ighorj/challenge-private
GitHub: ighorj/challenge-private
融合规则引擎、XGBoost 风险排序与多 Agent LLM 编排的端到端 AML/FT 调查流水线,可自动生成带审计追踪的可疑活动报告。
Stars: 0 | Forks: 0
# AML-FT 多 Agent 调查系统
面向巴西金融科技的端到端 AML/FT 调查流水线:21 条规则检测引擎 + XGBoost 优先级排序 + Anthropic Claude 多 Agent 编排。以审慎的调查语言生成带有审计追踪、可输出 SAR 的报告,并为每个使用 LLM 的 Agent 提供确定性回退机制。
## 执行摘要
针对四个月内的 52,000 笔交易和 2,500 份 KYC 配置文件,该系统会揭示可疑实体,对其进行排序,构建基于证据的调查案件,起草 SAR 报告,并应用合规审查——每个阶段都可解释,每个产出物都可复现。五个由 Anthropic 支持的 Agent 通过顺序 DAG 进行编排;每个 Agent 都配备了确定性模板后端,可产生相同的 JSON 契约,因此系统无论是否具有 API 密钥均可运行。
## 主要结果
- **C102290** — 指定的**调查展示案件**。PEP 客户 (KYC=98),收入不匹配达 144 倍,过境比例 2,013%,Tor + 2 次 VPN 事件,单日爆发(R$42k),与 C100880 共享收款商户。这是数据集中最强的多重类型学汇合。完整 SAR:[`docs/phase1/SAR-2025-C102290-01.md`](docs/phase1/SAR-2025-C102290-01.md)。由行为信号驱动的 ML Tier 1(校准后概率为 1.00)—— 参见 [`docs/phase3/Phase3_ML_Summary.md`](docs/phase3/Phase3_ML_Summary.md)。
- **C100091** — 最高的**运营上报优先级**(综合优先级得分排名第一)。由单笔交易的制裁筛查事件驱动。该客户的 KYC 资料显示没有确认的制裁匹配,因此这被保留为“需要审查的筛查事件”,而不是已确认的风险暴露。
- **运营优先级与调查价值的区分十分明确。** 优先级得分回答了“今天必须上报什么?”——而调查丰富度则回答了“什么最能展示系统的深度?”这两个信号都会被呈现;任何一方都不会覆盖另一方。
## 架构
```
Data → Rules → ML → Investigation → SAR → Compliance
```
顺序 Agent DAG,带有共享产出物存储、编排器管理的审计追踪,以及每个 Agent 的 LLM/模板后端选择。
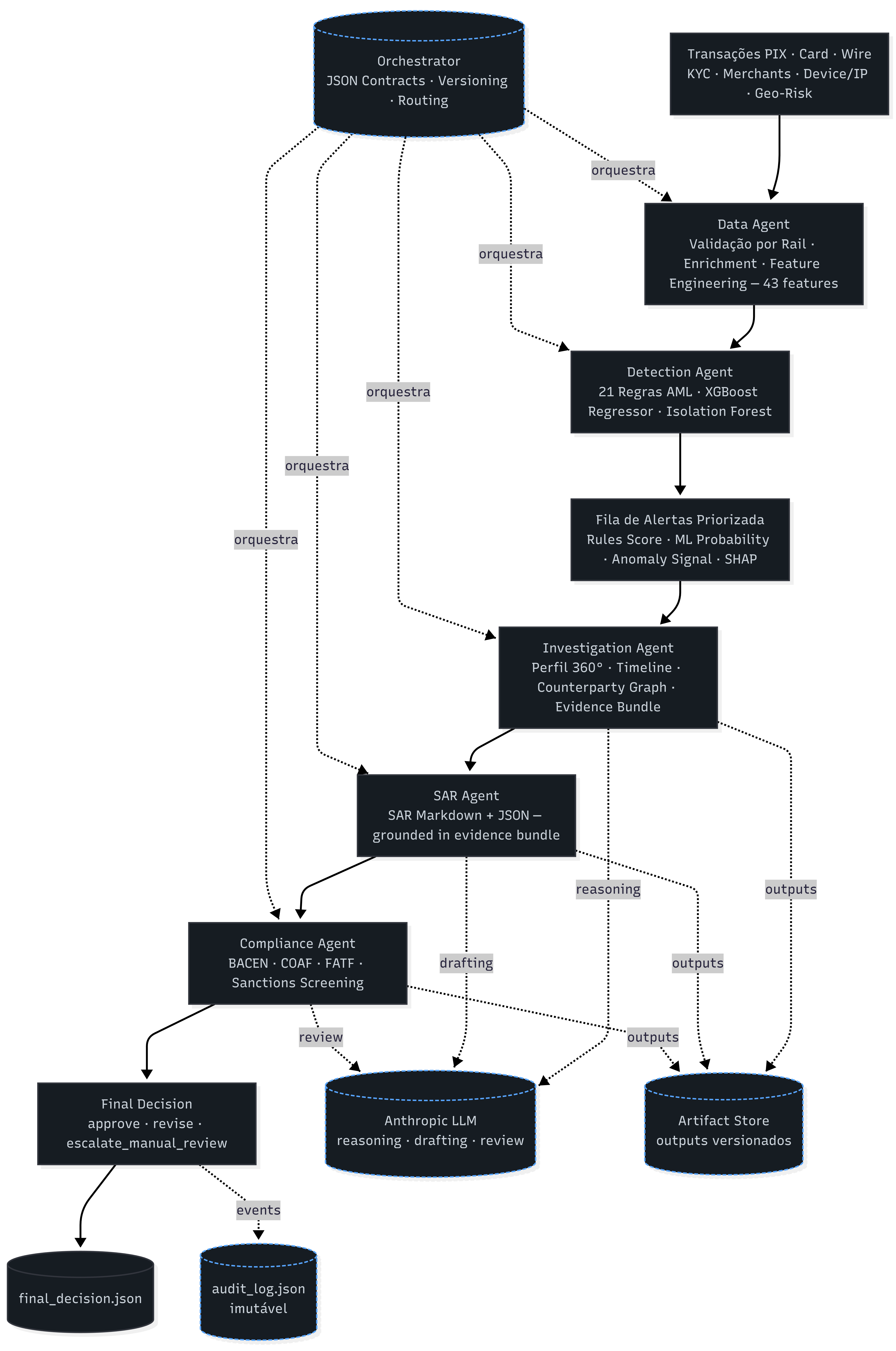
Mermaid 源码:[`docs/architecture/architecture.mmd`](docs/architecture/architecture.mmd)
## 项目结构
```
CW/
├── agents/ Phase 4 multi-agent system
│ ├── data_agent/ Ingestion + LLM quality assessment
│ ├── detection_agent/ Rules + ML + LLM triage memo
│ ├── investigation_agent/ Evidence bundle + LLM case narrative
│ ├── sar_agent/ SAR drafting (JSON + markdown)
│ ├── compliance_agent/ Policy checks + LLM regulatory review
│ ├── orchestrator/ Stage routing + audit logging
│ ├── aml_constants.py Canonical rule descriptions + sanctions logic
│ ├── priority.py Deterministic priority + severity scoring
│ └── shared.py soften_language, ml_confidence_band, RunContext
├── src/
│ ├── rules/ 21-rule alerts engine (Phase 2)
│ └── ml/ XGBoost prioritization + SHAP (Phase 3)
│ ├── ml_pipeline.py XGBoost regression on behavioral_risk_score
│ └── isolation_forest.py Unsupervised anomaly detection (raw features only)
├── docs/
│ ├── architecture/ Pipeline diagram (mmd + png)
│ ├── phase1/ Phase 1 manual investigation + SAR-2025-C102290
│ ├── phase4/ Multi-agent architecture deep-dive
│ └── final_summary.md Two-page delivery narrative
├── outputs/
│ ├── examples/showcase_run/ Canonical example output (committed)
│ ├── phase4_demo/runs/ Per-run artifacts (gitignored — regenerate locally)
│ ├── figures/ SHAP / chart PNGs
│ └── rankings/ Phase 2/3 CSV outputs
├── data/ Source xlsx
├── README.md
├── requirements.txt
└── .env.example
```
## 阶段划分
| 阶段 | 重点 | 关键产出物 |
|---|---|---|
| **1 — 调查** | 包含 9 个对象的手动队列 + 1 个展示用 SAR (C102290) | [`docs/phase1/`](docs/phase1/) |
| **2 — 规则引擎** | 21 条确定性规则,综合评分,上报阈值带 | [`src/rules/alerts_engine.py`](src/rules/alerts_engine.py) |
| **3 — ML 优先级排序** | 对行为风险目标(R02/R03/R09 规则子集)进行 XGBoost 回归分析,基于全部 2,500 名客户进行训练;硬性警报(R08/R16/R21)保留在规则引擎中。引入 Isolation Forest 得分和交易对手网络特征;保序校准可输出具有实际意义的概率。为每位客户生成 SHAP。 | [`src/ml/ml_pipeline.py`](src/ml/ml_pipeline.py) · [`src/ml/isolation_forest.py`](src/ml/isolation_forest.py) |
| **4 — 多 Agent 编排** | 5 个 LLM Agent + 带有确定性回退的编排器 | [`agents/`](agents/) |
## 多 Agent 系统
| Agent | 职责 | LLM 角色 |
|---|---|---|
| **Data Agent** | Schema 校验,资金流连贯性,数据富化,质量报告 | 识别数据集中的风险集中趋势 |
| **Detection Agent** | 运行 21 条规则 + XGBoost;构建基于队列相对 ML 阈值带的优先级队列 | 跨客户模式检测 + 分诊备忘录 |
| **Investigation Agent** | 证据捆绑,基于证据权重的 Timeline(匿名化 / 制裁 / Wire / 爆发 / 跨境等关键节点),实体关联 | 仅基于捆绑包事实撰写案件叙述报告 |
| **SAR Agent** | 结构化 JSON + markdown SAR 草稿,规范化规则引用,制裁区分 | 以审慎的调查语言起草 SAR |
| **Compliance Agent** | 强制字段 / SLA / 司法管辖策略检查,基于严重程度的决策 | 监管对齐审查(FATF / BACEN / COAF) |
| **Orchestrator** | 路由阶段,传递 `--use-llm`,追加至 `audit_log.json`,管理运行目录 | n/a |
每次 LLM 调用都有生成相同 JSON 契约的确定性模板回退。
## 运行系统
**环境要求:** Python 3.10+,通过 `pip install -r requirements.txt` 安装依赖。
```
# 1. 安装
pip install -r requirements.txt
# 2. 配置(仅限 LLM 模式)
cp .env.example .env
# 编辑 .env 并设置 ANTHROPIC_API_KEY=...
# 3a. 使用确定性后端运行(无 API 调用)
python -m agents.orchestrator.orchestrator --top-n 10
# 3b. 使用 Anthropic Claude 作为所有 agents 的后端运行
python -m agents.orchestrator.orchestrator --top-n 10 --use-llm
```
每次调用都会创建一个新的 `outputs/phase4_demo/runs//` 目录。Orchestrator 会写入:
- `processed_*.parquet`(Data Agent)
- `prioritized_alert_queue.json`(Detection Agent)
- `evidence_bundle.json`, `investigation_case.json`, `investigation_summary.md`(Investigation Agent)
- `sar_structured.json`, `sar_draft.md`(SAR Agent)
- `compliance_review.json`, `final_decision.json`(Compliance Agent)
- `audit_log.json`(Orchestrator,全程持续追加)
如果只需针对缓存过的运行重新执行最新阶段,请传入 `--run-id `。
## 输出示例
一个提交的规范运行示例位于 [`outputs/examples/showcase_run/`](outputs/examples/showcase_run/):
- `investigation_summary.md` — 包含 Timeline + 队列 ML 阈值带的单客户案件报告
- `sar_draft.md` — 完整的 SAR,包含案件识别、执行摘要、触发的警报、监管依据
- `final_decision.json` — 包含 approve / revise / escalate_manual_review 的合规审查
## 局限性
- **合成数据集。** 其行为未根据真实的客户实际情况进行验证。
- **弱标签 ML 训练(已缓解)。** 标签依然由规则引擎推导得出,但 v2 流水线将目标缩小至**行为-软性**子集(R02 结构化,R03 收入不匹配,R09 PEP),并明确将硬性警报(R08 制裁,R16 自我商户,R21 网络关联)排除在目标之外——这些是属于规则引擎所有的二元监管事实,而不是应该要求 ML 从交易行为中预测的模式。其余的 15 条规则被保留,仅作为模型必须重新发现的原始聚合特征保留。因此,三个独立的信号会输入给分析师队列:规则引擎(监管事实)、XGBoost 回归器(行为风险)以及 Isolation Forest(无监督异常,无标签)。各层级之间的一致性可增强置信度;而分歧则具有启发意义。
- **缺乏真实的制裁核查。** 未集成 OFAC、BACEN、欧盟制裁名单。制裁筛查事件仅被视为初步指标。
- **无人工干预反馈。** 没有分析师决策捕获或模型重训循环。
- **无生产环境监控或漂移处理。** 这是一个交付原型,而非已部署的系统。
- **网络分析较浅。** 揭示了被标记对象之间的直接 Wire,但未分析传递性的网络路径。
## 未来改进
- **分析师反馈循环** — 捕获合规专员的决策;弥合监督学习的差距
- **校准监控** — 跟踪得分布随时间的漂移
- **原生图调查** — 传递性实体 / 设备 / IP / 商户子图
- **人工介入审查 UI** — 面向分析师的案件仪表板,带有评论记录
- **实时制裁集成** — 在检测期间进行 OFAC / BACEN / 欧盟名单查询
## 审查者切入点
| 若想了解… | 请阅读... |
|---|---|
| **为何 C102290** 是展示案件 | [`docs/phase1/Phase1-Investigation-Report.md`](docs/phase1/Phase1-Investigation-Report.md) |
| **完整的调查方法** | [`docs/phase1/SAR-2025-C102290-01.md`](docs/phase1/SAR-2025-C102290-01.md) |
| **深入了解多 Agent 系统** | [`docs/phase4/Phase4_MultiAgent_Architecture.md`](docs/phase4/Phase4_MultiAgent_Architecture.md) |
| **用于交付的两页叙述报告** | [`docs/final_summary.md`](docs/final_summary.md) |
| **实时示例输出** | [`outputs/examples/showcase_run/`](outputs/examples/showcase_run/) |
| **架构图** | [`docs/architecture/architecture.png`](docs/architecture/architecture.png) |
标签:Apex, LLM多智能体, 反洗钱, 异常检测, 机器学习, 逆向工具, 金融科技