MaksymChunikhin/Advanced-Fraud-Detection-System
GitHub: MaksymChunikhin/Advanced-Fraud-Detection-System
端到端欺诈检测系统,实现实时监控和风险评估。
Stars: 1 | Forks: 0
# IEEE-CIS 欺诈检测




一个基于 [IEEE-CIS 欺诈检测](https://www.kaggle.com/c/ieee-fraud-detection) Kaggle 竞赛的机器学习项目,用于检测欺诈在线交易。
该项目实现了一个干净的端到端流程(三个笔记本)以及一个实时 Streamlit 监控仪表板。主要关注的是 **特征工程、诚实验证和模型可解释性**,而不是越来越复杂的集成。
## 突出亮点
* 最佳验证 ROC-AUC(LightGBM):**0.93797**
* 最佳 Kaggle **Private** 排行榜 ROC-AUC:**0.919338**
* 时间感知验证(无未来泄漏)
* 使用 **Optuna** 进行超参数调整
* **SHAP** 可解释性
* 实时 **Streamlit** 监控仪表板
## 技术栈
Python · pandas · NumPy · scikit-learn · LightGBM · XGBoost · CatBoost · Optuna · SHAP ·
Plotly · Streamlit · joblib · pyarrow
## 竞赛与数据集
该项目基于 [IEEE-CIS 欺诈检测](https://www.kaggle.com/c/ieee-fraud-detection) Kaggle 竞赛,由 IEEE 计算智能学会和 Vesta 公司组织。
**任务:** 预测在线交易是否为欺诈(`isFraud`)的概率。
**指标:** ROC-AUC。
**数据集大小:**
* ~590K 训练交易
* ~506K 测试交易
* 471 个工程特征
数据集高度不平衡:只有大约 **3.5%** 的交易是欺诈,这使得验证策略和指标选择尤为重要。
使用的原始文件:`train_transaction.csv`、`train_identity.csv`、`test_transaction.csv`、`test_identity.csv`。由于数据量较大,数据本身 **不包括** 在存储库中——请从竞赛页面下载。
## 项目结构
| 笔记本 | 描述 |
| --- | --- |
| `fraud_01_data_prep_features.ipynb` | 数据加载、EDA、预处理和特征工程 |
| `fraud_02_modeling_tuning.ipynb` | 基线、Optuna 调整、SHAP 分析和阈值调整 |
| `fraud_03_inference_submission.ipynb` | 测试评分和 Kaggle 提交 |
其他文件夹:
* `data/processed/` — parquet 数据集
* `models/` — 保存的模型和 Optuna 研究
* `submissions/` — Kaggle 提交
* `app/` — Streamlit 仪表板
## 流程
### 1. 数据准备与特征工程
* 交易和身份表合并
* 内存优化
* 缺失值处理
* 分类编码
* 时间归一化的 D 列
* 聚合特征
* 频率编码
* 电子邮件和交互特征
### 2. 验证策略
交易按时间顺序排列,竞赛测试集代表未来。
随机 K-Fold 混合过去和未来的观测值,往往会高估性能。
因此,该项目使用 **时间感知的保留**:
* 最早 80% → 训练
* 最晚 20% → 验证
### 3. 模型与超参数调整
基线 ROC-AUC:
| 模型 | ROC-AUC |
| --- | ---: |
| XGBoost | 0.92631 |
| LightGBM | 0.92463 |
| CatBoost | 0.89900 |
| 逻辑回归 | 0.81995 |
经过 Optuna 调整后:
| 模型 | 基线 | 调整 | 增益 |
| --- | ---: | ---: | ---: |
| LightGBM | 0.92463 | **0.93797** | +0.01334 |
| XGBoost | 0.92631 | 0.93580 | +0.00949 |
| CatBoost | 0.89900 | 0.92802 | +0.02902 |
三个梯度提升模型明显优于逻辑回归,表明数据中存在强大的非线性关系。
### 4. 可解释性
对最佳 LightGBM 模型进行 SHAP 分析表明,最强的预测因子包括:
* 活动计数器(C1、C11、C13、C14)
* 交易金额
* 基于卡的聚合特征
* 归一化的 D 列
* 频率特征
几个 **手动工程** 的特征出现在最有影响力的特征中,证实了特征工程工作的价值。
### 5. 阈值调整
模型输出概率而不是二元标签。分类阈值会影响操作决策,但 **不影响** ROC-AUC 分数。最佳阈值取决于业务在假阳性率和错过的欺诈之间的权衡。
### 6. 推理与提交
使用保存的模型对测试交易进行评分。提交以概率生成,并可选地使用 **排名平均** 集成来组合模型预测。
## 结果
### Kaggle 排行榜
| 提交 | 公共 LB | 私有 LB |
| --- | ---: | ---: |
| LightGBM + XGBoost | 0.948949 | **0.919338** |
| LightGBM | 0.949379 | 0.919059 |
| XGBoost | 0.946904 | 0.917151 |
| LightGBM + XGBoost + CatBoost | 0.947121 | 0.915877 |
| CatBoost | 0.934277 | 0.897988 |
尽管 LightGBM + XGBoost 混合实现了最高的私有分数,但与单个 LightGBM 模型的差异可以忽略不计(0.919338 vs 0.919059)。因此,**调整后的 LightGBM** 被选为最终模型——它更简单、更快且更容易维护。
这是一个干净、可读的端到端流程,用于学习和投资组合目的,而不是最大堆叠的竞赛入口;预计与排行榜顶部的差距(顶级解决方案依赖于激进的 UID 特征工程和大型集成)。
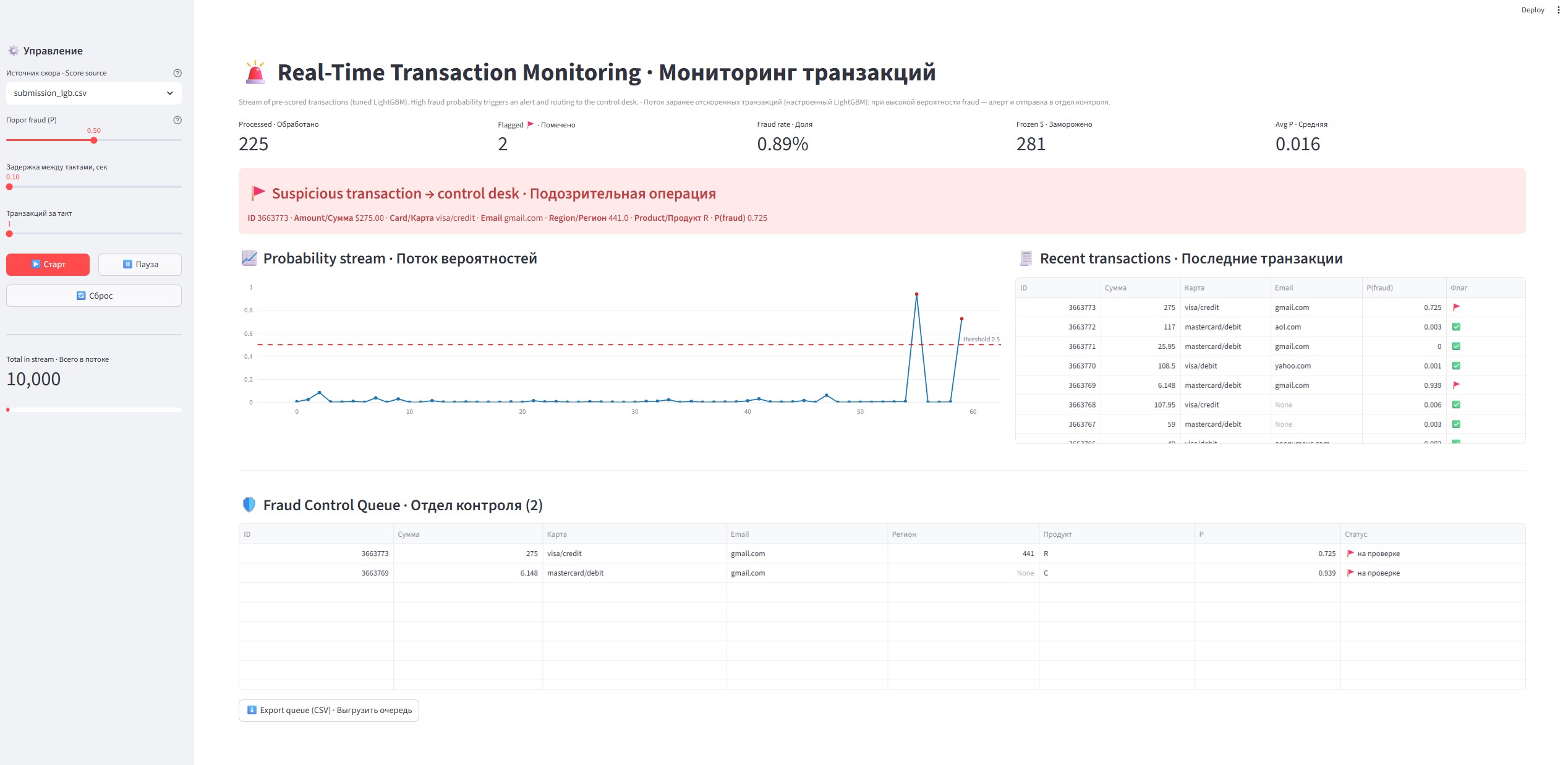
### 演示
#### 实时监控仪表板(Streamlit)
仪表板回放预先评分的交易,就像它们实时到达一样。当交易的欺诈概率超过阈值时,会触发警报,并将交易路由到审查队列。
功能:
* 实时概率流
* 欺诈警报
* 欺诈控制审查队列(可导出为 CSV)
* 处理/标记计数器和估计的欺诈率
* 冻结金额统计
* 可配置的阈值和从侧边栏切换模型
```
streamlit run app/streamlit_app.py
```
## 关键要点
* 特征工程对排行榜性能的贡献大于模型复杂性。
* 时间感知验证比随机 K-Fold 提供更现实的估计。
* 将较弱模型添加到集成中可能会 *降低* 性能。
* SHAP 证实了手动工程特征的重要性。
* 复杂性并不总是得到回报。
**主要要点:** 仔细的特征工程和诚实的验证策略可以比越来越复杂的模型集成对欺诈检测性能做出更大的贡献。
## 环境
```
conda env create -f environment.yml
conda activate fraud
```
Python 3.10。按顺序运行笔记本:`01 → 02 → 03`。
## 作者
**Maksym Chunikhin**
[GitHub](https://github.com/MaksymChunikhin)
标签:Apex, CatBoost, IEEE-CIS, Kaggle, Kubernetes, LightGBM, NumPy, Optuna, pandas, Python, ROC-AUC, scikit-learn, SHAP, Streamlit, WSL, XGBoost, 在线交易, 数据科学, 数据竞赛, 无后门, 时间感知验证, 机器学习, 模型可解释性, 模型调优, 欺诈检测, 欺诈识别, 特征工程, 访问控制, 资源验证, 超参数调优, 逆向工具