Mr-GauravKumar/Malware-Threat-Prediction-using-Machine-Learning-Kaggle-Classification-Project
GitHub: Mr-GauravKumar/Malware-Threat-Prediction-using-Machine-Learning-Kaggle-Classification-Project
这是一个利用机器学习分析系统遥测数据,以预测恶意软件感染风险的分类项目。
Stars: 0 | Forks: 0
# 使用机器学习预测恶意软件威胁
构建了一个机器学习分类模型,利用系统遥测数据和杀毒软件威胁数据预测恶意软件感染风险。使用 Python 和 Scikit-learn 进行了数据预处理、缺失值处理、特征工程和分类编码,以提升分类性能和恶意软件威胁检测准确率。
# 项目概述
本项目旨在构建一个机器学习分类系统,该系统能够利用系统遥测数据和杀毒软件威胁报告数据来预测恶意软件感染风险。项目的目标是分析设备行为模式和安全相关信息,以确定系统是否可能被恶意软件感染。
## SHAP 特征重要性分析
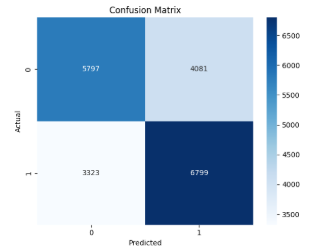
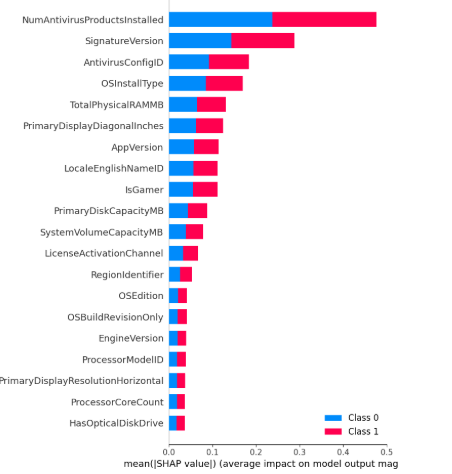 ## 混淆矩阵
混淆矩阵详细列出了分类模型做出的正确和错误预测。
它有助于评估模型准确识别恶意软件威胁的能力,同时最大限度地减少误报和漏报。
## 混淆矩阵
混淆矩阵详细列出了分类模型做出的正确和错误预测。
它有助于评估模型准确识别恶意软件威胁的能力,同时最大限度地减少误报和漏报。
 # 本项目展示了完整的端到端机器学习工作流程,包括:
* 数据理解
* 探索性数据分析 (EDA)
* 数据预处理
* 缺失值处理
* 特征工程
* 分类特征编码
* 模型构建
* 模型评估
* 恶意软件威胁预测
本项目是一个基于 Kaggle 的机器学习分类项目,使用 Python 和 Scikit-learn 开发。
# 问题陈述
## 现代计算机系统会产生大量的遥测数据,例如:
操作系统信息
杀毒软件状态
设备配置
安全设置
系统行为日志
威胁检测报告
这些数据可用于识别系统是否易受恶意软件攻击。
本项目的目标是:
构建一个基于系统遥测和杀毒软件威胁数据,能够预测恶意软件感染风险的机器学习模型。
该问题被视为一个分类问题,因为模型预测的是系统是否属于恶意软件感染类别。
# 数据集理解
数据集包含从设备和杀毒软件系统收集的系统遥测信息。
数据集包括:
数值型特征
分类型特征
设备相关信息
安全相关配置
威胁报告信息
目标变量代表恶意软件感染状态或恶意软件相关分类标签。
# 使用的技术
编程语言
Python
使用的库
Pandas
NumPy
Matplotlib
Seaborn
Scikit-learn
项目工作流程
本项目遵循结构化的机器学习流程。
# 步骤 1:导入库
笔记本中的第一步是导入所需的 Python 库。
这些库用于:
| 库 | 用途 |
| :-------- | :--------------- |
| Pandas | 数据处理与分析 |
| NumPy | 数值运算 |
| Matplotlib | 数据可视化 |
| Seaborn | 统计可视化 |
| Scikit-learn | 机器学习建模 |
执行的示例任务包括:
读取数据集
处理缺失值
可视化分布
编码分类特征
训练分类模型
# 步骤 2:加载数据集
数据集被加载到 Pandas DataFrame 中。
此步骤允许:
读取 CSV 文件
检查行和列
了解数据集维度
验证数据类型
使用的函数:
pd.read_csv()
df.head()
df.info()
df.shape()
df.describe()
目的:
在预处理之前了解数据集的结构。
# 步骤 3:探索性数据分析 (EDA)
进行 EDA 以深入理解数据集。
笔记本包括:
数据集结构分析
数据类型检查
缺失值分析
描述性统计
特征分布分析
EDA 有助于识别:
空值
不平衡的特征
数据不一致
潜在的预处理需求
使用的函数:
isnull().sum()
describe()
value_counts()
# EDA 的重要性:
EDA 至关重要,因为机器学习模型严重依赖数据质量。
低质量数据会导致:
模型准确率低
过拟合
泛化能力差
# 步骤 4:缺失值处理
数据集在多个特征中包含缺失值。
之所以处理缺失值,是因为机器学习算法无法直接处理不完整的数据。
# 使用的技术:
空值检测
缺失值替换
数据清理
# 常见方法:
| 数据类型 | 处理方法 |
| :------- | :----------------- |
| 数值型 | 均值/中位数填充 |
| 分类型 | 众数填充 |
目标:
提高数据质量
防止训练错误
提升模型性能
# 步骤 5:特征工程
# 特征工程是本项目中最重要的步骤之一。
# 此步骤将原始数据转换为有用的机器学习特征。
# 执行的任务:
# 本项目展示了完整的端到端机器学习工作流程,包括:
* 数据理解
* 探索性数据分析 (EDA)
* 数据预处理
* 缺失值处理
* 特征工程
* 分类特征编码
* 模型构建
* 模型评估
* 恶意软件威胁预测
本项目是一个基于 Kaggle 的机器学习分类项目,使用 Python 和 Scikit-learn 开发。
# 问题陈述
## 现代计算机系统会产生大量的遥测数据,例如:
操作系统信息
杀毒软件状态
设备配置
安全设置
系统行为日志
威胁检测报告
这些数据可用于识别系统是否易受恶意软件攻击。
本项目的目标是:
构建一个基于系统遥测和杀毒软件威胁数据,能够预测恶意软件感染风险的机器学习模型。
该问题被视为一个分类问题,因为模型预测的是系统是否属于恶意软件感染类别。
# 数据集理解
数据集包含从设备和杀毒软件系统收集的系统遥测信息。
数据集包括:
数值型特征
分类型特征
设备相关信息
安全相关配置
威胁报告信息
目标变量代表恶意软件感染状态或恶意软件相关分类标签。
# 使用的技术
编程语言
Python
使用的库
Pandas
NumPy
Matplotlib
Seaborn
Scikit-learn
项目工作流程
本项目遵循结构化的机器学习流程。
# 步骤 1:导入库
笔记本中的第一步是导入所需的 Python 库。
这些库用于:
| 库 | 用途 |
| :-------- | :--------------- |
| Pandas | 数据处理与分析 |
| NumPy | 数值运算 |
| Matplotlib | 数据可视化 |
| Seaborn | 统计可视化 |
| Scikit-learn | 机器学习建模 |
执行的示例任务包括:
读取数据集
处理缺失值
可视化分布
编码分类特征
训练分类模型
# 步骤 2:加载数据集
数据集被加载到 Pandas DataFrame 中。
此步骤允许:
读取 CSV 文件
检查行和列
了解数据集维度
验证数据类型
使用的函数:
pd.read_csv()
df.head()
df.info()
df.shape()
df.describe()
目的:
在预处理之前了解数据集的结构。
# 步骤 3:探索性数据分析 (EDA)
进行 EDA 以深入理解数据集。
笔记本包括:
数据集结构分析
数据类型检查
缺失值分析
描述性统计
特征分布分析
EDA 有助于识别:
空值
不平衡的特征
数据不一致
潜在的预处理需求
使用的函数:
isnull().sum()
describe()
value_counts()
# EDA 的重要性:
EDA 至关重要,因为机器学习模型严重依赖数据质量。
低质量数据会导致:
模型准确率低
过拟合
泛化能力差
# 步骤 4:缺失值处理
数据集在多个特征中包含缺失值。
之所以处理缺失值,是因为机器学习算法无法直接处理不完整的数据。
# 使用的技术:
空值检测
缺失值替换
数据清理
# 常见方法:
| 数据类型 | 处理方法 |
| :------- | :----------------- |
| 数值型 | 均值/中位数填充 |
| 分类型 | 众数填充 |
目标:
提高数据质量
防止训练错误
提升模型性能
# 步骤 5:特征工程
# 特征工程是本项目中最重要的步骤之一。
# 此步骤将原始数据转换为有用的机器学习特征。
# 执行的任务:
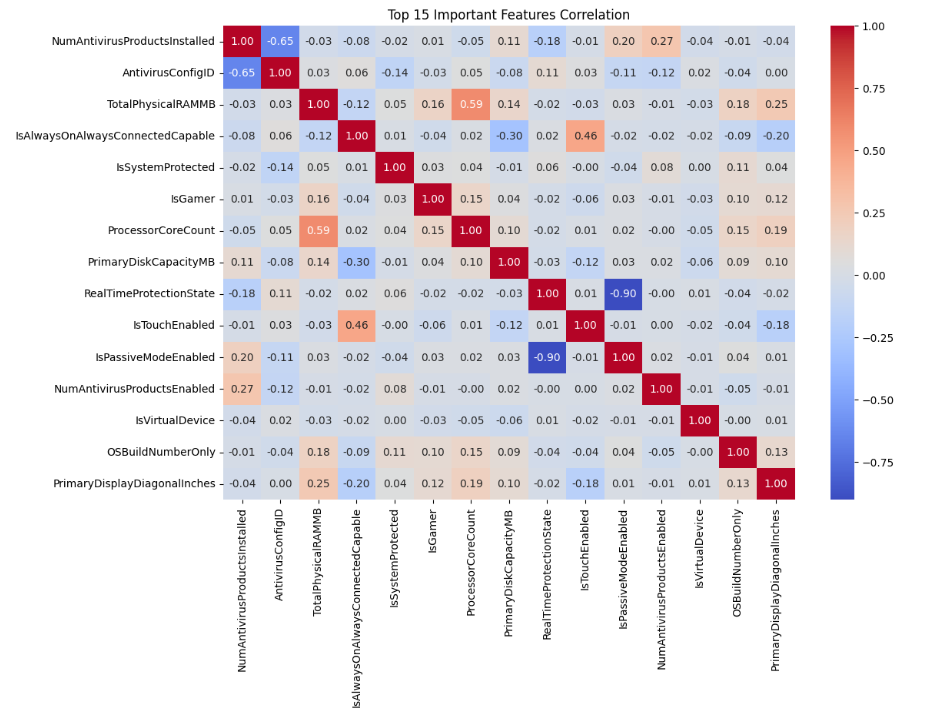 此热力图突显了为恶意软件威胁预测所选出的前 15 个最重要特征之间的相关性。特征间的强正相关和负相关关系有助于识别依赖关系、多重共线性以及对改善模型性能和特征选择有用的关键模式。
选择有用的列
移除不必要的信息
转换特征
准备模型就绪的输入
# 特征工程改善:
模型学习能力
预测质量
泛化性能
# 步骤 6:分类特征编码
数据集包含分类变量,例如:
设备配置
安全设置
系统标签
机器学习模型无法直接处理文本分类。
因此,需要应用编码技术。
编码将类别转换为数值表示。
常见的编码方法:
标签编码
独热编码
目的:
将分类数据转换为机器可读格式。
# 步骤 7:数据预处理
数据预处理为机器学习准备数据集。
包含的任务:
清理数据
处理缺失值
编码分类变量
组织特征
此步骤确保:
更好的模型训练
减少错误
提高预测性能
# 步骤 8:模型构建
## 使用 Scikit-learn 训练机器学习分类模型。
模型的目标是:
利用遥测数据预测恶意软件感染风险。
分类模型从历史系统行为中学习模式。
输入:
遥测特征
杀毒软件报告数据
输出:
恶意软件感染预测
模型识别系统特征与恶意软件威胁之间的关系。
# 步骤 9:模型评估
训练后,评估模型以衡量性能。
评估很重要,因为它有助于确定:
预测质量
模型可靠性
泛化能力
分类问题中常用的评估指标:
| 指标 | 目的 |
| :------- | :--------------------------------- |
| 准确率 | 整体预测正确性 |
| 精确率 | 正确的阳性预测比例 |
| 召回率 | 检测能力 |
| F1分数 | 精确率与召回率之间的平衡 |
笔记本重点介绍了如何使用预处理和机器学习技术提高恶意软件威胁检测性能。
# 项目成果
最终系统成功地:
从遥测数据中学习了模式
识别了与恶意软件相关的风险
提高了分类性能
展示了机器学习在网络安全领域的实际应用
该项目展示了机器学习如何应用于:
威胁检测
风险分析
安全预测系统
网络安全自动化
# 展示的关键技能
# 本项目展示了对以下方面的实践理解:
机器学习
分类建模
模型评估
预测系统
数据科学
探索性数据分析
数据预处理
缺失值处理
特征工程
Python 库
Pandas
NumPy
Matplotlib
Seaborn
Scikit-learn
网络安全分析
恶意软件威胁预测
系统遥测分析
杀毒软件报告分析
遇到的挑战
# 本项目中的一些重要挑战包括:
处理大型结构化数据集
管理缺失值
处理分类特征
提高模型性能
组织预处理工作流
这些挑战通过以下方式解决:
适当的预处理
特征转换
数据清理技术
结构化的机器学习工作流
结论
本项目成功展示了一个利用系统遥测和杀毒软件威胁报告数据进行恶意软件威胁预测的端到端机器学习工作流程。
# 该项目涉及:
数据分析
数据预处理
特征工程
分类编码
分类建模
性能评估
最终模型能够通过学习系统行为和遥测特征的模式来预测恶意软件感染风险。
本项目突出了机器学习技术在网络安全领域的应用,并展示了使用 Python 和 Scikit-learn 构建预测分析系统的实践经验。
此热力图突显了为恶意软件威胁预测所选出的前 15 个最重要特征之间的相关性。特征间的强正相关和负相关关系有助于识别依赖关系、多重共线性以及对改善模型性能和特征选择有用的关键模式。
选择有用的列
移除不必要的信息
转换特征
准备模型就绪的输入
# 特征工程改善:
模型学习能力
预测质量
泛化性能
# 步骤 6:分类特征编码
数据集包含分类变量,例如:
设备配置
安全设置
系统标签
机器学习模型无法直接处理文本分类。
因此,需要应用编码技术。
编码将类别转换为数值表示。
常见的编码方法:
标签编码
独热编码
目的:
将分类数据转换为机器可读格式。
# 步骤 7:数据预处理
数据预处理为机器学习准备数据集。
包含的任务:
清理数据
处理缺失值
编码分类变量
组织特征
此步骤确保:
更好的模型训练
减少错误
提高预测性能
# 步骤 8:模型构建
## 使用 Scikit-learn 训练机器学习分类模型。
模型的目标是:
利用遥测数据预测恶意软件感染风险。
分类模型从历史系统行为中学习模式。
输入:
遥测特征
杀毒软件报告数据
输出:
恶意软件感染预测
模型识别系统特征与恶意软件威胁之间的关系。
# 步骤 9:模型评估
训练后,评估模型以衡量性能。
评估很重要,因为它有助于确定:
预测质量
模型可靠性
泛化能力
分类问题中常用的评估指标:
| 指标 | 目的 |
| :------- | :--------------------------------- |
| 准确率 | 整体预测正确性 |
| 精确率 | 正确的阳性预测比例 |
| 召回率 | 检测能力 |
| F1分数 | 精确率与召回率之间的平衡 |
笔记本重点介绍了如何使用预处理和机器学习技术提高恶意软件威胁检测性能。
# 项目成果
最终系统成功地:
从遥测数据中学习了模式
识别了与恶意软件相关的风险
提高了分类性能
展示了机器学习在网络安全领域的实际应用
该项目展示了机器学习如何应用于:
威胁检测
风险分析
安全预测系统
网络安全自动化
# 展示的关键技能
# 本项目展示了对以下方面的实践理解:
机器学习
分类建模
模型评估
预测系统
数据科学
探索性数据分析
数据预处理
缺失值处理
特征工程
Python 库
Pandas
NumPy
Matplotlib
Seaborn
Scikit-learn
网络安全分析
恶意软件威胁预测
系统遥测分析
杀毒软件报告分析
遇到的挑战
# 本项目中的一些重要挑战包括:
处理大型结构化数据集
管理缺失值
处理分类特征
提高模型性能
组织预处理工作流
这些挑战通过以下方式解决:
适当的预处理
特征转换
数据清理技术
结构化的机器学习工作流
结论
本项目成功展示了一个利用系统遥测和杀毒软件威胁报告数据进行恶意软件威胁预测的端到端机器学习工作流程。
# 该项目涉及:
数据分析
数据预处理
特征工程
分类编码
分类建模
性能评估
最终模型能够通过学习系统行为和遥测特征的模式来预测恶意软件感染风险。
本项目突出了机器学习技术在网络安全领域的应用,并展示了使用 Python 和 Scikit-learn 构建预测分析系统的实践经验。
## 混淆矩阵
混淆矩阵详细列出了分类模型做出的正确和错误预测。
它有助于评估模型准确识别恶意软件威胁的能力,同时最大限度地减少误报和漏报。
# 本项目展示了完整的端到端机器学习工作流程,包括:
* 数据理解
* 探索性数据分析 (EDA)
* 数据预处理
* 缺失值处理
* 特征工程
* 分类特征编码
* 模型构建
* 模型评估
* 恶意软件威胁预测
本项目是一个基于 Kaggle 的机器学习分类项目,使用 Python 和 Scikit-learn 开发。
# 问题陈述
## 现代计算机系统会产生大量的遥测数据,例如:
操作系统信息
杀毒软件状态
设备配置
安全设置
系统行为日志
威胁检测报告
这些数据可用于识别系统是否易受恶意软件攻击。
本项目的目标是:
构建一个基于系统遥测和杀毒软件威胁数据,能够预测恶意软件感染风险的机器学习模型。
该问题被视为一个分类问题,因为模型预测的是系统是否属于恶意软件感染类别。
# 数据集理解
数据集包含从设备和杀毒软件系统收集的系统遥测信息。
数据集包括:
数值型特征
分类型特征
设备相关信息
安全相关配置
威胁报告信息
目标变量代表恶意软件感染状态或恶意软件相关分类标签。
# 使用的技术
编程语言
Python
使用的库
Pandas
NumPy
Matplotlib
Seaborn
Scikit-learn
项目工作流程
本项目遵循结构化的机器学习流程。
# 步骤 1:导入库
笔记本中的第一步是导入所需的 Python 库。
这些库用于:
| 库 | 用途 |
| :-------- | :--------------- |
| Pandas | 数据处理与分析 |
| NumPy | 数值运算 |
| Matplotlib | 数据可视化 |
| Seaborn | 统计可视化 |
| Scikit-learn | 机器学习建模 |
执行的示例任务包括:
读取数据集
处理缺失值
可视化分布
编码分类特征
训练分类模型
# 步骤 2:加载数据集
数据集被加载到 Pandas DataFrame 中。
此步骤允许:
读取 CSV 文件
检查行和列
了解数据集维度
验证数据类型
使用的函数:
pd.read_csv()
df.head()
df.info()
df.shape()
df.describe()
目的:
在预处理之前了解数据集的结构。
# 步骤 3:探索性数据分析 (EDA)
进行 EDA 以深入理解数据集。
笔记本包括:
数据集结构分析
数据类型检查
缺失值分析
描述性统计
特征分布分析
EDA 有助于识别:
空值
不平衡的特征
数据不一致
潜在的预处理需求
使用的函数:
isnull().sum()
describe()
value_counts()
# EDA 的重要性:
EDA 至关重要,因为机器学习模型严重依赖数据质量。
低质量数据会导致:
模型准确率低
过拟合
泛化能力差
# 步骤 4:缺失值处理
数据集在多个特征中包含缺失值。
之所以处理缺失值,是因为机器学习算法无法直接处理不完整的数据。
# 使用的技术:
空值检测
缺失值替换
数据清理
# 常见方法:
| 数据类型 | 处理方法 |
| :------- | :----------------- |
| 数值型 | 均值/中位数填充 |
| 分类型 | 众数填充 |
目标:
提高数据质量
防止训练错误
提升模型性能
# 步骤 5:特征工程
# 特征工程是本项目中最重要的步骤之一。
# 此步骤将原始数据转换为有用的机器学习特征。
# 执行的任务:
此热力图突显了为恶意软件威胁预测所选出的前 15 个最重要特征之间的相关性。特征间的强正相关和负相关关系有助于识别依赖关系、多重共线性以及对改善模型性能和特征选择有用的关键模式。
选择有用的列
移除不必要的信息
转换特征
准备模型就绪的输入
# 特征工程改善:
模型学习能力
预测质量
泛化性能
# 步骤 6:分类特征编码
数据集包含分类变量,例如:
设备配置
安全设置
系统标签
机器学习模型无法直接处理文本分类。
因此,需要应用编码技术。
编码将类别转换为数值表示。
常见的编码方法:
标签编码
独热编码
目的:
将分类数据转换为机器可读格式。
# 步骤 7:数据预处理
数据预处理为机器学习准备数据集。
包含的任务:
清理数据
处理缺失值
编码分类变量
组织特征
此步骤确保:
更好的模型训练
减少错误
提高预测性能
# 步骤 8:模型构建
## 使用 Scikit-learn 训练机器学习分类模型。
模型的目标是:
利用遥测数据预测恶意软件感染风险。
分类模型从历史系统行为中学习模式。
输入:
遥测特征
杀毒软件报告数据
输出:
恶意软件感染预测
模型识别系统特征与恶意软件威胁之间的关系。
# 步骤 9:模型评估
训练后,评估模型以衡量性能。
评估很重要,因为它有助于确定:
预测质量
模型可靠性
泛化能力
分类问题中常用的评估指标:
| 指标 | 目的 |
| :------- | :--------------------------------- |
| 准确率 | 整体预测正确性 |
| 精确率 | 正确的阳性预测比例 |
| 召回率 | 检测能力 |
| F1分数 | 精确率与召回率之间的平衡 |
笔记本重点介绍了如何使用预处理和机器学习技术提高恶意软件威胁检测性能。
# 项目成果
最终系统成功地:
从遥测数据中学习了模式
识别了与恶意软件相关的风险
提高了分类性能
展示了机器学习在网络安全领域的实际应用
该项目展示了机器学习如何应用于:
威胁检测
风险分析
安全预测系统
网络安全自动化
# 展示的关键技能
# 本项目展示了对以下方面的实践理解:
机器学习
分类建模
模型评估
预测系统
数据科学
探索性数据分析
数据预处理
缺失值处理
特征工程
Python 库
Pandas
NumPy
Matplotlib
Seaborn
Scikit-learn
网络安全分析
恶意软件威胁预测
系统遥测分析
杀毒软件报告分析
遇到的挑战
# 本项目中的一些重要挑战包括:
处理大型结构化数据集
管理缺失值
处理分类特征
提高模型性能
组织预处理工作流
这些挑战通过以下方式解决:
适当的预处理
特征转换
数据清理技术
结构化的机器学习工作流
结论
本项目成功展示了一个利用系统遥测和杀毒软件威胁报告数据进行恶意软件威胁预测的端到端机器学习工作流程。
# 该项目涉及:
数据分析
数据预处理
特征工程
分类编码
分类建模
性能评估
最终模型能够通过学习系统行为和遥测特征的模式来预测恶意软件感染风险。
本项目突出了机器学习技术在网络安全领域的应用,并展示了使用 Python 和 Scikit-learn 构建预测分析系统的实践经验。标签:AMSI绕过, Apex, Python, Scikit-learn, SHAP分析, 分类模型, 分类特征编码, 反病毒威胁, 威胁检测, 探索性数据分析, 数据科学, 数据预处理, 无后门, 机器学习, 模型评估, 混淆矩阵, 特征工程, 端到端工作流, 系统遥测, 缺失值处理, 网络安全, 网络设备安全, 资源验证, 逆向工具, 隐私保护, 风险预测