justkelvin/rag-phishing-incident-response
GitHub: justkelvin/rag-phishing-incident-response
基于检索增强生成技术的钓鱼事件响应指导系统,帮助中小型组织从权威安全文档中获取可溯源的应急处置建议。
Stars: 1 | Forks: 0
# RAG 钓鱼事件响应指南
这是一个检索增强生成(RAG)系统,旨在利用基于源头验证的网络安全指南,帮助中小型组织解答实际的钓鱼事件响应问题。
该项目构建了一个经过精选的知识库,将权威的事件响应文档进行分块和嵌入,使用 ChromaDB 检索相关上下文,并利用 Google GenAI/Gemma 模型生成简洁的实践指南。
## 项目概览
| 领域 | 详情 |
| --- | --- |
| 领域 | 网络安全 |
| 用例 | 中小型组织的钓鱼事件响应 |
| 知识库 | 10 份精选的政府和供应商指南文档 |
| 文档数量 | 总计 20,007 个源词 |
| 分块 | 277 个感知段落的数据块 |
| 嵌入模型 | `sentence-transformers/all-MiniLM-L6-v2` |
| 向量存储 | ChromaDB |
| 检索方法 | 稠密向量相似度搜索 |
| 检索到的上下文 | 每次查询提取前 3 个数据块 |
| 生成器 | 通过 Google AI Studio / Gemini API 使用 `models/gemma-4-26b-a4b-it` |
| 评估集 | 10 个钓鱼响应查询 |
## 系统功能
RAG pipeline 可以解答以下问题:
- 当员工点击了钓鱼链接后,我们该怎么办?
- 发生钓鱼邮件导致凭据被盗后,小公司应如何应对?
- 当 Microsoft 365 邮箱被攻破时,管理员应该怎么做?
- 钓鱼事件响应手册应包含哪些内容?
对于每次查询,系统会:
1. 嵌入实践者提出的问题。
2. 从 ChromaDB 检索最相关的源数据块。
3. 构建严格的基于源验证的 prompt。
4. 利用检索到的来源标题作为引用,生成操作指南。
5. 使用无参考的 RAG 评估代理指标对答案进行评分。
## 架构
```
Curated source documents
|
v
Document loading and cleaning
|
v
Paragraph-aware chunking
|
v
MiniLM embeddings
|
v
ChromaDB vector store
|
v
Top-k retrieval
|
v
Source-grounded prompt
|
v
Google GenAI / Gemma generation
|
v
Heuristic RAG evaluation and reporting
```
## 仓库结构
```
.
|-- data/
| |-- raw/sources/ # Curated source text files
| |-- processed/ # Cleaned documents and generated chunks
| |-- evaluation/ # Evaluation query set
| `-- metadata/ # Source metadata and project config
|-- notebooks/
| `-- 01_rag_phishing_incident_response.ipynb
|-- outputs/
| |-- retrieval/ # Retrieved chunks per query
| |-- generation/ # Generated answers and full RAG results
| |-- evaluation/ # Heuristic evaluation scores
| |-- tables/ # Report-ready tables
| `-- figures/ # Report-ready plots
|-- report/
| |-- figures/ # Figures copied for report writing
| |-- tables/ # Tables copied for report writing
| `-- assignment3_report.pdf
|-- slides/ # Presentation deck
|-- src/ # Reusable pipeline modules
|-- video/ # Demo video and transcript
|-- requirements.txt
`-- README.md
```
`vectorstore/chroma/` 由 notebook 在本地生成,并被 Git 忽略。
## 源语料库
该知识库汇集了来自 NIST、CISA、NSA、FBI、MS-ISAC、NCSC、Microsoft、Google 和 FTC 的网络安全指南。
| ID | 来源 | 机构 |
| --- | --- | --- |
| `src001` | Incident Response Recommendations and Considerations for Cybersecurity Risk Management: A CSF 2.0 Community Profile | NIST |
| `src002` | Phishing Guidance: Stopping the Attack Cycle at Phase One | CISA, NSA, FBI, MS-ISAC |
| `src003` | Recognize and Report Phishing | CISA |
| `src004` | Small organisations guide to cyber security | NCSC |
| `src005` | Plan: Your cyber incident response processes | NCSC |
| `src006` | Respond to a compromised cloud email account | Microsoft |
| `src007` | Incident response overview | Microsoft |
| `src008` | Identify and secure compromised accounts | Google |
| `src009` | Protect your Google Cloud resources from compromised credentials | Google |
| `src010` | Cybersecurity for Small Business | FTC |
完整的来源 URL 和元数据存储在 [`data/metadata/sources_metadata.csv`](data/metadata/sources_metadata.csv) 中。
## 核心模块
| 模块 | 用途 |
| --- | --- |
| [`src/config.py`](src/config.py) | 用于模型、分块、检索和评估的中心项目常量 |
| [`src/document_loader.py`](src/document_loader.py) | 加载源元数据和原始源文件 |
| [`src/preprocessing.py`](src/preprocessing.py) | 清理文本,创建重叠的数据块,并分配确定性的 chunk ID |
| [`src/embeddings.py`](src/embeddings.py) | 加载 sentence-transformer 模型并创建归一化的嵌入 |
| [`src/retriever.py`](src/retriever.py) | 从 ChromaDB 检索前 k 个数据块 |
| [`src/generator.py`](src/generator.py) | 构建基于源验证的 prompt 并调用 Google GenAI |
| [`src/evaluator.py`](src/evaluator.py) | 计算上下文相关性、答案相关性、忠实度和引用覆盖率等代理指标 |
| [`src/utils.py`](src/utils.py) | 共享的文件系统和 JSON 辅助工具 |
## 配置
### 1. 创建虚拟环境
```
python -m venv .venv
source .venv/bin/activate
```
在 Windows PowerShell 中:
```
python -m venv .venv
.\.venv\Scripts\Activate.ps1
```
### 2. 安装依赖
```
pip install -r requirements.txt
```
### 3. 配置环境变量
从示例文件创建 `.env`:
```
cp .env.example .env
```
然后添加你的 Google AI Studio 密钥:
```
GOOGLE_API_KEY=your_google_ai_studio_key_here
OPENAI_API_KEY=your_openai_key_here
```
生成答案需要 `GOOGLE_API_KEY`。包含的 `OPENAI_API_KEY` 是一个可选的占位符,默认的 pipeline 并不需要它。
## 运行项目
从上到下打开并运行 notebook:
```
notebooks/01_rag_phishing_incident_response.ipynb
```
该 notebook 将执行完整的工作流程:
1. 环境与 API 设置
2. 导出项目配置
3. 加载来源与文本清理
4. 生成数据块
5. 嵌入与 ChromaDB 索引
6. 加载评估查询
7. 检索测试
8. RAG 答案生成
9. 启发式评估
10. 错误分析、绘图与报告导出
## 主要输出
| 输出 | 描述 |
| --- | --- |
| [`data/processed/documents_cleaned.csv`](data/processed/documents_cleaned.csv) | 清理后的文档级语料库 |
| [`data/processed/chunks.csv`](data/processed/chunks.csv) | 用于检索的数据块级语料库 |
| [`outputs/retrieval/retrieved_chunks.csv`](outputs/retrieval/retrieved_chunks.csv) | 用于评估查询的检索数据块 |
| [`outputs/generation/generated_answers.csv`](outputs/generation/generated_answers.csv) | 仅包含生成的答案 |
| [`outputs/generation/rag_results_full.csv`](outputs/generation/rag_results_full.csv) | 查询、检索到的上下文、prompt、答案和元数据 |
| [`outputs/evaluation/heuristic_scores.csv`](outputs/evaluation/heuristic_scores.csv) | 每次查询的评估得分 |
| [`outputs/tables/results_summary.csv`](outputs/tables/results_summary.csv) | 简洁的结果表格 |
| [`outputs/tables/error_analysis_with_scores.csv`](outputs/tables/error_analysis_with_scores.csv) | 结合得分的错误分析 |
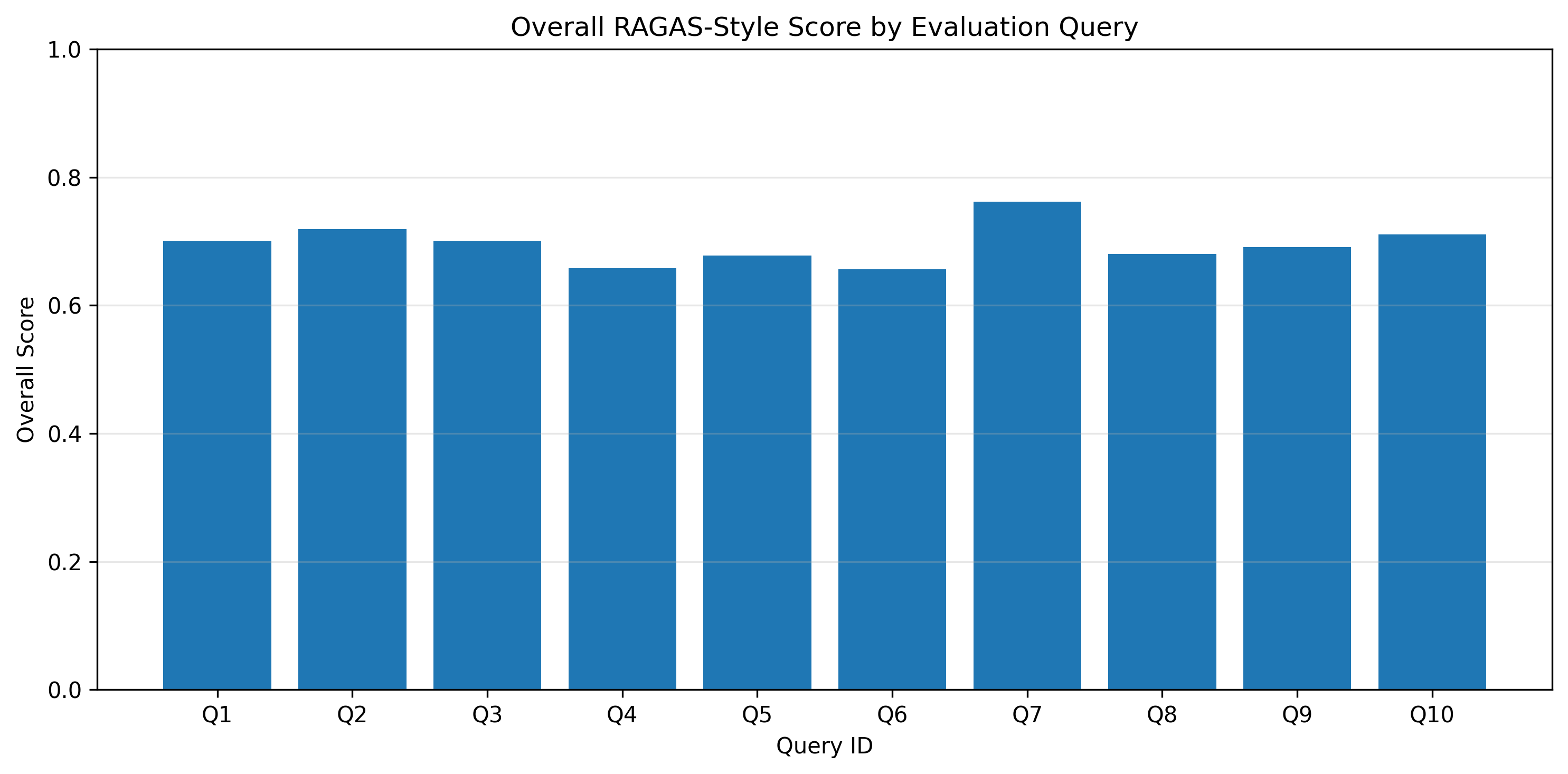
| [`outputs/figures/overall_score_by_query.png`](outputs/figures/overall_score_by_query.png) | 总体得分可视化 |
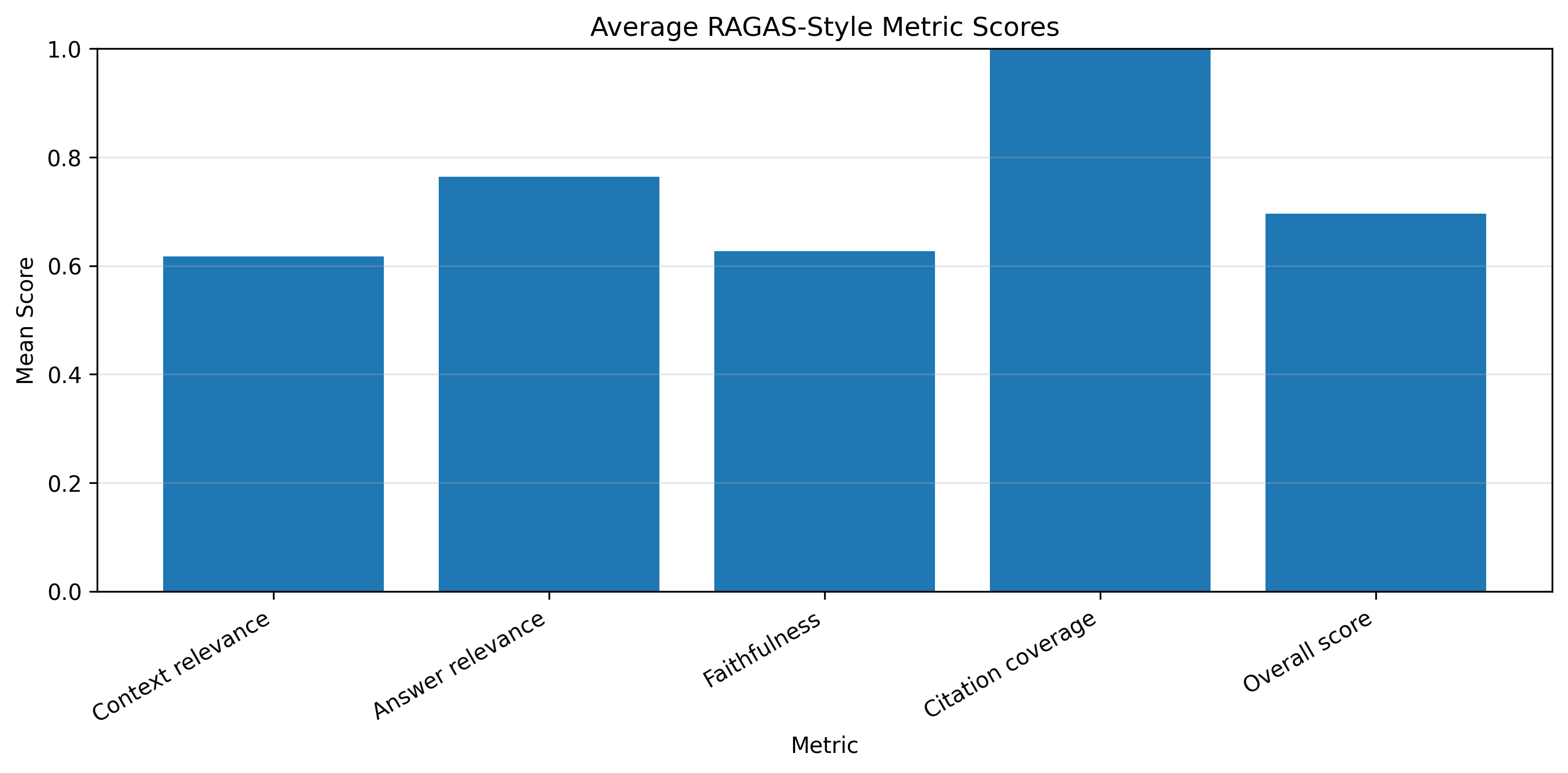
| [`outputs/figures/average_metric_scores.png`](outputs/figures/average_metric_scores.png) | 平均得分可视化 |
## 评估
由于该项目不包含人工编写的参考答案,因此评估使用 RAGAS 风格的无参考代理指标:
- **上下文相关性**:检索到的数据块与查询的匹配程度。
- **答案相关性**:生成的答案与查询在语义上的一致程度。
- **忠实度**:答案中的主张在检索到的上下文中的依据充分程度。
- **引用覆盖率**:生成的指南是否引用了检索到的来源标题。
- **总体得分**:跨评估维度的综合质量得分。
### 最终平均得分
| 指标 | 平均值 | 最小值 | 最大值 |
| --- | ---: | ---: | ---: |
| 上下文相关性 | 0.617 | 0.541 | 0.689 |
| 答案相关性 | 0.764 | 0.671 | 0.873 |
| 忠实度 | 0.627 | 0.568 | 0.740 |
| 引用覆盖率 | 1.000 | 1.000 | 1.000 |
| 总体得分 | 0.696 | 0.656 | 0.762 |
表现最好的查询:`Q7`
最弱的查询:`Q6`
## 可复现性说明
- 源语料库在 `data/raw/sources/` 中进行版本控制。
- 包含处理后的语料库和生成的输出,以供检查。
- 本地的 ChromaDB 目录是可复现的,并通过 `.gitignore` 刻意忽略。
- 由于托管模型和提供商侧的行为可能发生变化,生成结果可能会略有不同。
- Notebook 会在可用时选择具备生成能力的 Gemma 模型。
## 局限性
- 该系统是一个研究原型,不能替代专业的事件响应支持。
- 因为没有包含人工标记的黄金标准答案,所以评估是基于代理指标的。
- 语料库规模经过刻意精简,主要聚焦于钓鱼和账号被盗指南。
- 供应商特定的指南可能会过时,在实际操作前应进行更新。
- 生成的建议应根据组织的法律、监管和技术背景进行审查。
## 提交的产物
- 报告:[`report/assignment3_report.pdf`](report/assignment3_report.pdf)
- 幻灯片:[`slides/RAG System for Phishing Incident Response Guidance.pptx`](slides/RAG%20System%20for%20Phishing%20Incident%20Response%20Guidance.pptx)
- 演示视频:[`video/screen-2026-05-26_22-52-06.mp4`](video/screen-2026-05-26_22-52-06.mp4)
- 视频文字稿:[`video/video_transcipt.pdf`](video/video_transcipt.pdf)
## 许可证
本项目基于 [MIT 许可证](LICENSE) 发布。
本仓库包含学术/研究实现,以及对公开网络安全指南的精选引用。在生产环境中重用这些材料之前,请审查原始的来源条款和您所在组织的政策。
标签:DLL 劫持, RAG, 向量数据库, 大语言模型, 库, 应急响应, 网络安全, 逆向工具, 隐私保护