thiagofsdata-collab/wyllo-fraud-pipeline
GitHub: thiagofsdata-collab/wyllo-fraud-pipeline
该 pipeline 将电商原始交易数据转化为退货欺诈检测所需的 point-in-time 特征存储,采用 Medallion 分层架构并配备完整的编排与质量测试体系。
Stars: 0 | Forks: 0
# Wyllo 退货欺诈 Pipeline





## 简介
退货欺诈每年给电商造成约 1000 亿美元的损失。**2% 的客户导致了 20%
的欺诈性退货**(NRF)。最困难的部分不在于拦截,而在于对**行为进行细分**,从而确保合法的偶尔退货者不被拦截。该 Pipeline 生成了实现该细分的 feature store。
**作为一名 Data Engineer:** 我们不负责训练模型。我们交付的是一张能让决策变得显而易见的表。
```
┌───────────────────────────────────┐
Olist CSVs → S3 → Bronze → Silver → Gold │ fct_customer_return_risk_features │
│ PK: (customer, snapshot_date) │
└─────────┬─────────────────────────┘
│
┌────────────────────┼────────────────────┐
▼ ▼ ▼
Data Scientist Fraud Analyst Pipeline Health
(trains models) (writes rules) (Streamlit + Plotly)
```
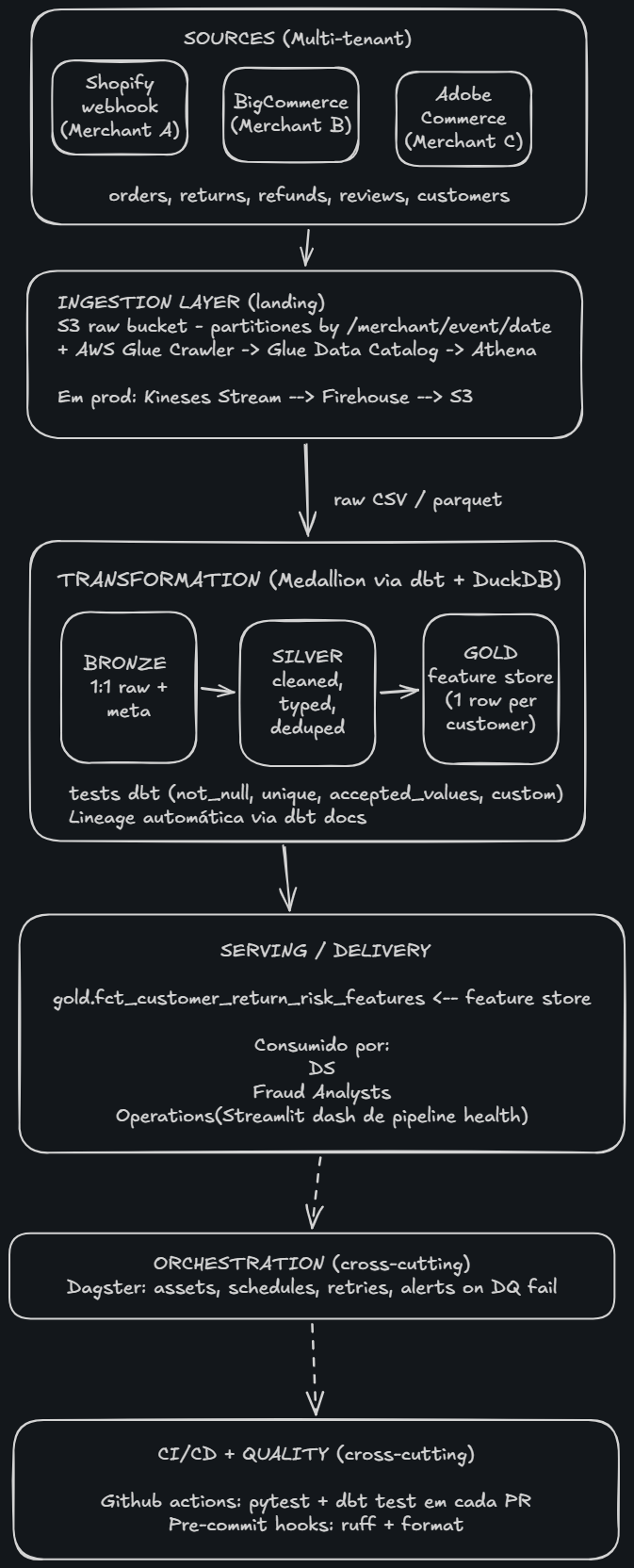
## 架构
标签:Dagster, dbt, DuckDB, Kubernetes, 数据工程, 数据管道, 欺诈检测, 特征工程, 软件工程, 逆向工具