nazmiefearmutcu/awareness
GitHub: nazmiefearmutcu/awareness
一个在单台笔记本上运行的轻量级公共网络文本摄取与查询系统,无需 Spark 或云服务即可实现大规模数据回填、实时追踪与去重分析。
Stars: 4 | Forks: 0
# 意识
[](https://github.com/nazmiefearmutcu/awareness/releases)
[](LICENSE)
[](https://github.com/nazmiefearmutcu/awareness/stargazers)
[](https://python.org)
[](https://iceberg.apache.org/)
[](https://duckdb.org/)
**将公共网络(Common Crawl + HuggingFace FineWeb + RSS + GDELT)摄取到你的笔记本电脑上,之后像查询普通数据表一样查询它。** 回填("BODY")任何历史日期范围,并运行一个实时追踪("TAIL"),在你停止它之前,它会持续捕获新发布的公共文本。单一 Python 进程 —— 无需 Spark、无需 Kafka、无需云账户。
仅存储**文本及面向文本的元数据**。不含图片,不含二进制媒体,
不含登录受限内容,不绕过付费墙。遵守 robots.txt 规则;对实时抓取应用
单域名礼貌策略。
## Research Workbench (UI)
Awareness 内置了一个静态 SPA,通过 FastAPI 控制层在 `/` 提供服务。使用 `awareness-api` 启动它(默认端口 `8085`)并打开 `http://127.0.0.1:8085/` —— 无需单独的构建步骤。
#### Dashboard
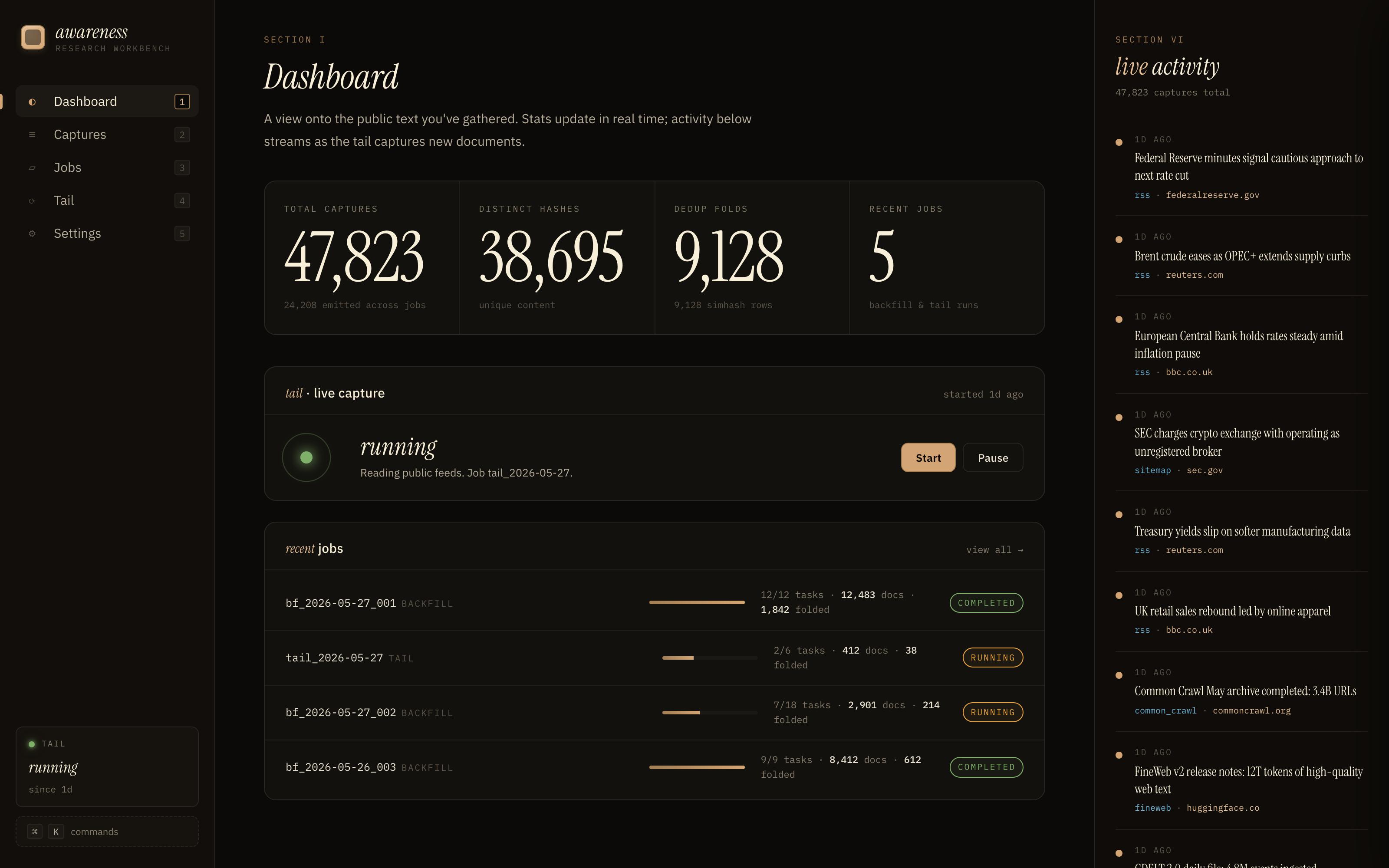
#### Captures
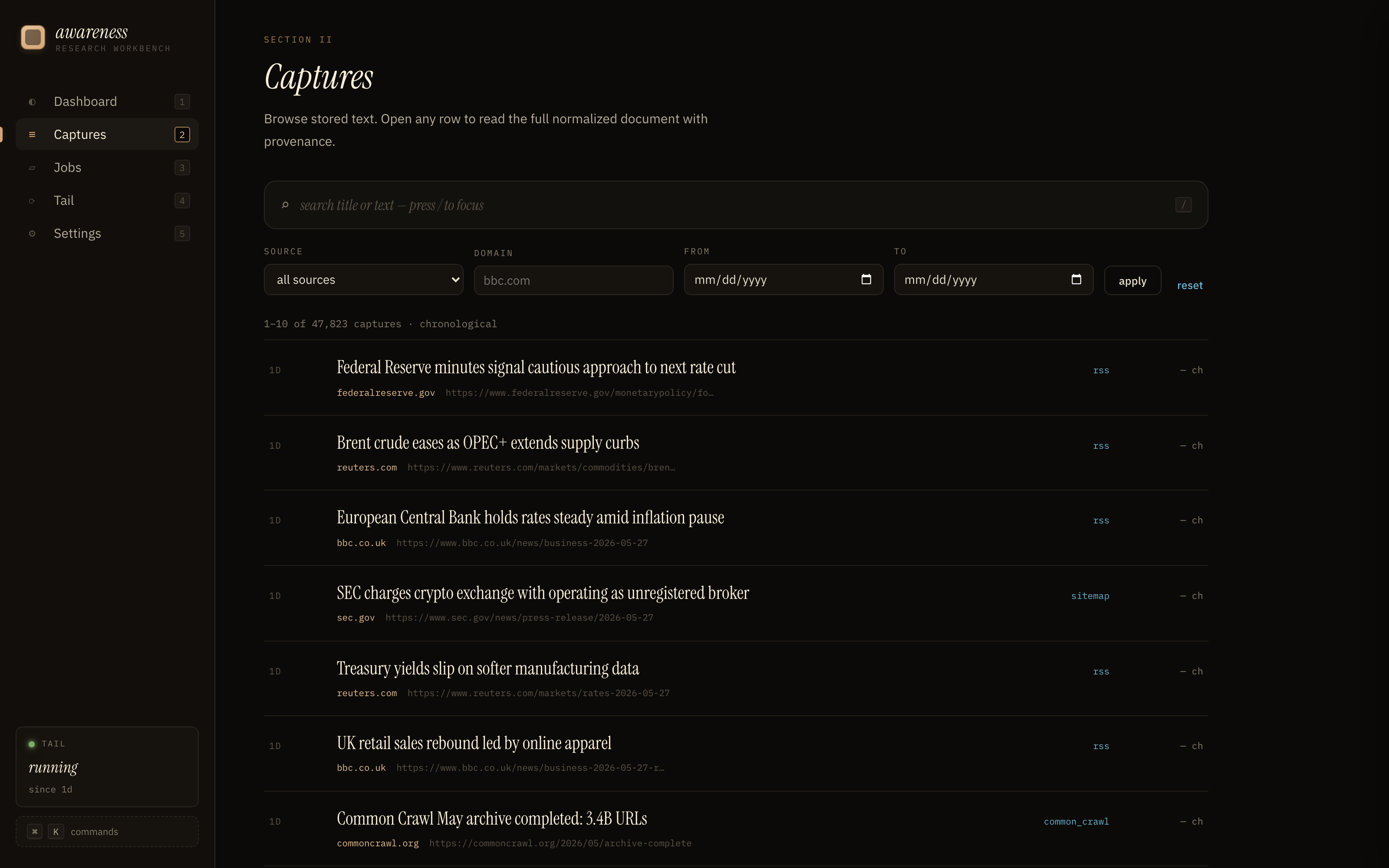
#### Jobs
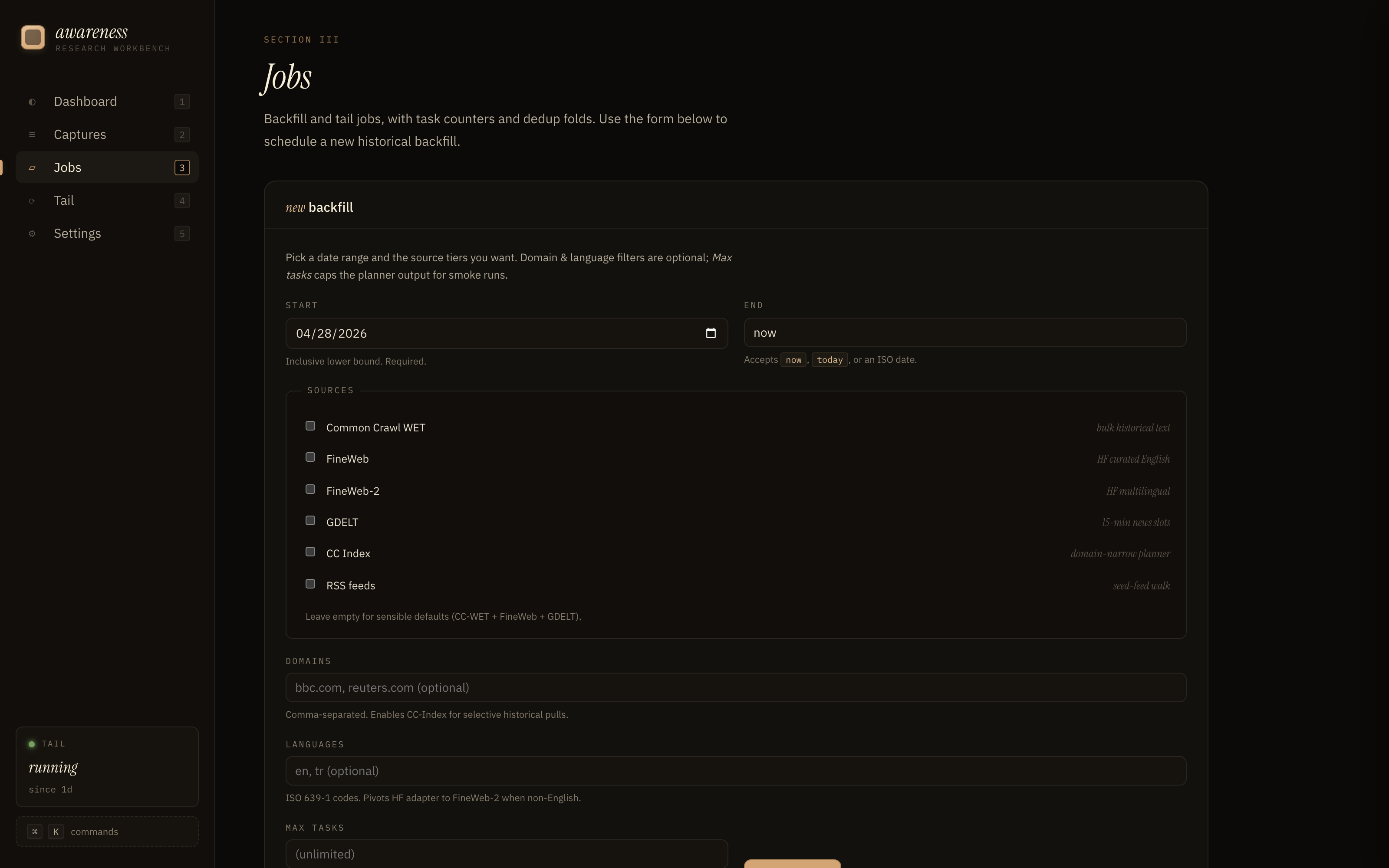
#### Tail (实时捕获)
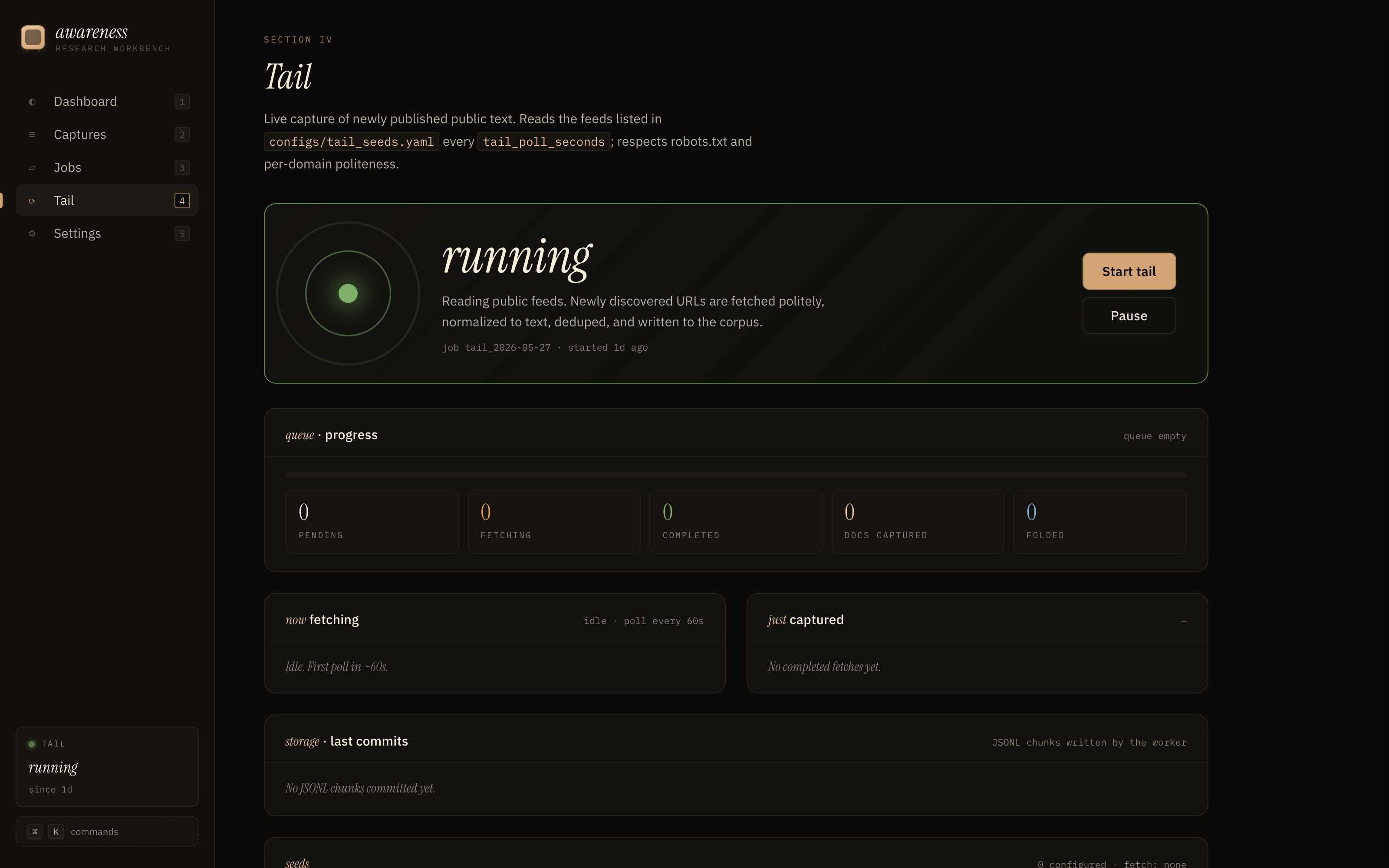
#### Settings
单进程 Python + FastAPI + 位于 `src/awareness/api/web/` 的纯手写原生 SPA。五个部分(Dashboard / Captures / Jobs / Tail / Settings),支持键盘快捷键(`1`–`5`)和 `⌘K` 命令面板。
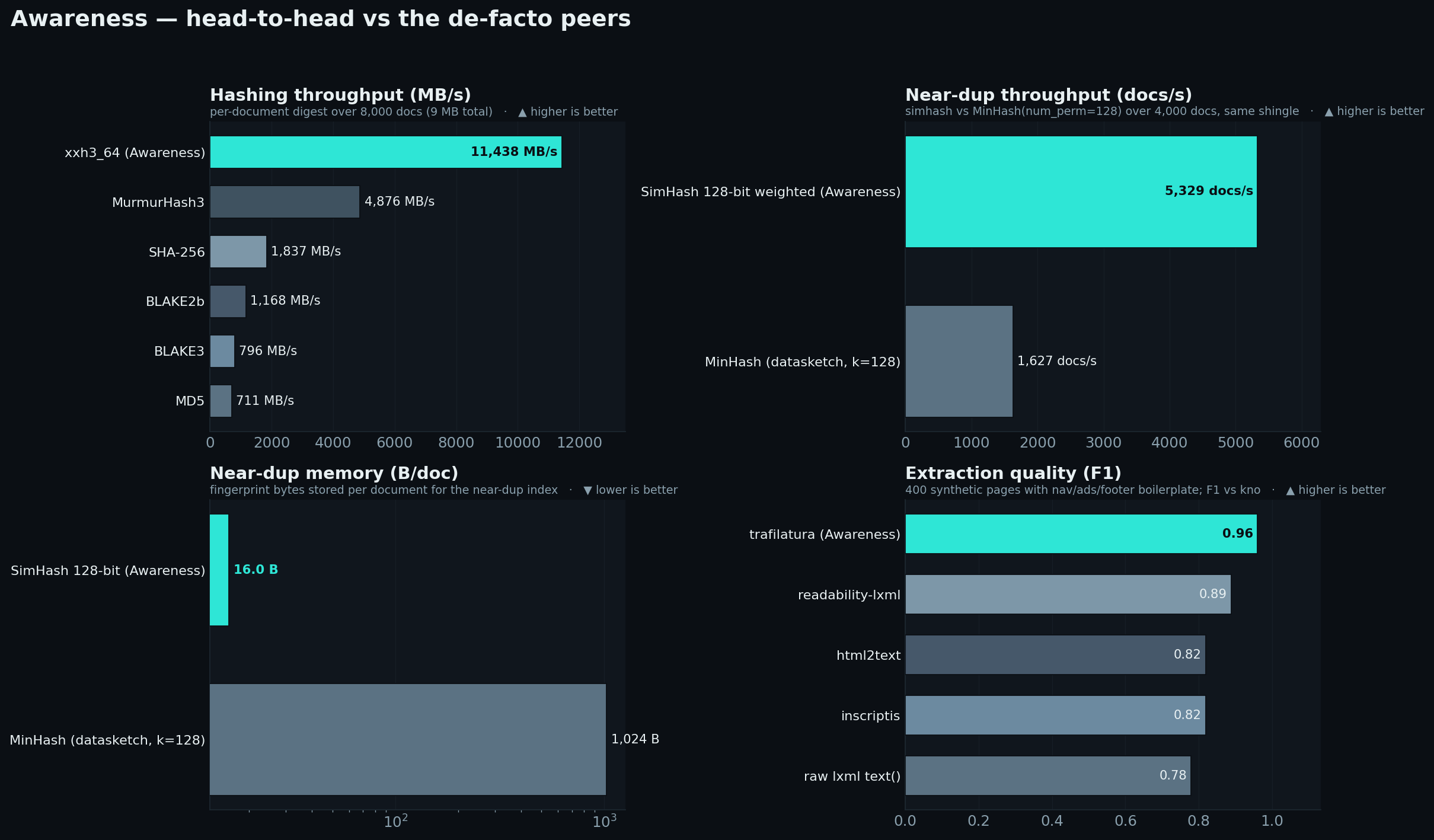
## Benchmarks
Awareness 在同一台机器上,基于**确定性**的合成语料库(固定随机种子 —— 语料库和准确率数值可精确复现;吞吐量随硬件/负载而波动),与各领域**事实上的对标产品进行了正面基准测试**。当结果落后于标准时,我们通过*真实的代码更改*弥补了差距,然后重新测量。这里没有任何为了迎合某个单一数字而进行的手工调优;以下图表来自一次具有代表性的运行(`results.json`)。
```
uv pip install -e '.[bench]'
python -m benchmarks.run_all # writes docs/benchmarks/results.json
python -m benchmarks.plot # renders the charts below
```
以下数值的测试机器:Apple Silicon (arm64),Python 3.11,单核。对标产品:datasketch 1.10, BLAKE3 1.0, trafilatura, DuckDB FTS, SQLite FTS5。
### 近似重复检测 —— 修复了指纹*和*检索
Awareness 使用 **128 位频率加权 Charikar SimHash** + Hamming 距离阈值进行去重,并通过 Manku/Jain 鸽巢原理带状索引进行索引。事实上的对标产品是 `datasketch` **MinHashLSH** (num_perm=128)。我们比较的是**端到端的完整流水线**(检索 + 阈值 + 分组)—— 这与 text-dedup 和 datasketch 报告的方式相同 —— 而非全配对预言机。
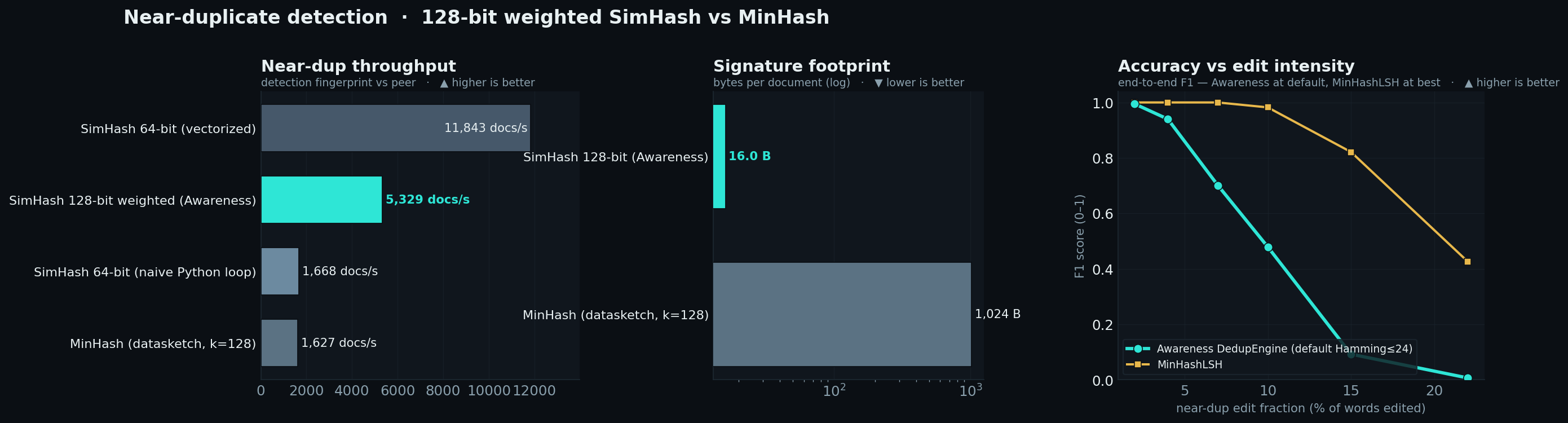
最初的引擎表现极差:一个 64 位 SimHash(可分离性 F1 约 0.86)位于一个在现实的近似去重半径下几乎检索不到任何内容的 8 带索引之后 —— 端到端召回率仅为 **~2%**。三处修改修复了它:**128 位频率加权指纹**(全配对*可分离性* **0.99**,与 MinHash 持平 —— 所以指纹从来都不是问题;
[text-dedup 的 CORE 基准测试](https://github.com/ChenghaoMou/text-dedup) 给出
普通 64 位 SimHash 的得分为 0.85,MinHash 为 0.95),**更精细的 32×4 位分带**(鸽巢精确检索支持 Hamming 距离最高 ≤31,覆盖了默认阈值),以及 **Hamming≤24 的默认**阈值。
| 端到端(完整流水线) | **Awareness DedupEngine** | `datasketch` MinHashLSH |
| --- | --- | --- |
| **F1**(出厂默认 · 调优后) | **0.85 · 0.97** | 0.998 |
| **Precision** | **1.00** — 从不发生错误合并 | 0.999 |
| **Recall**(默认 · 调优后) | 0.74 · 0.95 | 0.997 |
| **Throughput** | **≈5,200 docs/s** (3.3×) | ≈1,600 docs/s |
| **Signature 大小** | **16 B/doc** (小 64 倍) | 1,024 B/doc |
这些数值是**出厂默认值**(`near_threshold=24`);向精度边界(Hamming≤32)提高时,引擎达到了 **F1 0.97 / 召回率 0.95,且精度仍为 1.00** —— 该阈值支持在每次调用时进行调优。MinHashLSH 报告的是其处于 F1 最优状态时的 Jaccard≥0.5(约等于其默认值)。
客观结论:**MinHashLSH 在召回率上胜出** —— 它的 LSH 不需要针对每个语料库进行调优,并且随着编辑量的增加,其性能下降得更为平稳(右图;在出厂默认值下,当词汇编辑比例超过约 ~7% 时,曲线开始产生分化)。这是众所周知的 SimHash 与 MinHash 之间的权衡。Awareness 的 SimHash 是**精度优先、节约资源**的选择:相同的精度,**3.3 倍的吞吐量,低 64 倍的内存消耗**,并且 —— 因为去重仅仅提供分组提示,而永远不会丢弃任何一行数据 —— 较低的召回率只会减少一部分折叠合并操作,永远不会丢失数据。
### 内容指纹提取 —— xxh3 是正确的选择
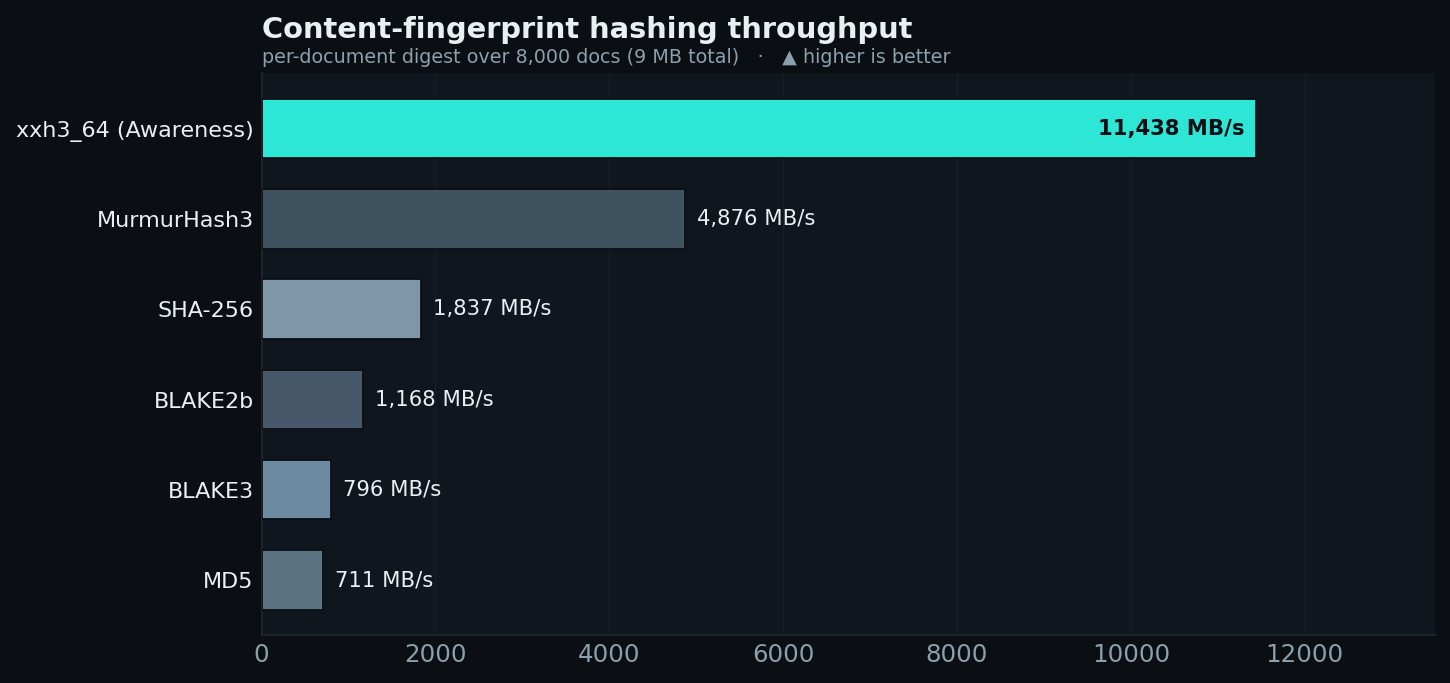
Awareness 使用 `xxhash.xxh3_64` 为每个文档生成指纹以进行精确去重。在逐个文档生成摘要方面,它是测量到的最快选项 —— **≈11 GB/s**,约为 MurmurHash3 的 2.4 倍,SHA-256 的 6 倍,以及 BLAKE3/MD5 的 14–16 倍 —— 因此精确去重永远不会成为瓶颈。(BLAKE3 的 SIMD 优势体现在大型连续缓冲区上,而不是 Awareness 实际进行哈希处理的许多小输入上。)
### HTML → 正文提取 —— 搭乘 F1 领跑者
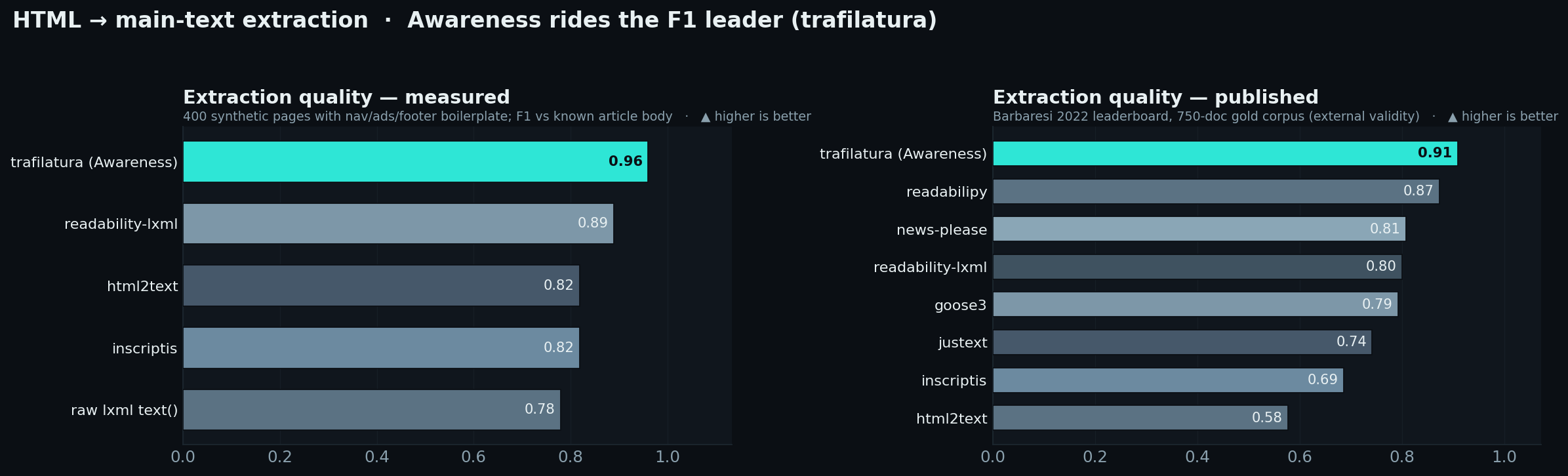
Awareness 使用 **trafilatura** 提取文章文本,该方法在我们测量的样板拒绝测试(**F1 0.96**)和已发布的
[Barbaresi 2022 排行榜](https://trafilatura.readthedocs.io/en/latest/evaluation.html)
(**F1 0.909**,领先于 readabilipy, news-please, readability-lxml, goose3, jusText, inscriptis, html2text)上均名列前茅。诚实说明:这种质量是以牺牲速度为代价的 —— trafilatura 是测量到的*最慢*提取器(约 370 页/秒,而原始标签剥离约为 50k 页/秒);Awareness 刻意花费这些时间将样板内容排除在持久化语料库之外。
### 查询与摄取 —— 为此基准测试发布的优化
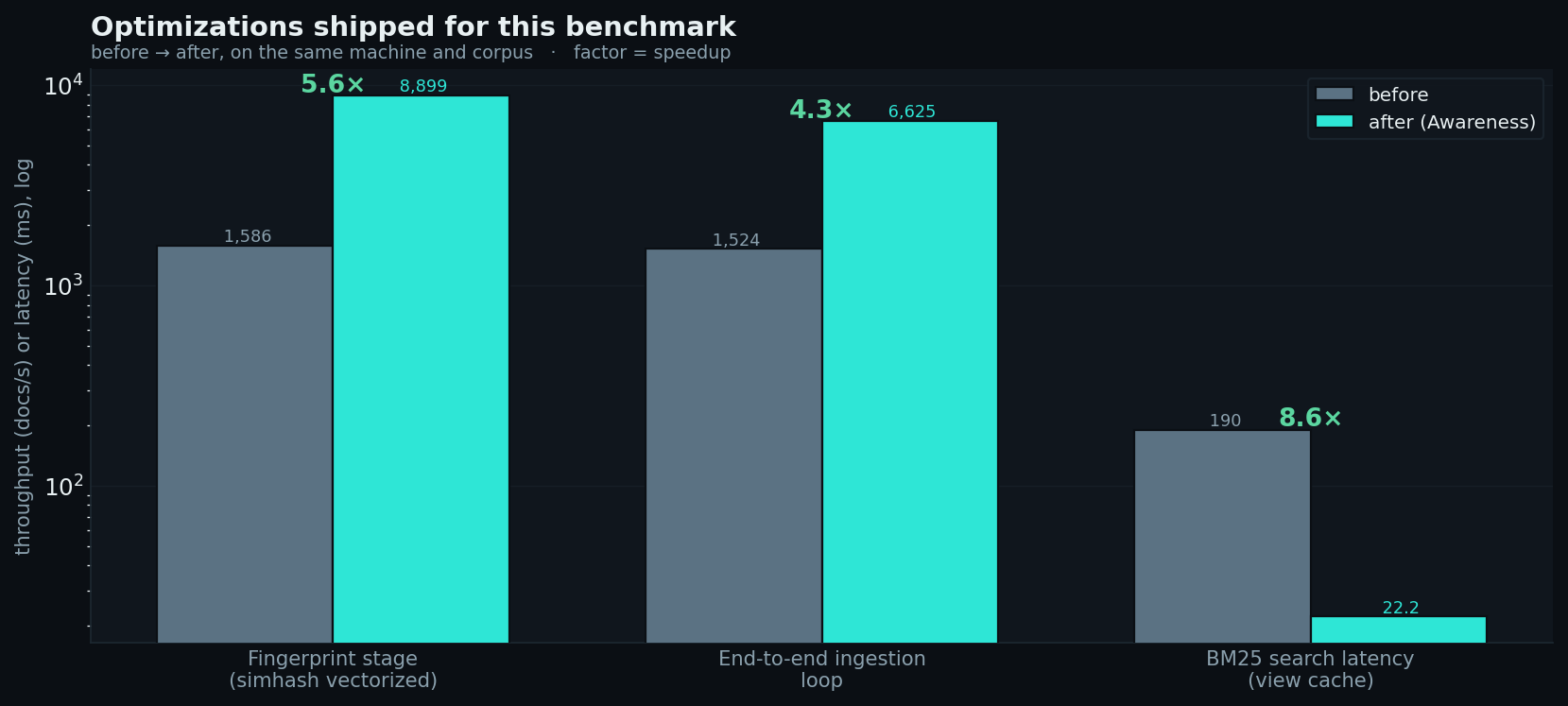
在进行基准测试期间完成的三项具体改进(同一台机器,同一个语料库):
- **SimHash 向量化** —— 将基于每 shingle 的 64 位累加器循环替换为 NumPy 位矩阵;指纹提取阶段速度提升了 **≈5–6 倍**
(并且在 64 位路径上位级完全相同)。
- **端到端摄取循环**(标准化 → 指纹提取 → JSONL 写入)作为结果
速度提升了 **≈4 倍**。
- **BM25 搜索延迟** 降低了 **≈8–9 倍**(≈200 毫秒 → ≈24 毫秒),这是在 DuckDB
索引停止在*每次*查询时重建其视图,转而仅在磁盘上的语料库发生更改时刷新之后实现的。
关于搜索的诚实说明:专用的倒排索引(SQLite FTS5)响应未排名查找的速度要*快得多*(此处为亚毫秒级,而相比之下约为 24 毫秒)—— Awareness 选择 DuckDB 是为了让*同一个* SQL 引擎在一个数据湖中提供 BM25 搜索、范围扫描和 Iceberg 分析服务,而不是因为它是纯粹最快的 FTS 引擎。
完整的方法论和原始数据位于 [`benchmarks/`](benchmarks/) 和
[`docs/benchmarks/results.json`](docs/benchmarks/results.json) 中。
## 架构
```
flowchart TD
user(["user / CLI"]) -->|plan request| planner[Planner]
planner -->|partitions| state[(Tasks
state DB)] state --> worker[Worker Engine
asyncio] worker -->|async runs partition| adapters subgraph adapters[Source Adapters] cc[Common Crawl
WET / CDX / WARC] fw[HuggingFace
FineWeb / FineWeb2] rss[Sitemap / RSS / Atom] tail[Tail recrawl
politeness] gd[GDELT] end adapters -->|DocCapture| norm[Normalize → Dedup
xxhash + 64-bit simhash
pigeonhole near-dup] norm --> jsonl[JSONL staging atomic
data/jsonl/captures/Y/M/D/] jsonl -.optional copy.-> iceberg[(Apache Iceberg
PyIceberg
data/iceberg/awareness/captures/)] iceberg --> duckdb[DuckDB range query
awareness inspect / counts] classDef sourceNode fill:#1f6bff15,stroke:#1f6bff,color:#1f6bff classDef storageNode fill:#d4a57420,stroke:#d4a574,color:#d4a574 class cc,fw,rss,tail,gd sourceNode class state,iceberg storageNode ```
### 层级
| 层级 | 模块 | 用途 |
| --- | --- | --- |
| Config | `awareness.config.settings` | 环境变量 + YAML 覆盖 |
| Schemas | `awareness.schemas.{doc,jobs}` | 规范文档信封 + 任务状态 |
| Util | `awareness.util.*` | URLs, 时间, 哈希, robots, ratelimit |
| Sources | `awareness.sources.*` | 每个数据层一个适配器 |
| Normalize | `awareness.normalize.{text,html}` | trafilatura 包装器 + 清理 |
| Dedup | `awareness.dedup.engine` | 精确去重 + 规范 URL + simhash |
| Storage | `awareness.storage.{jsonl,iceberg,duckdb_index,state}` | 暂存 + 持久化 + 查询 + 状态 DB |
| Planner | `awareness.planner.planner` | 请求 → 分区 → 任务 |
| Workers | `awareness.workers.engine` | 异步池,背压,去重,刷新 |
| Tail | `awareness.tail.engine` | 实时捕获生命周期 |
| API/CLI | `awareness.{cli,api}` | 用户界面 |
### 数据模型
唯一的持久化 schema 是 `DocCapture`(参见 [src/awareness/schemas/doc.py](src/awareness/schemas/doc.py))。每个适配器都会
生成它。Iceberg 写入相同的字段(参见 [iceberg_schema.py](src/awareness/storage/iceberg_schema.py))。所有
时间戳均为 UTC。来源信息存在于 `source_*` 列中;标识信息存在于
`doc_id`/`capture_id` 中;去重分组存在于 `parent_doc_or_dup_group` 中。
## 安装
```
cd /path/to/awareness
uv venv --python 3.13 --seed
uv pip install -e '.[dev]'
# 可选:HuggingFace adapters
uv pip install -e '.[hf]'
# 可选:Postgres state DB
uv pip install -e '.[postgres]'
```
## 运行
### 初始化存储
```
awareness init
```
### BODY — 历史回填
```
# 提交,然后在进程内运行(CLI 也有一个单独的 worker 入口)。
awareness backfill submit --start 2024-06-01 --end 2024-06-14 --max-tasks 5
# → 发出 JOB_ID
awareness backfill run JOB_ID
awareness backfill status JOB_ID
```
### TAIL — 实时捕获
```
# 编辑 configs/tail_seeds.yaml(你想关注的 RSS/Atom/sitemaps)。
awareness tail start # foreground; Ctrl-C stops cleanly
# 替代方案:`awareness-tail` 运行相同的循环,并支持基于 signal 的关闭。
awareness tail status
awareness tail stop # cooperative stop request
```
### 检查与指标
```
awareness status
awareness inspect --start 2024-06-01 --end now --limit 25
awareness counts --start 2024-06-01 --end now
awareness dedup-stats
awareness metrics
```
### HTTP API
```
awareness-api # listens on 127.0.0.1:8085
# Endpoints:/healthz /status /metrics /backfill /tail /inspect /counts ...
```
## 这是什么以及不是什么
| 是 | 否(尽管早期的文档/提交信息有所不同) |
| --- | --- |
| 仅限本地摄取:SQLite 状态,磁盘上的 JSONL,通过 PyIceberg 存储在磁盘上的 Iceberg | **没有云存储**。任何数据都不会离开你的机器。`ops/compose` 中的 Postgres + Min + Redpanda + ClickHouse 栈是可选的脚手架;它默认不会运行,且代码不会写入其中。 |
| 基于轮询的实时更新:Dashboard 每 4–5 秒刷新一次;Tail 视图每 2 秒刷新一次 | **没有 Server-Sent Events / WebSocket 推送。** “实时活动信息流”会在新捕获内容到达时产生跳动,但它是通过轮询实现的;如果 Tail 处于空闲状态(没有发现新内容),UI 将显示相同的数字。 |
| `tail_poll_seconds` 节奏会定期重新轮询每个配置的 RSS/Atom/Sitemap 种子,并重新激活发现任务 | 直到提交 `` 之前,重新播种循环在第一次迭代后由于 UNIQUE 约束而静默崩溃。如果你运行的是较旧的构建版本,你的“Tail”实际上只运行了*一次*,然后就处于空闲状态。 |
| 在 `tail_recrawl` 中强制执行 robots.txt + 单域名礼貌策略 | 我们尚未在 UI 中展示单次抓取的 robots 结果。 |
| `max_tasks` 限制了*规划器*的初始输出 | 发现适配器(CC 索引 → WARC 修复,GDELT 槽位 → 尾随重新爬取)排队的子分区**不受** `max_tasks` 限制。单个 GDELT 15 分钟的时间槽可能会扇出成超过 1000 次子抓取。 |
## 配置
`configs/awareness.yaml` 是默认的配置文件;在 YAML 中设置的值优先于
环境变量(这是我们将要修复的一个怪癖)。要设置环境变量,还需要从
`configs/awareness.yaml` 中删除相应的行。
示例:
| 环境变量 | 含义 |
| --- | --- |
| `AW_PROJECT_ROOT` | 基础目录(默认:此代码库) |
| `AW_DATA_DIR` | Iceberg + JSONL + 状态数据的存放位置 |
| `AW_STATE_DB_URL` | SQLAlchemy URL(默认为 SQLite;也支持 PG) |
| `AW_USER_AGENT` | 用于 HTTP 抓取的机器人标识符 |
| `AW_PER_DOMAIN_CONCURRENCY` | 单域名实时抓取并发上限 |
| `AW_TAIL_POLL_SECONDS` | 信息流重新轮询的间隔 |
| `AW_ENABLE_ICEBERG` | 切换 Iceberg 写入(JSONL 始终开启) |
## 存储布局
```
data/
├── jsonl/captures/YYYY/MM/DD/captures-*.jsonl ← atomic staging (source of truth)
├── iceberg/ ← PyIceberg warehouse + catalog
├── state/awareness.sqlite ← jobs/tasks/manifests/dedup
├── checkpoints/ ← reserved for adapters
├── dlq/ ← dead-letter task payloads
├── cache/ ← robots cache & helpers
├── warc/ ← cached WET/WARC bytes (TTLable)
└── logs/awareness.log
```
## 合规性
- Robots.txt:在任何实时抓取之前通过 `RobotsCache` 强制执行。
- 礼貌策略:单域名信号量 + 最小请求间延迟;如果 robots.txt 中存在
crawl-delay 则予以遵守。
- 仅限公开内容:适配器仅针对公开可访问的语料库和界面。
- 仅限文本持久化:HTML 被转换为文本后被丢弃;二进制媒体
永远不会被持久化存储。
## 可选的生产级栈
`ops/compose/docker-compose.yml` 为那些需要分析级环境的用户
运行 Postgres + Redpanda + MinIO + ClickHouse。相同的
Awareness 二进制文件通过环境变量指向它;无需更改代码。
```
docker compose -f ops/compose/docker-compose.yml up -d
```
请参阅 [docs/runbook.md](docs/runbook.md) 获取操作手册。
## 测试
```
pytest # all tests
pytest -m smoke # smoke only
pytest -m integration # integration only
```
state DB)] state --> worker[Worker Engine
asyncio] worker -->|async runs partition| adapters subgraph adapters[Source Adapters] cc[Common Crawl
WET / CDX / WARC] fw[HuggingFace
FineWeb / FineWeb2] rss[Sitemap / RSS / Atom] tail[Tail recrawl
politeness] gd[GDELT] end adapters -->|DocCapture| norm[Normalize → Dedup
xxhash + 64-bit simhash
pigeonhole near-dup] norm --> jsonl[JSONL staging atomic
data/jsonl/captures/Y/M/D/] jsonl -.optional copy.-> iceberg[(Apache Iceberg
PyIceberg
data/iceberg/awareness/captures/)] iceberg --> duckdb[DuckDB range query
awareness inspect / counts] classDef sourceNode fill:#1f6bff15,stroke:#1f6bff,color:#1f6bff classDef storageNode fill:#d4a57420,stroke:#d4a574,color:#d4a574 class cc,fw,rss,tail,gd sourceNode class state,iceberg storageNode ```
ASCII 备用图(适用于终端查看器)
``` ┌──────────────────────────┐ user/CLI ────►│ Planner │── partitions ──┐ └──────────────────────────┘ │ ▼ ┌──────────────────────────┐ ┌────────────────────┐ │ Worker Engine (asyncio) │◄─────│ Tasks (state DB) │ └─────────┬────────────────┘ └────────────────────┘ │ async runs partition ▼ ┌──────────────────────────┐ │ Source Adapters │ Common Crawl WET / CDX / WARC │ │ HF FineWeb / FineWeb2 │ │ Sitemap / RSS / Atom │ │ Tail recrawl (politeness) │ │ GDELT └─────────┬────────────────┘ │ DocCapture ▼ ┌──────────────────────────┐ │ Normalize → Dedup │ xxhash + 64-bit simhash └─────────┬────────────────┘ pigeonhole near-dup index │ ▼ ┌──────────────────────────┐ │ JSONL staging (atomic) │ data/jsonl/captures/Y/M/D/*.jsonl └─────────┬────────────────┘ │ optional copy ▼ ┌──────────────────────────┐ │ Iceberg (PyIceberg) │ data/iceberg/awareness/captures/ └─────────┬────────────────┘ │ query ▼ ┌──────────────────────────┐ │ DuckDB ── range query │ CLI: `awareness inspect / counts` └──────────────────────────┘ ```标签:Apache Iceberg, DuckDB, ESC4, OSINT, Python, 代码示例, 命令控制, 恶意软件检测, 数据分析, 数据采集, 无后门, 计算机取证, 逆向工具