mus1afq/Hybrid-IDS-Containers
GitHub: mus1afq/Hybrid-IDS-Containers
结合 eBPF 系统调用追踪与网络遥测的 Docker 容器混合入侵检测系统,通过后期融合双模态概率提升容器运行时的威胁检测率。
Stars: 0 | Forks: 0
# 面向容器化环境的混合入侵检测系统




## 概述
这是一个双模型 pipeline,它在 runtime 监控 Docker 容器,独立地从 syscall 追踪和网络流中分类行为,并通过确定性规则融合这两路概率流。该项目作为伯明翰城市大学网络安全理学学士(BSc)毕业论文的最终成果进行开发与评估,荣获了一等荣誉学位。
| 指标 | 仅 Syscall | 仅网络 | **混合** |
| ----------------------------------------------- | ------------ | ------------ | ---------- |
| F1 (synthetic fusion-rule validation, n=580) | 0.719 | 0.841 | **0.898** |
| Recall (synthetic) | 0.561 | 0.726 | **0.815** |
| FPR (synthetic, curated set) | 0.000 | 0.000 | **0.000** |
| Runtime accuracy (6-container live demo) | — | — | **0.667** |
在 15 秒的检测窗口下,synthetic 的 F1 峰值达到了 **0.957**。由于 distribution shift,runtime 性能有所下降;我们在局限性部分对此进行了公开讨论。
## 评估体系
本项目报告了三种不同评估体系的结果。它们不可互换,因此 README 标题中的数字带有体系标签。
概述:
| 体系 | 衡量内容 | 状态 |
| ------------------------------------- | ------------------------------------------------------------- | ------------------- |
| **Synthetic fusion-rule validation** | 确定性规则是否在精心配对的数据集 (n=580) 上优于任何单一模态。 | 已实现并报告。 |
| **Live runtime demo evaluation** | 端到端 pipeline 能否在六个预设的 Docker 场景中产生合理的判定。 | 已实现并报告。 |
| **Production evaluation** | 泛化到具有真实 class imbalance、drift 以及数万个样本的真实工作负载。 | **未来工作**,未实现。 |
请将 0.898 的 F1 数值视为 fusion-rule validation 的结果,而不是一个部署声明。请将 0.000 的 FPR 视为平衡的精选数据集的一个属性,而不是现实世界中的保证。
## 项目意义
容器 runtime 是短暂且易失的,并与宿主机共享 kernel。传统的基于主机的 IDS 工具假设 OS 是长期存在的,并且磁盘工件是持久的。网络 IDS 会遗漏所有留在容器内部的活动。两种视角都是片面的。研究问题在于,是否通过 late fusion 结合它们能够比单独使用任何一种都能提高检测率。
交付成果是一个可运行的 pipeline,它从 live 容器中捕获两种 telemetry 流,对其进行分类,融合结果,并生成适合研究论文的评估指标。
## 架构
```
┌──────────────────────────────────────────────────────────────────────┐
│ Docker Container Workload │
└──────────────────────┬─────────────────────────┬─────────────────────┘
│ │
syscalls │ │ network traffic
▼ ▼
┌──────────────────┐ ┌──────────────────┐
│ sysdig (eBPF) │ │ tshark │
└────────┬─────────┘ └────────┬─────────┘
│ │
sysdig_raw.txt *.pcap
│ │
┌────────▼─────────┐ ┌────────▼─────────┐
│ Feature extract │ │ Feature extract │
│ + schema align │ │ + schema align │
└────────┬─────────┘ └────────┬─────────┘
│ │
┌────────▼─────────┐ ┌────────▼─────────┐
│ Logistic Reg. │ │ Random Forest │
│ (CHIDS-trained) │ │ (Bot-IoT trained)│
└────────┬─────────┘ └────────┬─────────┘
│ p_sys p_net │
└──────────┬───────────────┘
▼
┌─────────────────────────┐
│ Late-fusion decision │
│ (deterministic rule) │
└────────────┬────────────┘
▼
Benign / Malicious
```
## 结果
### Synthetic fusion-rule validation (n = 580)
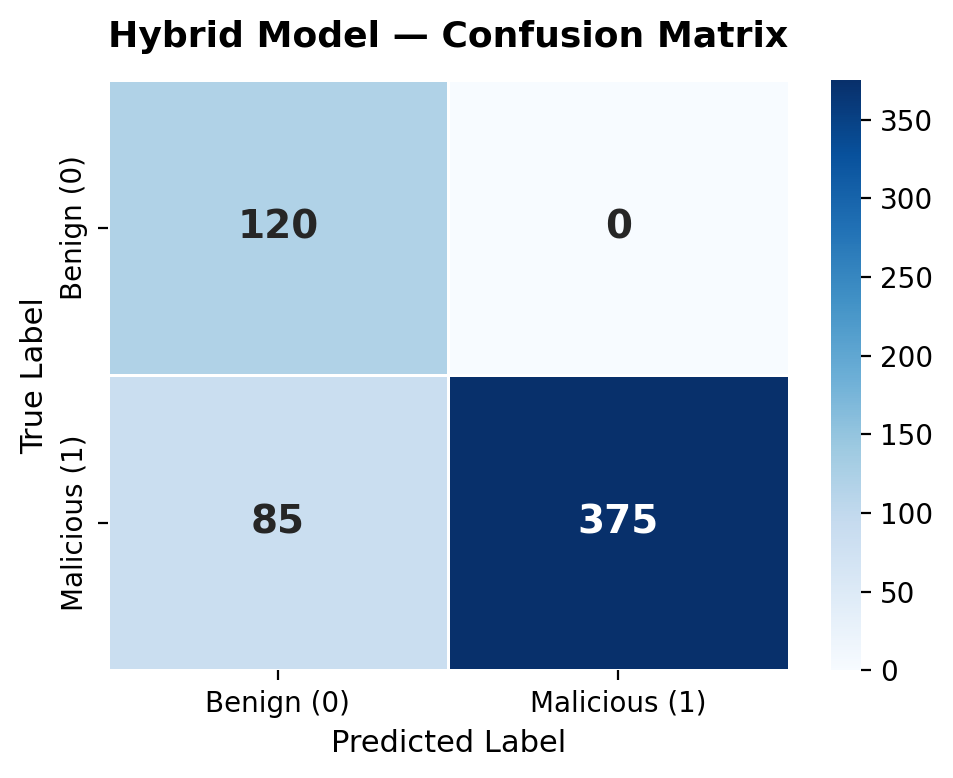
混合模型的混淆矩阵:
| | 预测为良性 | 预测为恶意 |
| -------------------------- | ---------------- | ------------------- |
| **实际良性 (120)** | 120 | 0 |
| **实际恶意 (460)** | 85 | 375 |
零误报是此 synthetic 配对数据集的一个属性,而不是现实世界中的保证。该数据集是平衡且经过精心筛选的;production 噪声会改变这一点。请将 FPR 数值视为受控条件下的上限。

## 检测窗口分析
混合 IDS 的一个核心设计问题是 telemetry 捕获窗口 (N) 如何影响检测准确率。较短的窗口检测速度更快,但积累的信号较少。较长的窗口积累更多信号,但会延迟检测。因此,在四个 N 值下对模型进行了评估,以找到最佳工作点。
| 窗口 (N) | 仅 Syscall | 仅网络 | 混合 |
|------------|--------------|--------------|------------|
| 5s | 0.6818 | 0.7612 | 0.8335 |
| 10s | 0.6932 | 0.8205 | 0.9112 |
| 15s | 0.7204 | 0.8354 | **0.9569** |
| 30s | 0.7187 | 0.8413 | 0.8982 |
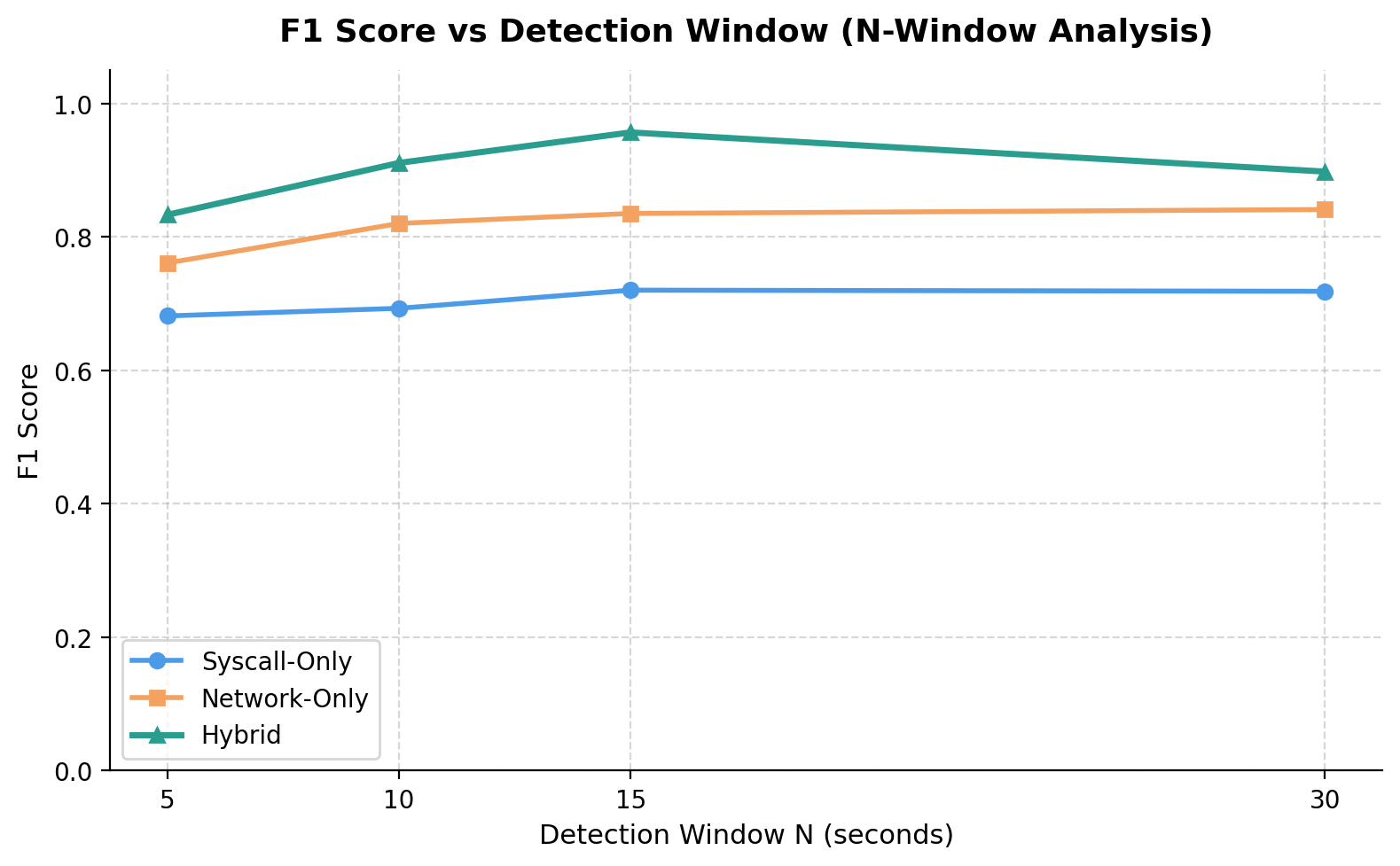
混合模型的峰值 F1 出现在 N = 15s 时。低于 15s 时,syscall 追踪无法积累足够的事件来区分良性和恶意工作负载。超过 15s 后,额外的 telemetry 并未提高 F1,只会增加检测决策的 latency。混合模型在测试的每个窗口都超过了两个单领域基线,其中在 N = 15s 时获得了最大的绝对增益。
### Live runtime demo (6 个 Docker 容器)
| 场景 | 真实标签 | 混合判定 | 备注 |
| -------- | --------------------------------- | -------------- | ------------------ |
| 1 | 良性工作负载 (nginx) | 良性 | clean |
| 2 | 良性工作负载 (python REST API) | 良性 | clean |
| 3 | 反弹 shell | 恶意 | syscall 主导 |
| 4 | 挖矿程序 | 恶意 | 网络主导 |
| 5 | 提权尝试 | 良性 (FN) | distribution shift |
| 6 | 数据泄露 | 良性 (FN) | distribution shift |
Runtime 准确率为 **4/6 = 66.7%**。从 synthetic 到 runtime 的性能下降是项目中最有趣的发现,而不是标题中的 F1 数字。它证明了当训练数据与部署条件不匹配时,基于 ML 的 IDS 会变得多么脆弱。完整分析请参阅论文。
## 融合工作原理
融合层是一个确定性规则,而不是一个学习型的 meta-classifier。这是为了可解释性而做出的刻意选择——每个判定都可以追溯到两个概率和一个固定的规则,中间没有不透明的第二阶段模型。
```
def hybrid_decision(p_sys: float, p_net: float) -> str:
if p_sys >= 0.60: # syscall model highly confident
return "MALICIOUS"
if p_net >= 0.50 and p_sys >= 0.10: # network flags + syscall suspicion floor
return "MALICIOUS"
return "BENIGN"
```
阈值在验证集上进行了调优,目标是在最大化 recall 的同时,保持良性样本的零误报。设置 syscall 可疑度下限 (0.10) 是因为,对于具有突发流量的良性工作负载,纯粹的网络信号被证明充满噪声;要求少量的 syscall 印证消除了这些误报。
## 仓库结构
```
.
├── data/
│ ├── raw/ # CHIDS + Bot-IoT source datasets
│ └── runtime/ # sysdig + tshark captures from live containers
├── models/
│ ├── syscall/ # Logistic Regression + scaler
│ └── network/ # Random Forest
├── src/
│ ├── common/ # shared config and helpers
│ ├── syscall/ # training / inference / evaluation
│ ├── network/ # training / inference / evaluation
│ └── hybrid/ # fusion / evaluation / runtime capture
├── tests/ # End-to-end validation suite + unit tests
├── demo/ # Four prepared runtime scenarios (see below)
├── outputs/
│ ├── predictions/ # Per-model and hybrid prediction CSVs
│ ├── metrics/ # Evaluation tables
│ └── plots/ # Confusion matrices, ROC curves, N-window plot
├── requirements.txt # Core dependencies
├── changelog.md
├── LICENSE # MIT
└── README.md
```
## 快速开始
```
# 1. Clone and install core dependencies
git clone https://github.com/mus1afq/Hybrid-IDS-Containers.git
cd Hybrid-IDS-Containers
pip install -r requirements.txt
# 2. Reproduce the headline synthetic metrics
python3 src/hybrid/evaluation/evaluate_hybrid_synthetic.py
# 3. Full validation suite
bash tests/run_all_tests.sh
```
对于实时捕获 pipeline(需要 `docker`、`sysdig`、`tshark`):
```
# Step 1: capture syscalls + packets and emit a run_id
bash src/hybrid/runtime/run_and_capture.sh
# Step 2: extract features. The syscall extractor refuses to produce output
# silently from synthetic profiles. To run a demo without a live capture, pass
# the explicit flag below; the output will be marked SYNTHETIC.
python3 src/hybrid/runtime/extract_syscall_features.py
python3 src/hybrid/runtime/extract_network_features.py
# Step 3: align schemas
python3 src/hybrid/runtime/align_network_schema.py
# Step 4: inference
python3 src/syscall/inference/run_syscall_inference.py
python3 src/network/inference/run_network_inference.py
# Step 5: fuse predictions by run_id and evaluate
python3 src/hybrid/fusion/run_hybrid_fusion.py
python3 src/hybrid/evaluation/evaluate_hybrid_runtime.py
```
### 无需实时捕获的演示(synthetic 回退,明确的选择)
如果 `docker`、`sysdig` 或 `tshark` 不可用,而您只是想在视觉上过一遍 pipeline,syscall 提取器接受 `--allow-synthetic-fallback`。输出将被显眼地标记为 synthetic,且不得将其报告为成功的实时捕获:
```
python3 src/hybrid/runtime/extract_syscall_features.py --allow-synthetic-fallback
```
## 改进方向
写于口头答辩之前。评分者指出了其中的大部分问题。
- **更大、更嘈杂的评估集。** n=580 较小;完美的 precision 数字反映了这一点。包含 5–10k 样本且具有真实 class imbalance 的数据集将能够对融合规则进行适当的压力测试。
- **在相同的原始样本上进行端到端混合评估。** 目前的 synthetic 混合指标使用的是预先配对的概率 CSV,而不是针对相同的输入追踪运行两个 pipeline。针对配对的原始捕获重新评估将增强该声明的说服力。
- **通过学习而不是手动设置阈值。** 对这三个阈值进行网格搜索,并在留出集上进行优化,将比凭经验选择更有说服力。
- **Concept drift 处理。** Runtime 准确率下降是一个 distribution shift 问题。流式重训循环或校准步骤将是下一个研究方向。
- **在 runtime 增加攻击的多样性。** 六个场景只能算作演示,而非评估。
## 项目时间线
该项目贯穿了整个最后学年。各阶段如下。
| 阶段 | 期间 | 里程碑 |
| ------------------- | ----------------- | --------------------------------------------------------------------------- |
| 规划 | 2025年9月 - 10月 | 问题定义,导师批准,数据集选择 (CHIDS, Bot-IoT) |
| 数据 pipeline | 2025年10月 – 11月 | 预处理,schema 对齐脚本,特征提取模块 |
| 建模 | 2025年11月 – 2026年1月 | Syscall LR 分类器,网络 RF 分类器,单模态基线 |
| 融合 | 2026年2月 | Late-fusion 规则设计,阈值调优,synthetic 评估 |
| Runtime 捕获 | 2026年2月–3月 | sysdig + tshark Docker pipeline,演示场景构建 |
| 评估 | 2026年3月–4月 | N 窗口分析,runtime 实验,distribution shift 调查 |
| 论文撰写 | 2026年4月–5月 | 论文起草,结果汇总,图表生成 |
| 提交与答辩 | 2026年5月–6月 | 最终提交,答辩准备,仓库定稿 |
## 技术栈
| 层级 | 工具 |
| ------------------- | --------------------------------------------------------- |
| Runtime 捕获 | Docker, sysdig (eBPF), tshark |
| 特征工程 | Python, pandas, NumPy |
| 建模 | scikit-learn (Logistic Regression, Random Forest), joblib |
| 评估 | matplotlib, seaborn |
| 数据集 | CHIDS (syscalls), Bot-IoT (网络流) |
## 局限性
在此明确列出,因为不应将本项目视为 production-ready。
- 0.000 的 synthetic FPR 是精心筛选的评估集的属性,而不是可泛化的声明。
- Runtime 评估涵盖了六个场景。在 distribution shift 下出现的两次漏报将准确率拉低至 66.7%。
- 两个训练数据集都是静态的、过时的,不能反映现代攻击者针对容器化微服务的攻击行为。
- 融合阈值是在单个验证集上手动调优的。
- 该系统是离线和面向批处理的。Latency 未经过优化。
## 参考文献
- CHIDS Dataset — Container Host Intrusion Detection System 数据集,用于 syscall 模型训练。
- Bot-IoT Dataset — Koroniotis 等人,2019 年,用于网络模型训练。
- sysdig — runtime syscall 捕获 ()。
- tshark — 数据包捕获与分析 (
- LinkedIn:[Mustafa Sheikh](https://uk.linkedin.com/in/mustafa-sheikh-357715341)
## 许可证
MIT — 详见 [`LICENSE`](LICENSE)。
标签:Apex, Docker, Docker镜像, Python, Web截图, 入侵检测系统, 安全数据湖, 安全防御评估, 容器安全, 无后门, 机器学习, 网络遥测, 请求拦截, 逆向工具