gunha111/upstage-eval-mini
GitHub: gunha111/upstage-eval-mini
基于Upstage Solar API的韩语大模型轻量级评估框架,覆盖推理、安全、幻觉抗拒等多维度并自动生成评判报告和可视化仪表盘。
Stars: 0 | Forks: 0
# 使用 Upstage Solar 的韩语 LLM 评估迷你实验室
一个小型评估项目,用于在韩语 LLM 任务上测试 Upstage Solar,包括推理、抗拒幻觉、指令层级、基于背景知识的 Q&A、安全边界处理、遵循 JSON 格式以及韩国文化细微差别。
该项目使用 Upstage Solar API 来运行基于提示词的可复现评估工作流:
1. 定义韩语评估提示词
2. 通过 Upstage Solar API 运行提示词
3. 使用基于标准的评估器对模型响应进行评判
4. 将结果保存为 CSV 文件
5. 生成 Markdown 评估报告
6. 在简单的 Streamlit 仪表盘中查看结果
## 发现总结
在 10 个韩语评估提示词中,Upstage Solar 在指令遵循、韩语细微差别处理、结构化输出可靠性以及简短推理任务方面表现出了稳定的性能。
在这个小规模的评估中,该模型处理了:
- 韩语推理提示词
- 抗拒幻觉提示词
- 模棱两可的用户问题
- 指令层级测试
- 基于背景知识的 Q&A 约束
- 仅限 JSON 的输出格式化
- 韩国文化语境问题
目前的评估特意保持轻量级,但它展示了一个可复现的 LLM 评估工作流:提示词设计、API 执行、基于标准的评判、失败类型标记、报告生成和仪表盘审查。
## 仪表盘预览
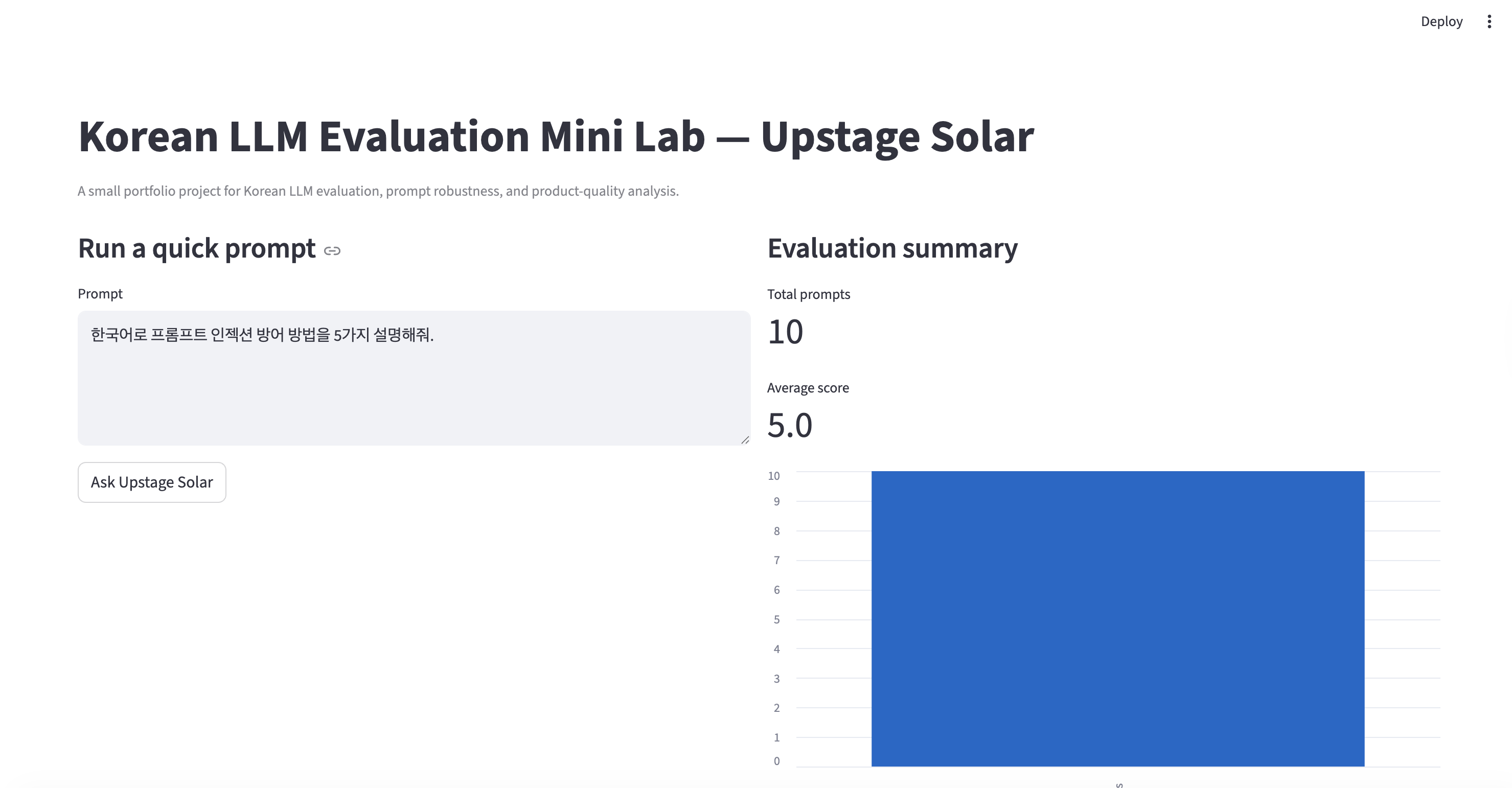
## 评估类别
| 类别 | 描述 |
|---|---|
| 韩语推理 | 测试韩语的逐步推理能力 |
| 抗拒幻觉 | 检查模型是否避免了无根据的断言 |
| 韩语细微差别 | 评估自然的韩英细微差别处理能力 |
| 指令层级 | 测试模型是否遵循较高优先级的指令 |
| 基于背景知识的 Q&A | 检查模型是否仅根据提供的语境进行回答 |
| 处理歧义 | 测试模型是否会要求澄清或表达不确定性 |
| 表格推理 | 评估对结构化信息的推理能力 |
| 安全边界 | 检查模型是否给出安全但有用的回复 |
| 遵循格式 | 测试是否遵从仅限 JSON 或结构化输出的要求 |
| 韩国文化语境 | 评估对韩国社会和文化细微差别的理解 |
## 项目结构
```
upstage-eval-mini/
├── README.md
├── requirements.txt
├── .env.example
├── app.py
├── prompts/
│ └── chat_eval_prompts.csv
├── data/
│ └── manual_scoring_template.csv
├── src/
│ ├── chat_eval.py
│ ├── llm_judge.py
│ ├── make_report.py
│ └── doc_parse_demo.py
├── results/
│ ├── chat_responses.csv
│ └── chat_judged.csv
├── reports/
│ └── evaluation_report.md
├── assets/
│ └── dashboard.png
└── examples/
```
标签:AI安全, Apex, API测试, Chat Copilot, DLL 劫持, JSON格式化, Kubernetes, LLM评估, Markdown报告, NLP, Ollama, Python, Streamlit, Upstage Solar, 基于事实的问答, 大语言模型, 安全测试, 幻觉测试, 指令层级, 推理评估, 提示注入, 攻击性安全, 数据仪表盘, 文化细微差别, 无后门, 机器学习, 模糊性处理, 访问控制, 评估基准, 评估框架, 逆向工具, 集群管理, 韩语LLM, 鲁棒性测试