paras-the-coder/FraudGuard-Ai
GitHub: paras-the-coder/FraudGuard-Ai
FraudGuard AI 是一个结合机器学习与业务规则的汽车保险理赔欺诈检测系统,通过风险评分和可解释性分析帮助调查人员高效识别可疑理赔。
Stars: 1 | Forks: 0
# FraudGuard AI — 保险理赔欺诈检测系统
[](https://python.org)
[](https://streamlit.io)
[](https://scikit-learn.org)
[](LICENSE)
🔗 **[在线演示 → fraudguard-ai.streamlit.app](https://fraudguard-ai-ljpybjziicpkymlpuzbsus.streamlit.app/)**
FraudGuard AI 是一个由 Machine Learning 驱动的保险理赔欺诈检测系统,旨在识别可疑的汽车保险理赔并支持欺诈调查工作流。
该项目结合了:
* Machine Learning
* 业务规则智能
* 交互式分析仪表板
* 风险评分和报告
# 应用预览
 # 问题描述
每年,保险欺诈都会给保险公司造成巨大的经济损失。欺诈性理赔可能包括:
* 虚假事故
* 夸大的伤害索赔
* 虚高的维修费用
* 人为策划的碰撞
* 虚假的盗窃报告
手动审查每一项理赔既昂贵又耗时。
FraudGuard AI 有助于尽早识别高风险理赔,确定调查优先级,并提高欺诈筛查效率。
# 保险领域
本项目重点关注:
```
Automobile Insurance Claim Fraud Detection
```
数据集包含汽车事故和保险理赔记录,其中包括:
* 客户信息
* 保单详情
* 事故详情
* 理赔财务信息
* 车辆信息
* 欺诈标签
目标变量:
```
Fraudulent Claim vs Legitimate Claim
```
# 使用的特征
### 理赔财务特征
* total_claim_amount
* injury_claim
* vehicle_claim
* property_claim
* policy_annual_premium
* policy_deductable
### 事故特征
* incident_type
* collision_type
* incident_severity
* incident_hour_of_the_day
* number_of_vehicles_involved
* bodily_injuries
* witnesses
* police_report_available
* property_damage
### 客户与保单特征
* age
* months_as_customer
* insured_occupation
* insured_education_level
* insured_relationship
* policy_state
### 车辆与位置特征
* auto_make
* auto_model
* auto_year
* incident_state
* incident_city
# 特征工程
为了提高欺诈检测性能,创建了额外的工程特征:
* claim_ratio
* incident_year
* vehicle_age
* days_between_policy_incident
* csl_per_person
* csl_per_accident
这些工程特征有助于捕捉可疑的理赔行为和与欺诈相关的模式。
# 模型性能
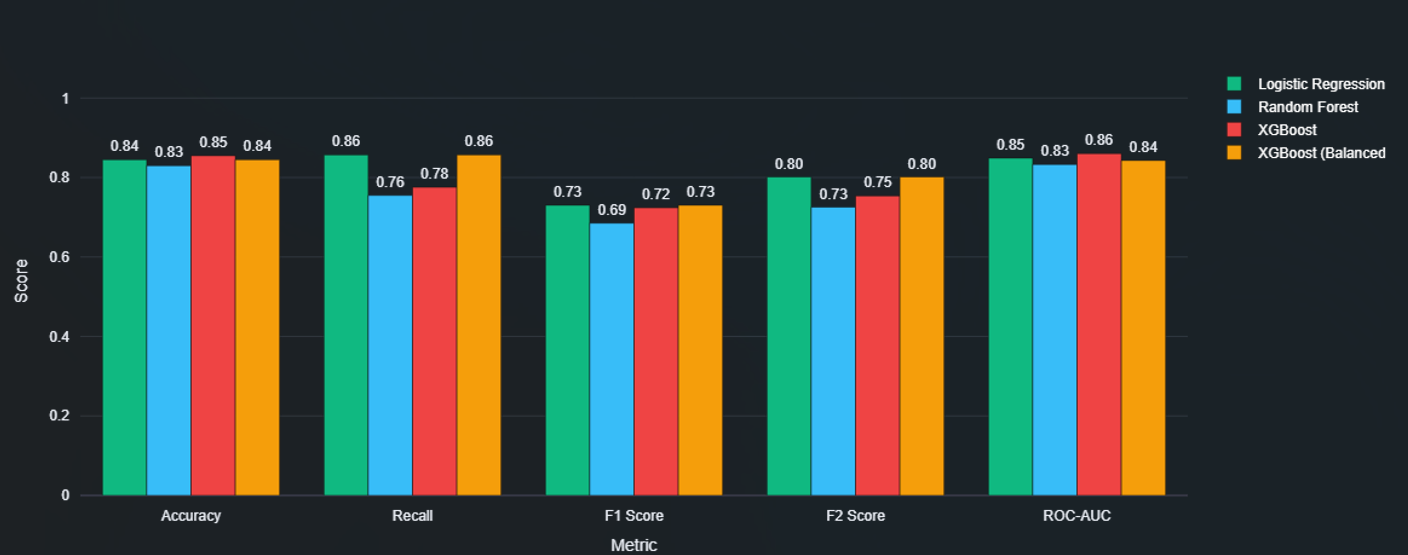
本项目最终选择的模型是 **Logistic Regression**。
尽管测试了多种模型,包括 **Random Forest** 和 **XGBoost**,但 Logistic Regression 被选为最佳的生产就绪模型,因为它在欺诈检测方面实现了最佳的平衡,尤其是在 **recall** 上。
| 模型 | Accuracy | Recall | F1 Score | F2 Score | ROC-AUC |
| --- | --- | --- | --- | --- | --- |
| **Logistic Regression** ✓ | 0.845 | **0.857** | **0.730** | **0.802** | 0.849 |
| Random Forest | 0.830 | 0.755 | 0.685 | 0.726 | 0.833 |
| XGBoost (SMOTE, tuned) | 0.855 | 0.776 | 0.724 | 0.754 | 0.860 |
| XGBoost (scale_pos_weight, tuned) | 0.845 | **0.857** | **0.730** | **0.802** | 0.841 |
## 为什么选择 Logistic Regression
在保险欺诈检测中,**漏掉欺诈性理赔比将合法理赔送去审查的成本更高**。正因为如此,选择模型主要基于 **Recall** 和 **F2 Score**,而不仅仅是 accuracy。
虽然最初不平衡的 XGBoost 漏掉了更多的欺诈案例,但通过类别权重平衡(`scale_pos_weight`)和超参数调优重新训练 XGBoost 后,它能够匹配 Logistic Regression 最高的 recall(86%)和 F2 score(0.802)。
然而,**Logistic Regression 仍然被选为最终的生产模型**,因为它在与调优后的 XGBoost 提供相同的 recall 和 F2 score 的同时,还具有以下优势:
- **高度可解释:** 更容易向理赔理算员、调查人员和监管机构解释预测逻辑和特征贡献。
- **更简单、更快速:** 与复杂的树集成相比,在生产环境中的训练、运行和维护速度更快,且零部署开销。
最终模型并非旨在自动拒绝理赔。相反,它作为一个**欺诈风险筛查工具**,帮助确定手动或 SIU 审查的理赔优先级。
### 模型性能可视化
# 问题描述
每年,保险欺诈都会给保险公司造成巨大的经济损失。欺诈性理赔可能包括:
* 虚假事故
* 夸大的伤害索赔
* 虚高的维修费用
* 人为策划的碰撞
* 虚假的盗窃报告
手动审查每一项理赔既昂贵又耗时。
FraudGuard AI 有助于尽早识别高风险理赔,确定调查优先级,并提高欺诈筛查效率。
# 保险领域
本项目重点关注:
```
Automobile Insurance Claim Fraud Detection
```
数据集包含汽车事故和保险理赔记录,其中包括:
* 客户信息
* 保单详情
* 事故详情
* 理赔财务信息
* 车辆信息
* 欺诈标签
目标变量:
```
Fraudulent Claim vs Legitimate Claim
```
# 使用的特征
### 理赔财务特征
* total_claim_amount
* injury_claim
* vehicle_claim
* property_claim
* policy_annual_premium
* policy_deductable
### 事故特征
* incident_type
* collision_type
* incident_severity
* incident_hour_of_the_day
* number_of_vehicles_involved
* bodily_injuries
* witnesses
* police_report_available
* property_damage
### 客户与保单特征
* age
* months_as_customer
* insured_occupation
* insured_education_level
* insured_relationship
* policy_state
### 车辆与位置特征
* auto_make
* auto_model
* auto_year
* incident_state
* incident_city
# 特征工程
为了提高欺诈检测性能,创建了额外的工程特征:
* claim_ratio
* incident_year
* vehicle_age
* days_between_policy_incident
* csl_per_person
* csl_per_accident
这些工程特征有助于捕捉可疑的理赔行为和与欺诈相关的模式。
# 模型性能
本项目最终选择的模型是 **Logistic Regression**。
尽管测试了多种模型,包括 **Random Forest** 和 **XGBoost**,但 Logistic Regression 被选为最佳的生产就绪模型,因为它在欺诈检测方面实现了最佳的平衡,尤其是在 **recall** 上。
| 模型 | Accuracy | Recall | F1 Score | F2 Score | ROC-AUC |
| --- | --- | --- | --- | --- | --- |
| **Logistic Regression** ✓ | 0.845 | **0.857** | **0.730** | **0.802** | 0.849 |
| Random Forest | 0.830 | 0.755 | 0.685 | 0.726 | 0.833 |
| XGBoost (SMOTE, tuned) | 0.855 | 0.776 | 0.724 | 0.754 | 0.860 |
| XGBoost (scale_pos_weight, tuned) | 0.845 | **0.857** | **0.730** | **0.802** | 0.841 |
## 为什么选择 Logistic Regression
在保险欺诈检测中,**漏掉欺诈性理赔比将合法理赔送去审查的成本更高**。正因为如此,选择模型主要基于 **Recall** 和 **F2 Score**,而不仅仅是 accuracy。
虽然最初不平衡的 XGBoost 漏掉了更多的欺诈案例,但通过类别权重平衡(`scale_pos_weight`)和超参数调优重新训练 XGBoost 后,它能够匹配 Logistic Regression 最高的 recall(86%)和 F2 score(0.802)。
然而,**Logistic Regression 仍然被选为最终的生产模型**,因为它在与调优后的 XGBoost 提供相同的 recall 和 F2 score 的同时,还具有以下优势:
- **高度可解释:** 更容易向理赔理算员、调查人员和监管机构解释预测逻辑和特征贡献。
- **更简单、更快速:** 与复杂的树集成相比,在生产环境中的训练、运行和维护速度更快,且零部署开销。
最终模型并非旨在自动拒绝理赔。相反,它作为一个**欺诈风险筛查工具**,帮助确定手动或 SIU 审查的理赔优先级。
### 模型性能可视化
 ## 可解释性与风险解读
FraudGuard AI 通过 `shap.LinearExplainer` 使用 **SHAP (SHapley Additive exPlanations)**
来生成每次预测的实例级解释。
每项预测都会显示对于该特定理赔,哪些特征推高或降低了欺诈概率
—— 这不是全局的模型权重,而是针对特定理赔的推理过程。
SHAP 分析表明,`incident_severity_major_damage` 是最强的
全局欺诈信号。出现在 SHAP top values 中的某些被保险人爱好等特征,已被确认可能是
由于小数据集(约 1000 行)导致的伪相关,
而不是真正的因果欺诈指标。
这些解释支持欺诈风险解读工作流,但不应将其视为
欺诈的法律或因果证明。
# 混合欺诈检测逻辑
FraudGuard AI 结合了:
1. Machine Learning 概率评分
2. 额外的业务规则欺诈分析(模型后业务规则调整)
业务规则信号示例:
* 异常高的伤害索赔
* 缺失的警方报告
* 不一致的理赔明细
* 可疑的时间模式
* 虚高的理赔与保费比率
这提高了欺诈筛查的真实性和操作可解释性。
# 应用功能
* 多页 Streamlit 仪表板
* 欺诈概率评分
* 风险分类
* 可解释 AI 输出
* 可视化风险驱动因素
* 可下载的 HTML 调查报告
### 预测演示
## 可解释性与风险解读
FraudGuard AI 通过 `shap.LinearExplainer` 使用 **SHAP (SHapley Additive exPlanations)**
来生成每次预测的实例级解释。
每项预测都会显示对于该特定理赔,哪些特征推高或降低了欺诈概率
—— 这不是全局的模型权重,而是针对特定理赔的推理过程。
SHAP 分析表明,`incident_severity_major_damage` 是最强的
全局欺诈信号。出现在 SHAP top values 中的某些被保险人爱好等特征,已被确认可能是
由于小数据集(约 1000 行)导致的伪相关,
而不是真正的因果欺诈指标。
这些解释支持欺诈风险解读工作流,但不应将其视为
欺诈的法律或因果证明。
# 混合欺诈检测逻辑
FraudGuard AI 结合了:
1. Machine Learning 概率评分
2. 额外的业务规则欺诈分析(模型后业务规则调整)
业务规则信号示例:
* 异常高的伤害索赔
* 缺失的警方报告
* 不一致的理赔明细
* 可疑的时间模式
* 虚高的理赔与保费比率
这提高了欺诈筛查的真实性和操作可解释性。
# 应用功能
* 多页 Streamlit 仪表板
* 欺诈概率评分
* 风险分类
* 可解释 AI 输出
* 可视化风险驱动因素
* 可下载的 HTML 调查报告
### 预测演示
 # 技术栈
- **编程与数据处理**: Python,Pandas,NumPy
- **机器学习**: Scikit-learn, Imbalanced-learn / SMOTE, Logistic Regression, Random Forest, XGBoost, 用于模型序列化的 Joblib
- **数据可视化**: Plotly, Matplotlib, Seaborn
- **Web 应用程序**: Streamlit, 自定义 CSS
- **模型可解释性与报告**: SHAP (LinearExplainer), 单次预测的 waterfall 贡献图, 业务规则欺诈信号, HTML 和 PDF 调查报告生成
### 部署
* Streamlit Community Cloud
# 📁 项目结构
```
FraudGuard-AI/
│
├── app.py
├── app_pages/
├── src/
├── models/
├── data/
├── assets/
├── notebooks/
├── tests/ (pytest suite for data pipeline and model validation)
├── requirements.txt
└── README.md
```
# 系统流程
```
Raw Insurance Claim
│
▼
Feature Engineering
(claim_ratio, vehicle_age, days_between_policy_incident, csl splits)
│
▼
Logistic Regression Pipeline
(StandardScaler + OneHotEncoder + SMOTE + LR)
│
▼
Base Fraud Probability Score
│
▼
Business Rule Adjustment
(injury-to-damage ratio, missing police report, short tenure, claim dominance)
│
▼
Final Risk Score + Signals
│
├── Low (<35%) → Auto-approve
├── Medium (35–65%) → Manual review
└── High (>65%) → Escalate to SIU
```
# 局限性
FraudGuard AI 是一款欺诈筛查支持工具,而不是最终的欺诈决策系统。
- 预测是基于概率的,因此模型有时可能会错误地预测欺诈或漏掉一些欺诈案例。
- 数据集的大小和范围有限。现实世界中的保险欺诈系统需要更大、更多样化的数据集。
- 仍需人工调查以做出最终的欺诈决定。
- 部署的模型优先考虑可解释性和 recall,而不是最大化的预测性能。
- 应用程序中添加的某些业务规则检查是手动设计的,可能无法完全代表真实的保险公司工作流。
- 模型性能基于历史标记数据,在应对全新的或不断演变的欺诈模式时可能表现不佳。
- 某些输入字段为了演示目的进行了简化或内部生成。
- 模型可能会产生假阳性和假阴性。
- 特征贡献解释仅显示哪些因素影响了预测。它们不应被视为欺诈的法律证明。
- 该应用程序不包括生产监控、漂移检测或与实时理赔系统的集成。
应将 FraudGuard AI 视为欺诈风险评估和调查支持工具,而不是全自动的欺诈检测系统。
# 未来改进
- 用于实时理赔评分 API 的 FastAPI 后端
- 集成学习模型(堆叠 LR + XGBoost)
- 与理赔管理系统的实时 API 集成
- 用户身份验证和基于角色的访问控制
* 理赔历史追踪和趋势分析
- 生产级监控和模型漂移检测
- 更大、更多样化的训练数据集,以减少伪相关
# 我学到了什么
* 构建了一个端到端的 ML pipeline,在 imbalanced-learn `Pipeline` 中使用 SMOTE,以防止在交叉验证期间发生数据泄漏
* 使用 `make_scorer(fbeta_score, beta=2)` 作为 `RandomizedSearchCV` 的评分函数,以便超参数搜索直接针对欺诈 recall 进行优化,而不是 accuracy
* 在模型概率评分的基础上设计了业务规则后处理,以捕捉仅靠统计特征无法表达的欺诈信号
* 实现了基于系数的 Logistic Regression 特征贡献解释,作为 SHAP 的轻量级、兼容生产的替代方案
* 理解了在像保险欺诈这样不平衡且高成本的分类问题中,为什么 precision-recall 权衡比 accuracy 更重要
# 总结
FraudGuard AI 展示了 Machine Learning 和业务规则智能如何协同工作以支持保险欺诈调查工作流。
该项目不仅关注预测 accuracy,还关注:
* 可解释性
* 欺诈推理
* 业务价值
* 调查支持
这使其更接近于真实的欺诈分析应用程序,而不仅仅是一个简单的 ML notebook 项目。
# 技术栈
- **编程与数据处理**: Python,Pandas,NumPy
- **机器学习**: Scikit-learn, Imbalanced-learn / SMOTE, Logistic Regression, Random Forest, XGBoost, 用于模型序列化的 Joblib
- **数据可视化**: Plotly, Matplotlib, Seaborn
- **Web 应用程序**: Streamlit, 自定义 CSS
- **模型可解释性与报告**: SHAP (LinearExplainer), 单次预测的 waterfall 贡献图, 业务规则欺诈信号, HTML 和 PDF 调查报告生成
### 部署
* Streamlit Community Cloud
# 📁 项目结构
```
FraudGuard-AI/
│
├── app.py
├── app_pages/
├── src/
├── models/
├── data/
├── assets/
├── notebooks/
├── tests/ (pytest suite for data pipeline and model validation)
├── requirements.txt
└── README.md
```
# 系统流程
```
Raw Insurance Claim
│
▼
Feature Engineering
(claim_ratio, vehicle_age, days_between_policy_incident, csl splits)
│
▼
Logistic Regression Pipeline
(StandardScaler + OneHotEncoder + SMOTE + LR)
│
▼
Base Fraud Probability Score
│
▼
Business Rule Adjustment
(injury-to-damage ratio, missing police report, short tenure, claim dominance)
│
▼
Final Risk Score + Signals
│
├── Low (<35%) → Auto-approve
├── Medium (35–65%) → Manual review
└── High (>65%) → Escalate to SIU
```
# 局限性
FraudGuard AI 是一款欺诈筛查支持工具,而不是最终的欺诈决策系统。
- 预测是基于概率的,因此模型有时可能会错误地预测欺诈或漏掉一些欺诈案例。
- 数据集的大小和范围有限。现实世界中的保险欺诈系统需要更大、更多样化的数据集。
- 仍需人工调查以做出最终的欺诈决定。
- 部署的模型优先考虑可解释性和 recall,而不是最大化的预测性能。
- 应用程序中添加的某些业务规则检查是手动设计的,可能无法完全代表真实的保险公司工作流。
- 模型性能基于历史标记数据,在应对全新的或不断演变的欺诈模式时可能表现不佳。
- 某些输入字段为了演示目的进行了简化或内部生成。
- 模型可能会产生假阳性和假阴性。
- 特征贡献解释仅显示哪些因素影响了预测。它们不应被视为欺诈的法律证明。
- 该应用程序不包括生产监控、漂移检测或与实时理赔系统的集成。
应将 FraudGuard AI 视为欺诈风险评估和调查支持工具,而不是全自动的欺诈检测系统。
# 未来改进
- 用于实时理赔评分 API 的 FastAPI 后端
- 集成学习模型(堆叠 LR + XGBoost)
- 与理赔管理系统的实时 API 集成
- 用户身份验证和基于角色的访问控制
* 理赔历史追踪和趋势分析
- 生产级监控和模型漂移检测
- 更大、更多样化的训练数据集,以减少伪相关
# 我学到了什么
* 构建了一个端到端的 ML pipeline,在 imbalanced-learn `Pipeline` 中使用 SMOTE,以防止在交叉验证期间发生数据泄漏
* 使用 `make_scorer(fbeta_score, beta=2)` 作为 `RandomizedSearchCV` 的评分函数,以便超参数搜索直接针对欺诈 recall 进行优化,而不是 accuracy
* 在模型概率评分的基础上设计了业务规则后处理,以捕捉仅靠统计特征无法表达的欺诈信号
* 实现了基于系数的 Logistic Regression 特征贡献解释,作为 SHAP 的轻量级、兼容生产的替代方案
* 理解了在像保险欺诈这样不平衡且高成本的分类问题中,为什么 precision-recall 权衡比 accuracy 更重要
# 总结
FraudGuard AI 展示了 Machine Learning 和业务规则智能如何协同工作以支持保险欺诈调查工作流。
该项目不仅关注预测 accuracy,还关注:
* 可解释性
* 欺诈推理
* 业务价值
* 调查支持
这使其更接近于真实的欺诈分析应用程序,而不仅仅是一个简单的 ML notebook 项目。
# 问题描述
每年,保险欺诈都会给保险公司造成巨大的经济损失。欺诈性理赔可能包括:
* 虚假事故
* 夸大的伤害索赔
* 虚高的维修费用
* 人为策划的碰撞
* 虚假的盗窃报告
手动审查每一项理赔既昂贵又耗时。
FraudGuard AI 有助于尽早识别高风险理赔,确定调查优先级,并提高欺诈筛查效率。
# 保险领域
本项目重点关注:
```
Automobile Insurance Claim Fraud Detection
```
数据集包含汽车事故和保险理赔记录,其中包括:
* 客户信息
* 保单详情
* 事故详情
* 理赔财务信息
* 车辆信息
* 欺诈标签
目标变量:
```
Fraudulent Claim vs Legitimate Claim
```
# 使用的特征
### 理赔财务特征
* total_claim_amount
* injury_claim
* vehicle_claim
* property_claim
* policy_annual_premium
* policy_deductable
### 事故特征
* incident_type
* collision_type
* incident_severity
* incident_hour_of_the_day
* number_of_vehicles_involved
* bodily_injuries
* witnesses
* police_report_available
* property_damage
### 客户与保单特征
* age
* months_as_customer
* insured_occupation
* insured_education_level
* insured_relationship
* policy_state
### 车辆与位置特征
* auto_make
* auto_model
* auto_year
* incident_state
* incident_city
# 特征工程
为了提高欺诈检测性能,创建了额外的工程特征:
* claim_ratio
* incident_year
* vehicle_age
* days_between_policy_incident
* csl_per_person
* csl_per_accident
这些工程特征有助于捕捉可疑的理赔行为和与欺诈相关的模式。
# 模型性能
本项目最终选择的模型是 **Logistic Regression**。
尽管测试了多种模型,包括 **Random Forest** 和 **XGBoost**,但 Logistic Regression 被选为最佳的生产就绪模型,因为它在欺诈检测方面实现了最佳的平衡,尤其是在 **recall** 上。
| 模型 | Accuracy | Recall | F1 Score | F2 Score | ROC-AUC |
| --- | --- | --- | --- | --- | --- |
| **Logistic Regression** ✓ | 0.845 | **0.857** | **0.730** | **0.802** | 0.849 |
| Random Forest | 0.830 | 0.755 | 0.685 | 0.726 | 0.833 |
| XGBoost (SMOTE, tuned) | 0.855 | 0.776 | 0.724 | 0.754 | 0.860 |
| XGBoost (scale_pos_weight, tuned) | 0.845 | **0.857** | **0.730** | **0.802** | 0.841 |
## 为什么选择 Logistic Regression
在保险欺诈检测中,**漏掉欺诈性理赔比将合法理赔送去审查的成本更高**。正因为如此,选择模型主要基于 **Recall** 和 **F2 Score**,而不仅仅是 accuracy。
虽然最初不平衡的 XGBoost 漏掉了更多的欺诈案例,但通过类别权重平衡(`scale_pos_weight`)和超参数调优重新训练 XGBoost 后,它能够匹配 Logistic Regression 最高的 recall(86%)和 F2 score(0.802)。
然而,**Logistic Regression 仍然被选为最终的生产模型**,因为它在与调优后的 XGBoost 提供相同的 recall 和 F2 score 的同时,还具有以下优势:
- **高度可解释:** 更容易向理赔理算员、调查人员和监管机构解释预测逻辑和特征贡献。
- **更简单、更快速:** 与复杂的树集成相比,在生产环境中的训练、运行和维护速度更快,且零部署开销。
最终模型并非旨在自动拒绝理赔。相反,它作为一个**欺诈风险筛查工具**,帮助确定手动或 SIU 审查的理赔优先级。
### 模型性能可视化
## 可解释性与风险解读
FraudGuard AI 通过 `shap.LinearExplainer` 使用 **SHAP (SHapley Additive exPlanations)**
来生成每次预测的实例级解释。
每项预测都会显示对于该特定理赔,哪些特征推高或降低了欺诈概率
—— 这不是全局的模型权重,而是针对特定理赔的推理过程。
SHAP 分析表明,`incident_severity_major_damage` 是最强的
全局欺诈信号。出现在 SHAP top values 中的某些被保险人爱好等特征,已被确认可能是
由于小数据集(约 1000 行)导致的伪相关,
而不是真正的因果欺诈指标。
这些解释支持欺诈风险解读工作流,但不应将其视为
欺诈的法律或因果证明。
# 混合欺诈检测逻辑
FraudGuard AI 结合了:
1. Machine Learning 概率评分
2. 额外的业务规则欺诈分析(模型后业务规则调整)
业务规则信号示例:
* 异常高的伤害索赔
* 缺失的警方报告
* 不一致的理赔明细
* 可疑的时间模式
* 虚高的理赔与保费比率
这提高了欺诈筛查的真实性和操作可解释性。
# 应用功能
* 多页 Streamlit 仪表板
* 欺诈概率评分
* 风险分类
* 可解释 AI 输出
* 可视化风险驱动因素
* 可下载的 HTML 调查报告
### 预测演示
# 技术栈
- **编程与数据处理**: Python,Pandas,NumPy
- **机器学习**: Scikit-learn, Imbalanced-learn / SMOTE, Logistic Regression, Random Forest, XGBoost, 用于模型序列化的 Joblib
- **数据可视化**: Plotly, Matplotlib, Seaborn
- **Web 应用程序**: Streamlit, 自定义 CSS
- **模型可解释性与报告**: SHAP (LinearExplainer), 单次预测的 waterfall 贡献图, 业务规则欺诈信号, HTML 和 PDF 调查报告生成
### 部署
* Streamlit Community Cloud
# 📁 项目结构
```
FraudGuard-AI/
│
├── app.py
├── app_pages/
├── src/
├── models/
├── data/
├── assets/
├── notebooks/
├── tests/ (pytest suite for data pipeline and model validation)
├── requirements.txt
└── README.md
```
# 系统流程
```
Raw Insurance Claim
│
▼
Feature Engineering
(claim_ratio, vehicle_age, days_between_policy_incident, csl splits)
│
▼
Logistic Regression Pipeline
(StandardScaler + OneHotEncoder + SMOTE + LR)
│
▼
Base Fraud Probability Score
│
▼
Business Rule Adjustment
(injury-to-damage ratio, missing police report, short tenure, claim dominance)
│
▼
Final Risk Score + Signals
│
├── Low (<35%) → Auto-approve
├── Medium (35–65%) → Manual review
└── High (>65%) → Escalate to SIU
```
# 局限性
FraudGuard AI 是一款欺诈筛查支持工具,而不是最终的欺诈决策系统。
- 预测是基于概率的,因此模型有时可能会错误地预测欺诈或漏掉一些欺诈案例。
- 数据集的大小和范围有限。现实世界中的保险欺诈系统需要更大、更多样化的数据集。
- 仍需人工调查以做出最终的欺诈决定。
- 部署的模型优先考虑可解释性和 recall,而不是最大化的预测性能。
- 应用程序中添加的某些业务规则检查是手动设计的,可能无法完全代表真实的保险公司工作流。
- 模型性能基于历史标记数据,在应对全新的或不断演变的欺诈模式时可能表现不佳。
- 某些输入字段为了演示目的进行了简化或内部生成。
- 模型可能会产生假阳性和假阴性。
- 特征贡献解释仅显示哪些因素影响了预测。它们不应被视为欺诈的法律证明。
- 该应用程序不包括生产监控、漂移检测或与实时理赔系统的集成。
应将 FraudGuard AI 视为欺诈风险评估和调查支持工具,而不是全自动的欺诈检测系统。
# 未来改进
- 用于实时理赔评分 API 的 FastAPI 后端
- 集成学习模型(堆叠 LR + XGBoost)
- 与理赔管理系统的实时 API 集成
- 用户身份验证和基于角色的访问控制
* 理赔历史追踪和趋势分析
- 生产级监控和模型漂移检测
- 更大、更多样化的训练数据集,以减少伪相关
# 我学到了什么
* 构建了一个端到端的 ML pipeline,在 imbalanced-learn `Pipeline` 中使用 SMOTE,以防止在交叉验证期间发生数据泄漏
* 使用 `make_scorer(fbeta_score, beta=2)` 作为 `RandomizedSearchCV` 的评分函数,以便超参数搜索直接针对欺诈 recall 进行优化,而不是 accuracy
* 在模型概率评分的基础上设计了业务规则后处理,以捕捉仅靠统计特征无法表达的欺诈信号
* 实现了基于系数的 Logistic Regression 特征贡献解释,作为 SHAP 的轻量级、兼容生产的替代方案
* 理解了在像保险欺诈这样不平衡且高成本的分类问题中,为什么 precision-recall 权衡比 accuracy 更重要
# 总结
FraudGuard AI 展示了 Machine Learning 和业务规则智能如何协同工作以支持保险欺诈调查工作流。
该项目不仅关注预测 accuracy,还关注:
* 可解释性
* 欺诈推理
* 业务价值
* 调查支持
这使其更接近于真实的欺诈分析应用程序,而不仅仅是一个简单的 ML notebook 项目。标签:Apex, Kubernetes, Python, 保险业务, 分类算法, 安全规则引擎, 无后门, 机器学习, 欺诈检测, 逆向工具