utkarshkumarug21-byte/Hybrid-Deep-Learning-and-Ensemble-Approaches-for-Fake-News-Detection
GitHub: utkarshkumarug21-byte/Hybrid-Deep-Learning-and-Ensemble-Approaches-for-Fake-News-Detection
一个基于堆叠集成学习和 SHAP 分析的可解释假新闻检测框架,通过发现并修复基准数据集的数据泄露问题,在干净数据上实现了高精度文本分类。
Stars: 0 | Forks: 0
# 混合机器学习与集成方法用于假新闻检测
一个可解释的假新闻检测框架,采用混合特征工程、堆叠集成学习和 SHAP 分析。该系统结合了 Logistic Regression、XGBoost 和 LightGBM,在经过清理和仔细评估的新闻数据集上实现了可靠且高精度的文本分类。
## 📌 项目概述
假新闻已成为数字时代的主要挑战之一。社交媒体平台允许错误信息迅速传播,影响公众舆论、政治事件、财务决策和医疗健康意识。因此,自动假新闻检测系统已成为自然语言处理 (NLP) 和机器学习中的重要研究领域。
现有的多项研究报告了假新闻检测极高的准确率。然而,其中许多研究未能调查基准数据集中存在的隐藏数据质量问题。重复的文章和重叠的样本会导致机器学习模型记忆模式,而不是学习有意义的表示。
本项目使用稳健且可解释的机器学习框架,对假新闻检测进行了批判性的重新评估和增强。
## 🔍 关键发现:基准数据集中的数据泄露
在数据集分析期间,我们在广泛使用的 Kaggle Fake and Real News 数据集中发现了一个严重的方法论缺陷:
| 指标 | 数值 |
|--------|-------|
| 原始文章数 | 44,898 |
| 发现的重复文章数 | **6,333 (14.1%)** |
| 清理后的唯一文章数 | 38,565 |
| 移除的训练-测试集重叠样本 | 1,664 |
当存在重复项时,同一篇文章可能**同时出现在训练集和测试集中**。这被称为**数据泄露**——模型记忆了答案,而不是学习了模式。Alotaibi 等人 (2026) 发表的原始论文报告了 99.13% 的准确率,但由于这种泄露,这个数值被人为地夸大了。
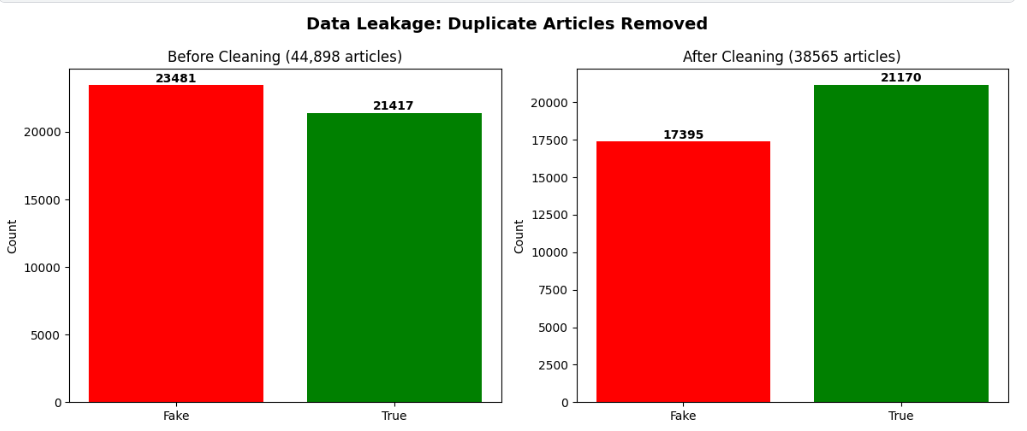
*图:展示重复文章和清理后数据集大小的数据分析*
## 🏗️ 系统架构
所提出的系统遵循一个四阶段的 pipeline:
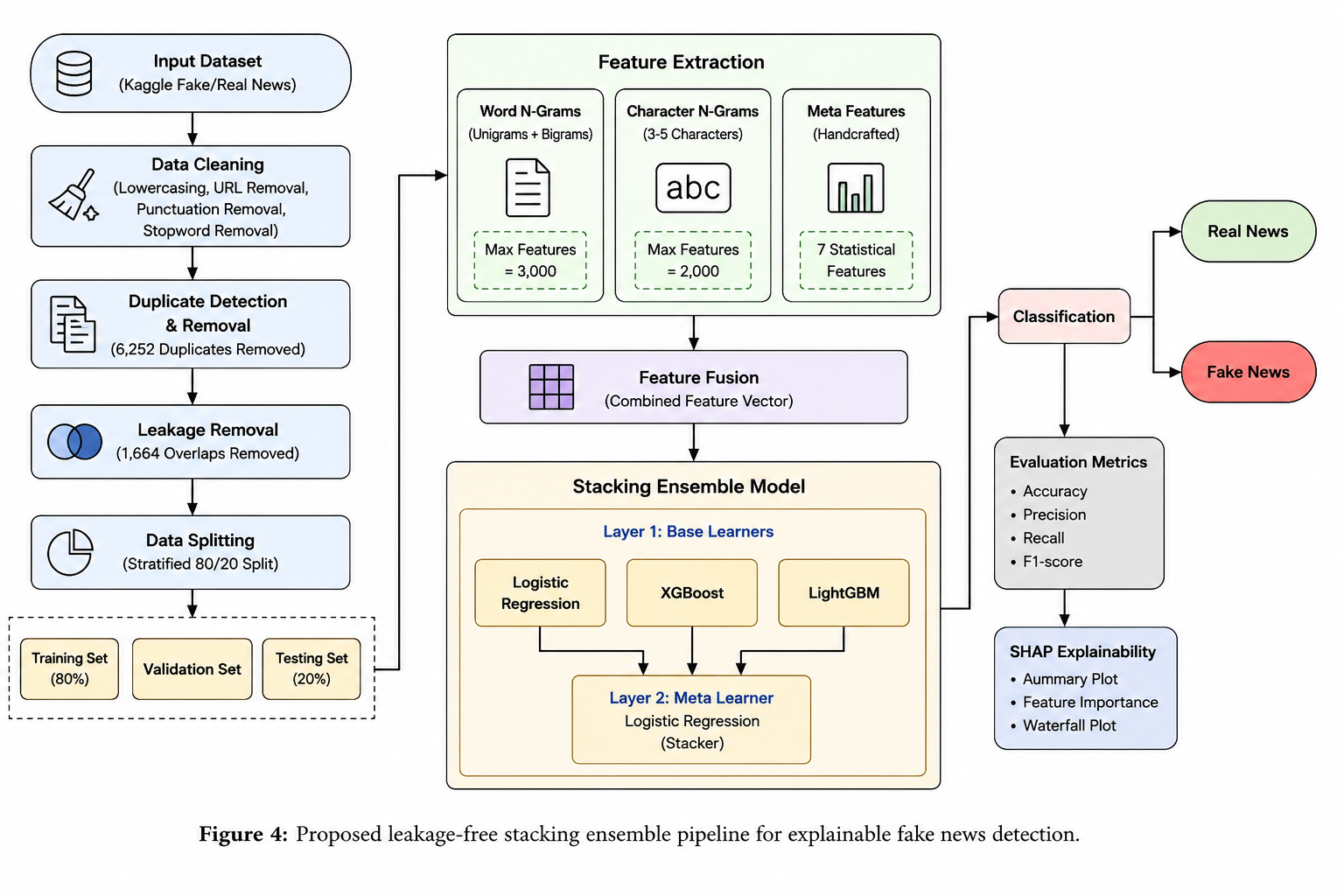
*图:用于可解释假新闻检测的所提出的无泄露堆叠集成 pipeline*
### 阶段 1:数据预处理
- 将所有文本转换为小写
- 移除 URL 和标点符号
- 移除重复文章(移除了 6,333 篇)
- 分层 80/20 拆分,训练集与测试集零重叠
### 阶段 2:特征工程(三个并行分支)
| 特征类型 | 描述 | 特征数量 |
|--------------|-------------|-------------------|
| **单词 N-grams** | 使用 TF-IDF 的一元语法 + 二元语法 | 3,000 |
| **字符 N-grams** | 使用 TF-IDF 的 3-5 字符序列 | 2,000 |
| **元特征** | 手工制作的文体特征 | 7 |
**提取的元特征:**
- 文章长度(字符数)
- 单词数
- 大写字母比例(假新闻经常使用全部大写)
- 感叹号数量(煽情指标)
- 问号数量(反问风格)
- 平均单词长度
- 标点符号数量
所有特征被组合成一个单一的 5,007 维特征向量。
### 阶段 3:堆叠集成
**第一层 - 基础模型:**
- Logistic Regression
- XGBoost
- LightGBM
**第二层 - 元学习器:**
- Logistic Regression(组合三个概率输出)
每个基础模型输出一个概率分数。这 3 个概率成为元学习器的输入特征,由其做出最终决策。
### 阶段 4:使用 SHAP 进行可解释性
集成了 SHAP (SHapley Additive exPlanations) 来解释:
- **全局重要性** – 总体上哪些特征最重要
- **局部解释** – 为什么特定文章被分类为假新闻或真实新闻
## 📊 结果
### 干净测试集上的模型性能(7,713 篇文章)
| 模型 | 准确率 |
|-------|----------|
| 原始论文 (Alotaibi 等人,存在泄露) | 99.13% |
| Logistic Regression | 99.51% |
| XGBoost | 99.64% |
| LightGBM | 99.64% |
| **堆叠集成 (Ours)** | **99.66%** |
| DistilBERT (微调) | 99.71% |
我们的堆叠集成在干净、无泄露的数据集上实现了 **99.66% 的准确率**——真实地超越了原始论文中被夸大的结果。
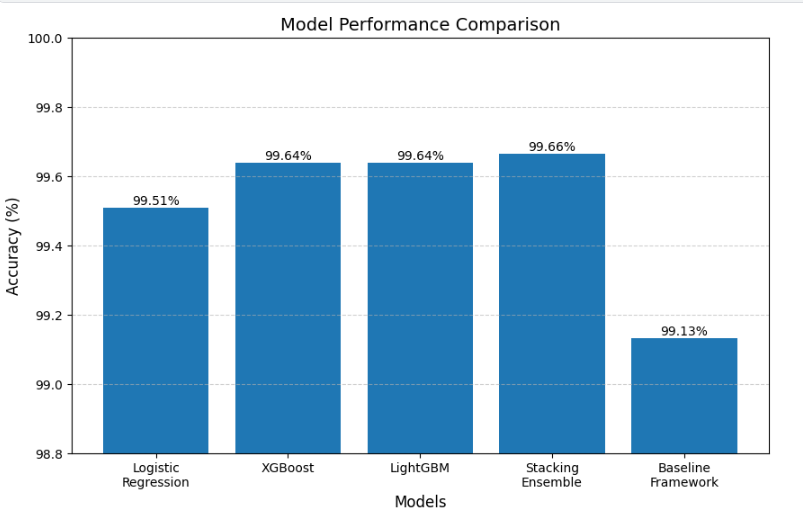
*图:所有模型之间的准确率比较*
### 混淆矩阵
在 7,713 篇测试文章中,只有 **26 个错误分类**。
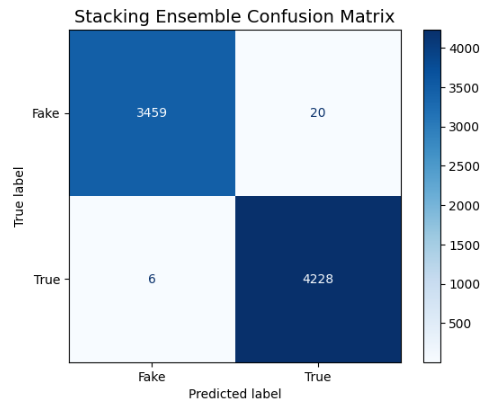
*图:堆叠集成模型的混淆矩阵*
## 🔬 使用 SHAP 的可解释性
### 全局特征重要性
SHAP 摘要图显示了整个数据集中最具影响力的特征。捕获标点符号模式的字符 n-grams 和如感叹号数量等元特征是主要贡献者。
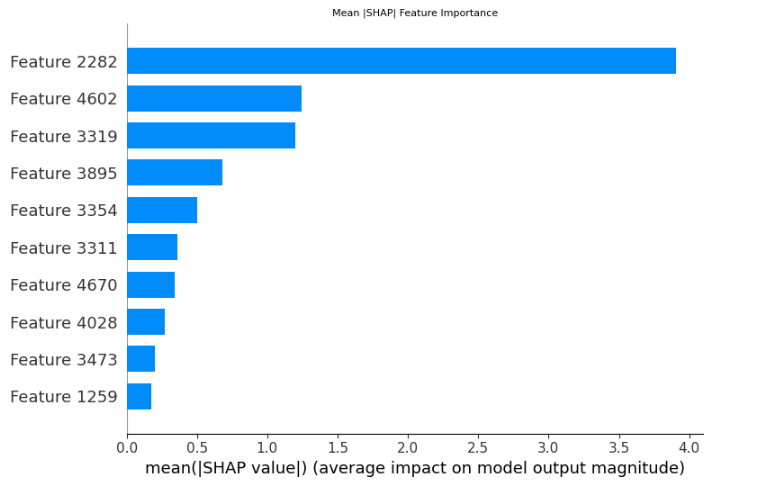
*图:展示全局特征重要性的 SHAP 摘要图*
### 局部解释(单个预测)
瀑布图展示了每个特征如何对特定预测做出贡献——红色条推向“假”,蓝色条推向“真”。
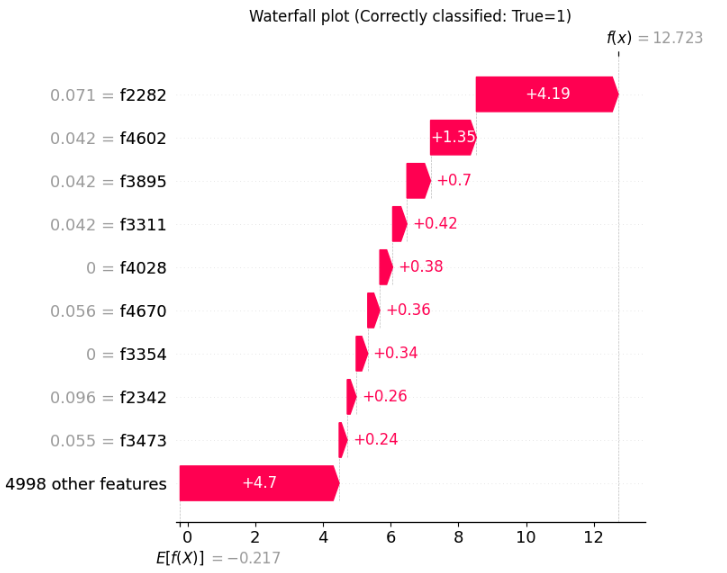
*图:单个预测的 SHAP 瀑布图解释*
### ROC-AUC
堆叠集成实现了接近完美的 ROC-AUC **0.9997**,表明在假新闻和真实新闻类别之间具有出色的区分度。
## 🌍 跨数据集泛化(LIAR 数据集)
为了测试模型对不同类型文本的泛化能力,我们在 LIAR 数据集(来自 PolitiFact 的简短政治声明)上进行了评估。
| 模型 | Kaggle 准确率 | LIAR 准确率 |
|-------|-----------------|---------------|
| 堆叠集成 | 99.66% | ~60% |
| DistilBERT (仅 LIAR) | 55.09% | 60.46% |
| DistilBERT (组合训练) | 99.71% | 62.43% |
在 LIAR 上从 99% 下降到 60% 是一个**诚实且重要的发现**——它表明 Kaggle 数据集具有非常明显的风格模式,而现实世界中的假新闻检测要困难得多。这被作为一项局限性报告,并激发了未来的工作。
## 🛡️ 鲁棒性测试(噪声注入)
我们通过向测试文章注入四种类型的噪声来测试模型的鲁棒性。
| 噪声水平 | 拼写错误 | 标点符号 | 大小写 | 单词丢弃 |
|-------------|------|-------------|------|-----------|
| 0% | 99.4% | 99.0% | 99.6% | 99.4% |
| 5% | 89.2% | 88.0% | 99.6% | 97.8% |
| 10% | 82.0% | 76.2% | 99.6% | 95.0% |
| 15% | 73.6% | 63.6% | 99.6% | 94.0% |
| 20% | 63.6% | 60.6% | 99.6% | 92.8% |
### 关键发现:
- **大小写更改**几乎没有影响(在 20% 噪声下为 99.6%)——由于预处理中进行了小写转换
- **单词丢弃**处理得很好(在 20% 噪声下为 92.8%)
- **拼写错误**显著降低性能(在 10% 噪声下为 82%)——字符级特征很敏感
- **标点符号更改**也会导致性能下降(在 10% 噪声下为 76%)——标点符号计数被用作元特征
## 📈 完整结果总结
| 模型 / 方法 | 准确率 | ROC-AUC | 备注 |
|----------------|----------|---------|-------|
| 原始论文 (Alotaibi 等人) | 99.13% | — | 存在数据泄露 |
| Logistic Regression | 99.51% | — | 干净数据 |
| XGBoost | 99.64% | — | 干净数据 |
| LightGBM | 99.64% | — | 干净数据 |
| **堆叠集成 (Ours)** | **99.66%** | **0.9997** | **干净数据 – 最佳** |
| DistilBERT (Kaggle) | 99.71% | — | 重型 Transformer |
| DistilBERT (LIAR) | 60.46% | — | 跨领域下降 |
为了更深入地了解项目方法论、实验结果和详细分析,请参阅 [`paper/`](paper) 目录中提供的完整项目摘要。
## 📁 仓库结构
```
Hybrid-Machine-Learning-and-Ensemble-Approaches-for-Fake-News-Detection/
├── figures/ # Visualizations and performance plots
│ ├── architecture_pipeline.png
│ ├── leakage_analysis.png
│ ├── model_accuracy_comparison.png
│ ├── stacking_confusion_matrix.png
│ ├── shap_summary_plot.png
│ ├── shap_waterfall_plot.png
│ ├── roc_curve.png
│ └── robustness_test.png
├── notebooks/ # Step-by-step implementation
│ ├── 01_data_cleaning.ipynb
│ ├── 02_feature_engineering.ipynb
│ ├── 03_model_training.ipynb
│ ├── 04_stacking_ensemble.ipynb
│ └── 05_shap_analysis.ipynb
├── models/ # Serialized trained model files (.pkl)
│ ├── model_lr.pkl # Logistic Regression (Base Model)
│ ├── model_xgb.pkl # XGBoost (Base Model)
│ ├── model_lgbm.pkl # LightGBM (Base Model)
│ └── meta_model.pkl # Final Stacking Meta-Classifier
├── paper/ # Research documentation
│ ├── research_paper.pdf
│ └── research_paper.docx
├── README.md # Project documentation
├── requirements.txt # Python dependencies
└── LICENSE # Project license
```
## 🚀 安装
```
# Clone 仓库
git clone https://github.com/utkarshkumarug21-byte/Hybrid-Machine-Learning-and-Ensemble-Approaches-for-Fake-News-Detection.git
cd Hybrid-Machine-Learning-and-Ensemble-Approaches-for-Fake-News-Detection
# 安装所需的库
pip install -r requirements.txt
## 📚 Citation
If you use this work in your research, please cite:
```bibtex
@software{kumar2026hybrid,
author = {Utkarsh Kumar},
title = {Hybrid Machine Learning and Ensemble Approaches for Fake News Detection},
year = {2026},
url = {https://github.com/utkarshkumarug21-byte/Hybrid-Machine-Learning-and-Ensemble-Approaches-for-Fake-News-Detection}
}
```
标签:Apex, Atomic Red Team, Kaggle数据集, LightGBM, NLP, NoSQL, SHAP分析, XAI, XGBoost, 人工智能安全, 假新闻检测, 可解释人工智能, 合规性, 堆叠模型, 数据泄露检测, 数据清洗, 数据质量评估, 文本分类, 新闻真伪识别, 机器学习, 深度伪造与虚假信息防治, 混合模型, 特征工程, 社交媒体分析, 算法鲁棒性, 虚假信息检测, 逆向工具, 逻辑回归, 集成学习