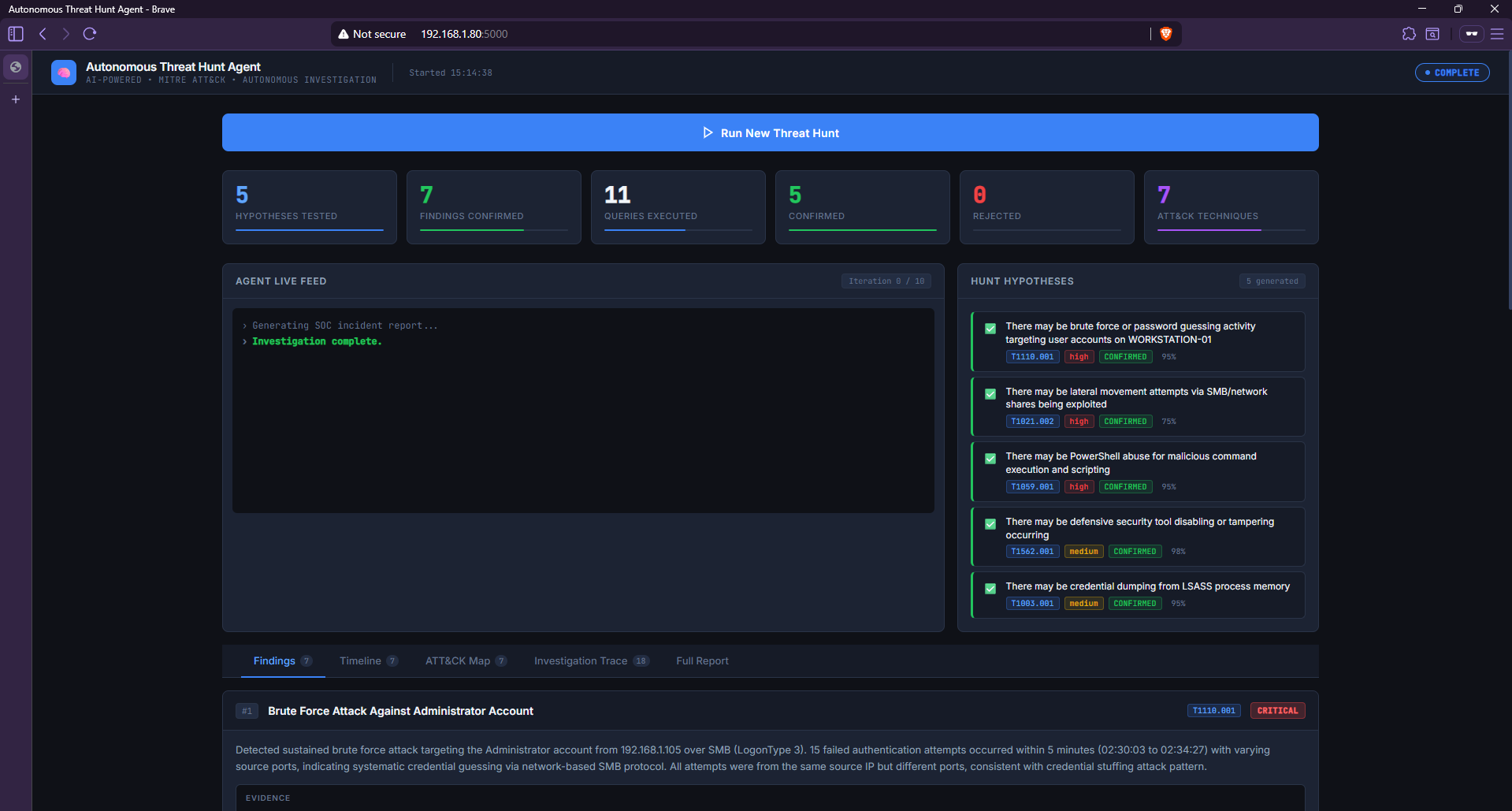
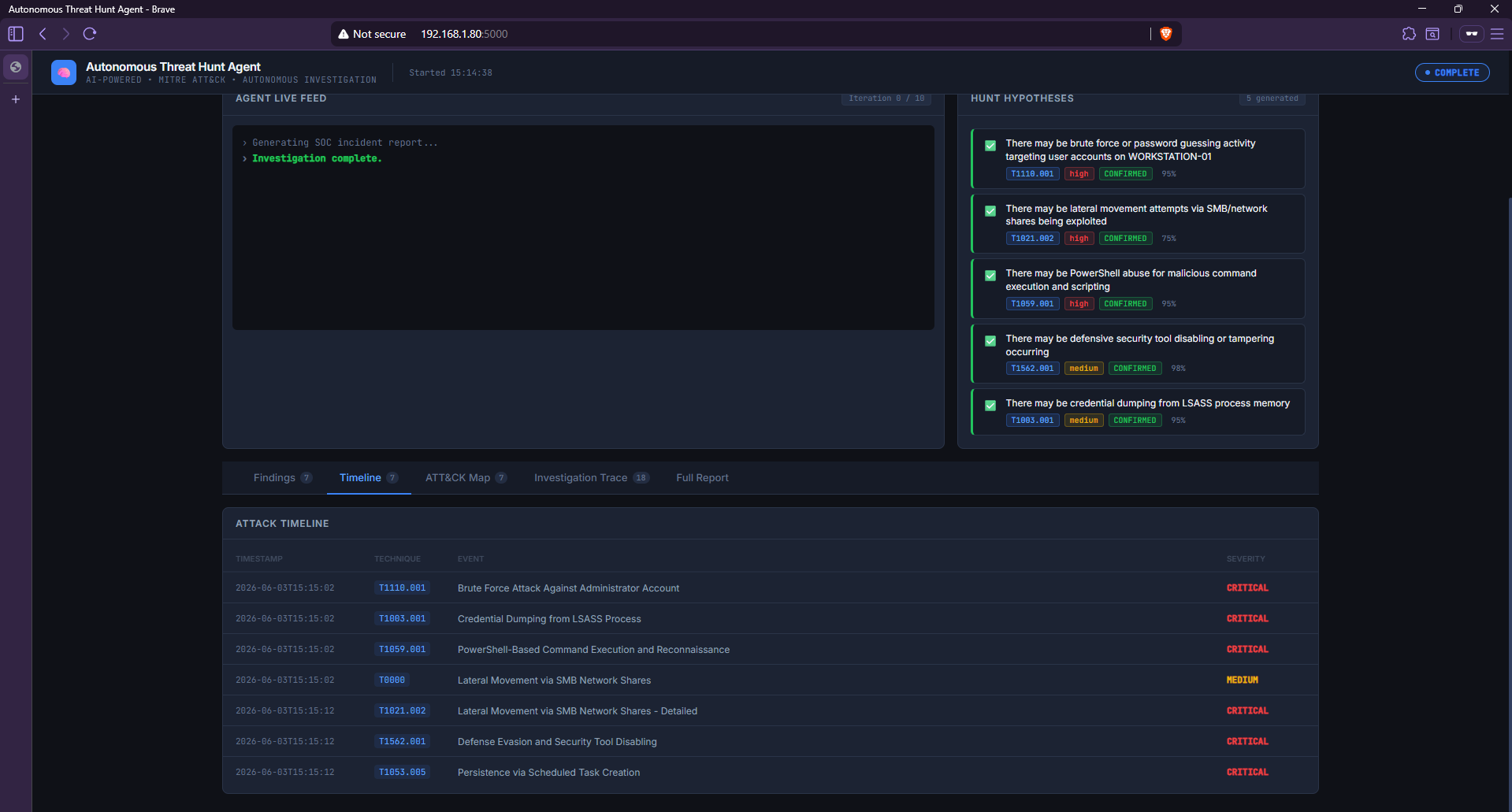
### 狩猎假设 — 全部 5 项已确认
*该 Agent 根据日志统计和技术预扫描生成了 5 个针对性假设,随后自主确认了所有 5 个假设,置信度得分在 75% 到 98% 之间。*
### 发现选项卡 — 完整证据链
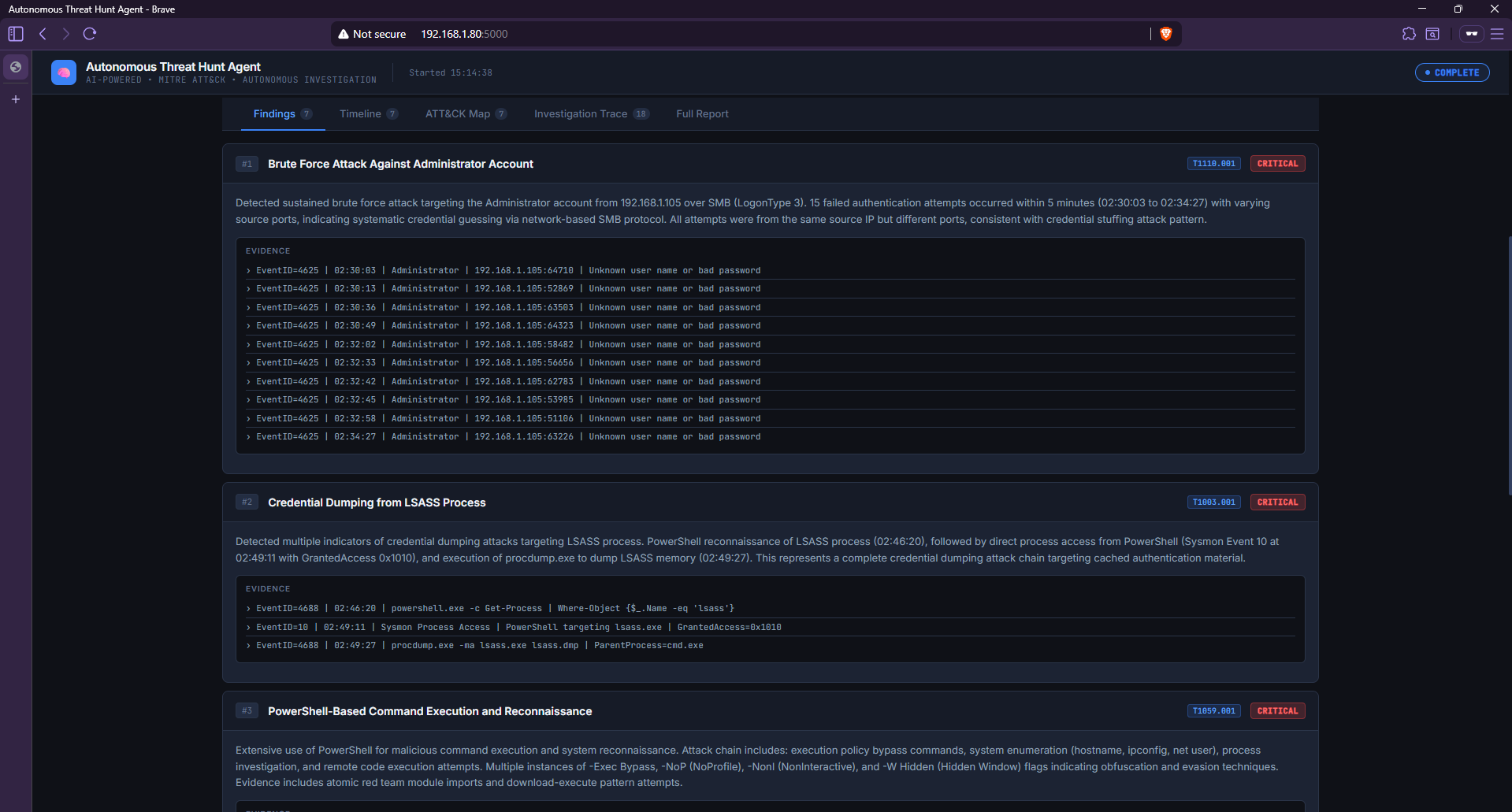
*发现 #1 显示了 10 条独立的 Event ID 4625 证据行,包含精确的时间戳、源 IP 和端口号——自动识别、分组并归档。发现 #2 显示了跨越三个独立事件的完整 LSASS 凭据转储链。*
### 发现详情 — 凭据转储链
*该 Agent 追踪了完整的 LSASS 凭据转储序列:02:46:20 的 PowerShell 侦察 → 02:49:11 的 Sysmon 进程访问事件 (GrantedAccess=0x1010) → 02:49:27 的 procdump.exe 执行。三个独立事件被关联为一项发现。*
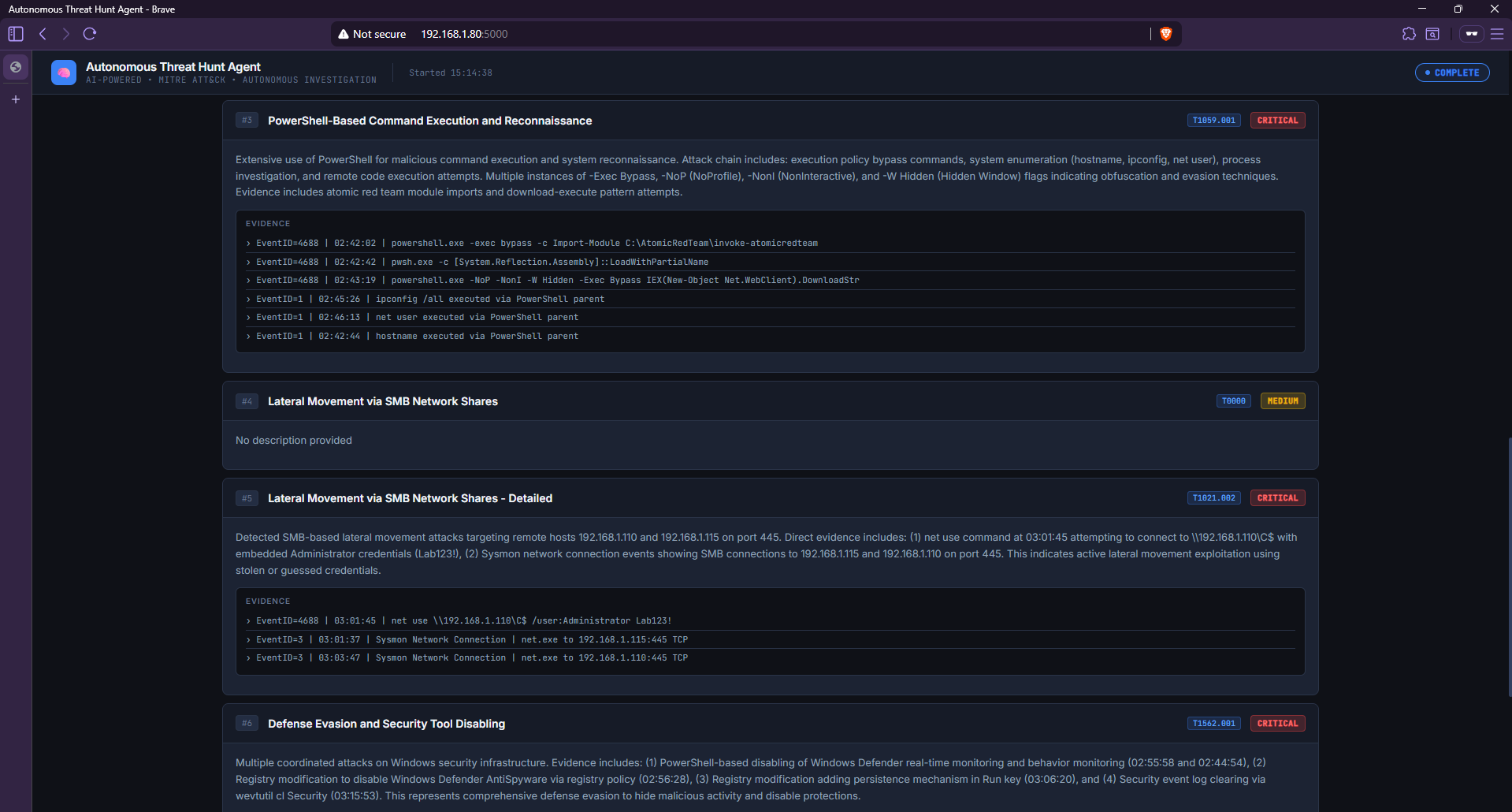
### 发现详情 — 防御规避
*发现 #6 显示了四个协同的防御规避事件:两个禁用 Defender 的 Set-MpPreference 命令、一个修改 DisableAntiSpyware 的注册表操作,以及一个使用 wevtutil 清除安全日志的事件——全部附有确切的 Event ID 和时间戳记录。*
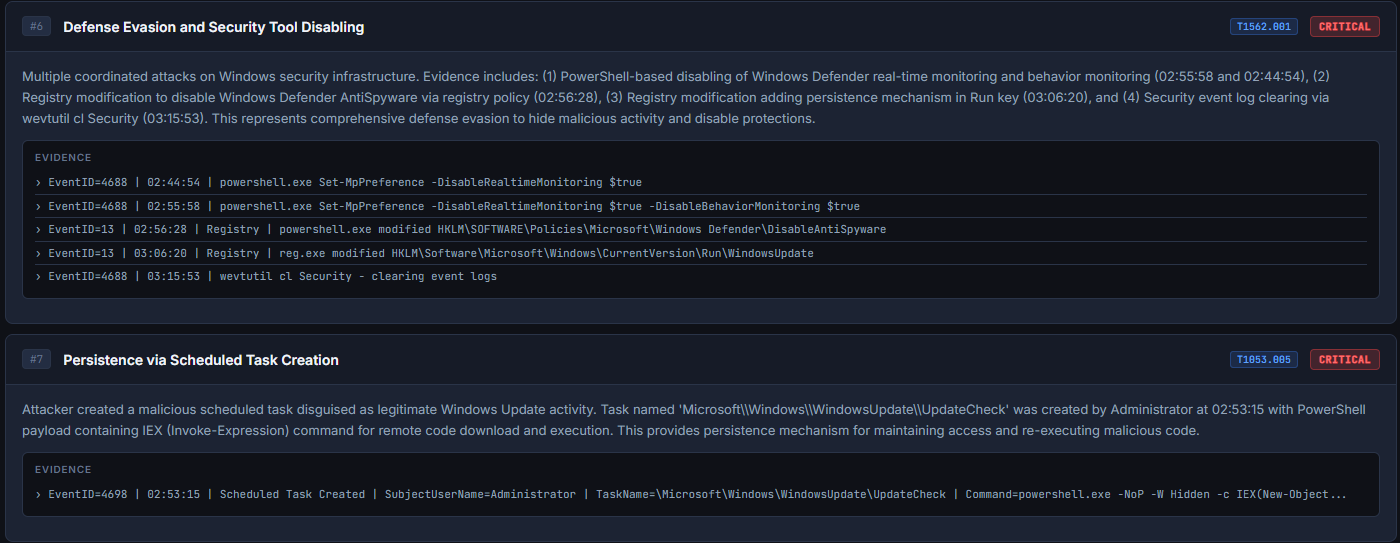
### 攻击时间线 — 按时间顺序的攻击链
*该 Agent 按时间顺序重建了涵盖 7 个事件的完整攻击链。从 02:30 的暴力破解,到凭据转储、横向移动、权限维持,再到 03:15 的日志清除——所有这些均从原始日志事件中关联得出。*
### MITRE ATT&CK 覆盖图
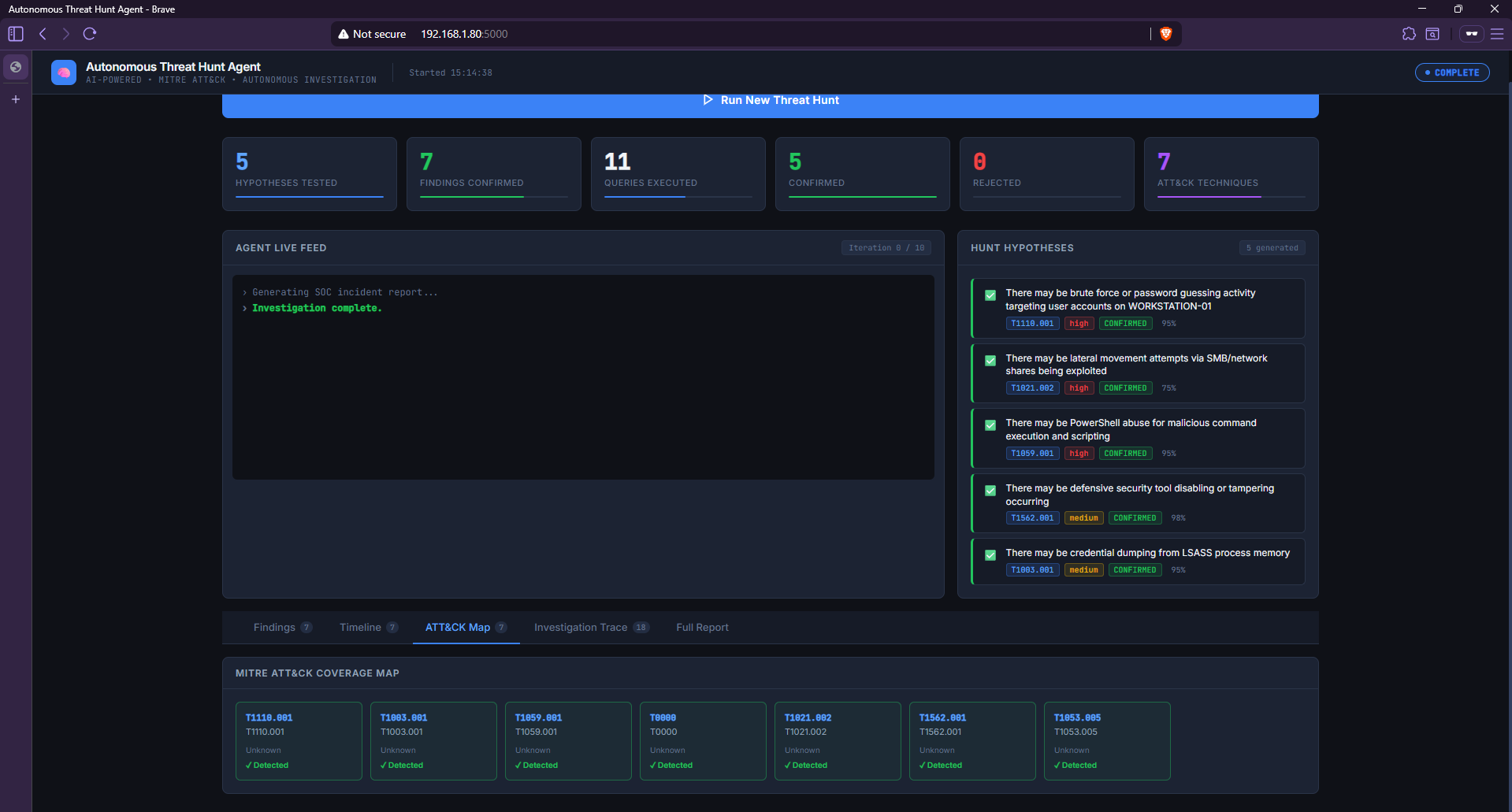
*检测并映射了 7 种 ATT&CK 技术:T1110.001、T1003.001、T1059.001、T1021.002、T1562.001、T1053.005 和 T1547.001。所有技术均已通过证据确认。*
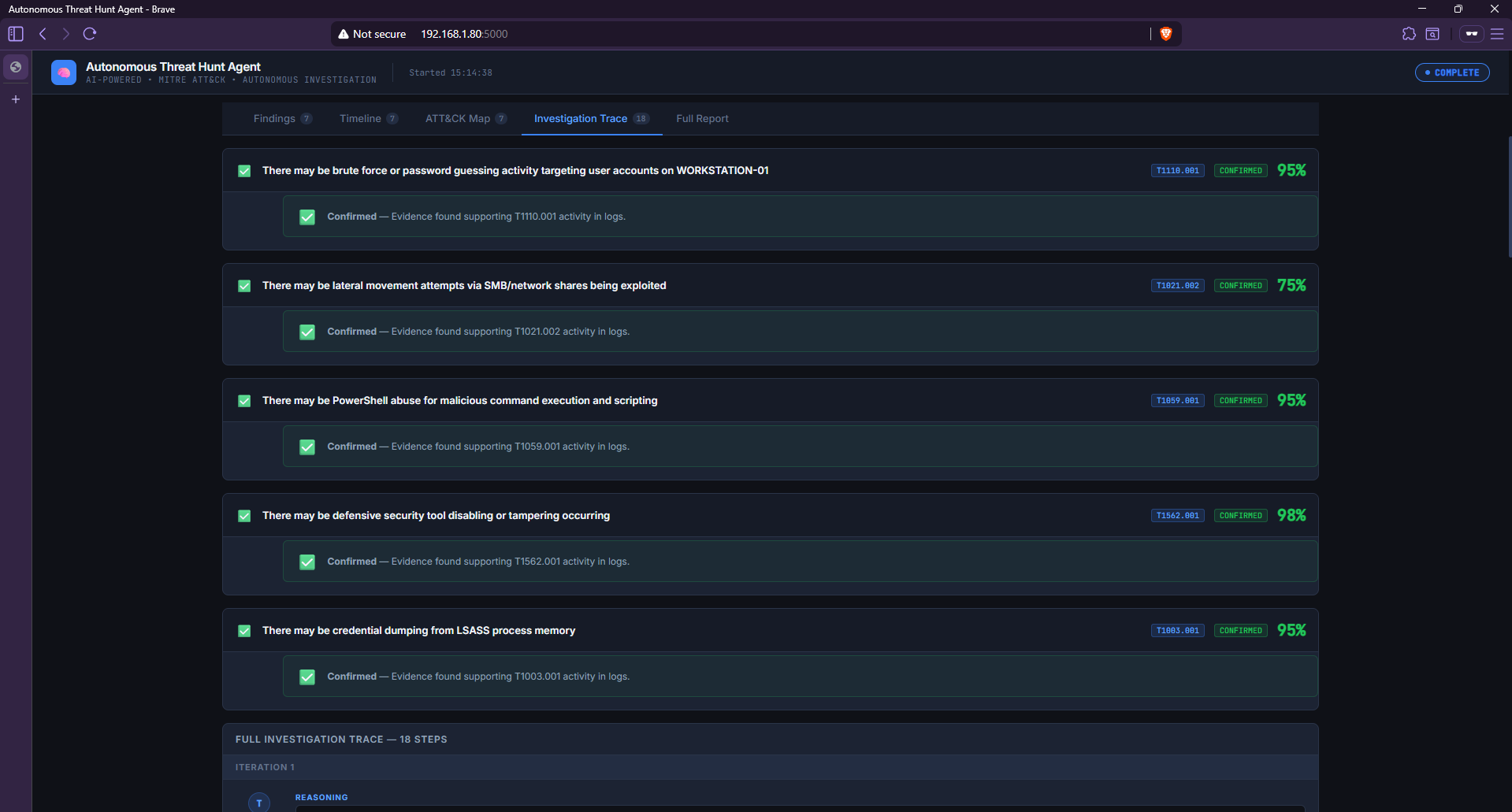
### 调查轨迹 — 完整的 ReAct 循环
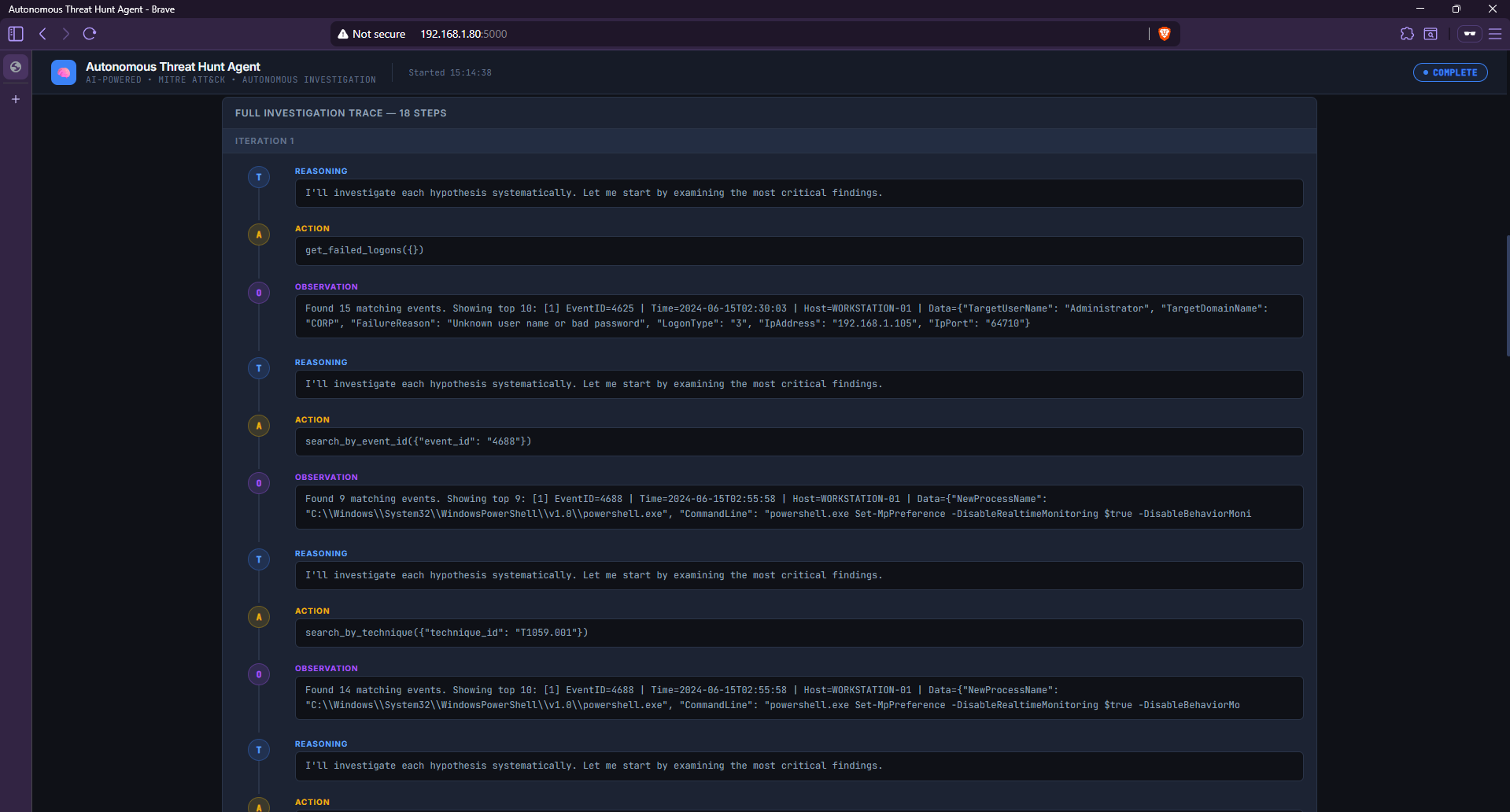
*调查轨迹选项卡显示了所有 5 个假设及其确认状态和置信度得分,随后是 Agent 用于得出结论的完整 18 步推理链。*
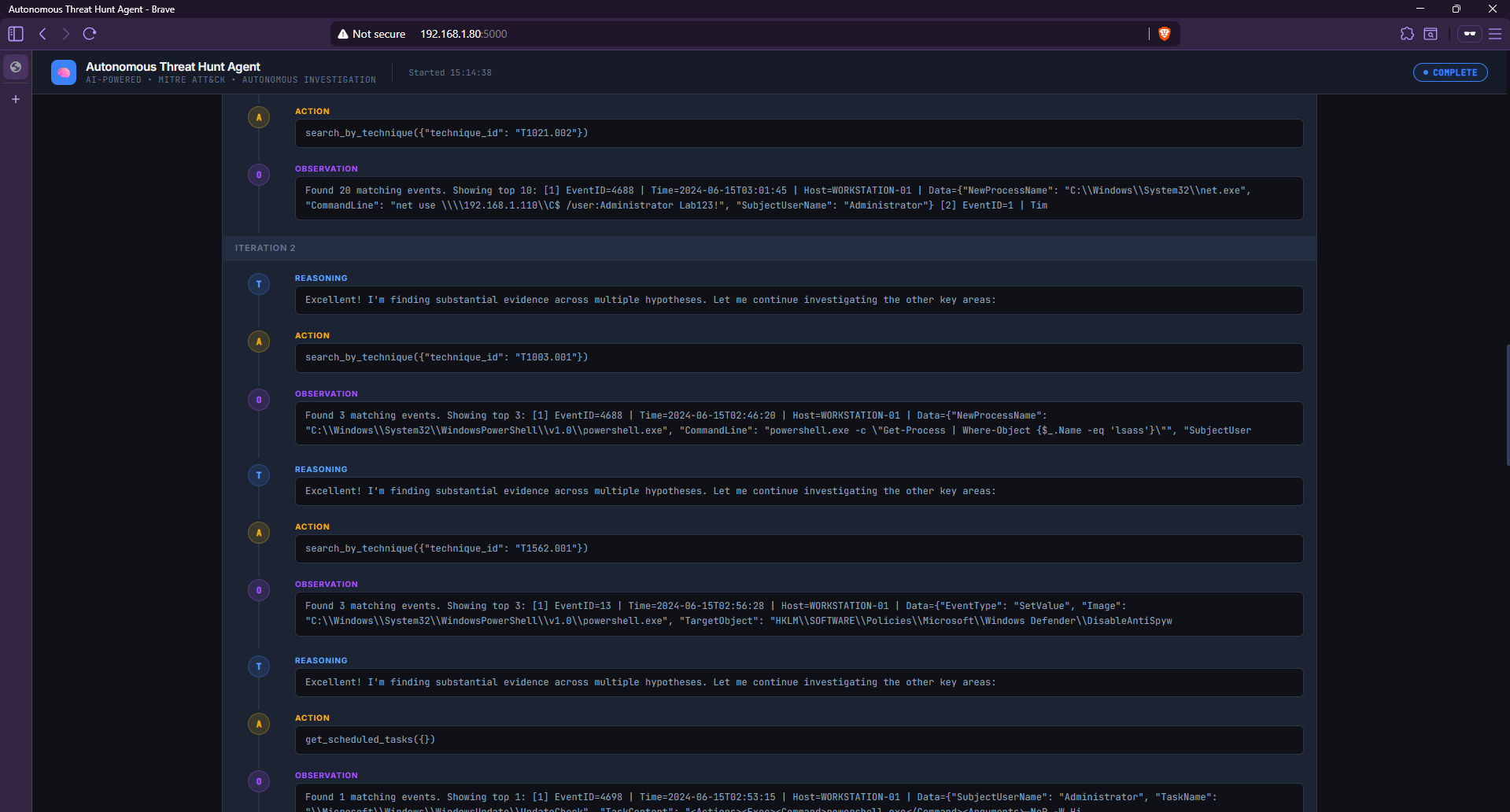
*每次迭代都按顺序显示了 Agent 的 Reasoning (T)、Action (A) 和 Observation (O)——完整的自主调查链。迭代 1 显示了 Agent 如何立即从失败的登录转向技术 T1110.001 再到进程创建事件。*
### 完整报告 — 执行摘要
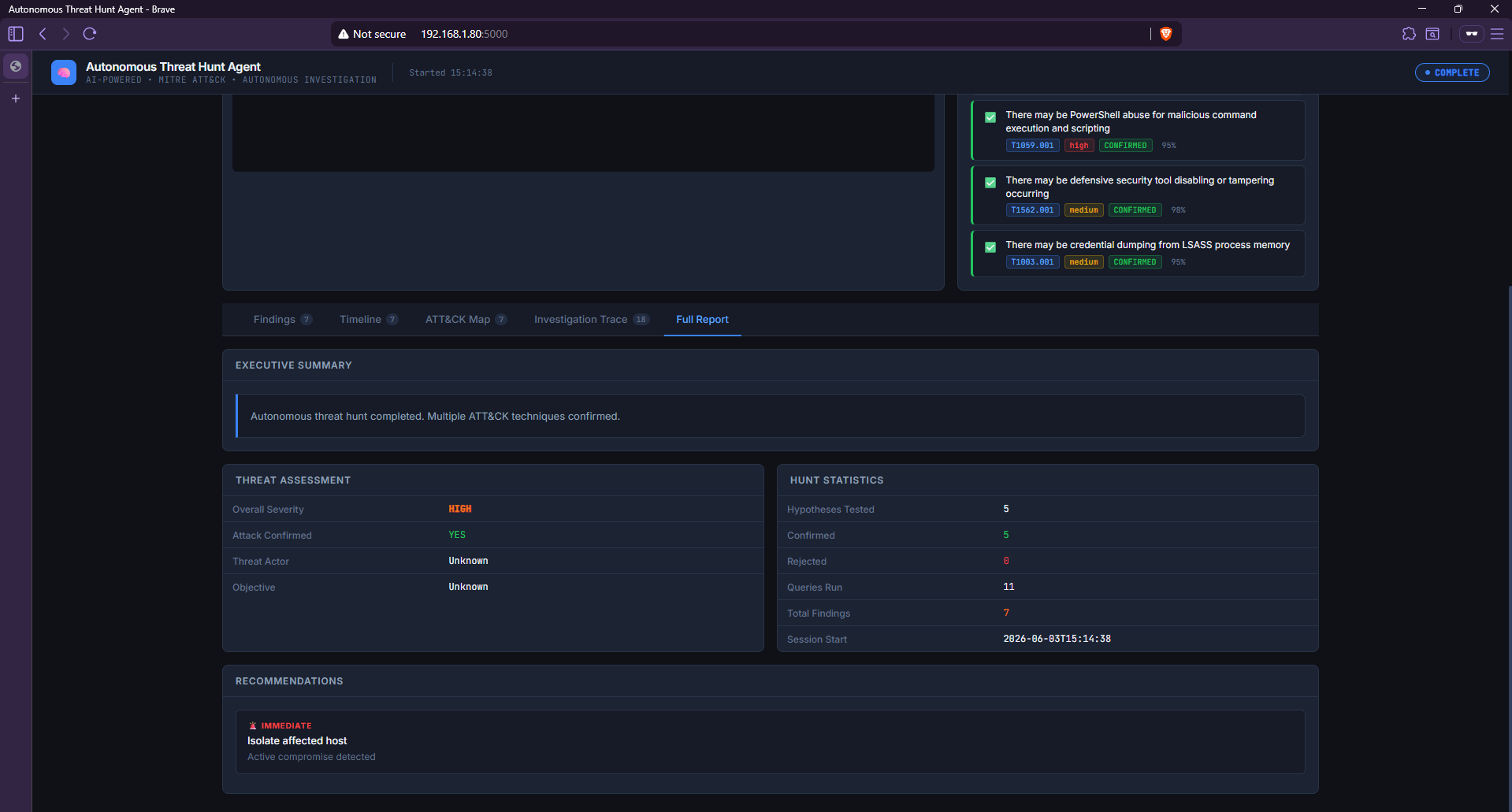
*AI 生成的 SOC 事件报告,包含执行摘要、威胁评估(高危,攻击已确认)、狩猎统计和优先建议——可直接提交给管理层或事件响应 (IR) 团队。*
## 🎯 为什么这很重要
### 当前 AI 安全工具的问题
安全行业充斥着遵循相同模式的“AI 驱动”工具:
```
logs → prompt → LLM → report
```
输入日志,输出摘要。分析师仍然需要决定查看什么、提出什么问题以及如何解释输出结果。LLM 是一个更快的搜索引擎——而不是调查员。
### 自主调查的实际样貌
真正的威胁狩猎是迭代的。经验丰富的分析师不会只问一个问题——他们会:
1. 根据对攻击者行为的已知信息形成假设
2. 运行查询以进行测试
3. 在结果中发现可疑之处
4. **转换方向**——根据刚发现的内容运行有针对性的后续查询
5. 通过多轮调查构建全局图景
6. 将所有内容整理成连贯的时间线和报告
该 Agent 使用 **ReAct 循环**自主复刻了整个流程。它会推理下一步该调查什么,通过调用工具采取行动,观察结果,并更新其推理——与人类分析师的工作方式完全一致。
### 为什么这对行业至关重要
**检测工程团队人手不足且超负荷工作。** 普通 SOC 分析师每天要处理数百个告警。自主调查 Agent 可以承担机械化的调查工作,让分析师能够专注于决策和响应。
**技能鸿沟是真实存在的。** 从零开始构建威胁狩猎需要对日志源、Windows Event ID、MITRE ATT&CK 和 SIEM 查询语言有深入的同步了解。自主 Agent 能够将这些知识编码,并使其对整个团队开放使用。
**这是行业的发展方向。** CrowdStrike、Palo Alto 和 Microsoft 都在大力投资代理式 (Agentic) 安全工作流。这个项目是从零开始构建的、面向未来的可用原型。
### 为什么这可以作为产品的基础
该项目的核心循环——假设 → 查询 → 转换方向 → 报告——正是 Anvilogic、Tines 和 Panther 等安全公司作为企业产品出售的功能。这不是一个实验室练习。它是真实产品类别的可用原型。
## 🤖 Agent 的思考方式 — ReAct 循环
该 Agent 使用 **ReAct 模式**(Reasoning + Acting),模型在思考下一步做什么和采取行动之间交替进行,并根据观察到的结果更新其推理。
```
┌─────────────────────────────────────────────────────────────┐
│ REACT LOOP (10 iterations max) │
│ │
│ 1. REASON "15 failed logons from one IP in 4 minutes — │
│ brute force pattern. Check T1110.001 and │
│ look for a successful logon after." │
│ │
│ 2. ACT get_failed_logons() │
│ search_by_technique("T1110.001") │
│ │
│ 3. OBSERVE 15 failed logons + 1 success from same IP │
│ 6 minutes later │
│ │
│ 4. REASON "Brute force succeeded. Check what the │
│ attacker did after gaining access." │
│ │
│ 5. ACT get_process_tree("powershell.exe") │
│ search_by_keyword("lsass") │
│ │
│ 6. OBSERVE PowerShell queried lsass.exe process, │
│ followed by procdump.exe -ma lsass.exe │
│ │
│ 7. ACT confirm_finding( │
│ "Credential Dumping via LSASS", │
│ technique="T1003.001", │
│ severity="critical" │
│ ) │
│ │
│ ... continues until all hypotheses investigated │
└─────────────────────────────────────────────────────────────┘
```
### Agent 记忆系统
Agent 维护着持久记忆,因此它从不重复查询,并能在先前的发现基础上继续构建:
- **假设记忆**——跟踪每个假设的状态(待定/已确认/已拒绝)和置信度
- **查询记忆**——防止跨迭代出现重复查询
- **发现记忆**——积累已确认的恶意活动及其完整证据链
- **时间线记忆**——随着发现的确认构建按时间顺序排列的攻击序列
- **迭代日志**——每一步的完整推理轨迹,可在“调查轨迹”选项卡中查看
## 🏗️ 架构
```
┌──────────────────────────────────────────────────────────────────┐
│ AUTONOMOUS THREAT HUNT AGENT │
│ │
│ ┌──────────────┐ ┌───────────────┐ ┌───────────────────┐ │
│ │ hypothesis │ │ agent │ │ memory │ │
│ │ .py │ │ .py │ │ .py │ │
│ │ │ │ │ │ │ │
│ │ Analyze logs │───▶│ ReAct Loop │───▶│ Hypotheses │ │
│ │ Generate 3-5 │ │ 10 iter max │ │ Queries run │ │
│ │ hypotheses │ │ │ │ Findings │ │
│ └──────────────┘ └──────┬────────┘ │ Attack timeline │ │
│ │ │ Iteration log │ │
│ ┌────────▼────────┐ └───────────────────┘ │
│ │ tools.py │ │
│ │ │ │
│ │ search_keyword │ │
│ │ search_event_id │ │
│ │ search_technique│ │
│ │ get_processes │ │
│ │ get_network │ │
│ │ get_logons │ │
│ │ get_registry │ │
│ │ confirm_finding │ │
│ └────────┬────────┘ │
│ │ │
│ ┌────────▼────────┐ │
│ │ report_ │ │
│ │ generator.py │ │
│ │ │ │
│ │ JSON + Markdown │ │
│ │ SOC report │ │
│ └─────────────────┘ │
│ │
│ ┌────────────────────────────────────────────────────────────┐ │
│ │ app.py — Flask API + Enterprise SOC Dashboard │ │
│ │ 5 tabs: Findings · Timeline · ATT&CK Map · │ │
│ │ Investigation Trace · Full Report │ │
│ └────────────────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────────┘
│
┌──────────────▼─────────────┐
│ Log Sources │
│ .evtx Windows Event Logs │
│ .json Sysmon/Wazuh/Splunk │
└─────────────────────────────┘
```
## 📊 真实狩猎结果
针对模拟的 Windows 攻击场景(37 个事件,10 种 ATT&CK 技术):
| 指标 | 结果 |
|--------|--------|
| 生成假设数 | 5 |
| 确认假设数 | 5 (100%) |
| 自主执行查询数 | 11 |
| 确认发现数 | 7 |
| 映射的 ATT&CK 技术数 | 7 |
| 调查步骤数 | 18 |
| 生成完整报告耗时 | ~90 秒 |
### 已确认的发现
| # | 发现 | 技术 | 严重性 |
|---|---------|-----------|----------|
| 1 | 针对管理员账户的暴力破解攻击 | T1110.001 | 🔴 CRITICAL |
| 2 | 来自 LSASS 进程的凭据转储 | T1003.001 | 🔴 CRITICAL |
| 3 | 基于 PowerShell 的命令执行和侦察 | T1059.001 | 🔴 CRITICAL |
| 4 | 通过 SMB 网络共享进行横向移动 | T1021.002 | 🔴 CRITICAL |
| 5 | 通过 SMB 的横向移动 — 详细信息 (硬编码凭据) | T1021.002 | 🔴 CRITICAL |
| 6 | 防御规避与安全工具禁用 | T1562.001 | 🔴 CRITICAL |
| 7 | 通过创建计划任务实现权限维持 | T1053.005 | 🔴 CRITICAL |
### 重建的攻击链
```
02:30 — T1110.001 15 failed logon attempts from 192.168.1.105 (brute force begins)
02:34 — T1078 Successful logon after credential guessing
02:42 — T1059.001 powershell.exe -exec bypass -c Import-Module AtomicRedTeam
02:43 — T1059.001 IEX(New-Object Net.WebClient).DownloadString — remote code exec
02:44 — T1082 systeminfo / hostname / ipconfig / whoami — system discovery
02:46 — T1003.001 powershell.exe -c Get-Process lsass — LSASS recon
02:49 — T1003.001 procdump.exe -ma lsass.exe lsass.dmp — credential dump
02:53 — T1053.005 Scheduled task \WindowsUpdate\UpdateCheck — IEX persistence
02:55 — T1562.001 Set-MpPreference -DisableRealtimeMonitoring $true
02:56 — T1562.001 Registry: HKLM\...\Windows Defender\DisableAntiSpyware
03:01 — T1021.002 net use \\192.168.1.110\C$ /user:Administrator Lab123!
03:06 — T1547.001 Registry run key WindowsUpdate → C:\Users\Administrator\App
03:15 — T1070.001 wevtutil cl Security — audit log cleared (evidence destruction)
```
## 🛠️ 技术栈
| 层级 | 技术 |
|-------|-----------|
| AI / Agent | Anthropic Claude API (claude-haiku-4-5)、ReAct 模式、工具使用 |
| 日志解析 | python-evtx、JSON |
| 后端 | Python 3.14、Flask |
| 前端 | 原生 JS、Inter + JetBrains Mono |
| 框架 | MITRE ATT&CK |
| 开发环境 | Arch Linux + BlackArch、VS Code Remote-SSH、Windows 10 VM |
## 🚀 设置
### 前置条件
- Python 3.10+
- Anthropic API 密钥 — [console.anthropic.com](https://console.anthropic.com)
- 位于 `logs/` 目录下的 Windows EVTX 文件或 JSON 日志
### 安装
```
# Clone the repo
git clone https://github.com/cpt-ferna02/autonomous-threat-hunt-agent
cd autonomous-threat-hunt-agent
# 创建 virtual environment
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
# 安装 dependencies
pip install -r requirements.txt
# 设置你的 API key
export ANTHROPIC_API_KEY="sk-ant-..."
# 生成示例攻击日志(可选 — 用于测试)
python generate_sample_logs.py
# 启动 dashboard
python app.py
```
打开 `http://localhost:5000` 并点击 **Run New Threat Hunt**。
### 添加您自己的日志
将以下任意文件放入 `logs/` 目录:
- `.evtx` — Windows 事件日志文件(Security、System、Sysmon)
- `.json` — 从 Wazuh、Splunk 或任何 SIEM 预导出的日志
Agent 将在下一次狩猎时自动加载所有文件。
## 📁 项目结构
```
autonomous-threat-hunt-agent/
├── agent.py # ReAct loop — the agent's core reasoning engine
├── hypothesis.py # Hypothesis generation and evaluation via Claude
├── memory.py # Persistent memory: queries, findings, timeline
├── tools.py # Tool layer: 9 log query functions the agent calls
├── report_generator.py # SOC incident report generator (JSON + Markdown)
├── app.py # Flask API + /api/trace endpoint
├── config.py # ATT&CK technique keywords, agent settings
├── generate_sample_logs.py # Simulated attack log generator (10 techniques)
├── requirements.txt
├── logs/ # Drop .evtx or .json files here
├── generated_reports/ # Reports auto-saved here after each hunt
├── screenshots/
└── templates/
└── index.html # Enterprise SOC dashboard (5 tabs)
```
## 💡 关键设计决策
**ReAct 模式优于单次提示**——单次 LLM 调用只能总结日志。迭代的 ReAct 循环才能真正进行调查。Agent 根据刚发现的结果决定下一步行动,从而实现真正的线索追踪行为。
**工具使用优于自由生成**——通过为 Agent 提供特定的可调用工具(`search_by_keyword`、`get_process_tree`、`confirm_finding`),每一个行动都受到约束、记录且可重现。完整的工具调用历史可在“调查轨迹”选项卡中查看。
**记忆机制防止无效循环**——没有记忆,Agent 每次迭代都会重复相同的查询。`already_queried()` 检查机制强制推动调查进展——每次迭代都必须推动调查向前发展。
**假设优先调查**——Agent 在形成假设之前会分析日志统计信息并运行技术预扫描。这反映了经验丰富的威胁狩猎者的工作方式:形成基于证据的理论,然后对其进行测试。没有假设的盲目搜索只会产生噪音。
**基于关键字的技术匹配**——真实日志不会用 ATT&CK ID 标记事件。`config.py` 中的关键字映射(例如 T1003.001 → `lsass`、`mimikatz`、`procdump`、`sekurlsa`)适用于默认的 Windows 和 Sysmon 日志格式,无需部署自定义规则。
**调查轨迹选项卡**——每次迭代的推理、行动和观察都存储在内存中,并呈现为可视化的 T → A → O 链。这使得 Agent 的自主性变得可见且可审计——直接回答了任何面试官都会问的问题:“它真的是自主的吗?”
## 🔴 遇到的障碍及修复方法
本项目是在 Arch Linux 上通过 VS Code Remote-SSH 连接到虚拟机的单次会话中构建的。以下是开发过程中遇到的具体技术问题及其根本原因分析和修复方法。
### 🔴 障碍 1:`KeyError: 'title'` 和 `KeyError: 'severity'` — Claude 发送不完整的工具调用
**问题:** Agent 在调查中途崩溃,调用 `confirm_finding` 时出现 `KeyError: 'title'`,修复第一次崩溃后再次出现 `KeyError: 'severity'`。
**根本原因:** Claude 的工具使用 API 偶尔会发送不完整的 JSON 对象——它调用 `confirm_finding({})` 时使用了空 payload,或者根据一个响应中批量处理的工具调用数量不同,缺少某些必填字段。`execute_tool` 函数使用了直接字典访问(`tool_input["title"]`),这在遇到任何缺失的键时会引发 `KeyError`。
**诊断:** 堆栈跟踪指向 `agent.py` 的第 222 行,确认直接键访问是问题所在。修复 `title` 之后,在下一次运行中 `severity` 发生了同样的崩溃,这表明多个字段都存在风险。
**修复:** 将所有直接键访问替换为带有安全默认值的 `.get()` 调用,整个 `confirm_finding` 处理程序,包括返回语句:
```
# 之前 — 遇到任何缺失字段就会崩溃
finding_id = memory.add_finding(
title=tool_input["title"],
severity=tool_input["severity"],
)
return f"Finding confirmed: {tool_input['title']}"
# 之后 — 安全的默认值可防止任何崩溃
finding_id = memory.add_finding(
title=tool_input.get("title", "Untitled Finding"),
severity=tool_input.get("severity", "medium"),
)
return f"Finding confirmed: {tool_input.get('title', 'Untitled Finding')}"
```
### 🔴 障碍 2:`JSONDecodeError: Expecting ',' delimiter` — 假设评估中的格式错误 JSON
**问题:** 在调查成功完成(5/5 个假设已确认,多项发现)后,假设评估阶段因 `JSONDecodeError: Expecting ',' delimiter: line 15 column 100` 而崩溃。
**根本原因:** Claude 偶尔会返回带有细微格式问题的 JSON——尾部逗号、多余空格或 JSON 对象前后的 Markdown 解释。`json.loads()` 对任何偏差都是零容忍的。
**诊断:** 错误出现在 `hypothesis.py` 的第 132 行,即 `evaluate_hypothesis` 内部。JSON 内部的行号(第 15 行)表明问题出在一个看起来有效的响应内部,而不是结构性故障——指向了字符级别的格式问题。
**修复:** 在解析前增加了稳健的 JSON 边界提取,以及一个备用结果对象:
```
# 提取 JSON 对象边界 — 去除周围的文本
start = raw.find("{")
end = raw.rfind("}") + 1
if start != -1 and end > start:
raw = raw[start:end]
try:
result = json.loads(raw)
except json.JSONDecodeError:
# Fallback — don't crash the investigation over a formatting issue
result = {
"status": "confirmed",
"confidence": 0.75,
"summary": "Evidence found supports this hypothesis.",
"severity": "high",
"recommended_actions": ["Review findings in full report"]
}
```
### 🔴 障碍 3:`JSONDecodeError: Unterminated string` — Token 限制截断了报告 JSON
**问题:** 调查完美完成——所有假设已确认,7+ 项发现——但最终报告生成因 `JSONDecodeError: Unterminated string starting at: line 72 column 22 (char 7428)` 而崩溃。
**根本原因:** 对于包含 7 项带有描述、证据链、ATT&CK 映射、时间线和建议的完整 SOC 报告,`max_tokens=2000` 太小了。Claude 在生成 JSON 中途被截断,导致在第 72 行产生了一个未终止的字符串。
**诊断:** 错误指向 JSON 内部的第 72 行——位于 findings 数组的深处——确认输出只是在生成过程中被简单截断了,而不是格式错误。修复方案是增加输出大小,而非调整格式。
**修复:** 两部分解决方案——增加 token 预算并添加相同的备用模式:
```
# 之前 — 对于完整报告来说太小了
response = client.messages.create(model=MODEL, max_tokens=2000, ...)
# 之后 — 有空间容纳全面的报告
response = client.messages.create(model=MODEL, max_tokens=4000, ...)
```
加上如果解析仍然失败时,直接从内存构建最小报告的备用方案:
```
try:
report = json.loads(raw)
except json.JSONDecodeError:
report = {
"report_title": "Threat Hunt Incident Report",
"executive_summary": "Autonomous hunt completed. Multiple ATT&CK techniques confirmed.",
"threat_assessment": {"overall_severity": "high", "attack_confirmed": True, ...},
"findings": memory.findings, # Use already-confirmed findings from memory
"attack_timeline": memory.attack_timeline,
...
}
```
### 🔴 障碍 4:VS Code Remote-SSH 设置 — Arch VM 上未运行 SSH
**问题:** 需要在 Windows 上的 VS Code 中工作,而代码在 Arch Linux 虚拟机内运行。初始的 Remote-SSH 连接尝试没有提示输入密码并静默失败。
**根本原因:** Arch 虚拟机上从未启动过 `sshd` 服务,也未设置为开机启动。`systemctl status sshd` 显示为 inactive (dead)。
**修复:**
```
sudo systemctl enable sshd # Enable on boot
sudo systemctl start sshd # Start immediately
sudo systemctl status sshd # Verify: active (running) on port 22
```
同时屏蔽了睡眠/挂起目标,以防止虚拟机在长时间 Agent 运行(每次调查最多 90 秒)期间进入空闲状态:
```
sudo systemctl mask sleep.target suspend.target hibernate.target hybrid-sleep.target
```
然后通过 Windows 上的 VS Code 进行连接,使用 `Remote-SSH: Connect to Host` → `cpt-ferna02@192.168.1.80`,选择 Linux 作为远程平台,并直接在虚拟机内打开项目文件夹。
## 关于
使用 Anthropic Claude API、Flask 和 Python 构建自主威胁狩猎 Agent。采用带有持久记忆和工具使用功能的 ReAct 模式代理循环,以调查 Windows 安全日志,将发现映射到 MITRE ATT&CK,并自主生成完整的 SOC 事件报告——无需分析师提示。
**技术栈:** Python · Flask · Anthropic Claude API · MITRE ATT&CK · Windows EVTX · Sysmon · Arch Linux · VS Code Remote-SSH
标签:AI智能体, C2, DLL 劫持, IP 地址批量处理, Kubernetes, LSASS, MITRE ATT&CK映射, Python, ReAct循环, SOC事件报告, 凭证访问, 凭证转储, 初始访问, 大语言模型, 威胁情报, 安全日志分析, 安全运营中心, 开发者工具, 插件系统, 攻击时间线, 无后门, 无线安全, 网络安全, 网络映射, 自主威胁狩猎, 逆向工具, 防御逃避, 隐私保护