tardigrade1001/spectrex
GitHub: tardigrade1001/spectrex
将日立分光光度计专有的 .UDS/.FDS 二进制光谱文件逆向解析并批量转换为通用 CSV,无需原厂软件即可在任何电脑上完成数据恢复。
Stars: 0 | Forks: 0
# spectrex
在任何 PC 上将日立(Hitachi)专有的分光光度计 `.UDS` 和 `.FDS` 二进制文件转换为纯 CSV(以及快速预览的 PNG 图表),无需依赖 1995 年时代的原版 Windows 软件。
| UV-Vis 吸光度 (`.UDS`) | 荧光发射 (`.FDS`) |
|:---:|:---:|
| 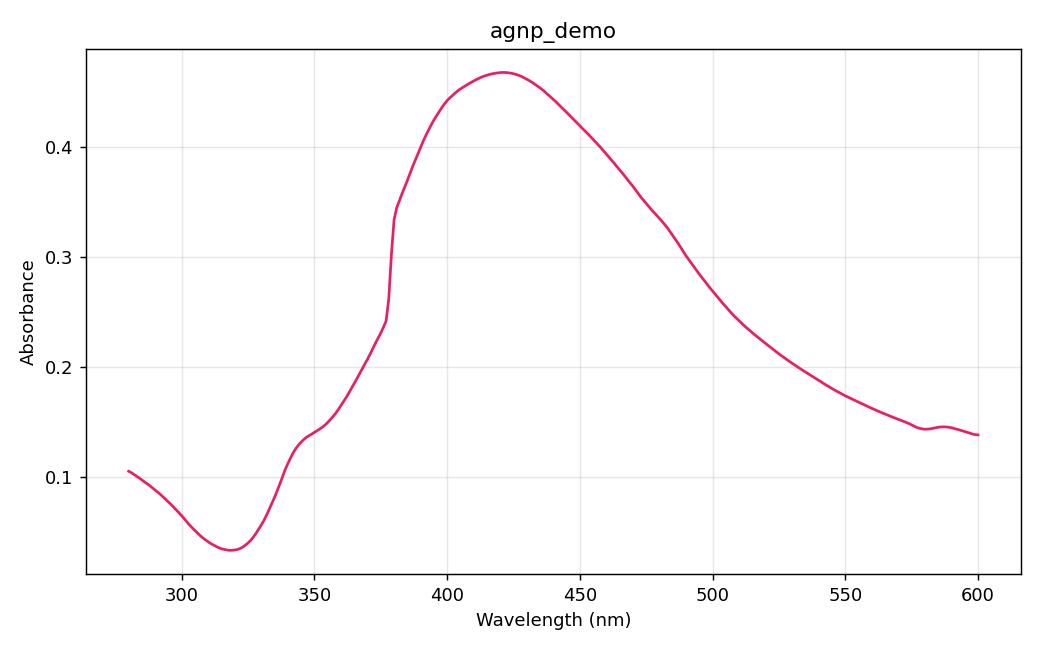 | 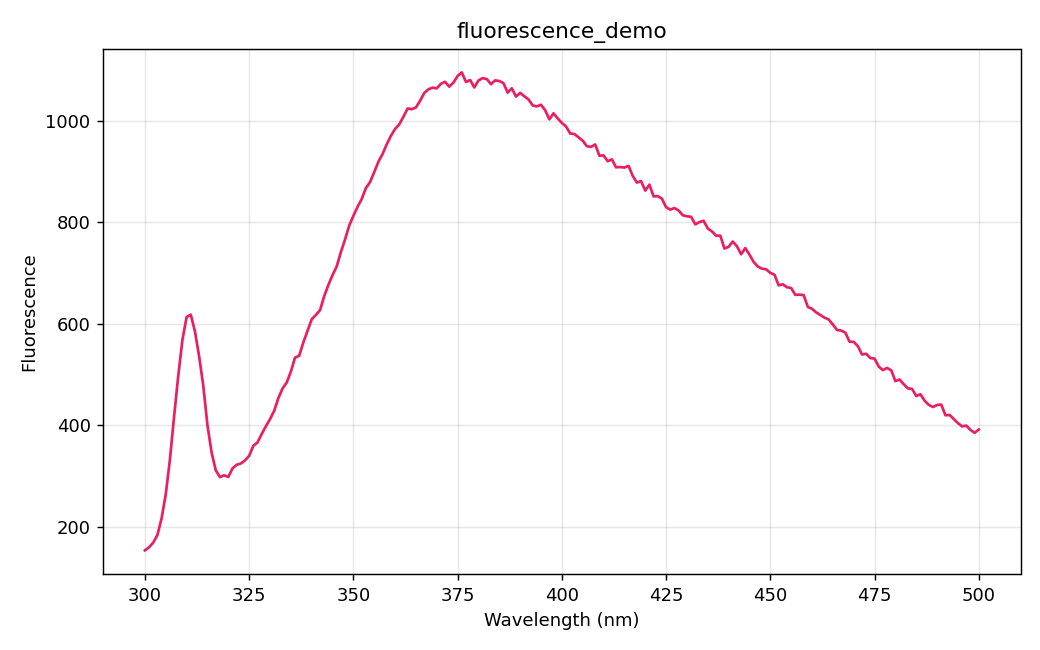 |
| 银纳米粒子等离激元峰 ~420 nm | 发射光谱(280 nm 激发) |
## 解决的问题
日立的 UV Solutions 和 FL Solutions 程序默认将数据保存为它们自己的二进制格式。它们在保存时提供了一个复选框,可以同时导出纯 TXT 文件。如果该复选框未被勾选,生成的 `.UDS`/`.FDS` 文件将无法在您的笔记本电脑上用任何其他软件打开。
通常的解决方法是亲自回到仪器 PC 前,在原版软件中逐一打开每个文件,并使用其“导出为 TXT”命令。当仪器 PC 正忙、位于另一栋建筑中,或者运行的是您不想碰的旧版 Windows 系统时,这种方法会变得非常痛苦。
本脚本直接读取这些二进制文件。用户现在可以在任何地方进行转换:他们自己的笔记本电脑、共享驱动器、旧测量的备份,无需返回仪器所在位置。
## 背景
本工具针对的仪器如下:
- **日立 U-2900 分光光度计**。用于 UV-Vis 吸光度,生成 `.UDS` 文件。由 *UV Solutions 4.2* 控制。
- **日立 F-4600 荧光分光光度计**。用于荧光,生成 `.FDS` 文件。由 *FL Solutions* 控制。
两者都是 Windows 9x 时代的程序。其二进制文件格式未公开文档。获取数据的唯一内置方法是在程序中打开每个文件并逐一运行其“导出为 TXT”命令。
本工具对这两种格式进行了逆向工程,并一次性转换整个文件目录树。
## 功能特性
指向一个文件夹,`spectrex.py` 会执行以下操作:
1. 递归查找其下的每个 `.UDS` 和 `.FDS` 文件。
2. 对于每个文件:
- 解析二进制头部(样品名称、时间戳、仪器、扫描参数)。
- 提取数据数组。
- 对于 UDS:将存储的透光率转换为吸光度(`A = -log₁₀ T`),并反转扫描方向,使 CSV 按波长升序排列。
- 对于 FDS:将 0.2 nm 内部存储的过采样数据抽样至 1.0 nm,以匹配仪器自身的 TXT 导出。在脚本顶部附近设置 `DECIMATE_FDS = False` 可保留完整的 0.2 nm 分辨率。
- 在原文件旁写入一个 CSV(基本名相同,扩展名为 `.csv`)。
- 在旁边写入一个单光谱 PNG 图表。
3. 在 `plots/` 文件夹中生成两张叠加 PNG 图表,一张用于所有 UDS 光谱,一张用于所有 FDS 光谱,以便快速进行跨样本比较。
4. 将所有操作记录到根目录的 `spectrex.log` 中。
## 快速开始
要求:Python 3.8+ 和 `matplotlib`。
```
pip install matplotlib
```
将 `spectrex.py` 放入包含您的数据的文件夹中(子目录会被自动遍历),然后运行:
```
python spectrex.py
```
或者指向一个特定的文件夹:
```
python spectrex.py "C:/path/to/data"
```
本代码库包含一个 `samples/` 文件夹,其中包含一个 UDS 文件和一个 FDS 文件,以及它们原始的 TXT 导出文件用于基准事实对比,因此您可以立即试用该工具:
```
python spectrex.py samples
```
输出如下所示:
```
OK Abs/AgNP - 04.03.UDS: UDS 321 pts 280-600 nm
OK Abs/AgNP - 07.03.UDS: UDS 321 pts 280-600 nm
note: 87/321 transmittance values are <=0 (very absorbing sample); absorbance set to NaN at those points
OK FDS/230222_sample_280nm.FDS: FDS 201 pts 300-500 nm
-> plots/_overlay_uds.png
-> plots/_overlay_fds.png
Done. 9 succeeded, 0 failed. Log: spectrex.log
```
重新运行该脚本将重新生成所有内容。CSV 和 PNG 输出可随时删除,并在下次运行时重新构建。
## 输出格式
每个 CSV 都有一个简短的注释头部,其后是数据。采集参数从二进制文件中提取,并与文件元数据一起输出。
对于 UDS:
```
# 类型: UDS
# 样品: ANDI+ Fe3+
# 时间戳: 10:16:32, 03/10/2022
# 仪器: U-2900 Spectrophotometer SN 2J15301 07 v 4.2
# 数据点: 321 范围: 280.00-600.00 nm
# 采样步长: 1.0 nm
# 狭缝宽度: 1.5 nm
# 扫描速度: 800.0 nm/min
# 光程长度: 10.0 mm
# 灯切换波长: 340.0 nm
# 基线校正: 无
# 响应设置: 中
wavelength_nm,absorbance
280.00,0.1049
281.00,0.1036
...
```
对于 FDS:
```
# 类型: FDS
# 样品: ANDI + AL3+
# 时间戳: 12:07:49, 02/23/2022
# 操作员: demo
# 仪器: F-4600 FL Spectrophotometer SN 2967-002 v5J24000 02
# 数据点: 201 范围: 300.00-500.00 nm
# 采样步长: 1.0 nm
# 激发波长: 280.0 nm
# 存储步长 (内部): 0.2 nm
# 注意: FDS 扫描速度、狭缝宽度、PMT 电压、响应和延迟
# 当前未被提取(似乎编码在二进制文件中;参见 README)。
wavelength_nm,fluorescence
300.00,154.1594
301.00,160.1994
...
```
波长始终为升序。值列对于 UDS 是 `absorbance`(吸光度),对于 FDS 是 `fluorescence`(荧光)。
### 关于 FDS 参数提取的说明
UDS 文件将采集参数存储在已知偏移量处,为普通的小端序双精度浮点数,因此可以恢复完整的参数集(扫描速度、狭缝宽度、光程、灯切换波长、基线校正、响应设置)。FDS 文件以编码形式存储某些参数,目前尚未完成映射:扫描速度、EX/EM 狭缝宽度、PMT 电压、响应时间和延迟。通过对具有不同参数的多个 FDS 文件进行差分分析,并未发现其偏移量是普通的双精度浮点数,这表明它们可能被存储为设置代码或查找表索引格式。这些字段目前在 FDS CSV 头部中显示为备注。欢迎贡献代码。
## 格式工作原理
如果有人想扩展该工具或编写自己的解析器,这部分非常重要。这两种格式都全程使用小端序 IEEE-754 双精度浮点数。
### UDS(日立 U-2900,文件扩展名 `.UDS`)
```
offset field bytes
0 magic "IIHIITAG" 8
8 (unknown / file id) 8
16 sample name (null-terminated string) var
timestamp (null-terminated string) var
instrument model (null-terminated string) var
serial number (null-terminated string) var
ROM version (null-terminated string) var
... a few more parameter doubles ...
slit width (double) 8
...
"None" (baseline correction name) var
"Medium" (response setting) var
lamp_change_wavelength (double, e.g. 340) 8
sampling_step (double, e.g. 1.0) 8
start_wavelength (double, e.g. 600) 8
N+0 transmittance value 1 (double) 8 <- data starts
N+8 transmittance value 2 8
... (N values in scan order: high to low wavelength)
footer sentinel (double, value 600.0) 8
start_wavelength repeated (double) 8
scan speed (double, e.g. 800) 8
start_wavelength repeated (double) 8
end_wavelength (double, e.g. 280) 8
path length (double, e.g. 10.0) 8
... more metadata strings + reserved space ...
```
关键事实:
- 仪器存储的是**透光率 T**。TXT 导出通过 `A = -log₁₀(T)` 进行转换。我们采用了相同的做法。
- 数据按**扫描顺序**存储。扫描从高波长到低波长运行,因此 `data[0]` 对应于起始波长(较高的那个)。我们在写入 CSV 之前将其反转。
- 数据数组的末尾通过开始页脚的哨兵值 `600.0` 来检测。任何绝对值 `abs(v) > 5` 的双精度数都超出了透光率范围,标志着数据的结束。
- 头部参数三元组为 `[lamp_change_wl, step, start_wl]`。结束波长未存储在头部;它是通过数据长度 × 步长推导出来的。
### FDS(日立 F-4600,文件扩展名 `.FDS`)
```
offset field bytes
0 magic "IIHIDTAG" 8
8 (unknown / file id) 8
16 sample name (null-terminated string) var
operator (null-terminated string) var
timestamp (null-terminated string) var
... reserved padding (00s or FFs) ...
anchor "F-4600 FL Spectrophotometer\0" var
ROM version (null-terminated) var
serial number (null-terminated) var
storage_step (double, value 0.2) 8
start_wavelength (double, e.g. 300) 8
D+0 record 0 (5 doubles) 40 <- data starts
D+40 record 1 (5 doubles) 40
... (N records, each = 5 oversampled intensity values at 0.2 nm spacing)
F-32 excitation wavelength (double) 8
F-24 (mystery double, e.g. 430) 8
F-16 zeros 16
F+0 "Reagent 1\0Reagent 2\0..." var
... filename string, more reserved space ...
```
关键事实:
- 仪器内部以 **0.2 nm 分辨率**进行扫描。其自身的 TXT 导出将其抽样至 1 nm。每条 40 字节的记录保存 5 个连续的 0.2 nm 采样点。
- 每条记录的第一个双精度数(记录内的偏移量 +0)是与 TXT 匹配的 1 nm 网格值。在脚本中设置 `DECIMATE_FDS = False` 可以每条记录写入全部 5 个采样点,以保留完整的 0.2 nm 分辨率。
- 数据从低波长扫描到高波长(自然方向)。
- 数据的末尾通过搜索 `"Reagent 1\0"` ASCII 标记来定位。它位于最后一个数据记录之后的 32 字节处。
- “F-4600”仪器字符串也被用作搜索锚点。在运行信息字符串和仪器块字符串之间的填充,在不同文件中其长度和填充字节各不相同。
## 健壮性
在为本工具构建时所针对的 U-2900 + F-4600 + UV Solutions / FL Solutions 系统的限制范围内,它可以处理:
- 任意的样品名称、操作员姓名、时间戳、注释。
- 不同的波长范围、步长(`0.1, 0.2, 0.5, 1.0, 2.0, 5.0 nm`)和点数。
- 极高吸收的样品,其透光率降至零或略呈负值。这些点在吸光度中变为 `NaN`。
- 两种扫描方向(UDS 从高到低,FDS 从低到高)。
会导致程序中断的情况(以及相应的错误信息):
- 不同的仪器(例如,日立 F-2700、F-7000)生成了具有不同魔术字节或锚点的文件 → `unrecognized magic bytes` 或 `instrument anchor 'F-4600' not found`。
- 不同的软件版本省略了 `"Reagent 1\0"` 页脚标记 → `footer marker 'Reagent 1\0' not found after data block`。
- `storage_step` 不等于约 0.2 nm 的 FDS 文件 → `storage_step X outside expected range`。
- 步长值不在白名单中的 UDS 文件 → `UDS data block not found`。
每次失败都会标记其阶段(`[parse]`、`[csv]`、`[png]`)以及人类可读的原因。意外异常也会输出 Python 堆栈跟踪。所有信息均输出到标准输出和 `spectrex.log`。
## 项目布局
对包含数据的文件夹进行典型运行后,最终结果如下所示:
```
your-data-folder/
├── spectrex.py
├── spectrex.log
├── plots/
│ ├── _overlay_uds.png
│ └── _overlay_fds.png
├── Abs/ # (your folder structure: anything goes)
│ ├── sample1.UDS
│ ├── sample1.csv # generated
│ ├── sample1.png # generated
│ └── ...
└── FDS/
├── sample1_280nm.FDS
├── sample1_280nm.csv # generated
├── sample1_280nm.png # generated
└── ...
```
该脚本并不关心您的文件夹是如何组织的。它只是遍历目录树。
## 自定义
在 `spectrex.py` 顶部附近的一些调节选项:
- `DECIMATE_FDS`:设置为 `False` 可保留 FDS 文件完整的 0.2 nm 内部分辨率,而不是抽样至 1 nm。
- 绘图颜色:单光谱颜色为 `#e91e63`(粉色)。叠加图使用 matplotlib 的默认颜色循环,以便区分每个光谱。
## 贡献
如果您拥有本工具无法处理的、来自相关日立仪器的 UDS/FDS 文件,获取支持的最快方法是将样本文件以及匹配的 TXT 导出文件(来自原版程序)提交至 issue。该 TXT 提供了验证任何新格式变体所需的基准事实。
## 背后的故事
这始于工作流程上的一个挫折。我们实验室的日立仪器将数据以其自己的二进制格式保存,并带有一个可选的复选框,可以在保存时同时导出纯 TXT 文件。如果该复选框被遗漏(这在实际操作中经常发生),数据实际上就被锁定在了仪器 PC 上。只有最初的 1995 年时代的软件才能打开它。
很长一段时间里,解决方法是亲自回到仪器前,在原版程序中将文件排队,并逐一导出它们。处理一个文件还可以。但当面对大量积压的测量数据时就非常痛苦了,特别是当仪器 PC 正忙、在另一栋楼里,或者运行着没人想碰的旧版 Windows 系统时。
最初的假设是,破解该格式需要反编译最初的 `.exe`。事实证明这是没有必要的。二进制格式使用了简单的小端序双精度浮点数和可读的 ASCII 字符串头部,而原版程序自身的 TXT 导出文件提供了验证所用的基准事实。只需一个下午的十六进制转储分析和 `struct.unpack_from` 调用,就足以确定这两种文件格式。
技术顺序:
1. **对文件进行十六进制转储。** 两种格式均以 ASCII “魔术字”开头:UDS 为 `IIHIITAG`,FDS 为 `IIHIDTAG`,其后是可读字符串(样本名称、时间戳、仪器型号)。这暴露了其高级布局。
2. **在头部发现可能的双精度浮点数。** 扫描字符串之后的字节时,几个 8 字节的块被解码为整数(340.0, 1.0, 600.0)。这些必然是扫描参数。
3. **获取 TXT 基准事实。** 通过原版软件导出一个文件,可以提供一个明确的“此波长 → 此值”的映射,以便进行核对验证。
4. **第一次错误的猜测(UDS)。** 最初假定这三个双精度数是 `[start, step, end]`。CSV 看起来合情合理。但随后绘出的图表反了,在吸光度本该达到峰值的地方波长却增加了,反之亦然。
5. **意识到 UDS 存储的是透光率。** 第一个位置的二进制值 0.7278 与 TXT 的 0.138 不匹配。尝试 `-log₁₀(0.7278) = 0.138` 得到了匹配。这也揭示了这几个双精度实际上是 `[lamp_change_wl, step, start_wl]`。
6. **发现 FDS 的过采样。** 第一个 FDS 值与 TXT 几乎匹配:`data[0] = 154.16` 对应 `TXT[0] = 154.2`,随后 `data[1] = 154.31` 对应 `TXT[1] = 160.2`。每隔 N 个值检查一次发现,在步长为 5 时完全匹配:每 1 nm 的 TXT 行对应 5 个内部采样点。紧挨着数据前方的 `0.2` 双精度数确认了存储步长。
7. **找到了稳定的数据结束标记**,通过检查预期数据范围之后的内容。UDS 使用 `600.0` 哨兵值。FDS 在数据块之后 32 字节处使用文字字符串 `"Reagent 1"`。
8. **端到端验证**,针对测试集中每个文件的原版程序 TXT 导出进行了核对。最大绝对差值:吸光度为 0.000(TXT 的显示精度),荧光强度约为 0.5(同样是显示精度)。
### 后续:尝试恢复 FDS 采集参数
头部提取在 UDS 上运行良好。在程序的 TXT 导出中可见的每个参数(狭缝宽度、扫描速度、光程、灯切换波长、基线校正、响应设置)都作为普通的小端序双精度数存储在固定偏移量处,因此 spectrex 在 CSV 头部中输出了所有这些参数。
FDS 拒绝了同样的处理方式。几个采集参数(扫描速度、EX/EM 狭缝宽度、PMT 电压、响应时间、延迟)并没有以其显示的值出现在 FDS 二进制文件中。为了进行调查,尝试了以下角度:
1. **对约 300 个具有混合参数的 FDS 档案文件进行差分分析。** 将文件配对,使得除了一个旋钮之外的所有内容都匹配(例如,扫描速度 1200 nm/min 与 240 nm/min,狭缝 5.0 nm 与 2.5 nm)。二进制文件对的字节级差异发现只有注释字段和嵌入的文件名发生了变化。没有任何字节位置能作为普通双精度浮点数追踪到参数的改变。
2. **检查 FL Solutions 安装目录。** 该程序附带了 `.FLM` 方法模板(与 FDS 具有相同的 `IIHIDTAG` 魔术字,参数块更密集)和 `flsol.MDB`(一个 Microsoft Access 数据库)。FLM 模板暴露了一个紧密排列的参数区域,但其中的双精度数是 `211, 163, 13, 19, 103, 220, 9000` 这样的值,而不是 TXT 导出中所见的人类可读参数值。这些看起来像是内部采集计数器或设置索引。
3. **读取 MDB。** Access 驱动程序以“由早期版本创建”(Jet 3.x / Access 97 时代)为由拒绝了该文件。对 MDB 进行的文本字符串扫描总共发现了 99 个字符串,其中没有一个是参数表名。MDB 并不以纯文本形式存储参数查找表。
结论是 FDS 将这些参数存储为**内部设置代码**,而代码到人类可读值的映射存在于程序的 DLL(`flmethod.dll`、`flprop.dll`)中作为编译好的表。提取它们将需要使用 Ghidra 等工具反汇编这些 DLL。这是一项独立的工作,超出了 spectrex 的范围。
**此限制不影响光谱数据本身。** UDS 和 FDS 文件的波长轴和强度值均已精确解码,并针对原版程序的 TXT 导出进行了逐字节的验证。缺失的 FDS 字段是关于如何进行扫描采集的元数据,而不是扫描数据。Spectrex 在 FDS CSV 头部中输出了一条备注,列出了尚未提取的字段,以便任何阅读输出的人都知道哪些可用,哪些不可用。
如果您确实需要某个特定文件的那些 FDS 采集参数,最简单的解决方法是回到 FL Solutions 中,勾选“另存为 TXT”复选框重新导出。该 TXT 将列出二进制文件包含的所有参数。
## 致谢
想法、需求、实验室知识和方向均来自于我。逆向工程和 Python 代码是与 [Claude](https://claude.ai) 作为 AI 编程助手在单次会话中协作完成的。每一步的验证都依赖于我通过原版仪器软件生成的 TXT 导出文件。
## 许可证
MIT。随意使用、分支、分享。
标签:CSV, legacy系统, Python, UV-Vis, 二进制文件, 云资产清单, 光谱学, 分光光度计, 化学分析, 实验室自动化, 数据提取, 数据转换, 文件格式解析, 文件解析, 无后门, 日立, 科学数据, 荧光光谱, 逆向工具, 逆向工程