AdityaBhatt3010/Splunk-Setting-up-a-SOC-Lab
GitHub: AdityaBhatt3010/Splunk-Setting-up-a-SOC-Lab
一份面向蓝队初学者的 Splunk SOC 实验室搭建指南,覆盖从部署 Splunk Enterprise 到配置日志转发与事件调查的完整流程。
Stars: 1 | Forks: 0
# Splunk:搭建 SOC 实验 walkthrough:使用 Splunk 和 Universal Forwarder 构建迷你 SIEM
安全运营中心(SOC)严重依赖集中式日志记录和监控来检测可疑活动、调查事件并维护基础设施的可见性。在这个动手实验中,我们将使用 Splunk 构建一个小型的 SOC 风格环境,配置日志转发,摄取 Linux 和 Apache Web 日志,并执行一些基本调查。
本房间较少关注攻击模拟,而更多关注蓝队基础工程——建立分析师每天依赖的遥测管道。
实验:[TryHackMe Splunk 实验](https://tryhackme.com/room/splunklab?utm_source=chatgpt.com)
# 任务 1:简介
该场景围绕 Coffely 展开,这是一家最近遭遇了涉及机密配方被盗的内部数据泄露事件的咖啡企业。在解决该事件后,下一步合乎逻辑的举措是增强检测能力。
与其等待事件发生,不如建立一个内部监控设置,能够从不同系统收集日志,并使其可从单一位置进行搜索,这正是我们此处的目标。
到本实验结束时,我们将:
* 在 Linux 上安装 Splunk Enterprise
* 安装并配置 Splunk Universal Forwarder
* 摄取 Linux 系统日志
* 转发 Apache Web 日志
* 配置索引和接收端口
* 使用 Splunk 搜索处理语言(SPL)执行简单调查
这本质上是一项适合初学者的 SOC 工程练习。
# 任务 2:理解 Splunk 部署架构
在部署任何东西之前,了解 Splunk 组件如何交互非常重要。
典型的 Splunk 架构由多个活动部分组成。
## Forwarders
Forwarders 是安装在端点或服务器上的轻量级代理,用于收集日志并将其发送到 Splunk。
可以将它们视为遥测数据传送器。
常见的有两种类型:
* Universal Forwarder → 轻量级,转发原始数据
* Heavy Forwarder → 可以在转发之前解析/过滤数据
在我们的实验中,我们将使用 Universal Forwarder。
## Indexer
Indexer 是处理和存储传入日志的地方。
其职责包括:
* 接收传入数据
* 解析日志
* 转换事件
* 将它们存储在可搜索的索引中
这实际上是 Splunk 的存储 + 摄取引擎。
问题:
在 Splunk 部署架构中,哪一部分负责处理来自 forwarders 的传入数据?
答案:
```
Indexer
```
## Search Head
这是分析师实际交互的组件。
Search Head 允许:
* 运行 SPL 查询
* 构建仪表板
* 调查事件
* 创建警报/报告
在本实验中,Search Head 和 Indexer 位于同一台机器上。
在企业环境中,这些角色通常是分离的。
## Deployment Server
手动管理一个 forwarder 很容易。
管理数百个呢?就不那么有趣了。
这就是 Deployment Server 的用武之地。
它集中管理:
* forwarder 配置
* 更新
* 输入
* 输出
问题:
哪个 Splunk 功能有助于远程管理数百台员工工作站?
答案:
```
Deployment Server
```
# 任务 3:Linux 部署 — 安装 Splunk Enterprise
现在是实际部署环节。
我们将在 Linux 主机上安装 Splunk Enterprise 并启动其 Web 界面。
安装程序已提前放置在实验环境中,无需手动下载。
## 步骤 1:进入安装程序目录
进入提供的 Splunk 包所在位置:
```
cd ~/Downloads/splunk
```
检查可用文件:
```
ls
```
预期输出:
```
splunk_installer.tgz
splunkforwarder.tgz
```
这确认了以下两项:
* Splunk Enterprise 安装程序
* Universal Forwarder 安装程序
均已就绪。
## 步骤 2:切换为 Root 用户
Splunk 安装在 `/opt` 目录下,这需要提升的权限。
```
sudo su
```
为什么?
因为 `/opt` 通常用于 Linux 上的可选或第三方软件安装。
## 步骤 3:解压 Splunk Enterprise
运行:
```
tar xvzf splunk_installer.tgz -C /opt
```
### 此命令的作用
分解此命令:
* `tar` → 归档实用工具
* `x` → 解压
* `v` → 详细输出
* `z` → gzip 压缩的归档文件
* `f` → 目标文件
* `-C /opt` → 直接解压到 `/opt`
这会将 Splunk 二进制文件安装到:
```
/opt/splunk
```
问题:
Splunk 通常应该安装在哪个 Linux 目录中?
答案:
```
/opt
```
## 步骤 4:启动 Splunk
进入二进制文件目录:
```
cd /opt/splunk/bin
```
启动 Splunk:
```
./splunk start --accept-license
```
### 为什么加 `--accept-license`?
因为这是首次启动。
如果不明确接受许可,启动将无法继续。
Splunk 将提示设置管理员凭据。
示例:
```
Username: admin
Password: ********
```
选择一个你自己的安全密码。
## 步骤 5:访问 Web UI
启动完成后,Splunk 在此处公开其接口:
```
http://coffely:8000
```
在虚拟机内打开浏览器。
使用刚才创建的凭据登录。
问题:
Splunk Web 默认运行在哪个端口?
答案:
```
8000
```
# 任务 4:通过 CLI 管理 Splunk
SOC 工程师通常通过终端管理 Splunk,而不是仅仅依赖 GUI。
了解 CLI 基础知识可以节省时间。
所有命令均运行自:
```
/opt/splunk/bin
```
## 启动 Splunk
```
./splunk start
```
启动所有必需的 Splunk 服务。
如果已经在运行,这不会产生任何影响。
## 停止 Splunk
```
./splunk stop
```
正常关闭实例。
在维护期间非常有用。
## 重启 Splunk
```
./splunk restart
```
在配置更改后使用此命令。
等效思维模式:
*"更改了配置 → 重启服务"*
## 检查状态
```
./splunk status
```
示例:
```
splunkd is running
```
这确认了服务状态。
## 单次日志摄取
您可以手动摄取单个文件:
```
./splunk add oneshot /path/to/logfile -index yourindex
```
适用于:
* 快速测试
* 导入单个取证工件
* 验证解析行为
与监控不同,这**不会**持续监视文件。
## 通过 CLI 搜索
搜索单个词:
```
./splunk search coffely
```
这将查询包含以下内容的已索引事件:
```
coffely
```
当您希望在不打开 GUI 的情况下进行快速验证时非常方便。
问题:
在 Splunk 中搜索词组 `coffely`。
答案:
```
./splunk search coffely
```
## CLI 帮助
需要语法帮助?
```
./splunk help
```
针对特定命令:
```
./splunk help search
```
这提供了特定命令的用法详情。
问题:
哪个命令可以获取 Splunk 搜索的帮助信息?
答案:
```
./splunk help search
```
## 为什么这很重要
GUI 工作流很舒适。
CLI 工作流更快。
在真实环境中,特别是在事件响应期间,终端熟练度至关重要。
# 任务 5:安装 Splunk Universal Forwarder
到目前为止,我们已经部署了 Splunk 服务器本身。
现在我们需要一种机制,将日志从端点实际传送到该服务器。
这就是 Splunk Universal Forwarder 的用武之地。
把它想象成一个轻量级的日志快递员——它监视选定的文件/事件并将它们转发给 Indexer。
在生产环境中,这通常运行在独立的端点上。
为简化实验,Splunk Enterprise 和 Forwarder 运行在同一台机器上。
## 步骤 1:返回安装程序目录
返回:
```
cd ~/Downloads/splunk
```
检查可用文件:
```
ls
```
预期:
```
splunk_installer.tgz
splunkforwarder.tgz
```
我们现在关心的文件:
```
splunkforwarder.tgz
```
## 步骤 2:解压 Universal Forwarder
以 root 身份运行:
```
tar xvzf splunkforwarder.tgz -C /opt
```
这会将 Forwarder 解压到:
```
/opt/splunkforwarder
```
与之前的逻辑相同:
* `x` → 解压
* `v` → 详细输出
* `z` → gzip 归档文件
* `f` → 文件
* `-C /opt` → 目标路径
## 步骤 3:启动 Forwarder
进入其二进制文件目录:
```
cd /opt/splunkforwarder/bin
```
启动:
```
./splunk start --accept-license
```
问题:
使用的完整命令是?
答案:
```
./splunk start --accept-license
```
## 端口冲突解释
在首次启动时,您会遇到一些有趣的情况。
Splunk Enterprise 已使用:
```
8089
```
该端口处理 Splunk 管理流量(`splunkd`)。
但 Universal Forwarder 也希望使用相同的默认管理端口。
结果?
冲突。
示例:
```
ERROR: mgmt port [8089] - port is already bound
```
Splunk 会询问:
```
Would you like to change ports? [y/n]
```
选择:
```
y
```
然后输入:
```
8090
```
为什么这样做可行:
* Splunk Enterprise → 8089
* Universal Forwarder → 8090
没有重叠。
问题:
Forwarder 的默认管理端口是?
答案:
```
8089
```
# 任务 6:配置 Forwarder 和摄取 Linux 日志
Forwarder 安装完毕 ≠ 可用。
目前它正在运行,但没有转发任何内容。
我们需要:
* 在 Splunk 中配置接收
* 创建目标索引
* 告诉 Forwarder 将日志发送到哪里
* 指定要监控的日志
这就是遥测管道真正构建起来的地方。
# 步骤 1:在 Splunk 中启用接收
在 Web UI 中:
前往:
```
Settings → Forwarding and receiving
```
点击:
```
Receive data → Add new
```
设置端口:
```
9997
```
为什么?
这是 Splunk 用于接收转发数据的标准端口。
意思是:
Forwarder → 发送日志 → Splunk 在此处监听
保存它。
# 步骤 2:创建专用索引
现在为 Linux 日志创建存储。
前往:
```
Settings → Indexes
```
点击:
```
New Index
```
名称:
```
linux_host
```
保持默认设置。
为什么要创建自定义索引?
因为将所有内容存储在:
```
main
```
很快就会变得混乱。
隔离的索引可改善:
* 组织性
* 保留管理
* 搜索效率
* 调查过程
# 步骤 3:添加转发服务器
现在告诉 Forwarder 将事件发送到哪里。
从终端执行:
```
./splunk add forward-server 10.48.147.244:9997
```
您将被提示输入凭据。
这意味着:
* `10.48.147.244` → Splunk 服务器 IP
* `9997` → 接收端口
* Forwarder 现在知道目的地了
这就建立了管道。
# 步骤 4:检查 Linux 日志
大多数 Linux 日志位于:
```
/var/log
```
检查:
```
ls /var/log
```
您将看到如下文件:
```
auth.log
syslog
kern.log
apache2/
```
每个文件对不同的调查都有用。
示例:
* `auth.log` → 身份验证事件
* `syslog` → 一般系统活动
* `kern.log` → 内核事件
* Apache 日志 → Web 流量
# 步骤 5:监控 syslog
告诉 Forwarder 持续监视 syslog:
```
./splunk add monitor /var/log/syslog -index linux_host
```
意思是:
* 监控此文件
* 摄取每一新行
* 发送到 `linux_host`
与单次摄取不同,这是持续性的。
# 步骤 6:验证配置
检查生成的配置:
```
cat /opt/splunkforwarder/etc/apps/search/local/inputs.conf
```
预期:
```
[monitor:///var/log/syslog]
disabled = false
index = linux_host
```
解读:
* 监控已激活
* syslog 被监视
* 目标索引已定义
# 步骤 7:生成测试事件
Linux 提供:
```
logger
```
一个写入 syslog 的简单实用工具。
生成测试事件:
```
logger "coffely-has-the-best-coffee-in-town"
```
检查本地日志:
```
tail -1 /var/log/syslog
```
预期:
```
coffely-has-the-best-coffee-in-town
```
这确认了事件生成。
# 步骤 8:在 Splunk 中搜索
查询:
```
index=linux_host "coffely-has-the-best-coffee-in-town"
```
如果事件出现:
管道工作正常 ✅
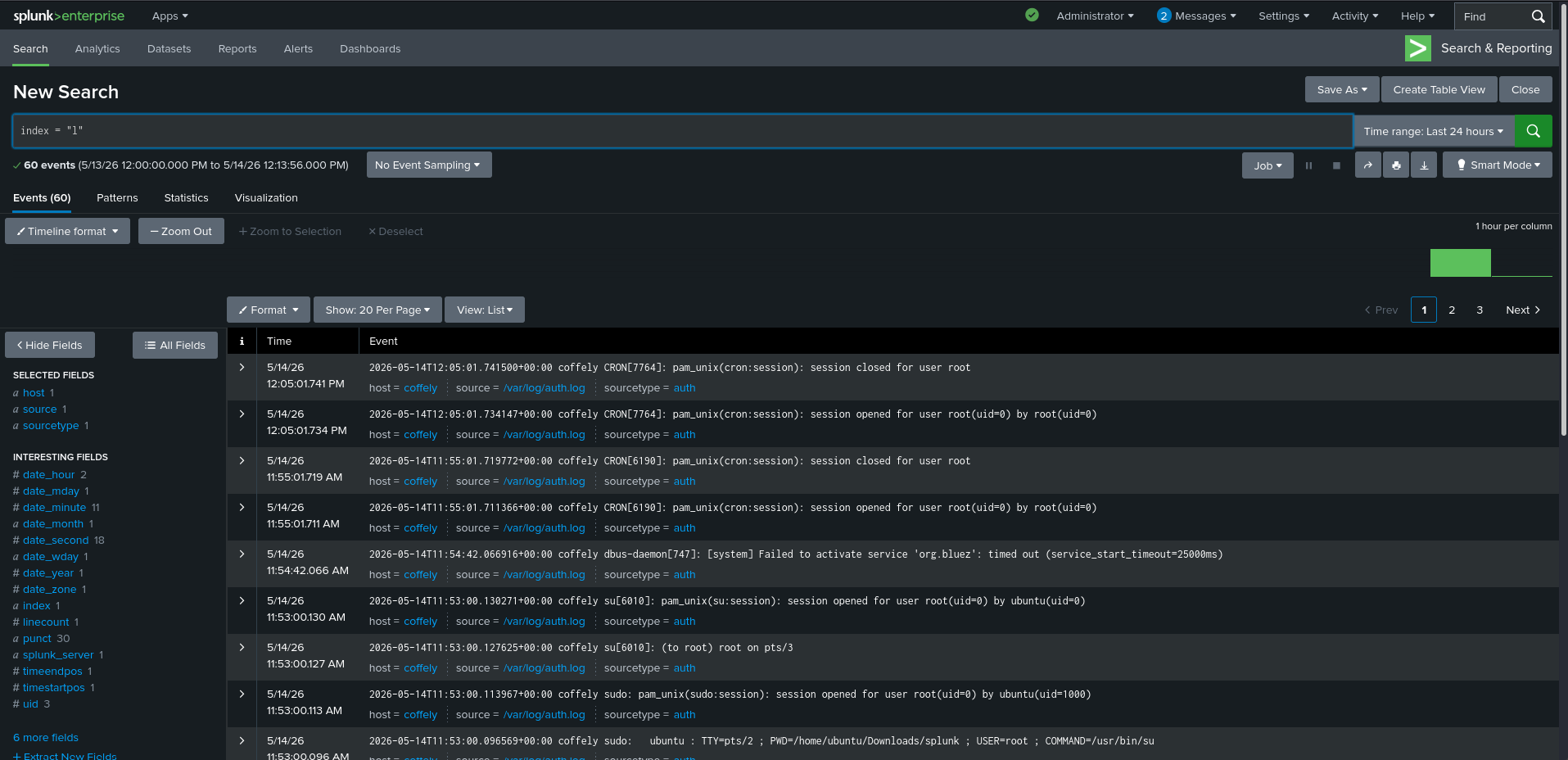
## 实践练习 1 — auth.log 摄取
现在,不要使用 syslog,而是摄取:
```
/var/log/auth.log
```
命令:
```
./splunk add monitor /var/log/auth.log -index linux_host
```
这会捕获与身份验证相关的事件。
示例:
* SSH 登录
* 失败的身份验证
* sudo 使用情况
* 账户更改
问题:
`sourcetype` 字段的值是?
答案:
```
auth
```
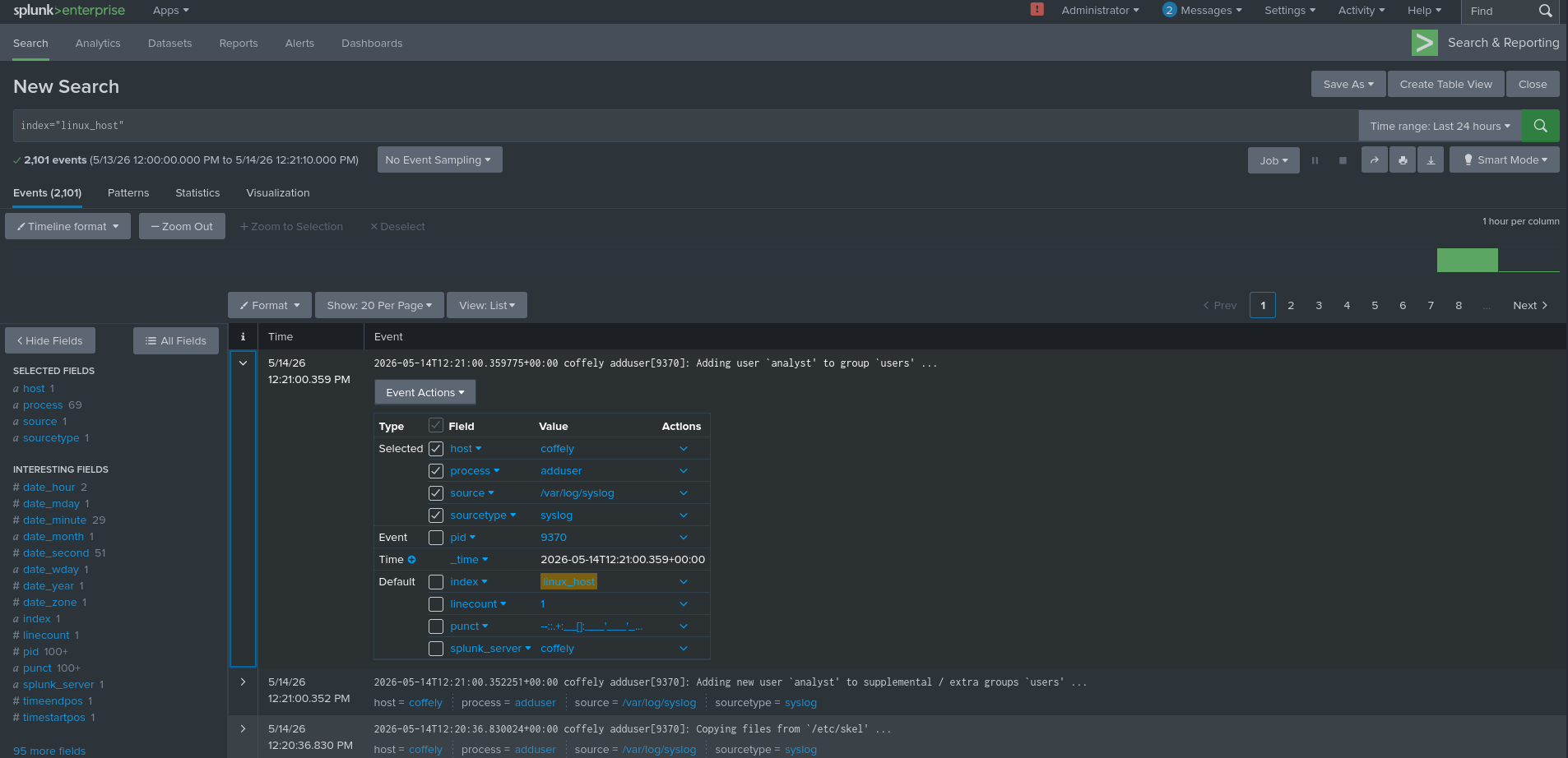
## 实践练习 2 — 用户创建事件
创建一个测试用户:
```
adduser analyst
```
为什么?
创建用户会生成身份验证/系统事件。
非常适合验证摄取。
现在在 Splunk 中搜索相关事件。
查看提取的字段。
如果 `process` 不可见:
```
More Fields
```
手动添加它。
问题:
`process` 字段的值是?
答案:
```
adduser
```
## 为什么这很重要
这是真实的 SOC 工程工作流。
遥测接入通常遵循以下步骤:
1. 识别日志源
2. 配置摄取
3. 规范化数据
4. 验证可见性
5. 构建检测
没有遥测,检测工程就是盲目的。
# 任务 7:Windows 转发(概念演练)
到目前为止,我们已经接入了 Linux 遥测数据。
但真实的 SOC 环境很少只监控 Linux。
典型的环境包括:
* Windows 工作站
* 域控制器
* Web 服务器
* 防火墙
* VPN 设备
* 云遥测
集中式日志聚合变得至关重要,因为孤立的日志只能讲述部分情况,而关联的日志能揭示完整事件。
由于本实验只提供一个 Linux 虚拟机,Windows 部分仅为概念演练——但其工作流程与生产环境设置一致。
## 使用 Universal Forwarder 控 Windows 日志
在 Windows 机器上,Universal Forwarder 的安装方式类似。
然后在 PowerShell 中运行:
```
cd "C:\Program Files\SplunkUniversalForwarder\bin"
```
添加 Windows 安全日志:
```
.\splunk.exe add monitor C:\Windows\System32\winevt\Logs\Security.evtx
```
### 这会做什么
这会告诉 Splunk Forwarder 监视:
```
Security.evtx
```
其中包含关键的 Windows 安全遥测数据,如:
* 登录事件
* 失败的登录
* 权限提升
* 账户创建
* 审核策略更改
对于防御者来说,这是无价之宝。
## 用于集中管理的 Deployment Server
手动管理少量 Forwarder?
还好。
管理 500 个端点?
非常痛苦。
Splunk 通过 Deployment Server 解决了这个问题。
启用它:
```
./splunk enable deploy-server
```
然后重启:
```
./splunk restart
```
这会将您的 Splunk 实例转变为集中配置管理器。
问题:
启用 Deployment Server 的 Linux 命令是?
答案:
```
./splunk enable deploy-server
```
## 为什么 Deployment Server 很重要
无需手动接触每台机器,您可以推送:
* 监控配置
* 应用部署
* 输入定义
* 输出设置
将其视为 Splunk 基础设施的配置管理。
# 任务 8:摄取 Apache Web 日志
现在我们进入 SOC 最有用的数据源之一:
**Web 服务器日志。**
Coffely 应用程序通过 Apache 在本地托管。
可通过以下地址访问:
```
http://coffely.thm:8080
```
Web 日志帮助分析师调查:
* 可疑请求
* 暴力破解尝试
* 路径枚举
* 漏洞利用尝试
* 用户活动
* 文件访问模式
## 步骤 1:定位 Apache 日志
Apache 访问日志位于:
```
/var/log/apache2/access.log
```
此文件记录传入的 HTTP 请求。
典型字段包括:
* 客户端 IP
* 请求方法
* URI
* 响应码
* 用户代理
* 时间戳
完美的 SOC 遥测数据。
## 步骤 2:通过 Splunk UI 添加数据
在 Splunk 中:
```
Settings → Add Data
```
选择:
```
Monitor
```
然后:
```
Files & Directories
```
路径:
```
/var/log/apache2/access.log
```
选择:
```
Continuously Monitor
```
为什么选择持续监控?
因为 Web 流量不断变化。
单次摄取只能捕获现有条目。
持续监控可提供实时遥测。
## 步骤 3:配置源类型
这非常重要。
选择:
```
Web → access_combined
```
问题:
正确的 sourcetype 是?
答案:
```
access_combined
```
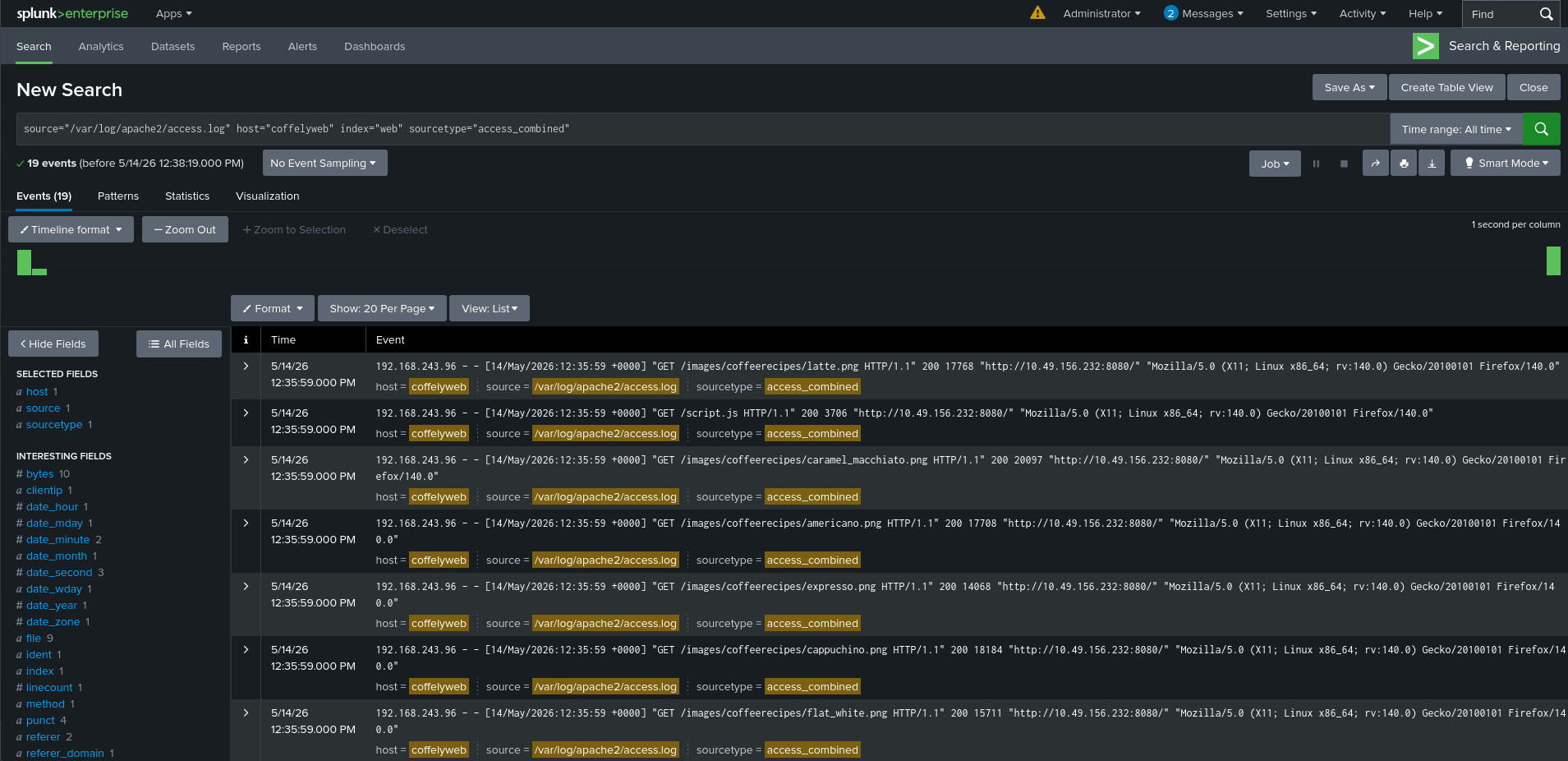
## 为什么选 `access_combined`?
Splunk 使用 sourcetypes 进行解析。
如果解析错误:
字段提取就会中断。
Apache 组合日志包含结构化的 HTTP 元数据,因此该 sourcetype 确保了诸如以下字段:
* method
* uri
* status
* bytes
* referer
* useragent
可被自动提取。
没有正确的解析,调查将变得极其痛苦。
## 步骤 4:配置主机和索引
设置主机值:
```
coffelyweb
```
创建索引:
```
web
```
为什么要分离索引?
因为 Web 遥测数据不同于 OS 遥测数据。
保持数据分段可改善:
* 更清晰的搜索
* 保留控制
* 性能
* 警报范围
## 步骤 5:生成流量
最初,日志可能比较安静。
访问:
```
http://coffely.thm:8080
```
四处浏览。
每个请求都会生成日志条目。
示例:
* 主页加载
* 图片获取
* 页面导航
* 资产检索
这会创建可搜索的事件。
# Web 调查问题
## 问题 1 — 最高的 `root` 字段计数
搜索 Web 索引:
```
index=web
```
然后检查提取的字段。
查看:
```
root
```
这代表顶级请求分组。
计数最高的是:
```
images
```
答案:
```
images
```
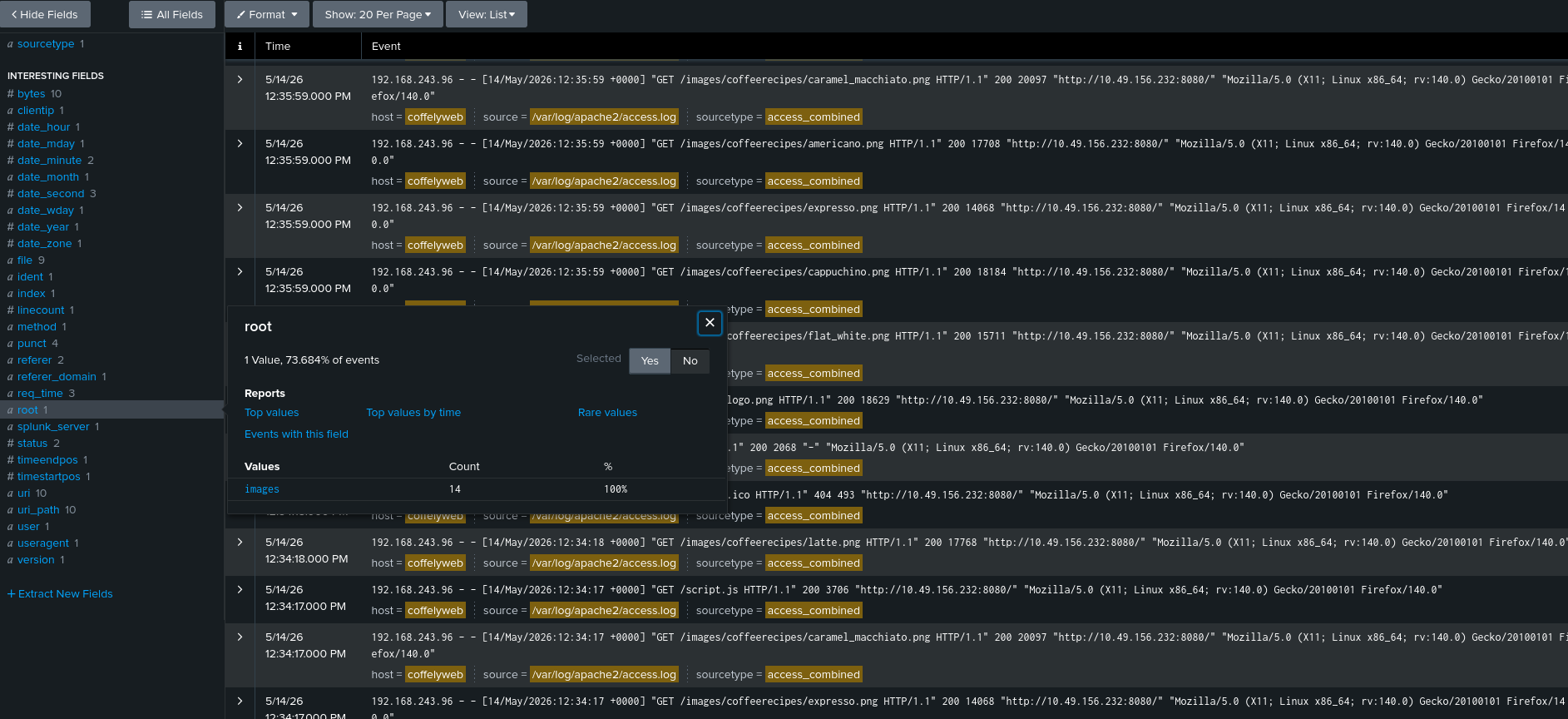
## 为什么是 `images`?
网页请求的不只是 HTML。
它们还会获取:
* PNGs
* CSS
* JS
* 图标
因此,图像较多的页面通常会生成许多资产请求。
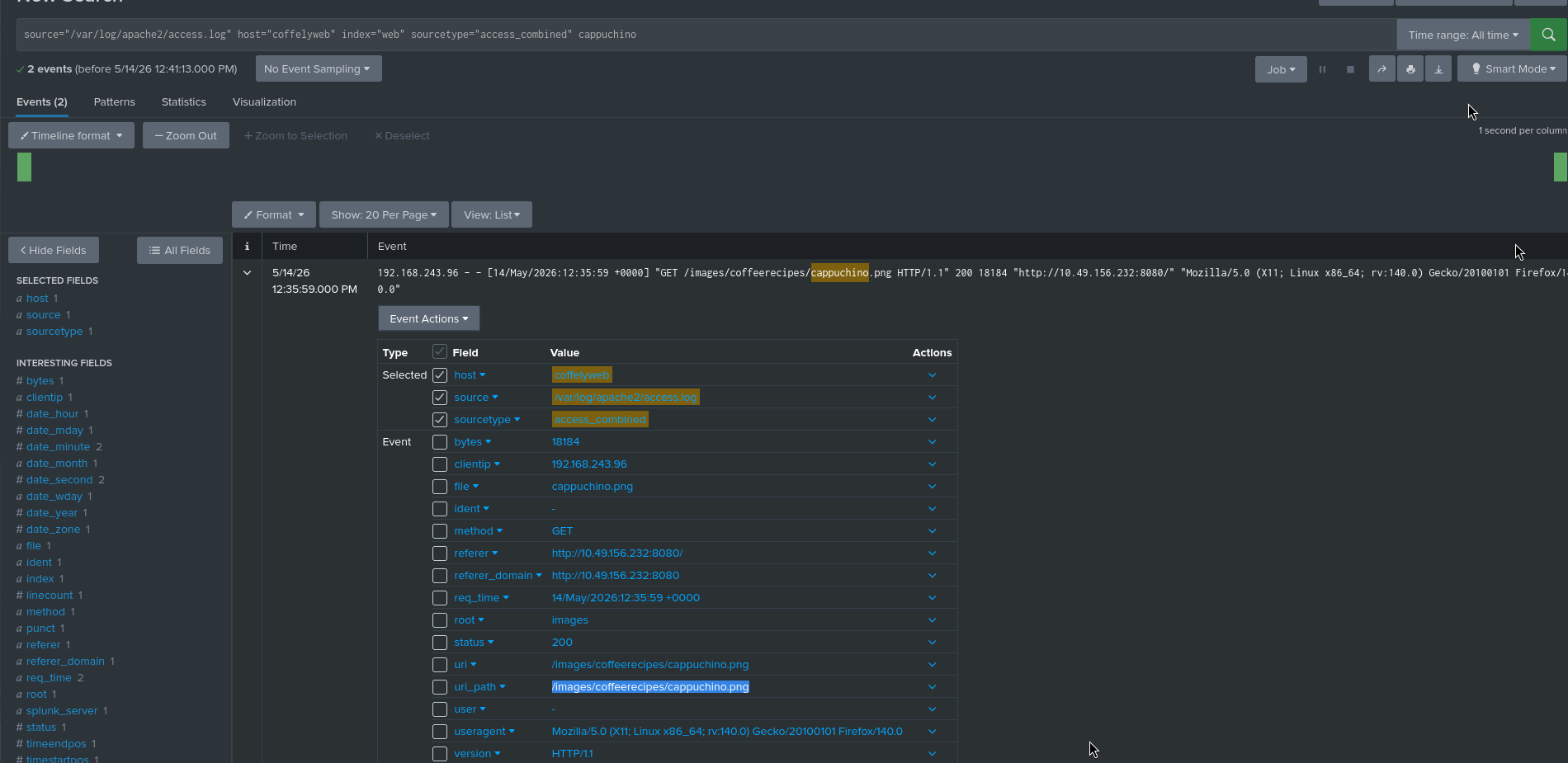
## 问题 2 — cappuchino 图片的完整 `uri_path`
搜索:
```
index=web cappuchino
```
检查:
```
uri_path
```
答案:
```
/images/coffeerecipes/cappuchino.png
```
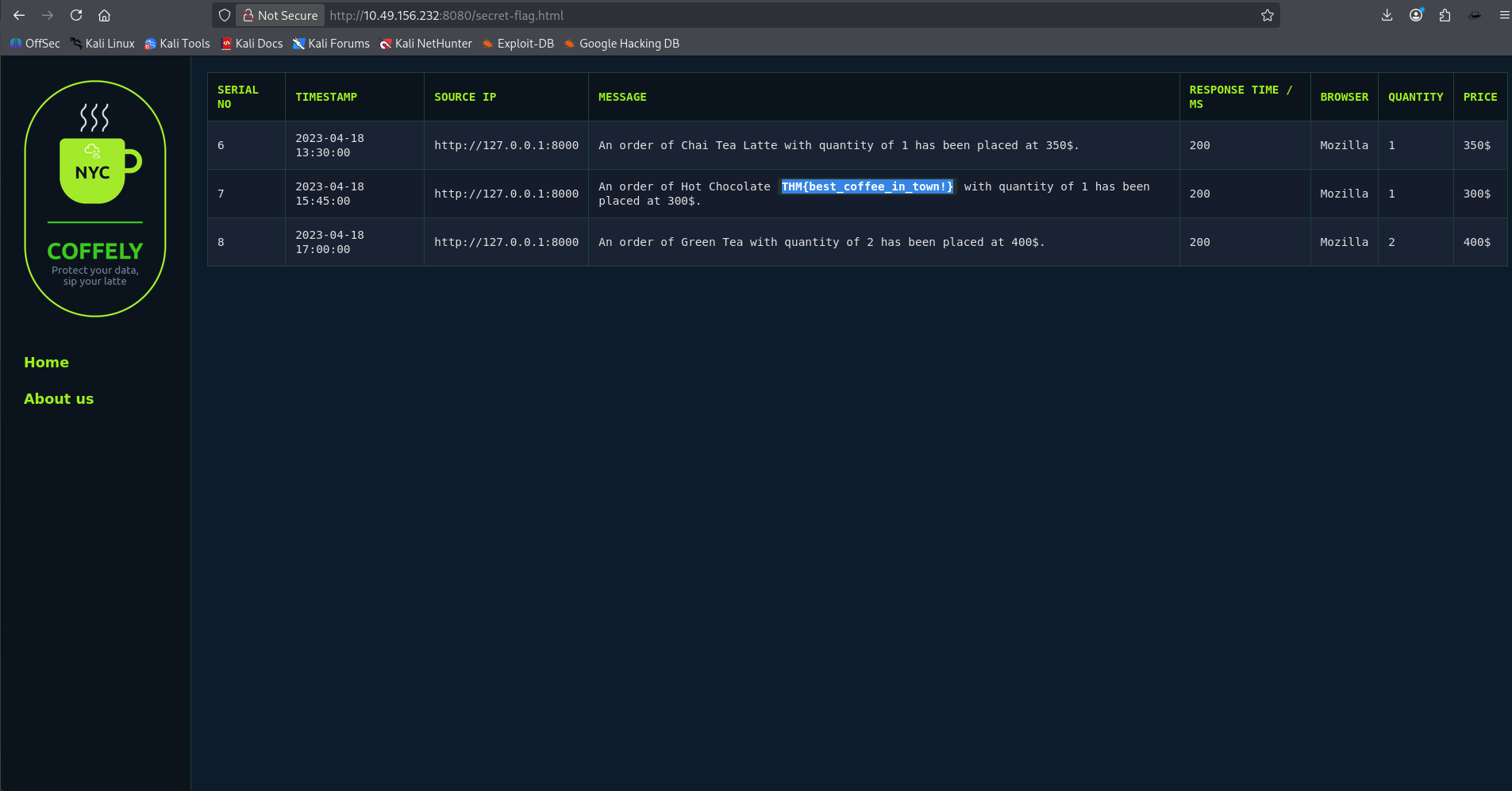
## 问题 3 — 秘密 Flag
访问:
```
http://coffely.thm:8080/secret-flag.html
```
查看最近的订单。
Flag:
```
THM{best_coffee_in_town!}
```
# 为什么 Web 日志在真实调查中很重要
Apache/Nginx 日志有助于检测:
### 侦察
反复请求:
```
/admin
/login
/phpmyadmin
/.git
```
通常是扫描行为。
### 漏洞利用尝试
URL 中的载荷:
```
?id=' OR 1=1--
```
或
```
../../etc/passwd
```
指标:
* SQLi
* 路径遍历
* LFI
### 暴力破解活动
来自同一 IP 的重复身份验证尝试:
```
POST /login
```
### Webshell 访问
奇怪的请求:
```
/uploads/shell.php?cmd=whoami
```
巨大的危险信号。
# 任务 9:结论
本实验通过实际的 Splunk 部署涵盖了基础的 SOC 工程概念。
我们:
✅ 安装了 Splunk Enterprise
✅ 通过 CLI 管理 Splunk
✅ 安装了 Universal Forwarder
✅ 配置了日志转发
✅ 创建了索引
✅ 摄取了 Linux 遥测数据
✅ 摄取了 Apache Web 日志
✅ 使用 SPL 调查了事件
✅ 探索了 Deployment Server 概念
# 最终想法 对于初入蓝队、SOC 分析或 SIEM 工程的初学者来说,这个房间非常棒。 最重要的收获是: **检测依赖于遥测。** 没有日志 → 没有可见性。 没有可见性 → 没有检测。 没有检测 → 攻击者保持隐身。 至此,本次实验结束 ☕🔍
✅ 通过 CLI 管理 Splunk
✅ 安装了 Universal Forwarder
✅ 配置了日志转发
✅ 创建了索引
✅ 摄取了 Linux 遥测数据
✅ 摄取了 Apache Web 日志
✅ 使用 SPL 调查了事件
✅ 探索了 Deployment Server 概念
# 最终想法 对于初入蓝队、SOC 分析或 SIEM 工程的初学者来说,这个房间非常棒。 最重要的收获是: **检测依赖于遥测。** 没有日志 → 没有可见性。 没有可见性 → 没有检测。 没有检测 → 攻击者保持隐身。 至此,本次实验结束 ☕🔍
标签:AMSI绕过, Apache日志, Linux日志, SPL, Splunk Enterprise, Splunk Universal Forwarder, Telemetry Pipeline, TryHackMe, Web日志, 代码示例, 初学者教程, 威胁检测, 安全信息与事件管理, 安全实验室, 安全工程, 安全运营, 扫描框架, 搜索引擎爬取, 数据分析, 数据摄取, 日志转发, 日志集中管理, 端口配置, 网络安全, 网络安全审计, 蓝军演练, 隐私保护