sumeshi/forensia
GitHub: sumeshi/forensia
forensia 是一款利用本地 LLM 辅助 Windows 数字取证调查的实验性工具,通过将调查拆分为可审计的微小步骤并配合确定性校验,使小型本地模型在离线环境中也能完成取证分析与报告生成。
Stars: 0 | Forks: 0
# forensia

**你的本地 AI 助手,专为周末的取证工作而生。**
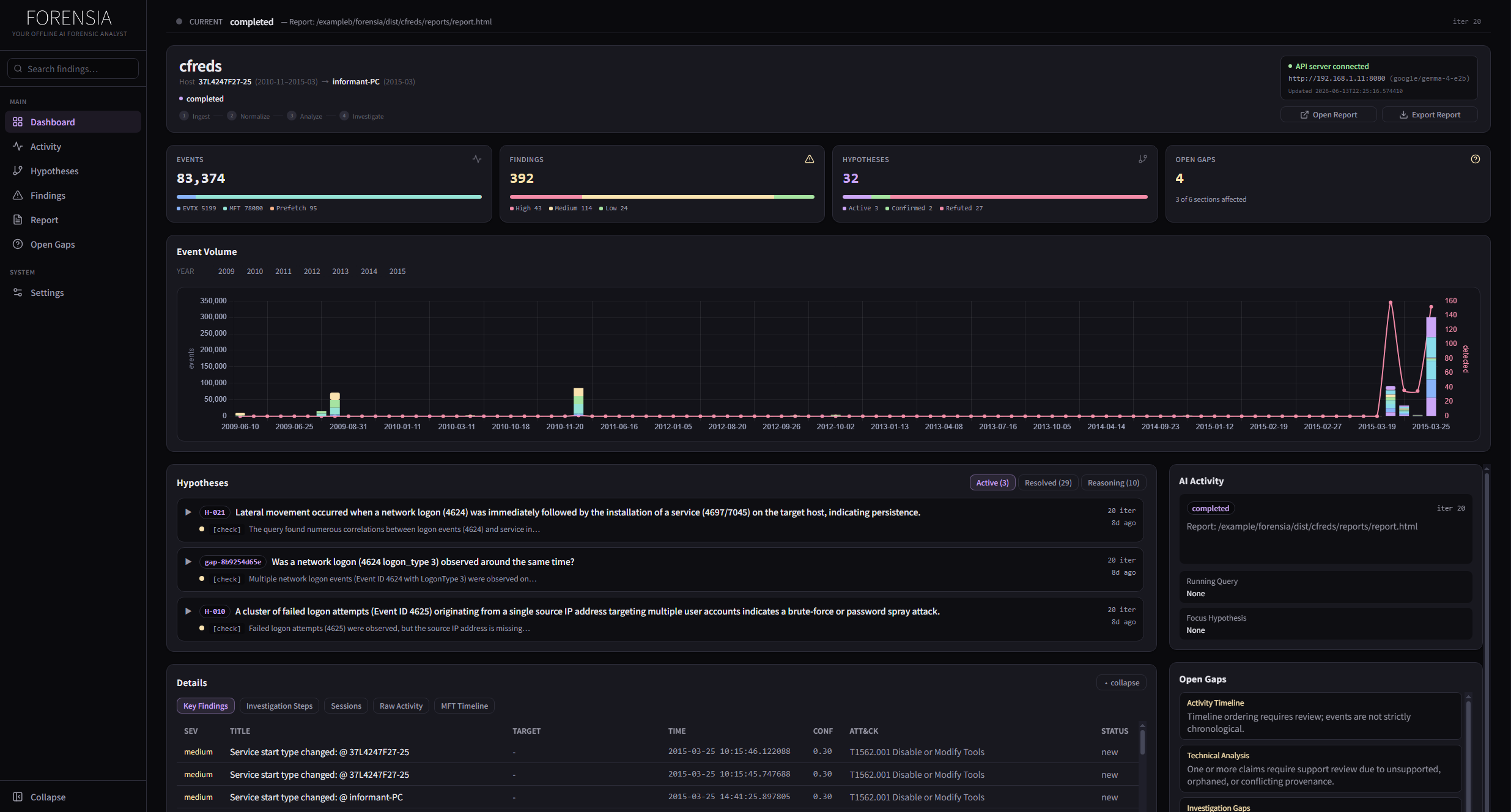 Investigation cockpit showing case progress, hypotheses, findings, and report sections.
Investigation cockpit showing case progress, hypotheses, findings, and report sections.
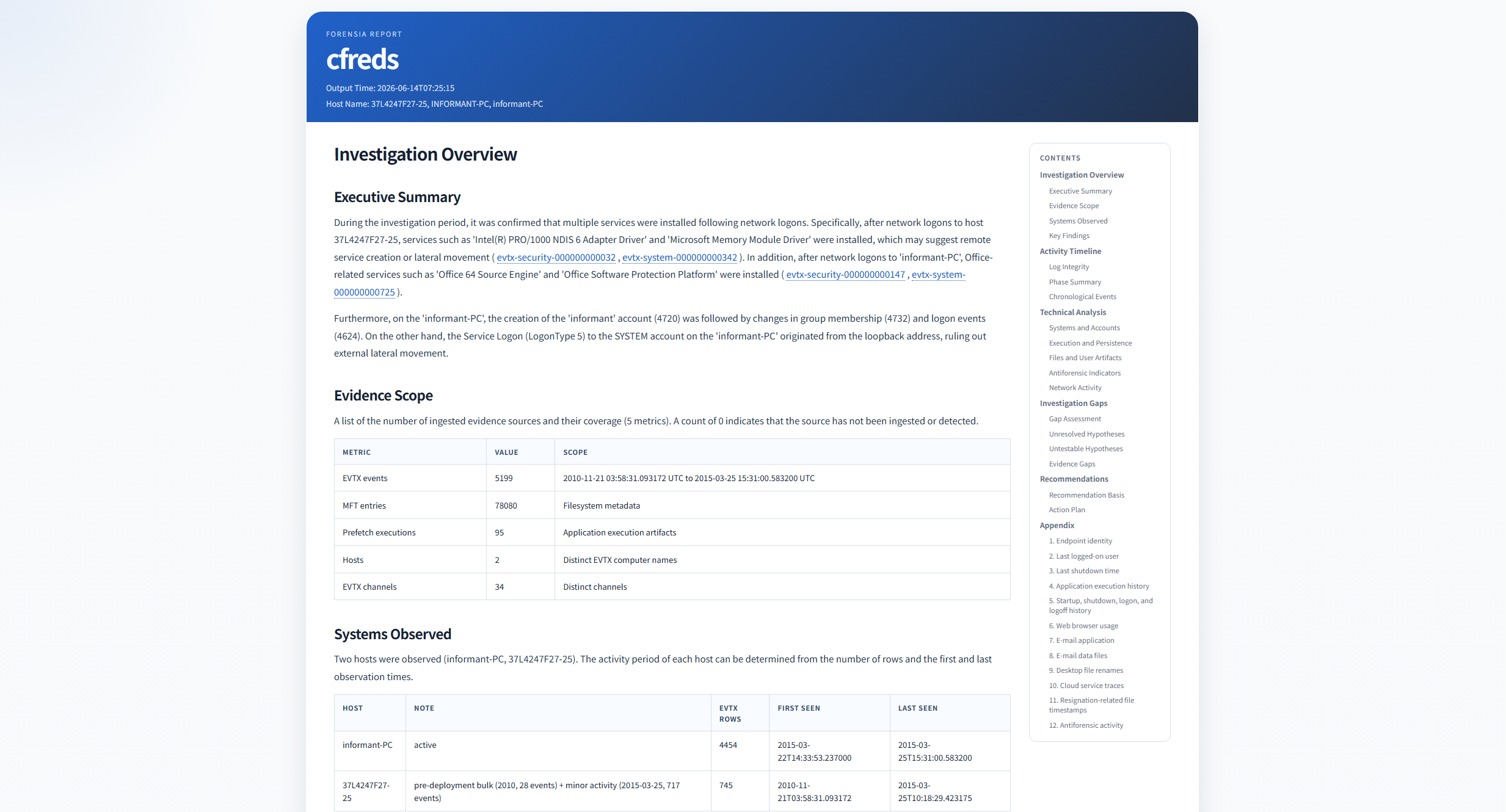 Generated forensic report with evidence-backed findings and investigation context.
## 概述
`forensia` 融合了**取证**与 **AI**。
这是一个利用本地 LLM 辅助 Windows 取证调查的实验性工具。其目标并非将整个案件直接丢给模型,并期望它能像资深分析师一样运作。相反,forensia 在模型周围构建了一套框架:将调查拆分为微小且可检查的步骤——收集证据、生成假设、将其与源数据核对、提取发现并持续更新报告——而模型每次只需处理一个细小步骤。
该项目源于两个实际限制:
因此,forensia 选择了截然相反的路线:依靠围绕它们构建的架构,使小型本地模型发挥大作用。
像 `google/gemma-4-e4b` 或 `qwen/qwen3.5-9b` 这样的模型,还不足以强大到能够在没有辅助的情况下阅读所有内容、记住所有内容,并连续数小时进行正确的推理。因此,forensia 结合了规范化证据、基于规则的信号、结构化 prompt、确定性检查以及持久化记忆,从而确保永远不会直接要求模型一次性解决整个案件。
## 开发状态
forensia 目前处于**早期开发**阶段。
其架构、内部 schema、模板、规则格式、命令行界面以及仓库结构可能会发生重大变化。目前的设计应被视为正在进行的研究原型,而非稳定的平台。
欢迎各种贡献,同时预期会有破坏性更新。正因如此,对核心逻辑的贡献才是最具价值的。针对特定场景的部分(例如单一规则)优先级较低:它们变化很快,根据你的需求,将其维护在你自己的 fork 中(按用户或任务进行微调)可能比向上游提交更容易。
## 为什么会有这个项目
现代的前沿模型令人惊叹。Claude 变得越来越好,GPT 也变得越来越好,未来一片光明。
但这在你处理敏感的应急响应数据时并没有太大帮助。
在许多真实的调查中,证据绝不能离开组织。它不能被上传到云 API。甚至在连接到网络的机器上进行操作都不安全。如果你足够谨慎地去妥善调查一起安全事件,你可能也会偏执到选择在离线状态下工作。在最敏感的案件中,甚至连分析环境都可能需要保持隔离、被擦除或事后被销毁。
所以问题是:
我尝试过。
**不能直接用。**
小型的本地模型会误解严格的指令,丢失长上下文的线索,遗忘之前的推理,并且有时会一遍又一遍地重复同样糟糕的推论。解决办法不是假装它们比实际上更聪明。解决办法在于架构。
forensia 的初衷就是通过用结构包围弱模型,使其变得实用。
## 周末难题
应急响应请求通常在周五送达。
这种模式令人似曾相识:
* 攻击者总是在无人值守时入侵系统。
* 周一,有人注意到了一些异常。
* 周二,内部进行了讨论。
* 到了周三,大家才承认这可能是一起安全事件。
* 周四,有人决定询问供应商。
* 周五早上,请求终于到了工程师手里。
* 报告要求在周一前交付。
* 而数据甚至还没传过来。
这让人精疲力尽。
要是有人能替你周末加班就好了。
没有这样的人。
但也许能有一个 AI 伙伴。
## 设计原则
### 1. 独立作战
forensia 旨在能够在离线或隔离环境中持续工作。
如果某个参与调查的系统在周末一直保持网络连接,那么周一早上等着的可能不是一份进度报告。而可能是一封勒索信。
因此,其最低运行假设被刻意设定得很低:一台本地机器、一块便宜的 GPU(如果有的话)、存储空间以及电力。
### 2. 不要信任 AI
forensia 不会将模型视为聪明的调查员。
模型只是一个组件。它不是决策权威。
该系统将工作划分为细小的角色:识别信息缺口、起草假设、规划查询、编写 SQL、审查结论、提取发现、构思大纲以及编写段落。每个角色的设定都极其聚焦,其目的用一句话就能概括。
任何可以被确定性决定的事情都应该由代码来处理,而不是由模型来处理。SQL 校验、重复查询检测、结构化路由、兜底逻辑、证据映射以及一致性检查都必须是可预测且可审计的。
模型得出的结论并不会仅仅因为模型说是真的就被接受。各项主张必须基于实际的查询结果和源自数据的证据。如果一项发现无法追溯到证据,它就不应成为持久记忆。
### 3. 花费时间,而非透支信任
forensia 不会试图通过一次运行就得出完美的结论。
相反,它会反复生成、测试、优化并记录假设。整个调查过程本身应该是可观测的。人类应该能够询问:
并追踪答案的来源,一直追溯到证据、中间推理以及报告输出。
报告并不是只在最后才编写。它会随着调查的推进不断刷新。已确认的发现会更新报告;未解决的缺口可以反馈给下一个调查周期。
## forensia 不是什么
forensia 并不打算仅仅成为现有检测规则的简单封装。
目前已经存在许多有价值的规则生态系统(例如 Sigma 规则),它们代表了大量的人类知识。但仅仅将这些结果输入给 LLM 并要求生成摘要,并不是本项目的主要目标。
那样只会让 AI 沦为检测结果的摘要生成器。
forensia 正在尝试探索一些不同的东西:
规则依然重要。本项目在有助于调查的地方包含了关键规则。但更重要的设计理念是:
这是 forensia 规则设计背后最重要的思想。一个好的规则不应仅仅记录检测到了什么——它还应该帮助系统理解用户接下来可能想要调查什么。随着模型的改进,这种富含意图的结构应该会变得更有价值:模型不仅能读出检测到了什么,还能明白为什么该检测结果很重要,以及调查的下一步方向。
## 架构概览
forensia 的运作方式是一个调查循环。
```
flowchart LR
A["Artifacts
Generated forensic report with evidence-backed findings and investigation context.
## 概述
`forensia` 融合了**取证**与 **AI**。
这是一个利用本地 LLM 辅助 Windows 取证调查的实验性工具。其目标并非将整个案件直接丢给模型,并期望它能像资深分析师一样运作。相反,forensia 在模型周围构建了一套框架:将调查拆分为微小且可检查的步骤——收集证据、生成假设、将其与源数据核对、提取发现并持续更新报告——而模型每次只需处理一个细小步骤。
该项目源于两个实际限制:
因此,forensia 选择了截然相反的路线:依靠围绕它们构建的架构,使小型本地模型发挥大作用。
像 `google/gemma-4-e4b` 或 `qwen/qwen3.5-9b` 这样的模型,还不足以强大到能够在没有辅助的情况下阅读所有内容、记住所有内容,并连续数小时进行正确的推理。因此,forensia 结合了规范化证据、基于规则的信号、结构化 prompt、确定性检查以及持久化记忆,从而确保永远不会直接要求模型一次性解决整个案件。
## 开发状态
forensia 目前处于**早期开发**阶段。
其架构、内部 schema、模板、规则格式、命令行界面以及仓库结构可能会发生重大变化。目前的设计应被视为正在进行的研究原型,而非稳定的平台。
欢迎各种贡献,同时预期会有破坏性更新。正因如此,对核心逻辑的贡献才是最具价值的。针对特定场景的部分(例如单一规则)优先级较低:它们变化很快,根据你的需求,将其维护在你自己的 fork 中(按用户或任务进行微调)可能比向上游提交更容易。
## 为什么会有这个项目
现代的前沿模型令人惊叹。Claude 变得越来越好,GPT 也变得越来越好,未来一片光明。
但这在你处理敏感的应急响应数据时并没有太大帮助。
在许多真实的调查中,证据绝不能离开组织。它不能被上传到云 API。甚至在连接到网络的机器上进行操作都不安全。如果你足够谨慎地去妥善调查一起安全事件,你可能也会偏执到选择在离线状态下工作。在最敏感的案件中,甚至连分析环境都可能需要保持隔离、被擦除或事后被销毁。
所以问题是:
我尝试过。
**不能直接用。**
小型的本地模型会误解严格的指令,丢失长上下文的线索,遗忘之前的推理,并且有时会一遍又一遍地重复同样糟糕的推论。解决办法不是假装它们比实际上更聪明。解决办法在于架构。
forensia 的初衷就是通过用结构包围弱模型,使其变得实用。
## 周末难题
应急响应请求通常在周五送达。
这种模式令人似曾相识:
* 攻击者总是在无人值守时入侵系统。
* 周一,有人注意到了一些异常。
* 周二,内部进行了讨论。
* 到了周三,大家才承认这可能是一起安全事件。
* 周四,有人决定询问供应商。
* 周五早上,请求终于到了工程师手里。
* 报告要求在周一前交付。
* 而数据甚至还没传过来。
这让人精疲力尽。
要是有人能替你周末加班就好了。
没有这样的人。
但也许能有一个 AI 伙伴。
## 设计原则
### 1. 独立作战
forensia 旨在能够在离线或隔离环境中持续工作。
如果某个参与调查的系统在周末一直保持网络连接,那么周一早上等着的可能不是一份进度报告。而可能是一封勒索信。
因此,其最低运行假设被刻意设定得很低:一台本地机器、一块便宜的 GPU(如果有的话)、存储空间以及电力。
### 2. 不要信任 AI
forensia 不会将模型视为聪明的调查员。
模型只是一个组件。它不是决策权威。
该系统将工作划分为细小的角色:识别信息缺口、起草假设、规划查询、编写 SQL、审查结论、提取发现、构思大纲以及编写段落。每个角色的设定都极其聚焦,其目的用一句话就能概括。
任何可以被确定性决定的事情都应该由代码来处理,而不是由模型来处理。SQL 校验、重复查询检测、结构化路由、兜底逻辑、证据映射以及一致性检查都必须是可预测且可审计的。
模型得出的结论并不会仅仅因为模型说是真的就被接受。各项主张必须基于实际的查询结果和源自数据的证据。如果一项发现无法追溯到证据,它就不应成为持久记忆。
### 3. 花费时间,而非透支信任
forensia 不会试图通过一次运行就得出完美的结论。
相反,它会反复生成、测试、优化并记录假设。整个调查过程本身应该是可观测的。人类应该能够询问:
并追踪答案的来源,一直追溯到证据、中间推理以及报告输出。
报告并不是只在最后才编写。它会随着调查的推进不断刷新。已确认的发现会更新报告;未解决的缺口可以反馈给下一个调查周期。
## forensia 不是什么
forensia 并不打算仅仅成为现有检测规则的简单封装。
目前已经存在许多有价值的规则生态系统(例如 Sigma 规则),它们代表了大量的人类知识。但仅仅将这些结果输入给 LLM 并要求生成摘要,并不是本项目的主要目标。
那样只会让 AI 沦为检测结果的摘要生成器。
forensia 正在尝试探索一些不同的东西:
规则依然重要。本项目在有助于调查的地方包含了关键规则。但更重要的设计理念是:
这是 forensia 规则设计背后最重要的思想。一个好的规则不应仅仅记录检测到了什么——它还应该帮助系统理解用户接下来可能想要调查什么。随着模型的改进,这种富含意图的结构应该会变得更有价值:模型不仅能读出检测到了什么,还能明白为什么该检测结果很重要,以及调查的下一步方向。
## 架构概览
forensia 的运作方式是一个调查循环。
```
flowchart LR
A["Artifacts
EVTX / MFT / Prefetch / ..."] A -->|Ingest / Normalize| C C[("Case State
normalized evidence")] C --> D["Rule Engine
Findings / Key Points"] subgraph L["Investigation Loop"] D --> E["Hypothesis Seeding
rules + gap analysis"] E --> P["Planner
query intent → SQL composition"] P --> X["Executor
query execution + fallback search"] X --> CK["Checker
verdict review → finding extraction"] CK --> TR["Progress Tracker
confirm / refute / pivot"] TR -->|active| P TR -->|resolved| R["Resolver
stale report sections + follow-up gaps"] R --> RW["Report Writer
section outline → narrative paragraphs"] RW -->|new gaps| E end T[("Trace State
steps / verdicts / evidence links")] M[("Structured Memories
working context")] E --> T CK --> T R --> T C -. derive .-> M T -. derive .-> M M -. context .-> P M -. context .-> CK ``` 在宏观层面上: 1. 提取 EVTX、MFT、Prefetch、浏览器数据或邮件痕迹等工件,并进行规范化处理。 2. 规则生成发现、关键点以及可能的假设。 3. 系统以微小的步骤起草并测试假设。 4. 生成、校验、执行并检查 SQL 查询。 5. 经过确认的证据转化为结构化的发现和持久记忆。 6. 随着新发现得到确认,报告的各个部分也会被刷新。 7. 报告中的信息缺口可以反馈给下一个调查周期。 模型被应用于语言和判断能发挥作用的地方。代码则被用于对确定性和可审计性有要求的地方。 这种分离是本项目的核心理念。 ## 为什么检索很重要 本项目得出的一个重要经验是:较弱的模型需要的不仅仅是 prompt。 它们需要在恰当的时机获得正确的信息。 当模型在不充分的上下文下启动时,它可能会做出错误的推断。如果这个错误的推断又被重复输入到后续的 prompt 中,模型就会一次又一次地重新发现那个相同的错误想法。这就形成了一个糟糕的推理死循环。 因此,forensia 的长期发展方向与检索增强生成紧密相连。 未来的版本应该能够使用本地的“第二大脑”:一个包含文档、笔记、报告、playbook、参考资料以及用户收集的知识的文件夹。系统应该通过全文检索对这些材料进行索引,在需要时检索相关的片段,并将其作为上下文传递给模型。 这与 `sumeshi/roughsearch` 中正在探索的搜索引擎在理念上很相似。 关键不在于让 prompt 变得更长。而在于激活正确的神经元。 对于本地模型而言,良好的检索可能与模型本身一样重要。 ## 架构带来的效能 forensia 的设计旨在让本地 LLM 发挥作用,而不是假装它们是前沿模型。 重要的技术包括: * **声明式知识层** 规则、schema 卡片、报告模板、问题规范以及调查提示应尽可能以 YAML 或 Markdown 格式进行编辑。 * **证据可用性画像** 系统在要求模型进行推理之前,应清楚已有哪些证据。依赖于不可用遥测数据的假设应被标记为无法测试,而不是被视为错误。 * **小任务对应小 prompt** 模型不应接收整个案件。它只应接收当前任务所需的上下文。 * **确定性关卡** 在采纳模型的主张之前,系统应验证它们是否得到了实际证据的支持。 * **结构化记忆** 已确认的事实、实体、时间线、假设和发现应存储在持久、可检查的格式中。 * **增量式报告** 报告应随着调查的深入而演进,而不是作为一个最终的黑盒生成。 * **人类可审计性** 输出应尽可能链接回证据。人类调查员依然对最终的判断负责。 ## 快速开始 ### 前置要求 * Python 3.14 或更高版本 * Windows 取证工件,例如 EVTX、MFT、Prefetch、浏览器数据或相关证据 * 一个本地且兼容 OpenAI 的 LLM 服务器,用于假设测试和报告编写 示例包括 LM Studio 或 llama.cpp server。 ### 安装说明 ``` pip install forensia ``` 你也可以使用: ``` uvx forensia ... uv tool install forensia ``` 用于开发环境: ``` git clone https://github.com/sumeshi/forensia.git cd forensia uv sync --dev ``` ### 本地 LLM 配置 通过环境变量或本地 `.env` 文件设置你的本地模型 endpoint: ``` export LLM_BASE_URL="http://127.0.0.1:1234" export LLM_MODEL="google/gemma-4-e4b" ``` 你可以从示例文件开始复制: ``` cp .env.example .env ``` 请勿提交 `.env` 文件。 ### 运行调查 将工件放入输入目录并运行: ``` forensia investigate case001 ./input --profile windows-basic ``` 运行更多调查周期: ``` forensia investigate case001 ./input --profile windows-basic --max-iter 50 ``` 使用自定义报告模板: ``` forensia investigate case001 ./input --template-dir ./my-templates ``` ### 继续处理现有案件 ``` forensia investigate case001 --max-iter 50 ``` ### 添加更多证据 ``` forensia add case001 ./new-input ``` ### 生成或刷新报告 ``` forensia report case001 forensia report case001 --write forensia report case001 --write --template-dir ./my-templates ``` ### 导出模板 ``` forensia templates-export ./my-templates ``` ### 打开本地 UI ``` forensia serve case001 --host 127.0.0.1 --port 8000 ``` 该 UI 为调查进度、发现、假设、报告各个部分、时间线数据以及证据引用提供了一个控制台。 ## 安全提示 * forensia 是一款调查辅助工具,不能替代人工审查。 * 始终需将发现与原始证据进行核对。 * 在进行敏感调查时,请使用本地或离线 LLM。 * 如果 `LLM_BASE_URL` 指向云端或外部 endpoint,prompt 中可能会包含源自案件数据的证据或摘要。 * 切勿发布真实的案件目录、原始证据、报告、AI 日志、记忆文件、DuckDB 数据库、邮件存储、磁盘镜像或其他调查工件。 * 详情请参阅 `SECURITY.md`。 ## 贡献指南 forensia 在设计上倾向于尽可能使用声明式修改。 如果你想添加检测知识、调查提示、schema 卡片、报告行为或结构化问题处理,请先从规则包和模板层入手,然后再考虑修改核心代码。 核心代码应专注于通用机制。针对特定场景的部分(如个别规则)最好先进行讨论。它们的变化通常很快,并且有些可能作为针对特定用户、数据集或任务调整的外部配置或 fork 来维护会更好。 开发指南请参阅 `CONTRIBUTING.md`。 ## 基准测试 与基准测试相关的说明记录在 `BENCHMARK.md` 中。 评分问题的标准答案记录在 `BENCHMARK-ANSWERS.md` 中。这些答案源自公开的 NIST CFReDS 数据集,仅供评估参考——请勿针对特定答案优化代码或 prompt(详见 `CONTRIBUTING.md`)。 由于体积、授权和敏感性问题,该仓库不包含大型的取证数据集或派生的案件目录。需要时,请从原始公开来源获取基准测试数据,将工件解压到本地工作目录中,并针对该本地副本运行 forensia。 示例: ``` forensia templates-export ./benchmark-templates forensia investigate benchmark-output ./path/to/extracted-artifacts --profile windows-basic --template-dir ./benchmark-templates forensia report benchmark-output ``` 基准测试模板和面向评分的配置可能会与核心项目分开记录。重要的架构目标是,特定于基准测试的行为应来自模板、配置文件或规则,而不是核心引擎中的隐藏假设。 ## 未来计划 未来重要的方向包括: * 更强大的检索增强生成 * 本地“第二大脑”风格的知识文件夹 * 整合用户收集的参考资料进行全文检索 * 更多声明式调查配置文件 * 通用引擎逻辑与特定案件知识之间更清晰的分离 * 更完善的模板文档 * 随着项目成熟,确立更稳定的贡献边界 长期目标不仅仅是自动化生成报告。 目标在于构建一个离线调查助手,它能够利用证据、规则、记忆、检索以及人类意图,来帮助回答这个问题: 而且同样重要的是,让人类能够准确追踪这个答案是如何得出的——并决定是否信任它。
Investigation cockpit showing case progress, hypotheses, findings, and report sections.
Generated forensic report with evidence-backed findings and investigation context.
## 概述
`forensia` 融合了**取证**与 **AI**。
这是一个利用本地 LLM 辅助 Windows 取证调查的实验性工具。其目标并非将整个案件直接丢给模型,并期望它能像资深分析师一样运作。相反,forensia 在模型周围构建了一套框架:将调查拆分为微小且可检查的步骤——收集证据、生成假设、将其与源数据核对、提取发现并持续更新报告——而模型每次只需处理一个细小步骤。
该项目源于两个实际限制:
因此,forensia 选择了截然相反的路线:依靠围绕它们构建的架构,使小型本地模型发挥大作用。
像 `google/gemma-4-e4b` 或 `qwen/qwen3.5-9b` 这样的模型,还不足以强大到能够在没有辅助的情况下阅读所有内容、记住所有内容,并连续数小时进行正确的推理。因此,forensia 结合了规范化证据、基于规则的信号、结构化 prompt、确定性检查以及持久化记忆,从而确保永远不会直接要求模型一次性解决整个案件。
## 开发状态
forensia 目前处于**早期开发**阶段。
其架构、内部 schema、模板、规则格式、命令行界面以及仓库结构可能会发生重大变化。目前的设计应被视为正在进行的研究原型,而非稳定的平台。
欢迎各种贡献,同时预期会有破坏性更新。正因如此,对核心逻辑的贡献才是最具价值的。针对特定场景的部分(例如单一规则)优先级较低:它们变化很快,根据你的需求,将其维护在你自己的 fork 中(按用户或任务进行微调)可能比向上游提交更容易。
## 为什么会有这个项目
现代的前沿模型令人惊叹。Claude 变得越来越好,GPT 也变得越来越好,未来一片光明。
但这在你处理敏感的应急响应数据时并没有太大帮助。
在许多真实的调查中,证据绝不能离开组织。它不能被上传到云 API。甚至在连接到网络的机器上进行操作都不安全。如果你足够谨慎地去妥善调查一起安全事件,你可能也会偏执到选择在离线状态下工作。在最敏感的案件中,甚至连分析环境都可能需要保持隔离、被擦除或事后被销毁。
所以问题是:
我尝试过。
**不能直接用。**
小型的本地模型会误解严格的指令,丢失长上下文的线索,遗忘之前的推理,并且有时会一遍又一遍地重复同样糟糕的推论。解决办法不是假装它们比实际上更聪明。解决办法在于架构。
forensia 的初衷就是通过用结构包围弱模型,使其变得实用。
## 周末难题
应急响应请求通常在周五送达。
这种模式令人似曾相识:
* 攻击者总是在无人值守时入侵系统。
* 周一,有人注意到了一些异常。
* 周二,内部进行了讨论。
* 到了周三,大家才承认这可能是一起安全事件。
* 周四,有人决定询问供应商。
* 周五早上,请求终于到了工程师手里。
* 报告要求在周一前交付。
* 而数据甚至还没传过来。
这让人精疲力尽。
要是有人能替你周末加班就好了。
没有这样的人。
但也许能有一个 AI 伙伴。
## 设计原则
### 1. 独立作战
forensia 旨在能够在离线或隔离环境中持续工作。
如果某个参与调查的系统在周末一直保持网络连接,那么周一早上等着的可能不是一份进度报告。而可能是一封勒索信。
因此,其最低运行假设被刻意设定得很低:一台本地机器、一块便宜的 GPU(如果有的话)、存储空间以及电力。
### 2. 不要信任 AI
forensia 不会将模型视为聪明的调查员。
模型只是一个组件。它不是决策权威。
该系统将工作划分为细小的角色:识别信息缺口、起草假设、规划查询、编写 SQL、审查结论、提取发现、构思大纲以及编写段落。每个角色的设定都极其聚焦,其目的用一句话就能概括。
任何可以被确定性决定的事情都应该由代码来处理,而不是由模型来处理。SQL 校验、重复查询检测、结构化路由、兜底逻辑、证据映射以及一致性检查都必须是可预测且可审计的。
模型得出的结论并不会仅仅因为模型说是真的就被接受。各项主张必须基于实际的查询结果和源自数据的证据。如果一项发现无法追溯到证据,它就不应成为持久记忆。
### 3. 花费时间,而非透支信任
forensia 不会试图通过一次运行就得出完美的结论。
相反,它会反复生成、测试、优化并记录假设。整个调查过程本身应该是可观测的。人类应该能够询问:
并追踪答案的来源,一直追溯到证据、中间推理以及报告输出。
报告并不是只在最后才编写。它会随着调查的推进不断刷新。已确认的发现会更新报告;未解决的缺口可以反馈给下一个调查周期。
## forensia 不是什么
forensia 并不打算仅仅成为现有检测规则的简单封装。
目前已经存在许多有价值的规则生态系统(例如 Sigma 规则),它们代表了大量的人类知识。但仅仅将这些结果输入给 LLM 并要求生成摘要,并不是本项目的主要目标。
那样只会让 AI 沦为检测结果的摘要生成器。
forensia 正在尝试探索一些不同的东西:
规则依然重要。本项目在有助于调查的地方包含了关键规则。但更重要的设计理念是:
这是 forensia 规则设计背后最重要的思想。一个好的规则不应仅仅记录检测到了什么——它还应该帮助系统理解用户接下来可能想要调查什么。随着模型的改进,这种富含意图的结构应该会变得更有价值:模型不仅能读出检测到了什么,还能明白为什么该检测结果很重要,以及调查的下一步方向。
## 架构概览
forensia 的运作方式是一个调查循环。
```
flowchart LR
A["ArtifactsEVTX / MFT / Prefetch / ..."] A -->|Ingest / Normalize| C C[("Case State
normalized evidence")] C --> D["Rule Engine
Findings / Key Points"] subgraph L["Investigation Loop"] D --> E["Hypothesis Seeding
rules + gap analysis"] E --> P["Planner
query intent → SQL composition"] P --> X["Executor
query execution + fallback search"] X --> CK["Checker
verdict review → finding extraction"] CK --> TR["Progress Tracker
confirm / refute / pivot"] TR -->|active| P TR -->|resolved| R["Resolver
stale report sections + follow-up gaps"] R --> RW["Report Writer
section outline → narrative paragraphs"] RW -->|new gaps| E end T[("Trace State
steps / verdicts / evidence links")] M[("Structured Memories
working context")] E --> T CK --> T R --> T C -. derive .-> M T -. derive .-> M M -. context .-> P M -. context .-> CK ``` 在宏观层面上: 1. 提取 EVTX、MFT、Prefetch、浏览器数据或邮件痕迹等工件,并进行规范化处理。 2. 规则生成发现、关键点以及可能的假设。 3. 系统以微小的步骤起草并测试假设。 4. 生成、校验、执行并检查 SQL 查询。 5. 经过确认的证据转化为结构化的发现和持久记忆。 6. 随着新发现得到确认,报告的各个部分也会被刷新。 7. 报告中的信息缺口可以反馈给下一个调查周期。 模型被应用于语言和判断能发挥作用的地方。代码则被用于对确定性和可审计性有要求的地方。 这种分离是本项目的核心理念。 ## 为什么检索很重要 本项目得出的一个重要经验是:较弱的模型需要的不仅仅是 prompt。 它们需要在恰当的时机获得正确的信息。 当模型在不充分的上下文下启动时,它可能会做出错误的推断。如果这个错误的推断又被重复输入到后续的 prompt 中,模型就会一次又一次地重新发现那个相同的错误想法。这就形成了一个糟糕的推理死循环。 因此,forensia 的长期发展方向与检索增强生成紧密相连。 未来的版本应该能够使用本地的“第二大脑”:一个包含文档、笔记、报告、playbook、参考资料以及用户收集的知识的文件夹。系统应该通过全文检索对这些材料进行索引,在需要时检索相关的片段,并将其作为上下文传递给模型。 这与 `sumeshi/roughsearch` 中正在探索的搜索引擎在理念上很相似。 关键不在于让 prompt 变得更长。而在于激活正确的神经元。 对于本地模型而言,良好的检索可能与模型本身一样重要。 ## 架构带来的效能 forensia 的设计旨在让本地 LLM 发挥作用,而不是假装它们是前沿模型。 重要的技术包括: * **声明式知识层** 规则、schema 卡片、报告模板、问题规范以及调查提示应尽可能以 YAML 或 Markdown 格式进行编辑。 * **证据可用性画像** 系统在要求模型进行推理之前,应清楚已有哪些证据。依赖于不可用遥测数据的假设应被标记为无法测试,而不是被视为错误。 * **小任务对应小 prompt** 模型不应接收整个案件。它只应接收当前任务所需的上下文。 * **确定性关卡** 在采纳模型的主张之前,系统应验证它们是否得到了实际证据的支持。 * **结构化记忆** 已确认的事实、实体、时间线、假设和发现应存储在持久、可检查的格式中。 * **增量式报告** 报告应随着调查的深入而演进,而不是作为一个最终的黑盒生成。 * **人类可审计性** 输出应尽可能链接回证据。人类调查员依然对最终的判断负责。 ## 快速开始 ### 前置要求 * Python 3.14 或更高版本 * Windows 取证工件,例如 EVTX、MFT、Prefetch、浏览器数据或相关证据 * 一个本地且兼容 OpenAI 的 LLM 服务器,用于假设测试和报告编写 示例包括 LM Studio 或 llama.cpp server。 ### 安装说明 ``` pip install forensia ``` 你也可以使用: ``` uvx forensia ... uv tool install forensia ``` 用于开发环境: ``` git clone https://github.com/sumeshi/forensia.git cd forensia uv sync --dev ``` ### 本地 LLM 配置 通过环境变量或本地 `.env` 文件设置你的本地模型 endpoint: ``` export LLM_BASE_URL="http://127.0.0.1:1234" export LLM_MODEL="google/gemma-4-e4b" ``` 你可以从示例文件开始复制: ``` cp .env.example .env ``` 请勿提交 `.env` 文件。 ### 运行调查 将工件放入输入目录并运行: ``` forensia investigate case001 ./input --profile windows-basic ``` 运行更多调查周期: ``` forensia investigate case001 ./input --profile windows-basic --max-iter 50 ``` 使用自定义报告模板: ``` forensia investigate case001 ./input --template-dir ./my-templates ``` ### 继续处理现有案件 ``` forensia investigate case001 --max-iter 50 ``` ### 添加更多证据 ``` forensia add case001 ./new-input ``` ### 生成或刷新报告 ``` forensia report case001 forensia report case001 --write forensia report case001 --write --template-dir ./my-templates ``` ### 导出模板 ``` forensia templates-export ./my-templates ``` ### 打开本地 UI ``` forensia serve case001 --host 127.0.0.1 --port 8000 ``` 该 UI 为调查进度、发现、假设、报告各个部分、时间线数据以及证据引用提供了一个控制台。 ## 安全提示 * forensia 是一款调查辅助工具,不能替代人工审查。 * 始终需将发现与原始证据进行核对。 * 在进行敏感调查时,请使用本地或离线 LLM。 * 如果 `LLM_BASE_URL` 指向云端或外部 endpoint,prompt 中可能会包含源自案件数据的证据或摘要。 * 切勿发布真实的案件目录、原始证据、报告、AI 日志、记忆文件、DuckDB 数据库、邮件存储、磁盘镜像或其他调查工件。 * 详情请参阅 `SECURITY.md`。 ## 贡献指南 forensia 在设计上倾向于尽可能使用声明式修改。 如果你想添加检测知识、调查提示、schema 卡片、报告行为或结构化问题处理,请先从规则包和模板层入手,然后再考虑修改核心代码。 核心代码应专注于通用机制。针对特定场景的部分(如个别规则)最好先进行讨论。它们的变化通常很快,并且有些可能作为针对特定用户、数据集或任务调整的外部配置或 fork 来维护会更好。 开发指南请参阅 `CONTRIBUTING.md`。 ## 基准测试 与基准测试相关的说明记录在 `BENCHMARK.md` 中。 评分问题的标准答案记录在 `BENCHMARK-ANSWERS.md` 中。这些答案源自公开的 NIST CFReDS 数据集,仅供评估参考——请勿针对特定答案优化代码或 prompt(详见 `CONTRIBUTING.md`)。 由于体积、授权和敏感性问题,该仓库不包含大型的取证数据集或派生的案件目录。需要时,请从原始公开来源获取基准测试数据,将工件解压到本地工作目录中,并针对该本地副本运行 forensia。 示例: ``` forensia templates-export ./benchmark-templates forensia investigate benchmark-output ./path/to/extracted-artifacts --profile windows-basic --template-dir ./benchmark-templates forensia report benchmark-output ``` 基准测试模板和面向评分的配置可能会与核心项目分开记录。重要的架构目标是,特定于基准测试的行为应来自模板、配置文件或规则,而不是核心引擎中的隐藏假设。 ## 未来计划 未来重要的方向包括: * 更强大的检索增强生成 * 本地“第二大脑”风格的知识文件夹 * 整合用户收集的参考资料进行全文检索 * 更多声明式调查配置文件 * 通用引擎逻辑与特定案件知识之间更清晰的分离 * 更完善的模板文档 * 随着项目成熟,确立更稳定的贡献边界 长期目标不仅仅是自动化生成报告。 目标在于构建一个离线调查助手,它能够利用证据、规则、记忆、检索以及人类意图,来帮助回答这个问题: 而且同样重要的是,让人类能够准确追踪这个答案是如何得出的——并决定是否信任它。
标签:TCP/UDP协议, 人工智能, 安全辅助工具, 数字取证, 本地大模型, 用户模式Hook绕过, 自动化报告, 自动化脚本, 逆向工具, 防御加固