sachixwadajkar/quora-duplicate-question-detection
GitHub: sachixwadajkar/quora-duplicate-question-detection
一个基于NLP特征工程和随机森林的Quora重复问题检测系统,通过Streamlit提供交互式预测界面。
Stars: 0 | Forks: 0
# Quora 重复问题检测
## 应用演示

## 模型评估
### 混淆矩阵
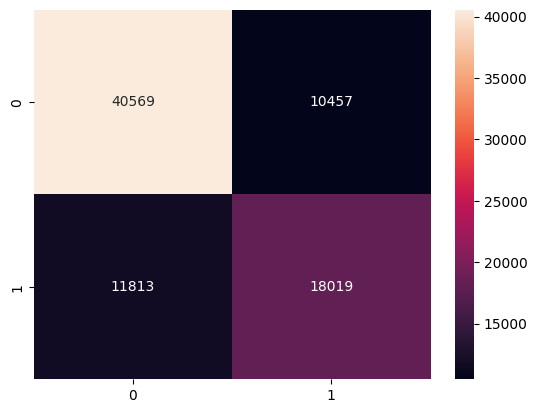
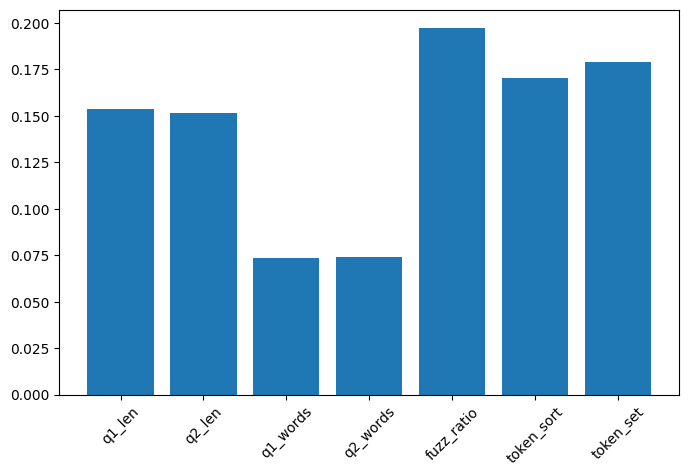
### 特征重要性
## 项目概述
本项目利用 NLP 特征工程与机器学习,检测两个 Quora 问题是否为重复问题。
解决方案通过文本相似度指标进行特征提取,并使用 Streamlit 部署的 Random Forest 模型预测重复问题。
## 功能特点
- 问题长度提取
- 词数特征
- 模糊字符串相似度
- Token sort ratio
- Token set ratio
- Random Forest 分类
- Streamlit 部署
## 技术栈
- Python
- Pandas
- NumPy
- Scikit-learn
- Streamlit
- FuzzyWuzzy
- Matplotlib
- Seaborn
## 数据集
使用的数据集:
Quora Questionairs Dataset
目标:
0 → 非重复
1 → 重复
## 使用的特征
q1_len
q2_len
q1_words
q2_words
fuzz_ratio
token_sort
token_set
## 模型流水线
问题
↓
特征工程
↓
Random Forest
↓
预测
↓
Streamlit 应用
## 结果
模型评估指标:
- Accuracy
- Precision
- Recall
- F1 Score
- Confusion Matrix
- Feature Importance
## 项目结构
quora-duplicate-question-detection/
│── app.py
│── quora.ipynb
│── README.md
│── requirements.txt
│── .gitignore
│
└── images/
```
├── confusion_matrix.png
├── feature_importance.png
└── streamlit_demo.png
```
## 本地运行
安装依赖项:
pip install -r requirements.txt
运行应用:
python -m streamlit run app.py
## Streamlit 演示
(在此处添加截图)
## 未来改进
- TF-IDF 嵌入
- BERT 嵌入
- Transformer 模型
- 语义相似度方法
标签:Apex, FuzzyWuzzy, Kubernetes, Python, Quora, Streamlit, 文本分类, 文本相似度, 无后门, 机器学习, 混淆矩阵, 特征工程, 特征重要性, 相似度计算, 访问控制, 逆向工具, 重复问题检测, 问题对, 随机森林