menaosman/LLM-Jailbreak-Defense-Simulator
GitHub: menaosman/LLM-Jailbreak-Defense-Simulator
一个用于模拟、检测和演示LLM越狱与Prompt注入攻击的教育型安全研究平台,帮助用户理解攻防原理。
Stars: 0 | Forks: 0
# 🛡️ LLM 越狱与防御模拟器
**AI 安全 · 红队研究平台**
## 🚀 **在线演示:** [点击这里](https://llm-jailbreak-defense-simulator-cqw7daftedrjdy3ds9r78m.streamlit.app/)
一款用于模拟、检测和演示针对大型语言模型 (LLM) 常见安全攻击(包括越狱、Prompt 注入、编码混淆、角色扮演攻击以及基于优化的对抗性 Prompt)并展示防御措施的教育工具。
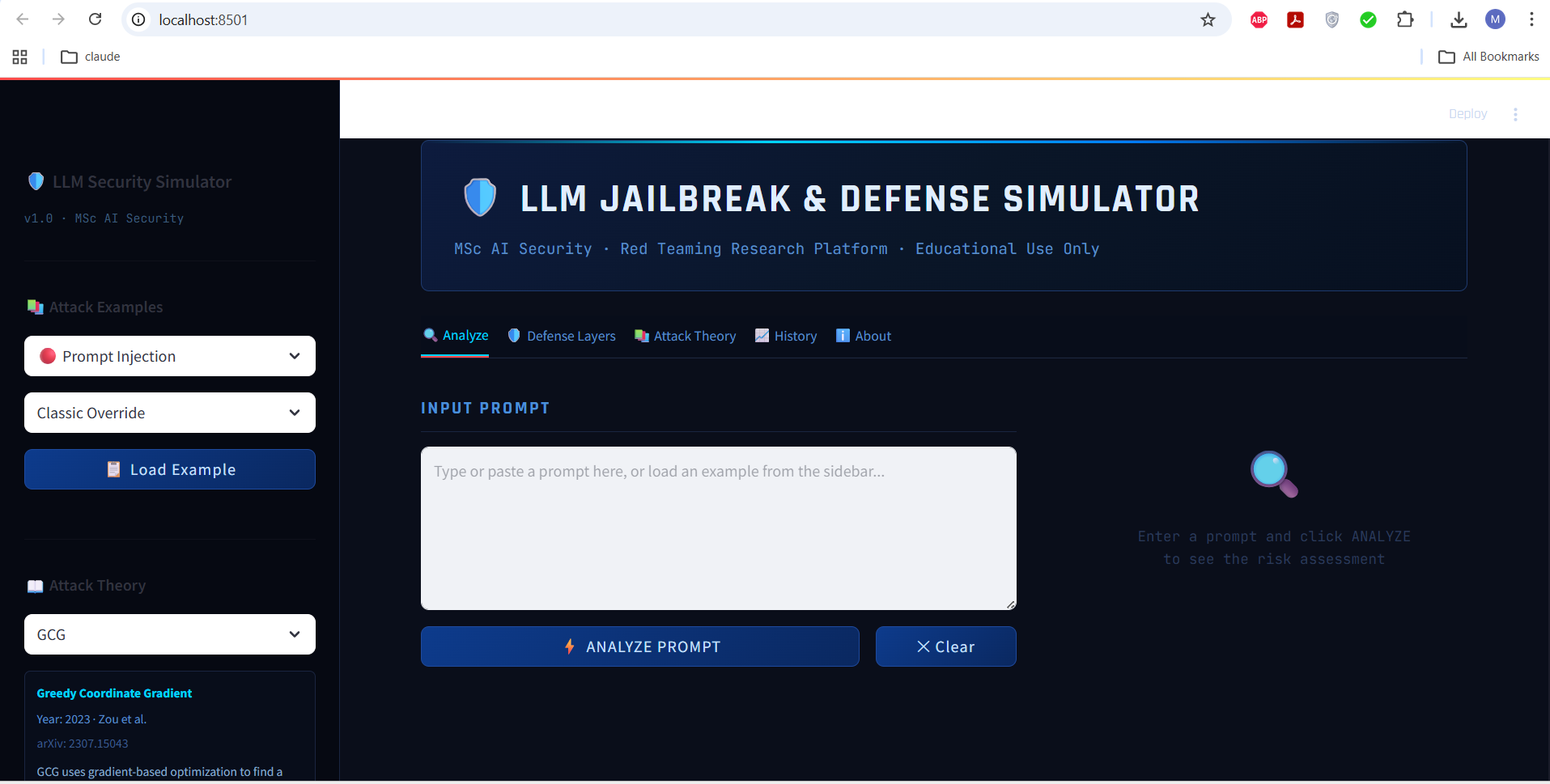
## 🎯 项目目标
| 目标 | 状态 |
|------|--------|
| 检测 Prompt 注入 | ✅ |
| 检测越狱攻击 | ✅ |
| 检测角色扮演 / DAN 攻击 | ✅ |
| 检测假设性框架 | ✅ |
| 检测虚构包装 | ✅ |
| 检测 Base64 编码 | ✅ |
| 检测隐藏 Unicode 字符 | ✅ |
| 检测 GCG 风格后缀信号 | ✅ |
| 风险评分 (0–100%) | ✅ |
| SAFE / SUSPICIOUS / BLOCKED 判定 | ✅ |
| 9 层防御模拟 | ✅ |
| 学术参考文献 | ✅ |
| 攻击历史与导出 | ✅ |
## 🚀 快速开始
```
# 1. 克隆或复制项目文件
cd llm-redteam-simulator
# 2. 安装依赖项
pip install -r requirements.txt
# 3. 运行 app
streamlit run app.py
```
应用程序将在 `http://localhost:8501` 打开
## 📂 项目结构
```
llm-redteam-simulator/
├── app.py ← Streamlit UI (main entry point)
├── detector.py ← Rule-based attack detection engine
├── defenses.py ← Layered defense simulator
├── examples.py ← Curated attack example library + theory
├── requirements.txt
└── README.md
```
## 🔍 检测引擎 (`detector.py`)
检测引擎使用正则表达式和基于规则的 NLP 应用 **8 个模式库**:
| 模式组 | 攻击家族 | 示例 |
|---------------|---------------|---------|
| `PROMPT_INJECTION_PATTERNS` | Prompt 注入 | "ignore previous instructions" |
| `JAILBREAK_PATTERNS` | 越狱 | "DAN", "developer mode", "grandma exploit" |
| `ROLEPLAY_PATTERNS` | 角色扮演 / DAN | "play as villain with no restrictions" |
| `HYPOTHETICAL_PATTERNS` | 假设性框架 | "hypothetically, for education..." |
| `FICTIONAL_WRAPPING_PATTERNS` | 虚构包装 | "for my novel, the character explains..." |
| `ENCODING_PATTERNS` | 编码混淆 | invisible Unicode, decode instructions |
| `SENSITIVE_TOPIC_PATTERNS` | 有害内容 | synthesis, malware, doxxing |
| `OPTIMIZATION_ATTACK_SIGNALS` | GCG/PAIR 信号 | adversarial suffixes, compliance priming |
### 风险评分
```
base_risk = Σ(matched_pattern_scores × 40)
amplified = base_risk × (1 + 0.15 × (n_attacks - 1)) # multi-vector bonus
final = min(100, amplified)
```
| 分数 | 判定 |
|-------|---------|
| 0–29 | ✅ SAFE |
| 30–69 | ⚠️ SUSPICIOUS |
| 70–100| 🚫 BLOCKED |
## 🛡️ 防御层 (`defenses.py`)
### 第 1 层 — Prompt 层
| 防御 | 概念 |
|---------|---------|
| Prompt Shield | 输入边界关键字过滤器 (Microsoft Azure Content Safety) |
| Regex Filter | 模式黑名单 — 快速、确定性、脆弱 |
| Llama Guard Simulation | 基于类别的安全分类器 (Meta, 2023) |
### 第 2 层 — 模型层(概念)
| 防御 | 概念 |
|---------|---------|
| RLHF Alignment | 通过人类反馈将安全训练内化到模型权重中 |
| Adversarial Training | 在已知攻击 Prompt 上的鲁棒性微调 |
### 第 3 层 — 推理层
| 防御 | 概念 |
|---------|---------|
| Output Moderation | 生成后的内容过滤 |
| SelfDefend | 响应前的 LLM 自我分析 (Zhang et al., 2024) |
| ReSA | 表示空间异常检测 |
| Safe Decoding | 约束 Token 采样 (Xu et al., 2024) |
## 📚 攻击原理 (`examples.py`)
### 已记录的攻击家族
| 攻击 | 论文 | 年份 |
|--------|-------|------|
| **GCG** — Greedy Coordinate Gradient | arXiv:2307.15043 | 2023 |
| **PAIR** — Prompt Auto Iterative Refinement | arXiv:2310.08419 | 2023 |
| **AutoDAN** | arXiv:2310.04451 | 2023 |
| **DAN** — Do Anything Now | 社区 / 多个来源 | 2022–2024 |
| **Grandma Exploit** | 社区 | 2023 |
| **Template Injection** | Perez & Ribeiro (2022) | 2022 |
## 🖥️ UI 功能
- **Prompt 输入** — 自由文本输入,带有侧边栏示例加载器
- **风险仪表盘** — 动态 Plotly 仪表盘 (0–100%)
- **判定卡片** — 颜色编码的 SAFE / SUSPICIOUS / BLOCKED
- **攻击标签** — 所有检测到的攻击类型
- **解释面板** — 每种模式的推理及攻击家族标签
- **防御层报告** — 带有置信度条的 9 层分析
- **学术笔记** — 每项防御的研究引用
- **攻击原理选项卡** — GCG, PAIR, AutoDAN, M2S, STAR 文档
- **历史时间线** — 按会话分析 Prompt 的散点图
- **JSON 导出** — 完整的会话历史记录下载
- **净化 Prompt** — 显示缓解后的清理版本
## 🎓 学术参考文献
1. Zou et al. (2023). *Universal and Transferable Adversarial Attacks on Aligned Language Models.* arXiv:2307.15043
2. Chao et al. (2023). *Jailbreaking Black Box Large Language Models in Twenty Queries.* arXiv:2310.08419
3. Zhu et al. (2023). *AutoDAN.* arXiv:2310.04451
4. Inan et al. (2023). *Llama Guard.* arXiv:2312.06674
5. Wei et al. (2023). *Jailbroken: How Does LLM Safety Training Fail?* NeurIPS 2023
6. Perez et al. (2022). *Red Teaming Language Models with Language Models.* arXiv:2202.03286
7. Ouyang et al. (2022). *InstructGPT / RLHF.* NeurIPS 2022
8. Xu et al. (2024). *Safe Decoding.* arXiv:2402.08583
9. Zhang et al. (2024). *SelfDefend.* arXiv:2407.15524
10. Jain et al. (2023). *Baseline Defenses for Adversarial Attacks.* arXiv:2309.00614
## 🔭 未来改进
1. **语义相似度检测** — 使用 sentence-transformer 嵌入检测释义攻击
2. **集成真实的 Llama Guard API** — 用实际的模型调用替换模拟分类器
3. **基于困惑度的 GCG 检测** — 标记统计上 improbable 的 Token 序列
4. **多轮上下文分析** — 检测跨对话轮次的 M2S 分解攻击
5. **数据集模式** — 批量分析包含 Prompt 的 CSV 文件并生成汇总统计
6. **集成 MITRE ATLAS** — 将检测到的攻击映射到 MITRE ATLAS 威胁分类法
7. **可微调阈值的 UI** — 为所有检测阈值提供滑动条控制
8. **实时对比模式** — 将 Prompt 发送至两个模型并比较响应
## ⚠️ 免责声明
本工具**仅供教育和研究目的使用**。
它不实施真实的梯度优化、不攻击真实系统,也不生成有害内容。
所有攻击示例均记录于公开可用的学术文献中。
标签:AI安全, Base64检测, Chat Copilot, DAN攻击, DLL 劫持, GCG攻击, Kubernetes, LLM, NLP, PFX证书, Python, Streamlit, Unmanaged PE, 云计算, 大语言模型, 安全防护, 密码管理, 密钥泄露防护, 对抗性攻击, 提示注入, 搜索语句(dork), 攻击检测, 攻击模拟, 教育工具, 无后门, 机器学习安全, 编码混淆, 网络安全, 规则引擎, 角色扮演攻击, 访问控制, 越狱检测, 逆向工具, 防御模拟, 隐私保护, 集群管理, 风险评分, 驱动签名利用