detain/php-dup-finder
GitHub: detain/php-dup-finder
基于 AST 的 PHP 重复代码深度检测与重构辅助工具,能够识别参数化逻辑克隆并自动生成带有类型提示的函数签名建议。
Stars: 1 | Forks: 0
# phpdup — 基于 AST 的 PHP 重复逻辑检测器
[](https://github.com/detain/php-dup-finder/actions/workflows/ci.yml)
[](https://app.codecov.io/gh/detain/php-dup-finder)
[](https://www.php.net)
[](LICENSE)
`phpdup` 将 PHP 代码库中的每个文件解析为抽象语法树,将这些 AST 规范化为标准形式,并寻找**参数化重复**的聚类——即代码的*形状*重复,而只有字面量、标识符、方法名、表名或*整个可选代码段*不同的地方。
对于每个聚类,它不仅会指出重复项,还会告诉你**抽象后的形式**——其参数列表、类型和建议的函数名——可以直接用于重构。

在 `tests/Fixtures` 上的一次运行返回影响最大的前 2 个聚类。每个聚类的“建议抽象”框是 phpdup 推荐你提取的函数签名;“Holes”表列出了每个参数及其推断的类型和在聚类成员中观察到的值。与之相比,传统的复制/粘贴检测器只高亮重复部分;phpdup 会告诉你阈值和角色字符串*是抽象的参数*及其推断类型和观察值,随时可以应用。
## 目录
- [功能特性](#features)
- [安装说明](#installation)
- [PHAR (推荐)](#installation-phar)
- [Composer](#via-composer)
- [从源码构建](#from-source)
- [自更新](#self-update)
- [快速开始](#quick-start)
- [工作原理](#how-it-works)
- [管道](#pipeline)
- [规范化模式](#normalization-modes)
- [聚类](#clustering)
- [双层 TED 预过滤](#two-tier-ted-pre-filter)
- [反统一](#anti-unification)
- [多种子搜索](#multi-seed-search)
- [模式识别](#pattern-recognition)
- [架构分析器](#architectural-analyzers)
- [聚类一致性(异常值检测)](#cluster-coherence-outlier-detection)
- [重构安全性评分](#refactor-safety-scoring)
- [排名](#ranking)
- [并行化](#parallelism)
- [增量索引](#incremental-indexing)
- [持久化聚类缓存](#persistent-cluster-cache)
- [AST 懒加载](#lazy-ast-loading)
- [Type-3 / 可选段检测](#type-3--optional-segment-detection)
- [Type-4 / 行为相似度](#type-4--behavioural-similarity-experimental)
- [ORM / 数据库感知的语义去重](#orm---db-aware-semantic-deduplication)
- [TUI 模式](#tui-mode)
- [Watch 模式](#watch-mode)
- [SIGINT 软取消](#sigint-soft-cancel)
- [`phpdup serve` REST API](#phpdup-serve-rest-api)
- [输出格式](#output-formats)
- [配置](#configuration)
- [按目录覆盖](#per-directory-overrides)
- [项目配置](#project-profiles)
- [自动调优](#auto-tune)
- [规范化插件](#normalization-plugins)
- [CLI 参考](#cli-reference)
- [编程式使用](#programmatic-use)
- [示例](#examples)
- [静态分析与配置验证](#static-analysis--config-validation)
- [基准测试](#benchmarks)
- [对比基准测试套件](#comparative-benchmark-suite)
- [功能矩阵](#feature-matrix)
- [内部扩展性基准测试](#internal-scaling-benchmark)
- [架构](#architecture)
- [测试](#testing)
- [性能](#performance)
- [路线图](#roadmap)
- [常见问题解答](#faq)
- [贡献](#contributing)
- [许可证](#license)
## 功能特性
- **语义分析而非文本比对。** 比较 AST 结构而非源代码文本——因此空格、注释和标识符重命名无法混淆它。
- **支持全部四种克隆类型。** Type-1(精确)、type-2(重命名变量/字面量)、**type-3**(某些成员存在但其他成员缺失的语句——参见 [Type-3 / 可选段检测](#type-3--optional-segment-detection)),以及实验性的 **type-4** 行为相似度评分器,可捕获结构不同但在 I/O 上等价的代码(例如 `foreach`-累加器 与 `array_reduce`,`switch` 与 `match`)。参见 [Type-4 / 行为相似度](#type-4--behavioural-similarity-experimental)。
- **参数发现。** 对于每个聚类,识别出变化的字面量、标识符、方法名、类名以及*整个可选代码段*,并将它们作为建议抽象的参数提出,附带推断的类型和命名占位符。
- **三种规范化模式。** 从 `strict`(仅容忍变量重命名)到 `aggressive`(同时折叠字面量值、方法名、属性名和类名)——根据你想要的精确度/召回率权衡进行选择。
- **三阶段聚类。**
- 用于精确规范匹配的**哈希桶**——O(N)。
- **N-gram 倒排索引 + Jaccard + APTED 树编辑距离**用于近似重复——在实际应用中不会出现二次方增长。
- **包含度回退**适用于因一个块是另一个的近似子集而导致 Jaccard 失败的 type-3 克隆。
- **带语句数组 LCS 的反统一。** 对于每个聚类,phpdup 计算其成员的最具体泛化,当 stmt 数组长度不同时,通过每个语句结构哈希的 LCS 进行计算。差异成为类型化的参数孔;每个语句的间隙成为默认的布尔参数。
- **模式识别**(22 个标签)。对匹配知名重构原型的聚类进行标签化——结构型、领域型、框架型:
- **结构型:** `sql-builder` · `crud-handler` · `validation-chain` · `strategy` · `config-driven` · `state-machine` · `optional-segments`。
- **领域型 (I.A.2-7):** `loop-map`(foreach + 累加器追加)· `loop-filter`(foreach + 前置守卫-continue)· `sql-query`(主体中的字面 SQL 字符串)· `http-call`(Guzzle / cURL / `wp_remote_*` 形状)· `error-handler`(带记录器或重新抛出的 try-catch)· `builder-chain`(≥3 个方法调用链)· `container-registration`(DI 绑定器)· `db-op`(数据库操作形状——由 `--db-aware` 规范化产生的 `__DB_READ__` / `__DB_WRITE__` / `__DB_UPSERT__` token)。
- **框架型 (IX.A):** `controller-action`(Laravel/Symfony 控制器)· `migration`(Laravel/Doctrine 迁移)· `eloquent-model`(`App\\Models\\…`)· `repository-method`(`*Repository::find/get/save…`)· `event-listener` · `service-provider`(Laravel SP / Symfony Bundle)· `query-builder-chain`(Doctrine/Eloquent QB 入口点)。
- **架构分析器** (IX.B)。除了模式标签之外,三个分析器会对每个聚类进行后处理,并发出带有严重性 + 修复建议的 `architectural_findings[]`:
- **SOLID**——标记 SRP 混合的主体(一个块中的持久化 + 副作用调用)和违反 DIP 的具体类字符串孔。
- **设计模式**——从现有标签 + 孔类型中识别策略 / 工厂 / 构建器形状。
- **反模式**——长参数列表(>5 个孔)、基本类型偏执(所有孔都是标量基本类型)。
- **聚类一致性** (VI.A.3)。通过平均成对 n-gram Jaccard 进行每个聚类的异常值检测;标记不属于其余部分的成员。在 JSON 中以 `outlier_members[]` 显示,在 CLI 中以 ⚠ 标记。
- **重构安全性评分** (VI.A.1)。将孔类型安全性、跨命名空间跨度、成员数量和模式标签差异组合成一个 `[0,1]` 的分数。`--min-safety` 会过滤掉那些看起来有机械提取风险的聚类。
- **影响排名输出。** 聚类按应用抽象后可消除的代码行数排序,并带有一个单独的置信度分数,用于标记有风险的重构(子树级孔、跨命名空间跨度)。
- **十二种输出格式。**
- SugarCraft 风格的彩色 **CLI**(带有 `--plain` 开关和 `--summary-only` / `--clusters` 详细模式)。
- 结构化 **JSON**(机器可读,包含完整的聚类 + 孔元数据,包括 type-3 孔的 `present_in_members[]`、`outlier_members[]`、`architectural_findings[]`、`safety` 评分;带有 `schema_version` 字段——[`docs/JETBRAINS_PLUGIN.md`](docs/JETBRAINS_PLUGIN.md) 是 IDE 插件的稳定契约)。
- 交互式 **HTML** 站点(可排序/过滤的索引、聚类影响迷你图、复制签名按钮、语法高亮代码、用琥珀色着色的可选段行、带有 `localStorage` 持久化 + JSON 导出的**每个孔的调整器 UI**)。
- **SARIF 2.1.0**(GitHub Code Scanning / GitLab Code Quality,带有分组指纹 + `optionalSegmentCount`)。
- **GitLab SAST v15.x**(MR 安全小部件,按影响分桶的严重性)。
- 每个聚类的 **Unified diff** + 累积的 `--patch` 文件。
- **Checkstyle XML**(Jenkins / Sonar / Bitbucket 消费者)。
- **CSV**(`--csv=FILE`)——每个聚类成员占一行,包含相似度/影响/安全性/签名,用于电子表格和 BI 摄取。
- **Prometheus** 文本格式(`--prometheus=FILE`)——`phpdup_clusters_total`、`phpdup_total_impact`、每个标签的计数器;准备好用于 pushgateway 抓取。
- **时间序列 JSONL**(`--timeseries=FILE`)——每次运行附加一行,通过 `GIT_COMMIT` / `GITHUB_SHA` / `CI_COMMIT_SHA` 进行 commit 标记;允许你在 BigQuery / ClickHouse / Elastic 中随时间跟踪重复债务。
- **Graphviz DOT**(`--graphviz=FILE`)——文件→聚类二分图;使用 `dot -Tpng …` 渲染。
- **PlantUML**(`--plantuml=FILE`)——带有聚类包和模式标签构造型的类图。
- **重构补丁**(`--refactor-patch=DIR`)——启发式、需人工审查的每个聚类 `.patch` 文件:添加一个 `Refactored/.php` 骨架以及每个成员的编辑提示。当 `$this`/`self::`/yield/闭包捕获会使机械替换变得不安全时,会转至人工审查头。
- **PHPUnit 测试骨架**(`--refactor-tests=DIR`)——每个聚类一个 `markTestIncomplete()` 测试类,带有从观察到的孔值填充的数据提供者。
- **可选的 SugarCraft TUI**(`--tui`)。四窗格 FlexBox 仪表板由协作管道驱动——计数、迷你图、OSC 9;4 任务栏进度均随着工作进展逐帧实时构建。六种主题,全键盘操作,在详细视图中使用 ←/→ 切换聚类。
- **Watch 模式**(`--watch`)。在文件更改时通过基于轮询的 `React\EventLoop` 计时器重新运行分析;`Ctrl+C` 干净地退出。与 `--tui` 结合使用,可创建在每次更改时重置和重建的实时仪表板。
- **SIGINT 软取消。** 第一次 `Ctrl+C` 翻转 `PipelineState::$cancelled`;协作阶段在 yield 之间检查它,短路到报告阶段,并生成部分报告。第二次 `Ctrl+C` 回退到默认的终止。退出代码是标准的 130。
- **REST API 服务器**(`phpdup serve`)。用于内部仪表板、CI 集成和游乐场前端的最小 HTTP 服务。路由:`GET /healthz`、`POST /analyze`(同步)、`POST /jobs` + `GETjobs/{id}`(异步形态)。手工编写的 HTTP/1.1 解析器——无 ReactPHP 依赖。SSRF 防护、Content-Length 上限、JSON_THROW_ON_ERROR,默认绑定到 `127.0.0.1`。参见 [`docs/SERVER.md`](docs/SERVER.md)。
- **PHAR 分发。** 每次发布都会附带发布 `phpdup.phar` 及其 sha256 附带文件;下载一次,即可在装有 PHP 8.1+ 和 `ext-phar` 的任何地方运行。`phpdup self-update`(别名 `update` / `upgrade`)在哈希验证后替换正在运行的二进制文件。使用 `php -d phar.readonly=0 build-phar.php` 进行本地构建。参见 [`docs/PHAR.md`](docs/PHAR.md)。
- **块类型过滤器**(`--kinds=method,closure`)。在提取时丢弃不匹配的块类型,使聚类只看到你要求的内容。
- **PHP 8.x 语法表面规范化。** `match` 分支折叠为等效 switch 的 token 形状,命名参数按字典顺序重新排序,属性在 `aggressive` 模式下被剥离——因此 PHP 8.0 → 8.4 之间仅语法上的差异不会混淆聚类。
- **自动调优**(`--auto-tune`)。在分析之前探测语料库并选择大小适当的默认值:小型(<200 个文件)获得宽松的阈值,中型(<20k 个)收紧 `max-df`,大型(≥20k 个)强制使用 `--exact-only` 以控制内存。显式的 CLI 标志始终覆盖自动选择。
- **项目配置。** `profiles/{laravel,symfony,drupal,wordpress,myadmin,generic}.json` 提供预设配置。`--profile=NAME` 显式选择一个;当没有给出显式配置时,通过项目标记文件(`artisan`、`bin/console`、`wp-config.php`、`include/Orm` 等)自动检测。
- **按目录配置覆盖。** `.phpdup.json` 文件可在扫描树的任何深度被发现,并根据 schema 进行验证,采用祖先优先的分层方式,使更深的目录覆盖父目录。符号(`db_symbols.methods` 和 `db_symbols.functions`)是累加的——按目录的符号**附加**到根配置符号而不是替换它们,允许在没有完全重复的情况下进行增量扩展。
- **用户自定义规范化插件。** 实现 `Phpdup\Normalization\NormalizationPlugin`,在 `phpdup.json -> normalization.plugins[]` 中注册 FQCN,你的插件将在内置传递之后运行,用于项目特定的规范化(例如统一 SDK 别名方法、项目特定的标识符规范化)。
- **Schema 验证的配置。** `phpdup.json` 在加载时根据 [`docs/config-schema.json`](docs/config-schema.json) 进行检查;`--validate-config` 在任何分析运行之前,在首次违规的字段路径上退出。
- **Shell 补全**适用于 bash、fish 和 zsh,通过 `phpdup completion ` 生成。输出是标准的 Symfony Console 补全脚本,前面加上了注释掉的安装说明,因此你可以直接粘贴并按照说明操作。
- **带有协作迭代的可组合管道。** 五个阶段(`Scanning`、`Preprocessing`、`Clustering`、`Refactoring`、`Reporting`)都实现了一个小型 `StageInterface` 并共享一个 `PipelineState`;协作阶段额外在执行期间 yield,以便 TUI 可以在并行工作正在进行时重绘。`ProgressListener` 接口允许观察者(TUI、监视器)在不接触阶段的情况下挂钩。
- **流式工作池。** `WorkerPool::runStreaming()` 返回一个 `\Generator`,在子进程结果到达时立即 yield——通过 `stream_select` 复用子进程各自的 socketpairs——因此 `PreprocessStage` 可以实时驱动仪表板,而不是阻塞在最慢的工作器上。经典的收集并返回的 `run()` 现在是对同一代码路径的一个简单的同步排空。
- **并行化预处理、对评分和重构。** `pcntl_fork` 工作池分批处理文件用于解析 + 提取 + 规范化 + 指纹识别(`PreprocessWorker`);用于 Jaccard + 树编辑评分的候选对(`PairScoreWorker`);以及每个聚类的反统一 + 标记(`RefactorWorker`)。自动 CPU 检测,在 pcntl 不可用时串行回退。
- **带有加权编辑的 APTED 风格的树编辑距离。** 具有重路径子排序和有界早期终止的 Zhang-Shasha 森林距离 DP,加上一个 `--ted-weights={default,semantic}` 成本模型,其中方法调用成本为 2.0,控制流为 1.5,字面量为 0.5——比单位成本更能代表行为相似度。
- **双层 TED 预过滤器。** 在 O(n²) DP 运行之前,大小差异检查 + 64 位(节点类型,深度)shapelet 草图会在约 10 次 ALU 操作中拒绝明显不同的对。参见 [双层 TED 预过滤](#two-tier-ted-pre-filter)。
- **三种候选对索引。** `NgramInvertedIndex`(默认,中小型语料库)、`BloomCandidateIndex`(直接替换,每个块保持固定大小的 2 KiB 过滤器——为了在庞大语料库上的 O(n²) 位重叠评分而交换发布列表内存)和 `LshIndex`(MinHash 签名 + 32 个段 / 4 行 LSH——每个块的近似常数查找时间)。
- **外部排序流式聚类原语。** 基于 (key, payload) 元组的磁盘支持 K 路归并排序——用于不适合 RAM 的语料库聚类的基础。
- **增量索引。** 由内容哈希 + 解析器版本 + 配置键作为键的每个文件块快照。编辑一个文件会保留其他 999 个快照不变。
- **持久化聚类缓存** (II.B.4)。在每次成功运行后将最终聚类列表快照到 `/clusters.idx`。在未更改的语料库上重新运行会完全跳过聚类 + 重构阶段。在任何块更改时进行整体失效。
- **AST 懒加载。** 原始 AST 在指纹识别后被丢弃,并仅对最终进入聚类的块按需重新加载。RSS 随语料库大小呈亚线性缩放。
- **AST + token 缓存。** 以 SHA-1 为键的磁盘缓存(`AstCache` 用于完整的 Stmt[],`TokenCache` 用于原始 token 流),两者都针对解析器发布进行版本控制,因此热缓存运行会完全跳过解析。
- **对比基准测试套件。** `bench/run-all.sh` 在精选的真实 OSS 语料库(Symfony Console、Laravel HTTP、PHPUnit、WordPress 核心)混合以及带有已知基本事实的综合模糊语料库上运行 phpdup 以及 phpcpd / pmd-cpd / jscpd / simian——发出挂钟时间 / RSS / 聚类计数比较以及合成集上的精确度/召回率/F1。参见 [基准测试](#benchmarks) 和 `bench/feature-matrix.md`。
- **内存上限。** `--max-memory=MB` 在管道中期的峰值 RSS 超过阈值时发出警告并建议使用 `--exact-only`。
- **`--stage` 停止点。** `--stage=clustering` 仅将管道运行到(并包括)聚类阶段并停止——用于调试增量缓存命中或分析各个阶段。
- **生产级 PHP。** 全程严格类型,PSR-4 自动加载,PHPStan 级别 6 干净,Psalm errorLevel 6 干净(无基线),四个套件(单元、集成、黄金快照、模糊检测率)中的 **396+** 个 PHPUnit 测试,需要 PHP 8.1+。
## 安装说明
### PHAR (推荐)
尝试 phpdup 的最快方法。从最新的 GitHub release 下载独立的 `phpdup.phar`,验证 SHA-256,然后将其放在你的 PATH 上:
```
curl -sSLO https://github.com/detain/php-dup-finder/releases/latest/download/phpdup.phar
curl -sSLO https://github.com/detain/php-dup-finder/releases/latest/download/phpdup.phar.sha256
sha256sum --check phpdup.phar.sha256
chmod +x phpdup.phar
sudo mv phpdup.phar /usr/local/bin/phpdup
```
要求:带有 `ext-phar` 的 PHP 8.1+。该 phar 大约 7 MB。
安装后,使用内置的自更新器保持最新:
```
phpdup self-update # download & swap the binary in place
phpdup self-update --dry-run # check what's available, change nothing
```
`update` 和 `upgrade` 是别名。有关完整流程 + 离线说明,请参见 [自更新](#self-update)。
自行构建 phar(例如用于私有分支):
```
composer install --no-dev --optimize-autoloader
php -d phar.readonly=0 build-phar.php
```
有关完整的分发流程、发布过程和故障排除(`phar.readonly`、共享主机上的 ext-phar 等),请参见 [`docs/PHAR.md`](docs/PHAR.md)。
### 通过 Composer
```
composer require --dev detain/php-dup-finder
vendor/bin/phpdup analyze src
```
该包尚未在 Packagist 上——需手动声明 GitHub 仓库:
```
{
"require-dev": {
"detain/php-dup-finder": "dev-master"
},
"repositories": [
{ "type": "vcs", "url": "https://github.com/detain/php-dup-finder" }
],
"minimum-stability": "dev",
"prefer-stable": true
}
```
### 从源码构建
```
git clone https://github.com/detain/php-dup-finder.git
cd php-dup-finder
composer install
bin/phpdup analyze /path/to/your/code
```
要求:
- PHP 8.1 或更新版本
- ext-hash(用于 `xxh128`)
- ext-pcntl + ext-posix(可选——没有它们 phpdup 将串行运行,没有其他变化)
- ext-phar(用于 phar 分发;源码/composer 安装不需要)
- ext-curl(可选;优先于流用于 `MlClient` 和自更新程序的 HTTP 获取)
- Composer(仅用于源码 / composer 安装)
## 自更新
当 phpdup 作为 phar 安装时,它可以在原地替换为最新的 GitHub release:
```
phpdup self-update # download, verify sha256, swap
phpdup self-update --dry-run # report the latest tag, change nothing
phpdup update # alias
phpdup upgrade # alias
```
流程:
1. 解析 `https://api.github.com/repos/detain/php-dup-finder/releases/latest`。
2. 从 release 资源下载 `phpdup.phar` 和 `phpdup.phar.sha256` 到临时目录。
3. 验证 SHA-256——如果不匹配则拒绝交换。
4. 将正在运行的二进制文件重命名为 `phpdup.phar.old`(回退安全),将新的 phar 移动到位,并将其标记为可执行。
5. 打印新版本。
需要对 phar 所在位置进行写访问(即,如果你不想使用 `sudo` 更新,就不要把它放在 `/usr/local/bin` 中;而是按用户安装在 `~/.local/bin` 下)。当 GitHub 返回“no releases yet”(`{"message":"Not Found"}`)时优雅回退,因此一个全新的分支仍然可以调用 `--dry-run` 而不会报错。
Composer / 源码安装不使用 `self-update`——以通常的方式拉取并重新安装:
```
composer update detain/php-dup-finder
# 或,用于源码克隆:
git pull && composer install
```
## 快速开始
扫描目录并打印最前面的重复项(自动并行化):
```
bin/phpdup analyze src
```
带有两种报告的多个目录:
```
bin/phpdup analyze src lib \
--json duplicates.json \
--html duplicates-report \
--min-impact 30
```
使用配置文件进行可重复运行:
```
bin/phpdup analyze --config phpdup.json
```
用于 CI 的快速仅限精确克隆的通过(非常快,在 3,300 块语料库上约 6 秒):
```
bin/phpdup analyze src --exact-only --min-impact 50
```
一次性发出所有与 CI 相关的格式:
```
bin/phpdup analyze src \
--sarif phpdup.sarif \
--gitlab-sast phpdup.gitlab.json \
--diff ./phpdup-diffs \
--checkstyle phpdup.xml \
--json phpdup.json \
--html phpdup-report
```
过滤为一种块类型并根据影响进行筛选:
```
bin/phpdup analyze src --kinds=method --min-impact=50 --exact-only
```
在重构时实时重新加载:
```
bin/phpdup analyze src --watch
```
在分析运行时显示交互式仪表板:
```
bin/phpdup analyze src --tui --theme=dracula
```
## 工作原理
### 管道
```
flowchart TB
subgraph Scan["Scanning"]
A[Scanner walks paths] -->|absolute file paths| B[FileScanner]
end
subgraph Preprocess["Preprocessing — parallel via WorkerPool::runStreaming"]
C[AstParser + AstCache] --> D[BlockExtractor with --kinds filter]
D --> E[Normalizer
strict / default / aggressive] E --> F[SubtreeHasher + NgramFingerprint] F --> G[(IndexStore
per-file snapshot)] end subgraph Cluster["Clustering"] H[BlockIndex] --> I[NgramInvertedIndex] I -->|candidate pairs| J{Pair scoring} J -->|hash-bucket: exact match| K[Edge weight = 1.0] J -->|Jaccard >= threshold| L[APTED tree-edit-distance] J -->|Jaccard < threshold
+ optional_blocks_enabled| M[ContainmentSimilarity
type-3 fallback] L --> N[Edge weight = min
jaccard, ted] M --> O[Edge weight = containment] K --> P[Union-find] N --> P O --> P P --> Q[Clusters] end subgraph Refactor["Refactoring"] R[AntiUnifier seed = max-size member] --> S{stmt arrays
differ in length?} S -->|yes + type-3 enabled| T[LCS on stmt hashes
→ optional_block holes] S -->|no| U[Recurse normally
→ literal/identifier/name holes] T --> V[ParameterSynthesizer] U --> V V --> W[bool $includeFooBar = false
or typed required param] W --> X[SignatureBuilder + PatternRecognizer] end subgraph Report["Reporting"] Y[Ranker by impact] --> Z[CLI / JSON / HTML / SARIF
GitLab SAST / Diff / Checkstyle] end B --> C G --> H Q --> R X --> Y %% Observer overlay PL[ProgressListener
e.g. PhpdupModel TUI] -.observes.-> Scan PL -.observes.-> Preprocess PL -.observes.-> Cluster PL -.observes.-> Refactor ``` 整个管道也作为 `\Generator`(`Pipeline::iter()`)被协作驱动——每个 yield 点都是 TUI 运行时重绘或观察者注入 `RestartPipelineMsg` 的机会。 | 阶段 | 输出 | |----------------|--------------------------------------------| | Scanning | 绝对文件路径(glob 包含/排除) | | Preprocessing | 每个文件的带注释块(规范 AST + n-gram 包 + 结构哈希) | | Clustering | 带有相似度分数 + 边权重的聚类 | | Refactoring | 泛化 AST、孔、签名、模式标签 | | Reporting | CLI / JSON / HTML / SARIF / GitLab SAST / diff / Checkstyle 输出 | ### 规范化模式 | 模式 | 变量重命名 | 字面量折叠 | 名称折叠 | |---------------|:---------------:|:----------------:|:-------------:| | `strict` | 是 | 否 | 否 | | `default` | 是 | 是 | 否 | | `aggressive` | 是 | 是 | 是 | 在 `aggressive` 模式(默认)下,具有不同表名、不同方法名和不同字面量值的两个函数仍然可以聚在一起。 ### 聚类 三个阶段: 1. **精确规范克隆。** 共享规范 AST 上相同 Merkle 哈希的所有块会被放入同一个桶中。O(N) 工作。 2. **近似重复。** 对于每个块,从稀有 n-gram 倒排索引(忽略出现在超过 `max_df` × N 个块中的 n-gram)中提取候选者。每个候选者通过规范 n-gram 多重上的 Jaccard 相似度进行评分;幸存者使用 APTED 风格的有界树编辑距离进行细化。 3. **Type-3 回退。** 当 Jaccard 失败但 `ContainmentSimilarity` 显示较小的块大部分包含在较大的块中时(`containment ≥ 0.85` 并且 `size_ratio ≥ 0.6`),该对仍然被接受。参见 [Type-3 / 可选段检测](#type-3--optional-segment-detection)。 幸存的边馈入一个 union-find 中,将它们合并为聚类。 ### 反统一 对于每个聚类,phpdup 计算其成员的最具体泛化。经典递归: ``` au(t1, t2) = if root(t1) == root(t2) and arity matches: Node(root(t1), [au(c1_i, c2_i) for i in children]) else: Hole(observed=[t1, t2]) ``` phpdup 中的扩展: - **种子 = 最大尺寸的成员。** 具有 AST 节点数最多的聚类成员被用作模板,因此“最大”版本驱动抽象,较短的成员高亮显示可选段(而不是因为种子碰巧很短导致对齐失败)。 - **stmt 数组的 LCS。** 当两个 stmts/cases/catches 数组长度不同时,phpdup 在每个语句的结构哈希上运行 LCS;匹配的位置递归,未匹配的模板位置成为 `optional_block` 孔。 生成的模板在每个成员不同意的位置都有 Hole 标记。每个孔跟踪其在所有成员中的观察值(按聚类顺序),因此报告显示 `threshold ∈ {10, 20, 30}` 和 `role ∈ {'admin', 'moderator', 'editor'}`。 ### 模式识别 在反统一之后,每个聚类都会对照一个小型重构原型目录进行检查(sql-builder、crud-handler、validation-chain、strategy、config-driven、state-machine、optional-segments)。标签是建议性的;它们不会改变聚类,只是在报告中标记聚类。 ### 排名 每个聚类获得两个分数: - **影响** ≈ `(members - 1) × avgBlockSize - holesPenalty`。应用抽象后可消除多少行代码。 - **置信度** 在 `[0,1]` 之间。聚类相似度,针对子树级孔(大型可变子树)和跨命名空间跨度进行惩罚,针对同类内聚性进行提升。 低于 `min_cluster_impact` 的聚类会被丢弃。幸存者按影响降序排序,在并列时按成员数量和相似度打破平局。 ### 并行化 `Phpdup\Parallel\WorkerPool` 将项目列表划分为 N 个批次,通过 `pcntl_fork` 为每个批次派生一个子进程,在子进程中运行闭包,父进程收集结果。有两种收集模式: - **`run()`**——收集并返回。每个子进程在完成时将其完整结果写入临时文件;父进程在所有子进程退出后一次性读取所有结果。 - **`runStreaming()`**——结果到达时 yield。子进程将长度前缀的序列化记录(4 字节大端 uint32 + 负载)写入每个子进程的 `stream_socket_pair`;父进程通过 `stream_select` 复用,返回的 `\Generator` 实时 yield 每条记录。`PreprocessStage` 消耗这些记录,因此协作管道可以获得阶段中期的进度事件,而不是阻塞直到每个 fork 退出。 两个阶段使用工作池: - **`PreprocessWorker`**——每个子进程为其文件批次执行解析 + 提取 + 规范化 + 哈希 + n-gram 指纹识别。 - **`PairScoreWorker`**——一旦从倒排索引生成候选对,主进程就会在工作器之间批量处理它们;每个子进程在其批次上运行 Jaccard + 有界 TED +(启用时)type-3 包含度回退,并发出幸存的边。 CPU 数量是自动检测的(`nproc` / `/proc/cpuinfo`)或可通过 `--workers N` / `PHPDUP_WORKERS=N` 覆盖。当 `pcntl_*` 不可用时(Windows、沙盒 PHP),工作池会在运行时检测到这一点,并回退到具有相同闭包接口的串行代码路径——调用者无需分支。 ### 增量索引 `Phpdup\Persistence\IndexStore` 在 `/.idx` 下快照每个文件的提取 + 规范化 + 指纹识别块。每个快照存储:
- `file_hash`——源文件的 `sha1_file()`。
- `parser_version`——与 AST 缓存键一起递增。
- `config_key`——相关配置字段(块大小、规范化模式、n-gram 大小)的 sha1。更改其中任何一个都会自动使快照失效。
- `blocks`——序列化的 `Block[]`,准备倒入索引。
在重新运行时,主进程将文件拆分为“重用”(快照命中)和“处理”(快照未命中)桶,只有后者进入工作池。编辑一个文件会保留其他快照不变。
使用 `--no-incremental` 禁用此功能以进行基准测试,或在担心缓存中毒时使用。
### AST 懒加载
在指纹识别之后,我们丢弃 `Block::$ast`(原始 PhpParser 子树),并在 `AntiUnifier` 中通过 `BlockAstLoader` 按需重新加载它。加载器遍历文件的解析缓存语句列表,寻找唯一的(kind, start_line, end_line, declared_name)元组;匹配项会重新填充回 Block 中。
首先查询 AST 缓存,因此在热运行中完全不会发生解析。如果你有充足的 RAM 并且想要最大速度,请使用 `--no-lazy-ast` 禁用此功能(重新加载的开销大致等于小型语料库上的 RSS 节省——参见 BENCHMARKS.md)。
## Type-3 / 可选段检测
“type-3”克隆是指结构匹配,但某些成员相对于其他成员有额外(或缺失)的语句。phpdup 在两个协调的阶段中检测这些。
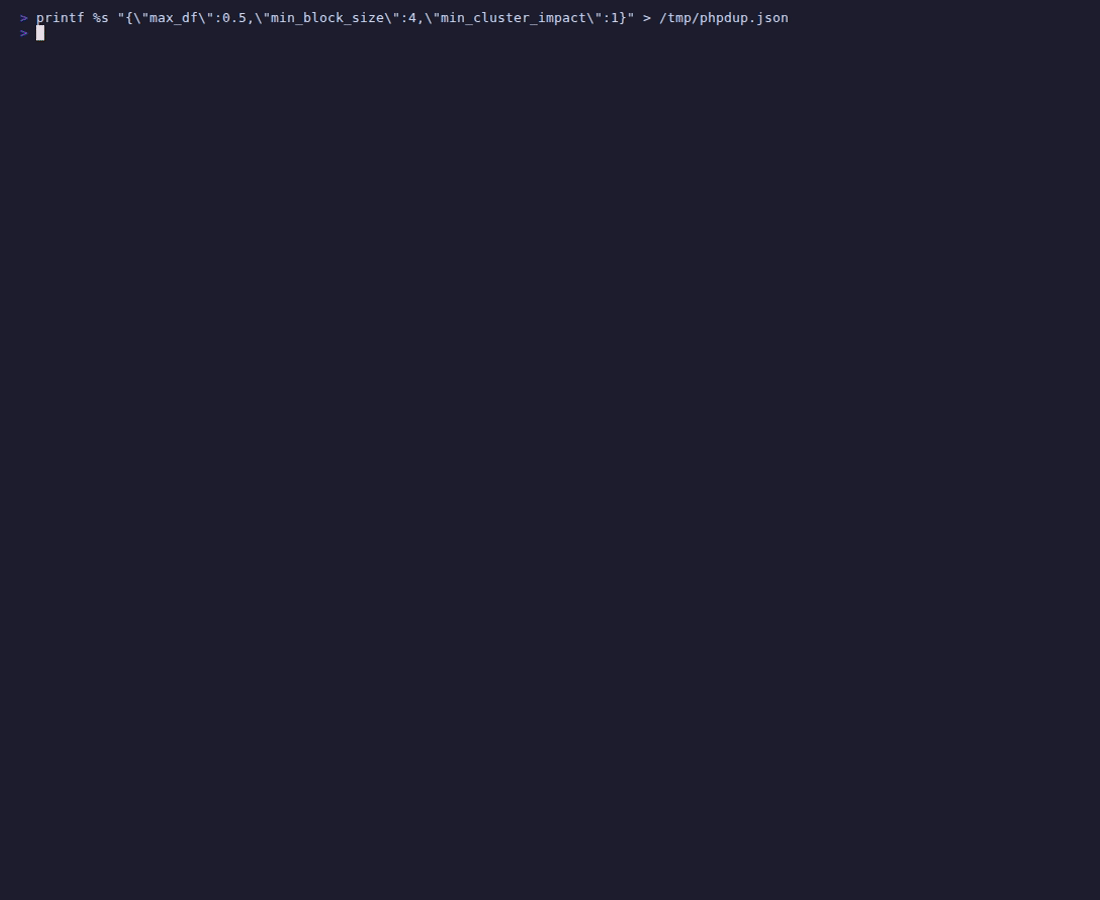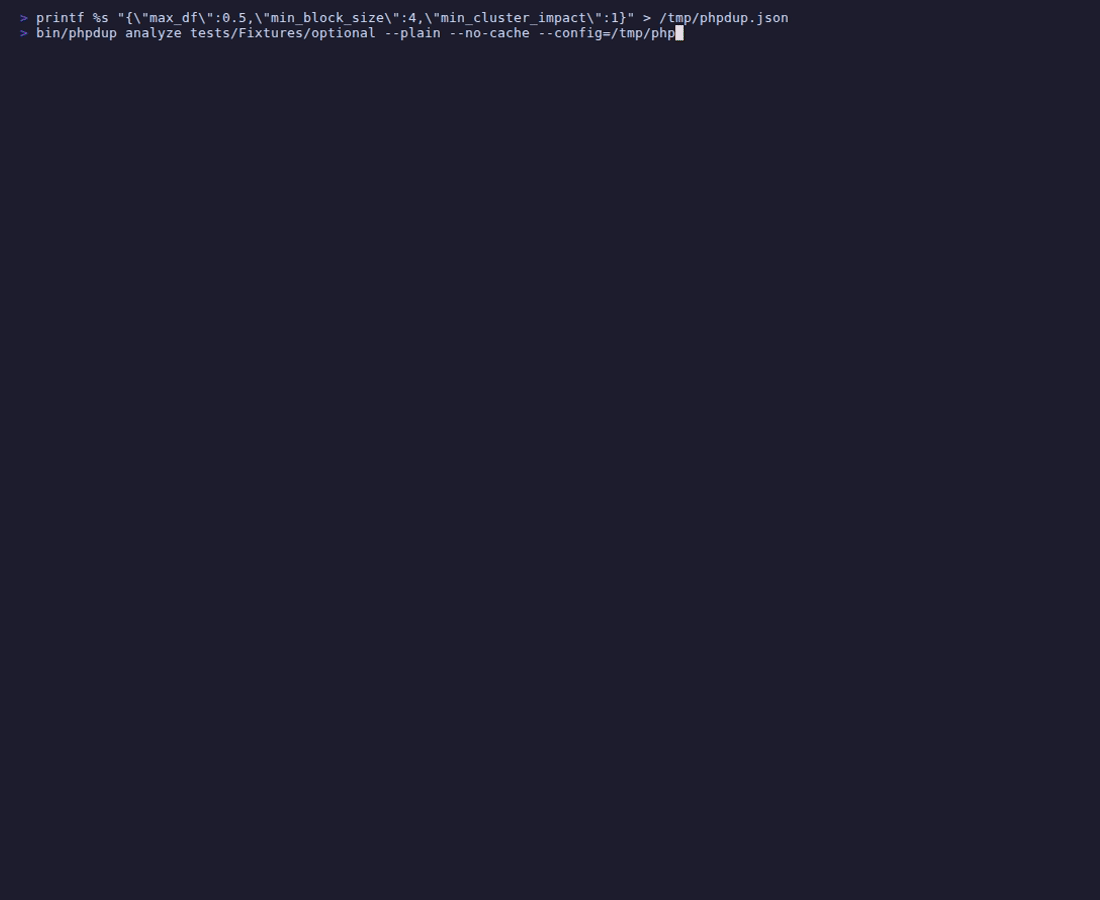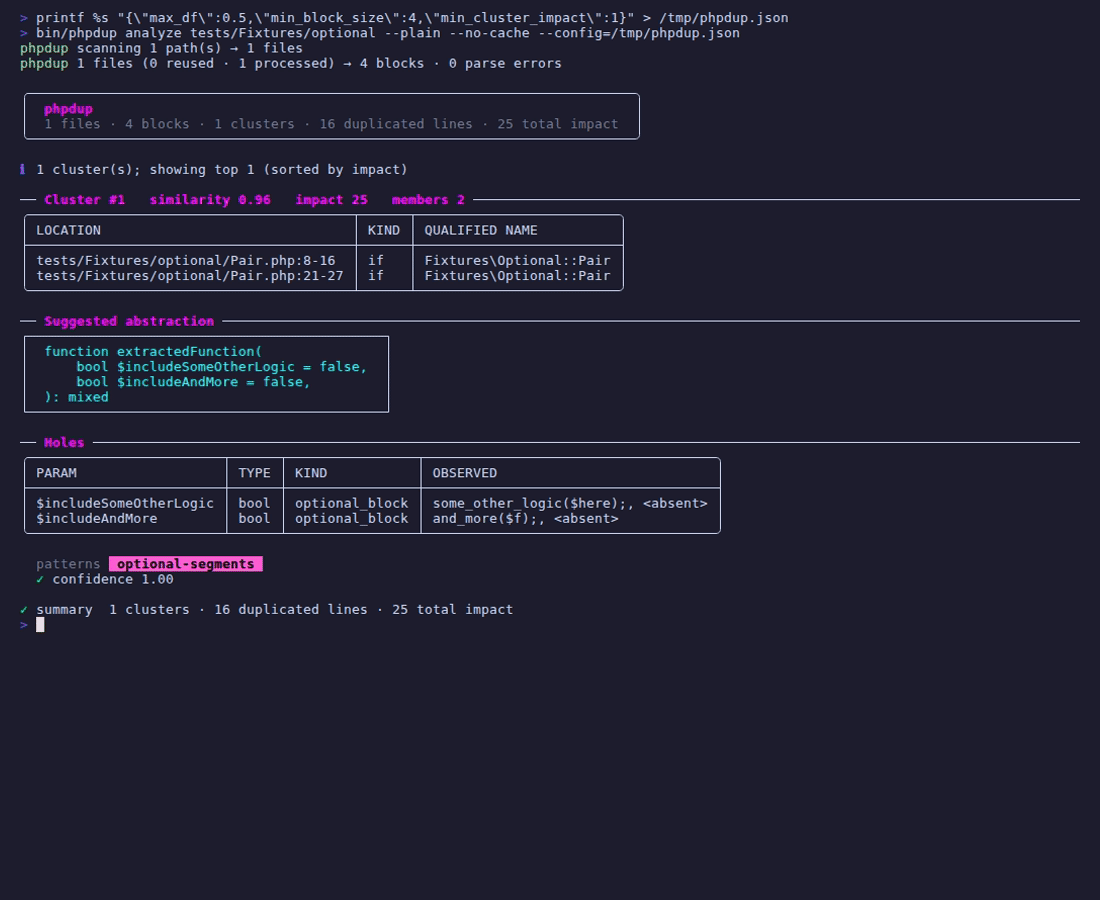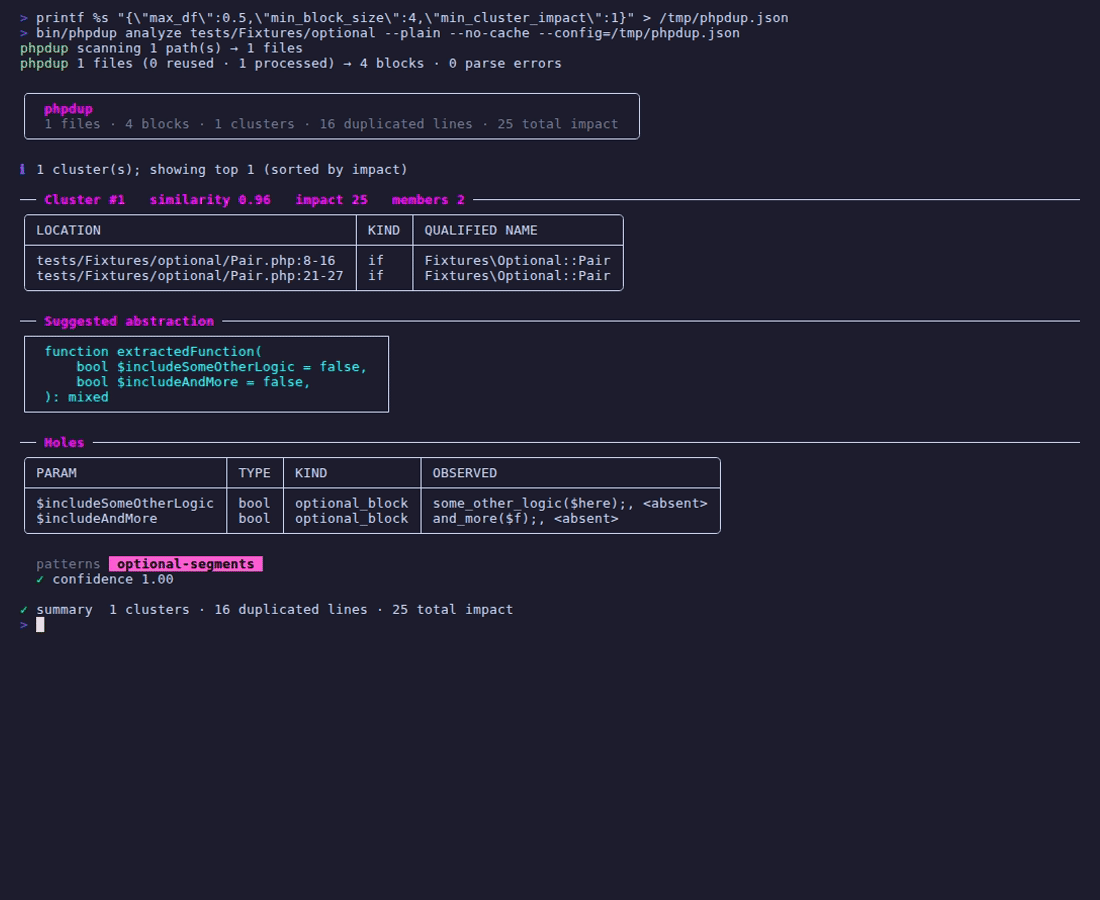
夹具运行显示 phpdup 拉入两个块,它们的语句共享一个公共前缀,但较长的块有两个额外的调用(`some_other_logic($here)` 和 `and_more($f)`)。“建议抽象”框最终有两个**默认布尔值**参数,以缺失的代码命名:
```
function extractedFunction(
bool $includeSomeOtherLogic = false,
bool $includeAndMore = false,
): mixed
```
……并且聚类被标记为 `optional-segments`。Holes 表中的每一行都标记为 `optional_block`,并带有字面量 `` 标记,显示哪些成员缺少该段。
### 聚类:包含度回退
当两个候选块之间的 n-gram Jaccard 低于 `similarity_threshold` 时,聚类器尝试 `ContainmentSimilarity = |A ∩ B|min / min(sum(A), sum(B))`,只要较小的包完全包含在较大的包中,无论大小差异如何,它都会返回 1.0。仅当以下情况时,该对才以包含度分数作为边权重被接受:
```
containment ≥ optional_blocks_containment (default 0.85) AND
size_ratio ≥ optional_blocks_min_overlap (default 0.6)
```
大小比率防护可防止单行块因一个共享的 n-gram 而与 100 行块聚类。
### 反统一:语句数组上的 LCS
种子(模板)是具有 AST 节点数最多的聚类成员。当 `walk()` 到达长度与种子不同的 `stmts` / `cases` / `catches` 数组时,phpdup 在每个语句的结构哈希上运行 LCS:
- 匹配的模板位置通过正常的遍历递归——匹配语句中的变量、字面量、名称仍然会产生常规的孔。
- 未匹配的模板位置成为 **`optional_block`** 孔——每个缺失的语句一个,上限为 `optional_blocks_max_per_cluster`(默认 3),以防止过度灵活的聚类爆炸成七个布尔的签名。
每个 `optional_block` 孔成为一个默认为 `false` 的 `bool` 参数。名称派生自段中第一个非停用词的标识符,例如,缺失的 `some_other_logic($here);` 变为 `bool $includeSomeOtherLogic = false`。`SignatureBuilder` 首先对所需的参数进行分组,然后是默认的布尔值,以便生成的签名是语法上有效的 PHP。
### 可调参数
```
{
"optional_blocks": {
"enabled": true,
"containment": 0.85,
"min_overlap": 0.6,
"max_per_cluster": 3,
"min_segment_length": 1
}
}
```
CLI 覆盖:
```
bin/phpdup analyze src \
--optional-blocks=on \
--optional-blocks-containment=0.85
```
要完全禁用 type-3 检测:`optional_blocks.enabled = false`(或 `--optional-blocks=off`);聚类器恢复为仅 Jaccard,并且当 stmt 数组长度不同时,AntiUnifier 回退到整个数组的子树孔。
### 在报告器中的表现
- **CLI**——Holes 表显示 `kind = optional_block`,观察值包括段缺失成员的字面量 `` 标记。
- **JSON**——每个 optional_block 孔都带有 `present_in_members: [int, ...]`,列出了*确实*包含该段的聚类成员索引。
- **SARIF**——每个结果的 `properties` 都会添加 `optionalSegmentCount` 和 `hasOptionalSegments`,以便 PR 注释工具可以明显地标记 type-3 聚类。
- **HTML**——可选行用琥珀色着色,获得“type-3”徽章,并将 `` 标记设为斜体。
## Type-4 / 行为相似度 (实验性)
Type-1/2/3 检测比较的是**形状**——AST 发出哪些 token。Type-4 检测比较的是**行为**——什么数据流过块,它发出什么调用,它返回什么。两个以结构不同但计算相同值的函数(`foreach` 累加器 与 `array_reduce`,递归 与 迭代,`switch` 与 `match`)即使在 AST 相似度拒绝它们时,也会在 type-4 下聚类。
phpdup 的 type-4 脚手架:
- `Phpdup\Semantic\DataflowSummarizer`——遍历块一次并发出 `(vars, calls, returns, sideEffects)`。
- `Phpdup\Semantic\DbOperationTagger`——单独遍历块并发出已识别数据库操作(`db.read`、`db.write`、`db.delete`、`db.execute`、`db.query`)的 `tag → count` 多重集。在设计上与库和扩展无关——参见下面的 [行为标签评分](#behavioural-tag-scoring)。
- `Phpdup\Similarity\BehaviouralSimilarity`——对这些摘要(变量集 1×、调用多重集 2×、返回形状 2×、副作用标志 1×、DB 操作标签多重集 2×)进行加权 Jaccard → `[0,1]` 分数。
- `Phpdup\Semantic\CallGraph` 和 `Phpdup\Semantic\ControlFlowGraph`——供未来 type-4 提升路径使用的粗略按块摘要。
按照设计,Type-4 具有比 type-1/2/3 更高的误报风险。今天它是一个基础脚手架;在聚类器中的实时接入(作为 Jaccard + APTED + 包含度全部拒绝后的第四层回退)由未来的 `--type4` 标志控制。有关算法参考,请参见 [`docs/algorithms/anti-unification.md`](docs/algorithms/anti-unification.md),以及了解这如何与 ORM/DB 语义等价检测的更广泛计划相联系,请参见 [`docs/plans/orm-db-semantic-dedup.md`](docs/plans/orm-db-semantic-dedup.md)。
## ORM / 数据库感知的语义去重
传统的 AST 聚类会遗漏开发者认为是“同一操作”的重复项,因为表面调用形状不同——通常当相同的数据库写/读操作在一个地方通过 ORM 表达,而在另一个地方通过原始 SQL 表达时。以下四个示例都执行**相同的写入**,但在没有 `--db-aware` 的情况下都不会聚类:
```
// Eloquent
$user = User::find($id);
$user->name = 'Bob';
$user->save();
// Doctrine
$user = $em->find(User::class, $id);
$user->setName('Bob');
$em->flush();
// Raw PDO
$pdo->query("UPDATE users SET name = 'Bob' WHERE id = {$id}");
// Query builder
$db->table('users')->where('id', $id)->update(['name' => 'Bob']);
```
传递 `--db-aware` 并且 phpdup 会在规范化期间作为前置传递运行 `Phpdup\Normalization\DbOpCanonicalizer`。它将已识别的数据库调用重写为规范的合成 FuncCalls——`__DB_FIND__("user")`、`__DB_QUERY__("users", "SELECT")`、`__DB_WRITE__("users")` 等——因此等效变体会产生相同的 token 流并在第一层 / 第二层中聚类在一起。
### 可识别的内容
`Phpdup\Normalization\DbOpRegistry` 中的内置符号表涵盖:
- **Eloquent / Laravel**——`Model::find`、`Model::all`、`Model::create`、`DB::table`、`DB::select`、`Model::where(...)->first|get|update|delete()` 等。
- **Doctrine ORM**——`EntityManager::find`、`EntityManager::flush`、`EntityManager::persist`、`Repository::findOneBy`、`Repository::findAll`。
- **PDO**——`PDO::query`、`PDO::prepare`、`PDOStatement::execute`、`PDOStatement::fetch*`。
- **mysqli(面向对象 + 过程式)**——`mysqli::query`、`mysqli_query`、`mysqli_stmt_execute`、`mysqli_fetch_*`。
- **PostgreSQL**——`pg_query`、`pg_query_params`、`pg_fetch_*`、`pg_insert`、`pg_update`、`pg`。
- **Firebird / InterBase**——`ibase_query`、`ibase_prepare`、`ibase_execute`、`ibase_fetch_row`、`ibase_fetch_assoc`、`ibase_fetch_object`、`ibase_commit`、`ibase_rollback`。
- **MSSQL / DB-Library**——`mssql_query`、`mssql_fetch_row`、`mssql_fetch_array`、`mssql_fetch_assoc`、`mssql_fetch_object`、`mssql_num_rows`。
- **IBM DB2**——`db2_prepare`、`db2_execute`、`db2_query`、`db2_fetch_row`、`db2_fetch_assoc`、`db2_fetch_array`、`db2_fetch_object`、`db2_num_rows`。
- **异步 MySQL 客户端**——`amphp/mysql`(`amysql_query`、`amysql_fetch_assoc`、`amysql_fetch_row`、`amysql_free_result`)、friends-of-reactphp/mysql(`react_mysql_query`、`react_mysql_fetch_assoc`、`react_mysql_fetch_row`)、Swoole Coroutine MySQL(`swoole_mysql_query`、`swoole_mysql_fetch_assoc`、`swoole_mysql_fetch_row`)、OpenSwoole MySQL(`openswoole_mysql_query`)、Workerman mysql(`workerman_mysql_query`)。
- **异步 PostgreSQL 客户端**——`amphp/postgres`(`apg_query`、`apg_fetch_assoc`、`apg_fetch_row`、`apg_free_result`)、`reactphp/postgres`(`react_pg_query`、`react_pg_fetch_assoc`、`react_pg_fetch_row`)、Swoole 协程 postgres(`swoole_postgres_query`)。
- **Oracle OCI8**——`oci_parse`、`oci_execute`、`oci_fetch`、`oci_fetch_assoc`、`oci_fetch_row`、`oci_fetch_object`、`oci_free_statement`、`oci_commit`、`oci_rollback`。
- **Cassandra (phpcassa)**——`phpcassa_query`、`phpcassa_fetch`。
- **LevelDB**——`leveldb_get`、`leveldb_put`、`leveldb_delete`、`leveldb_open`。
- **Memcached**——`memcached_get`、`memcached_set`、`memcached_add`、`memcached_replace`、`memcached_delete`、`memcached_increment`、`memcached_decrement`、`memcached_flush`。
- **异步事务方法**——`beginTransaction`、`commit`、`rollback` 被分类为 `OP_WRITE`;辅助方法 `affectedRows` → `OP_READ`、`insertId` → `OP_WRITE`、`count` → `OP_READ`。
- **通用 CRUD 动词**——在未知接收者上的任何名为 `find`、`findById`、`save`、`update`、`delete`、`query`、`execute` 的方法——粗糙但高召回率。此外:通过 illuminate/database 查询构建器 facade(Laravel `DB::table()->...` 链)的 `table`、`select`、`insert`、`upsert`、`lock`、`unlock`。
- **原始 SQL 字符串**——传递给上述任何项。捆绑的 `Phpdup\Normalization\SqlTableExtractor` 从字面量字符串中提取动词(`SELECT` / `INSERT` / `UPDATE` / `DELETE` / `REPLACE` / `TRUNCATE`)和主表,以便该动词作为 token 出现在合成的 `__DB___` 调用中。
### 它如何融入管道
```
1. ScanningStage
2. PreprocessStage
a. AstParser → plain AST
b. BlockExtractor → (file, kind, range)
c. Normalizer
├── DbOpCanonicalizer ← only when --db-aware
└── CanonicalizingVisitor (vars, literals, names)
d. SubtreeHasher + NgramFingerprint
3. ClusterStage
4. RefactorStage
5. ReportStage
```
DbOpCanonicalizer 在标准变量 / 字面量 / 名称传递**之前**运行,因此合成的 `__DB___` token 名称能在激进的名称规范化传递中存活(它们被视为结构函数名,如 `isset` 或 `count`)。
### 风险概况和误报
`--db-aware` 有意偏向于**高召回率**——少数良性的误报(例如非 DB 类上不相关的 `query()` 方法折叠为 `__DB_QUERY__`)比遗漏真正的 ORM ↔ 原始 SQL 克隆代价更小。两项保障措施:
1. **默认关闭。** 第一层仅 AST 聚类保持未修改的路径;在没有 `--db-aware` 的情况下,现有报告流中没有任何内容改变。
2. **切换时缓存失效。** `Phpdup\Pipeline\Stages\PreprocessStage` 在其 config-key 哈希中包含 `dbAware`,因此在运行之间翻转该标志会重新处理每个文件,而不是重用过时规范化的块。
对于按项目的调整,`DbOpRegistry` 构造函数接受 `customMethodOps` 和 `customFunctionOps` 映射,因此你可以扩展或覆盖内置的分发表——将其连接到规范化插件中(参见[规范化插件](#normalisation-plugins))以进行项目特定的重写。
### 三合一折叠 — `--trinity-collapse`
`--db-aware` 折叠单个 DB 调用。自然的后续是**三合一折叠**:检测规范的 CRUD 形状
```
$user = User::find($id); // (1) read
$user->name = 'Bob'; // (2) mutate
$user->save(); // (3) save
```
……并将这三个语句重写为单个 `__DB_UPSERT__("user")` 合成调用,以便 ORM 惯用法与原始等效项
```
$pdo->query("UPDATE users SET name = 'Bob' WHERE id = $id");
```
(`--db-aware` 单独将其折叠为 `__DB_WRITE__` token)聚类在一起。
`Phpdup\Normalization\TrinityCollapser` 遍历 AST 中的每个语句数组(函数/方法/闭包主体、if/else 分支、循环主体)并寻找 **读取 → 变异 → 保存** 形式的三元组,其中:
- 读取是任何分配给变量(`$x = User::find($id)`、`$x = $em->find(User::class, $id)`、`$x = $repo->findOneBy([...])` 等)的 `DbOpRegistry::OP_READ` 调用。
- 变异是绑定变量上的属性赋值(`$x->name = 'Bob'`、`$x->name .= 'X'`)或 setter 调用(`$x->setName('Bob')`、`$x->withFoo(...)`、`$x->addThing(...)`)。至少需要一次变异——中间没有更改的读取+保存将保持不变。
- 保存终止链:接收者绑定的写入(`$x->save()`、`$x->update()`)、Doctrine flush(`$em->flush()`)或 `$em->persist($x)`(其中 `$x` 作为第一个参数匹配绑定变量)。
**变异检测改进。** 折叠器识别简单属性赋值之外的额外变异模式:
- **ArrayAccess / 数组赋值**——通过 `Node\Expr\ArrayDimFetch` 在绑定变量上的 `$x['key'] = value`。
- **直接数组追加**——绑定变量上的 `$x[] = value` 追加。
- **扩展的 ORM 变异前缀**——除了基本的 `set` / `with` / `add` / `remove` / `append` / `replace` 集合之外,还识别 setter 方法前缀 `force`、`update`、`change`、`modify`,因此像 `$x->forceUpdate(...)` 或 `$x->changeName(...)` 这样的惯用法被正确归类为变异。
读取和保存之间的任何无关语句都会放弃三元组——数据流遍历器有意保持保守;漏报比误报更可取。
`--trinity-collapse` 与 `--db-aware`(典型组合)组合使用,并作为 `DbOpCanonicalizer` *之前的前置传递* 运行,以便折叠器可以匹配原始的读取/保存调用形状。
### 行为标签评分
Type-4 行为评分器(`Phpdup\Similarity\BehaviouralSimilarity`)获得了第五个频段:**DB 操作标签多重集 Jaccard**,与现有的调用名称和返回形状频段加权相等。
`Phpdup\Semantic\DbOperationTagger` 遍历每个块一次并生成粗略的 `tag → count` 摘要:
```
['db.read' => 2, 'db.write' => 1, 'db.execute' => 1]
```
具有相同 DB 形状的两个函数——相同数量的读取、写入、删除、执行和查询——在标签频段下得分相似,*无论哪个库或扩展* 提供每个操作。这折叠了库/扩展轴(Eloquent 与 Doctrine 与 PDO 与 mysqli 与 `pg_*`),而无需按对的表面分析。
对于不接触数据库的块(按照惯例,空包与空包比较为 `1.0`),标签频段是一个*空操作*,因此非 DB 代码不受影响。行为评分器的总权重现在是 `1 + 2 + 2 + 1 + 2 = 8`(变量 + 调用 + 返回 + 副作用 + DB 标签),归一化回 `[0, 1]`。
标记器重用与 `DbOpCanonicalizer` 相同的 `DbOpRegistry`,因此已识别的调用集在规范化和评分层中是一致的,并且由 `--db-aware` / `--trinity-collapse` 生成的合成 `__DB___` 调用也被正确标记。
### 符号等价类
内置的 `DbOpRegistry` 涵盖了明显的表面区域,但每个代码库都有在不使用已识别名称的情况下执行 DB 工作的包装器、助手和自制门面。计划的**选项 4** 公开了一个用户可扩展的符号等价注册表:在 `phpdup.json`(或配置文件 JSON 中)中声明 `app_db_get`、`MyRepo::lookup` 和 `LegacyDb::raw` 都与内置条目含义相同——并且它们会折叠为相同的规范 `__DB___` token。
```
{
"db_aware": true,
"db_symbols": {
"methods": {
"lookup": "db.read",
"persistMe": "db.write",
"wipe": "db.delete"
},
"functions": {
"app_db_get": "db.read",
"app_db_query": "db.query"
}
}
}
```
允许的规范操作:`db.read`、`db.write`、`db.delete`、`db.execute`、`db.query`。自定义条目会覆盖同名内置条目;其他所有内容都是累加的。
**捆绑符号包。** 开箱即用地附带 28 个框架风味的包,可以通过 `--profile` 加载:
| 配置文件名 | 添加的内容 |
|-----------------------------|------------------------------------------------------------------------------------------------------|
| `db-aware-laravel` | Eloquent / Laravel 方法(`firstWhere`、`pluck`、`chunk`、`increment`、raw\* 助手)。 |
| `db-aware-doctrine` | Doctrine ORM / DBAL(`createQuery`、`executeStatement`、`fetchAssociative*`、事务助手)。 |
| `db-aware-cake` | CakePHP ORM(`patchEntity`、`saveOrFail`、`findThreaded`、`loadInto`)。 |
| `db-aware-codeigniter` | CodeIgniter 4 DB Query Builder(`get`、`insert`、`update`、`delete`、`countAll`、`escape`)。 |
| `db-aware-thinkorm` | ThinkPHP 6.x / think-orm(`find`、`select`、`insert`、`update`、`delete`、`count`、聚合)。 |
| `db-aware-yii` | Yii 2 ActiveRecord / DB(`find`、`findOne`、`findAll`、`save`、`insert`、`update`、`delete`、`createCommand`)。 |
| `db-aware-medoo` | Medoo(`select`、`insert`、`update`、`delete`、`create`、`drop`、`query`、`exec`)。 |
| `db-aware-propel` | Propel ORM(`doSelect`、`doInsert`、`doUpdate`、`doDelete`、`find`、`save`)。 |
| `db-aware-redbean` | RedBeanPHP(`find`、`dispense`、`store`、`trash`、`save`、`load`、`wipe`、`related`)。 |
| `db-aware-cycle` | Cycle ORM(`find`、`findAll`、`persist`、`delete`、`select`、`where`、`aggregate`)。 |
| `db-aware-phpactiverecord` | PHP ActiveRecord(`find`、`all`、`first`、`last`、`create`、`save`、`update`、`delete`、`destroy`)。|
| `db-aware-myadmin` | MyAdmin 自定义 db_abstraction(`MyDb\Mysqli\Db`、`MyDb\Pdo\Db` —— `query`、`qr`、`next_record`、`prepare`、`execute`)。 |
| `db-aware-myadmin-orm` | MyAdmin 自定义 ORM(`MyAdmin\Orm\*` 扩展 `Base\Orm` —— `find`、`load`、`save`、`update`、`insert`、`delete`、`truncate`)。 |
| `db-aware-illuminate` | Illuminate Database 独立版(`DB::table()`、`DB::()`、`DB::insert()`、`DB::update()`、`DB::delete()`、`DB::raw()`)。 |
| `db-aware-aura` | Aura.Sql(`fetchAll`、`fetchOne`、`query`、`execute`、`quote`、`begin/commit/rollback`)。 |
| `db-aware-atlas` | Atlas.PDO(`fetchAll`、`fetchAssoc`、`fetchSelect`、`begin/commit/rollback`)。 |
| `db-aware-easydb` | EasyDB(`query`、`fetchAll`、`fetchOne`、`iterator`、`safeQuery`、`build`)。 |
| `db-aware-dibi` | Dibi(`query`、`fetchAll`、`fetch`、`test`、`begin/commit/rollback`)。 |
| `db-aware-pixie` | Pixie Query Builder(`table`、`get`、`insert`、`update`、`delete`、`where`、`orderBy`)。 |
| `db-aware-redis` | Redis(Predis、Credis、phpredis)—— `get`、`set`、`mget`、`mset`、`hget`、`hset`、`del`、`expire` 等。 |
| `db-aware-mongodb` | MongoDB 驱动(`find`、`findOne`、`insertOne`、`insertMany`、`updateOne`、`deleteOne`、`aggregate`、`count` 等)。 |
| `db-aware-elasticsearch` | Elasticsearch PHP 客户端(`search`、`index`、`get`、`mget`、`bulk`、`delete`、`update`、`count`、`scroll`、`msearch`)。 |
| `db-aware-neo4j` | Neo4j PHP 客户端(`run`、`match`、`create`、`merge`、`set`、`delete`、`detachDelete`)。 |
| `db-aware-influxdb` | InfluxDB 客户端(`query`、`write`、`ping`、`bucket`、`organization`、`flux`)。 |
| `db-aware-couchdb` | Doctrine CouchDB ODM(`find`、`findBy`、`persist`、`save`、`remove`、`delete`、`refresh`)。 |
| `db-aware-couchbase` | Couchbase SDK(`get`、`upsert`、`insert`、`replace`、`remove`、`lookupIn`、`mutateIn`、`view`、`query`)。 |
| `db-aware-idiorm` | Idiorm/Paris(`find`、`findOne`、`where`、`orderBy`、`count`、`create`、`save`、`update`、`delete`)。 |
| `db-aware-laminas` | Laminas\Db(原 Zend\Db)适配器(`select`、`fetchAll`、`fetchOne`、`query`、`insert`、`update`、`delete`)。 |
| `db-aware-phalcon` | Phalcon ORM(`find`、`findFirst`、`save`、`create`、`update`、`delete`、`refresh`、`query`、`aggregate`、`sum`、`count`、`average`、`min`、`max`)。 |
将它们与 `--db-aware` 组合使用以进行规范化传递以及内置 DB 调用覆盖。用户在 `phpdup.json` 中的 `db_symbols` 优先于配置文件提供的符号,而后者又优先于内置注册表。
### IR — 中间表示提升
`Phpdup\Ir\` 是计划**选项 5**的基础脚手架:位于 PHP AST 和相似度评分器之间的规范、语言/库无关的表示。
```
Block (PHP AST) → IR (canonical operation graph) → fingerprint / score
```
IR 将 PHP 特定的语法(`$x->y` 和 `$x['y']` 之间的区别,`for` 和 `foreach` 之间,`if/else` 和 `match` 之间)替换为一小部分操作形状的节点:
| IR 节点 | 提升自 |
|------------------|-----------------------------------------------------------------------|
| `DbReadIr` | `Model::find`、`$em->find(...)`、`$pdo->query("SELECT …")`、`pg_*` 读取。 |
| `DbWriteIr` | `$x->save`、`$em->flush`、`$pdo->query("UPDATE …")`、`pg_insert/update`。 |
| `DbDeleteIr` | `Model::destroy`、`$em->remove`、`DELETE FROM …`、`TRUNCATE …`。 |
| `DbQueryIr` | 没有干净读/写分类的通用 `query`/`exec` 调用。 |
| `DbExecuteIr` | `prepare`/`execute` 风格的两阶段调用。 |
| `AssignIr` | 局部赋值——LHS 形状折叠为 `var`/`prop`/`index`/… |
| `BranchIr` | `if`/`else`、`match`、`switch`(展开为嵌套分支)、三元表达式。 |
| `LoopIr` | `for`、`foreach`、`while`、`do-while`——关键字区别被抹除。 |
| `CallIr` | 任何未识别的方法/函数/静态调用。 |
| `ReturnIr` | `return [expr];` 和裸 `return;`。 |
| `VarIr` | 变量引用(名称折叠为 `__V`)。 |
| `LiteralIr` | 标量字面量(只有*类型*——`str`/`int`/`float`/`bool`/`null`——保留)。 |
| `BlockIr` | 语句序列(函数/方法主体、分支臂、循环主体)。 |
`Phpdup\Ir\IrLifter` 遍历 PhpParser AST 并生成 IR 树。
提升在设计上是**部分的**:未识别的输入形状(例如 `eval`、`goto`、复杂的可变变量)会落入带有节点类名的通用 `CallIr`;如果提升完全失败,则提升器返回 `null`,调用者回退到 AST 级别的评分(根据计划的风险缓解说明)。
`Phpdup\Ir\IrPrinter` 生成确定性 token 流和人类可读的漂亮打印。`Phpdup\Ir\IrSimilarity` 对两个 IR 树进行评分:对于相同的打印 token 流为 `1.0`(通过 `IrSimilarity::hash()` 公开 SHA-1 哈希快速路径),然后是多集 Jaccard 回退以用于部分重叠。
IR 评分器在 `--scorer=ir` 之后作为第五层接入 `Clusterer`。当 AST Jaccard / TED / 包含度都拒绝一对时,聚类器回退到预计算 IR token 包(`Block::$irBag`,当 `scorer=ir` 时由 `PreprocessWorker` 填充)上的多集 Jaccard;达到或超过 `--ir-threshold`(默认 `0.85`)的对形成由 IR 相似度加权的边。任一块上的提升失败都会使 `irBag` 保留为空,并且 IR 层会静默跳过该对,保留了计划的风险缓解说明(“在提升失败时回退到 AST 评分”)。
### ML 学习的对相似度 (sidecar)
phpdup 附带了一个 sidecar 契约,用于计划的**选项 6**:一个在包含 ORM ↔ 原始 SQL 示例的标记语料库上训练的外部 ML 对评分服务。PHP 端保持轻量级:
- `Phpdup\Ml\PairFeatures` 使用现有的数据流摘要、DB 操作标签和 IR token 流从 `(blockA, blockB)` 对中提取 11 个字段的特征向量——不需要 ML 库。
- `Phpdup\Ml\MlPairClient` 是现有 `MlClient`(聚类安全性评分)的 HTTP 伴随程序。它将特征向量 POST 到配置的 sidecar 上的 `/score-pair` 并使用单个 `{similarity, confidence}` 响应。
- `MlPairClient::score()` 在传输错误、格式错误的响应或不安全的 URL 时返回 `null`——调用者无需代码路径分支即可回退到 AST 级别的评分,反映了 IR 提升器的优雅失败模式。
连线契约记录在 [`docs/ML.md`](docs/ML.md) 中;sidecar 期望的标记语料库格式记录在 [`docs/ml-corpus-format.md`](docs/ml-corpus-format.md) 中。每个负载中都嵌入了 `feature_version` 字段,以便当模型针对不同的特征形状进行训练时,sidecar 可以发出警告(每当 schema 更改时,`PairFeatures::FEATURE_VERSION` 常量就会递增)。
模型本身、训练管道和标记语料库都位于姐妹存储库中——phpdup 仅附带契约和特征提取器。
一旦 sidecar 运行,通过 `--ml-pair-url`(或 `phpdup.json` 中的 `ml_pair_url`)指向它:
```
bin/phpdup analyze src --ml-pair-url=https://ml.example.com/api \
--ml-pair-threshold=0.85
```
`Phpdup\Clustering\Clusterer` 和 `Phpdup\Parallel\PairScoreWorker` 都将配置的 `Phpdup\Ml\PairScorer` 作为**最后**的聚类层进行查询——在结构哈希、AST Jaccard + TED、包含度和 IR 都拒绝一对之后。客户端在传输失败时返回 null(模型不可用、SSRF 拒绝的 URL、格式错误的响应),因此管道的其余部分继续以降低的精度运行,而不是使运行失败,反映了 IR 提升器的优雅失败契约。
## TUI 模式
`--tui` 打开一个从运行时内部驱动分析管道的 SugarCraft 仪表板——计数和计时随着工作进展而逐渐增加,而不是事后出现。

你将获得:
- **四窗格 FlexBox 仪表板**,带有 Scanning / Preprocessing / Clustering / Refactoring 的实时计数。
- 运行窗格中的 **SugarCraft 加载动画**(12 种动画样式之一)以及实时运行秒表。
- 每个阶段完成时的 **阶段持续时间迷你图**。
- **OSC 9;4 任务栏进度**——ConEmu、WezTerm 和 Windows Terminal 在 OS 任务栏上固定一个进度指示器。
- **六种主题**:`ansi`(默认)、`plain`、`charm`、`dracula`、`nord`、`catppuccin`——通过 `--theme=NAME` 选择。
- **键盘**:`q` / `Ctrl+C` 退出,`Ctrl+Z` 挂起,`↑/↓` 循环窗格焦点,`Enter` 打开详情,`←/→` 在详细视图中循环聚类,`t` 切换排序(影响 / 相似度 / 名称),`h` 切换帮助,`Esc` 关闭详情。
- **`--plain`** 强制纯 CLI 输出,即使 `--tui` 会触发(适用于 CI 和管道)。
管道通过协作的 `Pipeline::iter()` 生成器在运行时*内部*运行。每次 `next()` 推进到下一个 yield 点——阶段前、阶段后、`ScanningStage` 中的每 16 个文件、从并行预处理池流回的每 32 条记录。在 yield 之间运行时进行渲染,因此迷你图、文件计数、解析错误总数和任务栏进度会逐帧建立。
## Watch 模式
`--watch` 保持 phpdup 运行并在每次文件更改时重新分析。
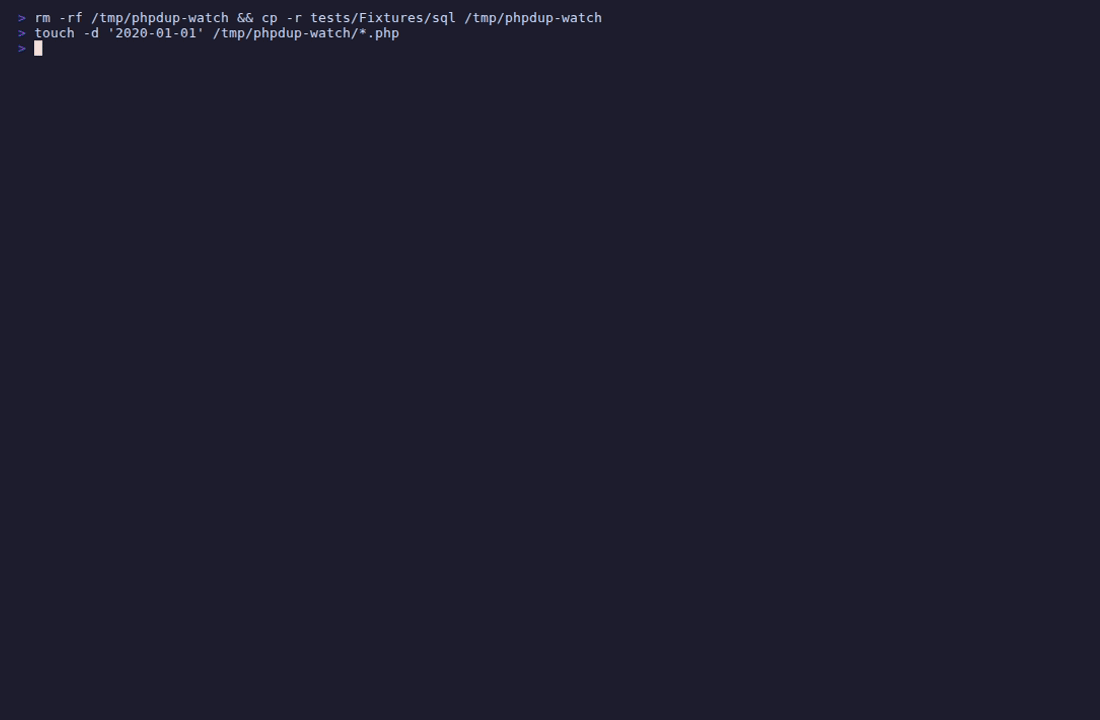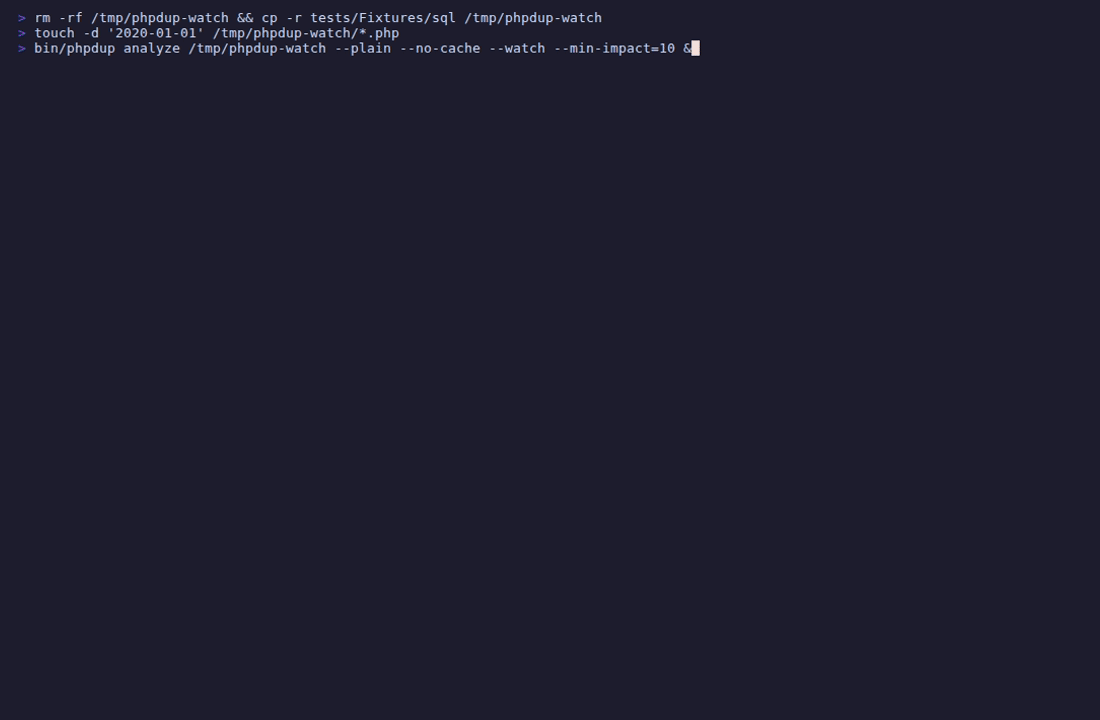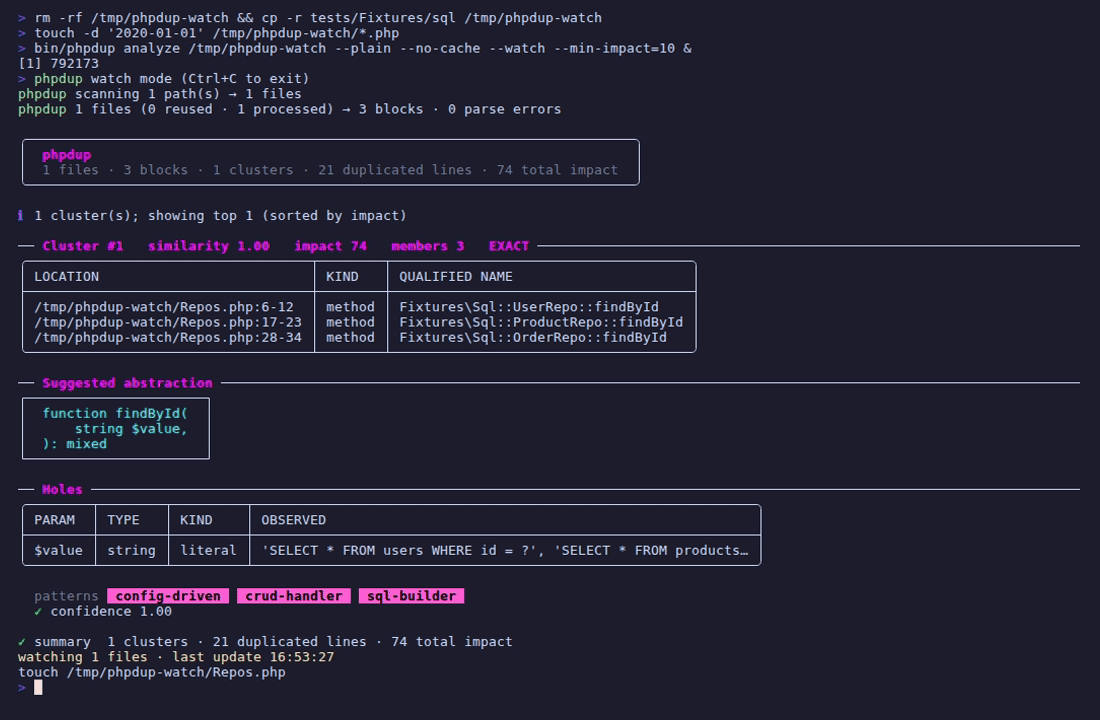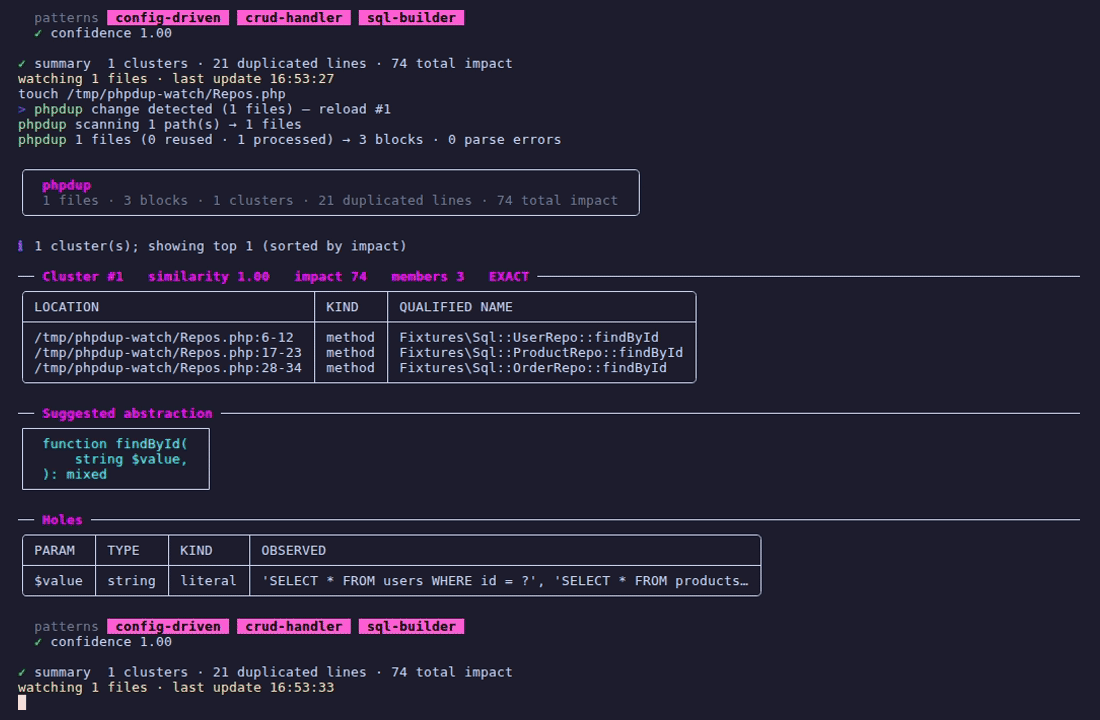
一个 `React\EventLoop` 周期计时器(默认 1.5 秒)轮询每个扫描文件的 `filemtime()`,在每次读取前带有 `clearstatcache()` 以击败 PHP 的 stat 缓存。当任何 mtime 更改时,phpdup 重新运行完整的管道并报告 `change detected (N files) — reload #X`。
轮询而不是 `inotify` / FSEvents 使监视器保持无依赖并可移植到 macOS / Linux 而无需扩展——代价是较小的(≤ 1.5 秒)重新加载延迟。
`Ctrl+C`(或 `SIGTERM`)通过 `Loop::addSignal` 触发干净的拆卸。**支持 `--watch --tui`**——监视器的周期计时器注册在 SugarCraft `Program` 运行所在的同一 `React\EventLoop` 实例上,因此仪表板在轮询时保持交互。更改时,监视器向程序分派 `RestartPipelineMsg`;模型重置状态,通过其工厂重建协作生成器,窗格中的实时计数在重新攀升之前降至零。
## SIGINT 软取消
在分析期间(在 `--watch` 之外)按下 `Ctrl+C` 不会丢弃正在进行的任务。`Phpdup\Cli\SignalHandler` 注册一个异步 SIGINT 处理程序,用于翻转 `PipelineState::$cancelled`;协作管道在阶段之间检查此标志并直接短路到报告阶段。用户会获得一份涵盖已形成聚类的部分报告,以及一个非零的退出代码(130,标准的 SIGINT 代码),以便 CI 工作流可以区分“用户取消”和“干净运行”。
第二次 `Ctrl+C` 恢复默认的 SIGINT 处理程序,因此真正卡住的进程仍然可以通过三次触发默认的逃生舱口被终止。
## `phpdup serve` REST API
`phpdup serve` 在分析管道之上启动一个最小的 HTTP 服务。适用于内部仪表板、CI 集成和托管后端游乐场前端。
```
phpdup serve --host 127.0.0.1 --port 8080
```
路由:
| 方法 | 路径 | 主体 | 返回 |
|--------|----------------|-----------------------------------|---------|
| GET | `/healthz` | — | `text/plain "ok"` |
| POST | `/analyze` | JSON: `{"paths":["src","lib"]}` | 完整的 JSON 报告 |
| POST | `/jobs` | JSON: 同 `/analyze` | `202 {"job_id":"…"}` |
| GET | `/jobs/{id}` | — | 作业状态 + 结果 |
实现有意保持轻依赖:`stream_socket_server` 加上手写的 HTTP/1.1 解析器。没有 ReactPHP / Amp 依赖——对于高流量部署,在 nginx 后面换入 Roadrunner / FrankenPHP / FPM 并直接重用 `Phpdup\Server\Application`。
安全默认值:
- 默认绑定是 `127.0.0.1`——外部公开需要反向代理。
- Content-Length 上限为 16 MB。
- JSON 解析使用 `JSON_THROW_ON_ERROR` 并在格式错误的主体上返回 400。
- `Application` 类完全与传输无关,并且在没有网络的情况下进行了单元测试。
有关完整的契约、部署说明和游乐场架构,请参见 [`docs/SERVER.md`](docs/SERVER.md)。
## 输出格式
```
bin/phpdup analyze src \
--json phpdup.json \
--html phpdup-report \
--sarif phpdup.sarif \
--gitlab-sast phpdup.gitlab.json \
--diff ./phpdup-diffs \
--patch phpdup.patch \
--checkstyle phpdup.xml \
--csv phpdup.csv \
--prometheus phpdup.prom \
--timeseries phpdup-history.jsonl \
--graphviz phpdup.dot \
--plantuml phpdup.puml \
--refactor-patch ./phpdup-refactors \
--refactor-tests ./phpdup-refactor-tests
```
phpdup 附带**十二种**输出格式;在经典五种之上的新增内容是:
- **CSV**(`--csv=FILE`)——扁平的每行一个聚类成员;非常适合电子表格 / BI 摄取。多行签名折叠为一行,因此消费者不必处理嵌入的换行符。
- **Prometheus** 文本格式(`--prometheus=FILE`)——适用于 `pushgateway` 抓取或 CI 仪表板的 `# HELP` / `# TYPE` 注释量规。包括每个模式标签的计数器。
- **时间序列 JSONL**(`--timeseries=FILE`)——每次运行附加一行,通过 `GIT_COMMIT` / `GITHUB_SHA` / `CI_COMMIT_SHA` / `BUILD_VCS_NUMBER`(带有 `.git/HEAD` 回退)进行 commit 标记,因此随着时间的推移跟踪重复债务曲线变得轻而易举。
- **Graphviz DOT**(`--graphviz=FILE`)——文件→聚类二分图;使用 `dot -Tpng phpdup.dot -o phpdup.png` 渲染。
- **PlantUML**(`--plantuml=FILE`)——类图风格,每个聚类作为一个 `package` 和模式标签构造型。
- **重构补丁**(`--refactor-patch=DIR`)——启发式、需人工审查的 `.patch` 文件。每个文件添加一个带有建议抽象签名的 `Refactored/.php` 骨架以及每个成员的编辑提示。当 `$this`/`self::`/`yield`/闭包捕获会使机械替换变得不安全时,转至人工审查头。
- **PHPUnit 测试骨架**(`--refactor-tests=DIR`)——每个聚类一个带有 `casesProvider()`(从观察到的孔值填充)的 `markTestIncomplete()` 测试类。
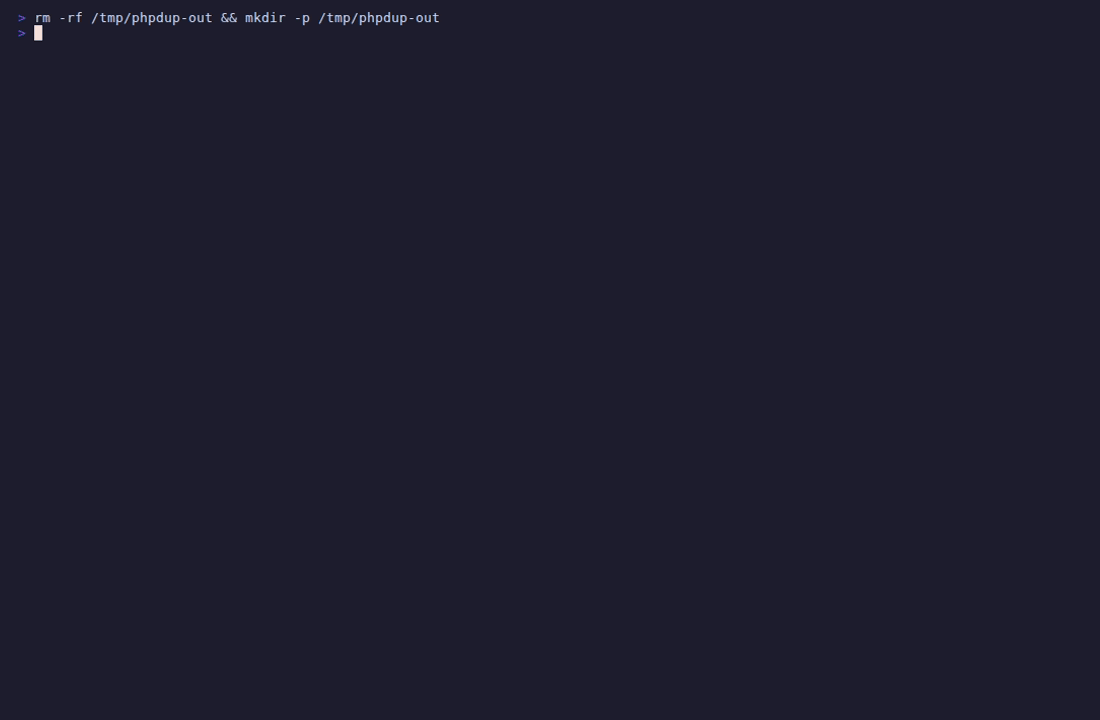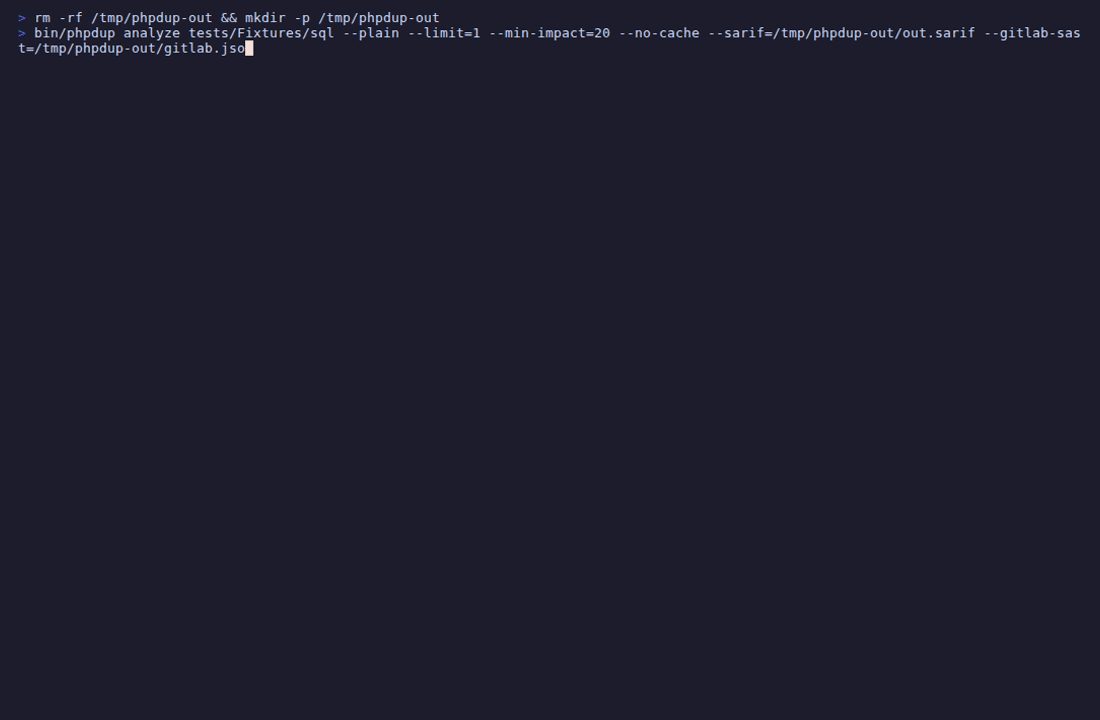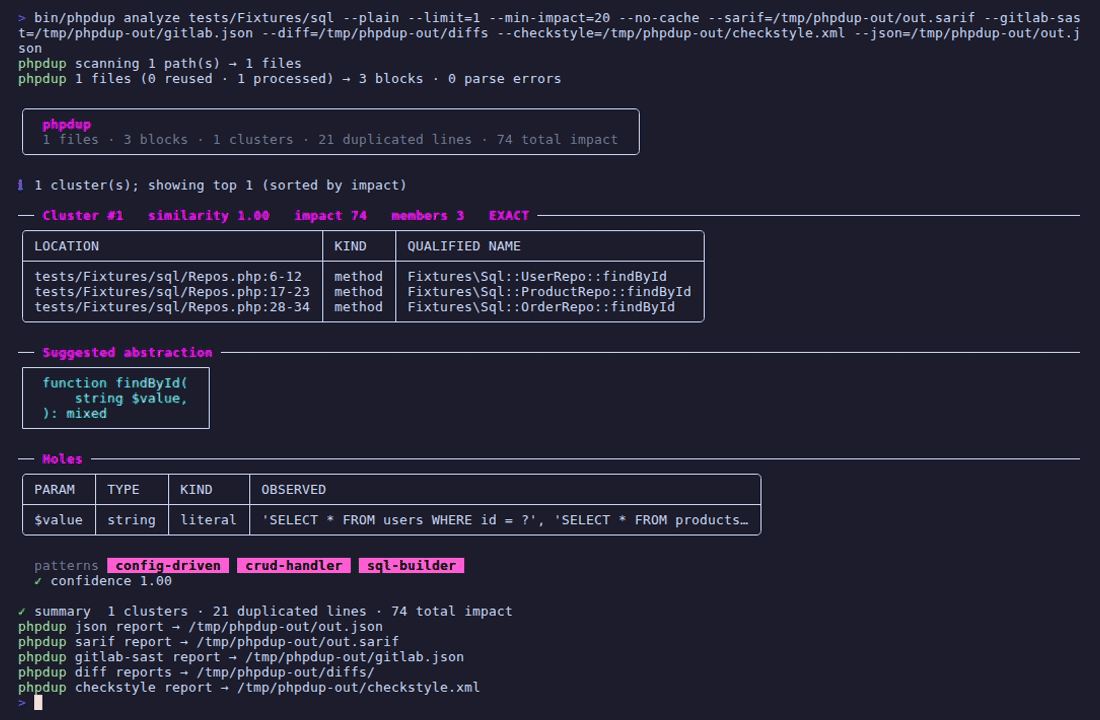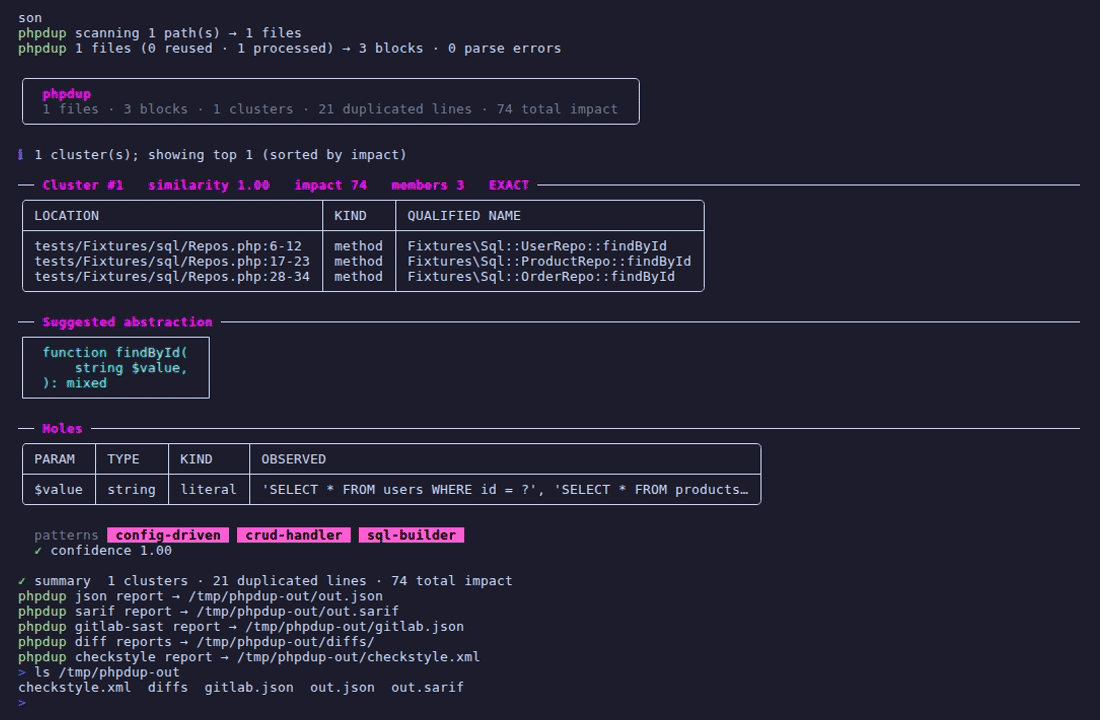
### CLI
SugarCraft 风格的彩色终端输出。遵循 `--no-ansi` / non-TTY:切换到 `Theme::plain()` 并跳过样式框 / 芯片,生成干净的 ASCII。
### JSON (`--json=FILE`)
```
{
"phpdup_version": "0.1.0",
"summary": { "files": 1888, "blocks": 12340, "clusters": 87 },
"clusters": [
{
"id": "Xaeb0e34a",
"kind": "method",
"exact": true,
"similarity": 1.0,
"confidence": 1.0,
"impact": 74,
"pattern_tags": ["config-driven", "crud-handler", "sql-builder"],
"signature": "function findById(string $value): mixed",
"members": [ ... ],
"holes": [
{
"placeholder": "__P0",
"kind": "literal",
"inferred_type": "string",
"suggested_name": "$value",
"observed": [
"'SELECT * FROM users WHERE id = ?'",
"'SELECT * FROM products WHERE id = ?'"
]
},
{
"placeholder": "__O0",
"kind": "optional_block",
"inferred_type": "bool",
"suggested_name": "$includeAudit",
"observed": ["audit($id);", ""],
"present_in_members": [0]
}
]
}
]
}
```
`holes[].present_in_members` 是 `optional_block` 孔独有的——它列出了*确实*包含该段的聚类成员索引。
### HTML (`--html=DIR`)
带有以下内容的静态站点报告:
- 按影响排序的索引页,带有聚类影响分布的**交互式迷你图**(绿色条表示精确,蓝色条表示近似重复;点击跳转)。
- 客户端**列排序**(点击任何标题)和**搜索过滤器**输入。
- 每个聚类的**复制建议签名**按钮(Clipboard API + 非安全上下文的 `execCommand` 回退)。
- 每个聚类的页面,成员源代码并排显示,**内联语法高亮**(无外部依赖,无构建步骤),孔表,前两个成员之间的 unified diff。
- 可选行用琥珀色着色,带有“type-3”徽章和斜体的 `` 标记。
JS 位于 `app.js` 中,紧挨着 `style.css`——两者都内联到构建中,无外部依赖,无构建步骤。
### SARIF (`--sarif=FILE`)
用于 GitHub Code Scanning 和 GitLab Code Quality 的 [SARIF 2.1.0](https://docs.oasis-open.org/sarif/sarif/v2.1.0/os/sarif-v2.1.0-os.html) 输出。每个重复块成为一个带有规则 `phpdup/duplicate-logic` 的 `result`,精确克隆的级别为 `warning` / 近似重复为 `note`,`properties.suggestedSignature` 中的聚类建议签名,以及共享的 `partialFingerprints.clusterId`,以便 SARIF 消费者可以将同级结果分组到一个聚类注释中。Type-3 聚类添加 `properties.optionalSegmentCount` 和 `properties.hasOptionalSegments`。
在 GitHub Actions 工作流中:
```
- run: vendor/bin/phpdup analyze src --sarif=phpdup.sarif --min-impact=50
- uses: github/codeql-action/upload-sarif@v3
if: always()
with:
sarif_file: phpdup.sarif
```
### GitLab SAST (`--gitlab-sast=FILE`)
[GitLab SAST 报告 v15.x](https://gitlab.com/gitlab-org/security-products/security-report-schemas)。
严重性按影响分桶(`>100` 为 High,`>=50` 为 Medium,`>=20` 为 Low,否则为 Info)。精确克隆的置信度为 `High`,否则从聚类置信度分数派生。将其作为 `report.sast` 工件连接到 `.gitlab-ci.yml` 中,以便 MR 安全小部件显示重复项。
### Diff 和补丁 (`--diff=DIR`, `--patch=FILE`)
`--diff=DIR` 为每个聚类写入一个 `.diff` 文件——从 member[0] 到每个后续成员的成对 unified diff,带有显示建议抽象和锚点位置的头部注释。`--patch=FILE` 将每个聚类的 diff 连接到一个累积的补丁文件中。
### Checkstyle XML (`--checkstyle=FILE`)
可被 Jenkins Warnings NG、Bitbucket Reports、Sonar、Detekt 消耗——任何解析 Checkstyle 的工具。每个重复项都是一个 ``,其中 `source="phpdup.duplicate-logic"`,精确 / 近似重复的严重性为 `warning` / `info`,以及链接回聚类 ID 的描述性消息。
## 配置
在你的代码旁边放一个 `phpdup.json`,或者传递 `--config`:
```
{
"paths": ["src", "app", "lib"],
"exclude": ["vendor/**", "node_modules/**", "**/*.tpl.php", "tests/**"],
"min_block_size": 8,
"max_block_size": 800,
"normalization_mode": "aggressive",
"similarity_threshold": 0.80,
"tree_threshold": 0.85,
"min_cluster_impact": 20,
"max_df": 0.01,
"ngram_size": 5,
"cache_dir": ".phpdup-cache",
"workers": 0,
"incremental": true,
"lazy_ast": true,
"kinds": ["method", "closure"],
"optional_blocks": {
"enabled": true,
"containment": 0.85,
"min_overlap": 0.6,
"max_per_cluster": 3,
"min_segment_length": 1
},
"report": {
"html": "phpdup-report",
"json": "phpdup.json"
}
}
```
完整的 schema 位于 [`docs/config-schema.json`](docs/config-schema.json),并在加载配置文件时由 `Config
| `confidence` | Ranker 的 `[0..1]` “此重构有多安全” 评分。 |
| `name` | 首个成员的限定名称(`Namespace\Class::method`),按字母顺序排序。 |
| `file` | 首个成员的文件路径,按字母顺序排序。 |
| `id` | 聚合 ID,按字母顺序排序(主要用于跨运行的稳定差异比较)。 |
排序方向默认为 `desc`。使用 `:asc` / `:desc`,或快捷前缀 `-`(降序)和 `+`(升序):
```
bin/phpdup analyze src --sort=members:desc # most-duplicated clusters first
bin/phpdup analyze src --sort=block-size:desc # biggest blocks first
bin/phpdup analyze src --sort=lines # most duplicated lines (desc default)
bin/phpdup analyze src --sort=similarity:asc # weakest matches first — review marginal type-3
bin/phpdup analyze src --sort=confidence:desc # safest refactors first
bin/phpdup analyze src --sort=name:asc # alphabetical
bin/phpdup analyze src --sort=-impact # leading - = desc shortcut
bin/phpdup analyze src --sort=+lines # leading + = asc shortcut
```
平局时的排序会保持一致性(成员数 DESC ▸ 相似度 DESC ▸ id ASC),因此无论用户指定的主要排序方向如何,相同的输入总是会产生相同的最终排序。
在 TUI 中,`t` 键可在相同的排序键之间实时循环(影响度 → 成员数 → 代码块大小 → 行数 → 相似度 → 置信度 → 名称 → 循环),而 shift-`T` 用于切换升序/降序。当前的排序方式显示在提示行中。
#### `--stats`
在报告之后打印流水线各阶段的耗时、代码块类型直方图和工作线程信息。
```
bin/phpdup analyze src --stats
```
### 运行时
#### `-c, --config FILE`
从 `phpdup.json` 文件加载设置。命令行标志会覆盖文件中的值。
```
bin/phpdup analyze --config=phpdup.json src
```
#### `-j, --workers N`(默认值:`0` = 自动)
用于并行预处理和配对评分的工作线程数量。`0` 表示从 `nproc` / `/proc/cpuinfo` 自动检测。`1` 表示强制串行执行。
```
bin/phpdup analyze src --workers=8 # explicit
bin/phpdup analyze src -j 1 # serial — debugging
```
#### `--no-cache`
在此运行期间不读取或写入 AST 缓存。
```
bin/phpdup analyze src --no-cache # benchmarking, or after upgrading php-parser
```
#### `--no-incremental`
禁用按文件的索引复用。即使 IndexStore 有命中记录,也强制重新计算每个文件的指纹。
```
bin/phpdup analyze src --no-incremental # benchmarking, or paranoid about cache
```
#### `--no-lazy-ast`
在整个运行过程中将所有原始 AST 保留在内存中。更高的 RSS 占用,但反统一(anti-unification)速度会略快一些。
```
bin/phpdup analyze src --no-lazy-ast # have RAM, want speed
```
#### `--stage NAME`
在 STAGE 之后暂停流水线(可选值为 `scanning`、`preprocessing`、`clustering`、`refactoring`、`reporting` 之一)。适用于调试增量缓存命中情况或分析各个阶段的性能。
```
bin/phpdup analyze src --stage=preprocessing --stats # measure how long parsing takes
bin/phpdup analyze src --stage=clustering # see clusters before refactor synthesis
```
### TUI / watch
#### `--tui`
在分析运行时显示交互式 SugarCraft 仪表盘。需要真实的 TTY 环境。
```
bin/phpdup analyze src --tui
```
#### `--theme NAME`(默认值:`ansi`)
TUI 主题:`ansi` | `plain` | `charm` | `dracula` | `nord` | `catppuccin`。
```
bin/phpdup analyze src --tui --theme=dracula
bin/phpdup analyze src --tui --theme=catppuccin
```
#### `--plain`
强制使用普通 CLI 输出(无 TUI,无 ANSI 颜色)。适用于 CI shell 报告 `isatty()=true` 但您希望输出不带颜色的情况。
```
bin/phpdup analyze src --plain
```
#### `--watch`
保持运行并通过基于轮询的 `React\EventLoop` 定时器在文件更改时重新分析。与 `--tui` 结合使用可实现实时仪表盘。
```
bin/phpdup analyze src --watch # plain mode, prints reload messages
bin/phpdup analyze src --watch --tui # interactive dashboard, resets on change
```
### 验证
#### `--validate-config`
根据文档中的 schema 验证 `--config` 文件,然后退出而不运行分析。退出码 `0` = 正常,`2` = 错误(附带字段路径)。
```
bin/phpdup analyze --config=phpdup.json --validate-config && echo OK
```
### Shell 补全
phpdup 内置了 `completion` 子命令。其输出是所选 shell 的标准 Symfony Console 补全脚本,并在开头附带了**注释掉的安装说明**,以便您可以 `cat` 输出内容并按说明逐步操作:
```
bin/phpdup completion bash # → bash script + comments showing 3 install paths
bin/phpdup completion fish # → fish script + comments
bin/phpdup completion zsh # → zsh script + comments (#compdef stays first)
```
每种 shell 最常用的一行命令:
```
# bash — 在 XDG home 下的按用户补全
mkdir -p ~/.local/share/bash-completion/completions
phpdup completion bash > ~/.local/share/bash-completion/completions/phpdup
# fish — 在下次 shell 启动时自动加载
mkdir -p ~/.config/fish/completions
phpdup completion fish > ~/.config/fish/completions/phpdup.fish
# zsh — 在 $fpath 上选择一个目录,需在 compinit 之前
mkdir -p ~/.zsh/completions
phpdup completion zsh > ~/.zsh/completions/_phpdup
# 然后在 ~/.zshrc 中,在 'compinit' 之前: fpath=(~/.zsh/completions $fpath)
```
当省略 `shell` 参数时,将参考 `$SHELL` 环境变量。未知的 shell 将以退出码 `2` 退出。
### 退出码
| 代码 | 含义 |
|------|------------------------------------------------------|
| `0` | 分析已完成。注意:phpdup 在发现集群时**不会**以非零退出码退出。|
| | 请使用 JSON 报告来控制 CI;空的 `clusters` 数组表示代码整洁。|
| `1` | 内部错误。 |
| `2` | 缺少必需的参数或配置无效。 |
### 环境变量
| 变量 | 效果 |
|-------------------|-------------------------------------------------------|
| `PHPDUP_WORKERS` | 覆盖工作线程数量(优先级低于 `-j`)。 |
| `COLUMNS` | 覆盖 CLI 报告的终端宽度检测。 |
## 编程方式使用
流水线可以从 PHP 完全自由组合。最简单的入口点是 `Pipeline` 本身;其他所有内容都通过阶段构造函数插入其中:
```
use Phpdup\Cli\Config;
use Phpdup\Pipeline\Pipeline;
use Phpdup\Pipeline\PipelineState;
use Phpdup\Pipeline\Stages\ScanningStage;
use Phpdup\Pipeline\Stages\PreprocessStage;
use Phpdup\Pipeline\Stages\ClusterStage;
use Phpdup\Pipeline\Stages\RefactorStage;
use Phpdup\Pipeline\Stages\ReportStage;
use Symfony\Component\Console\Output\NullOutput;
$config = new Config(
paths: ['src'],
exclude: ['vendor/**'],
optionalBlocksEnabled: true,
);
$state = new PipelineState($config);
(new Pipeline([
new ScanningStage(),
new PreprocessStage(useCache: true),
new ClusterStage(exactOnly: false),
new RefactorStage(useCache: true),
new ReportStage(limit: 50, showStats: false),
]))->run($state, new NullOutput());
foreach ($state->clusters as $c) {
echo "{$c->size()} members, signature: {$c->signature}\n";
}
```
为了进行更细粒度的控制——例如,要在不进行集群分析的情况下运行预处理,或者要从您自己的事件循环中协同驱动流水线——请使用 `Pipeline::iter()` 并由您自己手动驱动生成器。TUI 正是采用这种方式工作的。
## 示例
### 基于阈值的门控通知(type-2)
输入:
```
public function notifyHigh($user, int $score): void {
if ($score > 10) { $this->mailer->send('admin', $user); }
}
public function notifyMid($user, int $score): void {
if ($score > 20) { $this->mailer->send('moderator', $user); }
}
```
输出:
```
function notifyByThresholdAndStrategy(
int $threshold,
string $value,
): mixed
```
孔位:
| 参数 | 类型 | 观察值 |
|--------------|---------|-----------------------------------|
| `$threshold` | int | `10, 20` |
| `$value` | string | `'admin', 'moderator'` |
模式:`config-driven`。
### 仓库 CRUD(type-1 / type-2)
三个类包含 `findById($db, $id)` 方法,仅在表名上有所不同。
```
function findById(string $value): mixed
```
| 参数 | 类型 | 观察值 |
|----------|--------|---------------------------------------------------------|
| `$value` | string | `'SELECT * FROM users WHERE id = ?'`, |
| | | `'SELECT * FROM products WHERE id = ?'`, |
| | | `'SELECT * FROM orders WHERE id = ?'` |
模式:`config-driven, crud-handler, sql-builder`。
### 可选代码段(type-3)
用户请求的情况——请参阅 [Type-3 / 可选代码段检测](#type-3--optional-segment-detection) 了解算法。两个 `if` 体共享相同的开头三条语句;较长的那个在尾部多了两次额外调用。
```
function extractedFunction(
bool $includeSomeOtherLogic = false,
bool $includeAndMore = false,
): mixed
```
| 参数 | 类型 | 类型 | 观察值 |
|---------------------------|------|------------------|---------------------------------------|
| `$includeSomeOtherLogic` | bool | `optional_block` | `some_other_logic($here);`, `` |
| `$includeAndMore` | bool | `optional_block` | `and_more($f);`, `` |
模式:`optional-segments`。
### 策略分派
一系列 `if (...)` 语句分别调用了不同的验证器,这些验证器都具有相同的结构。集群被标记为 `strategy`,仅在调用名称上存在单一孔位,并将方法名称列表作为观察值——这是一个提取接口和策略数组的明确提示。
## 静态分析与配置验证
CI 在每次推送和 PR 时会运行三层静态检查:
```
- run: find src tests -name '*.php' -print0 | xargs -0 -n1 -P4 php -l > /dev/null
- run: vendor/bin/phpstan analyse --memory-limit=1G --no-progress
- run: vendor/bin/psalm --no-progress --no-cache
```
- **PHPStan level 6** 检查无误(无基线)。配置在
[`phpstan.neon`](phpstan.neon) 中。
- **Psalm** 在错误级别 6 运行,并具有已跟踪的基线
(`psalm-baseline.xml`),用于 APTED 实现中遗留的 `InvalidArrayOffset` /
`MissingParamType` 发现。
- **配置 schema 验证** —— `ConfigLoader::validate()` 镜像了
[`docs/config-schema.json`](docs/config-schema.json),并在首次违规时抛出
`RuntimeException`,其消息会指出违规字段。`--validate-config` 可独立运行验证,用于 CI 门禁。
## 基准测试
phpdup 附带了一个真实的对比基准测试工具——而不是合成的微基准测试。该套件在一个精选的公共 OSS 语料库组合上,将 phpdup 与其他用户可能选择的 PHP 重复检测工具一起运行,并报告了执行时间、峰值 RSS、集群数量,以及相对于基本事实的精确度 / 召回率 / F1 分数。它的设计是**诚实的**——phpdup 并不是在每个测试单元中都是最好的工具,下面的矩阵也直言不讳地说明了这一点。
### 对比基准测试套件
```
bench/run-all.sh
```
这就是整个流程:
1. 自动下载 `phpcpd.phar`(仅限 phar;约 3 MB)。
2. 在 `bench/tools/` 中运行 `npm install jscpd@4`(如果没有 node 则跳过)。
3. 浅克隆 OSS 语料库(Symfony Console、Laravel HTTP、
PHPUnit、WordPress 核心)。
4. 确定性地生成合成模糊测试语料库。
5. 在每个工具的执行时间上限内,使用每个可用工具针对每个语料库运行测试。
6. 根据合成语料库的 `.ground-truth.json` 对每个工具的输出进行评分。
输出:
- `bench/results/latest.md` —— 每个工具针对各个语料库的执行时间 / RSS /
集群数量。
- `bench/results/detection-rate.md` —— 每个工具在合成语料库上的精确度 / 召回率 /
F1 分数(这是唯一公平竞争的场景,因为我们知道确切答案)。
探测的工具(当缺失时自动跳过——在表中显示为 `—`):
| 工具 | 来源 | 自动安装 |
|-------------|---------------------------------------|----------------|
| **phpdup** | `bin/phpdup`(本仓库) | 始终安装 |
| phpcpd | `bench/tools/phpcpd.phar` | 是 |
| pmd-cpd | 系统 `pmd cpd` | 否——需单独安装 |
| jscpd | `bench/tools/node_modules/.bin/jscpd` | 是 |
| simian | 系统 `simian` | 否——商业软件 |
请参阅 [`bench/README.md`](bench/README.md) 以了解如何添加新工具或语料库,并参阅 `bench/feature-matrix.md` 查看功能比较。
### 功能矩阵
一份人工整理的 40 多行功能对比表,比较对象包括 phpcpd、pmd-cpd、
jscpd 和 simian——完整表格见
[`bench/feature-matrix.md`](bench/feature-matrix.md)。以下是摘要:
**phpdup 的优势:**
- **建议重构的输出。** 没有其他工具能生成参数化的函数签名、孔位清单和统一差异补丁。如果您的目标是“我想要重构这些重复代码”,phpdup 是唯一实用的选择。
- **Type-3 检测。** `--optional-blocks` 能找到在可选代码段上存在差异的克隆——phpcpd / pmd-cpd / jscpd 需要连续相同的 token 序列,因此完全忽略了这一点。
- **报告器覆盖范围。** phpdup 提供了 12 种输出格式,包括
SARIF、GitLab SAST、Prometheus、Graphviz 和 time-series JSONL。
其他工具没有提供超过三种的。
- **模式标签分类。** 将集群标记为 `sql-builder`、
`crud-handler`、`controller-action` 等是独一无二的,可让您按类型过滤/路由发现结果。
- **实时工作流。** `--watch` + TUI 适用于希望在重构时获得反馈的内循环开发者;没有其他工具能做到这一点。
- **诚实度。** phpdup 附带了合成模糊测试的基本事实评分器
(`bench/score.php`) 并发布了精确度/召回率——其他工具都没有发布。
**phpdup 的劣势:**
- **完全相同克隆的纯速度。** phpcpd 的分词器极其简单,在您只想要“是否有完全复制粘贴的内容?”时,其原始执行时间击败了 phpdup 的 AST + APTED 流水线。使用 `phpdup --exact-only` 可以缩小大部分差距。
- **小型输入的冷启动 RSS。** phpcpd 峰值约 50 MB;phpdup 峰值约 60–80 MB,因为它加载了 php-parser、Symfony Console 和整个流水线脚手架。
- **成熟的 IDE 集成。** PMD 拥有超过十年历史的 JetBrains 插件;phpdup 目前还没有(未来 IntelliJ 插件的契约位于 [`docs/JETBRAINS_PLUGIN.md`](docs/JETBRAINS_PLUGIN.md))。如果您的团队已经在 PhpStorm 的 PMD 检查中深度使用,那将是一个真正的锁定。
- **多语言支持。** jscpd 可通过单个二进制文件处理 PHP、JS/TS、Python、
Java、Ruby、Go、Rust 等。phpdup 在设计上仅支持 PHP。
- **维护认知。 phpcpd 已被归档,但它是历史上的默认选择——许多 CI 流水线仍在运行它。
**快速选择指南:**
| 如果您需要… | 请选择… |
|--------------------------------------|-------------|
| 可操作的重构输出、type-3 检测、模式标签,或任何独特的报告器 | **phpdup** |
| CI 中快速的完全相同克隆门禁,不需要其他功能 | phpcpd |
| JetBrains IDE 检查 / 多语言 Java + PHP 项目 | pmd-cpd |
| 多语言支持:通过一个二进制文件支持 PHP + JS + Python + … | jscpd |
| 基于行的商业差异查找器 | simian |
### 内部扩展性基准测试
phpdup 在真实 PHP 语料库(`include/Api/`:530 个文件,3,295 个可比较的代码块,96 个集群)上的自身并行扩展性:
| 配置 | 执行时间 | 与串行比较 |
|--------------------------------------------|----------:|----------:|
| 串行(`--workers 1`),冷缓存 | 61.13 s | 1.00× |
| 4 个工作线程,冷缓存 | 30.39 s | 2.01× |
| 8 个工作线程,冷缓存 | 21.11 s | 2.90× |
| 16 个工作线程,冷缓存 | 17.47 s | 3.50× |
| 8 个工作线程,`--exact-only` | 5.74 s | 10.65× |
集群输出在不同配置之间是字节级完全相同的——这些加速并非来自跳过工作。APTED 确实执行了正确的 Zhang-Shasha 工作(每对计算比有界启发式算法慢);用户可见的收益来自于在此基础上的并行化堆叠。
在您自己的语料库上重现:
```
rm -rf .phpdup-cache
/usr/bin/time -f "%e s wall, %M KB rss" \
bin/phpdup analyze /path/to/your/code \
--min-impact 100 --stats --workers 8 --no-cache
```
#### 执行时间阶段细分(8 个工作线程,冷缓存)
| 阶段 | 时间 | 占比 | 实现 |
|---------------|-------:|------:|------------------------------------------------------|
| 预处理 | 1.4 s | 7% | 解析 + 提取 + 规范化 + 指纹,并行 |
| 集群 | 14.3 s | 68% | APTED + 并行候选对评分 |
| 重构 | 4.2 s | 20% | 反统一 + 合成 + 模式标签(通过 `RefactorWorker` 并行) |
| 报告/IO | 1.2 s | 5% | |
| **总计** | 21.1 s | 100% | 峰值 RSS 464 MB |
集群分析仍然占主导地位,其中并行的 TED 工作负载本身是最大的一块。
#### 关于效果不佳之处的诚实报告
- **单独的 APTED 是一种串行性能倒退。** 正确,但比较旧的有界自顶向下算法慢:在此语料库上单线程需 61 秒,而后者需 35 秒。收益必须来自于在此基础上叠加的并行化。
- **超过 8 个工作线程后收益递减。** 16 → 8 节省了 4 秒;串行部分在这个语料库上施加了约 2× 的 Amdahl 定律上限。
- **在此规模下,Lazy AST 目前并不比全内存模式快**——约 2 秒的重新加载开销大致抵消了微小的 RSS 节省。默认设置(`lazy_ast: true`)是保守的;如果您拥有大型主机,可以在 `phpdup.json` 中将其设置为 `false` 以获得速度提升。
- **当集群阶段主导总执行时间时,增量的温缓存节省效果有限**。增量模式在语料库每次运行只增加少数几个文件时表现出色。
- **持久化集群缓存**在无更改的重新运行中效果显著——它完全跳过了集群 + 重构阶段。但在任何代码块更改时都会整体失效,因此只有在没有源文件移动时才是“温”的。
#### 能产生明显效果的调整旋钮
- `--workers N` —— 并行级别(0 = 自动检测)。
- `--exact-only` —— 跳过近似重复检测。在上述语料库(8 个工作线程)上仅需 **5.74 秒执行时间** —— 最快的“代码是否整洁?”门禁。
- `--similarity`(默认值 0.80)—— 提高此值可在 TED 计算前剪枝更多对。
- `--min-block-size`(默认值 8)—— 更少的代码块,更少的对。
- `--max-df`(默认值 0.01)—— 更严格的稀有 gram 截止值。
- `--auto-tune` —— 根据您的语料库形状选择大小合适的上述组合;显式标志仍然优先。
- `--ted-weights=semantic` —— 为方法调用分配比字面量更高的权重;每对计算速度较慢,但在聚类行为相近的近似重复项时效果更好。
- `--no-incremental` —— 禁用按文件的索引快照。
- `--no-lazy-ast` —— 将所有原始 AST 保留在 RAM 中。
针对任何代码库的探索性分析:
```
bin/phpdup analyze src --auto-tune --workers $(nproc)
```
CI 门禁(仅限精确克隆,最快):
```
bin/phpdup analyze src --exact-only --min-impact 30 --workers 8
```
大型单体仓库(低内存预算):
```
bin/phpdup analyze src \
--workers $(nproc) \
--min-block-size 20 \
--similarity 0.88
# lazy_ast 和 incremental 默认开启。
```
## 架构
完整的设计文档(包括数据结构、算法细节和分阶段实现计划)请参阅 [`ARCHITECTURE.md`](ARCHITECTURE.md)。
项目组织结构如下:
```
src/
Cli/ CLI entry point, ConfigLoader (with schema validation), Command
Pipeline/ Stage enum, PipelineState, ProgressListener,
CooperativeStageInterface, Pipeline orchestrator,
five Stage classes (Scanning/Preprocess/Cluster/Refactor/Report).
Scanning/ File walking and glob filtering
Parsing/ nikic/php-parser wrapper + AST cache
Extraction/ Block selection (with --kinds filter) + lazy AST loader
Normalization/ Three-pass canonicalization
Fingerprint/ Structural hash + n-gram bag
Index/ In-memory + inverted index
Persistence/ IndexStore (per-file block snapshots)
Similarity/ Jaccard, ContainmentSimilarity (type-3), APTED tree-edit-distance
Clustering/ Hash-bucket + union-find with type-3 containment fallback
Parallel/ WorkerPool (run + runStreaming) + Preprocess/PairScore workers
Refactor/ Anti-unification with statement-array LCS,
parameter/signature synth (incl. optional_block bools),
pattern recognition.
Reporting/ CLI / JSON / HTML / SARIF / GitLab SAST / Diff / Checkstyle
reporters + ranker
Tui/ PhpdupModel (SugarCraft Model + ProgressListener), ViewState,
Msg types (StagePumpedMsg, RestartPipelineMsg),
TuiRunner (theme resolution + Program boot, with
shared-loop support for --watch + --tui)
Watch/ WatchRunner (poll-based React\EventLoop watcher)
Util/ AST serializer, hash helpers, line range
```
模块具有小而文档化的接口。新的规范化规则、相似度度量或模式识别器可以在不触及流水线其余部分的情况下插入。
## 测试
```
composer test # full suite
vendor/bin/phpunit --testsuite Unit
vendor/bin/phpunit --testsuite Integration
composer coverage:html # writes tests/phpunit/coverage-html/
```
测试套件(165 多个测试,469 多个断言)涵盖:
- 扫描器 glob 语义
- 所有三种模式下的规范化器规范化
- N-gram 指纹确定性和 + 不相关代码上的 Jaccard 下限
- ContainmentSimilarity:子集/重叠/空情况 + 大小比率保护
- APTED 在相同、重命名、不相关树上的正确性,以及有界短路行为
- WorkerPool 串行路径、并行路径(无 pcntl 时跳过)、空
输入、CPU 数量检测,以及流式变体,包括子异常传播和数组与生成器任务的返回
- IndexStore 往返测试、文件更改失效、配置键失效
- 流水线编排:阶段排序、`stopAfter` 在正确的边界停止、
`stageProgress` 在阶段之间重置,协同 iter() 为协同阶段产生前/后阶段和阶段中事件
- ProgressListener 连线:按文件扫描 + 预处理事件触发,
空监听器为默认值,且永远不会分支阶段行为
- BlockExtractor `--kinds` 过滤器拒绝未知类型并保留您请求的类型
- ConfigLoader schema 验证:每个字段的边界 + 跨字段 `min_block_size <= max_block_size` 规则 + `optional_blocks` 子对象
- 反统一器在规范示例上的孔位发现 + type-3 可选块形成,每集群最大上限回退,与 cluster.members 顺序无关的种子选择,种子交换后的观察值重映射
- ParameterSynthesizer 类型推断(每个分支)+ optional_block 名称派生(来自片段的动词、跳过停用词、snake-to-camel、无标识符回退)
- SignatureBuilder:必需-然后-可选的排序,默认为 false 的渲染,仅包含可选的集群签名,名称回退
- PatternRecognizer:optional-segments 标签的存在/缺失,以及
config-driven, strategy, crud-handler
- 报告器:SARIF、GitLab SAST、Diff(每集群 + 累积
补丁)、Checkstyle XML、JSON(带有 `present_in_members`)、HTML
索引/集群页面——每一个都根据夹具数据上的真实 Pipeline 运行进行了测试,包括 type-3 可选夹具
- TUI:ViewState 面板焦点/排序循环,PhpdupModel 按键绑定,
`View::progressBar` 任务栏更新,`←/→` 集群导航,
StagePumpedMsg 驱动/生成器耗尽,RestartPipelineMsg
重建,主题解析
- 在带有预期集群的夹具语料库上的端到端测试
GitHub Actions 会在每次推送和 PR 时,在 PHP 8.1、8.2、8.3、8.4 上运行完整的测试套件,然后在 PHP 8.3 上运行 PHPStan level 6 和 Psalm,最后将 Clover 覆盖率上传到 Codecov。
## 性能
### 渐进复杂度
| 操作 | 复杂度 | 备注 |
|--------------------------|-------------------------------------|------------------------------------------------------------------------|
| 文件扫描 | O(F) | F = 文件数 |
| 解析 | 每个文件 O(L) | L = 行数;在后续运行中缓存;**已并行化** |
| 代码块提取 | O(N) | N = AST 节点数 |
| 规范化 | O(N) | 已并行化 |
| 哈希 | 每个代码块 O(N) | 已并行化 |
| 哈希分桶 | O(B) | B = 代码块数 |
| 倒排索引候选 | O(B × g̅) | g̅ = 每个代码块的平均 n-grams 数,带有稀有 gram 预过滤 |
| 成对 Jaccard | 受候选数限制 | 仅共享稀有 gram 的代码块;**已并行化** |
| 树编辑距离 | 受 `(1−τ) × max(\|a\|,\|b\|)` 限制 | APTED 风格的 Zhang-Shasha 森林 DP,采用重路径排序;提前中止 |
| 反统一 | 每个集群 O(\|cluster\| × N) | 目前为串行 |
| 语句数组的 LCS | 每个发散数组 O(n × m) | 受 `optional_blocks_max_per_cluster` 限制 |
### 可调旋钮
- `min_block_size` —— 过滤掉样板代码(最大的噪音源)。
- `max_block_size` —— 限制 TED 计算;超过此大小的代码块将被丢弃。
- `max_df` —— 用于候选生成的稀有 gram 过滤截止值。
- `similarity_threshold` 和 `tree_threshold` —— 如何划定近似重复的界限。
- `optional_blocks.containment` 和 `optional_blocks.min_overlap` —— type-3 检测灵敏度。
- `workers` —— 并行级别。
- `incremental` / `lazy_ast` —— 重新运行的复用和内存预算。
### 缓存
- **AST 缓存**(`/parser-v5_.cache`)—— 通过 `sha1(file) + parser_version` 键控的序列化解析树。没有源代码更改的重新运行将完全跳过解析。
- **索引存储**(`/.idx`)—— 按文件内容哈希 + 解析器版本 + 配置键键控的按文件代码块快照。重新运行会复用未更改文件的代码块。
两者都位于项目根目录旁边的 `.phpdup-cache/` 下,随时可以安全删除。
## 路线图
活跃的规划文档:
- **ORM / 数据库感知的语义去重** ——
[`docs/plans/orm-db-semantic-dedup.md`](docs/plans/orm-db-semantic-dedup.md)。
六选项矩阵(数据库调用规范化 token 重写、
read→mutate→save 三合一折叠、行为调用图相似度、符号等价类注册表、IR 提升、ML 学习的相似度),并附有建议的分阶段推出计划。弥补了当前 Eloquent `User::find()->save()` 和等效原生 SQL `UPDATE` 无法聚合的差距。
- **LSP 服务器** —— 推迟到持久化集群缓存
在实际工作负载中证明其价值后(刚刚发布)。LSP 需要增量的文件更改重新评分,这由集群缓存解锁。
- **用于超过 1000 万代码块语料库的流式集群** ——
`Phpdup\Index\ExternalSort` 是磁盘上的 K 路合并原语;
连入的集群器路径是下一层工作。
- **VSCode 扩展** —— 依赖于 LSP。
架构决策位于
[`docs/adr/`](docs/adr/),算法参考位于
[`docs/algorithms/`](docs/algorithms/)。教程位于
[`docs/tutorials/`](docs/tutorials/),CI 集成方案位于
[`docs/CI.md`](docs/CI.md),IDE 插件 / playground 契约位于 [`docs/JETBRAINS.md`](docs/JETBRAINS_PLUGIN.md) 和 [`docs/PLAYGROUND.md`](docs/PLAYGROUND.md)。
## 常见问题
**这和 PHPCPD 有什么区别?**
PHPCPD 发现的是重复的 *tokens* —— 一长串相同的词法分析器输出。`phpdup` 在规范化之后的 AST 上工作,因此重命名的变量、不同的字面量、不同的方法名,*甚至整个可选代码段*都可以聚合在一起。更重要的是,phpdup 会告诉您抽象*看起来会是什么样* —— 它的参数列表、类型和建议的函数名 —— 而不仅仅是重复的位置。
**它会重写我的代码吗?**
不会。`phpdup` 仅作建议。它展示重构机会;由人类决定是否执行。自动重写被明确排除在目标之外——请参阅 ARCHITECTURE.md §1。
**并行模式可以在 Windows / 沙箱化的 PHP 上工作吗?**
工作池会在运行时检测 `pcntl_*` 的可用性,并自动回退到串行代码路径。CLI 仍然接受 `--workers N`,因此配置文件无需进行分支判断——当缺少 pcntl 时,该值会被忽略。
**缓存会占用多少 RAM?**
AST 缓存存储了由文件哈希作为键的序列化解析器输出;
典型的 PHP 文件在磁盘上约占 5–50 KB。索引存储(增量快照)每个文件约占 10–100 KB。两者默认都位于项目根目录旁边的 `.phpdup-cache/` 下,随时可以删除。
**为什么在我的代码中不能那么干净地获得阈值/角色的示例?**
尝试使用 `--mode=aggressive --min-impact=30`。默认设置是为首次运行时的安静输出而调整的。降低 `--min-impact` 并切换到 `aggressive` 模式会暴露出更多候选者。反之,如果噪音过大,降级到 `default` 模式可减少误报。
**它支持 PHP 7.x 吗?**
该工具本身需要 PHP 8.1+(使用了 `xxh128` 和构造函数属性提升)。它可以分析用较旧 PHP 版本编写的代码库——解析器支持 5.x 及更高版本。
**它能处理现代 PHP 8.x 语法吗?**
是的——match 表达式、enums、readonly、命名参数、
attributes、nullsafe、一等公民可调用语法——均受 `nikic/php-parser` v5 支持。
**我该如何重新渲染演示 GIF?**
安装 [VHS](https://github.com/charmbracelet/vhs),然后:
```
docs/tapes/render.sh # render all
docs/tapes/render.sh tui-live.tape # render one
```
VHS 需要 Chromium 二进制文件。在限制非特权用户命名空间的 Ubuntu 23.10+ 上(且 `/usr/bin/chromium-browser` 是仅限 Snap 的存根),请传递 `CHROME_BIN=/path/to/chrome`——Playwright 的 `chrome-headless-shell` 效果很好——脚本会在 PATH 中引导一个 `--no-sandbox` 的垫片程序。
**当我添加 `--tui` 时,TUI 看起来是空的 / 没有出现。**
仪表盘需要真实的 TTY 来进行键盘输入和渲染。
如果您的终端不是真实的 TTY(CI、通过管道的 stdout、重定向的文件),SugarCraft 的 `Program` 将无法附加到输入流——请改用 `--plain`。流水线现在运行在运行时*内部*,因此随着工作的进行,面板会实时更新;如果所有面板仍为零,则很可能在流水线初始化期间发生了某些错误(运行 `bin/phpdup analyze … --plain` 以查看 TUI 可能隐藏的错误消息)。
## 贡献
欢迎提交 PR。请:
1. 运行 `composer test` 并为新功能添加测试。
2. 遵循现有的 PHP 编码风格(`declare(strict_types=1)`,PSR-4,构造函数属性提升,精简的公共接口)。
3. 对于新的规范化规则、相似度度量或模式识别器,请在相关模块的文档块中记录该规则。
对于较大的架构更改,请先开 issue 讨论设计。
## 许可证
MIT —— 请参阅 [LICENSE](LICENSE)。
strict / default / aggressive] E --> F[SubtreeHasher + NgramFingerprint] F --> G[(IndexStore
per-file snapshot)] end subgraph Cluster["Clustering"] H[BlockIndex] --> I[NgramInvertedIndex] I -->|candidate pairs| J{Pair scoring} J -->|hash-bucket: exact match| K[Edge weight = 1.0] J -->|Jaccard >= threshold| L[APTED tree-edit-distance] J -->|Jaccard < threshold
+ optional_blocks_enabled| M[ContainmentSimilarity
type-3 fallback] L --> N[Edge weight = min
jaccard, ted] M --> O[Edge weight = containment] K --> P[Union-find] N --> P O --> P P --> Q[Clusters] end subgraph Refactor["Refactoring"] R[AntiUnifier seed = max-size member] --> S{stmt arrays
differ in length?} S -->|yes + type-3 enabled| T[LCS on stmt hashes
→ optional_block holes] S -->|no| U[Recurse normally
→ literal/identifier/name holes] T --> V[ParameterSynthesizer] U --> V V --> W[bool $includeFooBar = false
or typed required param] W --> X[SignatureBuilder + PatternRecognizer] end subgraph Report["Reporting"] Y[Ranker by impact] --> Z[CLI / JSON / HTML / SARIF
GitLab SAST / Diff / Checkstyle] end B --> C G --> H Q --> R X --> Y %% Observer overlay PL[ProgressListener
e.g. PhpdupModel TUI] -.observes.-> Scan PL -.observes.-> Preprocess PL -.observes.-> Cluster PL -.observes.-> Refactor ``` 整个管道也作为 `\Generator`(`Pipeline::iter()`)被协作驱动——每个 yield 点都是 TUI 运行时重绘或观察者注入 `RestartPipelineMsg` 的机会。 | 阶段 | 输出 | |----------------|--------------------------------------------| | Scanning | 绝对文件路径(glob 包含/排除) | | Preprocessing | 每个文件的带注释块(规范 AST + n-gram 包 + 结构哈希) | | Clustering | 带有相似度分数 + 边权重的聚类 | | Refactoring | 泛化 AST、孔、签名、模式标签 | | Reporting | CLI / JSON / HTML / SARIF / GitLab SAST / diff / Checkstyle 输出 | ### 规范化模式 | 模式 | 变量重命名 | 字面量折叠 | 名称折叠 | |---------------|:---------------:|:----------------:|:-------------:| | `strict` | 是 | 否 | 否 | | `default` | 是 | 是 | 否 | | `aggressive` | 是 | 是 | 是 | 在 `aggressive` 模式(默认)下,具有不同表名、不同方法名和不同字面量值的两个函数仍然可以聚在一起。 ### 聚类 三个阶段: 1. **精确规范克隆。** 共享规范 AST 上相同 Merkle 哈希的所有块会被放入同一个桶中。O(N) 工作。 2. **近似重复。** 对于每个块,从稀有 n-gram 倒排索引(忽略出现在超过 `max_df` × N 个块中的 n-gram)中提取候选者。每个候选者通过规范 n-gram 多重上的 Jaccard 相似度进行评分;幸存者使用 APTED 风格的有界树编辑距离进行细化。 3. **Type-3 回退。** 当 Jaccard 失败但 `ContainmentSimilarity` 显示较小的块大部分包含在较大的块中时(`containment ≥ 0.85` 并且 `size_ratio ≥ 0.6`),该对仍然被接受。参见 [Type-3 / 可选段检测](#type-3--optional-segment-detection)。 幸存的边馈入一个 union-find 中,将它们合并为聚类。 ### 反统一 对于每个聚类,phpdup 计算其成员的最具体泛化。经典递归: ``` au(t1, t2) = if root(t1) == root(t2) and arity matches: Node(root(t1), [au(c1_i, c2_i) for i in children]) else: Hole(observed=[t1, t2]) ``` phpdup 中的扩展: - **种子 = 最大尺寸的成员。** 具有 AST 节点数最多的聚类成员被用作模板,因此“最大”版本驱动抽象,较短的成员高亮显示可选段(而不是因为种子碰巧很短导致对齐失败)。 - **stmt 数组的 LCS。** 当两个 stmts/cases/catches 数组长度不同时,phpdup 在每个语句的结构哈希上运行 LCS;匹配的位置递归,未匹配的模板位置成为 `optional_block` 孔。 生成的模板在每个成员不同意的位置都有 Hole 标记。每个孔跟踪其在所有成员中的观察值(按聚类顺序),因此报告显示 `threshold ∈ {10, 20, 30}` 和 `role ∈ {'admin', 'moderator', 'editor'}`。 ### 模式识别 在反统一之后,每个聚类都会对照一个小型重构原型目录进行检查(sql-builder、crud-handler、validation-chain、strategy、config-driven、state-machine、optional-segments)。标签是建议性的;它们不会改变聚类,只是在报告中标记聚类。 ### 排名 每个聚类获得两个分数: - **影响** ≈ `(members - 1) × avgBlockSize - holesPenalty`。应用抽象后可消除多少行代码。 - **置信度** 在 `[0,1]` 之间。聚类相似度,针对子树级孔(大型可变子树)和跨命名空间跨度进行惩罚,针对同类内聚性进行提升。 低于 `min_cluster_impact` 的聚类会被丢弃。幸存者按影响降序排序,在并列时按成员数量和相似度打破平局。 ### 并行化 `Phpdup\Parallel\WorkerPool` 将项目列表划分为 N 个批次,通过 `pcntl_fork` 为每个批次派生一个子进程,在子进程中运行闭包,父进程收集结果。有两种收集模式: - **`run()`**——收集并返回。每个子进程在完成时将其完整结果写入临时文件;父进程在所有子进程退出后一次性读取所有结果。 - **`runStreaming()`**——结果到达时 yield。子进程将长度前缀的序列化记录(4 字节大端 uint32 + 负载)写入每个子进程的 `stream_socket_pair`;父进程通过 `stream_select` 复用,返回的 `\Generator` 实时 yield 每条记录。`PreprocessStage` 消耗这些记录,因此协作管道可以获得阶段中期的进度事件,而不是阻塞直到每个 fork 退出。 两个阶段使用工作池: - **`PreprocessWorker`**——每个子进程为其文件批次执行解析 + 提取 + 规范化 + 哈希 + n-gram 指纹识别。 - **`PairScoreWorker`**——一旦从倒排索引生成候选对,主进程就会在工作器之间批量处理它们;每个子进程在其批次上运行 Jaccard + 有界 TED +(启用时)type-3 包含度回退,并发出幸存的边。 CPU 数量是自动检测的(`nproc` / `/proc/cpuinfo`)或可通过 `--workers N` / `PHPDUP_WORKERS=N` 覆盖。当 `pcntl_*` 不可用时(Windows、沙盒 PHP),工作池会在运行时检测到这一点,并回退到具有相同闭包接口的串行代码路径——调用者无需分支。 ### 增量索引 `Phpdup\Persistence\IndexStore` 在 `
标签:ffuf, HTML报告, JSON报告, n-gram指纹, odt, OpenVAS, PHP, 云安全监控, 代码克隆检测, 代码审查, 代码相似度分析, 代码规范化, 代码重复检测, 代码重构, 反统一化, 多模态安全, 威胁情报, 开发者工具, 抽象语法树, 数据管道, 文档结构分析, 树编辑距离, 自动化payload嵌入, 自动提取函数, 软件工程, 静态分析