kayadibi1/dc-frontier-events
GitHub: kayadibi1/dc-frontier-events
一个生产级的前沿科技活动聚合器,从多层级数据源抓取华盛顿特区 AI 与科技活动,经去重、过滤和排名后输出多种订阅格式。
Stars: 0 | Forks: 0
# dc-frontier-events
一个生产级别的聚合器,将华盛顿特区都会区的**AI、半导体和前沿科技活动**汇集到一个单一的、去重的、**按相关性排名**的订阅源中——首要关注“知名”活动(Anthropic、OpenAI、Nvidia、Microsoft 等),以及这些知名机构在特区实际会出席的政策 / 智库活动地点。
请参阅 [`GOAL.md`](GOAL.md) 了解使命,以及 [`PROGRESS.md`](PROGRESS.md) 获取最新验证的运行记录。
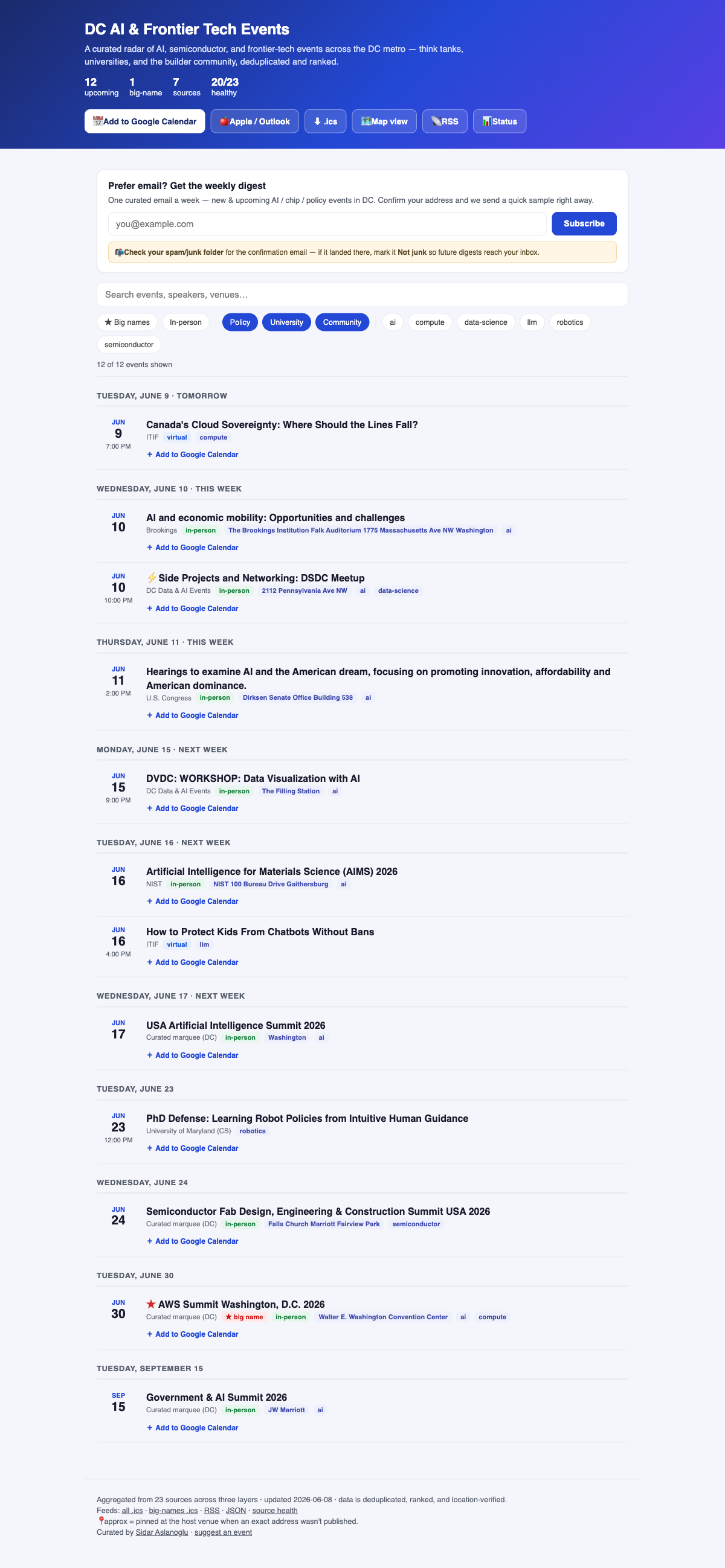
## 为什么需要三个层级
特区标志性的 AI/芯片活动大多**不**在社区日历上。该聚合器会提取所有三个层级的数据,从而确保不会错过最重要的活动:
| 层级 | 内容 | 接入的数据源 |
|------:|------|---------------|
| **1 — 构建者/社区** | 原生 iCal 社区日历 | Luma: DC Data & AI, DC Tech Events, DC Tech & Venture, AI Collective DC, global AI |
| **2 — 政策 / 知名机构** | 智库(HTML 抓取) | **CSET** (Georgetown), **CSIS** |
| **3 — 大学** | 校园活动日历(iCal) | **GWU** (Localist) |
空数据或获取失败的数据源会被**隔离并记录日志,绝不伪造**(例如,404 或空订阅源会被报告,而不是被静默丢弃)。
## Pipeline
```
fetch (per-source adapter) → normalize → dedupe → filter → rank → store → emit
```
- **fetch** — `aggregator/fetchers/` 适配器:`luma`/`ics` (httpx + icalendar),`cset` (curl_cffi 浏览器 TLS 模拟 + selectolax),`csis` (httpx + selectolax)。每个适配器都会返回已标准化的 `Event`。
- **normalize** — 统一 schema (`aggregator/models.Event`):id、title、start/end/tz、venue/address、lat/lng (GEO)、organizer、speakers、source、source_url、topics、is_big_name、raw。
- **dedupe** — 精确的 UID 去重(同一活动的多处列出)+ 基于日期范围内的模糊标题去重 (`difflib`)。
- **filter** — 仅当满足 `(DC 都会区 OR 来自 DC 策划数据源的虚拟活动) AND (主题相关 OR 知名机构)` 时保留。**对于线下活动,GEO 是权威判断标准**(如果坐标确实不在 DC,即使文本中偶然出现了 "VA" 或 "Washington" 也会被排除)。从配置的观察名单中设置 `is_big_name`。
- **rank** — `score = 主题强度 + 知名机构 + 即将到来 + DC 接近度 (haversine)`。
- **store** — 幂等的 SQLite upsert(支持 Postgres 的接口);永远不会因基础设施问题而被阻塞。
- **emit** — 参见 Outputs。
## Outputs(输出至 `out/` 目录)
| 文件 | 内容 |
|------|------|
| `events.ics` / `feed.xml` | 完整的去重 + 过滤集合 (iCalendar / RSS 2.0) |
| `events-upcoming.ics` / `feed-upcoming.xml` | 开始时间 ≥ 今天的活动 |
| `feed-top.xml` | 按相关性排名的前 25 名即将到来的活动 |
| `events-big-names.ics` / `feed-big-names.xml` | 仅限观察名单的变体 |
| `events.json` | 机器可读的导出数据(包含 `layer`、`score`) |
| `map.html` | 包含所有 GEO 活动的独立 Leaflet 地图(按层级 / 知名机构进行颜色编码) |
| `digest.md` | 排名后的每周摘要(邮件发送系统的基础) |
## 安装与运行
```
pip install -r requirements.txt
python -m aggregator # writes feeds to ./out, db at ./data/events.db
python -m aggregator --out site --db /var/lib/dcfe.db
python -m aggregator --today 2026-06-01 # override the upcoming/ranking window
```
需要 Python 3.11+。Postgres 是可选的(`DATABASE_URL`);它会自动回退到 SQLite,以确保运行永远不会因基础设施问题而被阻塞。可重复运行且幂等(每次运行都会重新获取并 upsert;订阅源反映最新抓取的数据,SQLite 存储则是持久化的归档)。
## 测试
```
python -m pytest tests/ -q # offline, deterministic (parsers / dedupe / filter / rank / emit / digest)
```
## 配置
数据源、主题关键词集、知名机构观察名单以及 DC 边界框 / 文本匹配器全都位于 [`aggregator/config.py`](aggregator/config.py) 中。只需一行代码即可添加 Luma 日历或任何 iCal 订阅源;将智库抓取器添加为一个新的 `fetchers/.py` 适配器,并在 `fetchers/__init__.py` 中注册。
## 项目布局
```
aggregator/
config.py sources, watchlists, topic + DC matchers
models.py the normalized Event schema
fetchers/ ics, luma, cset, csis adapters + dispatcher
normalize.py iCal VEVENT -> Event (+ topic detection)
dedupe.py exact-UID + fuzzy dedupe
filter.py DC + topic + big-name relevance
rank.py relevance scoring
storage.py idempotent SQLite store
emit.py ICS / RSS / JSON / map writers
digest.py ranked markdown digest
pipeline.py orchestration + concrete-count logging
tests/ offline unit tests
```
标签:Python, URL抓取, 信息聚合, 前沿科技, 数据处理流水线, 数据抓取, 无后门, 日程管理, 运行时操纵, 逆向工具