mos-nabih/aws-cloudwatch-incident-response
GitHub: mos-nabih/aws-cloudwatch-incident-response
AWS云监控与事件响应实验室
Stars: 0 | Forks: 0
# 结算服务可观测性
部署在 AWS 上的结算 API,具有结构化 JSON 日志、自定义业务指标、CloudWatch 仪表板、警报、SNS 通知和记录的延迟事件。
本项目的目标是可观测性,而非应用复杂性。服务故意保持小巧,以便于监控、警报和事件响应工作易于检查。
## 架构
```
Client / traffic generator
|
v
Application Load Balancer
|
+--> AWS/ApplicationELB metrics
|
v
EC2 instance
- FastAPI checkout service
- systemd service
- CloudWatch Agent
|
+--> structured JSON logs -> CloudWatch Logs
+--> custom checkout metrics -> CloudWatch Metrics
+--> host metrics -> CloudWatch Metrics
|
v
CloudWatch Dashboard + CloudWatch Alarms -> SNS Email
```
Terraform 管理 EC2 实例、ALB、安全组、IAM 角色、CloudWatch 日志组、仪表板、警报和 SNS 主题。
## 包含内容
| 区域 | 实现 |
| --- | --- |
| 工作负载 | 位于应用程序负载均衡器后面的 EC2 上的 FastAPI 结算服务 |
| 日志 | 带有关联 ID 的结构化 JSON 请求日志 |
| 日志传输 | CloudWatch Agent 将应用程序日志发送到 `/checkout-service/app` |
| 标准指标 | ALB 请求计数、延迟、HTTP 状态码、目标健康 |
| 自定义指标 | 结算开始、成功、失败、支付拒绝、结算价值 |
| 仪表板 | 带有 RED/USE 视图和业务指标的 CloudWatch 仪表板 |
| 警报 | 带有 SNS 邮件通知的 CloudWatch 警报 |
| 事件 | 结算路径中的支付提供程序延迟,通过 RED/USE 诊断 |
## 仓库结构
```
app/ FastAPI app, requirements, deployment helper
config/ CloudWatch dashboard, alarms, and agent config
docs/ Deployment guide, dashboard guide, runbook
infra/ Terraform infrastructure
presentation/ HTML/PDF slides and demo script
scripts/ Traffic generator and repeatable incident runner
screenshots/ Final screenshots and incident data for submission
```
## API 端点
| 端点 | 目的 |
| --- | --- |
| `GET /health` | 由 ALB 目标组使用的健康检查 |
| `POST /checkout` | 正常结算支付路径 |
| `POST /checkout/simulate-latency` | 用于事件测试的受控慢支付提供程序路径 |
| `POST /checkout/simulate-error` | 受控 500 错误路径 |
| `POST /checkout/simulate-cpu` | 受控 CPU 负载路径 |
## 部署
1. 配置 AWS 凭据。
2. 使用区域、密钥对、警报电子邮件和允许的 CIDR 更新 `infra/terraform.tfvars`。
3. 部署:
```
cd infra
terraform init
terraform apply
```
4. 确认 SNS 邮件订阅。
5. 使用 Terraform 输出的 `service_url` 进行所有流量生成。
## 测试流量
生成基线结算流量:
```
python3 scripts/generate_traffic.py \
--url http://ALB_DNS_NAME \
--scenario normal \
--requests 50 \
--sleep 0.5
```
运行可重复的事件:
```
python3 scripts/run_incident.py \
--url http://ALB_DNS_NAME \
--baseline-seconds 300 \
--incident-seconds 120 \
--recovery-seconds 300 \
--baseline-concurrency 2 \
--incident-concurrency 8 \
--baseline-interval 0.5 \
--incident-interval 0 \
--timeout 10
```
完成后销毁:
```
cd infra
terraform destroy
```
## 关键截图
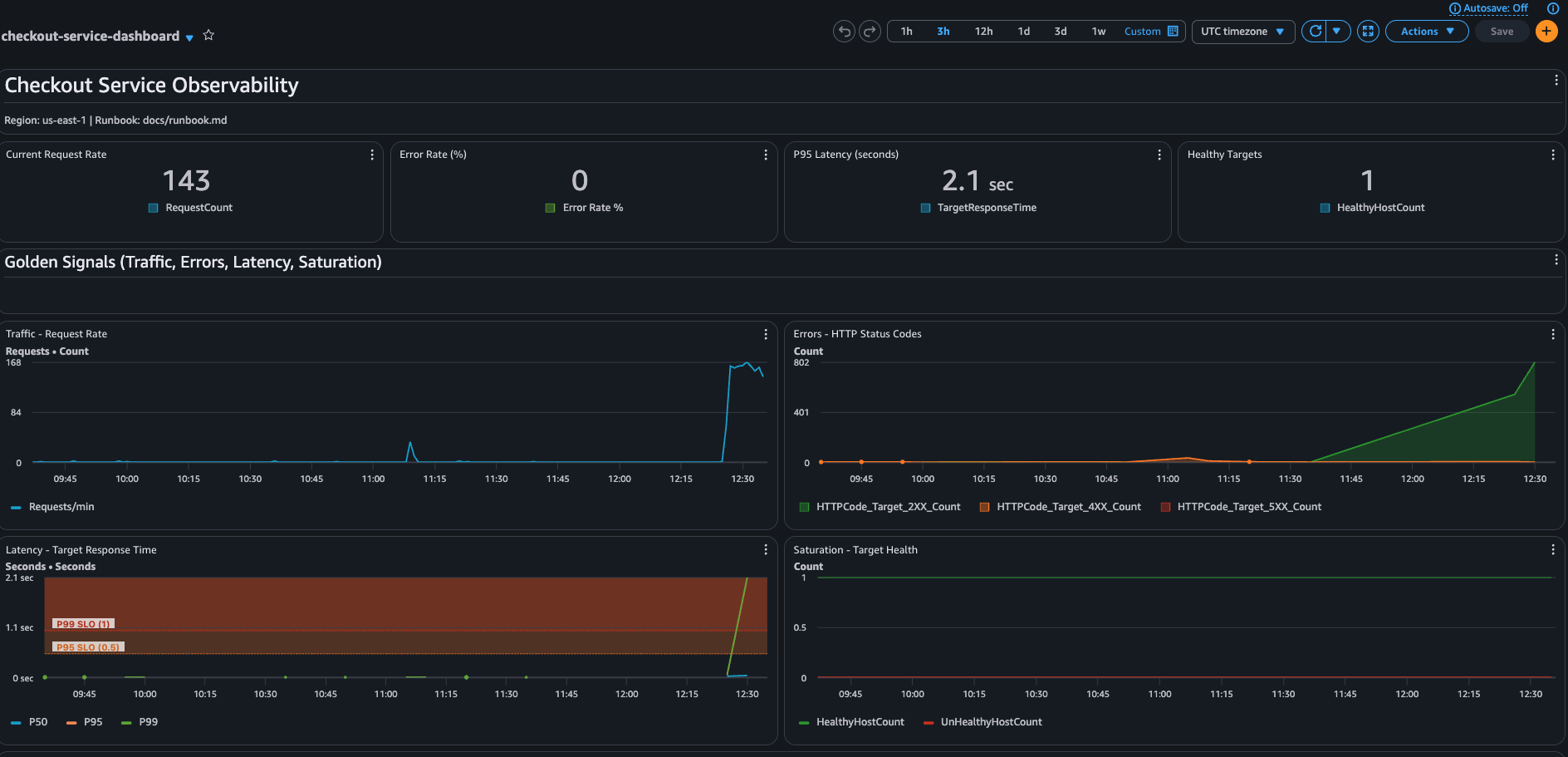
### CloudWatch 仪表板
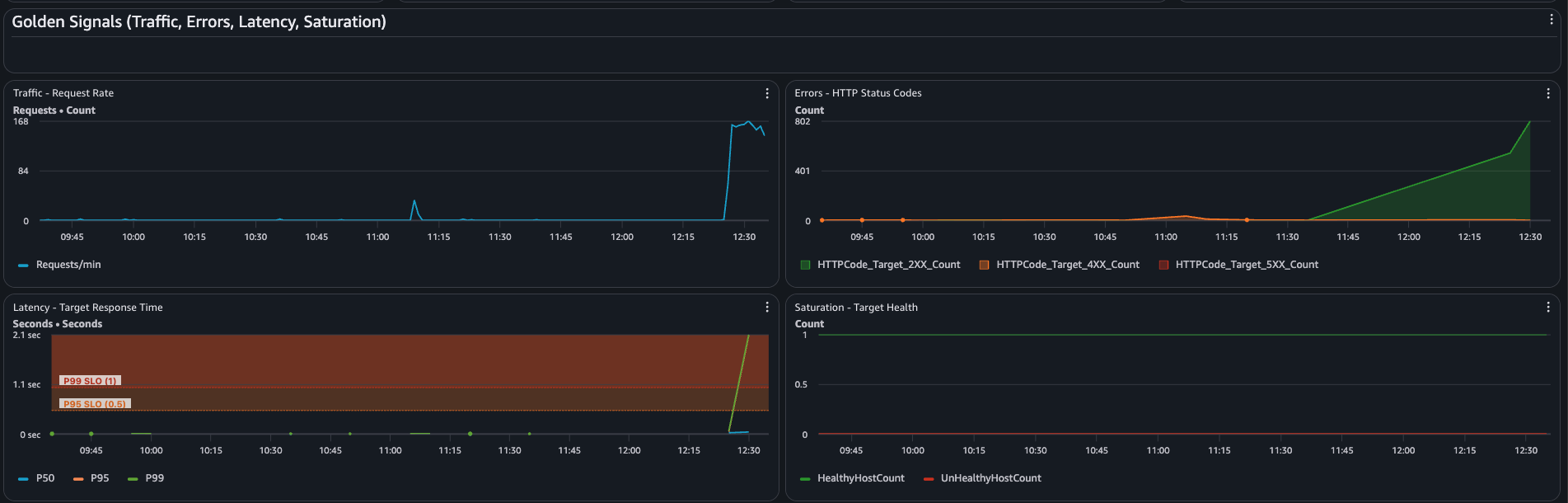
### 金色信号
### 事件延迟峰值

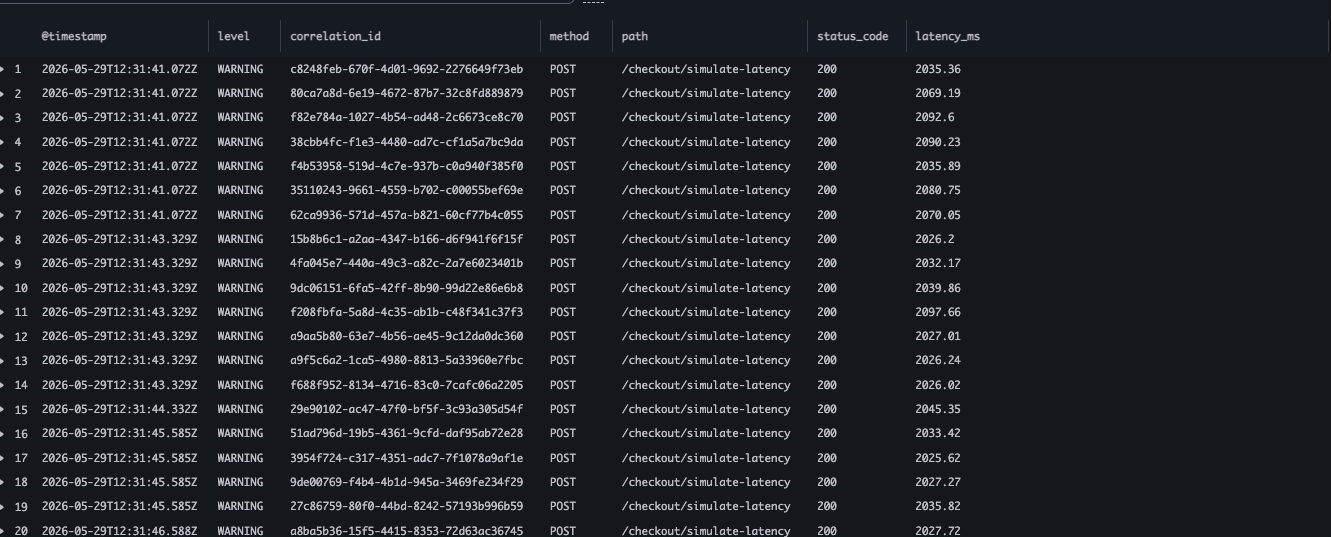
### 日志调查
### 资源利用率

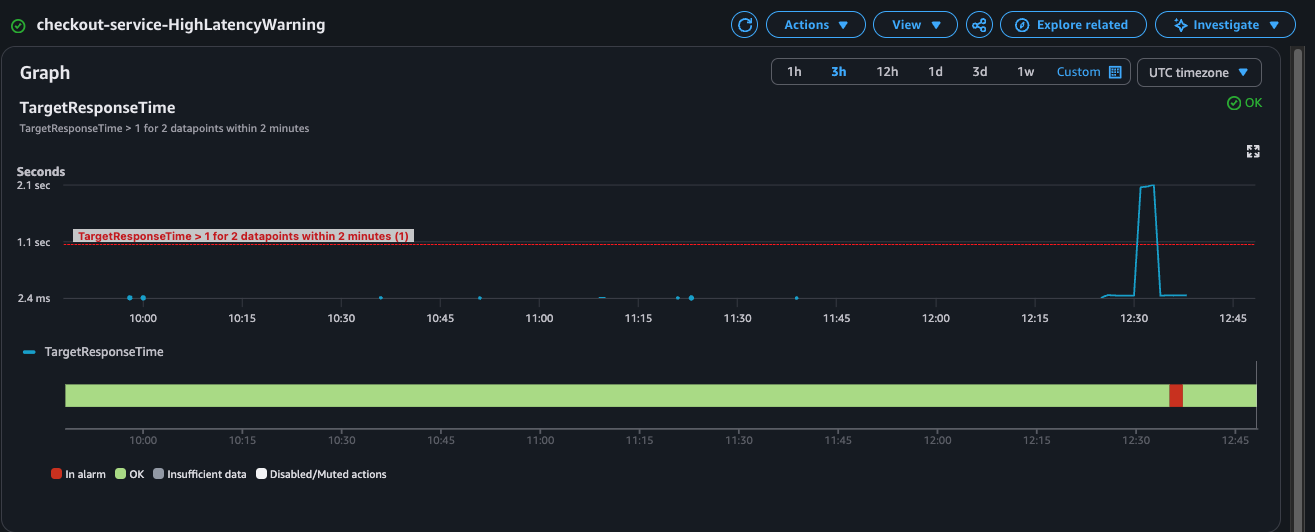
### 警报证据
### 业务指标快照

### 业务指标
在事件期间,CloudWatch 业务指标保持可用,并提供了对客户端健康状态的第二视角,超越了基础设施指标。
## 事件摘要
在 **2026-05-29 从 12:26:37 到 12:38:41 UTC** 期间,服务运行了受控基线 -> 延迟峰值 -> 恢复测试。在峰值期间,结算请求触发了慢支付提供程序路径,327 个请求返回了 `200`,而 18 个客户端请求在等待降级路径时超时。
CloudWatch 检测到问题:
- ALB p95 `TargetResponseTime` 在 `12:31 UTC` 达到 `2.079s`,在 `12:32 UTC` 达到 `2.094s`,在 `12:33 UTC` 达到 `2.130s`。
- `checkout-service-HighLatencyWarning` 在 `2026-05-29 12:35:08 UTC` 进入 `ALARM` 状态,并在 `12:37:08 UTC` 返回 `OK`。
- 日志洞察显示 `/checkout/simulate-latency` 请求的延迟约为 `2035ms` 到 `2098ms`。
- EC2 CPU、内存、磁盘和目标健康保持正常,因此问题不是主机饱和。
事件运行者观察到更高的 p95 为 `10110.44ms`,因为降级峰值还产生了 18 个客户端超时,因此客户端观察到的延迟比 ALB 延迟指标(针对完成的响应)更差。
根本原因:结算路径中的支付提供程序行为缓慢。
立即缓解措施:切换到备用结算路径或禁用降级的支付提供程序集成。
长期修复:提供程序超时、提供程序特定延迟警报、回退路由和发布前的性能测试。
## 文档
| 文件 | 目的 |
| --- | --- |
| [ARCHITECTURE.md](ARCHITECTURE.md) | 系统设计、组件、数据流 |
| [INSTRUMENTATION.md](INSTRUMENTATION.md) | 日志、关联 ID、标准和自定义指标 |
| [MONITORING.md](MONITORING.md) | 仪表板设计、RED/USE 方法 |
| [ALERTING.md](ALERTING.md) | 警报阈值和响应程序 |
| [INCIDENTS.md](INCIDENTS.md) | 事件时间线、根本原因分析、截图、经验教训 |
| [docs/runbook.md](docs/runbook.md) | 运营故障排除步骤 |
| [docs/dashboard-guide.md](docs/dashboard-guide.md) | 如何阅读仪表板 |
| [docs/deployment.md](docs/deployment.md) | 部署和清理说明 |
标签:AV绕过, AWS, CloudWatch, DPI, EC2, ECS, FastAPI, Homebrew安装, IaC, OISF, SNS通知, Terraform, 业务指标, 云服务监控, 仪表盘, 后端开发, 安全告警, 性能监控, 支付处理, 故障诊断, 日志管理, 特权提升, 结构化日志, 自动化部署, 自定义指标, 警报, 负载均衡