SStevenB/cyberfusion-complete
GitHub: SStevenB/cyberfusion-complete
一个开源的威胁情报原型平台,通过多源安全数据标准化、关联分析和可解释评分,帮助用户理解和实践威胁优先级排序。
Stars: 0 | Forks: 0
# CyberFusion
这是我为了了解威胁情报平台实际工作原理而构建的一个副项目。它能摄入 CVE 数据、扫描结果、泄露导出数据和资产清单,进行标准化处理,运行关联规则,然后给出一个按优先级排序的待审查列表。思路是以更小规模实现类似 Tenable 或 Recorded Future 这类工具的功能,并且所有步骤都可解释,让你清楚看到某个条目为什么被标记。
前端是 React,后端是 FastAPI,底层跑着一个 Python 管道。生产环境单服务器,开发环境双服务器。
**在线演示:** https://SStevenB.github.io/cyberfusion-complete/(静态快照,实际管道数据)
## 实际功能
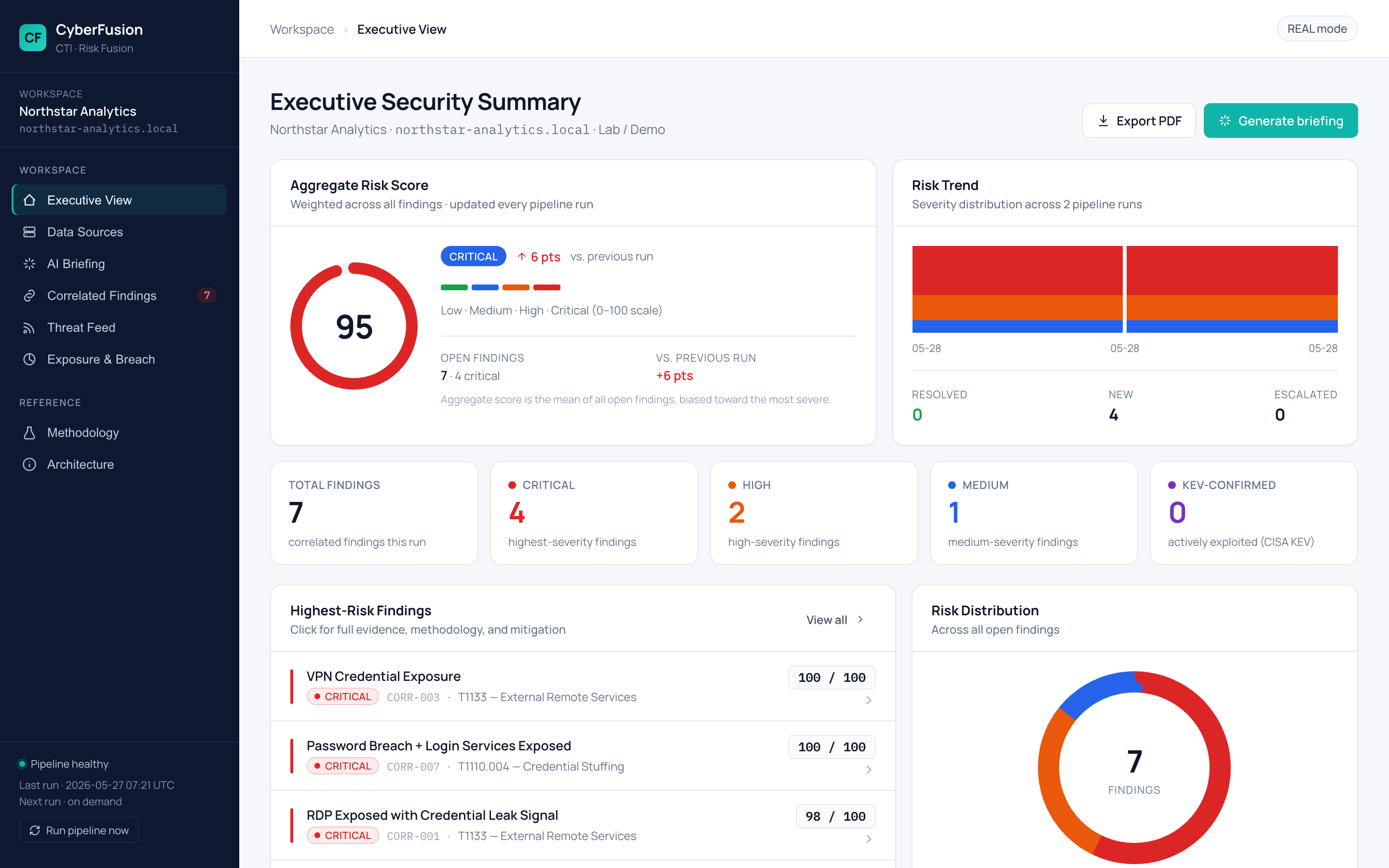
你上传安全证据(或连接 HaveIBeenPwned 这类 API),管道进行解析,分析层跨来源关联信号。最终输出一个按排名排列的发现列表,每项都有分数分解,显示其排名依据。严重程度、资产关键性、KEV 交叉引用(CISA 已知利用漏洞列表)、证据数量——这些都会纳入评分,并且你可以看到每项贡献了多少。
我构建这个项目是因为对可解释性感兴趣。大多数安全工具给出一个数字却没有任何依据,分析人员最终只能怀疑其准确性。而在这里,每个评分都是可重现的。
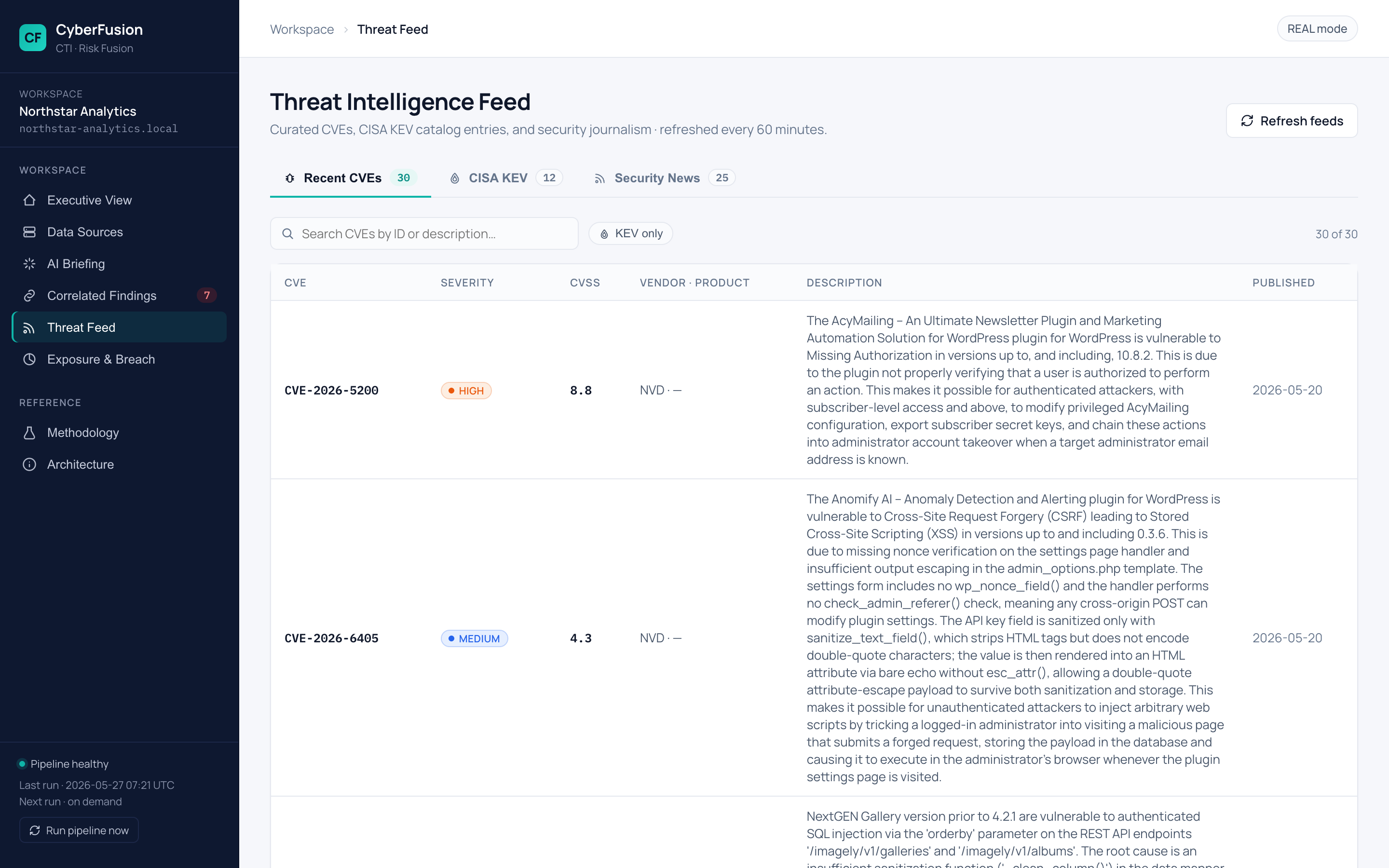
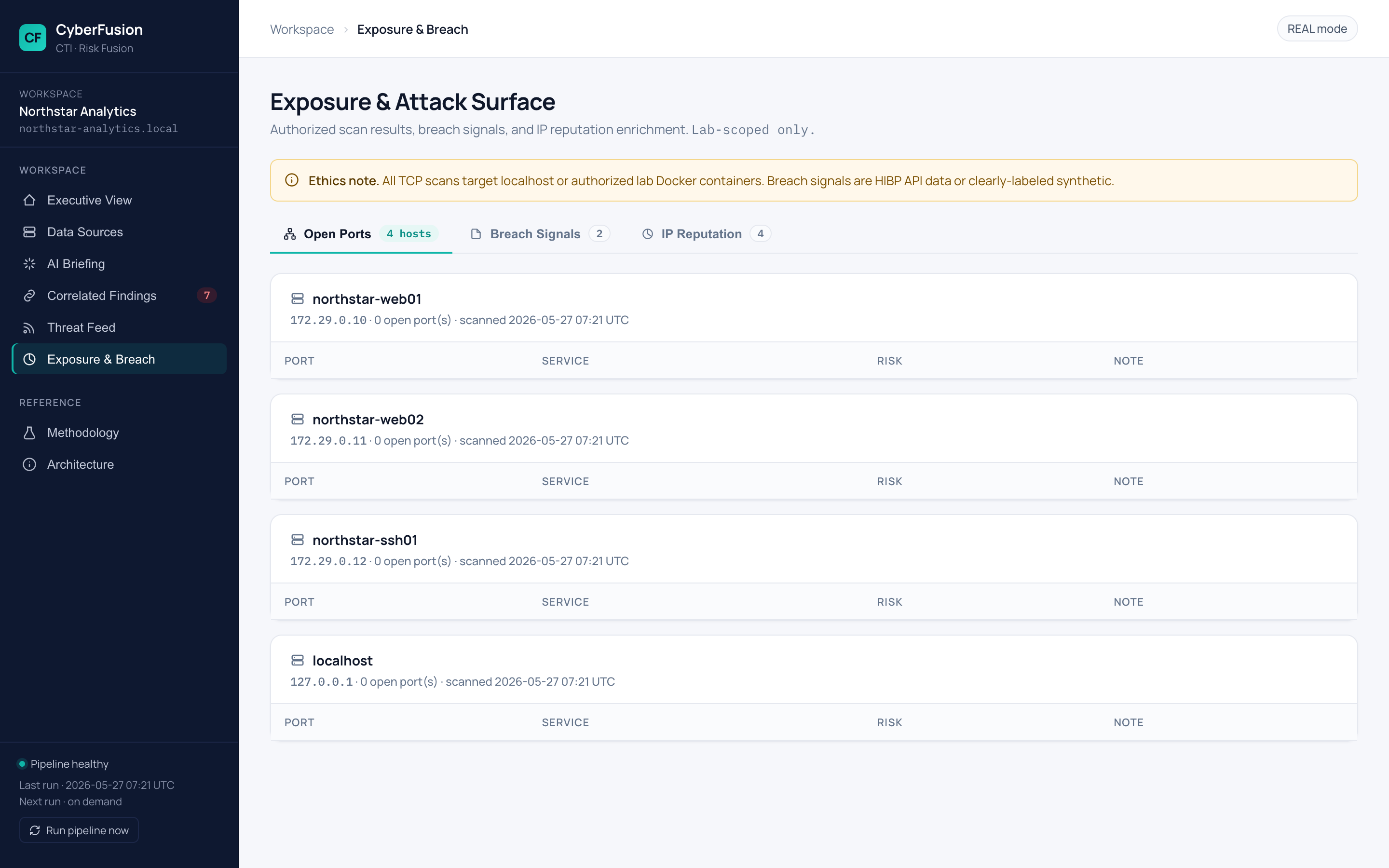
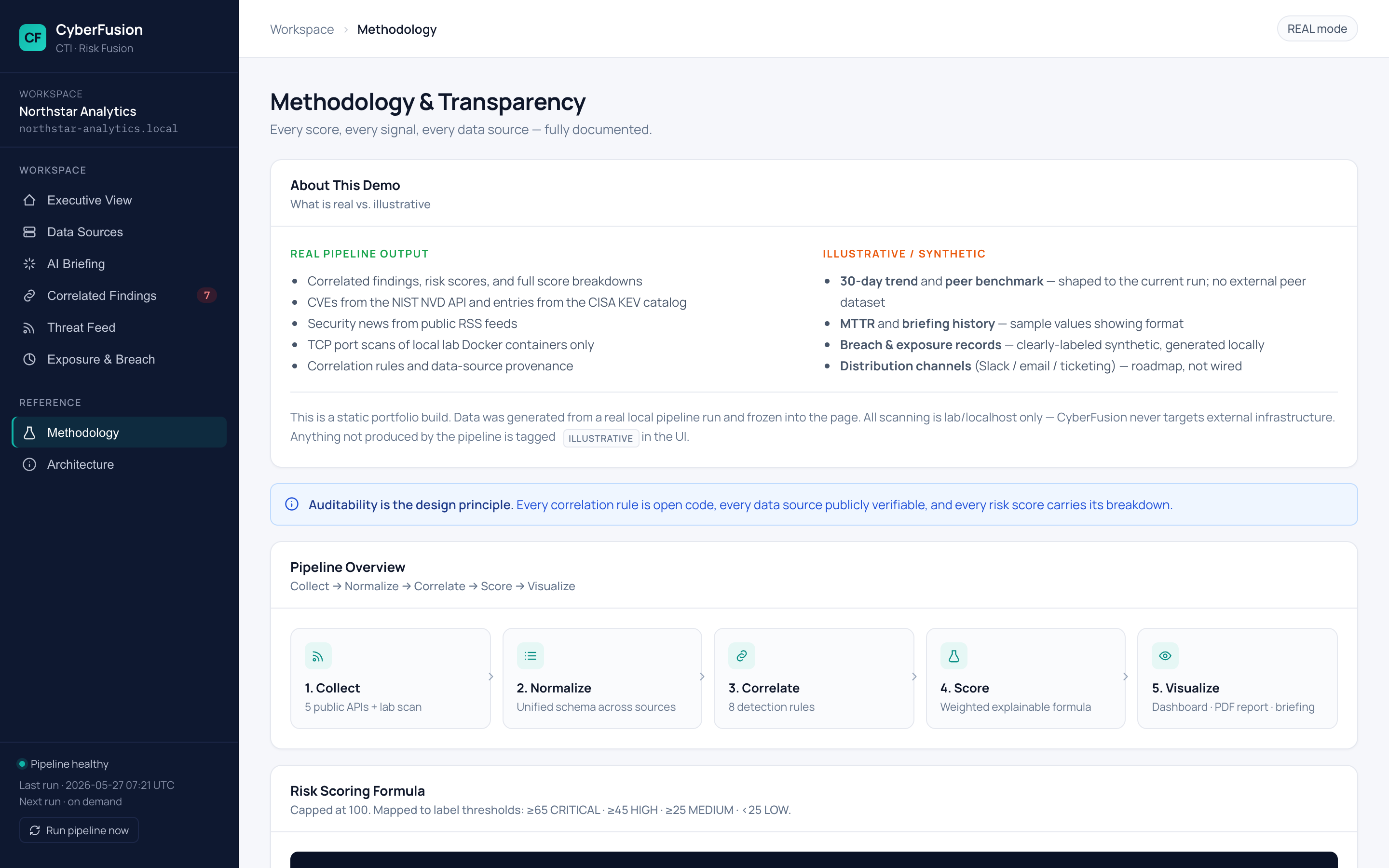
## 截图
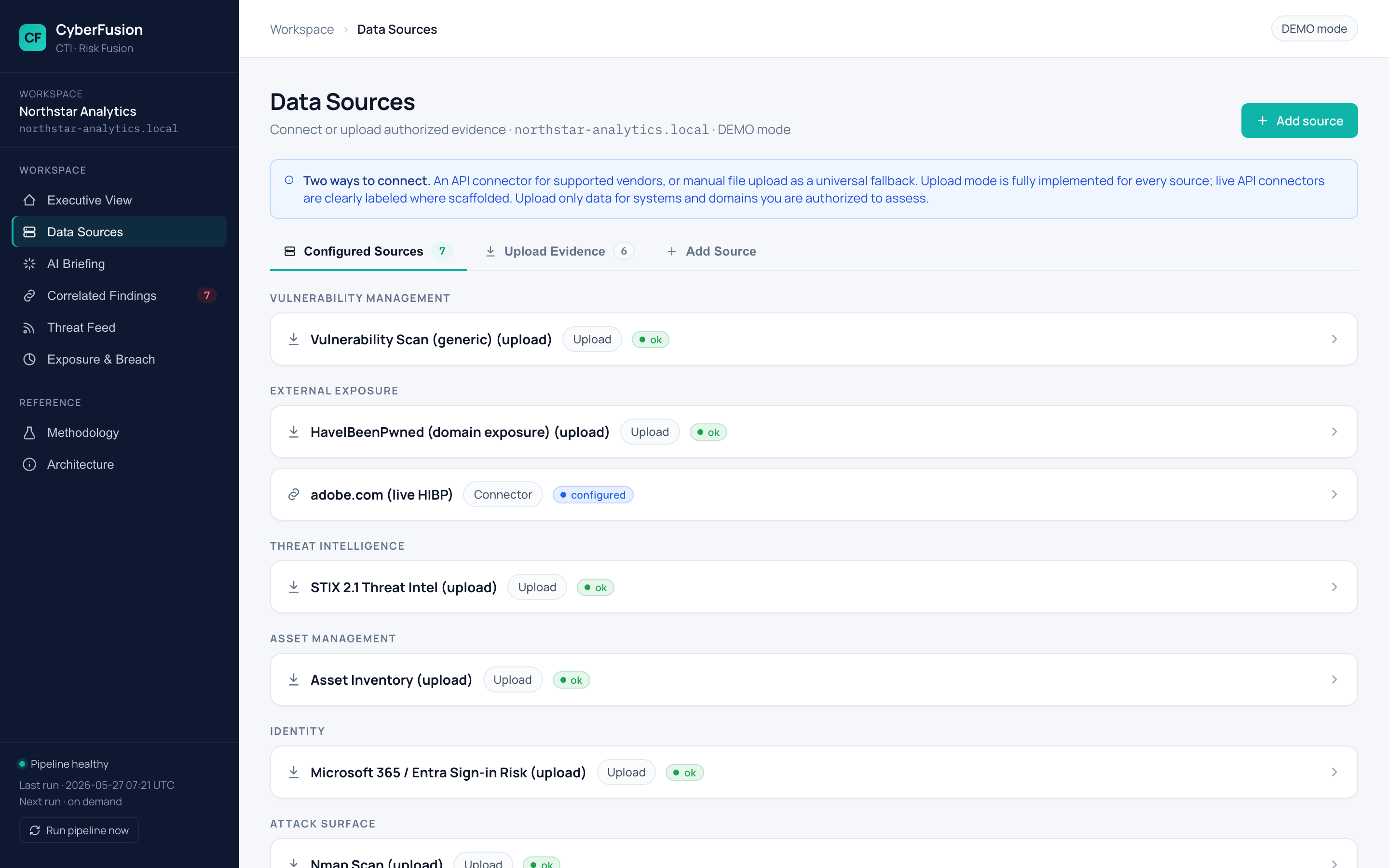
数据源页面——配置连接器、上传文件、查看实时 HIBP 连接器抓取真实泄露数据:
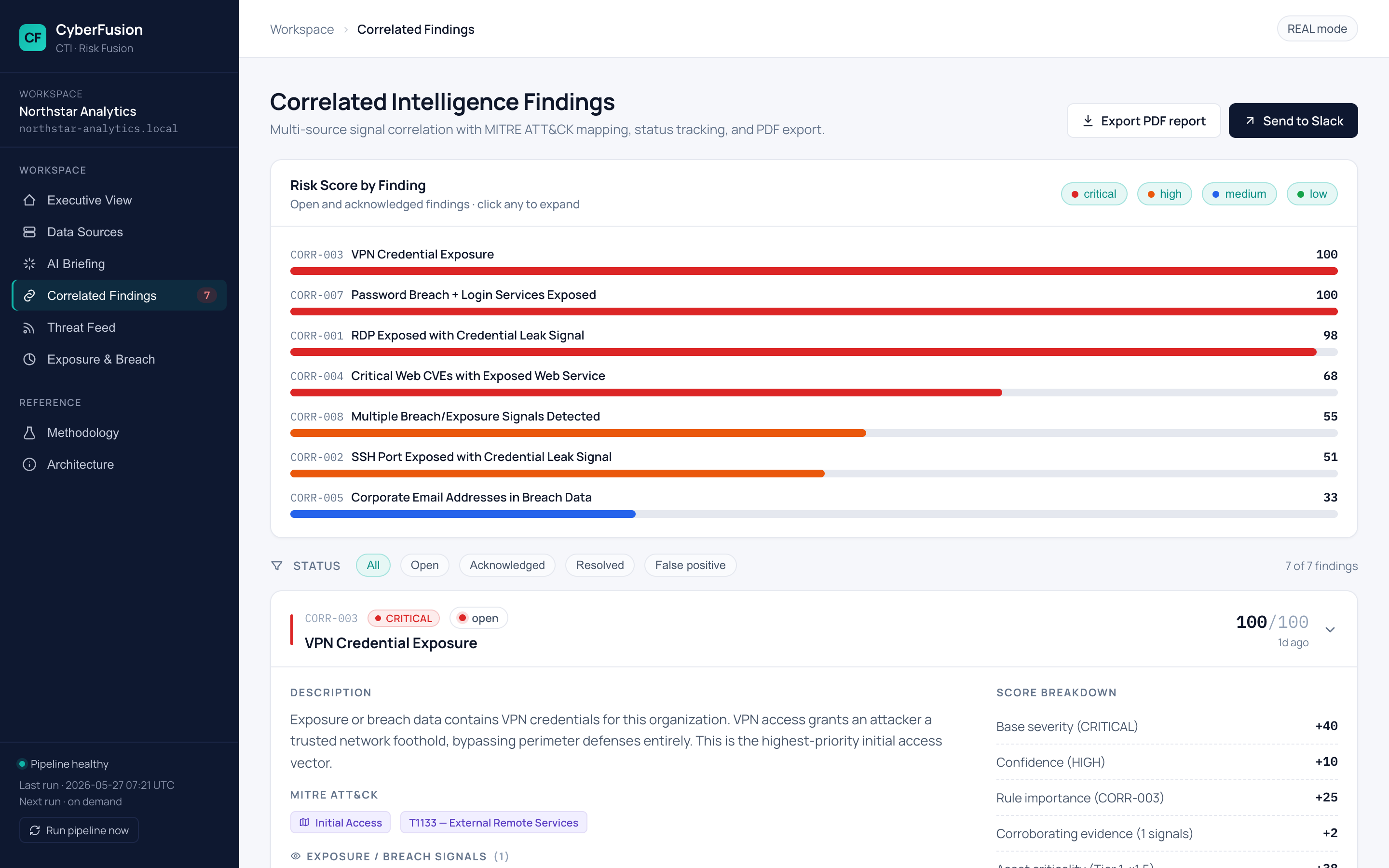
带有完整证据链和状态追踪的发现:
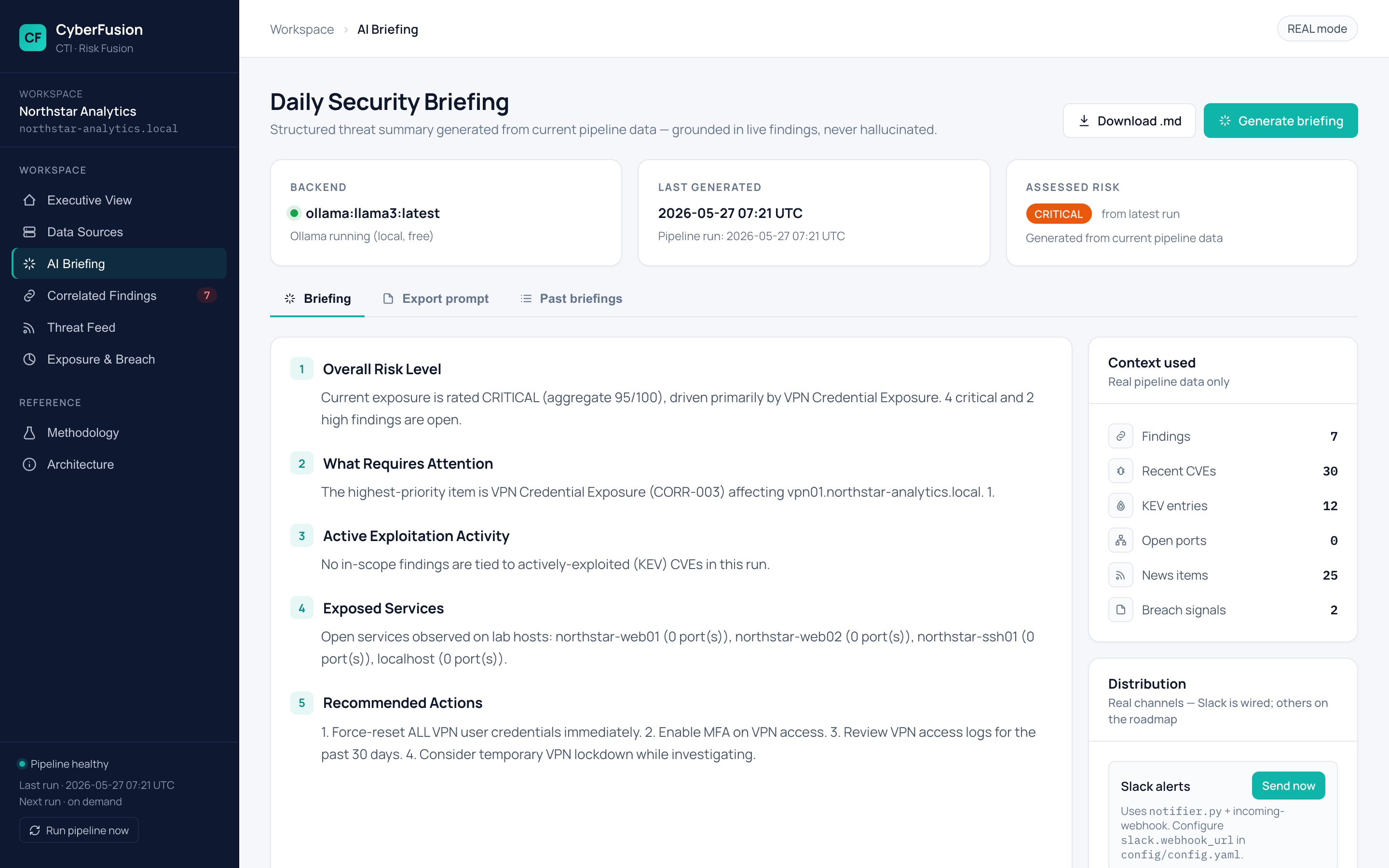
简报页面生成结构化的 CISO 风格摘要。如果你本地运行了 Ollama,它会免费使用 llama3;否则回退到基于当前发现的模板:
## 运行方式
需要 Python 3.11+ 和 Node 22+。首次运行:
```
git clone https://github.com/SStevenB/cyberfusion-complete.git
cd cyberfusion-complete
python3 -m venv venv && source venv/bin/activate
pip install -r requirements.txt
cd frontend && unset NODE_ENV && npm install --include=dev && npm run build && cd ..
```
然后直接运行 `./start.sh`,打开 http://localhost:8000。启动脚本会激活虚拟环境,如果端口被占用则释放端口,然后启动服务器。按 Ctrl+C 停止。
如果你希望 AI 简报真正使用 AI 而非模板回退,另开一个终端运行 `./start_ollama.sh`——它会拉取 llama3(约 4.6 GB,仅需一次)并启动一个本地 LLM 服务器。免费,离线运行。
开发模式(前端热重载)需要两个终端:
```
uvicorn api.main:app --reload --port 8000 # terminal 1
cd frontend && unset NODE_ENV && npm run dev # terminal 2 — opens :5173 with /api proxy
```
## 项目结构
```
api/main.py FastAPI — wraps the pipeline as REST endpoints
frontend/ Vite + React SPA, served from /api/main.py in prod
analysis/ normalizer, correlator (8 rules → MITRE), risk scorer, history
ingestion/ parsers (nmap, vuln CSV, asset, HIBP, M365, STIX) + connectors
data_collection/ NVD, CISA KEV, RSS, breach, IP reputation collectors
scanning/scanner.py TCP scanner (lab/localhost only — never external)
samples/ Synthetic evidence files for the demo
tests/ 78 pytest tests
run_pipeline.py The pipeline orchestrator
build_demo.py Builds the static GitHub Pages snapshot
```
## 数据源
所有数据均来自公共 API 或你提供的文件。运行无需付费账户,不过某些连接器在拥有可选免费密钥时能获取更丰富的数据。
| 数据源 | 提供内容 | 密钥 |
|--------|----------|------|
| NIST NVD | CVE 记录 | 无 |
| CISA KEV | 正在被利用的 CVE 目录 | 无 |
| RSS 源 | Krebs、BleepingComputer、Hacker News | 无 |
| Shodan InternetDB | IP 暴露上下文 | 无(免费) |
| GreyNoise | 扫描器/噪声分类 | 免费密钥 |
| HaveIBeenPwned | 域名泄露历史 | 可选 |
## 连接器
在 `ingestion/connectors/` 目录下有一套连接器层,支持 Tenable、Qualys、HIBP、M365/Entra 以及 STIX/TAXII。其中**只有 HIBP 接入了真实供应商 API**——它调用免费的 `/breaches?domain=` 端点并返回真实的泄露记录(试试 `adobe.com`,你会看到 2013 年的 1.52 亿账户转储)。
其余四个在 UI 中诚实地标记为“骨架”。它们的配置界面可以工作,连接测试端点也能运行,但我没有接入它们的实时获取功能,因为这需要付费供应商账户,而我没有。对于每个数据源,CSV 上传模式作为通用回退方案完全可用。“立即同步”按钮只出现在实际实现的连接器上——我特意在 UI 中保持这种区分,而不是假装它存在。
## 诚实地说明哪些是真实的
仪表板上有几项内容在方法论页面中明确标注,而非含糊不清:
- **发现、评分、CVE、KEV 交叉引用、端口**——全部是真实的管道输出,每次运行重新生成
- **运行间趋势**——随着你多次运行管道而累积;仅运行一次时会有相应说明
- **泄露数据**——未配置 HIBP 密钥时使用合成数据(并明确标注)
- **简报分发**——Slack 是真实的(设置 webhook 后使用 `notifier.py`);电子邮件和 Jira 在路线图中,并相应标注
安全工具的核心是信任,所以在作品集版本中使用虚假数字反而适得其反。
## 伦理
扫描仅针对 localhost 或 Docker 实验室容器运行。扫描器不会接受外部目标。合成数据在代码注释和 UI 中均有标识。真实凭据永远不会存储到仓库中——连接器密钥通过 `keyring` 存入系统钥匙,在无头环境中使用 gitignored 本地文件作为回退。
## 测试
```
source venv/bin/activate
pytest tests/ -q
```
共 78 个测试,覆盖管道、摄入、数据源注册中心、密钥、连接器、FastAPI 端点和趋势历史。它们使用隔离的临时工作空间,不会影响你的真实状态。
## 部署
项目包含 `Dockerfile`、`render.yaml` 和 `build.sh`,适用于 Render/Fly/Railway。详情见 [DEPLOY.md](DEPLOY.md)。简短说明:Render 读取 `render.yaml`,运行 `./build.sh`,然后启动一个同时处理 API 和已构建 React 应用的单一 uvicorn 进程。
## 许可证
MIT
更多截图——威胁情报、暴露面、方法论
  标签:AI风险缓解, AV绕过, CISO报告, CVE管理, FastAPI, GPT, HaveIBeenPwned, KEV已知利用漏洞, LLM评估, masscan, Ollama, Python, React, Syscalls, 二进制发布, 优先级排序, 大型语言模型, 威胁情报平台, 威胁情报联动, 安全发现, 开源工具, 扫描结果分析, 数据关联, 数据源管理, 无后门, 暴露面分析, 泄露数据, 漏洞管理, 网络安全, 自动简报, 证据追溯, 评分可解释性, 请求拦截, 资产清单, 资产风险管理, 逆向工具, 隐私保护, 静态快照, 风险评分, 黄金证书