nagyonmarci/ossf-scout
GitHub: nagyonmarci/ossf-scout
ossf-scout:AI赋能的GitHub仓库安全审计工具
Stars: 0 | Forks: 0
# ossf-scout
[](go.mod)
[](LICENSE)
[](https://securityscorecards.dev/viewer/?uri=github.com/nagyonmarci/ossf-scout)
[](https://www.bestpractices.dev/projects/13066)
发现 GitHub 仓库中安全实践最薄弱的地方——以及一个精心制作的 PR 可以产生最大影响的地方。
在 GitHub 上搜索流行的仓库,查询每个仓库的 [OpenSSF Scorecard](https://scorecard.dev/) API,并显示缺少关键安全实践的项目——没有 CI 测试、没有 SAST、没有分支保护等。
作为 **CLI 工具** 或带有浏览器 UI 的 **web 服务器**,提供扫描历史、计划审计、修复跟踪和投资组合视图。
## 如何比较
大多数 OpenSSF Scorecard 工具回答的是 *"这个仓库有多安全?"* 或 *"我的组织趋势如何?"*。 ossf-scout 提出相反的问题:**目前哪些流行的仓库最薄弱,这样我知道我的贡献在哪里最有效?**
| 工具 | 重点关注 | ossf-scout 的不同之处 |
|------|-------|--------------------------|
| [`ossf/scorecard`](https://github.com/ossf/scorecard) | 分数引擎 + API | ossf-scout 消费 API 并在顶部添加 **发现/搜索层** |
| [`scorecard-visualizer`](https://github.com/ossf/scorecard-visualizer) | 一个仓库分数的漂亮视图 | ossf-scout 按弱点对 **多个** 仓库进行排名,而不是一次一个 |
| [`scorecard-monitor`](https://github.com/ossf/scorecard-monitor) | 跟踪 **您自己的** 组织的分数变化 | ossf-scout 找到 **其他人的** 流行但薄弱的仓库来贡献 |
| [deps.dev](https://deps.dev) / [Socket](https://socket.dev) | 包/依赖项 (SCA) 安全 | ossf-scout 查看 **仓库级** 的安全状况,而不是包 |
该细分市场:**GitHub 搜索 + Scorecard 过滤器以显示流行但薄弱的仓库**,以及一个 **AI 驱动的 DevSecOps 审计/修复工作区**——所有这些都在一个自包含的二进制文件中。
## 功能
### 发现与 Scorecard 扫描
- **GitHub 搜索 + OpenSSF Scorecard 发现** — 对分数低于您阈值的流行仓库进行排名
- **Scorecard API + CLI 后备** — 查询 `api.securityscorecards.dev`;对于尚未索引的仓库,可选地回退到本地的 `scorecard` 二进制文件
- **单仓库模式** — 直接通过 `owner/repo` 对任何公共仓库进行评分,而无需运行 GitHub 搜索查询
- **GitHub Trending 扫描器** — 抓取按语言/时间窗口趋势的仓库,并针对 OpenSSF 数据进行评分
- **组织扫描队列** — 列出 GitHub 组织的公共仓库,过滤分支/存档仓库/最小星级,并将选定的仓库排队进行审计
- **Open 问题数量** — 通过 GitHub 搜索 API 丰富扫描行,而无需额外的令牌范围
- **灵活的过滤器** — 语言、主题、关键词、推送日期后、最小星级、最大 Scorecard 分数、最小维护分数和突出显示的检查
- **快速预设** — DevSecOps 机会、AI/LLM、MCP/代理、云原生和安全工具
### Web 工作区
- **浏览器 UI** — 扫描表单、扫描历史、结果详情、可排序/可过滤的结果、可调整大小的列、粘性标题和 Scorecard 检查文档链接
- **持久的 SQLite 历史** — 扫描、结果、审计、审计上下文、计划、问题/PR 摘要、修复项和趋势数据在重启后仍然存在
- **投资组合仪表板** — 聚合最新的分数、星级、弱点检查、审计次数、提供者、语言和分数趋势线
- **分数趋势 API/UI** — 跟踪每个仓库的 Scorecard 分数和星级历史记录
- **修复板** — 从审计报告中提取发现,创建修复卡,并跟踪状态、严重性、备注、截止日期和解决方案;卡片标题直接链接到源审计
- **计划** — 在可配置的时间间隔内运行重复的审计,启用/禁用作业,立即触发,并将运行约束到 UTC 时间窗口
- **自动检测的审计计划** — 为反复出现薄弱或已被审计的仓库建议计划
- **问题/PR 智能化** — 缓存仓库的安全相关开放/关闭问题和 PR 摘要;`?refresh=true` 强制实时重新获取
- **通知** — 扫描完成后应用程序内托盘和浏览器通知 API;审计完成后可选的外部 webhook (`NOTIFY_WEBHOOK_URL`)
- **Authentik 兼容的访问控制** — 可选的前向身份验证模式,带有读取/写入/管理员组检查
### DevSecOps 审计
- **静态快照模式** — 无需 AI 密钥即可免费运行,并返回收集的证据作为结构化 Markdown 报告
- **AI 报告生成** — 支持 Anthropic、OpenAI、Gemini、本地/远程 Ollama 模型
- **分割生成** — 允许更便宜/更快的模型在更强的最终模型编写报告之前总结证据部分
- **保存的证据上下文** — 存储紧凑的 Markdown/JSON 上下文,以便以后可以使用另一个提供者或模型重新生成报告
- **上下文缓存** — 当仓库 HEAD SHA 没有更改时,重用最近的审计上下文
- **自动上下文压缩** — 如果提供者拒绝提示作为太大(每分钟令牌限制或上下文窗口超出),则自动使用压缩的上下文重试;适用于所有提供者(Anthropic、OpenAI、Gemini、Ollama)
- **跳过秘密选项** — 当速度很重要时,跳过较慢的 `gitleaks`/`trufflehog` 过程
- **审计比较** — 从同一保存的上下文中生成两个报告,并并排比较提供者/模型
- **供应链图** — 可视化 GitHub Actions 锚定建议和来自保存审计上下文的未解决操作引用
- **导出格式** — 下载 Markdown 报告、AI 上下文 Markdown、完整的 JSON 导出、适用于 GitHub Code Scanning 的 SARIF、格式化的 **PDF**(纯 Go 渲染器,无外部依赖)
- **推理模型输出清理** — 在保存报告之前删除推理模型(DeepSeek-R1、QwQ 等)发出的 `… ` 块
- **基线声明验证** — 在生成后,每个具体的声明(提交/锚定 SHA、`file:line`、`#PR`、CVE、`pkg@version`、工作流程文件、CVSS 带向量)都会与收集的证据和 CVSS 基线分数进行核对;不可验证的声明列在附录中,报告被标记为 **草稿**
- **成本跟踪和限制** — 记录输入/输出令牌,估计每个模型的成本,汇总 30 天支出,并可以拒绝超过 `MAX_AUDIT_COST_USD` 的审计
- **GitHub webhook 审计** — 签名的 GitHub `pull_request`/`push` webhook 可以在安全敏感文件更改时自动运行免费的静态审计
### 打包
- **自包含的二进制文件** — 通过 `//go:embed` 嵌入 React 前端,SQLite 通过纯 Go 驱动
- **带有捆绑工具的 Docker 图像** — 包含 `scorecard`、`gitleaks`、`actionlint`、`osv-scanner`、`trivy`、`helm`、`zizmor`、`kube-linter`、`trufflehog`、`semgrep`、Node/npm 和 `pnpm`
- **离线友好的 Ollama 配置文件** — Docker Compose 可以运行 Ollama 侧边车以进行本地 AI 生成
## 截图
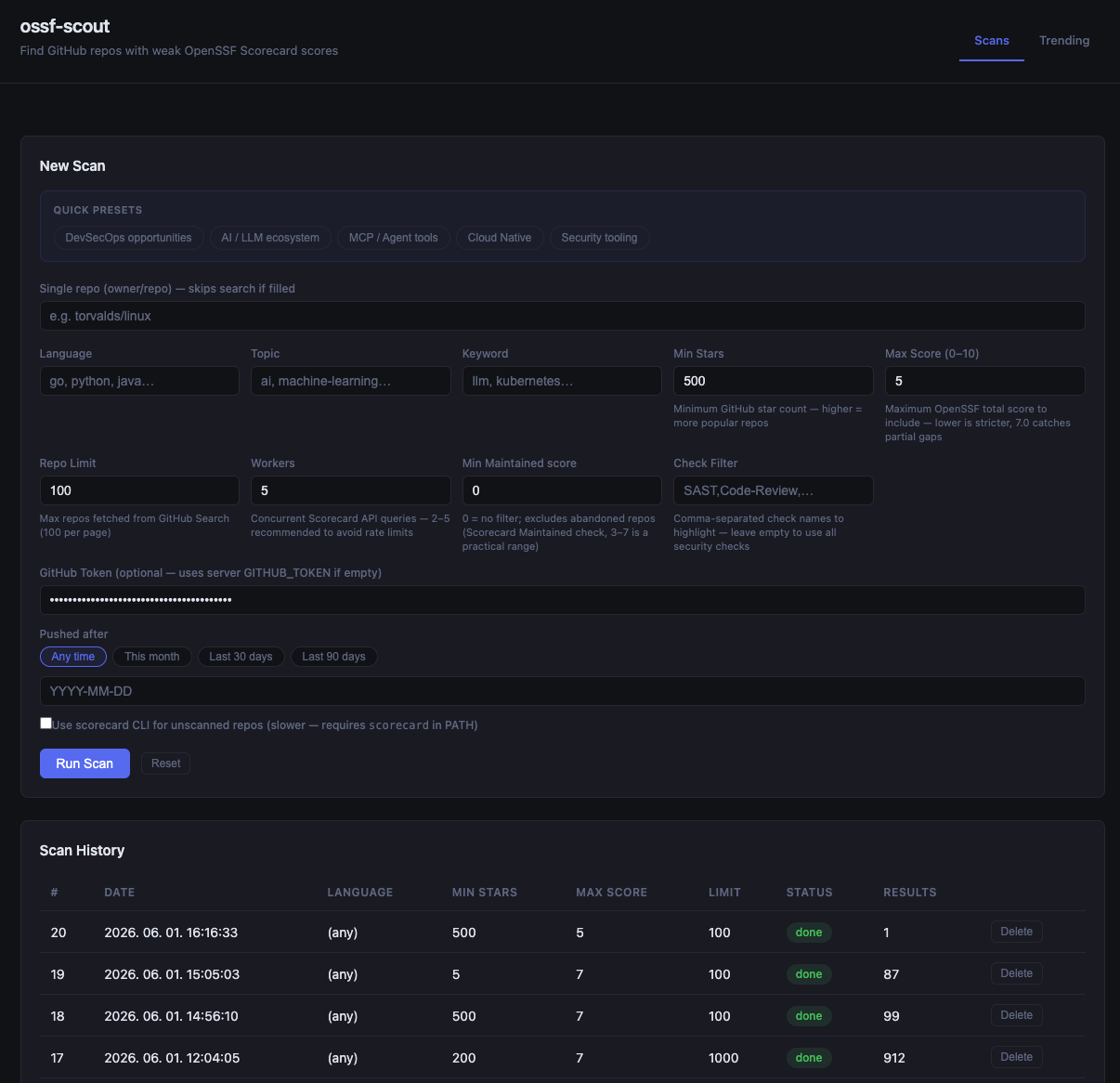
**扫描配置和历史记录**
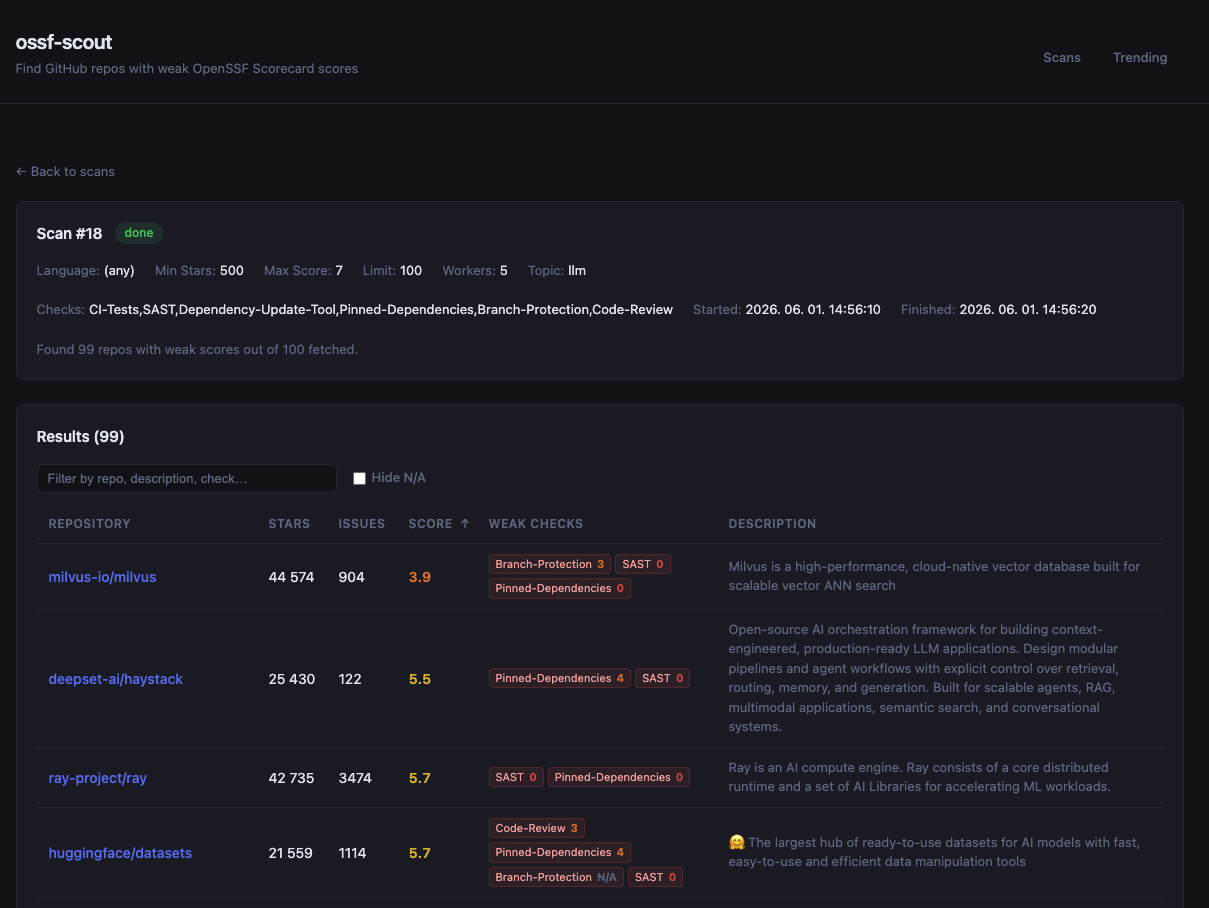
**扫描结果——分数较低的仓库**
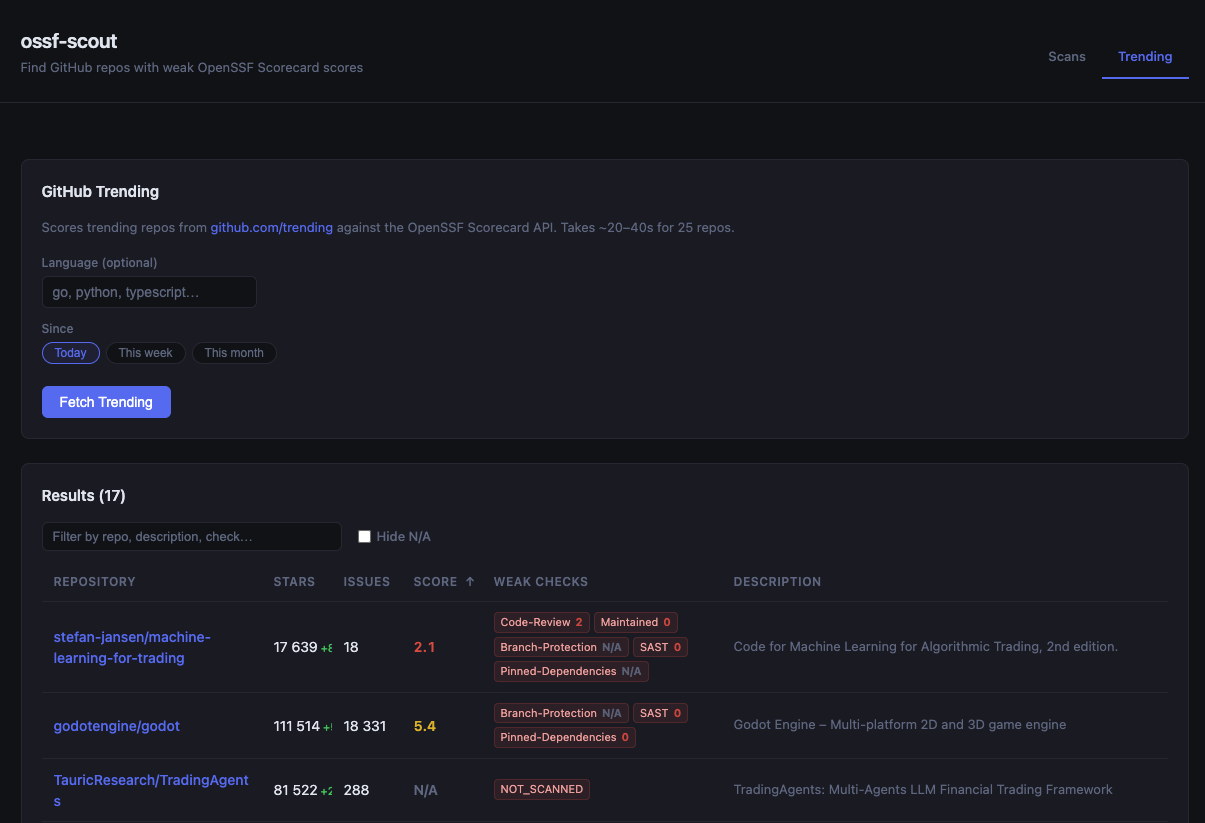
**GitHub Trending 与 Scorecard API 的比较**
## 快速入门
### CLI
```
export GITHUB_TOKEN=ghp_...
go run . -lang go -min-stars 1000 -max-score 5 -limit 50
```
### Web 服务器
```
go run . -serve
# 打开 http://localhost:7878
```
### Docker
```
GITHUB_TOKEN=ghp_... docker compose up --build
# 打开 http://localhost:7878
```
扫描历史记录存储在 `./data/ossf-scout.db` 中,并在重启后保持持久。
### 审计选项卡
在 web UI 中打开 **审计** 选项卡:
```
go run . -serve
# 导航至 http://localhost:7878 → 审计标签
```
输入 `owner/repo`(例如 `directus/directus`),选择提供者,然后单击 **运行审计**:
| 提供者 | 成本 | 设置 |
|----------|------|-------|
| **静态快照** | 免费 | 无需密钥——返回结构化原始数据 |
| **Anthropic** | 付费 | 通过 UI 或 `ANTHROPIC_API_KEY` 提供的 API 密钥;模型:Opus 4.8、Sonnet 4.6、Haiku 4.5、Opus 4.7、Opus 4.6、Sonnet 4.5、Opus 4.5 |
| **OpenAI** | 付费 | 通过 UI 或 `OPENAI_API_KEY` 提供的 API 密钥;模型:GPT-5.5、GPT-5.4、GPT-5.4 mini、GPT-4.1 family、GPT-4o family、o-series (o1/o3/o4-mini) |
| **Gemini** | 付费 | 通过 UI 或 `GEMINI_API_KEY` 提供的 API 密钥;模型:Gemini 3.5 Flash、3.1 Flash Lite、2.5 Pro/Flash/Flash-Lite、2.0 Flash、1.5 Pro/Flash |
| **Ollama** | 免费/本地 | 服务器上的 `OLLAMA_BASE_URL`;在 UI 中选择的模型名称 |
每次审计后,在 UI 中都会显示大约每运行一次的成本,基于记录的输入/输出令牌和配置的模型价格表。静态快照和 Ollama 运行被视为免费。
工具将 **Markdown 上下文** 发送到 AI,而不是原始 JSON——Zizmor SARIF 输出(可能超过 40,000 行)被替换为紧凑的发现表,与 JSON 方法相比,输入令牌减少了 ~90%。AI 路径使用此格式进行单阶段生成、分割部分分析、分割合成和从保存的上下文中重新生成。
在 UI 中启用 **分割生成**,以便分析模型首先总结每个证据部分;然后选择的最终模型合成报告。对于大型单体仓库,建议使用分割模式,因为按部分分析可以提高发现质量。分割模式目前为 Anthropic 和 Ollama 实现。
**Ollama 设置:**
```
ollama serve
ollama pull llama3.2 # or qwen2.5, deepseek-r1:8b, etc.
```
对于 Ollama,在服务器上设置 `OLLAMA_BASE_URL`。当通过 Docker 运行时,默认值(`http://host.docker.internal:11434`)在 `docker-compose.yml` 中预先配置;对于本地使用,将其设置为 `http://localhost:11434`。如果模型的上下文窗口太小,则工具会自动使用压缩的上下文重试(详细工具输出被截断)。
对于离线/本地配置文件:
```
OLLAMA_BASE_URL=http://ollama:11434 docker compose --profile offline up --build
```
Markdown 报告在完成后出现在浏览器中(AI 生成大约需要 1-3 分钟,快照大约需要 30 秒),可以下载为 `.md` 文件。如果 AI 生成失败,则将静态快照保存为后备——详细页面上的 **使用 AI 运行** 按钮允许您使用不同的提供者重新运行相同的保存上下文。
每个审计(包括静态快照)都有一个可用的 **下载 AI 上下文** 按钮,一旦已克隆和分析仓库。它下载将发送到 AI 的紧凑 Markdown——手动粘贴到任何 LLM 中或检查收集的确切证据非常有用。
审计详细页面公开了 GitHub Actions 锚定、JSON 导出、SARIF 导出、PDF 下载和将报告发现转换为可跟踪修复项的修复提取操作。
**它收集的内容**
| 类别 | 检查 |
|------|--------|
| CI/CD | 未锚定的 GitHub Actions、`zizmor` 工作流程分析、`actionlint` 工作流程检查、工作流程文件列表 |
| 代码 | `eval()`、`Math.random()`、原始 SQL、`X-Powered-By`、硬编码的秘密、弱加密、`process.exit`/`os.Exit`、SQL 注入 (`knex.raw`/`whereRaw`)、SSRF (`fetch`/`axios`/`got`)、路径遍历、XXE、反序列化、速率限制、CORS 配置、Semgrep 自动发现 |
| 关键文件 | 入口点(前 150 行)、身份验证中间件、权限系统、安全配置(`helmet`/`cors`/`session`)、启动验证检查、`CODEOWNERS` 文件 |
| 基础设施 | `helm lint`、Helm 密钥模板 + 值、`Dockerfile` |
| 依赖项 | `pnpm audit` / `npm audit` / `yarn audit` JSON、工作区 `overrides` |
| Git 历史 | 最后 30 个提交、过去 10 个提交中更改的文件 |
| GitHub API | 开放问题(最多 50 个)、 PR(最多 20 个)、秘密扫描警报、分支保护规则、Dependabot 警报(需要 `security_events` 范围),发布历史 |
| 秘密 | `gitleaks`、`trufflehog`、私有密钥头、`.env` 文件内容、AWS/JWT/GH 正则表达式模式 |
| IaC | Terraform 文件列表、`trivy config`、`osv-scanner`、Kubernetes 清单列表、`kube-linter` |
| Policy as Code | OPA `.rego` 文件、Kyverno `ClusterPolicy`/`Policy` YAML、Falco 规则检测 |
| SLSA / 供应链 | 原因证明 / SBOM 文件、cosign 密钥、SLSA GitHub Generator 工作流程使用、已签名提交检查 |
所有工具都 **包含在 Docker 图像中**(amd64 + arm64)——无需单独安装。
**报告结构**
生成的 Markdown 文档遵循固定的 17 个部分结构:
1. 元数据表——日期、仓库、提交、审计员、状态
2. 执行摘要——3-5 句非技术概述,供经理和 CISO 阅读使用
3. 范围——检查了什么(文件、工具、GitHub API 调用)
4. 方法——使用的工具、静态与动态的区别、已知限制
5. 安全优势——正确实施的控件及其证据引用
6. 发现摘要——表:ID · 优先级(P0–P3)· 严重性 · 标题 · OWASP 2021 · 状态
7. 安全状况摘要——
标签:AI 辅助, CVSS, DevSecOps, EVTX分析, GitHub 安全审计, Go 语言, Web 服务器, 上游代理, 代码审查, 安全修复跟踪, 安全发现, 安全排名, 安全最佳实践, 安全比较, 安全漏洞, 安全评分, 安全评分卡, 安全贡献, 安全趋势分析, 日志审计, 请求拦截