ipanalytics/CrawlerScope
GitHub: ipanalytics/CrawlerScope
CrawlerScope 是一个爬虫 IP 智能数据管道,用于收集和规范自动化流量的 IP 范围,支持安全策略设计与运维优化。
Stars: 1 | Forks: 0
# on the instruction, I keep technical terms in English.
## 架构
CrawlerScope 作为定时 GitHub Actions 收集器运行,并发布静态工件。
```
flowchart LR
A["config/sources.json"] --> B["scripts/update.py"]
B --> C["Fetch operator sources"]
C --> D["Normalize and collapse CIDR prefixes"]
D --> E["data/current/crawlers.json"]
D --> F["data/current/robots-ai.txt"]
D --> G["data/current/nginx-ai-map.conf"]
D --> H["data/snapshots/*.json"]
E --> I["Static dashboard"]
H --> J["GitHub Release artifacts"]
```
源类型:
| 类型 | 含义 |
|---|---|
| `official_json` | 运营商发布的机器可读 JSON 订阅源 |
| `official_text` | 运营商发布的纯文本 CIDR/IP 订阅源 |
| `official_embedded_json` | 运营商页面,其中嵌入了机器可读的范围 |
| `documented_user_agent` | 记录的机器人身份,但无稳定的公共 IP 列表 |
| `known_static` | 有用的静态种子列表,不被视为完全权威 |
## 功能
- 运营商发布的源收集,带源健康跟踪。
- IPv4/IPv6 规范化、CIDR 转换和前缀聚合。
- 静态仪表板,支持按类别、运营商、源、服务和搜索进行筛选。
- 支持导出为 JSON、CSV、CIDR 列表、`robots.txt` 和 Nginx 用户代理映射。
- 快照保留和历史摘要跟踪。
- GitHub Pages 发布和自动数据集发布。
- 基于配置的源清单,位于 [`config/sources.json`](./config/sources.json)。
## 快速开始
运行收集器并在本地提供仪表板服务:
```
python3 scripts/update.py
python3 -m http.server 8080
```
打开:
```
http://127.0.0.1:8080/public/
```
从 `public/` 目录提供服务时,应用从 `../data/current` 读取数据。对于 GitHub Pages 部署,工作流会将 `public/` 和 `data/` 复制到 Pages 工件中。
## 安装说明
CrawlerScope 在数据收集方面除了 Python 标准库外,没有其他运行时依赖项。
```
git clone https://github.com/ipanalytics/CrawlerScope.git
cd CrawlerScope
python3 scripts/update.py
```
可选的环境控制:
```
export CRAWLER_SCOPE_USER_AGENT="CrawlerScope/0.1 (+https://example.org/contact)"
export CRAWLER_SCOPE_SNAPSHOT_RETENTION=168
export CRAWLER_SCOPE_HISTORY_RETENTION=720
python3 scripts/update.py
```
## 用法示例
导出所有当前 CIDR:
```
jq -r '.services[].prefixes | .ipv4[], .ipv6[]' data/current/crawlers.json
```
导出 AI 爬虫 CIDR:
```
jq -r '.services[] | select(.category == "ai") | .prefixes | .ipv4[], .ipv6[]' data/current/crawlers.json
```
列出已记录但不发布 IP 范围的源:
```
jq -r '.services[] | select(.sourceType == "documented_user_agent") | [.id, .service, .sourceUrl] | @tsv' data/current/crawlers.json
```
根据当前数据集生成 Nginx 包含文件:
```
cp data/current/nginx-ai-map.conf /etc/nginx/conf.d/crawler-scope-ai-map.conf
nginx -t
```
## 输出
| 路径 | 描述 |
|---|---|
| [`data/current/crawlers.json`](./data/current/crawlers.json) | 完整的规范化数据集 |
| [`data/current/robots-ai.txt`](./data/current/robots-ai.txt) | 生成的 AI 爬虫 `robots.txt` 封锁规则 |
| [`data/current/nginx-ai-map.conf`](./data/current/nginx-ai-map.conf) | 用于 AI 爬虫用户代理的 Nginx `map` 配置 |
| [`data/history/summary.csv`](./data/history/summary.csv) | 历史摘要行 |
| [`data/snapshots/*.json`](./data/snapshots) | 带时间戳的数据集快照 |
| [`config/sources.json`](./config/sources.json) | 源清单和分类配置 |
## 数据格式
每条服务记录包括源元数据、用户代理模式、反向 DNS 提示、健康状态、前缀计数以及分离的 IPv4/IPv6 数组。
```
{
"id": "openai-gptbot",
"service": "GPTBot",
"operator": "OpenAI",
"category": "ai",
"sourceType": "official_json",
"sourceOk": true,
"ipListAuthoritative": true,
"userAgentPatterns": ["GPTBot"],
"counts": {
"prefixes": 17,
"ipv4": 17,
"ipv6": 0
},
"prefixes": {
"ipv4": ["20.42.10.176/28"],
"ipv6": []
}
}
```
## 操作说明
- 将 `sourceOk=false` 视为该次运行的收集失败。收集器在可用时会回退到先前缓存的前缀。
- IP 范围识别的是已发布的基础设施,而非意图。在执行风险相关时,请使用用户代理、反向 DNS、请求行为和应用上下文。
- 包含静态和仅记录的源是因为它们在操作上有用,但权威标志仍然分开。
- 发布工件由 GitHub Actions 在收集后生成,并附加到带时间戳的数据集发布中。
## 项目范围
CrawlerScope 跟踪公共的爬虫、抓取器、监控器、扫描器、分析器和预览机器人基础设施,这些基础设施对请求分类和网络策略有用。它优先考虑主要运营商发布的源。可能会审查聚合库以进行发现,但其 URL 不用作数据集源。
## 用例
- 针对爬虫流量的 WAF 白名单/黑名单策略设计。
- 搜索和 AI 爬虫可见性审计。
- 安全日志丰富和机器人归因。
- 监控探测器白名单。
- 自动化流量的欺诈/风险分流。
- 已发布爬虫基础设施的变更跟踪。
## 局限性
- 某些运营商发布了用户代理文档,但没有稳定的 IP 订阅源。
- 云托管的爬虫可能与不相关的工作负载共享网络空间。
- CIDR 列表可能在未通知的情况下发生变化;定时收集可以减少但不能消除这种延迟。
## 目录结构
```
.
├── config/
│ └── sources.json
├── data/
│ ├── current/
│ ├── history/
│ └── snapshots/
├── public/
│ ├── assets/
│ └── index.html
├── scripts/
│ └── update.py
└── .github/
└── workflows/
```
## 部署
包含的工作流每六小时运行一次,也可以手动触发:
```
on:
schedule:
- cron: "23 */6 * * *"
workflow_dispatch:
```
工作流步骤:
1. 运行 `scripts/update.py`。
2. 提交更新后的 `data/` 和 `config/` 更改。
3. 发布带时间戳的 GitHub Release,包含数据集工件。
4. 将静态仪表板部署到 GitHub Pages。
## 许可证
CrawlerScope 在 [MIT 许可证](./LICENSE) 下发布。
## 免责声明
CrawlerScope 发布来自公共运营商源的规范数据。在生产控制中使用数据集之前,请审查上游条款并验证执行逻辑。
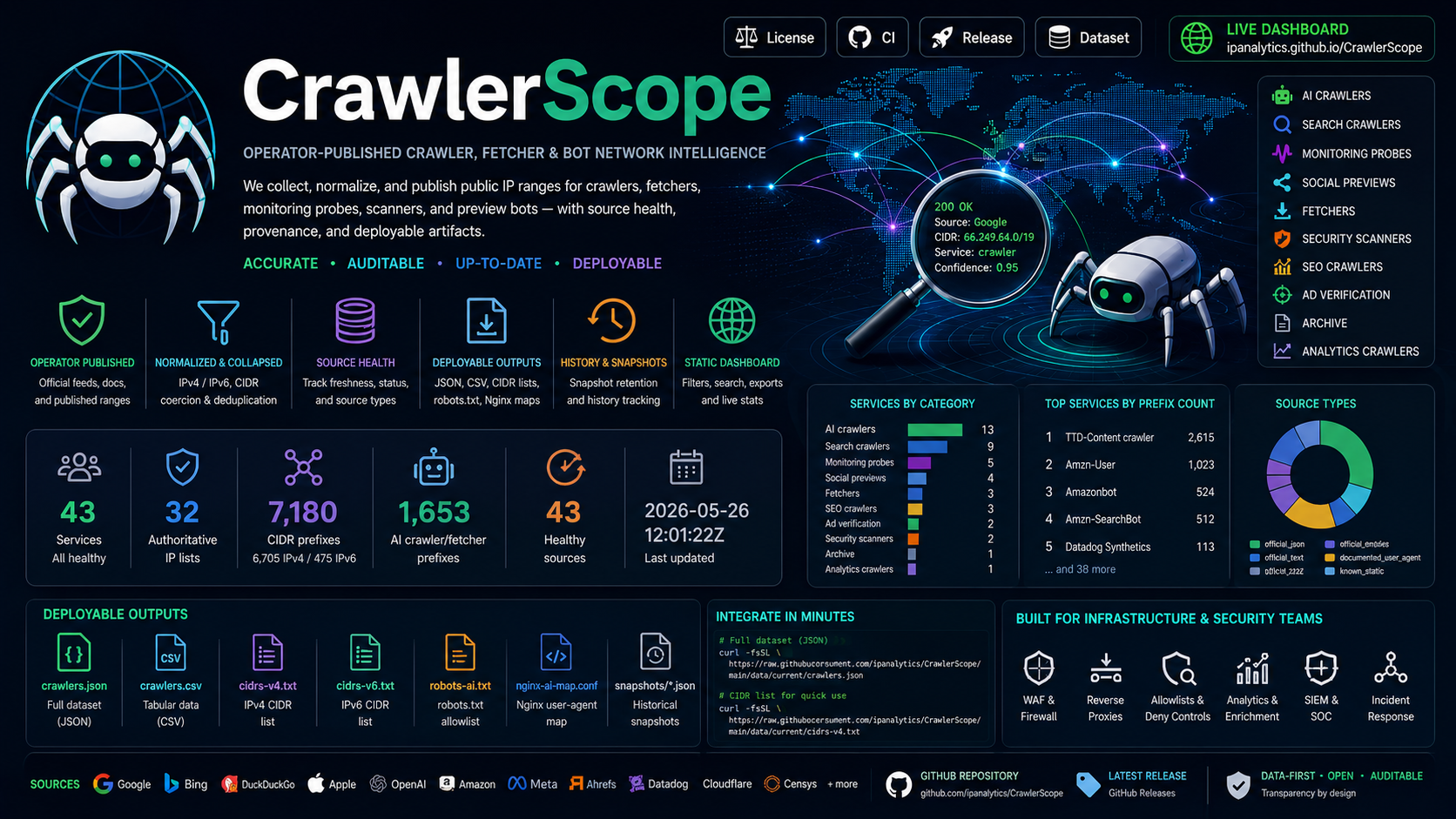

跟踪的服务
| 服务 | 类别 | 源类型 | 前缀 | |---|---|---|---:| | Google 通用爬虫 | search | official_json | 69 | | Google 特殊爬虫 | search | official_json | 46 | | Google 用户触发抓取器 | fetcher | official_json | 223 | | Bingbot | search | official_json | 28 | | DuckDuckBot | search | official_json | 334 | | DuckAssistBot | ai | official_json | 334 | | Applebot | search | official_json | 12 | | MojeekBot | search | official_json | 1 | | Naver Yeti | search | official_json | 36 | | YandexBot | search | known_static | 13 | | Baiduspider | search | known_static | 2 | | GPTBot | ai | official_json | 17 | | OAI-SearchBot | ai | official_json | 32 | | ChatGPT-User | ai | official_json | 214 | | OAI-AdsBot | ai | documented_user_agent | 0 | | PerplexityBot | ai | official_json | 8 | | Perplexity-User | ai | official_json | 4 | | ClaudeBot / Claude-SearchBot | ai | documented_user_agent | 0 | | Amazonbot | ai | official_embedded_json | 524 | | Amzn-SearchBot | ai | official_embedded_json | 512 | | Amzn-User | fetcher | official_embedded_json | 1,023 | | Meta-ExternalAgent / Meta-WebIndexer | ai | known_static | 4 | | Bytespider | ai | documented_user_agent | 0 | | MistralAI-User | ai | official_json | 4 | | AhrefsBot | seo | official_json | 51 | | Lumar crawler | seo | official_json | 66 | | SemrushBot | seo | documented_user_agent | 0 | | Censys 扫描器 | security-scanner | known_static | 2 | | Shodan 扫描器 | security-scanner | known_static | 9 | | Datadog Synthetics | monitoring | official_json | 113 | | IAS 爬虫 | ad-verification | official_json | 14 | | TTD-Content 爬虫 | ad-verification | official_text | 2,615 | | UptimeRobot | monitoring | official_text | 217 | | Pingdom 探测器 | monitoring | official_text | 158 | | StatusCake 探测器 | monitoring | official_json | 296 | | Better Stack 探测器 | monitoring | official_text | 34 | | Common Crawl CCBot | archive | official_json | 6 | | Flipboard 爬虫 | social | official_text | 136 | | Parse.ly 爬虫 | analytics | official_json | 10 | | Pinterestbot | social | documented_user_agent | 0 | | LinkedInBot | social | documented_user_agent | 0 | | Telegram 链接预览 | social | official_text | 11 | | RSS API 订阅源解析器 | fetcher | official_text | 2 |标签:AI集成, CIDR管理, GitHub Pages, Homebrew安装, IP情报, Python开发, WAF规则, 事件分类, 反向代理配置, 基础设施管理, 搜索引擎优化, 数据仪表板, 机器可读数据, 爬虫情报, 爬虫监控, 用户触发操作, 网络安全, 网络范围规范化, 自定义脚本, 逆向工具, 隐私保护, 静态网站