a1h8/KubeWhisperer
GitHub: a1h8/kube-verdict
KubeWhisperer 是一个开源AI辅助Kubernetes事件调查平台,通过关联多源数据提供基于证据的根本原因分析和经人工审核的修复建议,解决运维中复杂故障排查的认知负荷问题。
Stars: 3 | Forks: 0
# KubeWhisperer
开源 Kubernetes 事件调查平台。
KubeWhisperer 将 Kubernetes 事件、Helm 漂移、Prometheus 警报、OTel 链路和 Loki 日志关联起来,形成基于证据的事件总结,然后提出经人工审核的修复命令。
✅ 默认隔离运行 — Ollama + Mistral,数据不出基础设施
✅ 未经明确批准,不自动执行修复
✅ CI 中验证的六个端到端故障场景
✅ 无需活跃集群即可试用
[](https://github.com/a1h8/KubeWhisperer/actions/workflows/ci.yml)
[](#validated-scenarios)
[](https://www.python.org)
[](LICENSE)
## 为什么重要
大多数 Kubernetes 宕机并非由单个故障 Pod 引起。
当支付服务崩溃时,值班工程师需要同时打开五个标签页:Pod 日志、Kubernetes 事件、Helm 历史记录、Prometheus 图表以及 GitOps 仓库。在压力下,凌晨两点,同时开着三个 Slack 线程。根本原因很少在警报触发处 — 通常在三次跳转之后,一个配置错误的 Helm 值或声明与实际运行状态之间的漂移。
KubeWhisperer 降低了这种认知负荷。它将事件、Helm 漂移、Prometheus 信号和 OTel 链路关联为一个基于证据的根本原因分析 — 按置信度排名,并在任何修复命令触及生产环境前设置人工审核关卡。
## 无需集群即可试用
**集成测试**标签页完全离线运行 — 无需集群,无需 Ollama:
1. `streamlit run ui/app.py`
2. 前往 **🧪 集成测试**
3. 从下拉菜单中选择任意 `h00N_*` 案例
4. 模式默认为 **🔬 管道跟踪** — 管道自动运行
5. 探索所有 10 个步骤:分词器 → 检索 → 锚点 → 漂移 → 置信度 → 修复建议
## 演示
三个基于真实 k3d 集群的场景 — 无模拟,无硬编码答案。
**输出效果如下:**
```
════════════════════════════════════════════════════════════════════
INCIDENT SUMMARY
════════════════════════════════════════════════════════════════════
Severity : HIGH
Namespace : kubewhisperer-demo
Confidence : MEDIUM
Impacted : payment-service, ml-inference, notification-service
Root cause :
payment-service is in CrashLoopBackOff due to repeated container
failures. ml-inference cannot pull its image (ImagePullBackOff).
notification-service is missing a required environment variable.
Key evidence:
• [447×] BackOff on Pod/payment-service-58555ff9b6-4bxv2
"Back-off restarting failed container payment-service"
• [ 1×] Failed on Pod/ml-inference-6c7dbf6d5f-2nlsr
"Failed to pull image: not found"
Proposed fix:
$ kubectl rollout restart deployment/payment-service -n kubewhisperer-demo
$ kubectl set image deployment/ml-inference ml-inference=
════════════════════════════════════════════════════════════════════
Confidence: MEDIUM
Approve and apply remediation? [approve/reject]: approve
✓ Remediation approved — commands above should be applied.
```
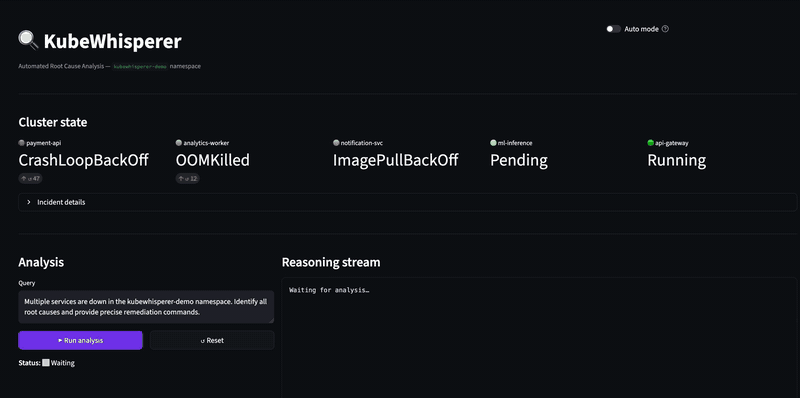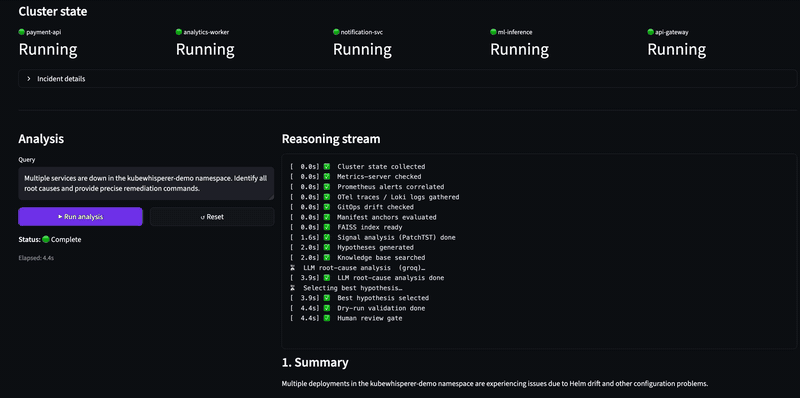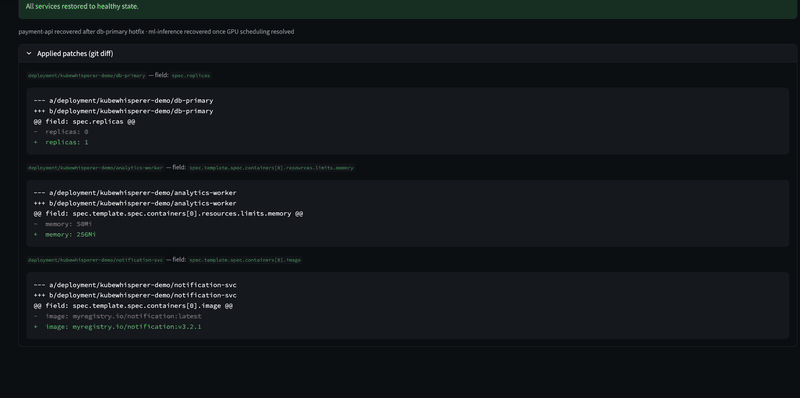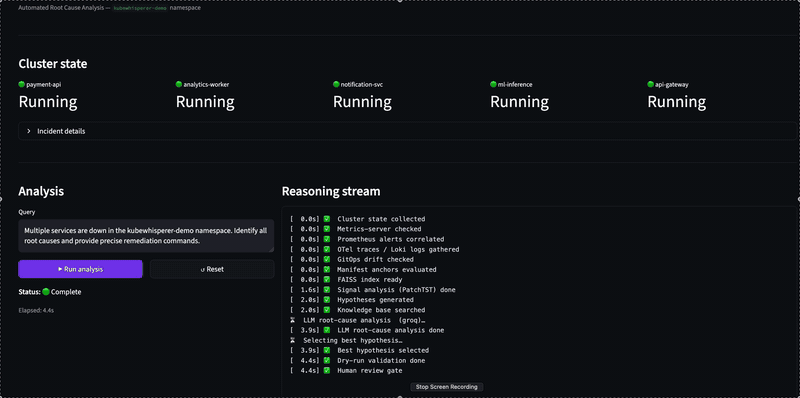
### 1 · 多重故障根因分析(隔离环境,Mistral)
五个服务同时宕机。KubeWhisperer 独立识别每个根本原因,按证据权重排序,并将根本原因与级联故障分离 — 完全在本地运行,数据不离开机器。
### 2 · 人工审核关卡
LLM 提出修复命令。执行受关卡限制:SRE 审查证据,输入 `approve` 或 `reject`。未经明确签字确认,任何操作都不会触及集群。
### 3 · 无误报 — 确认健康服务
`api-gateway` 运行正常。KubeWhisperer 查询同一管道,并正确返回高置信度,表明无需修复。信噪比很重要。
```
# 气隙环境(本地 Mistral)
LLM_PROVIDER=ollama python demo/run_rca.py --yes
# 在线演示(Groq,更快)
LLM_PROVIDER=groq python demo/run_rca.py --yes
```
→ [完整演示指南](docs/demo.md)
## 安全模型
每条修复命令在执行前都会经过三道关卡:
1. **试运行** — 命令在集群 API 上验证,但不应用更改
2. **人工审核** — SRE 审查证据、根本原因和建议的修复方案,然后输入 `approve` 或 `reject`
3. **回滚提示** — KubeWhisperer 在每条修复建议旁生成逆向命令(`helm rollback`、`kubectl rollout undo`)
未经明确签字确认,任何操作都不会触及集群。按设计,不实现自动执行。
## 工作原理
LLM 受检索到的证据约束。KubeWhisperer 首先根据确定性信号对假设进行排序 — 本体拓扑、锚点违规、漂移、策略和已解决的事件 — 然后仅使用 LLM 来生成基于证据的根本原因分析。
置信度路由使用波束搜索:同一假设路径上连续两次出现低置信度结果会立即切换到下一个候选,而归档路径会使用失败分析中的信号对剩余候选进行重新排序。
**管道:**
```
K8s events + Prometheus + OTel/Loki + Helm values
↓
Ontology graph + anchor drift detection
↓
BM25 + FAISS + RRF hybrid retrieval
↓
Beam-search hypothesis ranking
↓
LLM root-cause analysis (evidence-grounded)
↓
Dry-run validation → human review gate → GitOps patch
```
## 已验证场景
在 CI 中端到端验证的六种故障模式 — 无需集群,无需 Ollama。
| 场景 | 案例 | 验证内容 |
|---|---|---|
| CrashLoopBackOff — 缺失依赖 | h001 | BFS 图遍历、BM25+FAISS 检索、锚点检测、置信度评分、修复建议 |
| ImagePullBackOff — 仓库认证 / 标签漂移 | h002 | Helm 漂移检测、`drift.*` 注解、镜像建议生成 |
| OOMKilled — 内存限制漂移 | h003 | Helm 声明值与观测值差异、`anchor_fix_hints()` → `helm upgrade --set` |
| Pod 启动时缺失 ConfigMap / Secret | h004 | `DeploymentReadinessDetector`、`missing.*` 注解、`kubectl create` 提示 |
| RBAC — 缺失 ClusterRoleBinding | h005 | SA 存在但未检测到绑定、`kubectl create clusterrolebinding` 提示 |
| NetworkPolicy 出站阻止 | h006 | `netpol.*` 注解、`kubectl edit networkpolicy` 提示 |
每个案例都运行完整的预 LLM 管道:图构建 → 混合检索 (BM25 + FAISS + RRF) → 上下文构建 → 锚点/漂移/策略评分 → 建议生成。
## 快速开始
**前置条件:** Python 3.11+,一个可通过 kubeconfig 访问的 Kubernetes 集群,以及一个在 `.env` 中配置的 LLM 提供商。
```
git clone https://github.com/a1h8/KubeWhisperer.git
cd KubeWhisperer
pip install -r requirements.txt
cp .env.example .env
# 编辑 .env 文件:KUBECONFIG, LLM_PROVIDER, KUBE_NAMESPACES
# LLM_PROVIDER=ollama → ollama pull mistral (本地运行,数据不离开基础架构)
# LLM_PROVIDER=groq → 设置 GROQ_API_KEY (快速,免费层级)
# LLM_PROVIDER=anthropic|openai|google → 设置相应的 API 密钥
streamlit run ui/app.py
```
## 文档
| 文档 | 内容 |
|---|---|
| [架构](docs/architecture.md) | 完整管道图、LangGraph 工作流、证据优先假设生成、波束搜索路由、锚点系统设计、漂移检测、PatchTST |
| [REST API](docs/api.md) | FastAPI 端点、会话生命周期、请求/响应示例、SSE 流 |
| [UI 参考](docs/ui.md) | Streamlit 标签页、管道跟踪步骤、锚点透视表、推理旅程、路由决策 |
| [测试用例](docs/test-cases.md) | h001–h006 已验证场景、案例格式、添加新案例、CI 覆盖率 |
| [项目结构](docs/project-layout.md) | 完整目录树、RBAC |
| [路线图](docs/roadmap.md) | 已完成和下一步计划 |
| [配置](docs/configuration.md) | 所有 `.env` 变量、混合检索调优、源权重 |
| [部署](docs/deployment.md) | Docker、k3d、生产环境 K8s |
## 当前限制
一些约束是有意为之或已知问题:
- **已验证场景:仅 h001–h006。** h007–h012+(Helmfile 多发布、MCTS 路由、Slack/PagerDuty、RBAC 感知范围)在路线图中,尚未实现。
- **单集群。** 多集群支持尚未完全集成。
- **生产环境不自动执行修复。** 人工审核关卡是设计要求;按设计不实现自动执行。
- **LLM 性能取决于本地硬件。** 通过 Ollama 运行 Mistral 至少需要 8 GB 内存;GPU 可显著加速推理。
- **无实时警报集成。** Prometheus 和 Loki 数据是按需拉取的,不是流式传输。
查看[路线图](docs/roadmap.md)了解后续计划。
## 贡献
欢迎贡献 — 特别是:
- 新的故障场景案例(`tests/integration/cases/h0NN_*` 格式 — 参见[测试用例](docs/test-cases.md))
- 信号收集器(Prometheus 规则、OTel 导出器、Loki 查询)
- LLM 提供商集成
查看[项目结构](docs/project-layout.md)了解代码库布局。
## 社区
KubeWhisperer 是开源项目,专注于 Kubernetes 事件调查。
欢迎反馈、可复现的故障场景和集成 — 请提交 issue 或发起讨论。
## 许可证
[Apache 2.0](LICENSE)
标签:AI辅助诊断, AI风险缓解, API密钥扫描, API集成, CI集成, ESC漏洞, Helm部署, Kubernetes, Kubernetes根因分析, Kubernetes运维, LLM评估, Loki日志, Mistral, Ollama, OTel追踪, Prometheus监控, Python开发, Streamlit, Streamlit界面, 事件关联, 二进制发布, 人工验证, 修复建议, 分布式追踪, 可观测性, 开源工具, 故障场景验证, 故障排查, 漂移检测, 用户代理, 离线支持, 空气隔离, 自定义请求头, 警报关联, 访问控制, 证据收集, 运维平台