LindqvistMartin/flare
GitHub: LindqvistMartin/flare
Flare 是一个基于 .NET 10 和 React 19 的自托管事件管理平台,提供从告警接入、实时协作到自动生成事后复盘的完整闭环,帮助团队摆脱昂贵的事件管理 SaaS 依赖。
Stars: 0 | Forks: 0
# Flare
**自托管的事件管理。从告警到事后总结——无需 SaaS 账单。**
[](LICENSE)
[](https://dotnet.microsoft.com)
[](https://react.dev)
[](https://github.com/LindqvistMartin/flare/actions)
[](#)
[](https://flare-ui.onrender.com)
🔗 **在线演示:** [flare-ui.onrender.com](https://flare-ui.onrender.com) | 📊 **状态页面:** [flare-ui.onrender.com/#/p/demo](https://flare-ui.onrender.com/#/p/demo)
## 为什么选择 Flare
FireHydrant 的定价为 44 美元/用户/月。Rootly 为 20+ 美元/用户/月,且采用了不透明的
分级定价。Incident.io 为 19-50 美元/用户/月,并将状态页面和
值班功能限制在更高等级的套餐中。PagerDuty 起价为 21 美元/用户/月。
**作为历来经济实惠的选择,Opsgenie 将于 2027 年 4 月关闭——
约 80 万用户目前正在寻找替代品。**
目前还没有成熟的开源替代方案。Dispatch (Netflix) 需要 Keycloak、
PagerDuty 和 Slack 才能启动。其他项目的 star 数都没超过 2K。该领域
100% 被 SaaS 垄断。
Flare 填补了这一空白:完整的事件生命周期——webhook 接入、仅追加的
时间线、从事件流自动生成的复盘草稿、MTTR / MTTA
物化视图、通过 outbox 发送的 Slack 和 Teams 通知、公开的
状态页面——只需一条 `docker compose up` 命令。支持自托管,单一可部署单体架构,
后端使用 .NET 10,前端使用 React 19,一切存储交由 Postgres。
## 截图
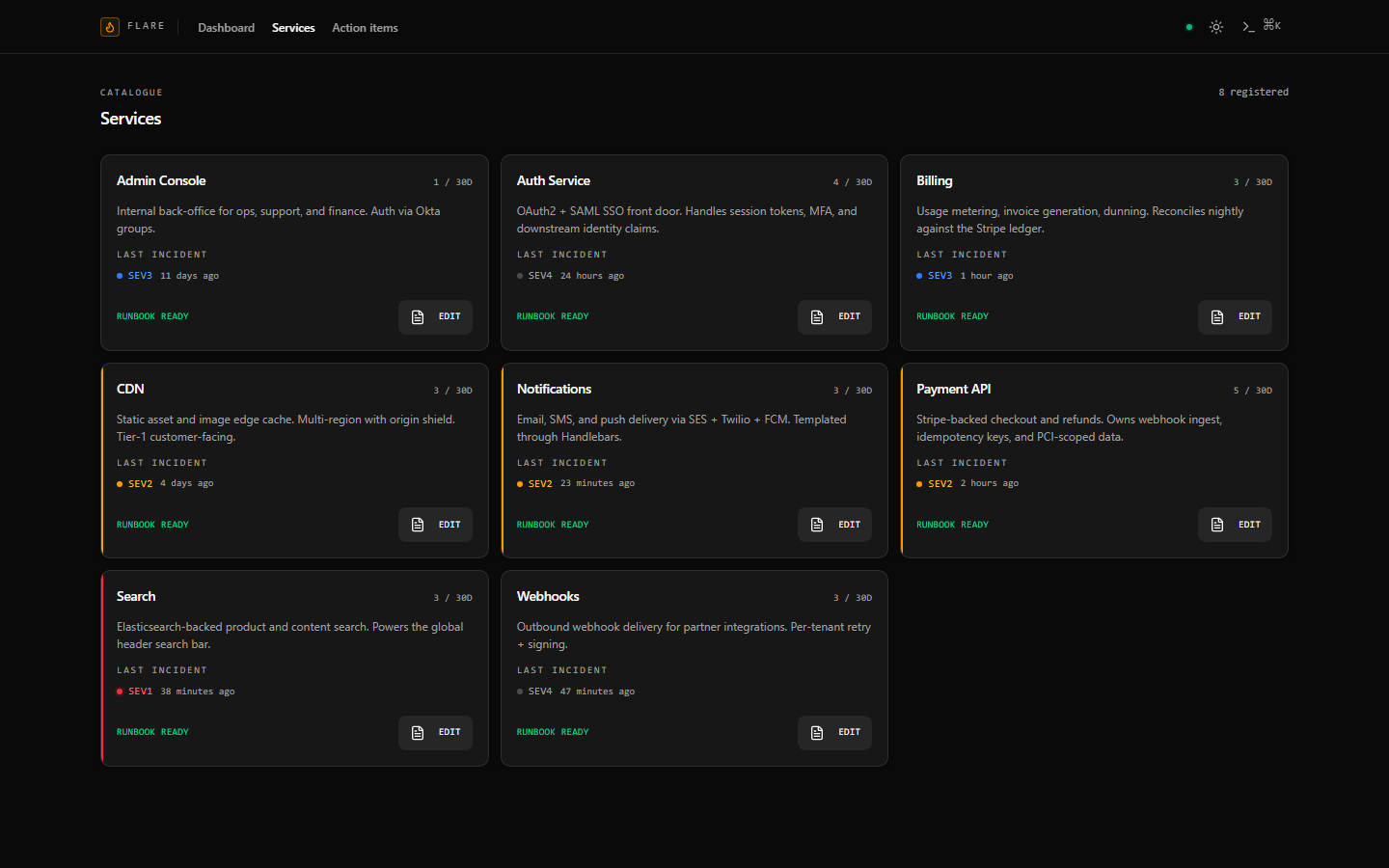
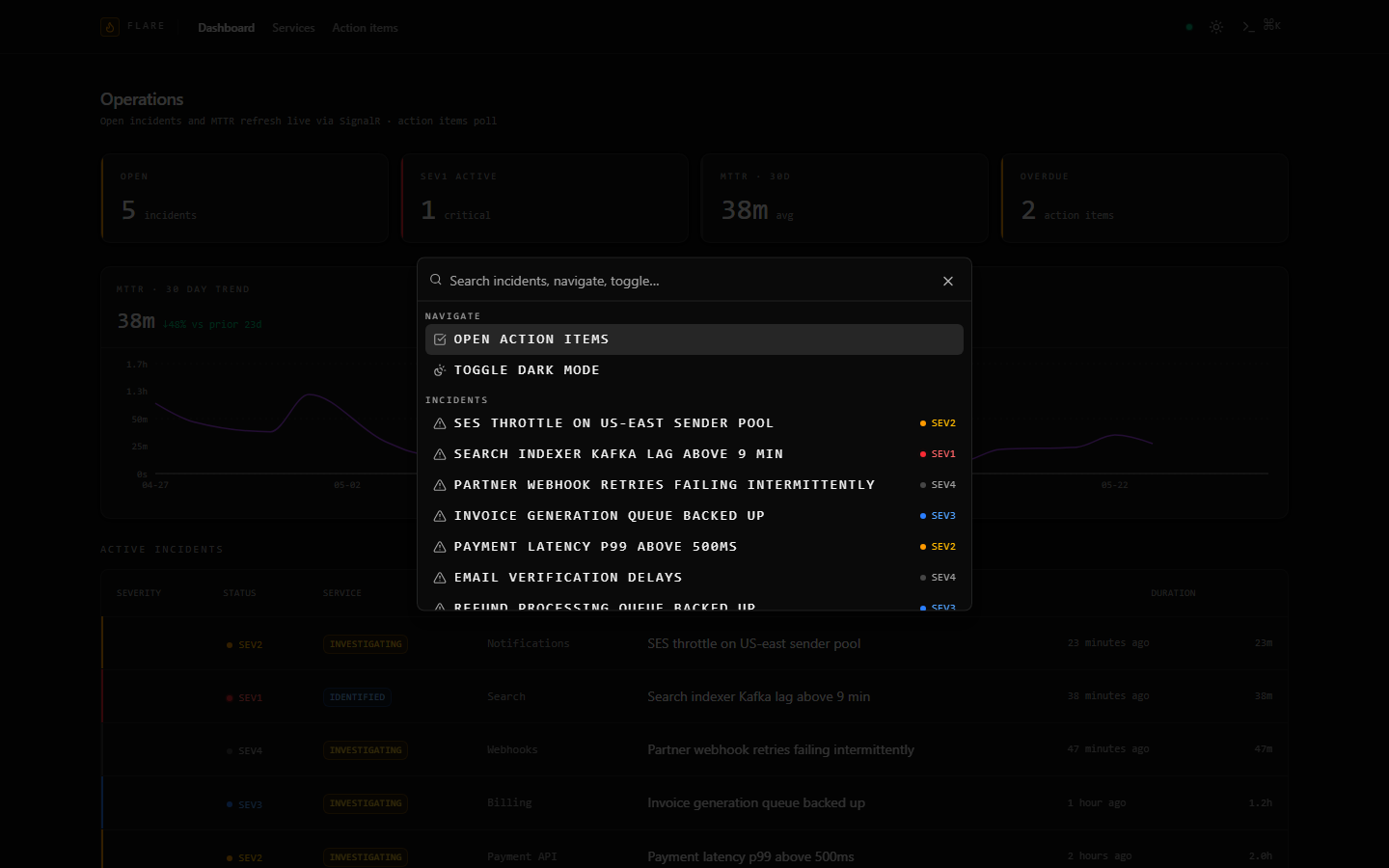
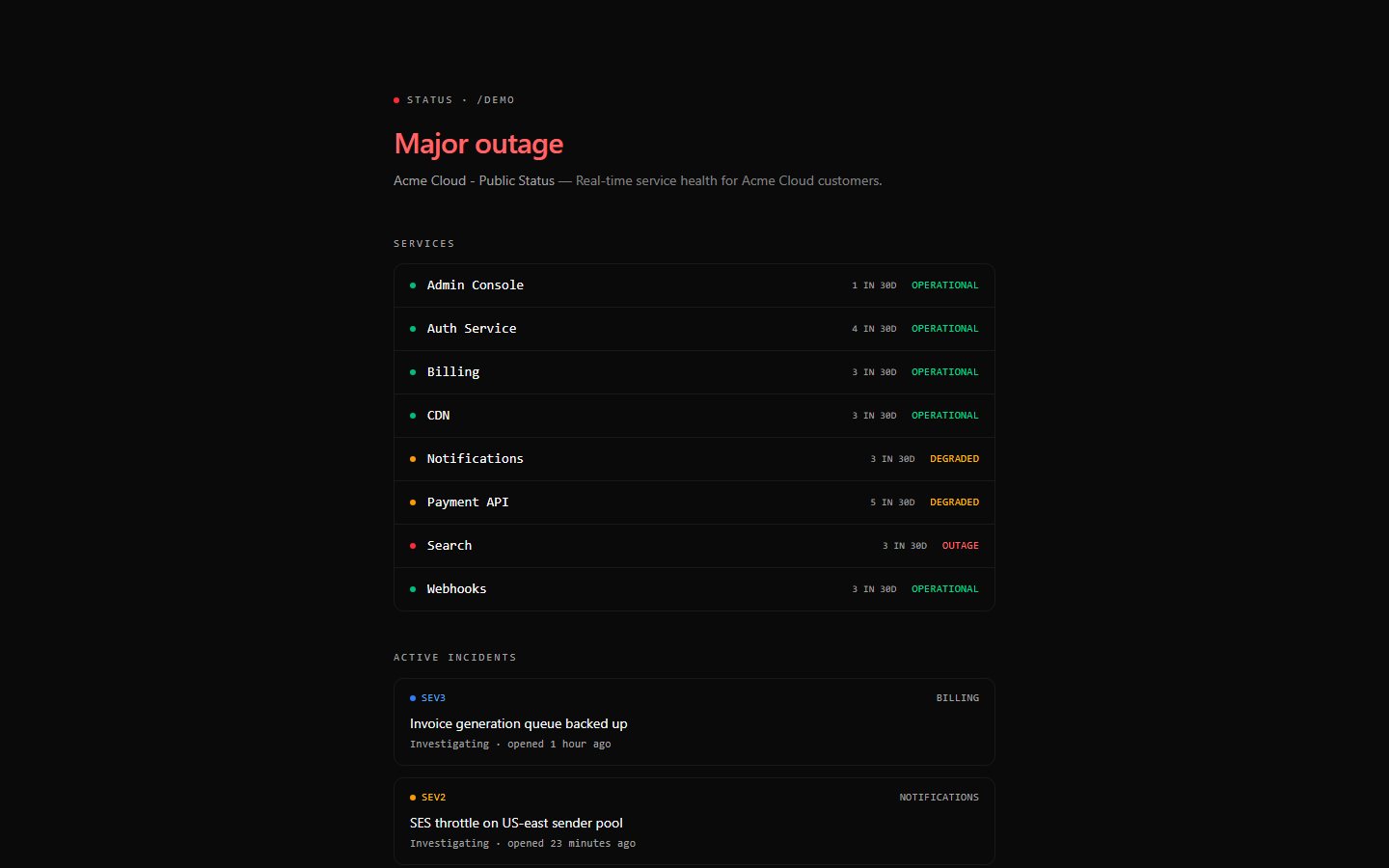
## 架构
单一可部署单体架构。前端边缘采用 ASP.NET Core 10 Minimal API,EF Core
配合 Postgres 进行存储,`BackgroundService` + `Channel` 用于接入和
outbox 分发,OpenTelemetry 用于追踪和指标,Serilog 用于结构化
日志,位于 `/scalar` 的 Scalar UI 用于展示 OpenAPI 文档。
```
┌──────────────────────────────────────────────────┐
alerts ───▶ │ API: POST /api/v1/webhooks/ingest/{source} │
(Prometheus, │ POST /api/v1/incidents/{id}/postmortem/... │
Grafana, │ GET /api/v1/metrics/{mttr,mtta,dashboard} │
PulseWatch, │ GET /public/status/{slug} (cached 30s) │
generic) │ │
│ IAlertIngestionAdapter (4 implementations) │
│ Channel (bounded, backpressure) │
│ PostmortemDraftBuilder (inline, synchronous) │
└──────────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────┐
│ IngestionWorker : BackgroundService │
│ one transaction: │
│ Incident + IncidentEvent + OutboxMessage │
└──────────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────┐
│ Postgres │
│ incidents, incident_events (append-only), │
│ postmortems, action_items, outbox_messages, │
│ status_pages, mttr_by_service_30d, │
│ mtta_by_service_30d │
│ (materialized views, refreshed every 5 min) │
└──────────────────────────────────────────────────┘
│ │
▼ ▼
┌────────────────────────┐ ┌───────────────────────────┐
│ NotificationDispatcher │ │ MetricsAggregator │
│ outbox SKIP LOCKED │ │ REFRESH CONCURRENTLY 5m │
│ → status-page cache │ └───────────────────────────┘
│ invalidation │
└────────────────────────┘
```
事件在 Postgres 触发器级别是严格只追加的——参见
[ADR-001](docs/adr/001-append-only-incident-events.md)。复盘从事件流
物化而来,而不是由人工手动输入——参见
[ADR-002](docs/adr/002-postmortem-from-events.md)。通知通过
outbox + `SKIP LOCKED` 轮询 worker 进行分发,以尽力而为的方式向 SignalR 组
广播——参见 [ADR-003](docs/adr/003-outbox-notification-dispatch.md)。MTTR
和 MTTA 是根据标准的 `Incident.ResolvedAt` 和 `Incident.AcknowledgedAt` 时间戳,在滚动的 30 天窗口内按服务聚合的——
领域状态机将它们与匹配的事件原子化写入,因此
matview SQL 保持快速且不受事件 payload 格式的影响。物化视图
策略及其扩展路径记录在
[ADR-004](docs/adr/004-mttr-materialized-views.md) 中。
## 快速开始
后端:
```
cp src/Flare.Api/appsettings.Local.example.json src/Flare.Api/appsettings.Local.json
# 编辑内部的 connection string(或导出 ConnectionStrings__Postgres),
# 然后:
dotnet run --project src/Flare.Api
```
`appsettings.Local.json` 已被 gitignored。示例文件是标准的
模板;在容器中首选使用环境变量。
客户端:
```
cd client
npm install
npm run dev
```
然后打开 `http://localhost:5173/#/dashboard`。客户端期望 API 位于
`http://localhost:5000`(使用 `VITE_API_URL` 环境变量进行覆盖)。
开发服务器的 CORS 已经在 `Program.cs` 中配置好了。
## 后端特性
- **Webhook 摄取** — Prometheus、Grafana、PulseWatch 和一个通用适配器
共享一个 `IAlertIngestionAdapter` 接口。入站请求排入一个
有界的 `Channel` 中;端点返回 202 Accepted,或当
通道已满时返回 503,以便发送方重试,而不是接受一个它无法
入队的任务。
- **仅追加时间线** — `IncidentEvents` 受 PostgreSQL
`BEFORE UPDATE OR DELETE` 触发器保护;无论调用方、ORM
还是迁移框架,行变更都会抛出异常。
- **领域状态机** — `Triggered → Investigating → Identified → Monitoring
→ Resolved → Closed`,在聚合内部进行验证。无效的状态转换将
以 RFC 7807 Problem+JSON 422 响应的形式呈现。
- **自动生成的复盘草稿** — `PostmortemDraftBuilder` 按需直接从事件流
物化 Impact、Timeline 和 Root Cause。复盘一旦 `Published` 即不可变。
- **MTTR / MTTA 物化视图** — `mttr_by_service_30d` 和
`mtta_by_service_30d`,每五分钟由
`MetricsAggregator` 并发刷新。
- **Outbox 分发** — `NotificationDispatcher` 使用
`FOR UPDATE SKIP LOCKED` 进行轮询,将行标记为已处理,提交,*然后*向
SignalR 组和已配置的 Slack / Teams webhook 广播。批处理内的扇出
在基于每条消息的 DbContext 作用域上并发运行(上限为 10),这样一个慢速的
webhook 就不会阻塞同级的消息。数据库层面上保证至少一次传递,网络层面上保证最多一次——参见 ADR-003。
- **公开状态页面** — 只读的 `GET /public/status/{slug}` 为运营者策划的
服务列表返回各服务的当前状态和 30 天事件计数。响应在进程内缓存 30 秒;分发器
在 `IncidentCreated` 和
`IncidentStatusChanged` 提交后使受影响的页面失效,因此变化会在一个周期内显现,而不是
等待 TTL 到期。管理 CRUD 位于
`/api/v1/status-pages`;公开端点位于
`/api/v1` 之外,因此未来在管理界面上的身份验证门控
不会将客户拒之门外。管理 CRUD 目前
无需身份验证——身份验证将在下一个里程碑中引入。
缓存设计参见 [ADR-005](docs/adr/005-status-page-cache.md)。
- **Slack 和 Teams 频道** — 可通过 `INotificationChannel` 插拔。Webhook URL
在启动时通过 `ValidateOnStart` 与 HTTPS 主机白名单(`hooks.slack.com`、
`*.webhook.office.com`)进行校验——配置错误的
webhook 会在启动时报错,而不是默默地将 payload 发送出去。
HTTP、回环地址以及私有/链路本地目标将被拒绝(SSRF 防护)。
空的 URL = 静默跳过。
- **行动项提醒** — `ActionItemReminderService` 自上一次成功运行后
每 24 小时运行一次(计划任务作为
`ReminderHeartbeat` outbox 行持久化,因此它能在进程重启后存续)。失败的
周期会在重试前退避 15 分钟,以避免在
永久性错误时不断冲击数据库。
- **Outbox 保留期** — `OutboxJanitorService` 每 6 小时清理一次,删除
超过 30 天的已处理消息;为任何合规审计限制存储和历史 PII
窗口。
- **通知指标与追踪** — 位于 `Flare.Notifications` meter 上的 `flare_notification_channel_sends_total`、
`flare_outbox_messages_processed_total` 和 `flare_dispatcher_dropped_total`
计数器;`Flare.NotificationDispatcher`
ActivitySource spans 补全了从 POST /incidents 到
通道 POST 的 Jaeger 追踪。
- **实时 UI 管道** — SignalR hub 位于 `/hubs/flare`,包含 `dashboard` 和
`incident:{id}` 组。
- **幂等的 POST 请求** — `Idempotency-Key` header 通过
内存缓存对写入请求进行去重,持续五分钟。
- **可观测性** — Serilog JSON 日志,基于
OTLP 的 OpenTelemetry 追踪和指标,`/metrics` 用于 Prometheus 抓取。
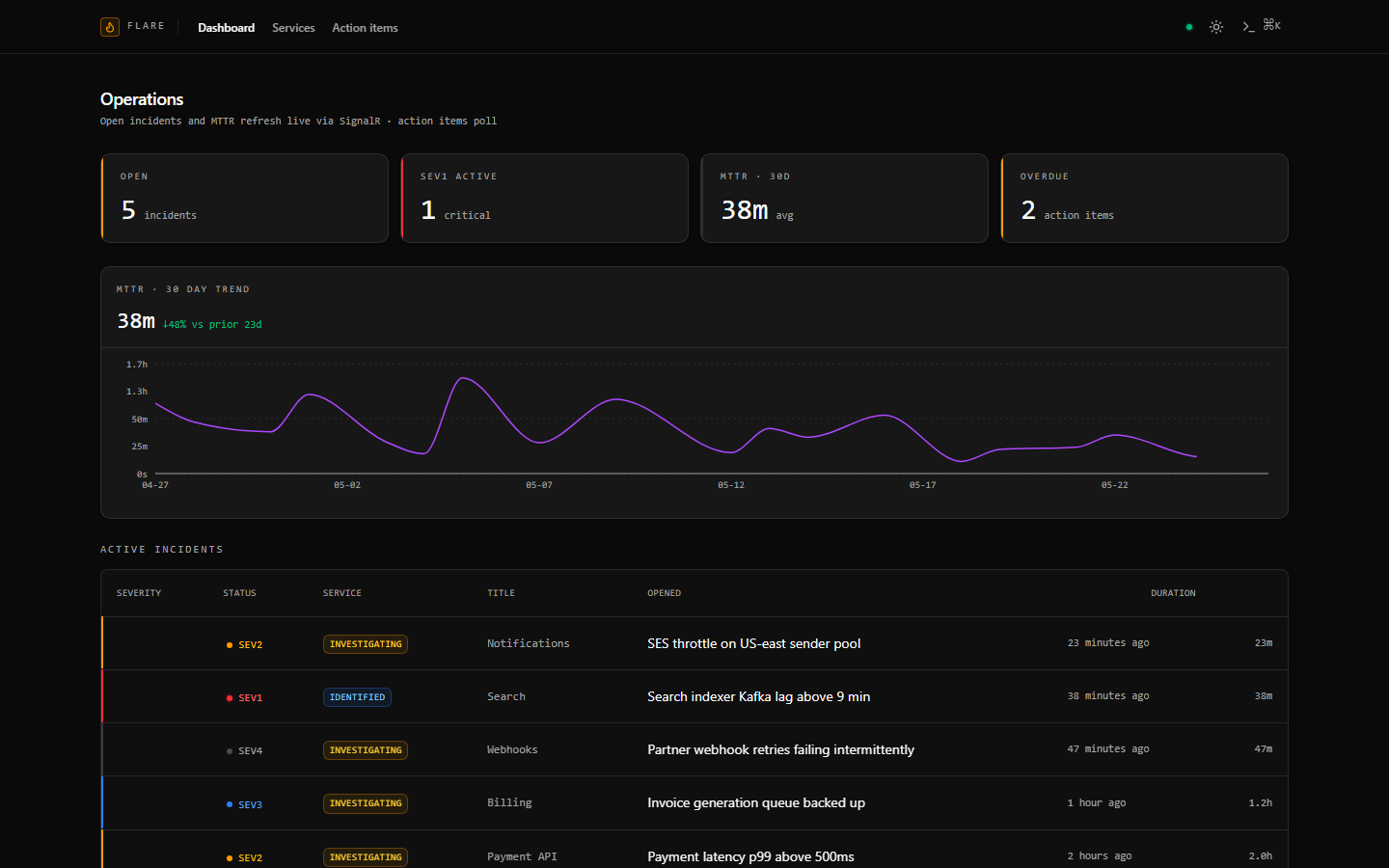
- **带有实时仪表板的 React 客户端** — `client/` 中的 Vite + React 19 前端。
仪表板订阅 `dashboard` SignalR 组;打开的
事件、MTTR 趋势和活跃事件表都会自动刷新而无需轮询。
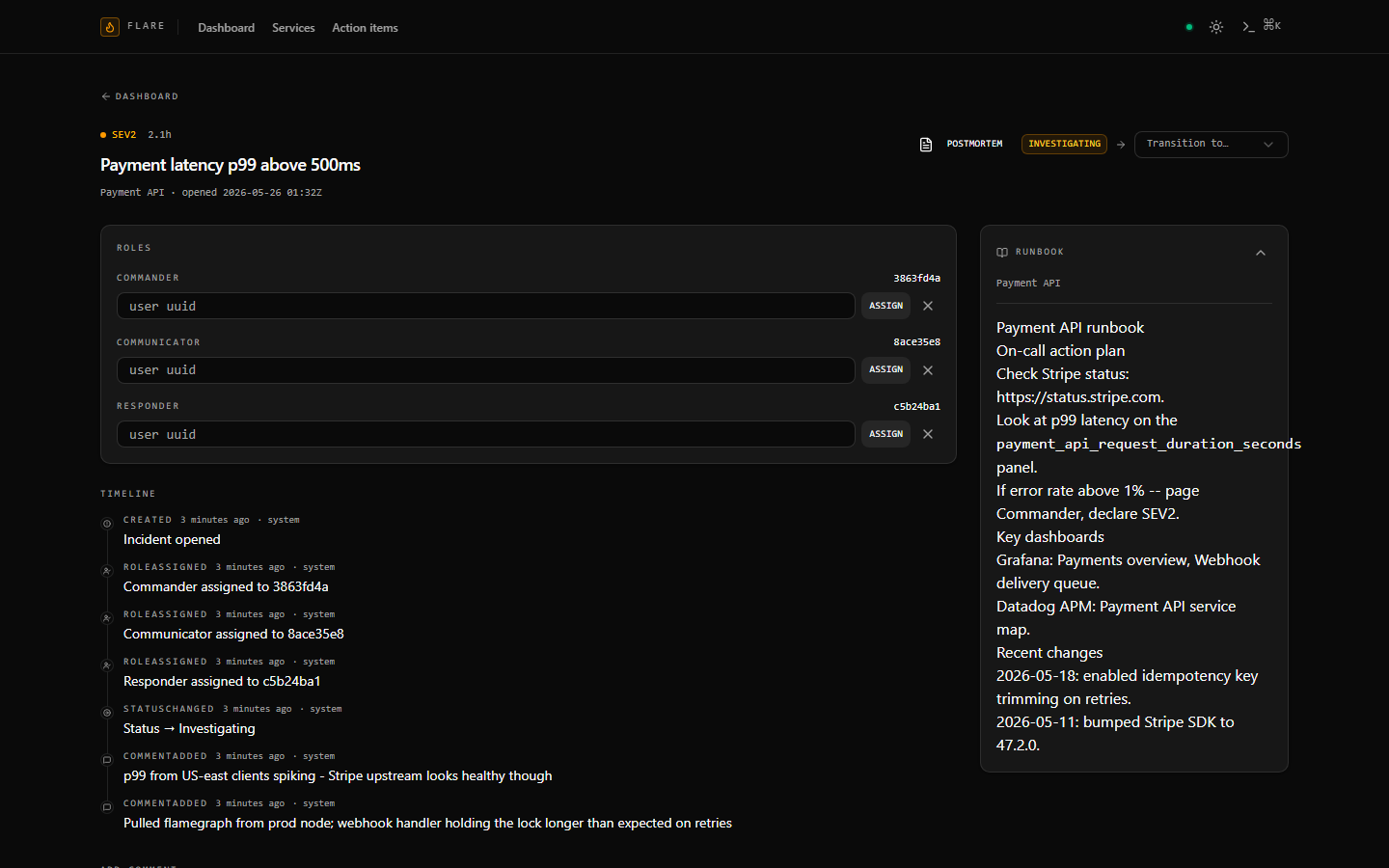
- **事件详情页** — 完整的时间线流,带有每个事件的图标,状态
转换通过仅限允许项的下拉菜单进行(乐观更新,在
422 时回滚),Commander / Communicator / Responder 分配,带有
zod 校验的评论编辑器,以及从链接的服务中提取的 Markdown runbook 侧边栏。
页面订阅 `incident:{id}` SignalR 组,因此来自其他操作者的转换和
事件无需轮询即可呈现。
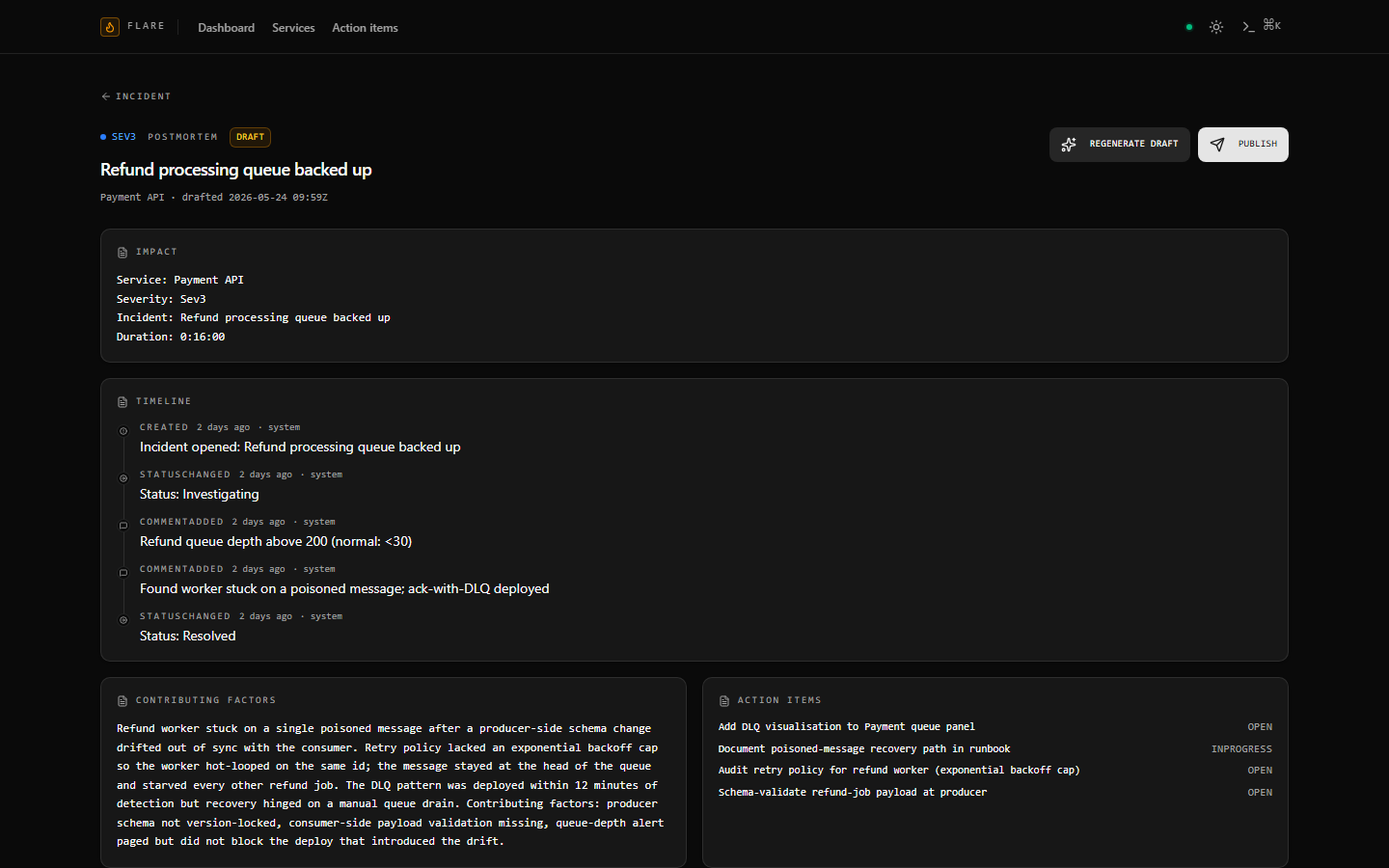
- **复盘查看器** — 从事件流生成草稿,Draft / Published
状态标签,带有内联创建功能的附加行动项面板。Impact 和 Root
Cause 与物化的时间线一起展示,因此发布的复盘
可以在单个屏幕上进行端到端阅读。
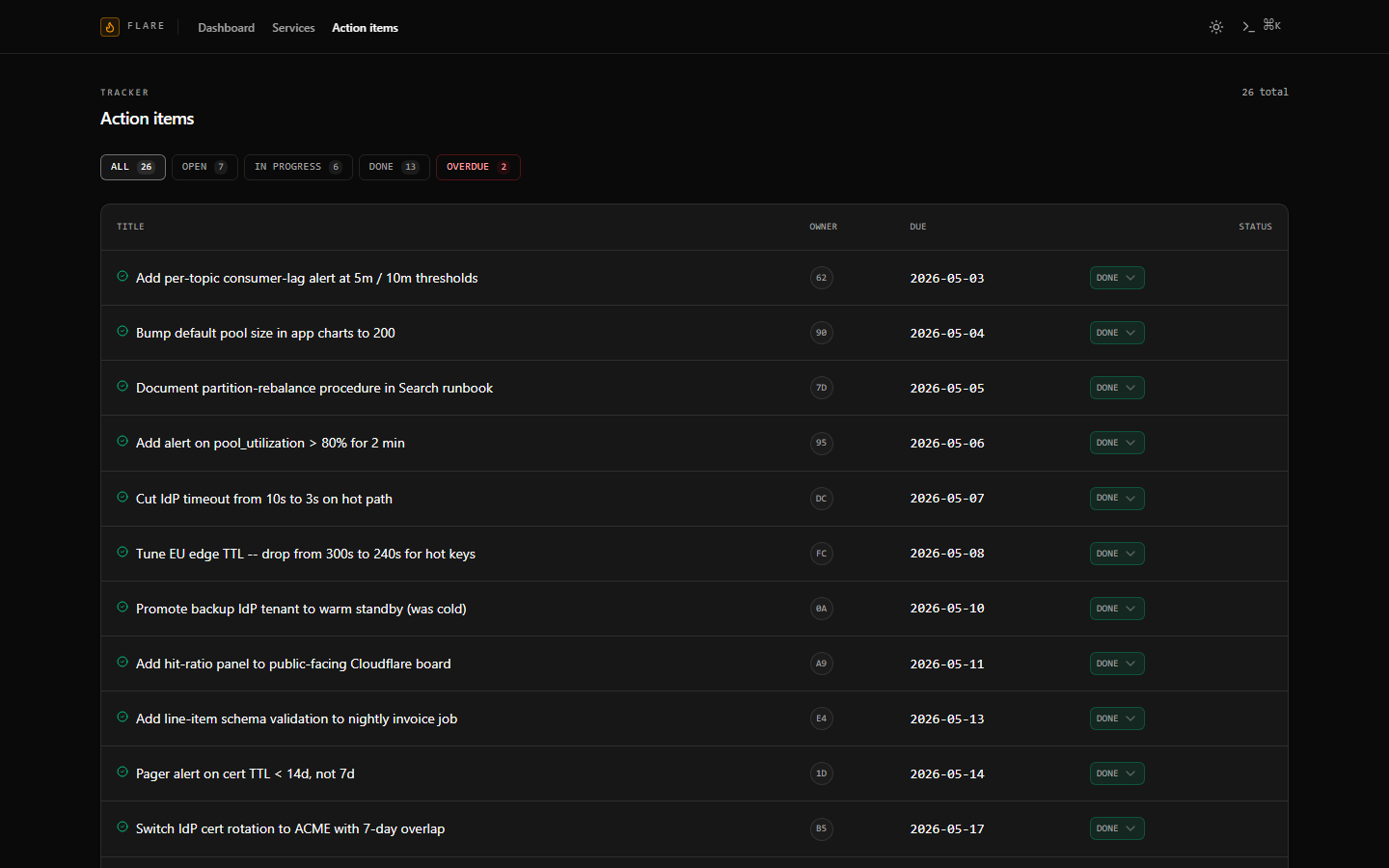
- **行动项跟踪器** — `/action-items` 显示“全部 / 待处理 / 进行中 /
已完成 / 已逾期”选项卡,并带有内联状态切换。截止日期标签在逾期时
会变为警报色调。
- **服务与 Runbook 编辑器** — 服务目录包含各服务的
事件历史;Runbook 是一个带有防抖保存功能的 Markdown 编辑器。
- **命令面板** — 全局 Ctrl/Cmd + K 打开一个由 `cmdk` 驱动的面板,包含
导航操作和基于近期事件的搜索索引。
- **公开状态页面前端** — `/p/:slug` 针对缓存的
`/public/status/{slug}` 端点渲染面向客户的
布局(总体状态、各服务行、活跃事件)。不带凭证的独立 axios 实例
确保即使在引入管理员身份验证后,该路由也保持免验证状态。
## 路线图
在 MVP(最小可行性产品)阶段刻意排除在外的事项:
- **OIDC 身份验证** — `docker-compose` 中的 Keycloak 或 Authentik,`/api/v1/*` 上的
JWT bearer,`/public/*` 和 `/healthz` 保持开放。目前管理界面
无需身份验证;对于自托管演示而言,基于 token 的
访问已经足够,并且公开/管理端点的划分已经为该门控做好了准备。
- **值班调度引擎** — 轮换、覆盖、升级策略以及它们带来的
时区计算。这本身就是一个独立的产品;Flare 会通知 Slack
和 Teams,而寻呼功能则超出范围。
- **AI 辅助复盘总结** — 对事件流进行一次可选的 LLM 处理
,以起草叙述性的 Root Cause 和 Contributing Factors。确定性的
`PostmortemDraftBuilder` 仍然是事实来源;AI 总结是作为附加功能存在的。
- **Opsgenie 导入** — 一个 CLI,用于读取 Opsgenie 导出文件并重新创建匹配的
服务和事件。Opsgenie 将于 2027 年 4 月关闭,因此迁移路径
是其用户最直接的入门方式。
- **Terraform provider** — 将服务、集成和状态页面作为声明式
资源,供将其他所有内容都作为代码管理的团队使用。
标签:On-Call, Postgres, React, Syscalls, 事件管理, 测试用例, 用户代理, 自托管, 运维监控