irembezci/ai-medical-assistant-threat-model
GitHub: irembezci/ai-medical-assistant-threat-model
针对 AI 医疗助手系统的完整威胁建模案例研究,系统性地将 STRIDE、OWASP LLM Top 10 和 MITRE ATLAS 框架应用于 LLM 应用安全风险评估。
Stars: 1 | Forks: 0
# AI 医疗助手威胁建模案例研究
## 简介
人工智能正在迅速改变医疗保健行业。由大型语言模型 (LLM) 驱动的应用程序能够在几秒钟内分析患者症状、检索可信的医学参考并生成初步的医疗指导。
这些能力带来了显著的优势,但同时也引入了严重的安全和保障风险。
如果 AI 医疗应用未得到妥善保护,攻击者可能能够窃取敏感的患者病历、操纵模型行为、污染可信的医学知识库或生成有害的医疗建议。
由于医疗系统处理高度敏感的个人健康信息 (PHI),安全故障可能会同时影响患者隐私和患者安全。
本项目展示了安全团队如何在 AI 驱动的医疗应用开发和部署之前对其进行评估。
在此场景中,一家医疗机构正计划推出一款 AI 医疗助手,该助手将允许患者:
1. 提交症状和医疗问题
2. 使用检索增强生成 (RAG) 检索可信的医学参考
3. 接收 AI 生成的医疗指导
4. 与授权医生共享摘要
在开发开始之前,安全团队的任务是评估拟定的架构,识别最重大的风险,并推荐安全部署系统所需的控制措施。
本次评估的目的是回答一个关键问题:
## 方法论
本项目采用了专业威胁建模评估中常用的结构化方法论。
评估首先从系统架构、数据流、信任边界和操作工作流进行建模。
接下来,分析识别了必须保护的关键资产、最有可能针对该系统的威胁行为者,以及定义安全基线的假设条件。
随后开发了现实的滥用案例,以说明该应用程序可能如何被故意滥用。
应用 STRIDE 方法论系统地识别影响每个组件的威胁。
这些发现被映射到 OWASP Top 10 LLM 应用和 MITRE ATLAS,以使分析与公认的 AI 安全框架保持一致。
最后,根据可能性和影响评估每个威胁,并提出实际的缓解策略。
## 项目交付物
本仓库包含完整的威胁建模和风险评估包。
### 架构和设计工件
- [系统架构图](docs/architecture/system-architecture.md)
- [数据流图 (DFD)](docs/architecture/data-flow-diagram.md)
- [信任边界图](docs/architecture/trust-boundary-diagram.md)
- [时序图](docs/architecture/sequence-diagram.md)
### 威胁建模文档
- [资产清单](docs/asset-inventory.md)
- [威胁行为者](docs/threat-actors.md)
- [安全假设](docs/security-assumptions.md)
- [滥用案例](docs/abuse-cases.md)
- [STRIDE 威胁模型](docs/stride-threat-model.md)
### 安全框架映射
- [OWASP Top 10 LLM 应用映射](docs/owasp-llm-mapping.md)
- [MITRE ATLAS 映射](docs/mitre-atlas-mapping.md)
### 风险分析和建议
- [风险评估](docs/risk-assessment.md)
- [安全控制和缓解措施](docs/mitigations.md)
- [执行摘要](docs/executive-summary.md)
- [参考文献](docs/references.md)
## 分析叙述
本项目是作为一次现实的部署前安全评估来进行的。
一家医疗机构计划开发一款由 AI 驱动的医疗助手,允许患者提交症状、接收 AI 生成的医疗指导,并可选择与授权医生共享摘要。
在开发开始之前,安全团队被要求回答以下问题:
第一步是了解拟议的应用程序在实践中将如何运作。
患者通过 Web 界面提交症状。应用程序对用户进行身份验证,从知识库中检索可信的医学参考资料,将相关上下文发送给大型语言模型 (LLM),验证生成的响应,并将结果存储在患者数据库中。患者还可以选择与授权医生共享摘要。
为了记录这一设计并确保所有利益相关者对系统有共同的理解,创建了四张架构图。
[系统架构图](docs/architecture/system-architecture.md) 识别了解决方案中涉及的所有主要组件,包括患者 Web 界面、身份验证服务、API 网关、LLM 编排器、检索引擎、医学知识库、外部 LLM 提供商、输出 Guardrails、患者数据库以及日志记录和监控。
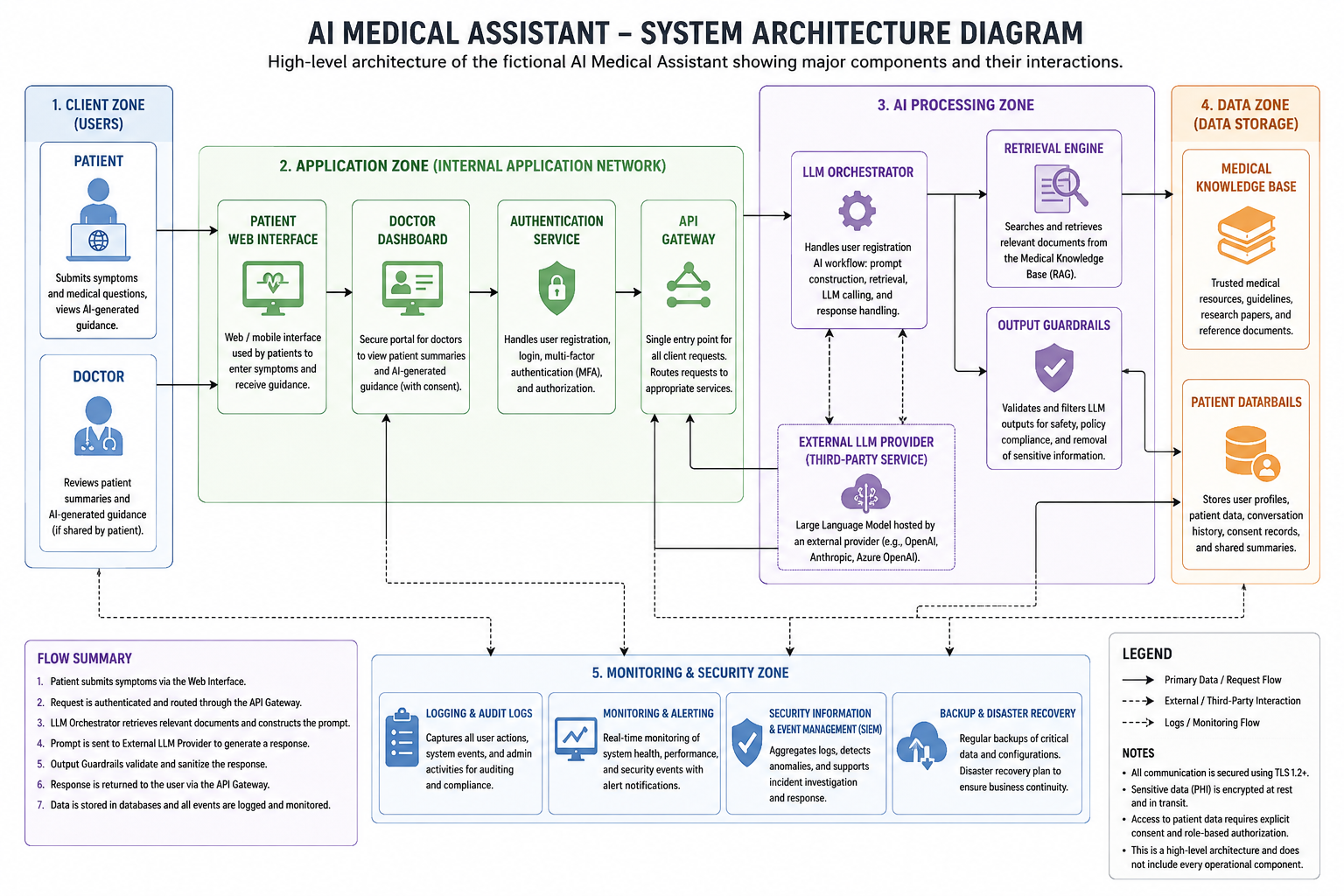
[数据流图 (DFD)](docs/architecture/data-flow-diagram.md) 追踪了敏感信息(如个人健康信息 (PHI)、提示词、检索到的文档和模型输出)如何在系统组件之间移动。
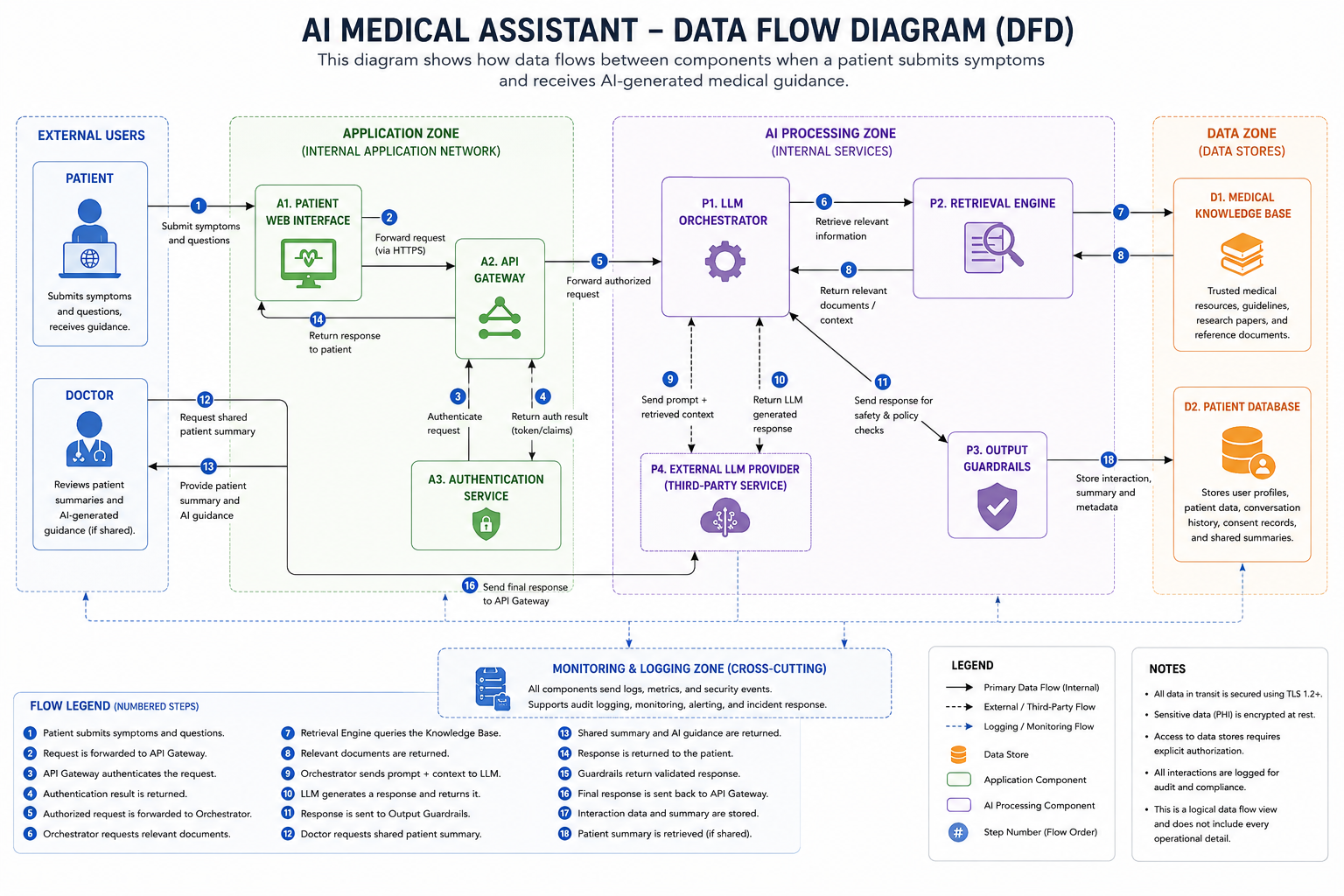
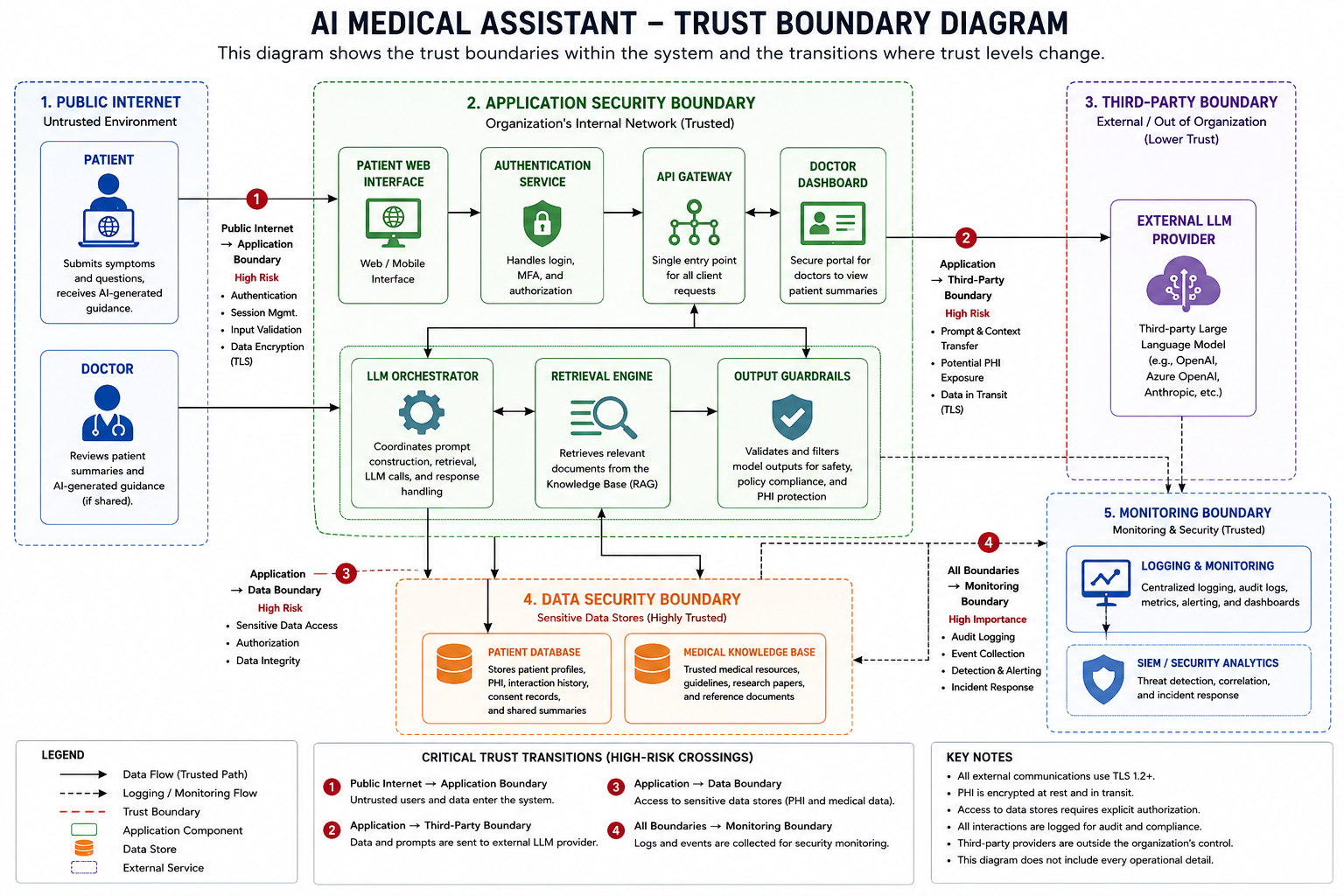
[信任边界图](docs/architecture/trust-boundary-diagram.md) 突出显示了系统内信任发生改变的位置,例如数据从外部用户输入时,或者敏感提示词被传输给第三方 LLM 提供商时。
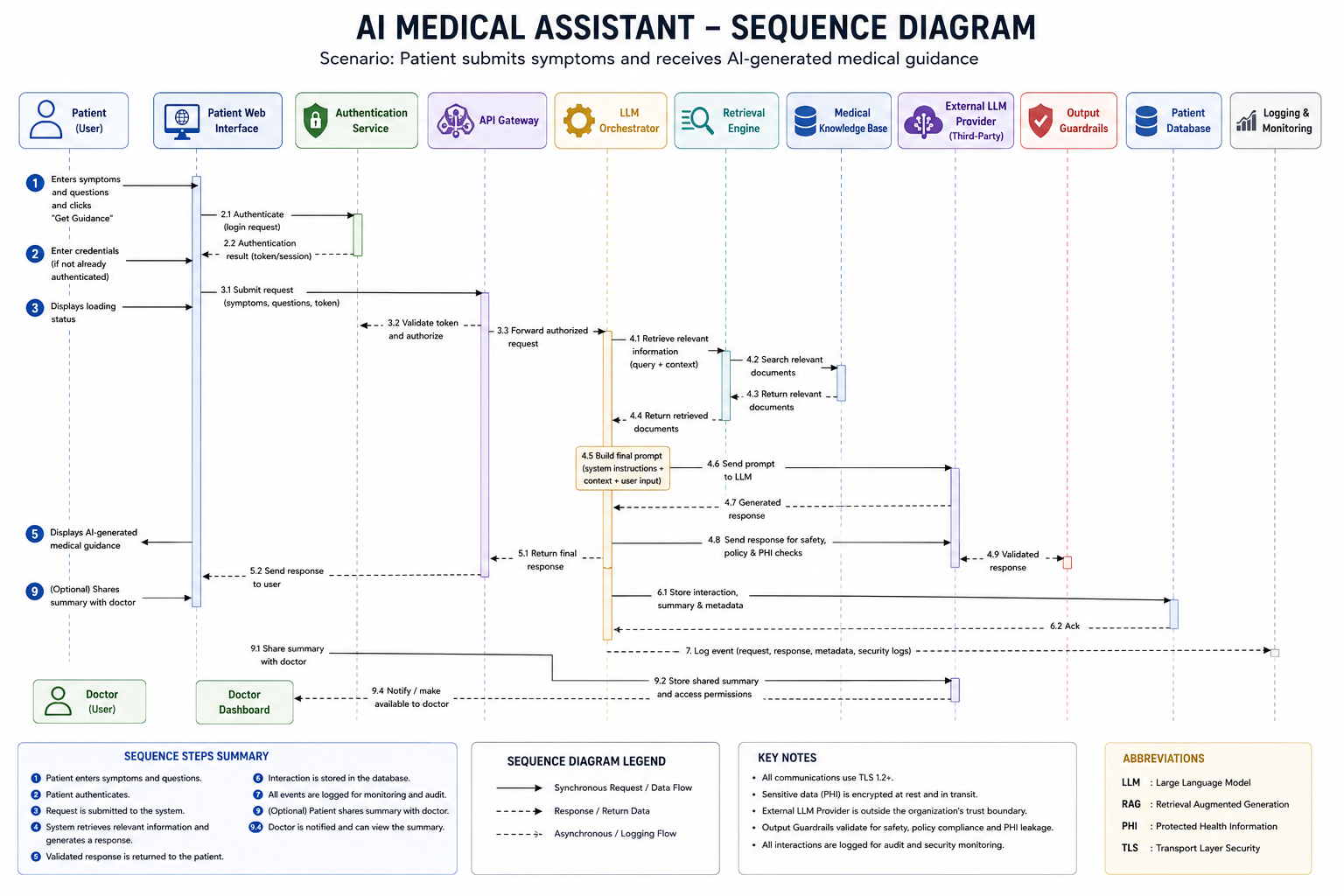
[时序图](docs/architecture/sequence-diagram.md) 展示了当患者提交症状并接收 AI 生成的医疗指导时发生的确切操作顺序。
一旦系统设计被明确定义,就会创建[资产清单](docs/asset-inventory.md),以确定组织必须保护什么。
### 关键资产
| 资产 | 安全重要性 |
|------|------|
| 个人健康信息 (PHI) | 包含高度敏感的医疗数据。 |
| 提示词 | 可能包括患者症状和机密的系统指令。 |
| 医学知识库 | 必须保持可信,以防止有害的建议。 |
| API 密钥 | 提供对外部 LLM 服务的访问权限。 |
| 审计日志 | 支持问责制和事件调查。 |
此分析表明,最有价值的资产包括患者记录、提示词、模型输出、身份验证凭据、API 密钥和审计日志。
下一步是识别谁可能试图破坏这些资产。[威胁行为者](docs/threat-actors.md)部分对现实的对手进行了剖析并解释了他们的动机。
### 威胁行为者
| 威胁行为者 | 主要目标 |
|------|------|
| 恶意患者 | 操纵模型并绕过安全防护。 |
| 外部攻击者 | 窃取 PHI 并破坏运营。 |
| 内部威胁 | 滥用对患者的记录的合法访问权限。 |
| 供应链对手 | 破坏依赖项和第三方组件。 |
| 针对医疗保健的 APT 组织 | 进行间谍活动和勒索软件攻击。 |
此分析表明,该系统可能会成为机会主义攻击者和复杂的针对医疗保健的威胁组织的攻击目标。
在评估威胁之前,[安全假设](docs/security-assumptions.md)部分记录了假定已到位的控制措施。
### 安全假设
- 传输中的数据使用 TLS 保护。
- 敏感数据在静态存储时已加密。
- 实施了基于角色的访问控制 (RBAC)。
- API 密钥被安全存储。
- 启用了审计日志记录和监控。
- 输出 Guardrails 会验证模型响应。
这些假设定义了整个评估过程中使用的基线环境。
[滥用案例](docs/abuse-cases.md)部分随后探讨了应用程序可能如何被故意滥用。
### 高影响滥用案例
| 滥用案例 | 潜在影响 |
|------|------|
| 提示注入 | 操纵模型行为并泄露受限信息。 |
| 知识库投毒 | 在响应中引入虚假的医学信息。 |
| 敏感数据泄露 | 暴露 PHI 和机密提示词。 |
| 凭据盗窃 | 导致未经授权的访问。 |
| 不安全输出生成 | 产生有害的医疗建议。 |
这些场景将攻击者的目标转化为现实的攻击路径。
为了系统地识别影响每个组件的威胁,应用了 [STRIDE 威胁模型](docs/stride-threat-model.md)。
### STRIDE 类别
| 类别 | 描述 |
|------|------|
| 欺骗 | 冒充用户或服务。 |
| 篡改 | 修改数据、提示词或配置。 |
| 否认 | 由于日志记录不足而否认操作。 |
| 信息泄露 | 暴露敏感信息。 |
| 拒绝服务 | 破坏系统可用性。 |
| 权限提升 | 获取未经授权的权限。 |
这种结构化分析确保了没有忽略任何主要的威胁类别。
然后,将识别出的威胁映射到 [OWASP Top 10 LLM 应用](docs/owasp-llm-mapping.md),以使发现与当前的行业指南保持一致。
### 最相关的 OWASP 类别
| 类别 | 相关性 |
|------|------|
| LLM01:提示注入 | 最高优先级的 AI 特定威胁。 |
| LLM02:不安全的输出处理 | 有害的响应可能会传达给患者。 |
| LLM03:训练数据投毒 | 被破坏的医学参考可能会影响输出。 |
| LLM06:敏感信息泄露 | PHI 和机密信息可能会被暴露。 |
| LLM09:过度依赖 | 用户可能会信任不准确的指导。 |
此映射确认拟议的应用程序几乎暴露于所有主要的 LLM 安全风险中。
相同的威胁也被映射到了 [MITRE ATLAS](docs/mitre-atlas-mapping.md),这将发现与针对 AI 系统的真实世界的对抗战术和技术联系起来。
### 相关的 MITRE ATLAS 技术
| 威胁场景 | 技术 |
|------|------|
| 提示注入 | 提示注入 |
| 知识库投毒 | 数据投毒 |
| 敏感数据窃取 | 通过 ML 推理 API 窃取 |
| 凭据盗窃 | 凭据访问 |
这一步骤将评估与现实的攻击者行为联系了起来。
[风险评估](docs/risk-assessment.md)部分使用可能性和影响评估了每个威胁,以确定哪些问题应被优先处理。
### 最高优先级风险
| 威胁 | 可能性 | 影响 | 总体风险 |
|------|------|------|------|
| 提示注入 | 严重 | 严重 | 严重 |
| 敏感数据泄露 | 高 | 严重 | 严重 |
| 医学知识库投毒 | 高 | 严重 | 严重 |
| 不安全输出生成 | 高 | 严重 | 严重 |
评估得出结论,最严重的风险集中在模型操纵、隐私暴露和患者安全方面。
[安全控制和缓解措施](docs/mitigations.md)部分将这些发现转化为可操作的建议。
### 建议的控制措施
| 威胁 | 建议的控制措施 |
|------|------|
| 提示注入 | 提示隔离和输出过滤 |
| 敏感数据泄露 | 数据最小化和加密 |
| 凭据盗窃 | 多因素认证 (MFA) |
| 不安全输出生成 | 人工审查和医疗免责声明 |
这些控制措施代表了系统获批投入生产使用之前推荐的最低限度保障。
[执行摘要](docs/executive-summary.md) 为管理层和决策者整合了最重要的发现。它突出了最高优先级的风险,解释了其业务影响,并总结了部署前需要采取的行动。
最后,[参考文献](docs/references.md)部分记录了整个评估过程中使用的标准和框架,包括 Microsoft STRIDE、OWASP Top 10 LLM 应用、MITRE ATLAS 和 NIST AI 风险管理框架。
本项目展示了安全团队如何在开发开始之前评估拟议的 AI 医疗应用,识别其最重大的风险,并为安全部署系统提供清晰的路线图。
标签:AI安全, Chat Copilot, CISA项目, DLL 劫持, DNS重绑定攻击, LLM聊天机器人, OWASP LLM Top 10, PHI, RAG, 人工智能, 医疗AI, 医疗保健, 向量数据库, 大语言模型, 威胁建模, 安全控制, 患者健康信息, 提示注入, 数据隐私, 权限滥用, 架构安全, 案例研究, 检索增强生成, 模型投毒, 漏洞映射, 用户模式Hook绕过, 网络安全, 网络安全评估, 过度授权, 配置审计, 防御加固, 防御避让, 隐私保护, 集群管理