Andybobo0825/aws-incident-response-observability-lab
GitHub: Andybobo0825/aws-incident-response-observability-lab
一个完整的 AWS 事故响应与可观测性实验室项目,模拟从故障注入、告警通知到 Runbook 排查和 RCA 根因分析的全流程运维闭环。
Stars: 1 | Forks: 0
# AWS Incident Response & Observability Lab
## 專案重點
這個 lab 不是單純部署一個服務,而是模擬服務上線後的維運閉環:
- 用 ECS/Fargate 與 ALB 承載範例 API。
- 用 CloudWatch Logs、Metrics、Dashboard 建立可觀測性。
- 用 CloudWatch Alarms 與 SNS email 建立告警通知。
- 用故障注入產生 5xx、target unhealthy、高 CPU / 高併發情境。
- 用 Runbook 記錄告警發生後的排查與復原流程。
- 用 RCA 記錄 timeline、根因、影響、復原與改善項目。
## 架構
flowchart LR
User[User / Tester] --> ALB[Application Load Balancer]
ALB --> ECS[ECS Service on Fargate]
ECS --> App[Python Demo API]
App --> Logs[CloudWatch Logs]
ALB --> Metrics[CloudWatch Metrics]
ECS --> Metrics
Metrics --> Dashboard[CloudWatch Dashboard]
Metrics --> Alarms[CloudWatch Alarms]
Alarms --> SNS[SNS Email Notification]
Alarms --> RCA[RCA / Incident Review]
Dashboard --> Runbook[Runbook]
SNS --> Runbook
Load[CPU / Fault Injection] --> App
Metrics --> Scaling[ECS Service Auto Scaling]
Scaling --> ECS
### 主要元件
| 元件 | 角色 |
| --- | --- |
| ALB | 對外入口,負責 health check 與流量導向。 |
| ECS/Fargate | 執行 demo API container。 |
| CloudWatch Logs | 收集應用程式 request / fault logs。 |
| CloudWatch Metrics | 追蹤 ALB 5xx、healthy targets、ECS CPU 等指標。 |
| CloudWatch Dashboard | 集中觀察服務健康、錯誤率、CPU 與近期 logs。 |
| CloudWatch Alarms | 在 5xx、target unhealthy、CPU 過載時觸發告警。 |
| SNS | 將告警寄送到 email。 |
| ECS Service Auto Scaling | CPU 高負載時自動增加 task 數量,壓力下降後回復。 |
| Runbook / RCA | 定義事故處理流程與事後檢討紀錄。 |
## 事故處理流程
正常服務
→ 故障注入 / 高併發壓力
→ CloudWatch 指標異常
→ Alarm 進入 In alarm
→ SNS email 通知
→ 依 Runbook 判斷與復原
→ 服務恢復健康
→ 撰寫 RCA 與改善項目
### 已驗證情境
| 情境 | 偵測方式 | 處理 / 結果 | RCA |
| --- | --- | --- | --- |
| ALB Target 5xx | `HTTPCode_Target_5XX_Count >= 1` | SNS 通知,確認為受控故障注入,服務後續恢復健康。 | [ALB 5xx RCA](docs/RCA_2026-05-14_alb_5xx_fault_injection.md) |
| Target unhealthy | ALB healthy target count 低於預期 | Runbook 記錄 target health 異常時的排查與復原流程。 | [Runbook](docs/RUNBOOK.md) |
| ECS CPU 高負載 / 高併發 | ECS average CPU 超過 60% alarm;Auto Scaling target tracking 觸發 | ECS desired count 從 1 擴到 2,服務維持可用,CPU alarm 回 OK。 | [CPU Auto Scaling RCA](docs/RCA_2026-05-14_cpu_autoscaling.md) |
## 必要驗證圖片
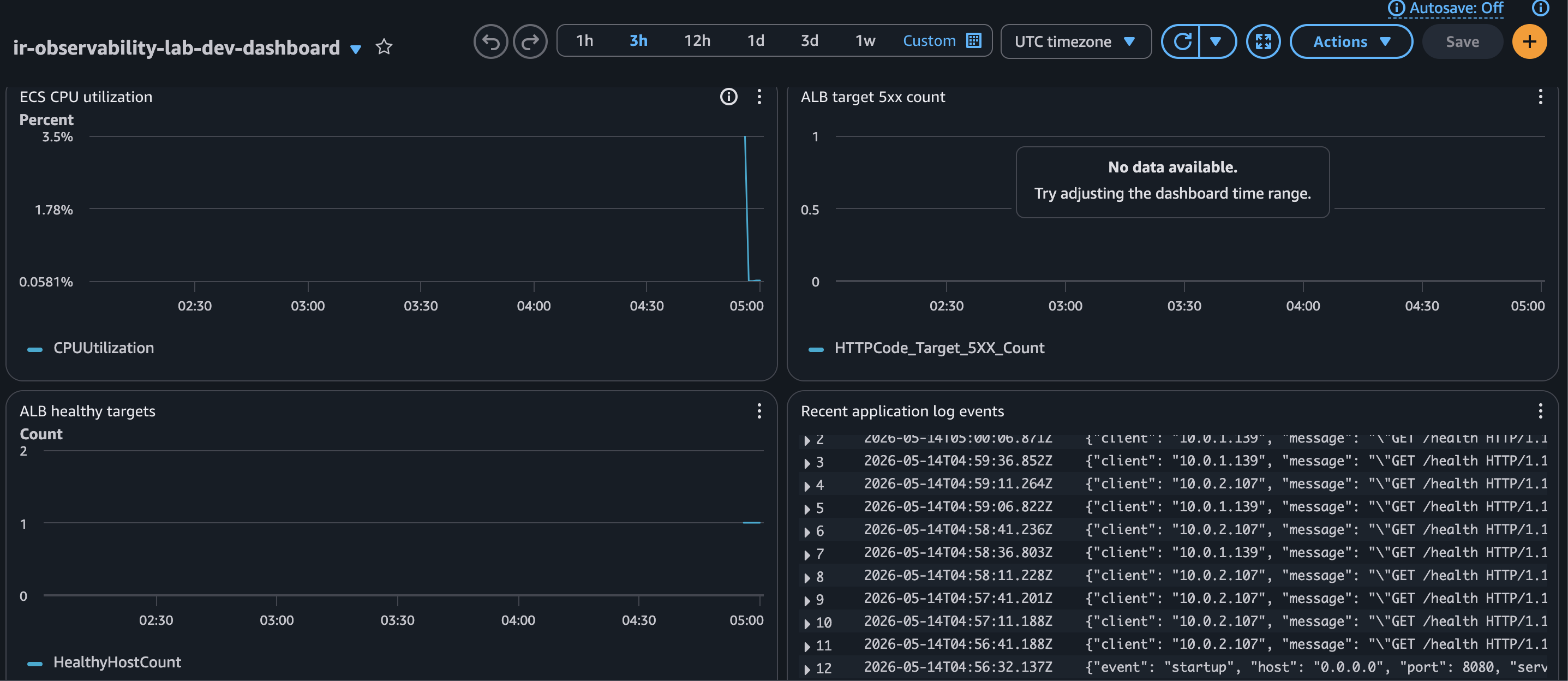
### 1. CloudWatch Dashboard
集中呈現 ECS CPU、ALB 5xx、target health 與 recent logs,是事故判斷的主要入口。
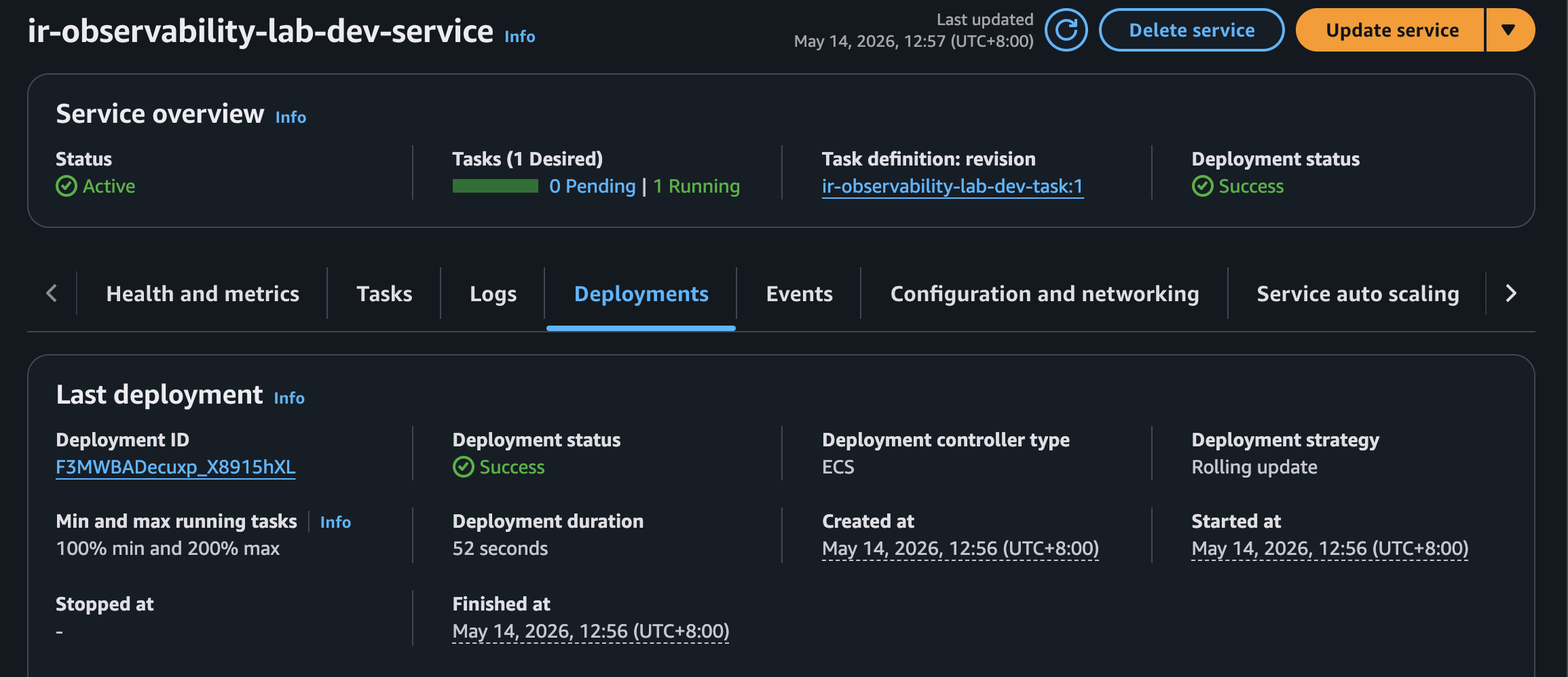
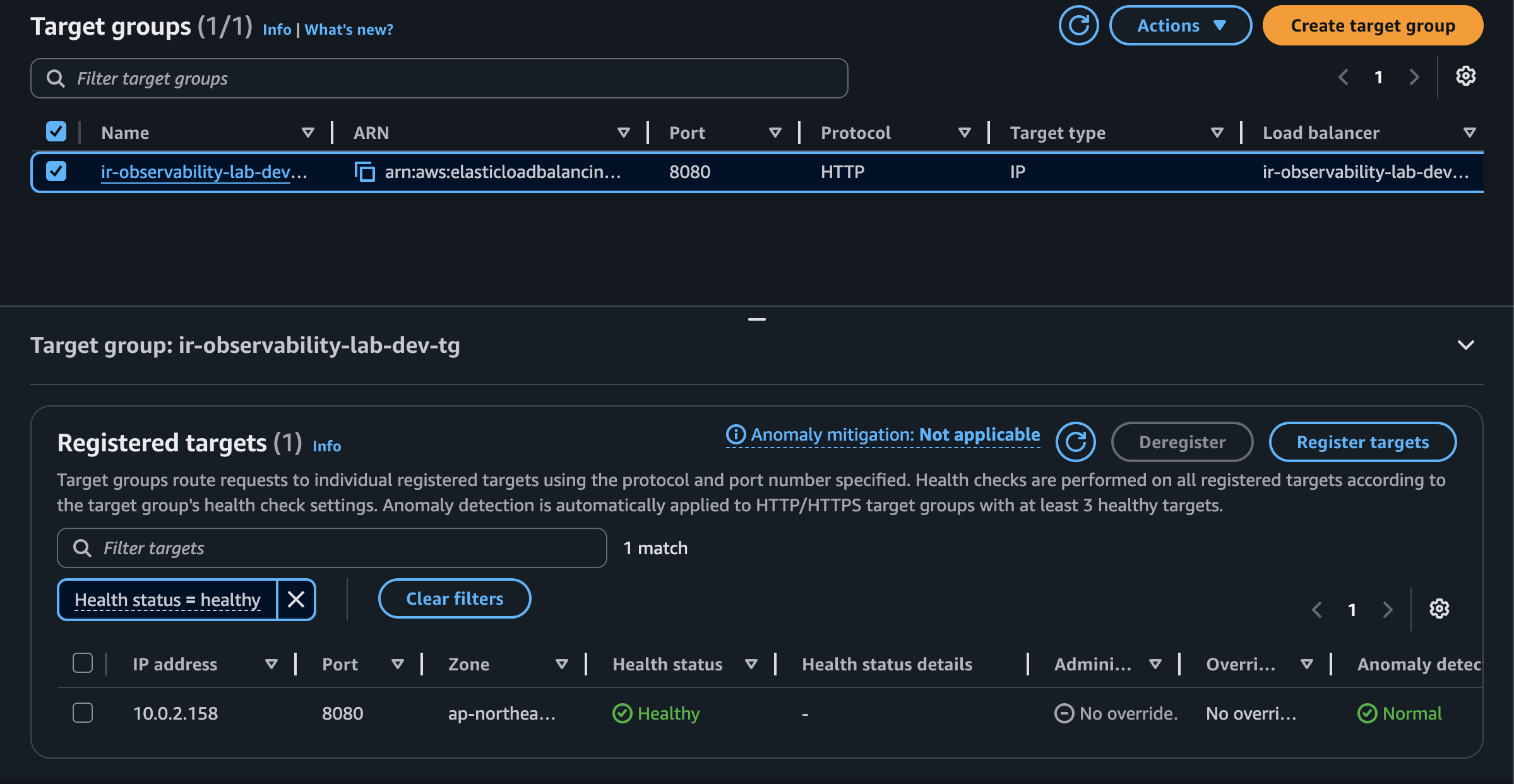
### 2. 服務與 ALB Target 健康
ECS service 正常部署,ALB target group 至少有一個 healthy target。
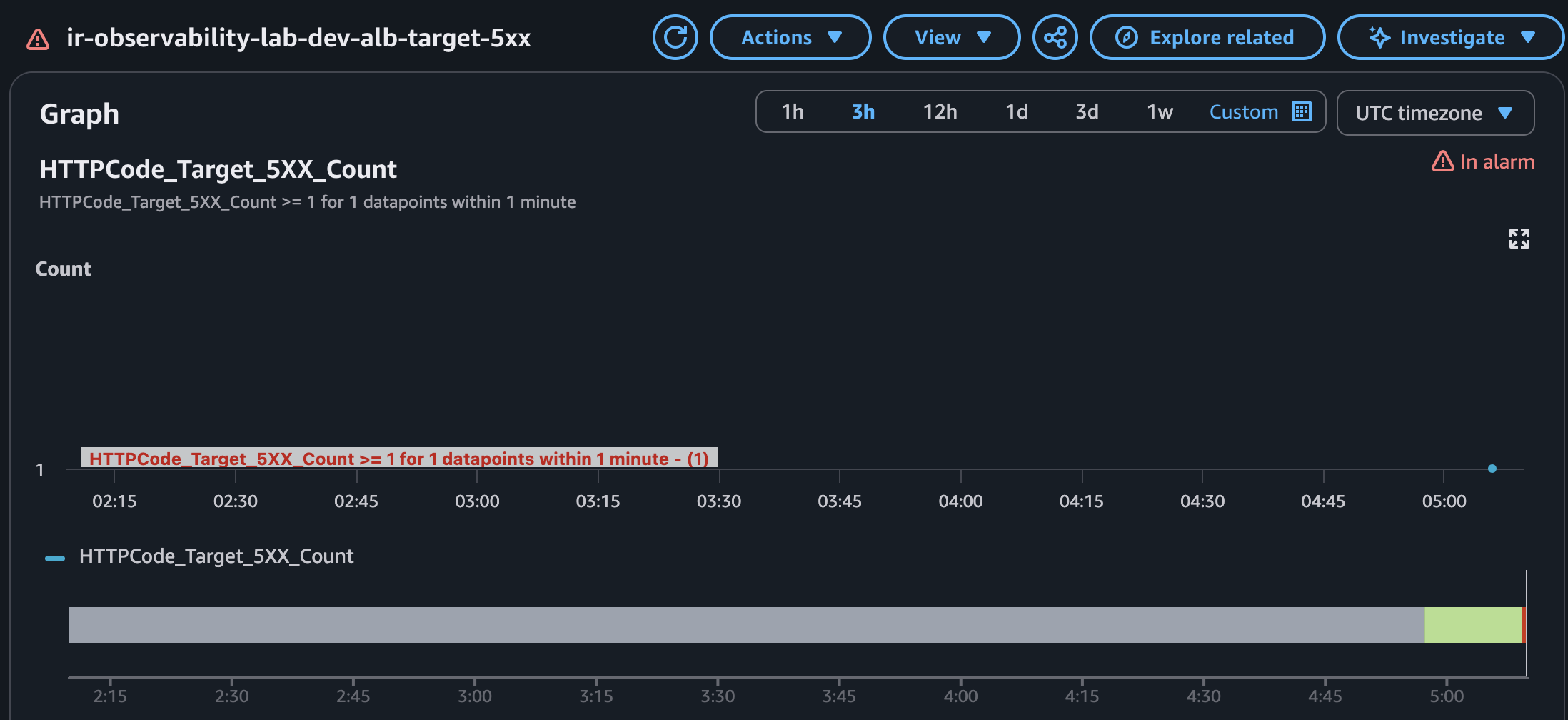
### 3. 5xx 告警與 SNS 通知
故障注入後,ALB 5xx alarm 進入 `In alarm`,SNS email 成功送出通知。

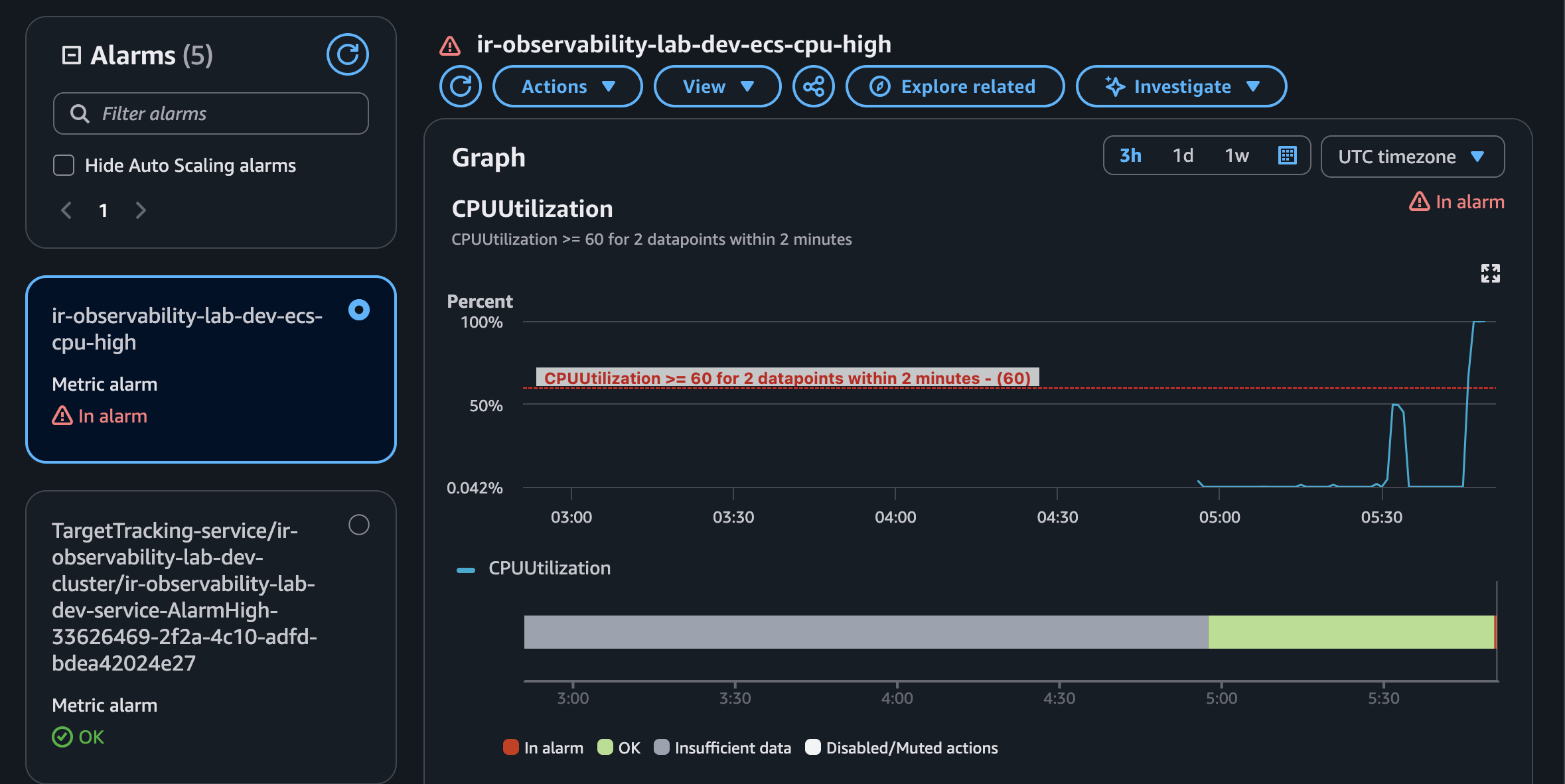
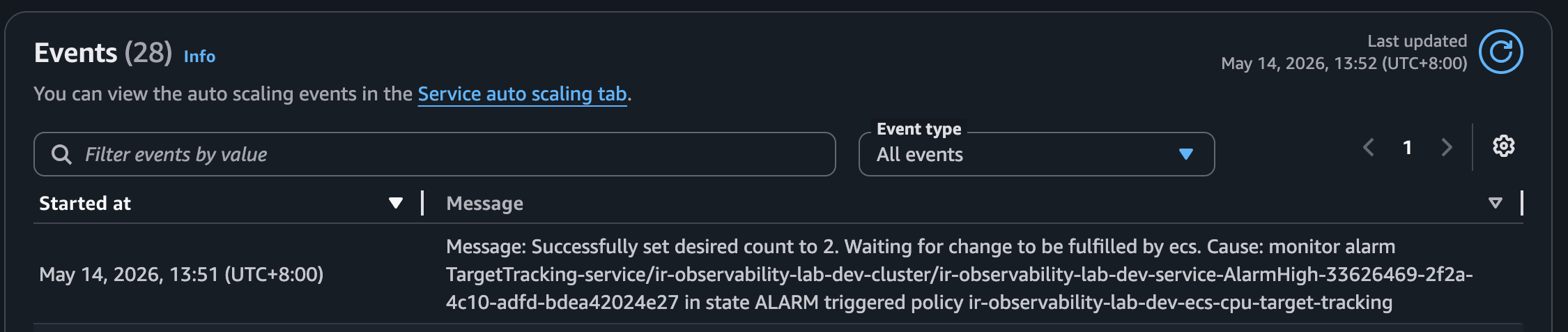
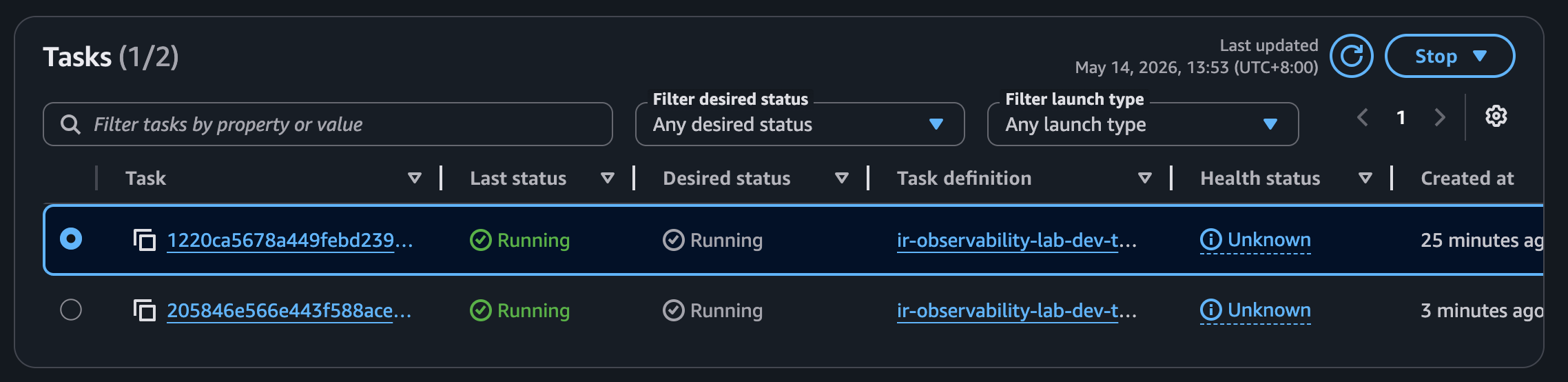
### 4. 高 CPU 告警與 Auto Scaling
高併發 CPU load 使 ECS CPU alarm 觸發,Application Auto Scaling 將 desired count 提高到 2。
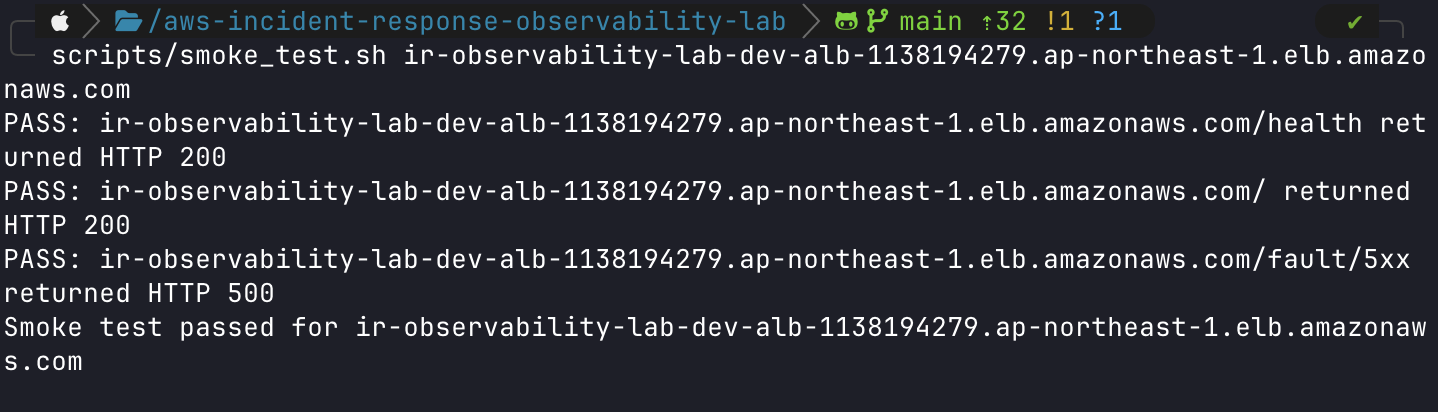
### 5. 復原驗證
故障處理後重新執行 smoke test,確認服務回到可用狀態。
## 文件
- [Architecture](docs/ARCHITECTURE.md)
- [Runbook](docs/RUNBOOK.md)
- [RCA 範例:ALB 5xx 故障注入](docs/RCA_2026-05-14_alb_5xx_fault_injection.md)
- [RCA 範例:CPU 高負載與 ECS Auto Scaling](docs/RCA_2026-05-14_cpu_autoscaling.md)
- [Validation Guide](docs/VALIDATION.md)
- [Roadmap](docs/ROADMAP.md)
标签:ALB, API集成, ASM汇编, AWS, CloudWatch, DevSecOps, DPI, ECS, Fargate, IT运维管理, Python, RCA, Runbook, SNS, Terraform, 上游代理, 事后复盘, 云原生架构, 压力测试, 可观测性, 告警通知, 指标监控, 故障注入, 无后门, 混沌工程, 系统稳定性, 自动化扩容, 请求拦截, 负载均衡, 运维, 逆向工具, 配置错误