evilsocket/audit
GitHub: evilsocket/audit
一个基于 Claude Code Agent SDK 的 8 阶段 AI 漏洞发现智能体,通过多智能体并行、对抗性验证和可达性追踪来自动化代码安全审计。
Stars: 766 | Forks: 108
# 审计
一个 8 阶段的漏洞发现智能体,通过官方 Claude Code Agent SDK 由您的 **Claude Pro / Max 订阅** 驱动。包含许多狭窄范围的智能体、刻意的不一致反驳,以及严格的可达性关卡。
MIT 许可证。如果您已经在使用 `claude login`,则无需 API key。
## 起源
本项目是对 Cloudflare 的 [Project Glasswing](https://blog.cloudflare.com/cyber-frontier-models/) 文章中所述工作流从零开始的重新实现。该文章测试了 Anthropic 的 Mythos 预览版 LLM 与 Cloudflare 自有代码库的对抗。该博客认为,现实世界中的漏洞发现**并**非来自于要求一个大模型“在这里寻找漏洞”——它来自于:
1. **许多狭窄范围的智能体** 并行处理严格限定范围的问题(“在这个特定函数中寻找命令注入,且在其上方存在此信任边界”),而不是一个详尽的智能体。
2. **刻意的不一致** —— 第二个智能体,使用不同的模型,试图*推翻*第一个智能体的发现。
3. **可达性追踪** 作为关卡步骤 —— 大多数“此代码有漏洞吗?”的发现都是噪音,除非攻击者控制的输入确实能够从系统外部到达 sink。
4. **反馈循环**,使得在一个地方发现的可达漏洞自动触发对其他地方相同模式的搜寻。
本仓库将该流水线打包成一个可运行的智能体。Cloudflare 的文章展示了架构;本代码库则提供了提示词、schema、状态存储和编排器。
## 8 个阶段
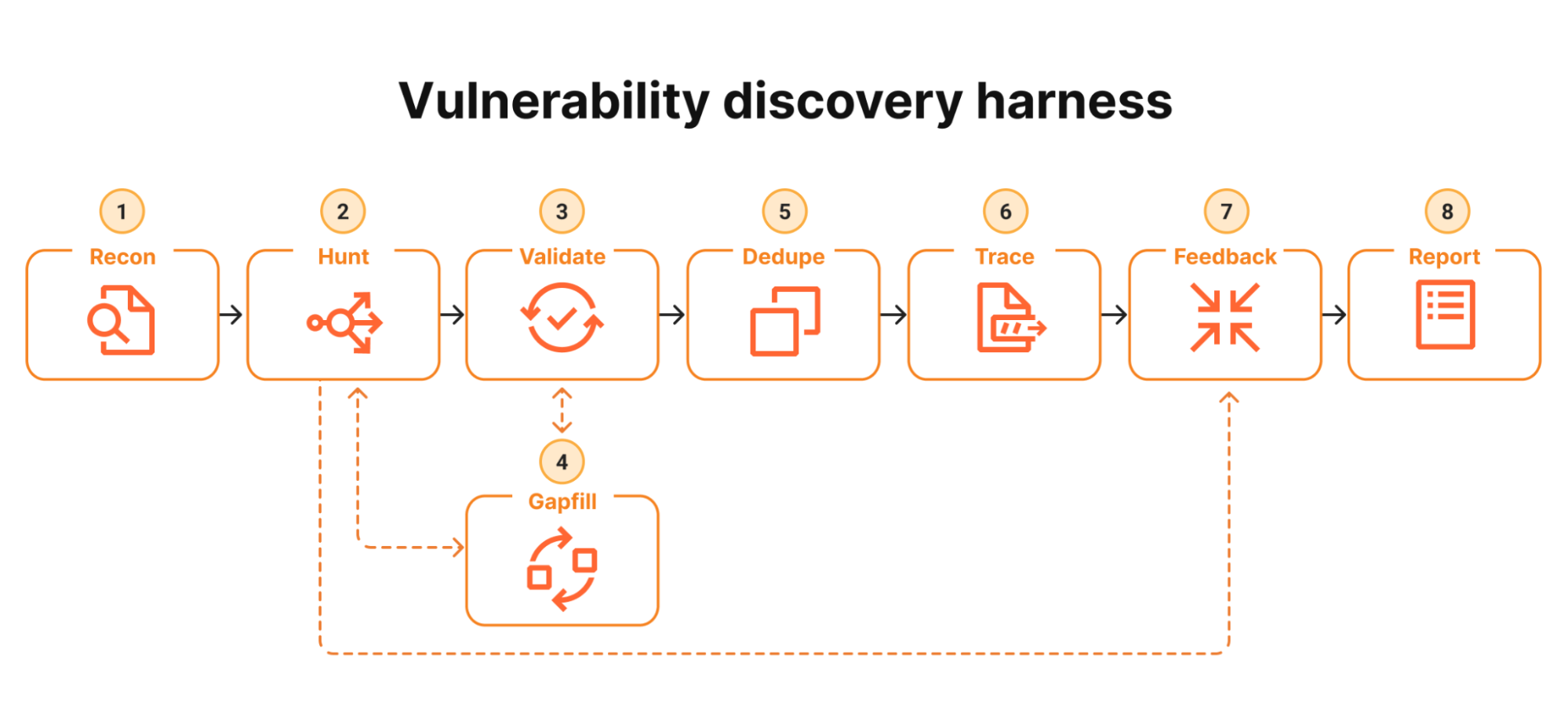
图表来自 Cloudflare 的 [Project Glasswing](https://blog.cloudflare.com/cyber-frontier-models/) 文章,在此处复制以供参考。
| # | 阶段 | 默认模型 | 用途 |
|---|----------|---------------|---------|
| 1 | Recon | Opus 4.7 | 映射代码库,生成范围狭窄的 Hunt 任务 |
| 2 | Hunt | Sonnet 4.6 | 每个智能体处理一种攻击类别;编译/运行 PoC |
| 3 | Validate | Opus 4.7 | 对抗性重读;试图**推翻**(使用与 Hunt 不同的模型) |
| 4 | Gapfill | Sonnet 4.6 | 重新排队覆盖不足的区域 |
| 5 | Dedupe | Sonnet 4.6 | 按根本原因对发现进行聚类 |
| 6 | Trace | Opus 4.7 | 证明攻击者控制的输入能够到达 sink |
| 7 | Feedback | Sonnet 4.6 | 将可达的追踪转化为新的 Hunt 任务 |
| 8 | Report | Sonnet 4.6 | 经过 schema 验证的结构化报告 |
每个阶段在 `prompts/` 中包含一个 markdown 提示词,并在 `schemas/` 中包含一个 JSON Schema。编排器将 schema 传入系统提示词中,从而确保每次输出在首次尝试时即保持结构稳定。
## 快速开始
```
# 1. 安装
python -m venv .venv && source .venv/bin/activate
pip install -e .
# 2. Auth(任选其一)
# (a) 已经通过 claude login 登录?那就完成了。
# (b) 或者为 CI / 非交互式使用生成一个 1 年期的 OAuth token:
claude setup-token
echo "CLAUDE_CODE_OAUTH_TOKEN=" > .env
# 3. 验证
audit auth-check
# 4. 运行
audit run --repo /path/to/target --run-id my-run
audit status --run-id my-run
audit report --run-id my-run --format md > report.md
```
默认情况下,该智能体通过您的 Claude.ai 登录使用**订阅计费** —— 它**不会**调用按量计费的 Anthropic API。磁盘上的身份验证模块会从环境中清除 `ANTHROPIC_API_KEY`,从而防止其悄悄绕过 OAuth 流程。
## 使用不同的模型 / 提供商
身份验证模块按以下顺序选择三种模式之一:
1. **LLM 网关**(OpenRouter、自定义代理等)—— 当 `ANTHROPIC_BASE_URL` 指向非 `anthropic.com` 且设置了 `ANTHROPIC_AUTH_TOKEN` 时。网关环境变量保持不变;仅清除 `ANTHROPIC_API_KEY`(否则它的优先级将高于网关 token)。
2. **订阅 OAuth(无头模式)** —— 来自 `claude setup-token` 的 `CLAUDE_CODE_OAUTH_TOKEN`。最适合 CI。
3. **订阅 OAuth(交互式)** —— 来自 `claude login` 的 `~/.claude/.credentials.json`。最适合本地开发。
### OpenRouter
OpenRouter 在其自己的信用体系后面提供了兼容 Claude 的 Anthropic API endpoint;这允许您使用 OpenRouter 信用额度而不是 Anthropic 订阅,并允许您通过相同的 SDK 路径访问 Sonnet/Opus *以及*其他模型。请参阅 [OpenRouter 的 Agent SDK 指南](https://openrouter.ai/docs/guides/community/anthropic-agent-sdk)。
```
export ANTHROPIC_BASE_URL="https://openrouter.ai/api"
export ANTHROPIC_AUTH_TOKEN="$OPENROUTER_API_KEY"
export ANTHROPIC_API_KEY="" # must be explicitly empty / unset
# 可选:选择一个非 Anthropic 模型
export ANTHROPIC_MODEL="anthropic/claude-sonnet-4-6"
# 或例如:ANTHROPIC_MODEL="openai/gpt-5"
# ANTHROPIC_MODEL="google/gemini-2.5-pro"
# ANTHROPIC_MODEL="qwen/qwen3-coder-480b"
audit auth-check # confirms "using LLM gateway at https://openrouter.ai/api"
audit run --repo /path/to/target --run-id orun --max-cost-usd 30
```
注意事项:
- `config/stages.yaml` 中的各阶段模型覆盖项是模型**名称**(例如 `claude-opus-4-7`);OpenRouter 接受带有斜杠前缀的形式,例如 `anthropic/claude-opus-4-7`。如果您希望在不同阶段使用不同的提供商,请修改 YAML 文件。否则,`ANTHROPIC_MODEL` 会强制每个阶段使用同一个模型。
- 非 Claude 模型可能无法可靠地生成符合 schema 的 JSON。运行器的 schema 验证 + 修复轮次仍然适用;但质量因模型而异。
- 工具使用语义(Read/Grep/Glob/Bash)是 Claude Code CLI 的一部分,而不是模型本身的一部分——只要网关支持 Anthropic Messages API,它们就能正常工作。
### 其他网关 / 云提供商
配方相同 —— 任何在 URL + bearer token 上提供 Anthropic Messages API 的服务都可以工作:
```
export ANTHROPIC_BASE_URL="https://your-proxy.example.com"
export ANTHROPIC_AUTH_TOKEN="$YOUR_TOKEN"
unset ANTHROPIC_API_KEY
```
对于 Amazon Bedrock / Google Vertex / Microsoft Foundry,Claude Code 拥有一流的 env-var 标志(例如 `CLAUDE_CODE_USE_BEDROCK=1` 等),其优先级高于其他一切。请参阅 [Claude Code 身份验证文档](https://code.claude.com/docs/en/authentication)。
## 成本控制
一个真实的生产代码库可能会产生 15-50 个 Hunt 任务和 25 个以上的待验证发现。在默认并发量下,这会变得非常昂贵。以下标志可帮助您将其保持在合理范围内:
```
audit run --repo /path/to/target \
--max-concurrency 1 \ # one claude subprocess at a time
--max-recon-tasks 15 \ # cap initial Hunt fanout
--max-cost-usd 30 # abort cleanly if exceeded
```
预算防护会在阶段*之间*以及阶段*内部*触发 —— Hunt 中的按任务检查机制会进行协作性中止,而不是在超过上限后再多运行 30 个任务。
## 实时目标复现(可选)
如果目标有正在运行的部署,请将智能体指向它。Hunt 现在会针对实时服务**复现**每个发现,而不是编译本地 PoC;Validate 会**拒绝**无法复现的发现;而 Trace 会通过真实的 HTTP 往返**确认**可达性。静态分析路径仍然可用 —— 这些标志是可选开启的。
```
audit run --repo /path/to/target --run-id live \
--max-concurrency 1 --max-cost-usd 30 \
--target-url http://server.local:8888 \
--target-creds email=admin@system.com \
--target-creds password=changechangeme
```
当设置了 `--target-url` 时,智能体遵循以下规则:
- 网络出口仅限于该主机 + `127.0.0.1`。不允许连接其他外部主机。
- 无法针对实时目标复现的发现将被丢弃或拒绝(取决于阶段)——“禁止捏造”。
- 凭据将作为一个 dict 流入每个相关阶段的 user_input 中。
## 范围说明(可选)
目标通常具有设计上故意放宽的交互面,这些并不是漏洞(例如,作为功能提供的纯文本 API key、仅用于测试的 Mailpit endpoint、匿名分析数据接收)。将它们放在文本文件中并传入 —— 这些说明将被逐字追加到每个阶段的 user_input 中,并且 Recon / Hunt / Validate 会执行您列出的排除项。
```
audit run --repo /path/to/target --scope-notes target_scope.md
```
示例 `target_scope.md`:
```
- Mailpit (port 1025) is test-only; ignore.
- Plaintext API keys in the database are a required feature.
- Don't flag rate-limit absence on anonymous /ping endpoints.
- Only consider critical/high severity.
```
## Recon 挖掘 git 历史
Recon 会在 git 历史中 grep 过去的安全补丁(`CVE`、`sec:`、`fix.*auth`、`sanitize` 等)—— 已修补的文件得到了强化,但**具有相同惯用法的兄弟文件往往并未被强化**。发现结果会针对未修补的副本进行播种。在没有这种模式的仓库中,这不会增加任何成本;而在存在这种模式的仓库中,它能捕获真实的跨组件漏洞。
## 逻辑链
流水线的默认设置是每个任务处理一种攻击类别(Cloudflare 文章中提到的狭窄范围规则)。Recon 也可以为高影响力的多组件路径发出 `logic_chain` 任务(auth-bypass + IDOR + path-traversal 共同导致 RCE 等)—— 每个任务对应一条链,并使用 `scope_hint` 命名具体的链。这是对单攻击类别范围界定唯一允许的例外。
## 布局
```
prompts/ 8 stage prompts (markdown, loaded as system prompts)
schemas/ 9 JSON schemas — every agent output is validated
config/ stages.yaml — model + concurrency + tool allowlist per stage
audit/ Python package
auth.py OAuth check + ANTHROPIC_API_KEY scrubbing
state.py SQLite DAO (runs, tasks, findings, traces, dedupe, costs)
runner.py claude-agent-sdk wrapper with schema validation + repair turn
orchestrator.py pipeline driver
stages/ one module per stage
work/ per-Hunt-task scratch dirs (sandbox for PoC compile/run)
results/ JSONL artifacts per stage + final report.json
state.db SQLite (gitignored)
```
## 安全性
Hunt 智能体拥有 Bash 权限并在按任务划分的临时目录中运行。它们在操作系统层面**并未**被沙盒化。当您不信任目标源代码时,请在一次性 VM 或 container 中运行审计 —— 否则,带有恶意构建脚本的目标可能会在编译 PoC 期间在您的主机上执行代码。
智能体会读取您 `--add-dir` 添加的所有内容,包括目标中的任何 `.env` 或 `secrets/` 目录。输出结果存放在 `results//` 中,该目录已在 `.gitignore` 中被忽略,但**并未**清除那些读取到的内容。
## 许可证
[MIT](LICENSE)。可自由复用。不提供任何担保。
## 致谢
- 流水线设计源自 Cloudflare 的 [Project Glasswing](https://blog.cloudflare.com/cyber-frontier-models/) 博客文章。架构的功劳归于他们。
- 基于官方 [Claude Code Agent SDK](https://code.claude.com/docs/en/agent-sdk/overview) 构建。
标签:AI安全, Chat Copilot, CISA项目, Claude Code, LLM代理, 对称加密, 自动化审计, 逆向工具