vahapogut/antigravity-add-model
GitHub: vahapogut/antigravity-add-model
一个为 Google Antigravity IDE 注入本地代理的补丁,使其支持接入 OpenAI、Claude、Ollama 等多种外部自定义 LLM。
Stars: 11 | Forks: 2
# Antigravity 自定义模型启用器
本仓库包含一个针对 **Google Antigravity** 的补丁,它可以在内置的 Gemini 模型之外,启用外部 AI 模型(OpenAI、Anthropic、Together API、Ollama、Google AI Studio 以及任何兼容 OpenAI 的提供商)。它向 Electron 应用中注入了一个本地 HTTP 代理,对 Cloud Code 内部 API(`v1internal`)进行了逆向工程,转换了不同提供商之间的请求/响应格式,并在“设置”页面中提供了一个内联的“添加模型”UI。
## 工作原理
### 架构
```
Antigravity IDE
└── Language Server (Go binary)
└── --api_server_url → http://127.0.0.1:50999 (local proxy)
├── Google models → daily-cloudcode-pa.googleapis.com
└── Custom models → external API (Together, OpenAI, etc.)
```
### 关键组件
#### 代理核心
| 文件 | 作用 |
|---|---|
| [proxy.ts](src/proxy.ts) | 本地 HTTP 代理:拦截 Cloud Code API,合并自定义模型,转换提供商格式,封装响应 |
| [registry.ts](src/proxy/registry.ts) | 自动发现的翻译器注册表,可动态加载 `openai`、`anthropic`、`google` 和 `ollama` 翻译器 |
| [shared.ts](src/proxy/shared.ts) | 具备自动 TTL 清理的跨轮次状态管理 |
| [modelUtils.ts](src/proxy/modelUtils.ts) | 集中的模型能力检测(thinking、DeepSeek、Claude) |
#### 格式翻译器
| 文件 | 作用 |
|---|---|
| [openai.ts](src/proxy/translators/openai.ts) | OpenAI ↔ Gemini 格式转换(请求、响应、流式数据块、工具调用) |
| [anthropic.ts](src/proxy/translators/anthropic.ts) | Anthropic ↔ Gemini 格式转换(Claude tool_use、SSE 流式传输、thinking 支持) |
| [google.ts](src/proxy/translators/google.ts) | Google AI Studio 透传及流式端点路由 |
| [ollama.ts](src/proxy/translators/ollama.ts) | Ollama ↔ Gemini 格式转换(兼容 OpenAI 的本地 LLMs) |
| [utils.ts](src/proxy/translators/utils.ts) | 共享的翻译器实用工具(工具调用映射、DSML 解析、参数类型修复) |
#### 安全与数据
| 文件 | 作用 |
|---|---|
| [cryptoStore.ts](src/cryptoStore.ts) | 通过 Electron `safeStorage` 进行 AES-256-GCM API 密钥加密 |
| [schemaValidator.ts](src/schemaValidator.ts) | 对 API 响应、自定义模型和流式数据块进行运行时 schema 校验 |
#### UI 与应用集成
| 文件 | 作用 |
|---|---|
| [preload.ts](src/preload.ts) | UI 注入:在设置 → 模型中的自定义模型仪表板,带动画的内联添加模型弹窗,连接测试按钮 |
| [main.ts](src/main.ts) | 应用生命周期:拦截并阻止 `SetCloudCodeURL` 请求,防止前端覆盖代理端点 |
| [ipcHandlers.ts](src/ipcHandlers.ts) | 后端 IPC:`storage:get-custom-models`、`storage:save-custom-model`、`storage:delete-custom-model`、`storage:test-model-connection` |
| [languageServer.ts](src/languageServer.ts) | 修改后的语言服务器管理器,在应用启动时开启代理 |
#### 部署脚本
| 文件 | 平台 |
|---|---|
| [deploy.ps1](deploy.ps1) | Windows — 停止 Antigravity,将 `dist/` 打包入 `app.asar`,重启 |
| [deploy.sh](deploy.sh) | macOS — 从 `/Applications/` 提取 `app.asar`,替换 `dist/`,重新打包并重启 |
| [deploy_linux.sh](deploy_linux.sh) | Linux — 跨标准 Electron 应用目录自动检测安装路径 |
| [repack.ps1](repack.ps1) | 使用更新后的 `dist/` 文件重新打包现有的 `app.asar` |
### Cloud Code API 逆向工程
Antigravity 使用 Google 的 **Cloud Code 内部 API**(`v1internal:*` 端点)而不是公开的 Gemini API。代理会处理以下差异:
1. **fetchAvailableModels**:拦截并注入自定义模型定义。自定义模型的 slug 会被添加到 `agentModelSorts` 中,以便它们出现在聊天模型下拉菜单中。自定义模型会省略配额信息,因为它们使用的是用户自己的 API 密钥。
2. **streamGenerateContent/generateContent**:Cloud Code 将 Gemini 请求封装在一个 `request` 字段中:
{
"project": "...",
"requestId": "...",
"request": { "contents": [...], "systemInstruction": {...}, "generationConfig": {...} },
"model": "custom-deepseek-ai-deepseek-v4-pro"
}
代理会在进行格式转换前提取出 `request`。
3. **systemInstruction**:Cloud Code 在一个单独的 `systemInstruction` 字段(不在 `contents` 内部)中发送模型身份/工具定义。代理会将其映射到 OpenAI 的 `role: "system"` 或 Anthropic 的 `system` 参数。
4. **响应包装**:Cloud Code 将响应封装在 `{"response": {...}, "traceId": "...", "metadata": {}}` 中。代理会仿照此格式,以便 IDE 能够接受该响应。
### 请求/响应流程
```
1. User selects custom model and sends message
2. IDE → POST /v1internal:streamGenerateContent?alt=sse → local proxy
3. Proxy detects custom model match (by slug or hash-based MODEL_PLACEHOLDER_* ID)
4. Extracts reqJson.request → maps systemInstruction + contents to provider format
5. POST to external API (e.g. https://api.together.xyz/v1/chat/completions)
6. Maps external response back to Gemini format
7. Wraps in Cloud Code envelope {"response": {...}, "traceId": "", "metadata": {}}
8. Returns SSE: data: {envelope}\n\n → IDE displays response
```
### 流式修复(关键)
代理会区分 **元数据请求**(需要缓冲以进行 URL 重写)和 **生成请求**(必须直接流式传输)。如果代理缓冲了 `streamGenerateContent` 或 `generateContent` 响应,Go 语言服务器会因为等待流结束而超时,导致应用崩溃并提示“由于错误而终止”。
- **元数据请求**(不包括生成请求的 `v1internal:*`):进行缓冲、解压,重写 URL 使其指向本地代理
- **生成请求**(`streamGenerateContent`、`generateContent`):直接通过管道传输而不进行缓冲,以保持实时的流式传输
### SetCloudCodeURL 拦截
Antigravity 前端会定期尝试调用 `SetCloudCodeURL`,这会用默认的 Google API URL 覆盖本地代理端点。`main.ts` 进程通过 `webRequest.onBeforeRequest` 拦截并 **取消** 这些请求,确保语言服务器始终通过本地代理进行路由。
### DSML 工具调用解析器
DeepSeek 模型(以及其他一些提供商)会以嵌入在文本内容中的自定义 **DSML**(DeepSeek Markup Language)格式返回工具调用:
```
latest news
```
代理会自动检测 DSML 块,将其解析为 Gemini 格式的 `functionCall` 对象,并从显示的文本中剔除该 XML。同时也支持原生的 OpenAI `tool_calls` 和 Anthropic 的 `tool_use` 块。
### Anthropic 工具调用
Claude 模型(`anthropic` 提供商)将工具调用作为 `tool_use` 内容块返回。代理将这些映射为 Gemini 格式的 `functionCall` 部分,设置 `finishReason: "TOOL_CALL"`,并存储工具调用 ID,以便在后续轮次中与 `functionResponse` 对象进行匹配。无论是流式(SSE `content_block_start`/`content_block_delta`)还是非流式响应,都能得到完整处理。
### 安全:API 密钥加密
所有 API 密钥在静态存储时均通过 Electron 的 `safeStorage` 使用 **AES-256-GCM** 进行加密。`cryptoStore.ts` 模块提供:
- **透明的加密/解密**:密钥在写入磁盘前被加密,加载到内存中时会即时解密。
- **自动迁移**:在加密更新后的首次运行中,任何遗留的纯文本 `custom_models.json` 配置都会被自动检测、加密并重写。
- **掩码显示**:UI 中的 API 密钥显示为 `sk-...XXXX`(仅显示最后 4 个字符),以防止肩窥。
- **操作系统级密钥存储**:在 macOS 上,`safeStorage` 使用 Keychain;在 Windows 上,它使用 DPAPI。
### 动态端口管理
本地代理使用具有自动回退机制的 **动态端口分配**:
```
// proxy.ts → startProxy()
server.listen(50999, ...); // Try default port
server.on('error', (e) => {
if (e.code === 'EADDRINUSE') {
server.listen(0, ...); // Fallback: let OS pick a free port
}
});
```
如果默认端口 `50999` 已被占用(例如,被另一个实例或僵死进程占用),代理会自动回退到一个随机可用的端口(`port: 0`)。`languageServer.ts` 模块会读取动态分配的端口,并在启动时将其注入到 Go 语言服务器的 `--api_server_url` 参数中,从而确保连接链路始终保持连通。
### 并行请求隔离
现在多个模型可以同时发出请求,且不会发生交叉污染。以前,像 `lastToolCallIds` 和 `lastReasoningContent` 这样的全局变量可能会被来自不同模型的并发请求覆盖。它们已被迁移至 **基于模型的 `Map` 结构**:
- `modelToolCallIds`(`Map`)将工具调用 ID 跟踪范围限定在每个模型内
- `modelReasoningContent`(`Map`)将 DeepSeek 的推理状态限定在每个模型内
- `activeStreamContexts`(`Map`)将流式累加器限定在每个流内
### 自动状态清理
代理状态会通过受管理的垃圾回收间隔自动进行清理:
- **流上下文**:TTL 10 分钟
- **工具调用 ID 和推理**:TTL 30 分钟
- 间隔随 `startProxy()` 启动,随 `stopProxy()` 停止,防止产生孤儿计时器
### Schema 校验
`schemaValidator.ts` 模块提供运行时校验,可以在格式错误的 API 响应到达 IDE 前端之前将其捕获,从而避免出现难以理解的错误。导出的校验器包括:
| 功能 | 校验内容 |
|---|---|
| `validateCandidate` | 单个 Gemini candidate 结构 |
| `validateGenerateContentResponse` | 完整的 Gemini 响应 payload |
| `validateCloudCodeEnvelope` | Cloud Code 的 `{ response, traceId, metadata }` 包装器 |
| `validateCustomModel` | 单个自定义模型配置(provider 枚举、URL 格式) |
| `validateCustomModels` | 自定义模型配置数组 |
| `validateGenerateContentRequest` | 请求体结构 |
| `validateOpenAiChunk` | OpenAI 流式数据块 |
| `validateAnthropicEvent` | Anthropic SSE 事件类型 |
### 模型连接测试
设置中的每个自定义模型都有一个 **“测试连接”** 按钮,该按钮会向模型的 API 端点发送一个轻量级的请求:
- 快速连接检查(10 秒超时)
- 绿色 ✅ 或红色 ❌ 状态指示器
- 针对常见问题(身份验证、超时、SSL)提供有用的错误消息
- 通过 IPC 实现:`storage:test-model-connection`
### 请求重试与速率限制
代理会通过指数退避自动重试失败的请求:
- **触发条件**:429(速率限制)、502、503、504(服务器错误)
- **退避策略**:1秒 → 2秒 → 4秒 → 8秒(最多重试 3 次)
- **Retry-After**:遵守服务器发送的 `Retry-After` 标头
- **可配置**:模型配置中的 `maxRetries` 字段(默认:3)
## 仓库结构
```
antigravity-add-model/
├── src/
│ ├── proxy.ts # HTTP proxy + Cloud Code interceptor + format translation
│ ├── proxy/
│ │ ├── registry.ts # Auto-discovery translator registry
│ │ ├── shared.ts # Cross-turn state management + TTL cleanup
│ │ ├── modelUtils.ts # Centralized model capability detection
│ │ └── translators/
│ │ ├── openai.ts # OpenAI ↔ Gemini translator
│ │ ├── anthropic.ts # Anthropic ↔ Gemini translator
│ │ ├── google.ts # Google AI Studio passthrough + stream routing
│ │ └── utils.ts # Shared translator utilities (DSML, tool calls)
│ ├── languageServer.ts # Modified language server manager
│ ├── ipcHandlers.ts # Custom model CRUD + connectivity test IPC
│ ├── cryptoStore.ts # AES-256-GCM API key encryption/decryption
│ ├── schemaValidator.ts # Runtime schema validation for responses & models
│ ├── preload.ts # Settings UI injection (inline Add Model dashboard)
│ ├── main.ts # App lifecycle + SetCloudCodeURL blocking
│ ├── constants.ts # Port & cert constants
│ ├── paths.ts # Path utilities
│ ├── storage.ts # StorageManager class
│ ├── menu.ts # Application menu
│ ├── tray.ts # System tray
│ ├── updater.ts # Auto-updater
│ ├── customScheme.ts # Plugin scheme handler
│ ├── keybindings.ts # Keyboard shortcuts
│ ├── loadingOverlay.ts # Loading screen overlay
│ ├── types.ts # Type definitions
│ ├── utils.ts # Window management & utilities
│ ├── services/
│ │ └── settingsService.ts
│ ├── ideInstall/ # IDE installation wizard
│ ├── __tests__/ # Unit tests (vitest)
│ │ ├── registry.test.ts
│ │ ├── proxy.test.ts
│ │ ├── modelUtils.test.ts
│ │ ├── anthropic.test.ts
│ │ ├── openai.test.ts
│ │ └── utils.test.ts
│ ├── __mocks__/ # Test mocks
├── dist/ # Compiled JavaScript output
├── tsconfig.json # TypeScript configuration
├── deploy.ps1 # Portable PowerShell deploy script
├── repack.ps1 # ASAR repack script
├── package.json # Electron app manifest
└── README.md
```
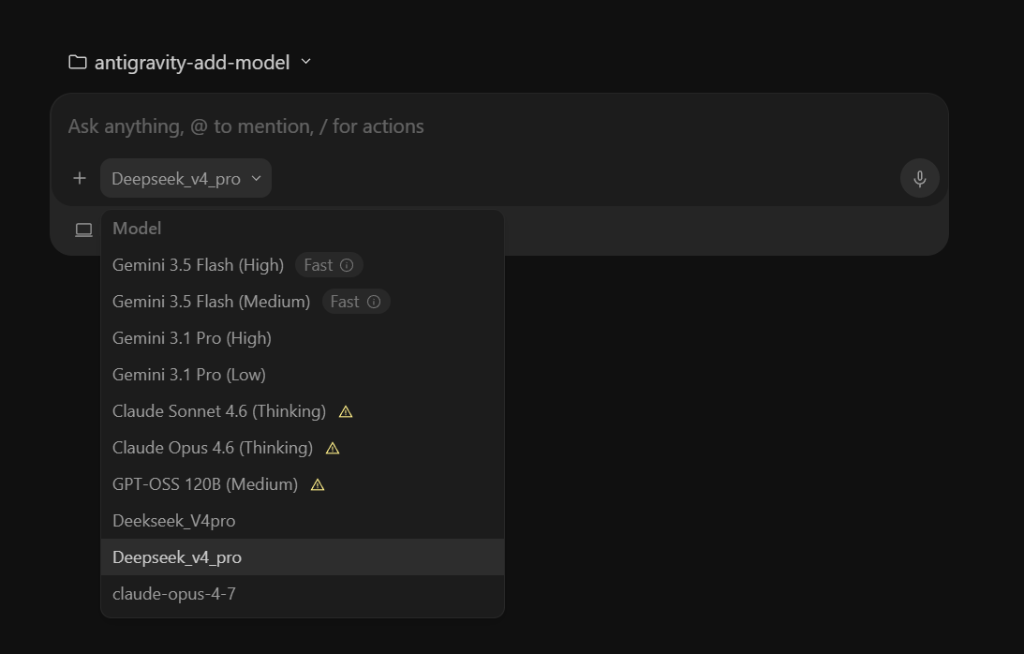
## 受支持的提供商
您可以 **同时配置来自不同提供商的多个模型**。所有这些模型都将一起显示在 Antigravity 聊天界面的模型选择下拉菜单中,您可以实时切换它们。
/app.asar"
```
- **Windows**: `C:\Users\\AppData\Local\Programs\antigravity\resources\`
- **macOS**: `/Applications/Antigravity.app/Contents/Resources/`
## Antigravity 更新恢复
### 问题所在
从 **Antigravity v2.0.6** 开始,Google 在 Language Server 的二进制文件中将 `fetchAvailableModels` API 的 URL 硬编码为 `https://daily-cloudcode-pa.googleapis.com/v1internal:fetchAvailableModels`。此调用 **完全绕过了本地代理**,这意味着:
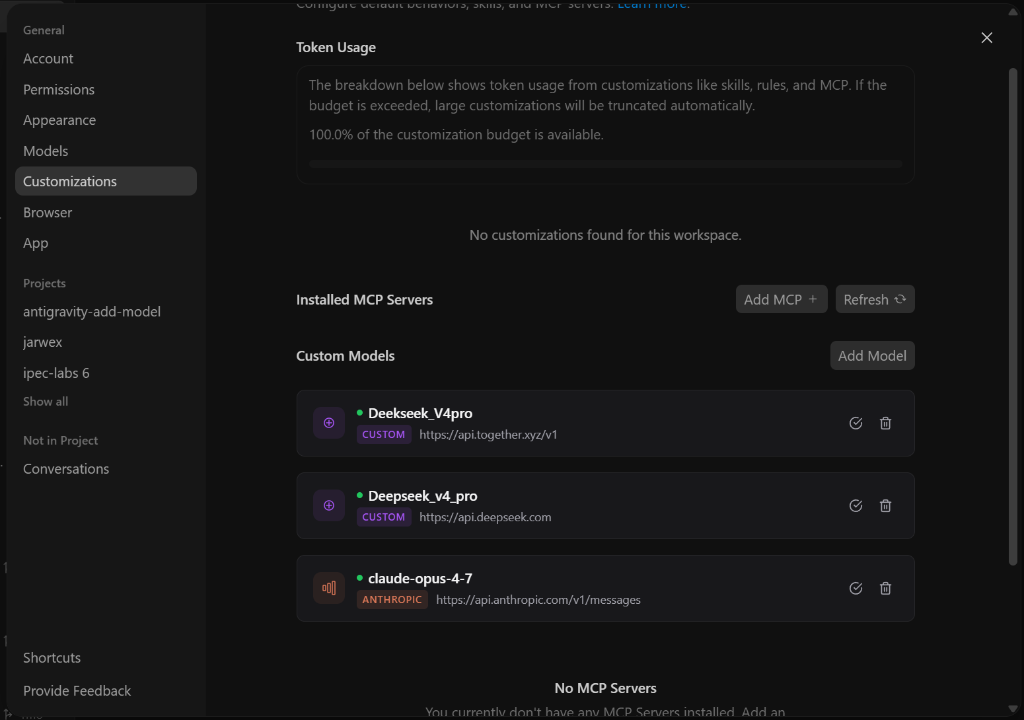
- 自定义模型保留在 `custom_models.json` 中,并出现在 **设置 → 自定义模型** 里
- 但它们 **不会出现** 在聊天模型下拉菜单中
- 聊天下拉菜单只显示 Google 内置的 Gemini 模型
### 修复方案:二进制补丁
`deploy.ps1` / `deploy.sh` / `deploy_linux.sh` 脚本会 **自动对 Language Server 可执行文件应用二进制补丁**。硬编码的 URL:
```
https://daily-cloudcode-pa.googleapis.com
```
会被替换为:
```
http://localhost:50999/v1internal/xxxxxxx
```
这会强制 Language Server 将 **所有** `fetchAvailableModels` 调用路由通过本地代理,在响应到达 Antigravity 前端之前,自定义模型就在这里被注入进去了。
### 每次 Antigravity 更新之后
当 Google 发布新的 Antigravity 版本(例如 v2.0.7、v2.1.0)时:
1. **Antigravity 自动更新** → Language Server 二进制文件被替换为未打补丁的版本
2. **自定义模型再次** 从聊天下拉菜单中消失
3. **重新运行部署脚本** 以重新应用二进制补丁:
```
# Windows (PowerShell)
npm run build
powershell -ExecutionPolicy Bypass -File ".\deploy.ps1"
```
```
# macOS / Linux
npm run build
bash deploy.sh # macOS
bash deploy_linux.sh # Linux
```
### 如何检查补丁是否生效
在启动后检查 Language Server 的日志:
```
# Windows
%APPDATA%\Antigravity\logs\language_server.log
```
如果补丁已生效,您会看到:
```
URL: http://localhost:50999/v1internal/xxxxxxx/v1internal:fetchAvailableModels
```
如果补丁未生效(更新后),您会看到:
```
URL: https://daily-cloudcode-pa.googleapis.com/v1internal:fetchAvailableModels
```
### 技术细节
二进制补丁的工作原理是:
1. **查找** LS 二进制文件中的字符串 `https://daily-cloudcode-pa.googleapis.com`(41 字节)
2. 将其 **替换** 为 `http://localhost:50999/v1internal/xxxxxxx`(正好 41 字节)
3. **URL 清理**:代理在转发至 Google 之前,会从传入请求中剥离 `/v1internal/xxxxxxx` 填充
该补丁还会影响其他硬编码的 Cloud Code 调用(`listExperiments`、`streamGenerateContent`、`loadCodeAssist`),将它们全部路由通过代理以保持行为一致。
### 手动二进制补丁(如果部署脚本失败)
```
# 查找 hardcoded URL 的 offset
$offset = (Select-String -Path "language_server.exe" -Pattern "daily-cloudcode-pa.googleapis.com" -Encoding byte).Matches[0].Index - 8
# 应用 patch
$newUrl = [System.Text.Encoding]::ASCII.GetBytes("http://localhost:50999/v1internal/xxxxxxx")
$fs = [System.IO.File]::OpenWrite("language_server.exe")
$fs.Seek($offset, [System.IO.SeekOrigin]::Begin)
$fs.Write($newUrl, 0, $newUrl.Length)
$fs.Close()
```
## 配置
模型存储在您的主目录下的 `~/.gemini/antigravity/custom_models.json` 中。您可以通过“设置”中的 **“添加模型”** 弹窗轻松添加它们,或者直接编辑 JSON 文件。
这是一个 **完整加载** 的 `custom_models.json` 文件示例,同时配置了 **跨所有提供商的多个模型**:
```
{
"models": [
{
"name": "models/gpt-4o",
"displayName": "GPT-4o (OpenAI)",
"description": "OpenAI GPT-4o model via official API",
"provider": "openai",
"apiKey": "sk-proj-...",
"apiUrl": "https://api.openai.com/v1/chat/completions",
"externalModelName": "gpt-4o"
},
{
"name": "models/claude-3-5-sonnet",
"displayName": "Claude 3.5 Sonnet",
"description": "Anthropic Claude 3.5 Sonnet via official API",
"provider": "anthropic",
"apiKey": "sk-ant-...",
"apiUrl": "https://api.anthropic.com/v1/messages",
"externalModelName": "claude-3-5-sonnet-latest"
},
{
"name": "models/gemini-1.5-pro",
"displayName": "Gemini 1.5 Pro (AI Studio)",
"description": "Gemini 1.5 Pro via Google AI Studio Key",
"provider": "google",
"apiKey": "AIzaSy...",
"apiUrl": "https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-pro:generateContent",
"externalModelName": "gemini-1.5-pro"
},
{
"name": "models/llama3",
"displayName": "Llama 3 (Local Ollama)",
"description": "Local Llama 3 model run on Ollama port 11434",
"provider": "ollama",
"apiKey": "",
"apiUrl": "http://localhost:11434/v1/chat/completions",
"externalModelName": "llama3"
},
{
"name": "models/deepseek-ai/deepseek-v4-pro",
"displayName": "DeepSeek V4 Pro (Together)",
"description": "DeepSeek V4 Pro via Together API",
"provider": "custom",
"apiKey": "YOUR_TOGETHER_API_KEY",
"apiUrl": "https://api.together.xyz/v1",
"externalModelName": "deepseek-ai/DeepSeek-V4-Pro",
"maxRetries": 3
}
]
}
```
### 字段说明
| 字段 | 描述 |
|---|---|
| `name` | 内部模型标识符(例如 `models/gpt-4o`)。必须以 `models/` 前缀开头。 |
| `displayName` | 将显示在 Antigravity 聊天模型下拉菜单中的友好名称。 |
| `description` | 显示在“设置”中“自定义模型”列表中的副标题/描述。 |
| `provider` | `openai`、`anthropic`、`openrouter`、`ollama`、`google` 或 `custom` 中的一种。这决定了如何转换请求和响应格式。 |
| `apiKey` | 提供商的 API 凭证。对于 Ollama 等本地提供商,请留空 `""`。 |
| `apiUrl` | 目标端点。这会根据 UI 下拉菜单的选择自动预填充。 |
| `externalModelName` | 目标提供商期望的精确模型 ID(例如,`gpt-4o`、`claude-3-5-sonnet-latest`、`llama3`)。 |
| `allowUnauthorized` | (可选)设置为 `true` 可绕过 SSL 证书验证。适用于内部/自签名端点。默认值:`false`。 |
| `timeout` | (可选)请求超时时间(以毫秒为单位)。默认值:`120000`(2 分钟)。 |
| `maxRetries` | (可选)对受到速率限制/失败的请求的最大重试次数。默认值:`3`。 |
## UI 功能
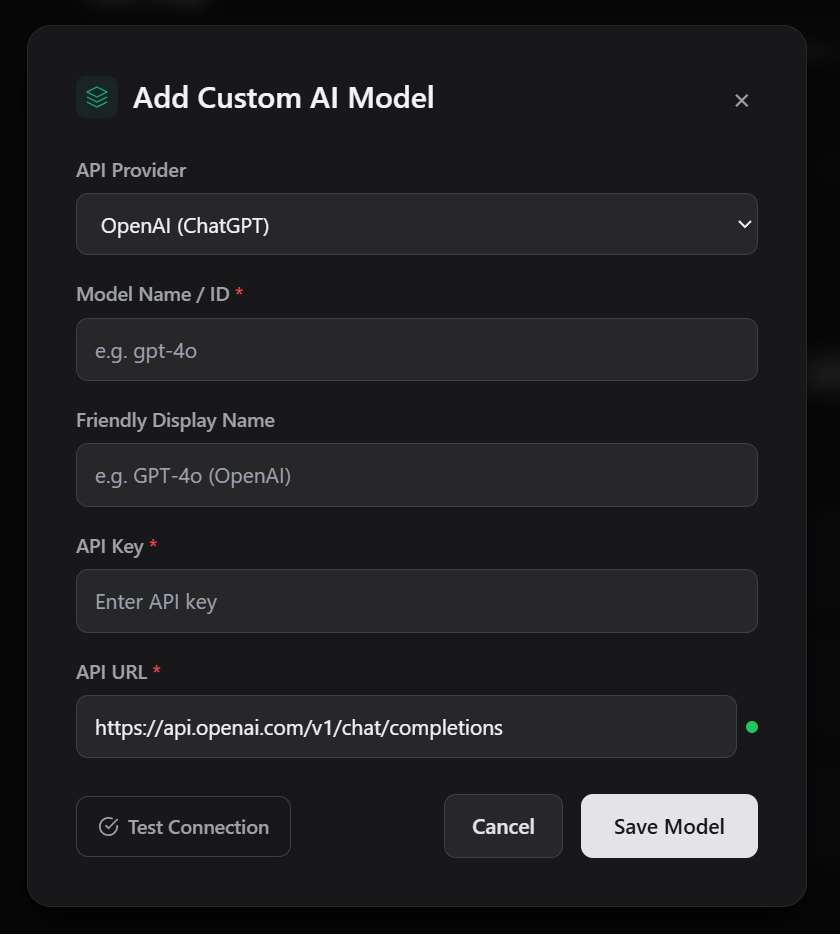
### 添加模型弹窗
点击“设置” → 模型中的 **“添加模型”** 按钮,打开一个精美的弹窗,包含:
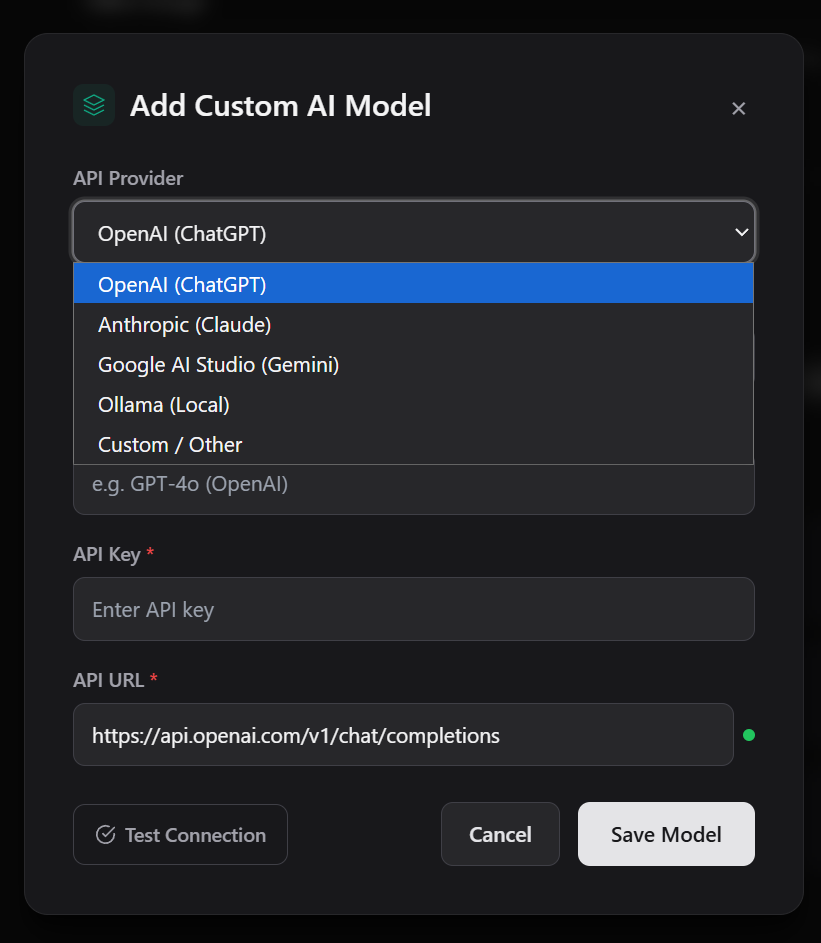
- 提供商下拉菜单(OpenAI、Anthropic、Google AI Studio、Ollama、OpenRouter、自定义)
- 根据选择的提供商自动预填充 URL
- 在您输入模型 ID 时动态生成 Google AI Studio URL
- 带有背景模糊的平滑进入/退出动画
- 表单验证(必填字段:模型 ID、API 密钥、API URL)
- 如果留空则自动生成显示名称
`)
2. 增加模型配置中的 `timeout` 字段(例如,`"timeout": 180000` 表示 3 分钟)
3. 验证网络/代理/VPN 设置
### 速率限制 (429)
代理会自动以指数退避方式最多重试 3 次。如果您仍然看到速率限制错误:
1. 降低请求频率
2. 增加模型配置中的 `maxRetries`
3. 检查您的 API 提供商的速率限制仪表板
## 开发者指南
### 项目设置
```
npm install # Install dependencies
npx tsc # Compile TypeScript → dist/
npx tsc --watch # Watch mode for development
```
### 添加新的提供商
1. 创建 `src/proxy/translators/.ts` 并包含以下导出:
- `mapGeminiTo(geminiBody, modelName)` → 提供商格式的请求
- `mapToGemini(providerRes, modelName)` → Gemini 格式的响应
- `mapChunkToGemini(chunk, modelName)` → 流式数据块处理程序
2. 注册表会自动发现新的翻译器模块,因此无需更改配置
3. 如果身份验证方式不同,请将提供商添加到 `registry.ts` 中的 `getProviderHeaders()`
4. 将提供商选项添加到 `src/preload.ts` 的 UI 下拉菜单中
5. 如果适用,请更新 `registry.ts` 中的 `supportsStreaming()`
### TypeScript 架构
- **严格模式**:`tsconfig.json` 中设置 `strict: true`(target: ES2020, module: CommonJS)
- **集中的类型定义**:模型能力在 `modelUtils.ts` 中,共享状态在 `shared.ts` 中
- **无 `eval()`**:JSON 修复使用 `repairPartialJson()`,而不是危险的 `eval()` 调用
- **关键路径中无 `any`**:请求/响应映射使用显式的接口
### 调试模式
```
$env:HEADLESS="1"; .\Antigravity.exe
```
设置 `DEBUG=antigravity:*` 以获取详细的日志记录(调试级别会捕获流解析回退和底层传输细节)。
## 更新日志
### v2.1.0
- **TypeScript**:全面迁移 — 所有 23 个源文件均从 JavaScript 转换为 TypeScript(`dist/*.js` → `src/*.ts`)
- **新提供商**:支持 OpenRouter(通过统一的 API 提供 300 多种模型,兼容 OpenAI 格式)
- **OpenRouter**:提供商下拉菜单、自动填充的 URL、连接测试、设置弹窗中的图标和颜色
- **开发体验**:配置了 ESLint + Prettier,并带有自动化的 `lint`、`format`、`lint:fix` 脚本
- **测试覆盖率**:扩展至涵盖 6 个测试文件(注册表、代理、modelUtils、翻译器)的 137 个测试
- **清理**:移除了 25 多个临时开发产物,添加了 `.prettierignore`
- **架构**:将 `ideInstall/` 向导提取到专用的 TypeScript 模块中
### v2.0.3
- **架构**:将 Google AI Studio 翻译器提取到专用模块
- **架构**:管理具有适当间隔生命周期的代理状态清理
- **新增**:设置中的模型连接测试(绿色/红色状态指示器)
- **新增**:带有指数退避的自动请求重试 (429/5xx)
- **新增**:每个模型可配置的 `maxRetries`
- **安全**:移除了对自定义提供商的自动 SSL 绕过
- **安全**:添加了 10MB 的请求正文大小限制(超出时返回 413)
- **安全**:在控制台输出中掩码处理 CSRF token
- **安全**:为所有 Google 代理请求添加了超时(30-60秒)
- **错误处理**:为之前静默的 6 个 catch 块添加了调试日志
- **错误处理**:在流式响应处理程序中正确传播错误
- **修复**:`deploy.ps1` 现在使用 `$PSScriptRoot`(可移植,无硬编码路径)
- **文档**:更新了 README,包含 TypeScript 架构、安全默认值和故障排除
- **包**:在 `package.json` 中添加了 `Apache-2.0` 许可证字段
### v2.0.2
- **安全**:使用安全的 `repairPartialJson()` 替换了 `eval()`(修复代码注入问题)
- **安全**:仅在 `allowUnauthorized: true` 时才进行 SSL 绕过(不适用于所有自定义提供商)
- **安全**:移除了向磁盘写入诊断性 `api_response_raw.json` 的操作
- **安全**:添加了 10MB 的请求正文大小限制
- **安全**:添加了 120 秒的可配置 API 请求超时
- **错误处理**:为流式和非流式 API 响应添加了错误处理程序
- **修复**:`deploy.ps1` 的硬编码路径现在使用 `$PSScriptRoot`
- **文档**:添加了安全考量、故障排除和开发者指南
### v2.0.2 (2026-05-24)
- **关键修复**:Antigravity v2.0.6 更新将 `fetchAvailableModels` URL 硬编码为 `daily-cloudcode-pa.googleapis.com`,绕过了本地代理。自定义模型从聊天下拉菜单中消失了。
- **二进制补丁**:现在会在构建时自动对 Language Server 二进制文件进行补丁处理,将硬编码的 Google URL 替换为本地代理 URL。
- **URL 填充处理程序**:在代理中添加了基于正则表达式的 URL 清理,以剥离二进制补丁的填充。
- **模型 API 回退**:添加了 `GetAvailableModels` 重定向、预加载网络拦截器以及强制页面重载,以确保在各种 Antigravity 版本中都能稳健地加载模型。
### v2.0.0
- 初版发布:多提供商代理、API 密钥加密、流式传输、工具调用、自定义 UI
## 贡献
欢迎提交 Pull request。请确保:
1. 代码遵循现有风格(JSDoc 注释、一致的错误处理)
2. 新的提供商翻译器包含请求和响应的映射
3. 安全敏感的代码避免使用 `eval`、记录明文密钥以及不当的 SSL 处理
4. TypeScript 编译无误:`npx tsc --noEmit`
## 许可证
Apache License 2.0。详情请参阅 [LICENSE](LICENSE)。
## 开发者
**Abdulvahap OGUT**
[](https://www.linkedin.com/in/abdulvahap-ogut-343992398/)
标签:AI集成, API转换, LLM评估, MITM代理, Ollama, OpenAI, SOC Prime, 云资产清单, 内存规避, 开发工具, 本地代理, 自动化攻击, 逆向工程