masoudd2159/LLMLogAnalyzer
GitHub: masoudd2159/LLMLogAnalyzer
该项目是一个基于 Spring Boot 和本地 Qwen2.5 模型的系统日志异常检测实验框架,旨在对比和评估不同 Prompt 工程策略对 LLM 日志分类效果的影响。
Stars: 1 | Forks: 0
# LLMLogAnalyzer
**基于大语言模型和 Prompt 工程改进系统日志异常检测**
LLMLogAnalyzer 是一个 Java Spring Boot 项目,作为硕士学位项目的一部分进行开发。
本项目的主要目标是研究如何利用大语言模型(LLM)进行系统日志的异常检测,特别是在使用不同的 Prompt 工程策略引导模型时的效果。
本项目聚焦于 **BGL (Blue Gene/L)** 系统日志数据集,并比较了多种用于二进制日志分类的 Prompt 方法:
* `0` = 正常日志
* `1` = 异常日志
本仓库中的实验均是通过本地的 Ollama 设置,使用 **Qwen2.5 7B** 模型进行的。
## 项目目标
传统的日志异常检测方法通常依赖于手工编写的规则、统计特征或监督式机器学习模型。然而,大语言模型能够理解日志消息的语义含义,并可能根据日志文本中描述的实际系统影响来检测异常。
本项目的目标是评估 Prompt 工程能否改善基于 LLM 的系统日志异常检测效果。
本项目比较了三种 Prompt 策略:
1. **Zero-Shot Prompt**
2. **Rule-Based Prompt**
3. **Template-Aware Prompt**
每种策略都向模型注入了不同深度的关于 BGL 日志的领域知识。
## 数据集
本项目使用 **BGL (Blue Gene/L)** 日志数据集。
BGL 日志由 Blue Gene/L 超级计算机系统生成,包含正常和异常的系统事件。
每个日志条目被分类为以下两类之一:
* **正常**:日志未指出严重的系统故障。
* **异常**:日志指出发生了真实故障、崩溃、不可恢复的错误、通信失败或其他严重的系统影响。
在本项目中,模型接收一条原始日志消息,并必须仅返回一个 JSON 标签:
```
{"label":"0"}
```
或
```
{"label":"1"}
```
## 使用模型
实验使用了以下模型:
```
Qwen2.5 7B
```
该模型使用 Ollama 在本地运行。
配置示例:
```
model.api.ollama.url=http://localhost:11434/api/chat
model.api.ollama.model-name=qwen2.5:7b
```
模型被配置为生成简短且确定的输出,以便响应能够被可靠地解析为 JSON 分类结果。
## Prompt 工程策略
### 1. Zero-Shot Prompt
Zero-Shot Prompt 在不使用详细的 BGL 特定模板的情况下向模型分配分类任务。
模型仅根据消息内容被告知将每个日志条目分类为正常或异常。
该方法旨在测试 LLM 的通用推理能力。
Zero-Shot Prompt 包含一般的异常指标,例如:
* 不可恢复的错误
* 内存错误中断
* 存储中断
* 内核或运行时恐慌
* 节点崩溃
* 硬件、电源、散热或链路故障
* 由系统故障导致的作业终止
它还告诉模型,诸如 `ERROR` 或 `FATAL` 等严重性词汇本身并不足以作为判定依据。
### 2. Rule-Based Prompt
Rule-Based Prompt 为模型提供了更结构化的决策过程。
它定义了一个决策顺序:
1. 检查直接的异常指标。
2. 检查直接的正常指标。
3. 使用基于真实系统影响的兜底规则。
该 Prompt 比 Zero-Shot Prompt 更加严格,旨在减少由 `ERROR`、`FATAL` 或 `INTERRUPT` 等误导性词汇引起的假阳性。
例如,该 Prompt 告诉模型,某些消息可能看起来很危险,但在 BGL 数据集中实际上是正常的,例如:
* 寄存器转储
* 指令地址消息
* 已纠正的错误
* 缺失文件消息
* 权限错误
* 诊断输出
这使得模型在将日志分类为异常时变得更加保守。
### 3. Template-Aware Prompt
Template-Aware Prompt 将已知的 BGL 风格消息模式作为领域知识使用。
该 Prompt 旨在模拟一个更智能的分类器,使其能够理解常见的 BGL 日志模板。
它将已知的类异常模式与已知的类正常模式区分开来。
异常模式示例包括:
* `data TLB error interrupt`
* `data storage interrupt`
* `failed to read message prefix on control stream`
* `uncorrected memory error`
* `kernel panic`
* `link failure`
* `node crash`
正常模式示例包括:
* 指令地址转储
* 数据地址转储
* 机器状态寄存器消息
* 已纠正的 ECC 或 DDR 错误
* 没有导致系统故障的缺失文件或权限错误
* 诊断或配置消息
该策略在三种 Prompt 中为模型提供了最特定于领域的指导。
## 系统架构
本项目使用 **Spring Boot** 实现,并遵循模块化结构。
```
src/main/java/masoud/dabbaghi/llmloganalyzer
│
├── config
│ ├── ChartRunner.java
│ ├── OpenAIConfig.java
│ └── WebClientConfiguration.java
│
├── controller
│ └── BglController.java
│
├── dto
│ └── LogBglEntryDto.java
│
├── entity
│
├── evaluation
│ ├── ClassificationResult.java
│ ├── EvaluationMetrics.java
│ ├── EvaluationMetricsService.java
│ ├── LogEvaluation.java
│ ├── LogEvaluationRepository.java
│ └── LogEvaluationService.java
│
├── service
│ ├── BglParser.java
│ ├── CallModelAi.java
│ ├── ModelClassificationResponse.java
│ ├── PromptExperiment.java
│ ├── PromptGenerator.java
│ └── PromptSpec.java
│
└── visualization
└── EvaluationChartService.java
```
## 主要组件
### BglParser
负责从数据集文件中读取和解析 BGL 日志条目。
### PromptGenerator
包含实验中使用的不同 Prompt 模板:
* Zero-Shot Prompt
* Rule-Based Prompt
* Template-Aware Prompt
### CallModelAi
将生成的 Prompt 和日志条目发送到本地 LLM API,并接收模型响应。
### EvaluationMetricsService
计算评估指标,例如:
* 准确率
* 精确率
* 召回率
* F1分数 (F1-score)
* 真阳性
* 真阴性
* 假阳性
* 假阴性
* 无效响应率
* 平均响应时间
### EvaluationChartService
生成用于比较 Prompt 策略的结果图表。
## 使用技术
* Java 17
* Spring Boot
* Maven
* MongoDB
* Ollama
* Qwen2.5 7B
* JFreeChart
* Spring WebFlux
* Spring Data MongoDB
## 如何运行
### 1. 克隆仓库
```
git clone https://github.com/masoudd2159/LLMLogAnalyzer.git
cd LLMLogAnalyzer
```
### 2. 安装并运行 Ollama
从官方网站安装 Ollama,然后拉取 Qwen2.5 7B 模型:
```
ollama pull qwen2.5:7b
```
在本地运行 Ollama:
```
ollama serve
```
### 3. 配置应用程序
编辑:
```
src/main/resources/application.properties
```
配置示例:
```
spring.application.name=LLMLogAnalyzer
server.port=8081
spring.data.mongodb.host=127.0.0.1
spring.data.mongodb.port=27017
spring.data.mongodb.database=LLMLogAnalyzer
model.api.ollama.url=http://localhost:11434/api/chat
model.api.ollama.model-name=qwen2.5:7b
bgl.location=D:/Programming/Thesis/Dataset/BGL/BGL_2k.log
hdfs.location=D:/Programming/Thesis/Dataset/HDFS_v1/HDFS.log
```
根据您的本地计算机更新数据集路径。
### 4. 运行 MongoDB
确保 MongoDB 正在本地运行:
```
mongod
```
### 5. 运行项目
```
mvn spring-boot:run
```
## 评估指标
本项目使用以下指标评估每种 Prompt 策略:
| 指标 | 描述 |
|---------------|--------------------------------------------------------|
| 准确率 | 所有正确分类的日志所占的百分比 |
| 精确率 | 预测为异常且实际为异常的日志所占的百分比 |
| 召回率 | 正确检测到的真实异常所占的百分比 |
| F1分数 | 精确率和召回率的调和平均数 |
| TP | 正确检测到的异常 |
| TN | 正确检测到的正常日志 |
| FP | 被错误分类为异常的正常日志 |
| FN | 被模型遗漏的异常 |
| 无效率 | 不是有效 JSON 标签的模型输出所占的百分比 |
| 响应时间 | 单个日志条目的平均推理时间 |
# 实验结果
以下图表展示了本项目中使用的三种 Prompt 工程策略的实验结果:
* Zero-Shot Prompt
* Rule-Based Prompt
* Template-Aware Prompt
所有实验均使用 **Qwen2.5 7B** 模型进行。
## 1. 指标对比
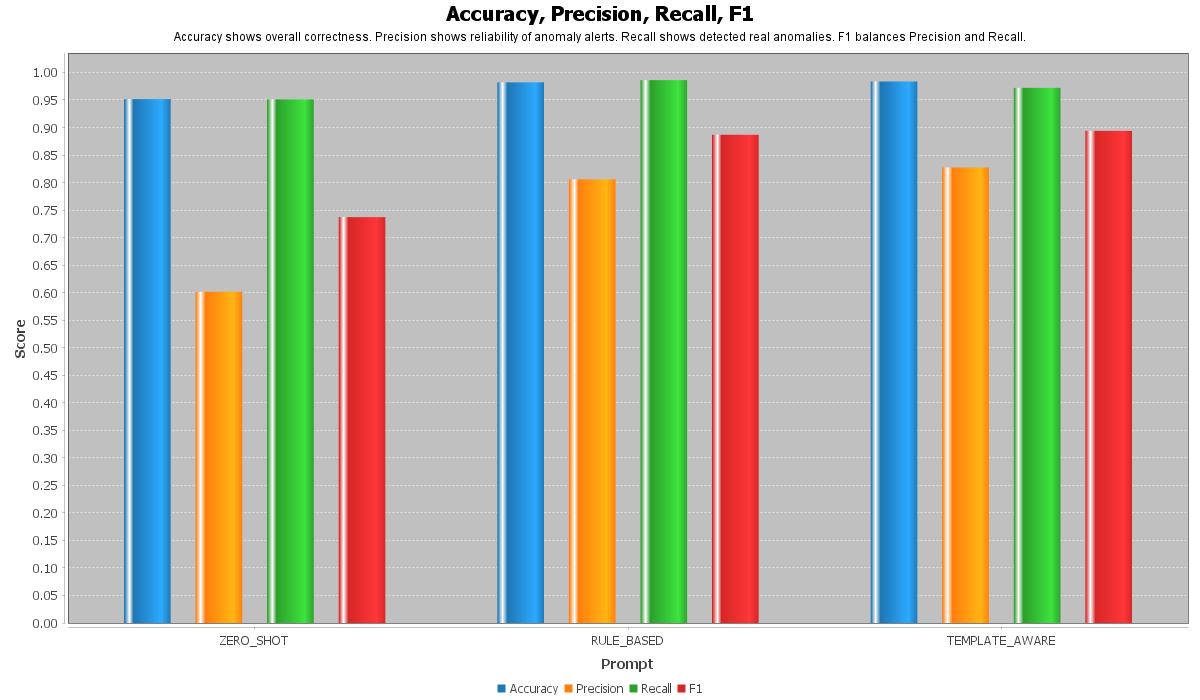
该图表比较了三种 Prompt 策略的主要评估指标。
比较的指标包括:
* 准确率
* 精确率
* 召回率
* F1分数
此图表的目的是展示不同的 Prompt 设计如何影响模型的最终分类性能。
**Zero-Shot** Prompt 仅向模型提供一般的分类指令。因此,模型能够理解许多日志消息,但当正常日志中包含诸如 `ERROR`、`FATAL` 或 `INTERRUPT` 等令人警觉的词汇时,它可能会将其误判为异常。
**Rule-Based** Prompt 通过向模型提供明确的规则来决定日志是正常还是异常,从而改进了分类过程。这有助于模型避免简单的基于关键词的决策。
**Template-Aware** Prompt 为模型提供了关于 BGL 日志模式的额外领域知识。这有助于模型更好地理解哪些日志模板通常代表真实的异常,哪些是正常的系统消息。
总体而言,此图表表明 Prompt 工程对基于 LLM 的日志异常检测质量有直接影响。
更结构化的 Prompt 可以提高模型的可靠性,特别是通过减少不正确的异常预测。
## 2. 混淆矩阵 — Zero-Shot Prompt
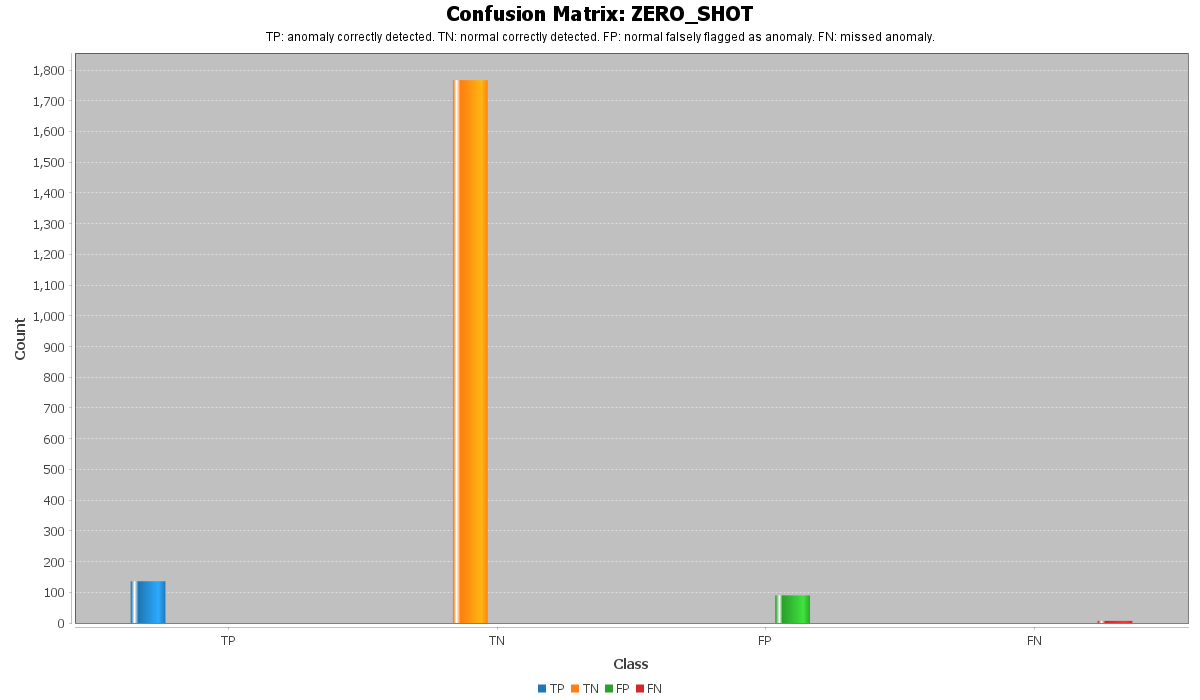
此混淆矩阵展示了 **Zero-Shot** Prompt 的分类结果。
在此 Prompt 策略中,模型仅接收到一般性指令,而没有接收到详细的 BGL 特定规则或模板。
该混淆矩阵包含四个值:
* **真阳性 (TP):**被正确分类为异常的异常日志
* **真阴性 (TN):**被正确分类为正常的正常日志
* **假阳性 (FP):**被错误分类为异常的正常日志
* **假阴性 (FN):**被错误分类为正常的异常日志
Zero-Shot Prompt 作为基准非常有用,因为它展示了 Qwen2.5 7B 模型在没有强力领域指导下的自然推理能力。
然而,这种方法可能会产生更多的假阳性。这是因为在日志消息中,模型可能过度依赖表面上看起来严重的词汇。例如,某些 BGL 日志可能包含诸如 `error`、`interrupt` 或 `warning` 的技术术语,但它们并不总是表明真实的系统故障。
因此,Zero-Shot 的结果表明,LLM 能在某种程度上理解日志消息,但它们需要更好的 Prompt 指导才能更可靠地进行异常检测。
## 3. 混淆矩阵 — Rule-Based Prompt
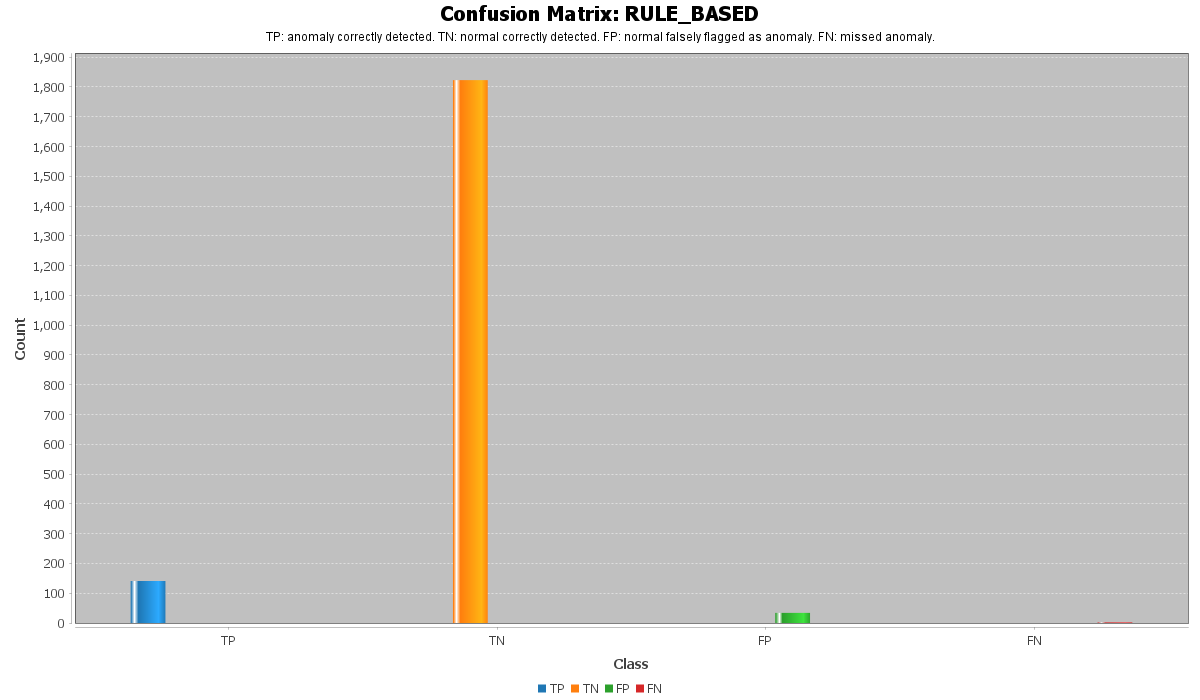
此混淆矩阵展示了 **Rule-Based** Prompt 的分类结果。
Rule-Based Prompt 为模型提供了清晰的决策过程。它解释了哪些类型的日志应被分类为异常,哪些应被分类为正常。
此 Prompt 关注真实的系统影响,而不是简单的关键词匹配。
例如,模型被指示仅当日志明确指出以下严重问题时,才将其分类为异常:
* 不可恢复的硬件故障
* 不可纠正的内存错误
* 通信失败
* 节点崩溃
* 内核恐慌
* 由系统故障引起的作业终止
同时,模型被告知某些日志应保持正常,例如:
* 已纠正的错误
* 诊断信息
* 寄存器转储
* 没有导致系统故障的缺失文件消息
* 没有严重影响权限的消息
与 Zero-Shot Prompt 相比,Rule-Based Prompt 通常能更好地控制模型的决策过程。它减少了假阳性,因为模型变得更加保守,不会仅仅因为包含看起来危险的词汇就将日志分类为异常。
此结果表明,在 Prompt 中添加明确的分类规则可以改善基于 LLM 的异常检测。
## 4. 混淆矩阵 — Template-Aware Prompt
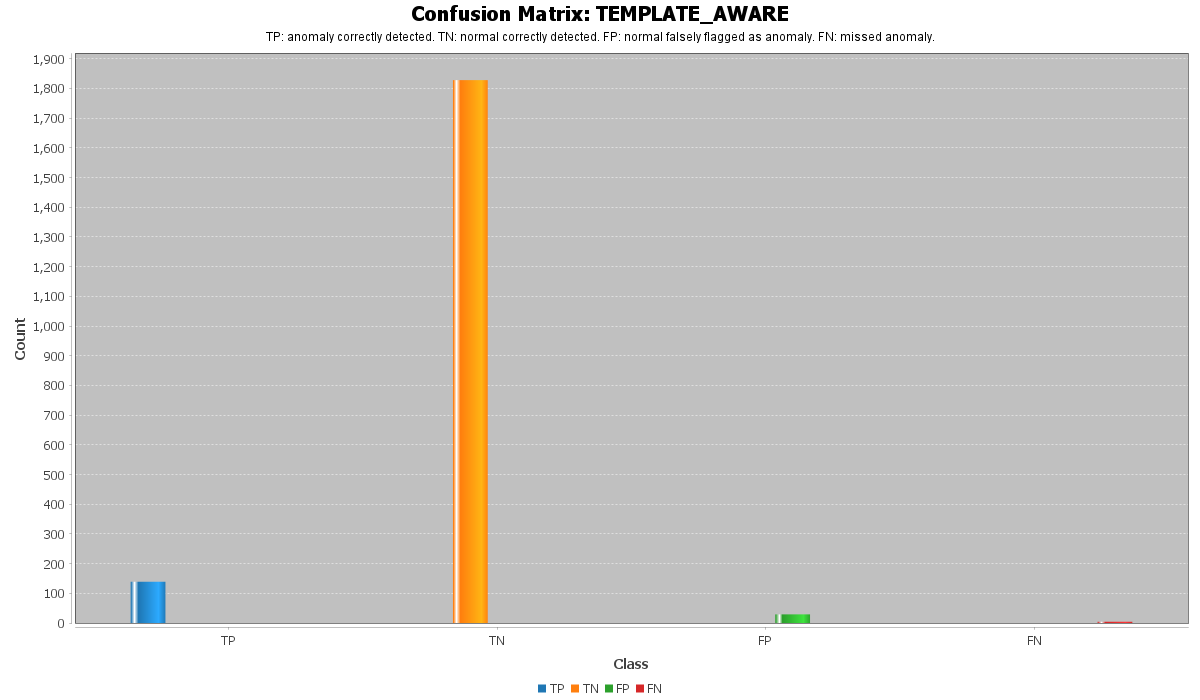
此混淆矩阵展示了 **Template-Aware** Prompt 的分类结果。
Template-Aware Prompt 是本项目中最特定于领域的策略。它为模型提供了 BGL 风格日志模板的示例,并解释了哪些模式通常与异常相关,哪些通常是正常的。
这很重要,因为系统日志通常包含重复的模板。某些模板可能看起来危险但在数据集中是正常的,而另一些模板则明确表明存在严重的系统故障。
Template-Aware Prompt 帮助模型识别诸如以下模式:
* `data TLB error interrupt`
* `data storage interrupt`
* `uncorrected memory error`
* `kernel panic`
* `link failure`
* `node crash`
作为更强的异常指标。
它还有助于模型避免对正常的 BGL 模式进行错误分类,例如:
* 指令地址消息
* 数据地址消息
* 寄存器转储
* 已纠正的 ECC 错误
* 诊断信息
* 配置信息
结果表明,使用模板级的知识可以使模型更加稳定,更适合进行日志异常检测。
当数据集具有已知的重复日志模式时,此 Prompt 策略特别有用,因为模型可以基于语义含义和特定领域的模板做出决策。
## 5. 无效响应率
此图表展示了每种 Prompt 策略的无效响应率。
无效响应意味着模型未返回预期的输出格式。
本项目中预期的输出格式为:
```
{"label":"0"}
```
或:
```
{"label":"1"}
```
此指标非常重要,因为系统会自动解析模型响应。如果模型返回了额外的文本、解释或格式不正确的 JSON,该响应将变为无效,无法直接用于评估。
结果表明,Prompt 成功地控制了模型的输出格式。
较低或为零的无效响应率意味着模型响应对于自动处理是可靠的。这在现实世界的系统中非常重要,因为 LLM 的输出必须能够在无需人工干预的情况下被解析。
此结果还表明,Prompt 内的严格输出指令对于强制模型返回纯净的 JSON 分类结果是有效的。
## 6. 平均响应时间
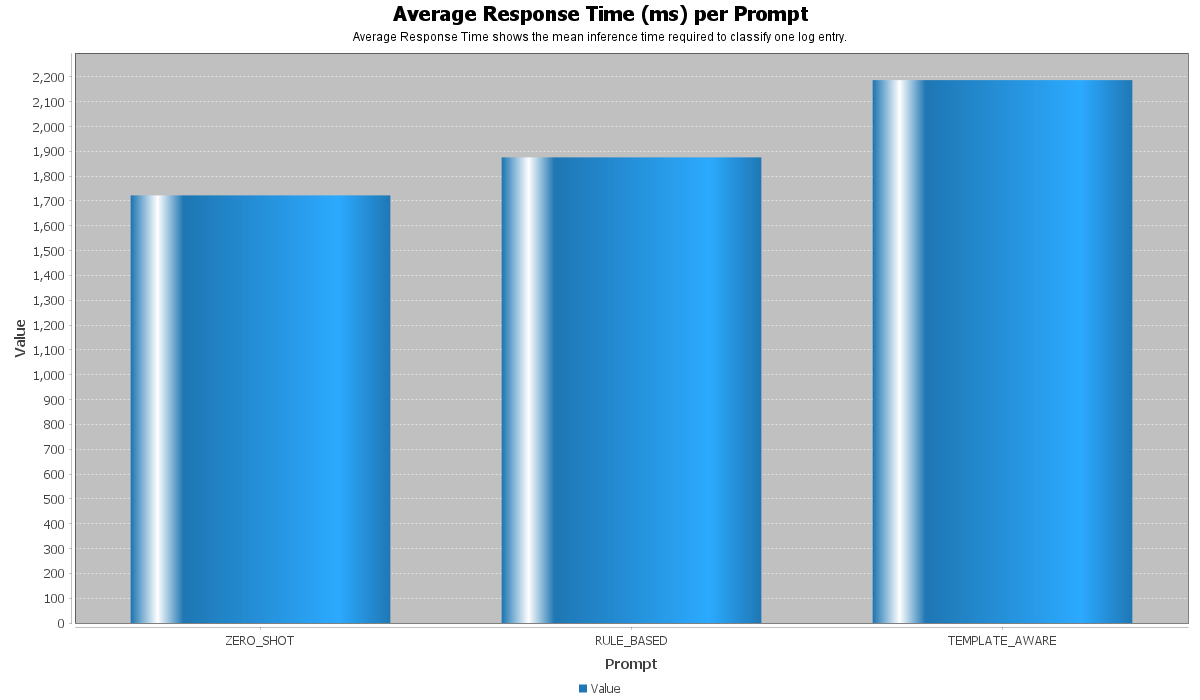
此图表比较了模型对每种 Prompt 策略的平均响应时间。
响应时间是一个重要指标,因为基于 LLM 的分类可能比传统的机器学习方法更慢。
Zero-Shot Prompt 通常具有最短的响应时间,因为它包含的指令更少且上下文更短。
Rule-Based Prompt 比 Zeroot Prompt 更长,因此模型需要处理更多的输入 token。这可能会略微增加响应时间。
Template-Aware Prompt 通常是最长的 Prompt,因为它包含特定于领域的 BGL 模式和额外的分类指导。因此,它可能具有最高的响应时间。
此图表展示了一个重要的权衡:
* 较短的 Prompt 更快。
* 更详细的 Prompt 可以提高分类质量。
* Template-Aware Prompt 提供了更好的领域知识,但可能会增加推理时间。
对于实际应用,应仔细考虑这种权衡。如果速度是首要考虑因素,则较短的 Prompt 可能更好。如果准确率和减少假阳性更为重要,则基于规则的或模板感知的 Prompt 可能更合适。
## 最终结果分析
实验结果表明,Prompt 工程可以利用大语言模型改善系统日志的异常检测。
**Zero-Shot** Prompt 可用作基准,并表明 Qwen2.5 7B 能够在没有训练的情况下对许多日志进行分类。
然而,由于它没有足够的 BGL 特定知识,它可能会产生更多的假阳性。
**Rule-Based** Prompt 通过为模型提供清晰的决策规则来改善结果。这使得模型更加保守,减少了不正确的异常预测。
**Template-Aware** Prompt 增加了关于 BGL 日志模式的特定领域知识。这有助于模型理解重复的日志模板并提高分类稳定性。
无效响应率结果表明,输出格式已通过 Prompt 设计成功得到控制。
响应时间结果表明,更好的 Prompt 可能需要更多的处理时间。因此,在性能和速度之间存在权衡。
总体而言,结果支持了本项目的主要理念:
**大语言模型可用于日志异常检测,而 Prompt 工程可以显著提高其可靠性。**
## 总体分析
实验结果表明,Prompt 工程能够改善基于 LLM 的系统日志异常检测。
Zero-Shot Prompt 表明,Qwen2.5 7B 在没有特定任务训练的情况下也能够理解许多日志消息。
然而,由于它没有关于 BGL 特定正常模式的足够信息,因此更有可能产生假阳性。
Rule-Based Prompt 通过给予模型明确的决策规则来改善结果。
这减少了假阳性,并使模型更加稳定。
Template-Aware Prompt 通过包含已知的 BGL 风格模式,提供了最特定于领域的信息。
其性能接近基于规则的策略,表明领域知识可以帮助模型更可靠地分类日志。
无效响应率为零,这意味着通过 Prompt 设计成功控制了 JSON 输出格式。
响应时间图表表明,更详细的 Prompt 会增加推理时间。因此,在 Prompt 的复杂性和分类速度之间存在着实际权衡。
## 结论
本项目表明,大语言模型可以在不进行传统模型训练的情况下用于系统日志异常检测。
结果表明,Prompt 工程对分类质量有显著影响。
简单的 Zero-Shot Prompt 可以正确分类许多日志,但结构化和领域感知的 Prompt 提供了更好的可靠性。
主要结论是,当 Prompt 包含以下内容时,基于 LLM 的日志异常检测会变得更加有效:
* 清晰的输出格式指令
* 严格的异常定义
* 正常日志示例
* 特定领域的日志模式
* 防止仅基于关键词进行分类的规则
这使得 Prompt 工程成为将 LLM 应用于日志分析和异常检测的一项重要技术。
## 作者
**Masoud Dabbaghi**
硕士学位项目
课题:基于大语言模型和 Prompt 工程改进系统日志异常检测
标签:AI风险缓解, DLL 劫持, Java Spring Boot, JS文件枚举, 域名枚举, 大语言模型, 异常检测, 数据分类