cvoid/llm_sidechannels
GitHub: cvoid/llm_sidechannels
该项目验证并复现了针对流式大语言模型的多种网络侧信道攻击及相应的防御措施。
Stars: 0 | Forks: 0
# LLM 侧信道
针对 LLM 的侧信道攻击及其防御措施的验证。
## LLM 侧信道实验环境
针对流式 LLM 的被动网络侧信道攻击。本仓库复现了 Wei 等人 (arXiv:2411.01076) 的核心查询指纹识别实验及相关工作,以 speculative decoding 作为信号源。被动攻击者通过监控加密的 TLS 流量,可以在不进行任何解密的情况下,通过观察每次迭代的 packet 大小,指纹识别出用户发送的 50 条医疗查询中的具体某一条——在 temperature 为 0.3 时,使用 LightGBM 的准确率可达 96.8%。
## 论文
**[1] Carlini & Nasr (2024). Remote Timing Attacks on Efficient Language Model Inference.**
[arXiv:2410.17175](https://arxiv.org/abs/2410.17175)。Google DeepMind。
奠基性论文。该论文表明,speculative decoding 及其他高效推理技术引入了数据依赖性的时间特征:模型的运行速度会根据每个 token 的难度而变快或变慢。监控加密流量的被动网络攻击者可以了解用户对话的主题(例如,医疗建议 vs 编程辅助),针对包括 ChatGPT 和 Claude 在内的生产系统,其精度超过 90%。通过对开源系统的黑盒访问,主动攻击者还可以恢复放置在 prompt 中的 PII(电话号码、信用卡号码)。
**[2] Wei et al. (2025). When Speculation Spills Secrets: Side Channels via Speculative Decoding in LLMs.**
[arXiv:2411.01076](https://arxiv.org/abs/2411.01076)。多伦多大学。
本仓库主要复现的论文。正确的推测会在每次迭代中生成多个 token(较大的 TLS 记录);错误的推测会回退到单个 token(较小的记录)。通过观察每次迭代的 packet 大小序列,攻击者可以从 50 个 prompt 集合中指纹识别出查询,在 temperature 为 0.3 时,跨四种 speculative decoding 方案(REST 100%、LADE 91.6%、BiLD 95.2%、EAGLE 77.6%)的准确率超过 75%。还演示了以超过每秒 25 个 token 的速率泄露机密数据存储内容。
**[3] McDonald & Bar Or (2025). Whisper Leak: A Side-Channel Attack on Large Language Models.**
[arXiv:2511.03675](https://arxiv.org/abs/2511.03675)。Microsoft。
最广泛的评估:来自主要提供商的 28 个生产级 LLM,每个模型多达 21,716 条查询。在 packet 大小和时间序列上训练 LightGBM、LSTM 和 BERT 分类器,以检测对话是否匹配敏感目标主题。对于大多数模型,AUPRC 达到 98% 以上,在 10,000:1 的噪声与目标不平衡下,5-20% 的召回率实现了 100% 的精度。提出了随机填充、token 批处理和 packet 注入作为部分缓解措施。
## 结果
### 实验 1 -- Wei et al. 查询指纹识别
在我们的本地 llama.cpp 设置上复现了 Wei 等人的查询指纹识别攻击(论文图 3)。50 个 MedAlpaca prompt,每个查询 30 条 trace,每类 25 条用于训练 / 5 条用于测试。
评估了三个分类器:Random Forest(论文基准)、LightGBM(McDonald & Bar Or 提出的主要方法)和 BiLSTM(200 个 epoch,2 层双向,每个方向 hidden=128)。
### TPQ 扫描 -- 准确率 vs 每个查询的 trace 数
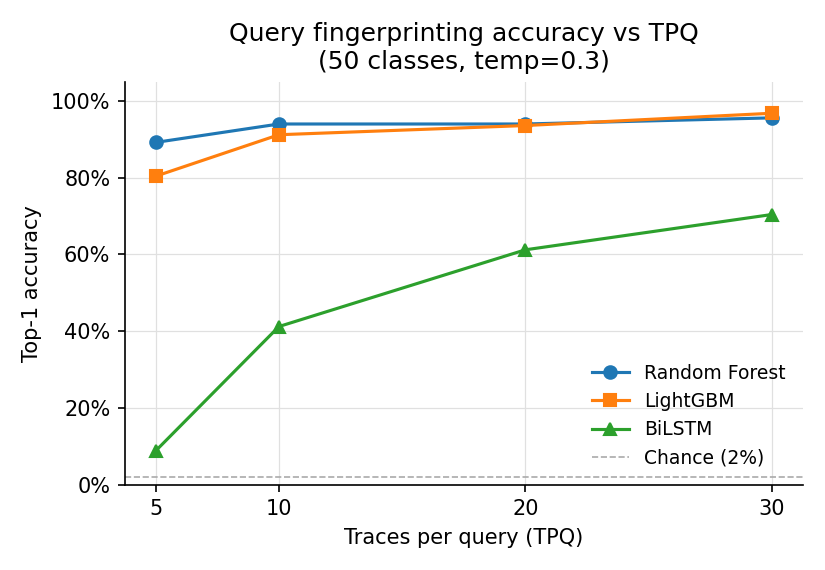
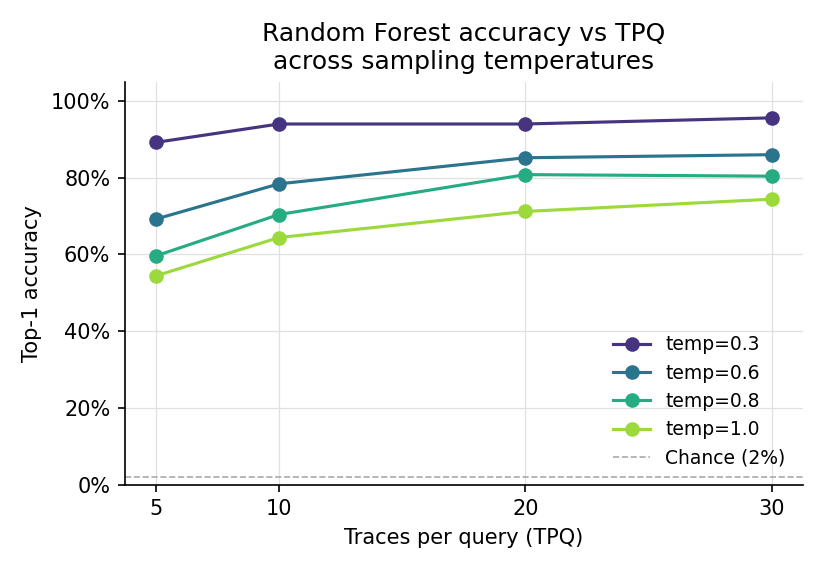
**Random Forest**
| temp | tpq=5 | tpq=10 | tpq=20 | tpq=30 |
|------|-------|--------|--------|--------|
| 0.3 | 0.892 | 0.940 | 0.940 | **0.956** |
| 0.6 | 0.692 | 0.784 | 0.852 | 0.860 |
| 0.8 | 0.596 | 0.704 | 0.808 | 0.804 |
| 1.0 | 0.544 | 0.644 | 0.712 | 0.744 |
**LightGBM**
| temp | tpq=5 | tpq=10 | tpq=20 | tpq=30 |
|------|-------|--------|--------|--------|
| 0.3 | 0.804 | 0.912 | 0.936 | **0.968** |
| 0.6 | 0.580 | 0.792 | 0.884 | 0.920 |
| 0.8 | 0.584 | 0.724 | 0.868 | 0.884 |
| 1.0 | 0.488 | 0.624 | 0.768 | 0.812 |
**BiLSTM** (2 层双向, hidden=128, 200 个 epochs, Adam lr=1e-3)
| temp | tpq=5 | tpq=10 | tpq=20 | tpq=30 |
|------|-------|--------|--------|--------|
| 0.3 | 0.088 | 0.412 | 0.612 | **0.704** |
| 0.6 | 0.076 | 0.156 | 0.396 | 0.564 |
| 0.8 | 0.076 | 0.136 | 0.380 | 0.416 |
| 1.0 | 0.064 | 0.188 | 0.416 | 0.524 |
论文报告在 temperature 为 0.3 时,针对 REST 风格 speculative decoding 的准确率约为 100%。在考虑硬件差异(A100 vs 双 RTX 3070,远程服务器 vs loopback)后,我们在 tpq=30 时 RF 为 95.6% 和 LightGBM 为 96.8% 的结果与此一致。
### 分类器比较
在 tpq=30,temp=0.3 时:LightGBM (0.968) > RF (0.956) > BiLSTM (0.704)。
LightGBM 在所有温度下的表现都比 RF 高出 1-6%;在信号噪声较大的较高温度下,差距进一步拉大。BiLSTM 的峰值为 0.704,而在 tpq=5 (0.088) 时表现接近随机。这反映了样本效率方面的文献结论:在每类约 25 条训练 trace 的情况下,树模型对单个特征的轴对齐分割优于循环网络的时间建模。BiLSTM 在 epoch 200 时训练损失接近于零,但泛化能力极差,这表明在这种数据集规模下,模型发生了过拟合,而不是学习到了可泛化的表示。McDonald & Bar Or 报告的 BiLSTM 优势可能需要更大的训练集(他们每个模型使用了 21,716 条查询)。
### 混淆矩阵
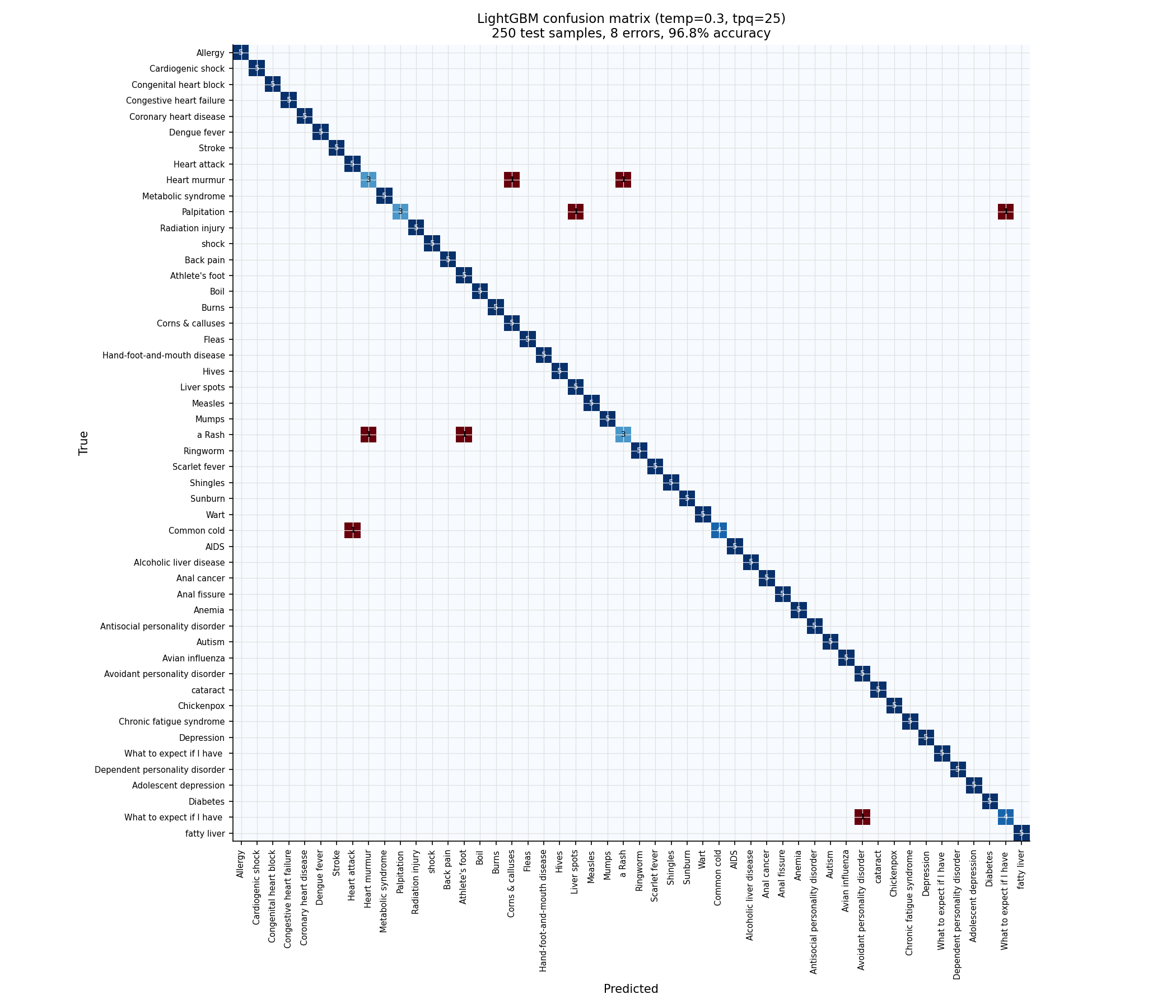
### 在 temp=0.3, tpq=30 时的分类细节
50 个 prompt 中有 43 个实现了完美分类。7 个错误集中在两个结构相似的配对中:
- **Antisocial personality disorder** (urgent) 与 **Avoidant
personality disorder** (urgent) 混淆 —— 5 条测试 trace 中有 3 条被误分类。两者都是简短的精神科“何时就医”回复,具有几乎相同的回复长度和迭代特征。
- 另外三个 prompt 各自在一个具有相似回复长度且属于相同问题模板的 prompt 上产生了一个错误。
在较高温度下准确率的下降是预期的:在 temperature 为 1.0 时,draft model 的 speculative token 被接受的一致性降低,使得在重复捕获同一 prompt 时,每次迭代的字节数变得更加嘈杂。
### 防御评估
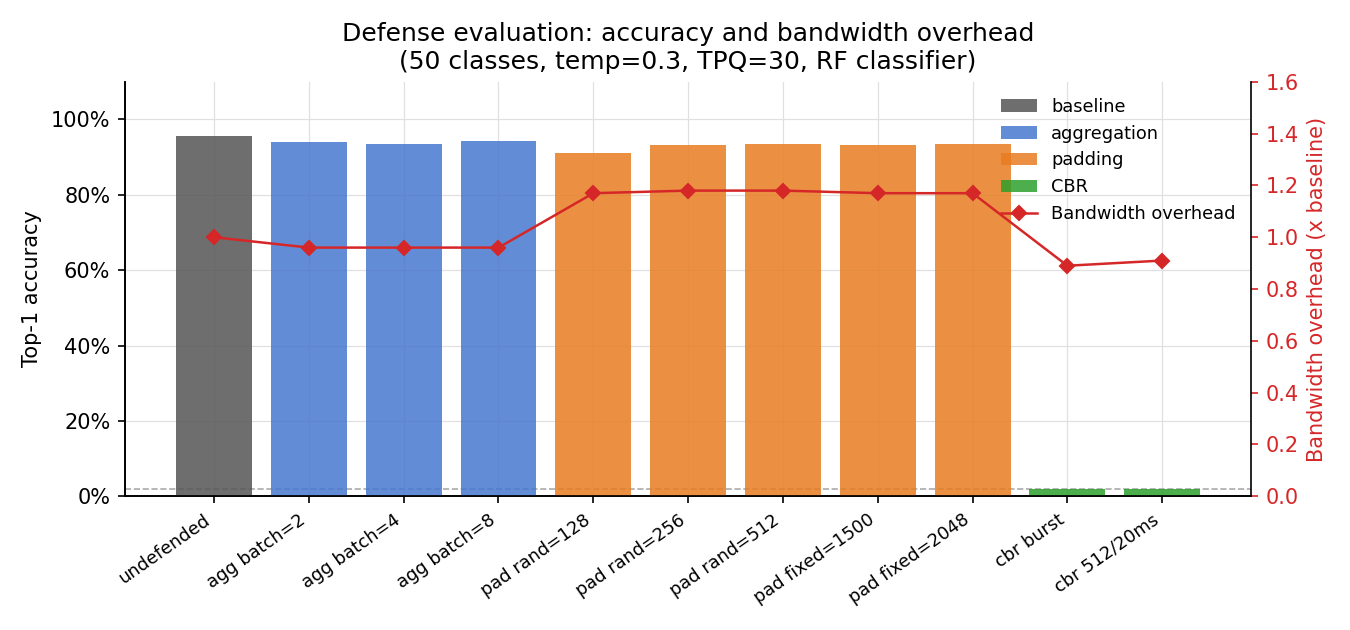
所有防御评估均在 temp=0.3, tpq=30, RF 分类器下进行。开销是相对于未防御基准的平均服务器到客户端字节数。
| 防御 | Accuracy | Reduction | Overhead |
|---------|----------|-----------|----------|
| undefended | 0.956 | -- | 1.00x |
| agg batch=2 | 0.940 | 0.016 | 0.96x |
| agg batch=4 | 0.936 | 0.020 | 0.96x |
| agg batch=8 | 0.944 | 0.012 | 0.96x |
| pad rand=128 | 0.912 | 0.044 | 1.17x |
| pad rand=256 | 0.932 | 0.024 | 1.18x |
| pad rand=512 | 0.936 | 0.020 | 1.18x |
| pad fixed=1500 | 0.932 | 0.024 | 1.17x |
| pad fixed=2048 | 0.936 | 0.020 | 1.17x |
| **cbr burst** | **0.020** | **0.936** | **0.89x** |
| **cbr 512/20ms** | **0.020** | **0.936** | **0.91x** |
**Token 聚合**(将 N 个 SSE 事件进行批处理)几乎没有用:在任何批处理大小下最大只有 2% 的 reduction。我们的字节大小信号是累加的 —— 批处理 N 次迭代会产生一个 packet,其总字节数仍然与 N 次迭代中每迭代的 token 计数总和相关。
**Packet 填充**(随机或固定大小)也无效:即使在 max_pad=128 的情况下,最大也只有 4.4% 的 reduction。填充是在 SSE 事件级别应用的,但每次解码迭代会产生 N 个 SSE 事件(每个被接受的 speculative token 对应一个)。特征提取器将 window_ms=3.5ms 内的所有字节数相加汇总为一次迭代的单一观察值,因此测量值为 N x padding_size。这仍然编码了接受计数 N —— 填充只是对信号进行了缩放,并没有破坏它。Fixed=2048 覆盖了观察到的全部事件大小范围,但正因如此,它仅将准确率降低了 2%。
**CBR (constant-bit-rate) 流式传输**是唯一有效的防御:两种变体都将准确率从 95.6% 降至 2.0%(对于 50 个类别来说相当于随机猜测)。`cbr burst` 缓冲完整的响应并一次性发送所有内容;特征提取器将所有字节折叠成一次迭代,唯一剩下的信号是总响应长度,这不足以进行 50 类分类。`cbr 512/20ms` 以 20ms 的间隔发送 512 字节的数据块,产生一个平坦的常量值特征向量。两者都破坏了分类器所依赖的每次迭代的结构。
CBR 不需要额外带宽(0.89-0.91x 的开销,而填充为 1.17-1.18x),但会增加与完整生成时间相等的延迟 —— 在模型完成生成之前,客户端不会收到任何信息。对于以约 15 tokens/sec 速度生成的 200-token 响应,大约会增加 13 秒的延迟。
### 实验 2 -- Carlini & Nasr 基于时间的二元消歧
在我们的本地 llama.cpp 设置上复现了 Carlini & Nasr 的 GMM 攻击。特征:每条 trace 的前 50 个 inter-packet gap(服务器->客户端,单位 ms)。在每条 prompt 上训练了 20 条 trace 的两个 GMM(每个假设对应一个),并通过 log-likelihood ratio 进行分类。
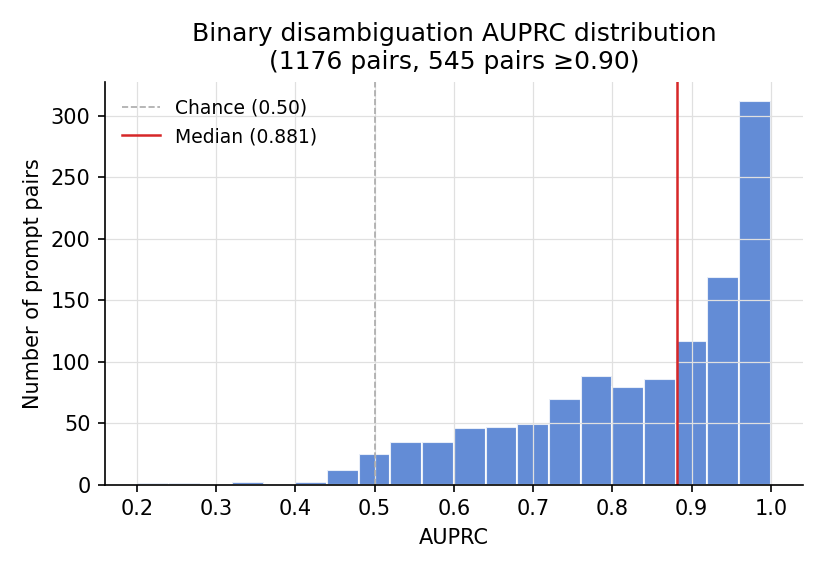
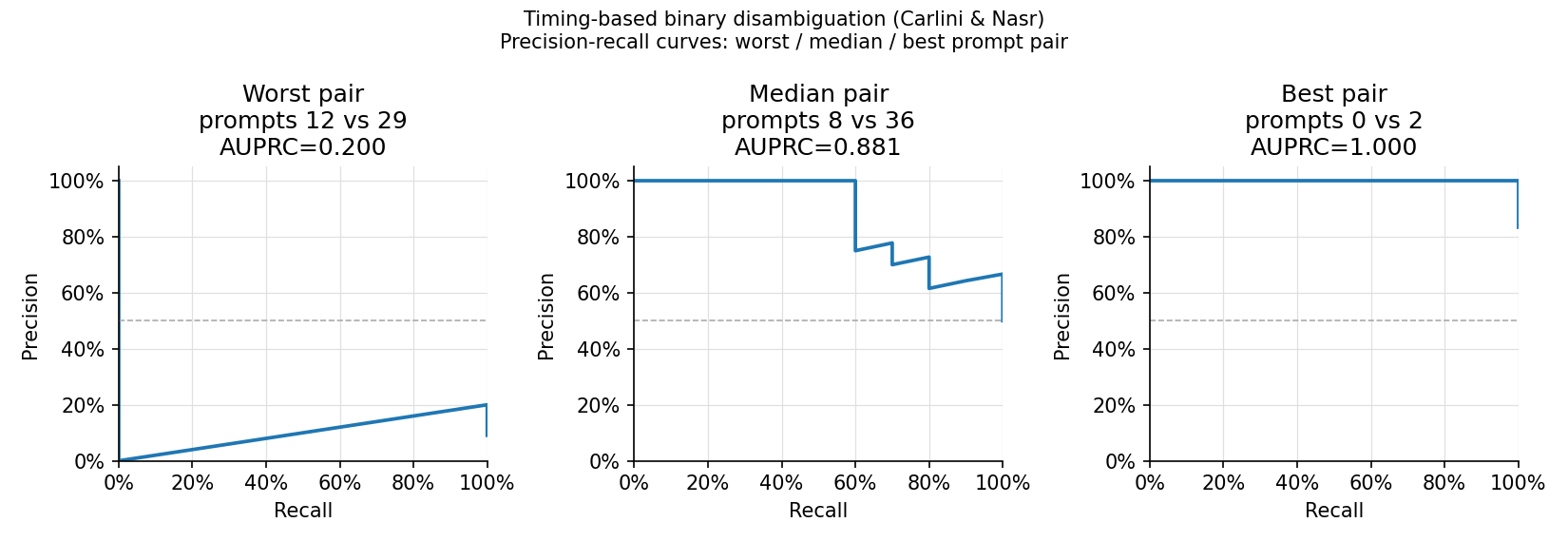
在 50 个 prompt 数据集的所有 1,176 个 prompt 配对中进行了评估(temp=0.3,每个 prompt 30 条 trace,20 条训练 / 10 条测试):
| Metric | Value |
|--------|-------|
| Pairs evaluated | 1,176 |
| Median AUPRC | 0.881 |
| Mean AUPRC | 0.840 |
| Pairs ≥ 0.90 AUPRC | 545 / 1,176 (46%)| Pairs ≥ 0.75 AUPRC | 875 / 1,176 (74%) |
| Best pair AUPRC | 1.000 |
| Worst pair AUPRC | 0.200 |
该分布呈现严重的右偏:大多数配对聚集在 1.0 附近,少数难以区分的配对中,两个 prompt 会产生相似的响应长度和迭代模式。最差的配对(prompt 12 vs 29)具有几乎相同的时间特征;而最好的配对(AUPRC=1.0)则涉及具有非常不同响应长度或 speculative 接受率的 prompt。
注意:该论文在远程商业 API 上使用了 100 个 inter-packet gap 和每个假设 100 条训练 trace。我们使用了 50 个 gap(较短的本地响应已满足 100-gap 要求)和 20 条训练 trace。尽管训练集较小,但带有 speculative decoding 的 llama.cpp 上显然存在 inter-packet timing 信号。
### 实验 3 -- McDonald & Bar Or 主题推断
在我们的本地 llama.cpp 设置上复现了 McDonald & Bar Or 的 LightGBM 主题检测 pipeline。目标主题:50 个 Python 编程问题(各 10 条 trace)。负样本集:50 个 MedAlpaca 医疗问题(各 30 条 trace)。特征:前 50 个 (packet_size, inter_arrival_ms) 对,展平为一个 100 维的向量。每个类别按 80/20 的比例划分训练/测试集。
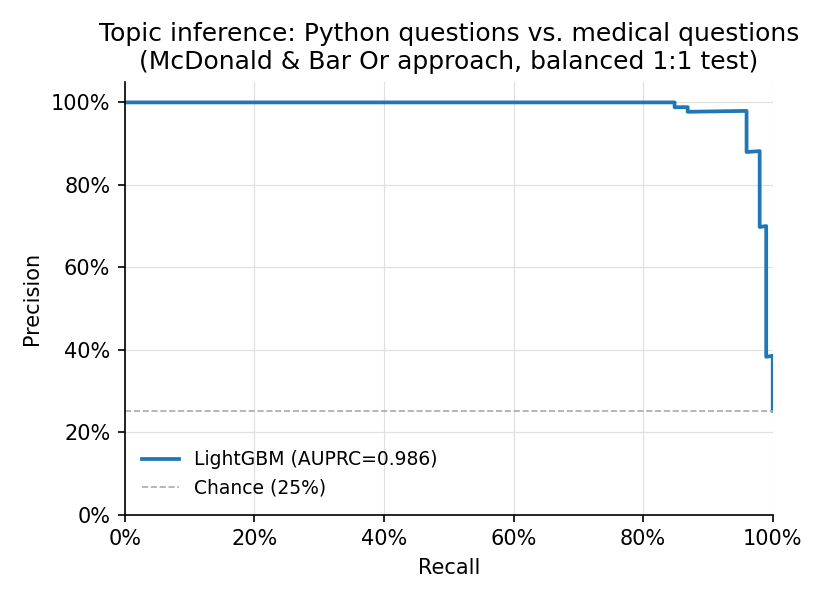
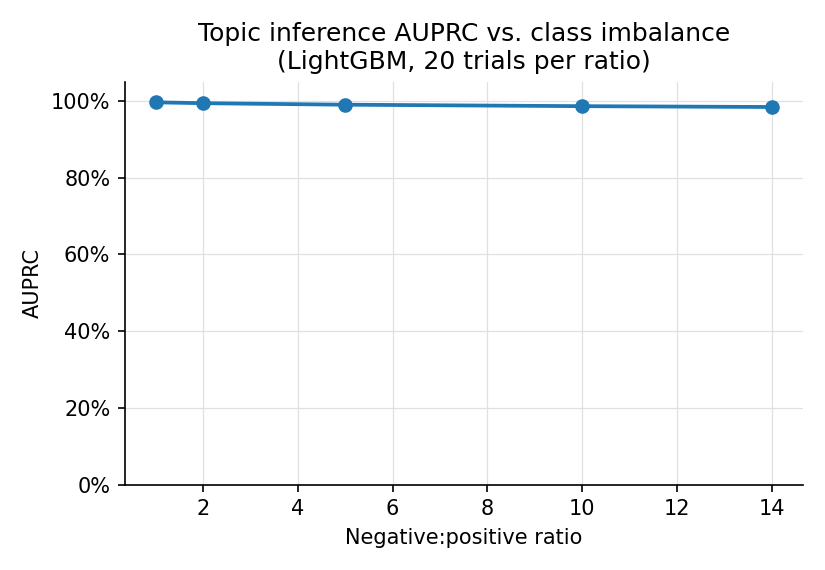
| Metric | Value |
|--------|-------|
| Target traces | 495 (50 prompts × ~10 runs) |
| Negative traces | 1,467 (50 prompts × 30 runs) |
| AUPRC (balanced 1:1) | **0.986** |
| AUPRC at 5:1 imbalance | 0.990 |
| AUPRC at 10:1 imbalance | 0.987 |
| AUPRC at 14:1 imbalance | 0.984 |
(size, timing) 特征表示干净地分离了这两个主题:Python 编程响应包含代码块和结构化的解释,产生了大初始 packet(代码)随后跟着较小的后续 packet 的特征模式。医疗响应则具有不同的节奏。
在高达 14:1 的负样本:正样本不平衡下,AUPRC 保持在 0.984 以上,这与论文中关于 28 个生产级 LLM 的 AUPRC >0.98 的发现相一致。
注意:论文在 100 个 prompt 变体上进行训练,并针对 11,716 个 Quora 问题负样本(117:1 不平衡)进行了评估。我们的数据集较小;此外,主题边界(编程 vs. 医疗)也比论文中“洗钱合法性” vs. 一般 Quora 问题更为分明,这解释了即使在中等训练集规模下 AUPRC 也很高的原因。
## 工作原理
### 信号源
llama.cpp 运行 speculative decoding:一个小的 draft model (Qwen2.5-0.5B) 在每次迭代中提出多个候选 token,然后大型 target model (Qwen2.5-7B) 在一次前向传递中对它们进行验证。当 draft 的预测正确时,多个 token 会被接受并组合在一个 SSE chunk 中流式传输 —— 从而产生一个大的 TLS 记录。当 draft 预测错误时,只有一个 token 会被接受 —— 产生一个小的记录。每次迭代接受的 token 数量是依赖于输入的:“简单”的内容(常见的医学术语、可预测的续写)比“困难”的内容(不寻常的术语、复杂的推理)接受更多的 speculative token。
这意味着给定 prompt 的 TLS 记录大小序列就是一个指纹:它编码了响应中哪些部分对于 draft 来说容易预测,哪些部分难以预测,这是生成特定内容的函数。
### 特征向量
对于每个响应,我们使用 tcpdump 在 loopback 接口上捕获原始 TLS 流量。Scapy 解析 pcap 并提取带有时间戳的服务器到客户端 payload 大小。我们使用时间窗口(`window_ms`,根据机器进行校准)将 packet 分组为解码迭代,对每个窗口内的字节数求和,丢弃前两次迭代(由于恒定的 TLS 握手和 HTTP 标头开销),并将长度填充或截断为固定的 100 次迭代。结果是一个 100 维的每次迭代的字节数向量。
### 攻击
**离线分析阶段:**在 50 个目标查询中为每个 prompt 捕获 25-30 条 trace。构建一个 100 维的特征矩阵,并训练一个 Random Forest 分类器(150 棵树,最大深度为 15)。
**在线阶段:**捕获一条未知查询的 trace。提取其特征向量,并根据训练好的模型进行分类。
### 为什么 nginx 和 tcpdump 很重要
两个配置细节对于能够观察到信号至关重要:
**nginx 不得进行缓冲或压缩。**如果使用 `proxy_buffering on` 或 `gzip on`,nginx 会在转发前累积 SSE chunk,从而将多个按迭代的记录折叠成一个单一的 packet。分类器看到的是一个平坦的信号,准确率会降至随机水平。配置使用了 `proxy_buffering off`、`gzip off` 和 `tcp_nodelay on`。
**tcpdump 必须使用 `--immediate-mode`。**如果不使用,libpcap (TPACKET_V3) 会将 packet 累积到环形缓冲区块中,并且只有在块填满或约 64ms 的退役计时器触发时才发送它们。短的响应可能会在任何块退役之前就完成了,导致捕获不到任何 packet。`--immediate-mode` 强制进行按 packet 发送。
## 依赖
**系统包**(由 `tools/setup_once.sh` 安装):
- `tcpdump` —— packet 捕获;要求运行用户位于 `pcap` 组中或拥有 `CAP_NET_RAW` 权限
- `nginx` —— TLS 终止反向代理
- `llama-server` —— 来自 [llama.cpp](https://github.com/ggerganov/llama.cpp);
必须在 `$PATH` 中
**模型**(通过 ollama 拉取,路径复制到 `tools/start_llama.sh` 中):
- `qwen2.5:7b-instruct-q4_K_M` —— target model (~4.7 GB)
- `qwen2.5:0.5b-instruct-q8_0` —— 用于 speculative decoding 的 draft model (~530 MB)
**Python 包**(由 [uv](https://github.com/astral-sh/uv) 管理,声明在 `pyproject.toml` 中):
| Package | Use |
|---------|-----|
| `scapy` | 离线 pcap 解析 |
| `httpx` | 用于 LLM 查询的 HTTPS 流式客户端 |
| `aiohttp` | 用于防御代理的异步 HTTP 服务器/客户端 |
| `scikit-learn` | RandomForest 分类器 |
| `numpy` | 特征数组构建 |
| `pandas` | TPQ 扫描结果表 |
| `lightgbm` | LightGBM 分类器 |
| `torch` | BiLSTM 分类器 (CUDA 12.1 build) |
开发依赖(`uv sync --group dev`):`pytest`, `mypy`, `pytest-mock`。
## 硬件
- AMD Threadripper (48 个逻辑核心), 64 GB RAM
- 2x RTX 3070 8 GB (共 16 GB VRAM)
- 单机设置:通过 nginx 反向代理和 loopback 上的 tcpdump 模拟网络“远程”
## 技术栈
| 组件 | 选择 | 原因 |
|-----------|--------|--------|
| LLM 服务器 | llama.cpp | 在 16 GB VRAM 下实现了更清晰的 SSE 分块和 speculative decoding |
| 目标模型 | Qwen2.5-7B-Instruct Q4_K_M | 适合放入 VRAM,并为 draft 留有空间 |
| 草稿模型 | Qwen2.5-0.5B-Instruct Q8 | 足够快以维持有用的推测率 |
| TLS 终止 | 带有自签名证书的 nginx | 在 server.local:8443 上的真实 TLS 边界 |
| 数据包捕获 | tcpdump + scapy | tcpdump 用于原始捕获,scapy 用于离线解析 |
| 分类器 | RandomForest, LightGBM, BiLSTM | RF 与论文 §4.4 一致;LightGBM 和 BiLSTM 遵循 McDonald & Bar Or 的方法 |
| 环境 | Python 3.11+, uv | 可重现,快速 |
## 仓库结构
```
serve/ nginx config, llama.cpp launch helpers
collect/ capture orchestration, prompt datasets, query client
data/ prompt JSONL files (committed; pcap data is gitignored)
features/ pcap parsing, TLS record extraction, feature builders
attack/ classifiers, training pipeline, evaluation metrics
analysis/ CSVs from tpq sweeps and accuracy comparisons
docs/ experiment plans, runbooks, paper PDFs
tools/ scripts for setup, calibration, smoke test, profiling
data/ pcap files and parquet feature files (gitignored)
logs/ llama.cpp and nginx logs (gitignored)
```
## 设置
**一次性系统设置**(需要 root 权限来配置 tcpdump 组和 nginx TLS 证书):
```
sudo bash tools/setup_once.sh
```
这将安装 tcpdump、nginx,为 server.local 创建自签名证书,并将您的用户添加到 pcap 组中。
**Python 环境:**
```
uv sync
```
## 运行实验
### 1. 启动 LLM 服务器
```
bash tools/start_llama.sh
```
使用 speculative decoding(Qwen2.5-7B 作为 target,Qwen2.5-0.5B 作为 draft)、完整 GPU 卸载和 4 个 HTTP 线程启动 llama.cpp。日志将输出到 `logs/llama.log`。在继续之前,请确认 speculative decoding 处于活动状态:
```
grep -i draft logs/llama.log
```
### 2. 校准 window_ms
```
bash tools/calibrate.sh
```
捕获一个查询并计算 `window_ms`:这是将迭代内的事件间间隔(亚毫秒级)与迭代间的推理暂停(几十毫秒)分开的间隔阈值。该算法查找连续排序的 inter-packet gap 之间的最大比率,然后返回边界 gap 的几何平均值。该值取决于硬件,如果服务器或模型发生改变,应重新校准。
### 3. 冒烟测试
```
uv run python tools/smoke_test.py --window-ms
```
对 3 个 prompt x 5 次运行进行分析,构建特征,训练 RandomForest,并检查准确率是否至少比随机概率(3 个类别为 0.33)高出 10 个百分点。通过的冒烟测试可确认在开始长达数小时的分析会话之前,完整的“从捕获到分类器” pipeline 正常工作。如果准确率接近随机猜测,请检查 pcap 大小(`ls -lh data/smoke/*.pcap`)并重新校准。
### 4. 完整特征分析
```
uv run python tools/run_profile.py --temperature 0.3 --tpq 30
uv run python tools/run_profile.py --temperature 0.6 --tpq 30
uv run python tools/run_profile.py --temperature 0.8 --tpq 30
uv run python tools/run_profile.py --temperature 1.0 --tpq 30
```
捕获 `n_prompts * tpq` 个 pcap 文件,并为每个 temperature 写入一个 `manifest.jsonl`。在每次运行开始前会打印预计时间(在 temperature 0.3 且开启 speculative decoding 时,每次查询约 5 秒,在 tpq=30 且覆盖所有四个 temperature 时约需 8 小时)。
### 5. TPQ 扫描
将各个 temperature 的清单合并为一个组合清单,然后运行扫描。之所以需要组合清单,是因为 `tpq_sweep.py` 会在内部根据 temperature 进行过滤,而每个单独的清单只包含一个 temperature 的数据。
```
cat data/raw/temp_*/manifest.jsonl > data/raw/all_temps/manifest.jsonl
uv run python tools/tpq_sweep.py \
--manifest data/raw/all_temps/manifest.jsonl \
--window-ms \
--out analysis/exp1_tpq_sweep_rf.csv
uv run python tools/tpq_sweep.py \
--manifest data/raw/all_temps/manifest.jsonl \
--window-ms \
--classifier lgbm \
--out analysis/exp1_tpq_sweep_lgbm.csv
uv run python tools/tpq_sweep.py \
--manifest data/raw/all_temps/manifest.jsonl \
--window-ms \
--classifier bilstm \
--out analysis/exp1_tpq_sweep_bilstm.csv
```
按照论文的协议,在每一个 (temperature, TPQ) 组合下训练和评估每个分类器:在每类的前 `tpq` 条 trace 上进行训练,在剩余的 5 条上进行测试。结果将写入 `analysis/`。
### 6. Prompt 多样性分析
```
uv run python tools/analyze_prompt_diversity.py \
--manifest data/raw_clean/manifest_all.jsonl \
--window-ms
```
报告每个 prompt 的响应长度统计信息,按问题模板对 prompt 进行分组,并计算模板内与模板间的余弦相似度。在进行完整的特征分析之前,使用此功能检查 prompt 集是否具有足够的响应长度多样性。需要关注的问题是,结构相同的模板(例如 14 个“何时寻求紧急医疗护理”问题)可能会生成长度相似的响应,从而在特征空间中导致这些类别发生折叠。对于此数据集,模板分离度为 +0.030 —— 完全在可接受的范围内。
## 关键实现说明
**Prompt 的顺序很重要。** `collect/data/exp1_prompts.jsonl` 中最初的 prompt 是为了响应长度多样性而排序的:一个简短的因果关系问题,一个中等长度的症状列表问题,以及一个较长的预后问题。在前几个位置结构相似的 prompt 会在 trace 之间产生较低的余弦分离度,并使冒烟测试的准确率退化到随机水平。
**跳过前导迭代。** `features/parse.py:trace_from_pcap` 默认会丢弃前两个分组迭代。这些对应于 TLS 握手记录和 HTTP 响应头,它们在所有请求中都是恒定的,并且不携带任何区分信号。
**min_samples_split。** `attack/train.py` 中的 RandomForest 使用了 `min_samples_split=2`,而不是论文中的值 10。论文中的值是针对拥有数千个训练样本的数据集进行调优的;在每类训练样本较少的情况下,它阻止了任何树节点的分裂,导致所有预测坍缩为多数类,准确率也退化到随机水平。
## 测试
```
uv run pytest
uv run mypy --strict .
```
## 参考文献
- Carlini, N. & Nasr, M. (2024). Remote Timing Attacks on Efficient Language
Model Inference. [ariv:2410.17175](https://arxiv.org/abs/2410.17175).
- Wei, J., Abdulrazzag, A., Zhang, T., Muursepp, A. & Saileshwar, G. (2025).
When Speculation Spills Secrets: Side Channels via Speculative Decoding in
LLMs. [arXiv:2411.01076](https://arxiv.org/abs/2411.01076).
- McDonald, G. & Bar Or, J. (2025). Whisper Leak: A Side-Channel Attack on
Large Language Models. [arXiv:2511.03675](https://arxiv.org/abs/2511.03675).
标签:凭据扫描, 逆向工具