vatsalparikh96/can-bus-anomaly-detection
GitHub: vatsalparikh96/can-bus-anomaly-detection
使用 PyTorch MLP 自编码器实现 CAN 总线无监督入侵检测,并在 OTIDS 与 CrySyS 数据集上完成训练和跨数据集域偏移评估。
Stars: 0 | Forks: 0
# 使用 MLP Autoencoder 进行 CAN 总线异常检测
## TL;DR
一个端到端解决真实汽车网络安全问题的作品集项目:
1. **数据理解** — 解析 200 MB 的原始 CAN 总线日志文件,记录特殊格式,并确定预处理规则。
2. **建模** — 设计并训练一个小型 MLP autoencoder,从零开始编写标准的 PyTorch 训练循环。
3. **客观评估** — 优先使用 PR-AUC 而不是 F1,因为 OTIDS 中的标签是文件级别的,而不是按帧标注的。仅使用训练数据选择阈值,以保持测试集的纯净。
4. **超参数扫描** 及文档化的直觉 (`results/iteration_log.md`) — 三次全量数据运行加上一次冒烟基线测试,并对每个结果进行了机制层面的推理。
5. **跨数据集评估** (在 CrySyS 上) — 相同的架构,不同的车辆 — 揭示了单数据集训练在何处会失效。
这**不是**一个代表最先进水平的基准测试,也不是一个生产级的入侵检测系统。它是一个达到作品集标准的项目演示,展示了将 CAN 总线异常检测想法从原始数据转化为可靠数据所需的*工程素养*。
## 0. 术语表
### 汽车网络
| 术语 | 含义 |
|---|---|
| **CAN 总线** (Controller Area Network) | 自 20 世纪 90 年代以来占主导地位的车内通信标准。一种共享的串行广播总线,连接车内所有的微控制器。专为可靠性和低延迟而设计,**而非**为了安全性 — 帧未经身份验证,任何节点都可以传输任何内容。 |
| **CAN 帧** | 总线上的一条消息。包含一个 **CAN ID** (11 位)、一个 **DLC**、0-8 个**数据字节**以及一个时间戳。 |
| **ECU** (Electronic Control Unit,电子控制单元) | 运行在车辆中的微控制器 — 发动机 ECU、制动 ECU、ABS ECU、信息娱乐 ECU 等。现代汽车拥有 50-150 个 ECU。每个 ECU 都会传输具有其自身特征 CAN ID 的消息。 |
| **CAN ID** | 每个帧上的 11 位标识符,用于说明“这是哪种类型的消息”(发动机转速、轮速等)。较低的 CAN ID 具有较高的总线优先级。 |
| **DLC** (Data Length Code,数据长度代码) | 帧中的数据字节数,从 0 到 8。其余的字节插槽未使用。 |
| **OEM** (Original Equipment Manufacturer,原始设备制造商) | 车辆制造商 — BMW、大众、丰田等。每个 OEM 都使用自己的 CAN ID 映射,因此起亚和大众的流量在链路上看起来完全不同。 |
| **SocketCAN / candump** | Linux 的标准 CAN 驱动程序及其日志文件格式。格式为 `(timestamp) interface can_id#data_bytes`。CrySyS 使用此格式;而 OTIDS 不使用。 |
### 网络安全 / 攻击
| 术语 | 含义 |
|---|---|
| **IDS** (Intrusion Detection System,入侵检测系统) | 监视网络流量并标记潜在攻击的系统。*基于网络的* IDS 监视数据包流;*基于主机的* IDS 监视单个设备。本项目构建的是一个 CAN 总线网络 IDS。 |
| **DoS 攻击** (Denial of Service,拒绝服务) | 用高优先级消息淹没总线(通常是 CAN ID `0x000`,因为它的数值最低,因此优先级最高)。合法的 ECU 会失去传输时间。 |
| **模糊攻击** (Fuzzy attack) | 注入带有随机数据字节的随机 CAN ID。目的通常是侦察:弄清楚哪些 ID/数据会触发哪些行为。 |
| **冒充攻击** / **伪装攻击** (Masquerade attack) | 注入看起来像是来自合法 ECU 的消息 — 相同的 CAN ID,但具有欺骗性的数据值以操纵车辆行为。这是最难检测的攻击,因为除了数据之外,该消息看起来很正常。 |
| **伪造攻击** (Fabrication attack) | 向总线中注入*新的*恶意帧(DoS、模糊攻击和某种形式的冒充攻击都属于伪造攻击)。 |
| **欺骗** (Spoofing) | 通过发送另一个节点的消息来冒充它。与冒充/伪装的意思相同。 |
### 机器学习 / 深度学习
| 术语 | 含义 |
|---|---|
| **Autoencoder** | 一种包含两部分的神经网络 — encoder 将输入压缩为低维表示,decoder 从该表示中重建输入。经过训练以复现其输入。这种压缩迫使模型学习正常数据的*结构*。**用于异常检测:** 在正常数据上进行训练,然后对新数据的高重建误差发出异常信号。 |
| **MLP** (Multi-Layer Perceptron,多层感知机) | 最简单的神经网络:由非线性激活分隔的堆叠全连接(Linear)层。没有卷积,也没有循环。 |
| **LSTM** (Long Short-Term Memory,长短期记忆) | 一种循环神经网络,可以处理序列并记住跨时间步的上下文。在时间模式很重要时使用 — 本项目未使用,但建议作为下一步。 |
| **Bottleneck** | autoencoder 中最小的层。所有信息都必须通过它,从而强制进行压缩。 |
| **MSE** (Mean Squared Error,均方误差) | 一种损失函数:所有特征上 `(prediction − target)²` 的平均值。在这里使用是因为 autoencoder 的输出是一个连续值向量。 |
| **重建误差** (Reconstruction error) | autoencoder 输入与其输出之间的 MSE。值小 = 模型“识别”了输入。值大 = 模型未能“识别”。 |
| **阈值** (Threshold) | 重建误差的值,超过该值的帧将被标记为异常。在本项目中,该值选取在训练误差的第 99 百分位数处。 |
| **PR-AUC** (Precision-Recall Area Under Curve,精确率-召回率曲线下面积) | 对检测质量的与*阈值无关*的单一数值总结。通过在所有值上扫描阈值并积分精确率 × 召回率来计算。范围为 `[0, 1]`;越高越好。**对于数据不平衡或标签粗糙的无监督异常检测,这是最客观的指标。** |
| **精确率** (Precision) | 在模型*标记*为异常的帧中,实际上有多少比例是真正的异常?`TP / (TP + FP)`。高精确率 = 误报少。 |
| **召回率** (Recall) | 在*实际*为异常的帧中,模型标记了多少比例?`TP / (TP + FN)`。高召回率 = 漏报少。 |
| **F1 分数** (F1 score) | 精确率和召回率的调和平均值。只有在*两者*都很高时才会很高。当标签粗糙或阈值错误时,它可能会产生误导 — 而这正是我们的情况,因此我们报告 PR-AUC。 |
| **混淆矩阵** (Confusion matrix) | 一个 2×2 的表格:(模型判断为正,模型判断为负) × (实际为正,实际为负)。以上四个指标均由此推导而来。 |
| **独热编码** (One-hot encoding) | 将分类值(如 CAN ID)转换为一个在某个位置为 `1`,其他位置为 `0` 的向量。使神经网络能够将每个类别视为一个单独的特征。 |
| **Sigmoid** / **ReLU** | 激活函数。**Sigmoid** 将任何输入压缩到 `[0, 1]` 范围内。**ReLU** (Rectified Linear Unit,修正线性单元) 原封不动地传递正值并将负值置零。 |
| **Adam** | 用于训练神经网络的最常见优化器;自适应地调整每个参数的学习率。我们使用了它。 |
| **训练 / 验证 / 测试集划分** (Train / val / test split) | 你的数据被划分成的三个子集。**训练集**:使用这些数据更新权重。**验证集**:在训练期间根据这些数据评估模型(用于提前停止);权重*不*更新。**测试集**:完全保留直到最终评估,以给出真实的数字。 |
| **提前停止** (Early stopping) | 当验证损失停止改善时停止训练。防止过拟合。 |
| **过拟合** (Overfitting) | 当模型记住了训练数据并在新数据上失效时。训练损失持续下降,而验证损失开始上升。 |
| **数据泄露** (Data leakage) | 当来自测试集的信息意外影响了训练时(例如,使用在整个数据集上计算的统计信息进行归一化)。会夸大报告的数据;导致模型在生产环境中失效。 |
| **领域偏移** (Domain shift) | 当训练数据和部署数据来自不同的分布时。跨数据集评估正是如此 — 在起亚车型上训练,部署到不同的车辆上。 |
| **Embedding** | 对分类事物的学习到的低维向量表示。是独热编码的一种替代方案,可以在不同数据集之间迁移。 |
| **autograd** | PyTorch 的自动微分引擎。记录你对张量执行的每一个操作,以便它可以通过 `loss.backward()` 计算梯度。 |
| **`nn.Module`** | 任何 PyTorch 模型或层的基类。你可以继承它,在 `__init__` 中定义你的层,并在 `forward()` 中定义前向传播。 |
| **DataLoader** | 一个 PyTorch 实用程序,用于对 Dataset 中的数据进行批处理和打乱。 |
| **BPTT** (Back-Propagation Through Time,随时间反向传播) | 应用于如 LSTM 等循环神经网络的反向传播。此处未使用,但在“后续步骤”部分中提到了。 |
### 数据集与实验室
| 术语 | 含义 |
|---|---|
| **OTIDS** | 来自韩国大学 HCRL (Hacking and Countermeasures Research Lab) 的 CAN 入侵数据集。记录自一辆起亚 Soul。事实上的 CAN 总线 IDS 研究入门基准。 |
| **CrySyS** | 来自 CrySyS Lab(匈牙利布达佩斯技术与经济大学)的 CAN 流量数据集,于 2023 年发表在《Nature Scientific Data》上。在此用作跨数据集领域偏移测试。 |
| **HCRL** | Hacking and Countermeasures Research Lab。发布 OTIDS 的韩国研究团队。 |
| **Figshare** | CrySyS 托管其数据集的公共科学数据存储库。 |
### 工程 / 标准
| 术语 | 含义 |
|---|---|
| **ISO 26262** | 汽车电子的功能安全标准。定义了如何系统地降低安全关键特性中的风险。 |
| **ASIL** (Automotive Safety Integrity Level,汽车安全完整性等级) | ISO 26262 中的风险分类 — ASIL D 是最高的安全完整性级别,ASIL A 是最低的。用于驱动设计和验证的严谨性。 |
| **ADAS** (Advanced Driver-Assistance Systems,高级驾驶辅助系统) | 如车道保持、自适应巡航、自动紧急制动等功能。这是与本项目职业发展相关的背景。 |
## 1. 问题
Controller Area Network 总线自 20 世纪 90 年代初以来一直是占主导地位的车内通信标准。它的设计初衷是低成本、低延迟和容错能力 — 而**不是**安全性。每个 CAN 帧都会广播给每个节点,这些帧未经身份验证,任何被攻陷的 ECU 都可以伪造来自任何其他 ECU 的消息。
在实践中,这使得针对现代车辆的三类攻击成为可能:
- **拒绝服务**:恶意节点用高优先级帧(通常是 CAN ID `0x000`,因为它在所有仲裁中都会胜出)淹没总线,导致合法的 ECU 失去传输机会。实际影响:仪表盘冻结、油门/刹车指令丢失。
- **模糊攻击**:注入带有随机数据字节的随机 CAN ID。用于侦察 — 找出哪些消息会产生哪些行为。
- **冒充 / 伪装**:被攻陷的 ECU 发出看起来像是来自另一个合法 ECU 的消息,但带有微妙篡改过的数据值。这是最难检测的攻击,因为除了数据值之外,该消息看起来很正常,而且接收方 ECU 会信任总线上的任何内容。
一个**有监督的**入侵检测器 — 在带有标签的攻击样本上训练分类器 — 无法泛化到未知的攻击模式。使用 autoencoder 的**无监督**异常检测巧妙地避开了这一点:仅在*正常*流量上训练模型,然后标记模型无法重建的任何帧。
本项目实现了该想法的最简单、可信的版本,对其进行了客观评估,并测试了其极限。
## 2. 数据集
### 主要:OTIDS
| 属性 | 值 |
|---|---|
| 来源 | [OTIDS — CAN 入侵数据集 (HCRL, 韩国大学)](https://ocslab.hksecurity.net/Dataset/CAN-intrusion-dataset) |
| 车辆 | 起亚 Soul |
| `Attack_free_dataset.txt` | 200 MB,约 450 万帧,驾驶 |
| `DoS_attack_dataset.txt` | 56 MB,正常流量中注入 `0x000` |
| `Fuzzy_attack_dataset.txt` | 51 MB,正常流量中注入随机 ID / 数据 |
| `Impersonation_attack_dataset.txt` | 84 MB,正常流量中注入欺骗性的合法 ID |
**行格式**(以空格分隔,带有内联标签词):
```
Timestamp: 0.000000 ID: 0316 000 DLC: 8 05 20 ea 0a 20 1a 00 7f
```
**标签警告。** OTIDS 攻击文件包含合法帧和注入帧的*混合体*,但唯一可用的标签是*文件名*(这整个文件是在 DoS 攻击场景下录制的)。没有按帧标注的攻击标签。这使得 F1 分数具有误导性,而 PR-AUC 才是客观的指标 — 在结果中进行了说明。
### 跨数据集:CrySyS
| 属性 | 值 |
|---|---|
| 来源 | [CrySyS Lab](https://www.crysys.hu/research/vehicle-security) (布达佩斯技术与经济大学)。发表在 [*Nature Scientific Data*, 2023](https://www.nature.com/articles/s41597-023-02716-9) 上。 |
| 格式 | SocketCAN candump:`() can0 #` |
| 大小 | 26 个场景记录,解压后约 12 GB,包含约 2.5 小时的良性流量以及攻击变体 |
在此用作跨车辆泛化的分布外测试。
### 如何下载
OTIDS:在 [`notebooks/project/01_explore_otids.ipynb`](notebooks/project/01_explore_otids.ipynb) 内自动下载。
CrySyS:一次性手动下载 — 详见 [`notebooks/project/03_crysys_cross_dataset.ipynb`](notebooks/project/03_crysys_cross_dataset.ipynb) 中的 Figshare 链接。两者最终都存放在 `data/` 下(该目录已被 gitignored — 永远不会提交数据集)。
## 3. 方法
### 特征工程
每个 CAN 帧都被转换为一个 40 维的特征向量:
| 切片 | 维度 | 编码 | 为何这样选择 |
|---|---:|---|---|
| 前 30 个 CAN ID(独热编码) | 30 | 从训练集中学习 | 告诉模型“这是哪种类型的 ECU 消息?” |
| “其他”桶 | 1 | 全局捕获的 0/1 标志 | 捕获罕见或未知的 ID |
| 数据字节 0-7 | 8 | `byte / 255` | 硬件定义的范围(每字节 0-255) → 固定的 min-max 缩放,无需拟合 |
| DLC | 1 | `dlc / 8` | 规范范围(0-8) → 固定缩放 |
**工程准则说明。** 前 30 个 CAN ID 列表*仅*从*训练集*中学习得到。验证集、测试集和 CrySyS 划分使用这些学习到的 ID 进行转换,不作修改。这是标准的 scikit-learn `fit`/`transform` 模式,可防止*数据泄露*。详见 [`src/data/preprocess.py`](src/data/preprocess.py) 中的 `FeatureBuilder` 类。
### 模型
```
Input (40) → Linear(40, 16) → ReLU
→ Linear(16, 8) → ReLU [bottleneck — 8 dim]
→ Linear( 8, 16) → ReLU
→ Linear(16, 40) → Sigmoid [output bounded to [0, 1]]
```
总共有大约 1,400 个参数。sigmoid 输出将重建范围限制在 `[0, 1]`,这与我们将特征归一化的范围相同 — 因此 MSE 损失是定义明确的。详见 [`src/models/autoencoder.py`](src/models/autoencoder.py)。
### 训练
| 超参数 | 值 | 理由 |
|---|---|---|
| 损失函数 | MSE | 输入和目标是相同的连续值向量(autoencoder 目标) |
| 优化器 | Adam,学习率 = 1e-3 | 对大多数问题都能“直接生效”的基线 |
| 批大小 | 256 | 消费级 GPU 上处理表格数据的标准配置 |
| 轮次 | 最多 30 次,并带有提前停止(耐心值 = 5) | 在实践中通常在 15-25 次内收敛 |
| 训练 / 验证 / 测试集划分 | 70 / 15 / 15(按时间顺序) | 因为 CAN 数据是序列化的,所以按时间顺序划分;随机打乱会导致时间戳在各划分集之间泄露 |
### 阈值选择
检测阈值设置在**训练集重建误差的第 99 百分位数**处。我们使用*训练集*误差(而不是验证集),以便让验证集保持纯净用于提前停止,让测试集保持纯净用于报告结果。第 99 百分位数是比较保守的 — 我们宁愿有较高的精确率也不愿有较高的召回率,因为误刹车是危险的(这正是 ADAS 的应用背景)。
与阈值无关的排序质量作为 PR-AUC 单独报告。
## 4. 结果
### OTIDS(领域内,全量数据,获胜配置:top_k=30, bottleneck=8)
| 攻击类型 | 精确率 | 召回率 | F1 | **PR-AUC** |
|---|---:|---:|---:|---:|
| DoS | 0.944 | 0.047 | 0.090 | **0.694** |
| 模糊攻击 | 0.993 | 0.446 | 0.615 | **0.892** |
| 冒充攻击 | 0.856 | 0.011 | 0.022 | **0.797** |
在保留的无攻击测试集划分上的假阳性率:**0.52%**。
**为什么尽管 PR-AUC 很强,但 F1 看起来却很低。** OTIDS 中的每个“攻击文件”都包含合法驾驶帧和注入攻击帧的混合,但唯一的真实标签是*文件名*(没有按帧标注的标签)。第 99 百分位阈值以非常高的精确率标记最异常的帧(超过阈值的每一帧确实都是异常的 — 各项的精确率均 > 0.85),但每个攻击文件中的大部分帧都是合法驾驶,模型正确地*没有*标记它们 — 这拉低了召回率(进而影响了 F1)。**PR-AUC 衡量的是模型在不考虑阈值的情况下将攻击帧排在良性帧之上的能力,这才是这里最客观的指标。**
图表:
- 训练损失: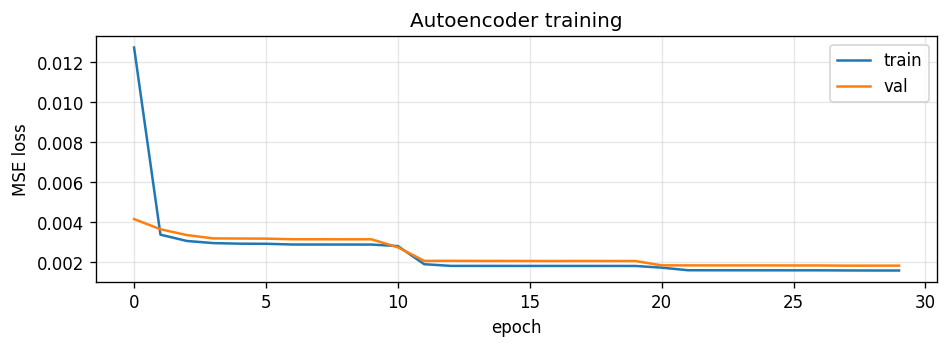
- 重建误差直方图(每种攻击一个):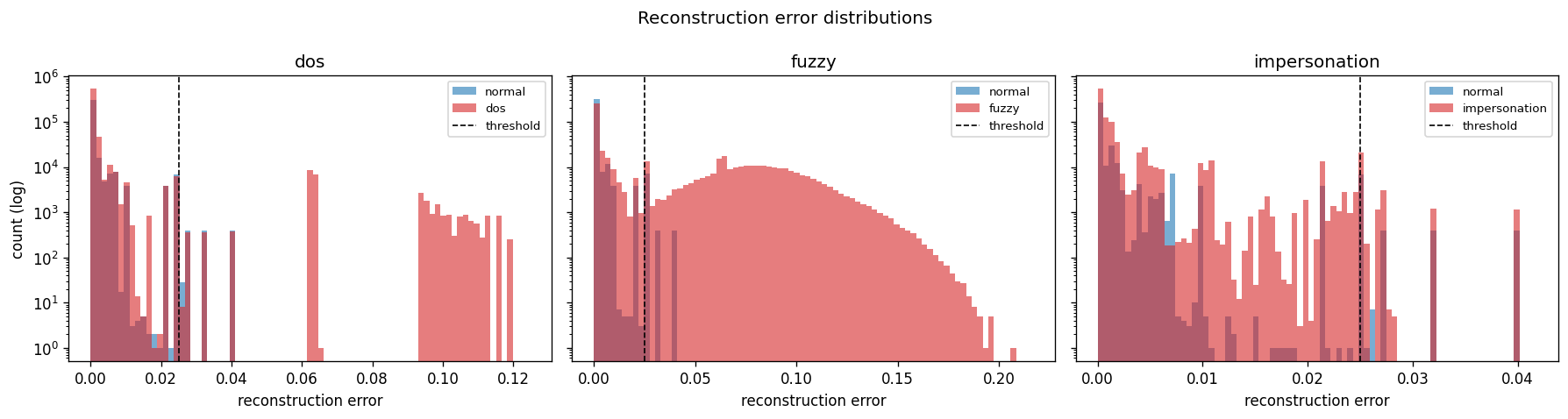
- 精确率-召回率曲线: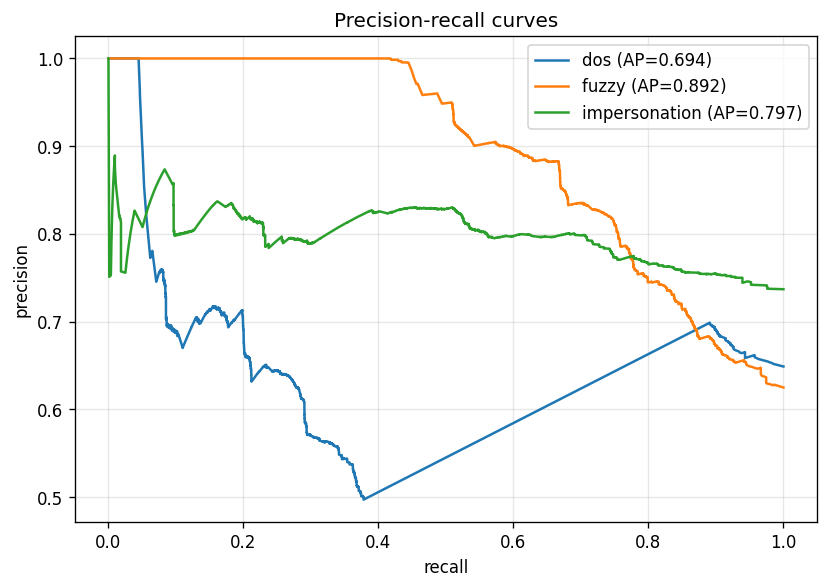
### 跨数据集评估(相同的模型,但在 CrySyS 数据上)
| 指标 | OTIDS 领域内 | CrySyS 跨领域 | 变化 |
|---|---:|---:|---:|
| 良性假阳性率 | 0.52% | **43.6%** | 恶化约 80 倍 |
| 三种攻击类型的平均攻击 PR-AUC | ~0.79 | **~0.05** | 崩溃至近似随机 |
**为什么会发生这种情况。** CrySyS 中的 18 个 CAN ID 中只有 1 个与 OTIDS 的前 30 个重叠(因为车辆使用了具有不同消息目录的不同 ECU)。因此,**99.8% 的 CrySyS 帧落入了 OTIDS 学习到的“其他”桶中** — 而在 OTIDS 上训练的 autoencoder 在训练期间很少见到“其他”桶的帧,因此无法很好地重建它们。模型不加区分地将良性的 CrySyS 帧和 CrySyS 攻击帧都标记为异常。
**根本原因是特征管道,而不是模型。** 不同的车辆有不同的 ECU ID,而我们的独热编码无法迁移。提议的补救措施:
1. **在目标车辆数据上重新拟合 FeatureBuilder。** 成本很低;虽然不能解决根本问题,但可以减轻表面症状。
2. **联合在多辆车上进行训练。** 多领域训练。模型学习与车辆无关的特征。
3. **用学习到的 CAN-ID embedding 替换独热编码**,跨数据集联合训练。Embedding 能够以独热编码无法做到的方式在不同车辆间泛化。
有关完整的分析,请参见 [`notebooks/project/03_crysys_cross_dataset.ipynb`](notebooks/project/03_crysys_cross_dataset.ipynb)。图表:
- 领域偏移直方图: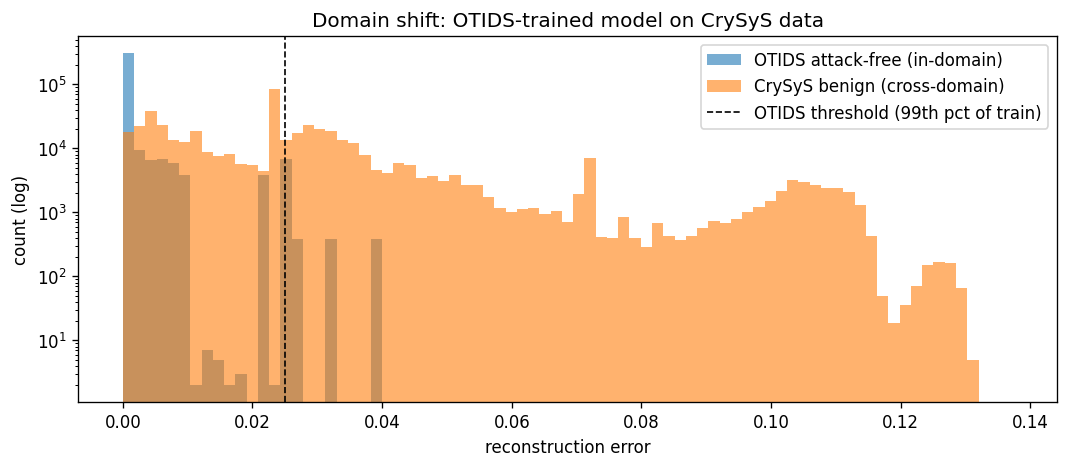
- 跨数据集攻击直方图: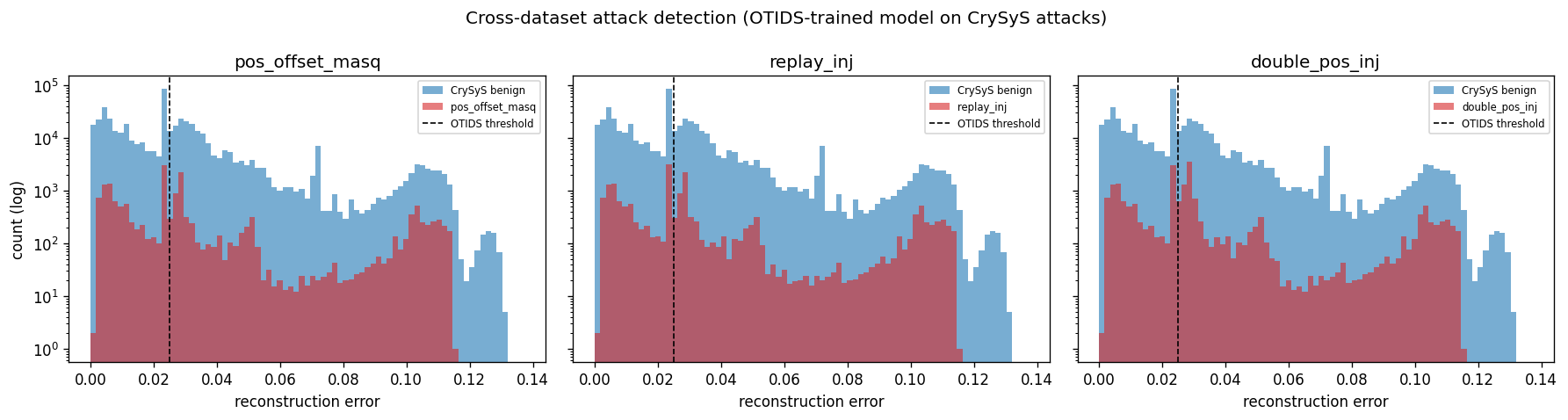
### 超参数研究
三次全量数据运行加上冒烟基线。完整记录在 [`results/iteration_log.md`](results/iteration_log.md) 中。核心发现:
- **更宽的 top-K (20 → 30) 持续发挥作用**,在冒充攻击上的增益最大(PR-AUC 增加 0.030)。原因:冒充攻击使用的是*合法的* CAN ID;为这些 ID 提供显式的特征列,可以让模型表达“*这个特定* ID 的数据字节看起来不对”。
- **更窄的 bottleneck (8 → 4) 在所有三种攻击中都造成了负面影响。** 过度压缩提高了正常重建的噪声基准,却没有按比例提高异常信号。Autoencoder 容量的 U 型曲线规律是真实存在的。
- **冒烟运行(LIMIT=200,000 行)在 PR-AUC 上击败了所有全量数据运行。** 机制:按时间顺序的狭窄训练切片产生了*狭窄*的“正常”分布 → 与异常之间的差距更大 → 在存在偏差的 OTIDS 标签上 PR-AUC 更高。对于部署而言,全量数据模型才是客观的。*经验教训:在无监督异常检测中,更多的数据可以改善建模,但也可能压缩异常检测信号。*
并排可视化:[`notebooks/project/04_hyperparameter_comparison.ipynb`](notebooks/project/04_hyperparameter_comparison.ipynb)。
## 5. 复现
### 环境设置
```
git clone https://github.com/vatsalparikh96/can-bus-anomaly-detection.git
cd can-bus-anomaly-detection
uv sync # core deps + PyTorch (CUDA 11.8)
uv sync --extra dev # add pytest
uv sync --extra notebook # add Jupyter
```
`uv` 将根据 `pyproject.toml` 中的 `[tool.uv.sources]` 自动安装 CUDA 11.8 PyTorch wheel。除了在全量数据集上进行训练外,仅使用 CPU 即可完成所有工作;下面的冒烟测试运行在任何机器上都可以正常工作。
如果你没有 `uv`:请执行 `pip install uv` 然后重新运行,或者直接使用 `pip install -e .` 从 `pyproject.toml` 安装。
### 下载数据
OTIDS:打开 [`notebooks/project/01_explore_otids.ipynb`](notebooks/project/01_explore_otids.ipynb) 并运行数据下载单元。最终状态:在 `data/otids/raw/` 目录下有 4 个文件。
CrySyS:从 Figshare 一次性下载 2.85 GB 的 ZIP 文件 — 请参阅 [`notebooks/project/03_crysys_cross_dataset.ipynb`](notebooks/project/03_crysys_cross_dataset.ipynb) 内部的链接。解压到 `data/crysys/logs/` 下。
### 训练与评估
全量数据训练(在如 GTX 1650 的消费级 GPU 上约需 10 分钟):
```
uv run python scripts/train.py --out-dir results/runs/new_run --top-k 30 --epochs 30
uv run python scripts/evaluate.py --out-dir results/runs/new_run
```
快速冒烟测试运行(总共约需 2 分钟):
```
uv run python scripts/train.py --limit 200000 --epochs 10 --out-dir results/runs/smoke
uv run python scripts/evaluate.py --out-dir results/runs/smoke
```
### 测试
```
uv run pytest # 13 tests, runs in ~25 seconds
```
## 6. 仓库结构
```
can-bus-anomaly-detection/
├── README.md # this file
├── LICENSE # MIT
├── pyproject.toml # project metadata, dependencies, pytest config
├── uv.lock # exact dependency versions (uv-managed)
├── .gitignore # excludes data/, .venv/, *.pt, *.npy, *.npz
├── configs/
│ └── default.yaml # training hyperparameters
├── data/ # gitignored — datasets live here
├── notebooks/
│ └── project/ # the four analytical notebooks behind this README
│ ├── 01_explore_otids.ipynb # OTIDS dataset deep-dive
│ ├── 02_autoencoder.ipynb # MLP autoencoder prototype
│ ├── 03_crysys_cross_dataset.ipynb # cross-dataset domain shift study
│ ├── 04_hyperparameter_comparison.ipynb # hyperparameter sweep analysis
│ └── _build_*.py # Python source-of-truth that generates each .ipynb
├── src/
│ ├── data/
│ │ ├── load.py # OTIDS log parser
│ │ ├── load_crysys.py # CrySyS (candump) log parser
│ │ ├── preprocess.py # FeatureBuilder (fit/transform/save/load)
│ │ └── dataset.py # CANFrameDataset (PyTorch Dataset wrapper)
│ ├── models/
│ │ └── autoencoder.py # MLPAutoencoder
│ ├── training/
│ │ ├── train.py # training loop with early stopping
│ │ └── evaluate.py # reconstruction-error / threshold / metric helpers
│ └── utils/
│ └── plot.py # plot_loss_curves, plot_recon_error_hist, plot_pr_curves
├── scripts/
│ ├── train.py # CLI entry: train + save artifacts
│ └── evaluate.py # CLI entry: evaluate + save metrics + plots
├── tests/
│ ├── test_preprocess.py # 8 tests for FeatureBuilder
│ └── test_model.py # 5 tests for MLPAutoencoder
└── results/
├── *.png # tracked — plots referenced in this README
├── *.json # tracked — metrics + history + model config
├── iteration_log.md # the hyperparameter sweep writeup
└── runs/{smoke_v1, run1_baseline, run2_topk30, run3_bottleneck4}/
# per-run artifacts
```
## 7. 讨论与局限性
**本项目充分展示的地方。**
- 端到端的 PyTorch 实践能力:从原始文本日志解析到训练循环、评估和 CLI 部署。
- 围绕评估的严谨性:优先使用 PR-AUC 而非 F1,并明确指出了标签的警告。
- 建立在真实实验而非经验之谈基础上的超参数直觉(详见 `iteration_log.md`)。
- 领域偏移评估:展示了跨车辆时泛化的真实表现。
- 面向生产的代码结构:可测试的模块、CLI 脚本、配置文件、可复现的运行。
**本项目*不*主张的内容。**
- 它不是代表最先进水平的基准测试。该架构是刻意保持简单的 — 在 40 个特征输入上的按帧处理的 MLP。已发表的基准测试使用了序列模型(LSTM-AE、基于 Transformer 的模型),并在相同数据集上报告了更高的数值。
- 它没有使用时间信息。冒充攻击特别会破坏 CAN ID 数据字节的*时间*模式(像 RPM 这样缓慢变化的信号会得到一个平滑变化的序列;欺骗性的帧打破了这种平滑度)。按帧处理的 MLP 看不到这一点。LSTM autoencoder 很可能会将冒充攻击的 PR-AUC 从约 0.80 提升到 0.90+。
- 它不处理多车辆部署。如结果所示,在 OTIDS 上训练的模型在 CrySyS 上彻底失败。生产环境部署将需要多领域训练或学习到的 CAN-ID embedding。
## 8. 参考资料
- **OTIDS:** Lee, H., Jeong, S. H., & Kim, H. K. (2017). *OTIDS: A novel intrusion detection system for in-vehicle network by using remote frame.* HC Korea University. Dataset: [https://ocslab.hksecurity.net/Dataset/CAN-intrusion-dataset](https://ocslab.hksecurity.net/Dataset/CAN-intrusion-dataset).
- **CrySyS:** Gazdag, A., Ferenc, R., & Buttyán, L. (2023). *CrySyS dataset of CAN traffic logs containing fabrication and masquerade attacks.* Nature Scientific Data 10, 903. DOI: [https://doi.org/10.1038/s41597-023-02716-9](https://doi.org/10.1038/s41597-023-02716-9).
- PyTorch 教程: [learnpytorch.io](https://www.learnpytorch.io/), [Sebastian Raschka — PyTorch in One Hour](https://sebastianraschka.com/teaching/pytorch-1h/).
- 异常检测背景: [Demystifying anomaly detection with autoencoders](https://medium.com/@weidagang/demystifying-anomaly-detection-with-autoencoder-neural-networks-1e235840d879).
标签:Apex, PyTorch, 代码示例, 凭据扫描, 安全, 异常检测, 数据分析, 机器学习, 自动驾驶, 超时处理, 车联网安全, 逆向工具