YanpengQi7/ai-reliability-copilot
GitHub: YanpengQi7/ai-reliability-copilot
一款将生产事故自动转化为结构化分析报告的 AI 可靠性助手,核心特色是内置量化驱动的提示词评估流水线。
Stars: 103 | Forks: 0
# AI Reliability Copilot
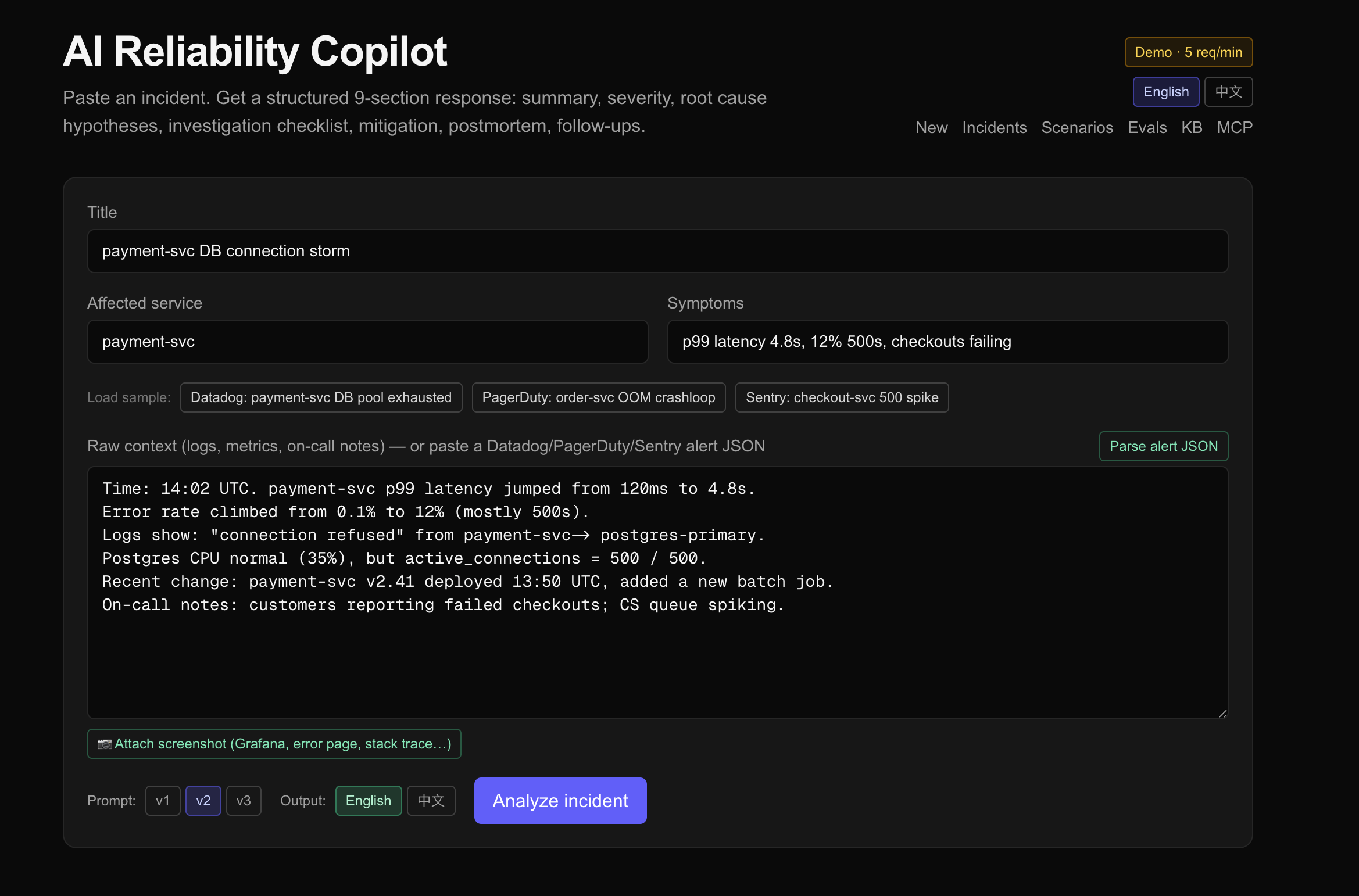
粘贴一个生产事故——日志、指标、on-call 笔记。Copilot 会以流式传输返回结构化的分析结果:严重程度、附带证据且按可能性排序的根因假设、可直接复制粘贴的排查清单、包含回滚步骤的缓解计划、面向客户的影响评估、复盘大纲,以及按优先级排列的跟进事项。
但它真正的核心不在于 prompt,而是**评估流水线**——一个包含 5 个维度的评分标准、一个包含 5 个场景的回归测试套件,以及一个对每次改动进行打分的 LLM-as-judge,从而让 prompt 的迭代过程有据可查,而非凭感觉。
**在线演示:** [ai-reliability-copilot.vercel.app](https://ai-reliability-copilot.vercel.app)
**📖 使用指南 (中文):** [USAGE.md](./USAGE.md) — 详细介绍了如何进行端到端的使用
**方法论深度剖析:** [EVALUATION.md](./EVALUATION.md)
## 架构
```
┌───────────────────┐ ┌───────────────────┐ ┌──────────────────┐
│ Browser (RSC) │◀────▶│ Next.js 16 App │◀────▶│ DeepSeek (AI SDK)│
│ experimental_ │ │ Router on Vercel │ │ generate/stream │
│ useObject hook │ │ (Fluid Compute) │ │ Object │
└───────────────────┘ └─────────┬─────────┘ └──────────────────┘
│
▼
┌───────────────────┐
│ Supabase (PG) │
│ incidents / │
│ analyses / │
│ scenarios / │
│ evaluations │
└───────────────────┘
```
- **Next.js 16** App Router,读多页面使用 RSC(事故列表/详情页,评估仪表盘);仅在需要时使用客户端组件(流式表单、复制按钮)
- **AI SDK** 使用 `streamObject` + Zod schema 以保证输出结构化
- **DeepSeek** 同时用于分析器和评判器(可在单个文件中替换提供商)
- **Supabase Postgres** 用于数据持久化;service-role client 仅限服务端使用
- **Vercel** 推送到 `main` 分支时自动部署
## 9 部分输出 schema
由 Zod 强制执行 ([`src/lib/schema.ts`](./src/lib/schema.ts)):
1. **摘要** + 严重程度徽标(含定量推理过程)
2. **严重程度** (SEV1/2/3) — 严格应用评分标准
3. **根因假设** (3–5 个,按可能性排序并附带引用证据)
4. **调查清单** (可直接复制粘贴的命令及其预期输出)
5. **缓解计划** (包含风险说明及每一步的强制回滚方案)
6. **客户影响** (面向外部)
7. **复盘草稿** (markdown 格式,所有 H2 部分按顺序排列)
8. **后续跟进** (P0–P2,关联到对应的 Owner 角色)
9. **严重程度推理** (引用所应用的评分标准规则)
## 量化的 Prompt 工程
每次 prompt 迭代都会在相同的 5 场景回归套件 × 2 种输出语言(en/zh)下进行追踪,并由 LLM 评判器根据 5 维度评分标准进行打分。
| 维度 | 衡量内容 |
|---|---|
| Specificity | 命令/指标/服务是否具体? |
| Safety | 每一项缓解措施是否都可逆?破坏性操作是否受限? |
| Actionability | on-call 人员是否能在 <5 分钟内无需进一步研究即可执行? |
| Domain correctness | SRE 机制是否正确?有无捏造的证据? |
| Completeness | 所有 9 个部分是否都有实质性内容填充? |
### 最新结果 (第 #3 次运行,每个单元重复 n=3 次,分析器和评判器均使用 deepseek-chat)
以 3 次重复后的 **mean ± std**(平均值 ± 标准差)呈现——因为这才是重点。平衡子集(4 个场景 × 所有 3 个版本均完成 × 2 种语言 × 3 次重复,n=24/版本):
| 版本 | 总体 (mean ± std) |
|---|---|
| **Prompt v1** (仅规则) | **4.62 ± 0.33** |
| **Prompt v2** (规则 + few-shot, 硬性限制) | **4.48 ± 0.24** |
| **Prompt v3** (限制 → 偏好 + 实质性指令) | **4.60 ± 0.26** |
| 对比组 | Δmean | 合并标准差 | 结论 |
|---|---:|---:|---|
| v1 − v2 | +0.13 | 0.29 | 在误差范围内 |
| v1 − v3 | +0.02 | 0.30 | 在误差范围内 |
| v2 − v3 | −0.12 | 0.25 | 在误差范围内 |
**真正的发现(也是作品集的核心要点):不同 prompt 版本之间的分数差异只是误差。** 单次运行的 #1 和 #2 产生了一个清晰的排名——v2 “退步”了 0.2,v3 又“恢复”到了榜首。而每个单元重复 3 次的运行 #3 显示,单元内的标准差 (0.2–0.46) *大于* 版本间的每一个差值 (0.02–0.13)。对于这 5 个场景和这个 1–5 分的评分标准,**这三个 prompt 在总体得分上不分伯仲。** 声称“v3 将质量从 4.36 提升到 4.52”其实是过度拟合了抽样误差——如果我没有增加重复次数,我完全可能会根据第 #2 次运行的结果得出这个结论。
**在误差范围之外依然成立的现象:** 两种一致的排序。(1) **v2 在每次运行中都是最弱的**——每一个差值都在误差范围内,但这种排序在 3 次独立运行中复现了,这足以说明“不要默认使用 v2。” (2) **中文得分在几乎所有对比单元中都低于英文**(en 4.64 ± 0.25 vs zh 4.49 ± 0.29)——这是数据集中重现性最强的效应,也是未来 prompt 优化信号最明确的方向。目前的默认选项是 **v3**——之所以选择它,是因为它在质量上与 v1 平手,且在双语场景下严格更易于维护(它的中文简明指令使得在所有场景下 v3·zh ≥ v2·zh),*而不是*因为它的得分更高。详见 [`notes/eval-run-3.md`](./notes/eval-run-3.md)。
完整的方法论(包括局限性和路线图)请参见 [EVALUATION.md](./EVALUATION.md)。
## 场景库
5 个精选的 SRE 场景涵盖了最常见的生产故障模式:
| 场景 | 类别 |
|---|---|
| Payment-svc 连接池耗尽 | Database |
| Order-svc 部署后 OOM 反复崩溃 | Deploy |
| Stripe API 超时级联导致结账中断 | Dependency |
| DNS 配置错误引发区域性 5xx 错误 | Network |
| 黑五缓存雪崩 | Capacity |
每个场景都提供了充足的上下文(指标、日志、部署历史、on-call 笔记)来区分不同的 prompt 版本。可在 `/scenarios` 浏览这些场景。
## 通过你自己的 Claude Code 使用(MCP server 模式)
本项目同时作为 **Web App 和 MCP server** 发布。高级用户可以将 MCP endpoint 添加到他们本地的 Claude Code 中,并使用自己的 Claude 订阅来驱动分析——平台支付 $0 的 LLM 成本,而用户能获得 Claude Opus 级别的质量。
```
claude mcp add --transport http ai-reliability https://ai-reliability-copilot.vercel.app/api/mcp
```
共暴露了 7 个工具:`search_kb`, `find_similar_incidents`, `list_scenarios`, `get_scenario`, `parse_alert_json`, `get_output_schema`, `save_incident_analysis`。完整模式请参见 [USAGE.md](./USAGE.md) 中的工作流 D-bis。
## 从终端使用 (CLI)
专为习惯在 Shell 中工作的 on-call 人员打造。直接将任何告警 JSON 或自由格式的笔记通过管道传入,读出结构化的分析结果——无需切换标签页,也无需复制粘贴到 Web 表单中。
```
npm i -g sre-copilot-cli # or: cd cli && npm link
pbpaste | sre analyze # macOS — paste a Datadog/PagerDuty alert from clipboard
sre analyze < alert.json # pipe a file
echo "checkout p99 8s" | sre analyze # free-form
sre analyze --json | jq # raw analysis JSON for scripting
sre analyze --no-wait # submit and exit, print URL only
sre analyze --open # also open the web view in browser
```
源码:[`cli/`](./cli)。零依赖,单文件 ESM,Node 20+。通过 webhook 所使用的相同解析器,自动识别 Datadog / PagerDuty / Sentry 的 payload 格式;如果都不匹配,则将标准输入视为原始上下文。默认指向托管实例;你也可以通过 `SRE_COPILOT_URL` 指向你自托管的实例。
**为什么在 $WORK 中 CLI 很重要:** 零基础设施审批。不需要安装 Slack App,不需要 PagerDuty 集成 token,也不需要提交 SecOps 工单——它只是从你笔记本发出的一次 HTTPS 调用。在任何新工作的第一天就能部署完毕。
## 知识库(内部 RAG)
让 AI 理解**你的公司**:将你的 runbook、postmortem 和服务目录放入 `sample-kb/`(或任何目录),然后运行 `npm run kb:ingest`。随后的每次分析都会自动检索出最相关的 top-5 分块,并将它们作为 `# Internal context` 注入到 prompt 中,这样 LLM 就能基于*你的*系统来生成答案,而不是提供通用的 SRE 建议。
- **存储:** `kb_documents`(每个文件一行,通过内容哈希去重)+ `kb_chunks`(具备段落感知的文本块,约 1500 字符,包含 150 字符的重叠)
- **Embeddings:** 设置了 `OPENAI_API_KEY` 时使用 OpenAI `text-embedding-3-small` (1536维);否则 **回退到 pg_trgm**
- **审计追踪:** `analysis_kb_chunks` 记录了哪些分块供给了哪次分析及其相似度得分。详情页会显示“📚 AI 使用了的内部文档”,并带有与 prompt 中内容相匹配的括号数字引用。
- **CLI:** `npm run kb:ingest -- ./docs/runbooks`(通过 SHA256 内容哈希实现幂等,若无更改则跳过)
- `sample-kb/` 中的**示例文档**展示了所需的格式——请将其替换为你自己的文档。
用于相似度检索的签名就是分块文本本身。服务目录片段、runbook 步骤和过往的 postmortem 都能被正确索引。
## 相似事故搜索
每个事故都会获得一个**签名**(标题 + 服务 + 症状 + 摘要 + 严重程度的拼接),并且在配置了 `OPENAI_API_KEY` 时,还会获得一个 **1536 维的 embedding**。详情页会显示按相似度排序的最多 5 个过往事故。
在运行时提供两种后端选择:
- **`pgvector` + HNSW + 余弦距离** — 语义匹配(首选)。使用 `text-embedding-3-small` 生成 embeddings($0.02/M tokens)。返回 `1 - cosine_distance > 0.4` 的匹配项。
- **`pg_trgm`** — 未配置 embedding 提供商时的词法回退方案。返回 trigram 相似度 > 0.15 的匹配项。
这种选择是自动的,并会在 UI 中显示(`semantic match (pgvector)` 或 `lexical match (pg_trgm)`)。日后迁移到 OpenAI 仅需改动一个环境变量;现有数据行可通过 `npm run backfill:similar` 进行回填。
该签名特意排除了 `raw_context`——因为日志和时间戳主导了该字段,从而会产生有干扰的匹配。
## 在本地运行
```
git clone https://github.com/YanpengQi7/ai-reliability-copilot
cd ai-reliability-copilot
npm install
# env: 创建 .env.local 并填入
# DEEPSEEK_API_KEY=
# NEXT_PUBLIC_SUPABASE_URL=
# NEXT_PUBLIC_SUPABASE_ANON_KEY=
# SUPABASE_SERVICE_ROLE_KEY=
# 公共部署还需要设置:
# WEBHOOK_SECRET=
# MCP_AUTH_TOKEN=
# DB: 在 Supabase SQL 编辑器中运行 supabase/schema.sql
# 该 schema 启用了 RLS,并仅向 service_role 授予 data/RPC 访问权限。
# 填充场景库
npm run seed:scenarios
# dev
npm run dev # → http://localhost:3000
# 运行 eval 批处理(写入到您的 Supabase)
npm run evals:run
```
Vercel 生产环境部署在缺失这些 token 时,会对 MCP 和 webhook 流量采取安全失败(fail closed)策略。仅在刻意进行公开部署时,才设置 `ALLOW_PUBLIC_MACHINE_API=true`。
## 已知局限性
- **内存级限流器** (`src/lib/rateLimit.ts`) — 在冷启动时会重置。生产环境的替代方案:Upstash Redis。
- **评判器 ≠ 事实真相** — 使用同系列模型来评判分析器。我曾猜测“存在约 10–20% 的乐观偏差”;随后我对其进行了测量。`npm run evals:crossjudge` 会保持每次分析不变,并使用独立的供应商(Claude Sonnet 4.6)对其重新打分。对 20 次分析的结果是:同系列评判器在总体得分上**高出 +0.24** (4.48 vs 4.24,约 5%——当初的猜测偏高了),在 `actionability`(可执行性)/`completeness`(完整性)上偏差最大(各为 −0.40),在 `safety`(安全性)上零偏差(90% 完全一致)。Pearson r 为 0.59,70% 的得分在 ±0.5 的范围内。结论是:偏差确实存在,但约为 5% 而非 10–20%,且是集中的而非均匀分布的。缓解措施依然是定期进行人工审查(参见 [EVALUATION.md](./EVALUATION.md))。
- **重复次数有限** — 默认的评估批次在每个测试单元中使用了 3 次重复,但这对于获得窄置信区间来说仍然太小。
- **5 个场景过于狭窄** — 真实的系统存在长尾效应。
## 技术栈
- Next.js 16 (App Router, RSC, Turbopack), TypeScript Tailwind v4
- Vercel AI SDK 6 (`streamObject`, `generateObject`, `experimental_useObject`)
- DeepSeek API (分析器 + 评判器)
- Supabase (Postgres, 服务端 service-role client)
- Zod (全面应用 schema — 数据库插入、LLM 输出、API 输入)
- react-markdown + `@tailwindcss/typography` 用于 postmortem 渲染
## License
MIT
本项目作为学习 AI 工程和评估方法论的副项目,历时 30 天完成开发。
标签:API集成, DeepSeek, LLM评估, Ollama, 可观测性, 熵值分析, 自动化攻击, 运维工具