datawithsayannaha/Fraud-Transaction-Detection-Risk-Intelligence-System
GitHub: datawithsayannaha/Fraud-Transaction-Detection-Risk-Intelligence-System
一个端到端的欺诈检测与风险智能系统,利用机器学习分析金融交易数据以识别欺诈行为。
Stars: 0 | Forks: 0
# 🕵️ 欺诈交易检测与风险智能系统
## 📌 项目概述
本项目利用交易级和身份级金融数据,构建了一个完整的欺诈检测与风险智能系统。
项目的目标是分析欺诈性交易行为、识别可疑交易模式、构建欺诈相关特征、应用异常检测技术,并建立用于欺诈预测的机器学习模型。
本项目使用了现实世界中的 IEEE-CIS 欺诈检测数据集,其中包含大规模的金融交易和身份信息。


# 🎯 项目目标
- 检测欺诈性金融交易
- 分析交易与身份行为
- 构建欺诈相关风险特征
- 处理高度不平衡的欺诈数据
- 比较多种机器学习模型
- 应用异常检测技术
- 生成欺诈概率与风险情报
- 创建交易级风险分层
# 🛠️ 使用技术
## 📚 库
- pandas
- numpy
- matplotlib
- seaborn
- scikit-learn
# 📂 数据集信息
本项目使用 IEEE-CIS 欺诈检测数据集,包含:
- 金融交易数据
- 交易金额信息
- 银行卡相关特征
- 电子邮件域名信息
- 地址与距离特征
- 设备与身份信息
- 行为交易模式
## 📁 数据集文件
本项目使用:
- train_transaction.csv
- train_identity.csv
### 🎯 目标变量
| 值 | 含义 |
|---|---|
| 0 | 正常交易 |
| 1 | 欺诈交易 |
# 🔄 项目流程
**原始交易数据 → 数据清洗 → 欺诈 EDA → 特征工程 → 风险特征创建 → 数据预处理 → 机器学习 → 模型评估 → 异常检测 → 风险智能 → 业务洞察**
# 🧹 数据清洗与预处理
项目包含:
- 缺失值分析
- 重复值检查
- 交易与身份数据合并
- 高缺失率列移除
- 标签编码
- 空值处理
- 对数变换
- 特征缩放准备
# 📊 探索性数据分析
项目包含以下分析:
- 欺诈分布分析
- 交易金额分析
- 基于时间的欺诈分析
- 产品欺诈分析
- 银行卡欺诈分析
- 电子邮件域名欺诈分析
- 设备欺诈分析
- 身份缺失模式分析
- 风险模式分析
# 📷 项目图表
## 📌 欺诈与非欺诈交易计数

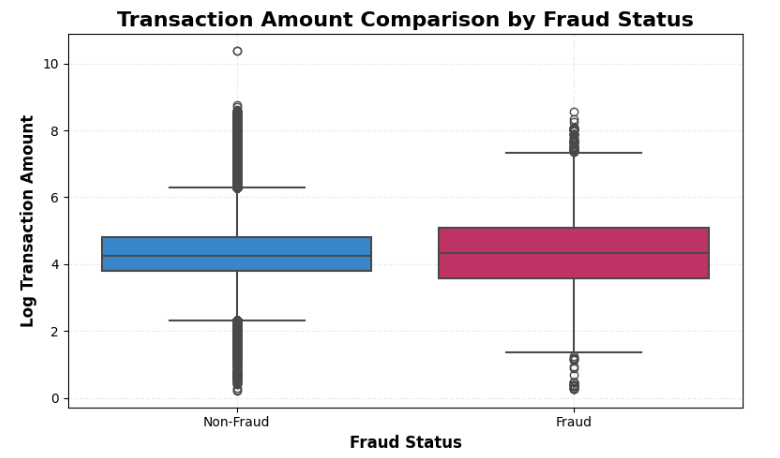
## 📌 按欺诈状态对比的交易金额
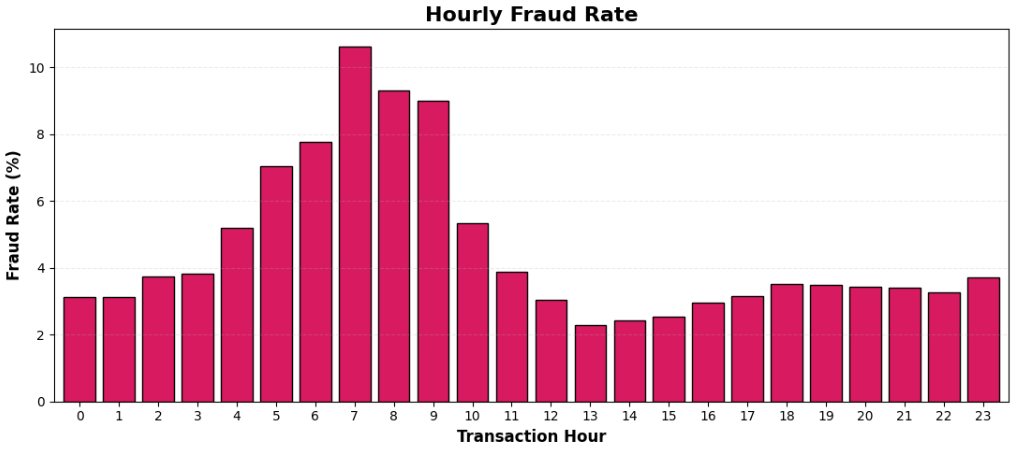
## 📌 每小时欺诈率
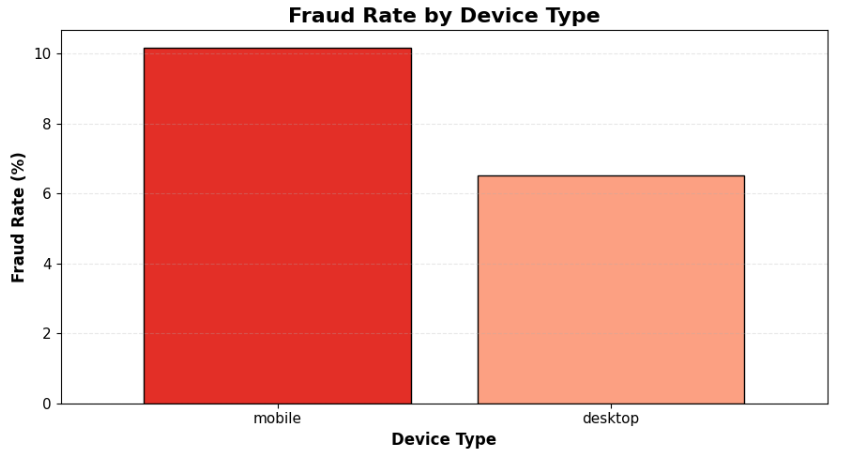
## 📌 按设备分类的欺诈率
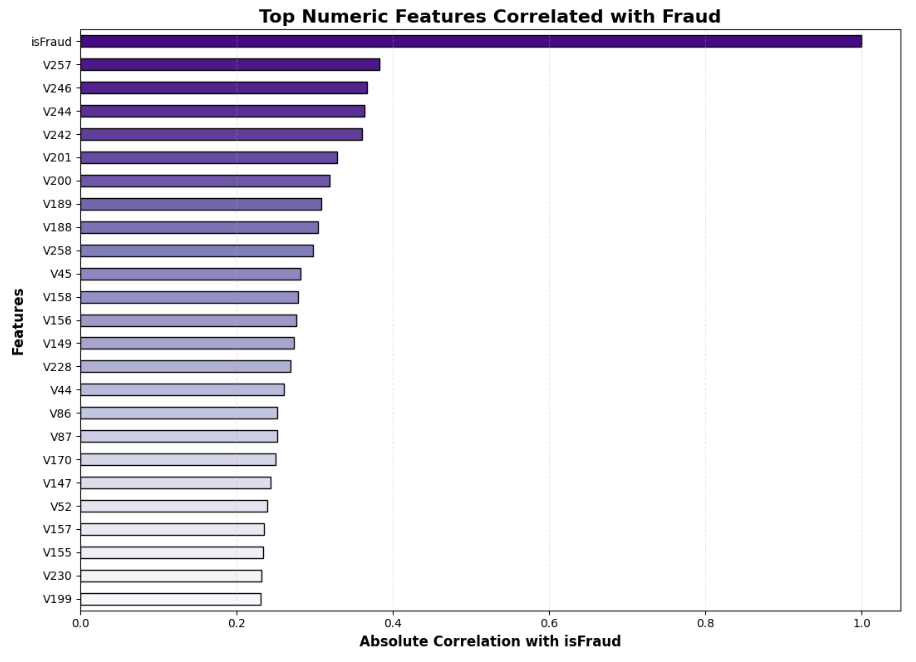
## 📌 最重要的欺诈检测特征
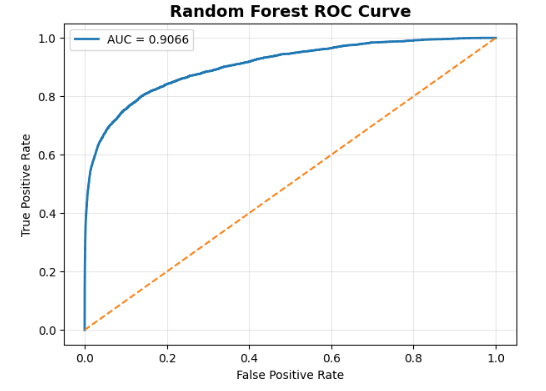
## 📌 随机森林 ROC 曲线
# ⚙️ 特征工程
创建了以欺诈为中心的特征,例如:
- 交易金额对数特征
- 金额分桶特征
- 高金额标志
- 交易小时特征
- 夜间交易特征
- 银行卡频率特征
- 银行卡组合特征
- 电子邮件频率特征
- 电子邮件匹配特征
- 距离缺失标志
- 设备清理特征
- 身份缺失计数
- 自定义风险评分特征
# 🤖 机器学习模型
## 使用的模型
- 逻辑回归
- 随机森林
- Isolation Forest
# ⚙️ 数据预处理
预处理流程包括:
- 训练-验证集拆分
- 缺失值处理
- 标签编码
- 特征选择
- 高缺失率列移除
- 数值与分类数据处理
# 📈 模型性能
| 模型 | 精确率 | 召回率 | F1 分数 | ROC-AUC |
|---|---|---|---|---|
| 逻辑回归 | 0.1030 | 0.5684 | 0.1744 | 0.7328 |
| 随机森林 | 0.2312 | 0.7433 | 0.3527 | 0.9066 |
# 🏆 最佳模型
## 随机森林
### 最终性能
| 指标 | 分数 |
|---|---|
| ROC-AUC | 0.9066 |
| 召回率 | 74.33% |
# 🔥 关键业务洞察
- 欺诈交易高度不平衡,仅占总交易的很小一部分。
- 交易金额模式在不同金额组中显示出不同的欺诈行为。
- 欺诈活动在不同交易小时中显著变化。
- 产品类别显示出不同的欺诈风险模式。
- 银行卡相关特征成为强欺诈指标。
- 电子邮件域名行为提供了有用的欺诈情报信号。
- 移动设备相比桌面设备显示出更高的欺诈活动。
- 身份和距离信息的缺失成为重要的欺诈指标。
- 自定义风险评分显著提升了欺诈检测能力。
- 随机森林在欺诈检测性能上远优于逻辑回归。
- 阈值调整有助于平衡欺诈检测与误报。
- Isolation Forest 成功检测出异常的交易行为模式。
# 🎯 风险智能系统
本项目生成:
- 欺诈概率预测
- 风险分层
- 交易级欺诈情报
交易被划分为:
- 低风险
- 中风险
- 高风险
# 🎯 最终输出
系统生成:
- 欺诈概率分数
- 基于风险的交易分层
- 欺诈情报输出数据集
- 清理后的欺诈就绪数据集
# 👨💻 关于我
## Sayan Naha
📧 **邮箱:** snsayan2012@gmail.com
🔗 **LinkedIn:** [Sayan Naha](https://www.linkedin.com/in/sayan-naha/)
标签:Apex, IEEE-CIS数据集, Python编程, 不平衡数据处理, 交易数据分析, 异常检测, 探索性数据分析, 数据预处理, 机器学习, 模型评估, 欺诈概率生成, 欺诈模式识别, 欺诈风险分析, 特征工程, 身份数据, 逆向工具, 金融数据挖掘, 金融欺诈检测, 风险分段, 风险智能系统, 风险特征工程