ChewYiSiang/sentiment-analysis-lazada
GitHub: ChewYiSiang/sentiment-analysis-lazada
这是一个基于Lazada用户评论训练的多类别情感分析项目,用于自动分类评论情感以支持产品反馈优化。
Stars: 0 | Forks: 0
# Lazada 应用评论 — 情感分析
一个基于 **775,000+ 条真实用户评论** 训练的多类别 NLP 情感分类器,数据来源于 Lazada 的 Google Play 商店页面。本项目涵盖了完整的机器学习流程:原始文本获取 → 探索性数据分析 → 预处理 → 特征工程 → 模型对比 → 最终模型选择 → 业务建议。
## 目录
- [概述](#overview)
- [数据集](#dataset)
- [技术栈](#tech-stack)
- [项目流程](#project-pipeline)
- [模型与结果](#models--results)
- [结果分析](#analysis-of-results)
- [业务发现与建议](#business-findings--recommendations)
- [关键挑战与解决方案](#key-challenges--solutions)
- [项目结构](#project-structure)
- [快速开始](#getting-started)
## 概述
**目标变量:** `sentiment` (由 `review_rating` 派生)
- ⭐⭐⭐⭐–⭐⭐⭐⭐⭐ → 积极
- ⭐⭐⭐ → 中性
- ⭐–⭐⭐ → 消极
## 数据集
| 属性 | 值 |
|---|---|
| 来源 | [Kaggle — Lazada App Reviews (Google Store)](https://www.kaggle.com/datasets/bwandowando/lazada-app-reviews-from-google-store/data) |
| 行数 | 775,323 |
| 使用的特征 | `review_text`, `review_rating` |
| 日期范围 | 2013 – 2023 |
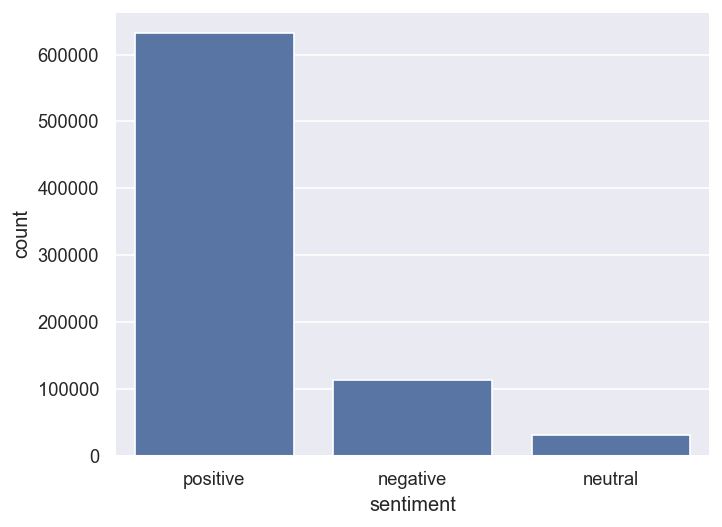
| 类别分布 | 严重不平衡(积极占优:~81.6% 积极,~14.6% 消极,~3.9% 中性) |
## 技术栈
| 类别 | 库 |
|---|---|
| 数据处理 | `pandas`, `numpy` |
| 可视化 | `matplotlib`, `seaborn`, `wordcloud` |
| NLP 与文本 | `nltk`, `emoji`, `re` |
| 特征工程 | `TF-IDF` (scikit-learn) |
| 机器学习模型 | `scikit-learn`, `imbalanced-learn` |
| 模型持久化 | `joblib` |
## 项目流程
### 1. 探索性数据分析 (EDA)
- 检查类别分布 — 发现 **严重的类别不平衡**:积极评论 (~81.6%) 在数据集中占压倒性优势,而中性评论极其稀少 (~3.9%)。
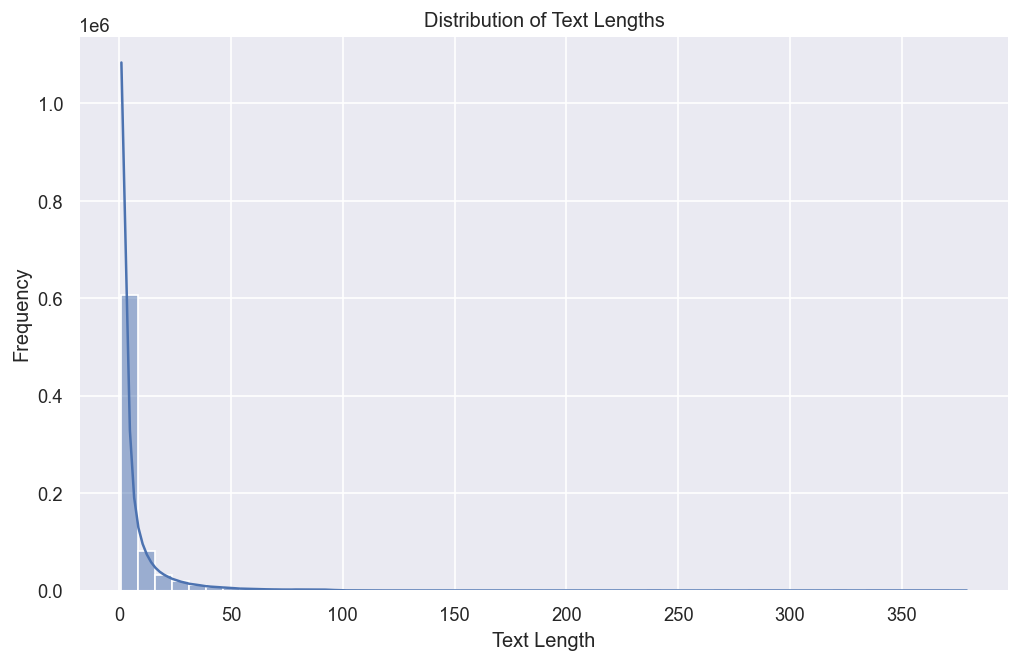
- 分析评论文本长度分布(平均:7 词,最大:379 词);发现长篇幅、包含多种情感的评论可能会混淆分类器。
- 验证评论者偏差:确认没有单一作者发布超过 2 条评论,排除了个人层面的数据偏斜。
- 处理 `review_text` 中的缺失值(删除了 305 行空值)。
### 2. 文本预处理
一个可复用的 `clean_text()` 函数按顺序执行以下步骤:
| 步骤 | 技术 | 原理 |
|---|---|---|
| 小写转换 | `str.lower()` | 规范化词汇 |
| 移除 URL / HTML / 提及 | `re.sub()` | 剥离非语义噪声 |
| 移除数字 | `re.sub(r'\d+', '', ...)` | 移除订单号、日期 |
| 移除标点符号 | `str.translate()` | 减少噪声 |
| 表情符号转换 | `emoji.demojize()` | 将表情符号情感保留为文本 |
| 重复字符规范化 | 正则表达式 `(.)\1{2,}` | "goooood" → "good" |
| 分词 | `nltk.word_tokenize()` | 将文本拆分为词元 |
| 移除停用词 | `nltk.corpus.stopwords` | 移除低信号功能词 |
| 词形还原 | `WordNetLemmatizer` | 将屈折形式还原为词根 ("running" → "run") |
### 3. 特征工程 — TF-IDF 向量化
- 使用 **TF-IDF** (词频-逆文档频率) 将清洗后的文本转换为数值特征向量。
- 设置 `max_features=5000` 以限制词汇表大小,防止因罕见词过拟合。
- 设置 `ngram_range=(1, 2)` 以捕获单字词和双字词(例如,"not good" 被视为一个特征)。
### 4. 类别不平衡处理
- 在逻辑回归和线性 SVM 中使用 `class_weight='balanced'` 来按比例惩罚少数类的误分类。
- 使用宏平均 F1 分数(平等对待所有类别)和准确率进行评估,以避免类别不平衡带来的误导性结果。
### 5. 模型训练与超参数调优
- 使用 `stratify=y` 进行分层 70/30 训练-测试划分,以保持类别比例。
- 全程使用 Scikit-learn `Pipeline` 以防止数据泄漏(向量化器仅在训练数据上拟合)。
- **分层 K 折交叉验证** (5 折) 用于获得稳健、无偏的性能估计。
- 使用 **GridSearchCV** 对朴素贝叶斯和 SVM 进行超参数调优。
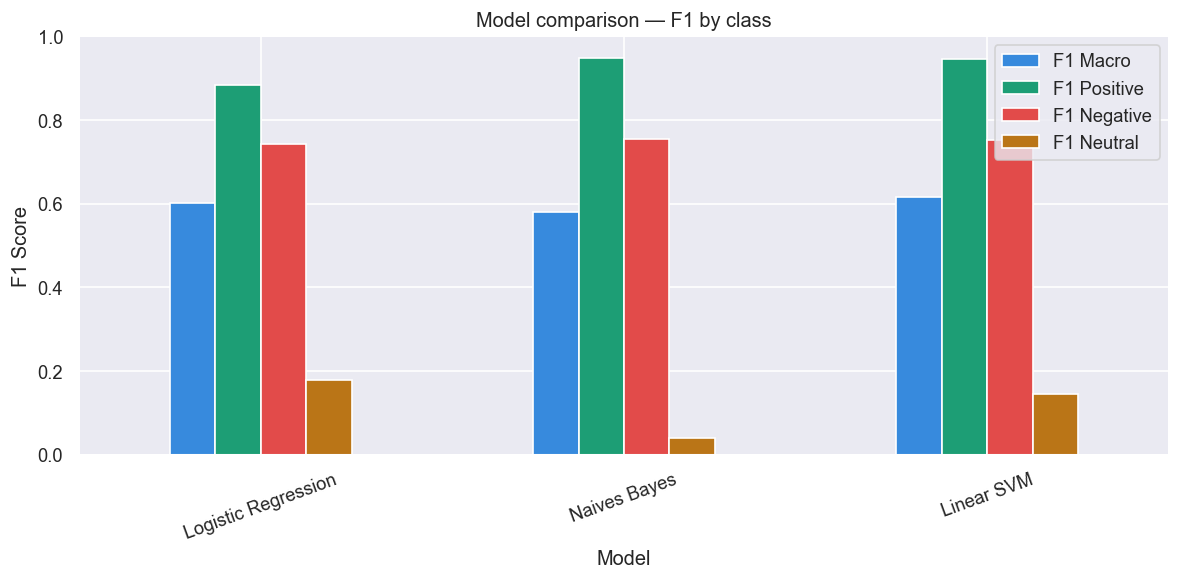
## 模型与结果
在相同的预处理数据集上对三种分类器进行了基准测试:
| 模型 | 准确率 | F1 宏平均 | F1 加权平均 | 备注 |
|---|---|---|---|---|
| 逻辑回归 | 0.7754 | 0.5898 | 0.8263 | 基线;`class_weight='balanced'` |
| 多项式朴素贝叶斯 | 0.8996 | 0.5800 | 0.8840 | 通过 GridSearchCV 调优 (alpha, fit_prior) |
| **线性 SVM (SGD) ✅** | **0.8943** | **0.6127** | **0.8864** | 最佳 F1 宏平均;通过 `SGDClassifier` 实现可扩展 SVM |
**胜出者:线性 SVM 配合 TF-IDF (最佳 F1 宏平均:0.6127)**
线性 SVM 在宏平均 F1 上优于另外两种模型 — 这是在类别不平衡下最有意义的指标,因为它平等地对待三个类别。虽然朴素贝叶斯取得了最高的原始准确率 (0.8996),但由于中性类别的召回率较差,其 F1 宏平均较低 (0.5800)。线性 SVM 在三个类别之间取得了最佳平衡。
最佳流程被序列化保存为 `best_pipeline.pkl`,所有模型保存为 `all_models.pkl`,用于后续推理而无需重新训练。
### 混淆矩阵
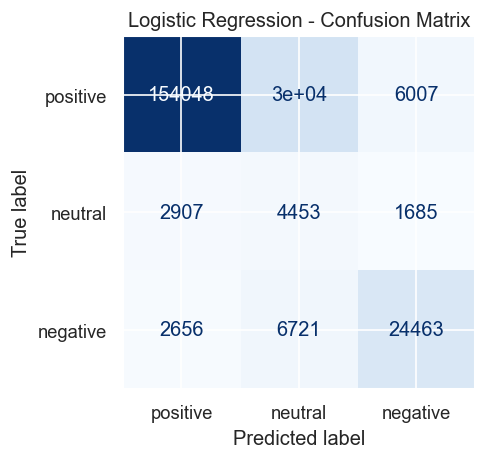
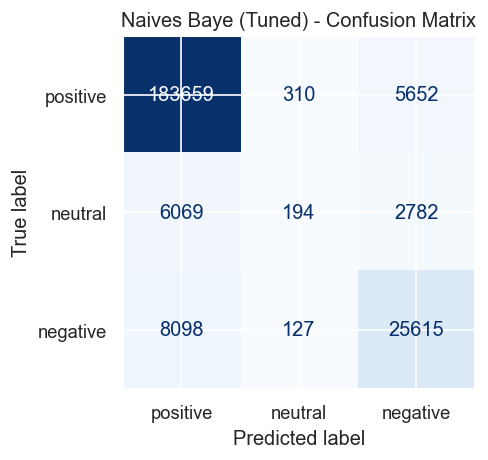
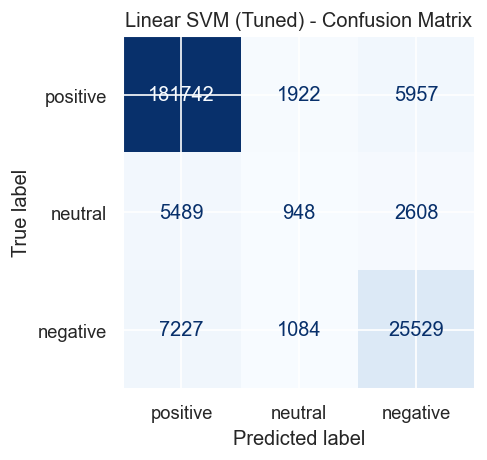
## 结析分析
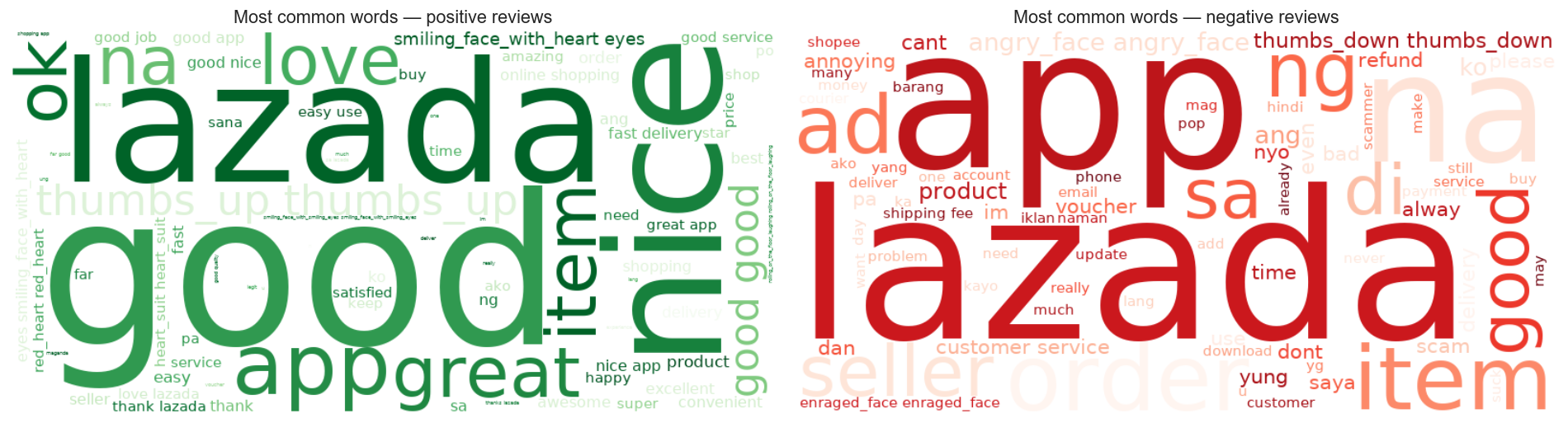
### 词云 — 用户在说什么?
下面的词云展示了文本预处理后积极和消极评论中最常出现的词语。
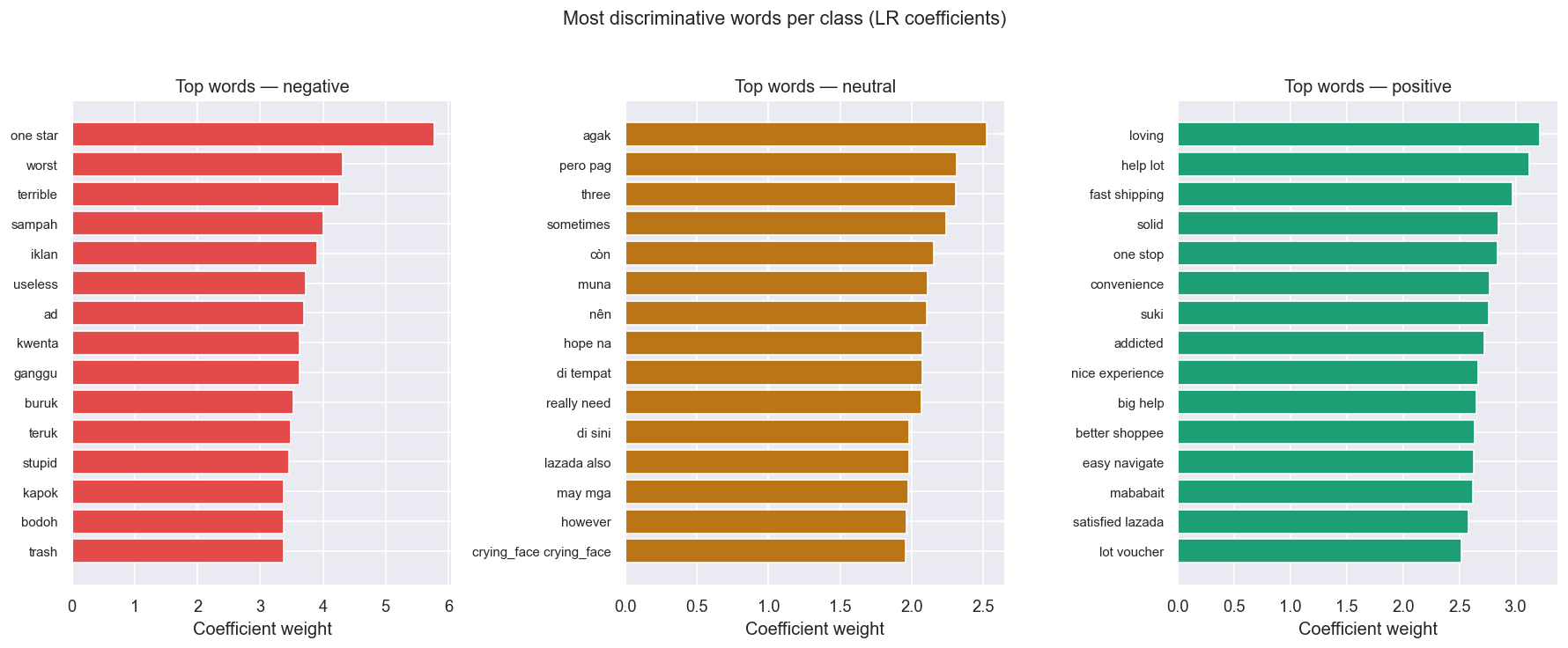
### 最具区分性的词(逻辑回归系数)
逻辑回归系数揭示了哪些词最强烈地推动模型倾向于每个情感类别。与原始词频不同,这显示了*相对*的预测重要性。
## 业务发现与建议
### 整体情感分布
| 情感 | 占比 |
|---|---|
| 积极 | 81.6% |
| 消极 | 14.6% |
| 中性 | 3.9% |
### 主要发现
1. **整体满意度较高 (~81.6% 积极):** 大多数 Lazada 用户对应用评价良好,表明品牌认知基础稳固。
2. **消极评论集中在应用性能:** 消极情感的最具区分性词汇始终包括与崩溃、卡顿、错误和更新失败相关的术语。应用稳定性是主要痛点。
3. **中性类别最难建模 (F1 ~0.14–0.16):** 3 星评分并不能可靠地映射到中性语言。对于生产部署,二分类(积极 vs. 消极)将提供更可靠和可操作的结果。
4. **情感趋势可作为产品信号:** 消极评论量的激增与应用发布窗口相关。产品工程团队可以将其用作早期预警系统,以捕捉发布后的回退问题。
5. **线性 SVM 是最佳的轻量级模型**(在 F1 宏平均上)。训练好的流程可以在毫秒内对任何新评论进行评分,使用 `pipeline.predict([review_text])`。
### 给 Lazada 的建议
| 优先级 | 措施 | 证据 |
|---|---|---|
| 高 | 调查应用更新中的崩溃/性能问题 | 消极情感的最具区分性词汇 |
| 高 | 每次应用发布后监控每周消极评论占比 | 情感分布 |
| 中 | 部署此流程用于实时评论标签 | 保存的 `best_pipeline.pkl` |
| 中 | 对消极评论运行主题建模 (BERTopic/LDA) | 识别具体的特性投诉 |
| 低 | 尝试二分类(积极 vs. 消极) | 中性类别不可靠 (F1 ~0.14) |
## 关键挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| **严重的类别不平衡** (积极 >> 中性) | 在逻辑回归和 SVM 中使用 `class_weight='balanced'` + 使用宏平均 F1 作为主要评估指标 |
| TF-IDF 带来的**数据泄漏风险** | 将向量化器和分类器包装在 `sklearn.Pipeline` 中 |
| **大型数据集** (775K 行) — SVC 太慢 | 用 `SGDClassifier(loss='hinge')` 替换 `SVC` — 等同于线性 SVM,线性扩展 |
| **包含多种情感的长评论** | 词形还原 + TF-IDF 双字词以捕获短语级上下文 |
| **嘈杂的非正式文本** (表情符号、俚语) | `emoji.demojize()` 保留表情符号情感;基于正则表达式的重复字符规范化 |
## 项目结构
```
├── Sentimental Analysis (Lazada).ipynb # Main notebook
├── LAZADA_REVIEWS.csv # Raw dataset (from Kaggle)
├── all_models.pkl # All trained model pipelines (joblib)
├── best_pipeline.pkl # Best model pipeline — Linear SVM (joblib)
└── README.md
```
## 快速开始
```
# 安装依赖
pip install pandas numpy matplotlib seaborn scikit-learn nltk emoji wordcloud langdetect
pip install transformers torch
pip install sentencepiece
pip install imbalanced-learn
# 下载 NLTK 资源(首次运行)
python -c "import nltk; nltk.download('stopwords'); nltk.download('punkt'); nltk.download('wordnet')"
```
然后在 Jupyter 中打开 `Sentimental Analysis (Lazada).ipynb` 并运行所有单元格。
要直接加载并使用保存的最佳模型:
```
import joblib
# 最佳模型管线(Linear SVM + TF-IDF)
pipeline = joblib.load("best_pipeline.pkl")
pipeline.predict(["This app keeps crashing, very frustrating"]) # ['negative']
pipeline.predict(["Great deals and fast shipping!"]) # ['positive']
```
要加载所有模型:
```
import joblib
models = joblib.load("all_models.pkl")
lr_pipeline = models["logistic"]
nb_pipeline = models["naives_baye"]
svm_pipeline = models["LinearSVC"]
```
## 致谢
数据集来源于 [Kaggle — Lazada App Reviews (Google Store)](https://www.kaggle.com/datasets/bwandowando/lazada-app-reviews-from-google-store/data),由 bwandowando 提供。
标签:Apex, Google Play, imbalanced-learn, Lazada, matplotlib, nltk, numpy, pandas, Python, scikit-learn, seaborn, TF-IDF, 多类分类, 客户反馈分析, 情感分析, 探索性数据分析, 数据科学, 数据预处理, 文本分类, 文本挖掘, 无后门, 机器学习, 模型比较, 特征工程, 电商应用, 类别不平衡处理, 评论分析, 资源验证, 逆向工具