AttiR/OpsCanvas
GitHub: AttiR/OpsCanvas
基于 LangGraph 的生产级多智能体事件响应系统,通过四个 AI 智能体自动完成告警分类、上下文研究与信息综合,并在人工审批后执行操作。
Stars: 0 | Forks: 0
# OpsCanvas
`
```
{
"alert_source": "cloudwatch",
"alert_payload": {
"AlarmName": "CRITICAL-PaymentService-ErrorRate",
"AlarmDescription": "Error rate exceeded 25% for 10 minutes",
"NewStateValue": "ALARM",
"Region": "eu-north-1"
}
}
```
响应 `202 Accepted`:
```
{
"run_id": "a3f8c2d1-4b5e-6789-abcd-ef0123456789",
"status": "running",
"message": "Incident run started. Poll GET /incidents/{run_id} for status."
}
```
### GET /api/incidents/:run_id
返回当前状态。每 3 秒轮询一次,直到 `status` 变为 `awaiting_review` 或 `completed`。
状态值:`running` · `awaiting_review` · `completed` · `failed`
### POST /api/incidents/:run_id/review
```
{ "decision": "approved" }
```
```
{ "decision": "rejected", "feedback": "Actions too generic — add kubectl commands" }
```
当 `decision` 为 `rejected` 时,`feedback` 是必填项。否则将返回 `422`。
### GET /health
```
{ "status": "healthy", "version": "1.0.0", "agent": "opscanvas" }
```
## 在本地运行
**前置条件:** Python 3.12、Node 22,以及 Anthropic、Tavily、Upstash Redis、Slack webhook、Google OAuth client ID、Langfuse 公开/密钥的 API 密钥。Sourciq 必须正在运行(或使用已部署的 Sourciq API)。
```
git clone https://github.com/AttiR/OpsCanvas
cd OpsCanvas
# 后端
python3.12 -m venv venv && source venv/bin/activate
pip install -r backend/requirements.txt
cp .env.example .env # fill in all API keys
make run # starts API on port 8001
# 前端(单独的 terminal)
cd frontend && npm install
cp .env.local.example .env.local # fill in VITE_ vars
npm run dev # starts at http://localhost:5173
```
```
make test # 58 unit tests — zero API/Redis/LLM calls
make eval # agent eval suite — triage · routing · synthesis · e2e (CI-gated)
make lint # ruff check + format
make graph # visualise LangGraph state machine → graph.png
make verify # confirm all imports resolve
```
## 成本
| 服务 | 成本 |
|---------|------|
| AWS Lambda + API Gateway (eu-north-1) | $0(免费额度——每月 100 万次请求) |
| Upstash Redis | $0(免费额度——每天 1 万条命令) |
| Tavily | $0(免费额度——每月 1 千次搜索) |
| Langfuse | $0(免费额度) |
| Vercel | $0(免费额度) |
| Slack webhooks | $0 |
| **基础设施总计** | **$0/月** |
每次事件运行的 Anthropic API 成本:**~$0.02**(4 个智能体 × 每个约 500 个 token,按 Claude Sonnet 定价计算),在 Langfuse 中按事件进行追踪,并由成本熔断器 (`MAX_INCIDENT_USD`) 限制单次运行额度。有关 Langfuse 追踪截图,请参见[第 4 层 · 成本](#4--cost--per-incident-with-a-runaway-breaker)。
## 项目结构
```
OpsCanvas/
├── backend/
│ ├── app/
│ │ ├── agents/
│ │ │ ├── triage.py Severity classification → TriageResult
│ │ │ ├── researcher.py Sourciq + Tavily research → ResearchResult
│ │ │ ├── synthesiser.py Incident summary → IncidentSummary
│ │ │ ├── action.py Slack Block Kit post (authorized · idempotent · audited)
│ │ │ └── models.py Pydantic output models for all agents
│ │ ├── graph/
│ │ │ ├── state.py IncidentState TypedDict
│ │ │ └── builder.py StateGraph assembly + conditional edges
│ │ ├── api/
│ │ │ └── incidents.py POST/GET /incidents, POST /incidents/:id/review
│ │ ├── core/
│ │ │ ├── redis_store.py checkpointer + save/load/delete/list
│ │ │ ├── observability.py Langfuse trace/span setup, flush
│ │ │ ├── guardrails.py schema + injection + action-auth + abstain
│ │ │ ├── cost.py per-incident CostMeter + circuit breaker
│ │ │ ├── reliability.py timeouts, retries, fallback, circuit breaker
│ │ │ └── audit.py append-only action audit log
│ │ └── integrations/
│ │ └── sourciq.py HTTP client for Sourciq (Agent 2)
│ ├── lambda_handler.py Mangum ASGI adapter
│ ├── main.py FastAPI app — CORS, rate limiting, health
│ ├── requirements.txt
│ └── template.yaml AWS SAM — Lambda + API Gateway + CloudWatch
├── frontend/
│ └── src/
│ ├── components/
│ │ ├── AgentTimeline.tsx 5-node LangGraph state visualisation
│ │ └── ApprovalPanel.tsx Human review — approve/reject/feedback
│ ├── pages/
│ │ ├── LoginPage.tsx Split panel: proof points + Google auth
│ │ └── DashboardPage.tsx Alert input → polling → review → resolved
│ ├── context/
│ │ └── AuthContext.tsx Google id_token in memory only
│ ├── hooks/
│ │ └── usePollIncident.ts Polls GET /incidents/:id every 3s
│ ├── api/
│ │ └── client.ts Typed fetch wrapper, ApiError class
│ └── types/
│ └── api.ts TypeScript types + EXAMPLE_ALERTS
├── tests/
│ ├── test_graph_agents.py State machine, Triage, Researcher (20 tests)
│ ├── test_api_pipeline.py Synthesiser, Redis, FastAPI contracts (25 tests)
│ ├── test_action_agent.py Slack Block Kit, webhook mocked (13 tests)
│ └── eval/
│ ├── triage_set.jsonl labelled alert → expected severity
│ ├── golden_incidents.jsonl alert → expected outcome
│ ├── test_triage_accuracy.py
│ ├── test_routing.py P4 auto-close · P1 escalate (must = 1.0)
│ ├── test_synthesis_judge.py
│ └── test_e2e_success.py
├── .github/workflows/
│ ├── ci.yml pytest + ruff + tsc + Trivy + agent-eval on every PR
│ ├── cd-backend.yml SAM deploy to Lambda on merge to main
│ └── cd-frontend.yml Vercel deploy on merge to main
├── infra/
│ └── secrets-reference.sh All secrets documented
├── Makefile
└── .env.example
```
*由 Atti Rehman 构建 · [LinkedIn](https://www.linkedin.com/in/attirehman/) · [GitHub](https://github.com/AttiR)*


![]()
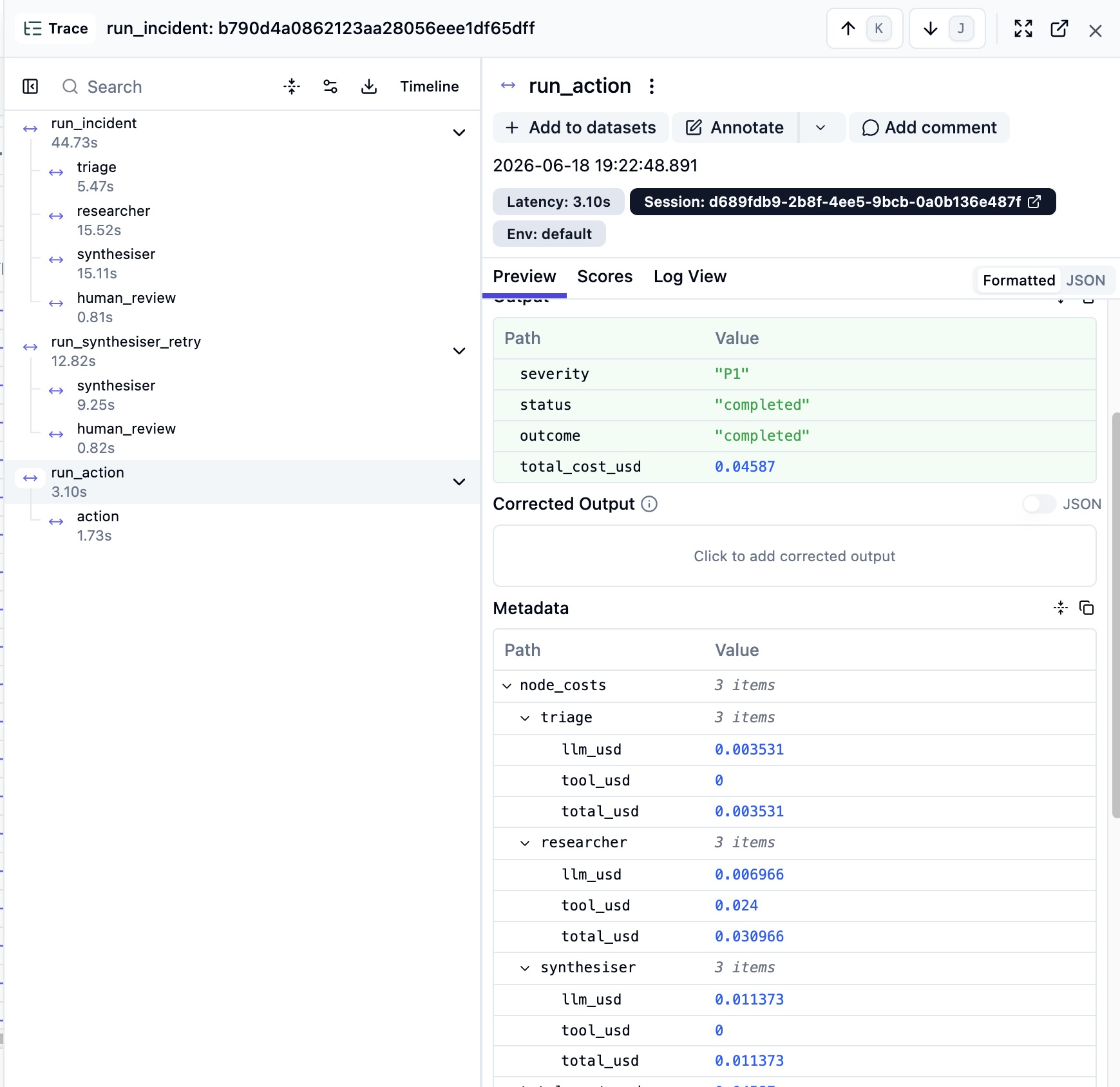
Langfuse — total_cost_usd and per-node LLM/tool breakdown for one incident run
标签:AWS Lambda, LangGraph, 多智能体, 搜索引擎查询, 运维