IntologyAI/NanoGPT-Bench
GitHub: IntologyAI/NanoGPT-Bench
一个评估自主编码 Agent 在 GPT-2 预训练加速任务上研究能力的基准测试平台,衡量 AI 能在多大程度上复现并超越人类专家的优化进度。
Stars: 21 | Forks: 3
# NanoGPT-Bench
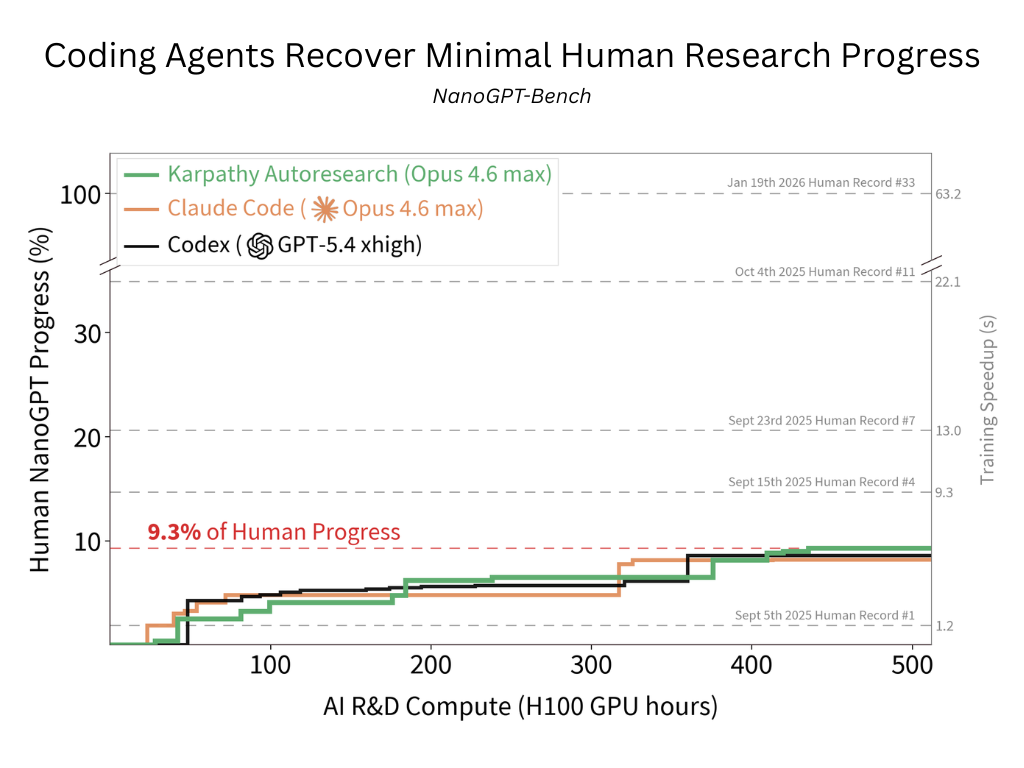
**NanoGPT-Bench** 是一个基准测试,用于评估 AI 系统执行开放式、长周期前沿 ML 研究的能力。它建立在流行的 GPT-2 预训练竞速挑战 [*NanoGPT Speedrun*](https://github.com/kellerjordan/modded-nanogpt) 之上,衡量自主编码 Agent 能在多大程度上恢复排行榜上历史性的人类进度。
## 概述
在 NanoGPT-Bench 中,Agent 以*完全自主*的方式工作——无需人类干预,也无法访问互联网——以在 *NanoGPT Speedrun* 的强大人类起点上进行改进。Agent 拥有固定的实验计算预算,并通过 `submit` 命令提交候选解决方案,该命令会:
1. 通过 LLM 裁决器检查竞赛规则(反映原始的 *NanoGPT Speedrun* 审查流程)。
2. 对候选方案进行十次重新计时,以确认具有统计学意义的加速效果。
该基准测试以初始人类纪录和计算预算作为参数,因此可以随着时间的推移更新配置,以避免基准污染。
### 为什么选择 NanoGPT-Bench?
我们发现了对自主研究评估至关重要的三个属性:
1. **开放式问题**,要求 Agent 自己提出想法,而不仅仅是遵循指令。
2. **强大且优化的起点**,确保进度不会轻易被唾手可得的成果混淆。
3. **长周期的人类参考轨迹**,突出当前的不足并指明改进空间。
*NanoGPT Speedrun* 作为自主研究评估环境具有独特的优势:它拥有悠久的人类专家提交历史、清晰的验证预言机(oracle)以及开放式的优化目标。
### 初步结果
我们评估了三个前沿编码 Agent —— Codex (GPT-5.4 xhigh)、Claude Code (Opus 4.6 Max) 以及一个使用 [Autoresearch](https://github.com/karpathy/autoresearch)-风格提示的 Claude Code 变体 —— 每个都分配了 512 个 H100 GPU 小时的计算预算,从 2025 年 9 月 3 日的人类世界纪录开始。
所有基线在随后五个月内(2025 年 9 月 3 日至 2026 年 1 月 19 日)恢复的人类世界纪录加速比均**不到 10%**:
| 基线 | 恢复的人类进度百分比 |
| --- | --- |
| Autoresearch (Opus 4.6 Max) | 9.3% |
| Codex (GPT-5.4 xhigh) | 8.6% |
| Claude Code (Opus 4.6 Max) | 8.2% |
Agent 将其大部分计算资源用于超参数调优。相比之下,约 77% 的人类世界纪录引入了算法层面的改进。请参阅[博客文章](#)了解完整分析。
## 仓库布局
```
NanoGPT-Bench/
├── assets/ # README figures and other static media
│ └── figure1.png
├── nanogpt/ # Host-side harness (driver, agents, prompts, launchers)
│ ├── driver.py # Container launcher invoked by nanogpt/run/*.sh
│ ├── prompts/ # Shared agent prompts mounted into every run
│ │ ├── RULES.md
│ │ ├── problem.txt
│ │ ├── local_prompt.md
│ │ └── resume_prompt.md
│ ├── agents/ # Per-agent harnesses (install.sh + run.sh entrypoint)
│ │ ├── claude/
│ │ ├── codex/
│ │ └── autoresearch/ # also carries its own `prompts/` overlay
│ └── run/ # Top-level launcher scripts (entry points for a user)
│ ├── claude_local.sh
│ ├── claude_autoresearch_local.sh
│ └── codex_local.sh
├── image/ # Docker build context (training environment + submit validator)
│ ├── Dockerfile
│ ├── requirements.txt
│ ├── submit.sh # installed in-container as `submit`
│ ├── codebase/data/ # FineWeb10B shard fetcher (baked into the image)
│ └── tools/ # submit validator (comparability judge + p-value retiming);
│ # copied to /opt/nanogpt/tools inside the container
└── human_baselines/ # Snapshot of historical human-record submissions (run.sh +
# train_gpt.py per record). The 2025-09-03_FA3 record is the
# comparability anchor; its serialized form is also baked
# into image/tools/baseline_code.txt.
```
## 运行基准测试
1. 构建镜像(一次性操作):
docker build -t nanogpt-bench image
构建过程会将 9 个 FineWeb10B 训练分片(shard)及验证分片预取到镜像内部的 `/workspace/data/fineweb10B/` 目录中。
2. Docker 卷 `nanogpt-bench-data` 会在运行时挂载到 `/workspace/data`。首次启动时,Docker 会使用镜像中内置的分片自动填充该卷;后续运行将重复使用它。如果你想使用不同的卷名称,请使用 `--data-volume`(或 `BENCHMARK_DATA_VOLUME`)进行覆盖。
3. 导出所选 Agent 需要的凭证和会话时长预算,然后启动以下其中一个:
export ANTHROPIC_API_KEY=...
export BENCHMARK_SESSION_HOURS=24
bash nanogpt/run/claude_local.sh
# 或者:bash nanogpt/run/claude_autoresearch_local.sh
# 或者:OPENAI_API_KEY=... CODEX_API_KEY=$OPENAI_API_KEY bash nanogpt/run/codex_local.sh
每个启动脚本都会调用 `nanogpt/driver.py`,该脚本会将 `2025-09-03_FA3` 人类纪录复制到 `runs/` 下一个带有新时间戳的工作区中,将 `nanogpt-bench-data` 卷挂载到容器内,并运行该 Agent 的 `run.sh`。驱动程序会将容器日志流式传输到终端,并将 Agent 的事件和渲染器输出持久化保存在运行目录下。Agent 通过调用 `submit /workspace/submissions/submission_N` 来验证中间候选方案,该命令会在容器内运行可比性 + p-value 检查,成功时返回退出代码 `0`。
## 如何引用
如果你在研究中使用了 NanoGPT-Bench,请引用:
```
@misc{intology2026nanogptbench,
title = {NanoGPT-Bench: Evaluating Autonomous Research Agents on the NanoGPT Speedrun},
author = {Intology},
year = {2026},
howpublished = {\url{https://github.com/IntologyAI/NanoGPT-Bench}},
}
```
## 致谢
NanoGPT-Bench 是建立在 Keller Jordan 和 *NanoGPT Speedrun* 社区开发的 [modded-nanogpt](https://github.com/kellerjordan/modded-nanogpt) 基础之上的,他们的创纪录提交为本基准测试中的人类参考轨迹提供了数据来源。
标签:AI智能体, Apex, DLL 劫持, 人工智能, 代码优化, 凭据扫描, 大语言模型, 机器学习, 用户模式Hook绕过, 自动化研究, 请求拦截, 逆向工具