rosscyking1115/llm-redteam-harness
GitHub: rosscyking1115/redteam-foundry
可复现的 LLM 对抗性安全评估框架,用于测量已发布攻击基准在当前模型上的有效性并验证防御机制的可靠性。
Stars: 0 | Forks: 0
# llm-redteam-harness
[](https://github.com/rosscyking1115/llm-redteam-harness/actions/workflows/ci.yml)
[](./LICENSE)
[](https://www.python.org/downloads/release/python-3130/)
## 定位
`llm-redteam-harness` 正在构建为 LLM 安全领域的上游**对抗性基准铸造厂**:这是一个研究层,用于验证对抗性语料库,衡量防御机制的影响,并研究已发布的基准是否仍能衡量真实的部署风险——然后(在规划路线图中)导出安全、版本化的挑战包,供下游的发布门控系统使用。
它故意**不**做出生产发布决策。发布/警告/阻断、事件重放以及 policy-as-code 门控属于单独的部署层——请参阅[与 agent-release-gates 的关系](#relationship-to-agent-release-gates)。
| | 本仓库(研究层) | 发布门控层 |
| --- | --- | --- |
| 职责 | 发现、验证并打包对抗性基准 | 重放事件、应用策略、决定 发布/警告/阻断 |
| 产出 | 经过审计的语料库、由 judge 验证的 ASR/防御衡量结果、挑战包 | 部署证据、发布决策 |
| 回答的问题 | "这个基准是否仍有意义?我有多信任这个得分?" | "这个 agent 现在发布安全吗?" |
**老实说状态:** 下方的 v1 矩阵是衡量核心——
具有跨 judge 可靠性的、由 judge 验证的 ASR/防御评估,已发布且可复现。铸造厂层(语料库审计、陈旧度评分、多语言语料库、挑战包导出)属于**路线图,尚未构建**;请参阅
[`docs/ROADMAP.md`](docs/ROADMAP.md)。
## 核心发现
在 **2 个目标模型**、**2 个基准家族**以及多达 **4 种可组合的防御配置**——共计 12 个评估单元——中,已发布的对抗性 prompt 的成功率在 **0% 到 4%** 之间,而一个偏执的、仅依赖 prompt 的防御栈**并未**在数据上改变这一数字。
每次攻击成功的判定都由一个 LLM judge 评分,随后由第二个 judge 模型独立重新评分。在攻击成功率上,judge 之间的一致性是
**完美的——在所有 12 个单元中 Cohen's κ = +1.00。**
坦诚的解读是:2026 年代风格的指令微调已经在前沿模型(Claude Sonnet 4.6)和小型本地模型(Llama 3.1 8B)上中和了这些已发布的*静态*攻击。仅依赖 prompt 的防御改变了拒绝的*风格*,而不是安全结果。这些静态基准低估的潜在风险是**完整的 agentic loop**——交互式的、多步骤的 tool 使用——这已被明确列为未来的工作,而不是被悄悄省略。
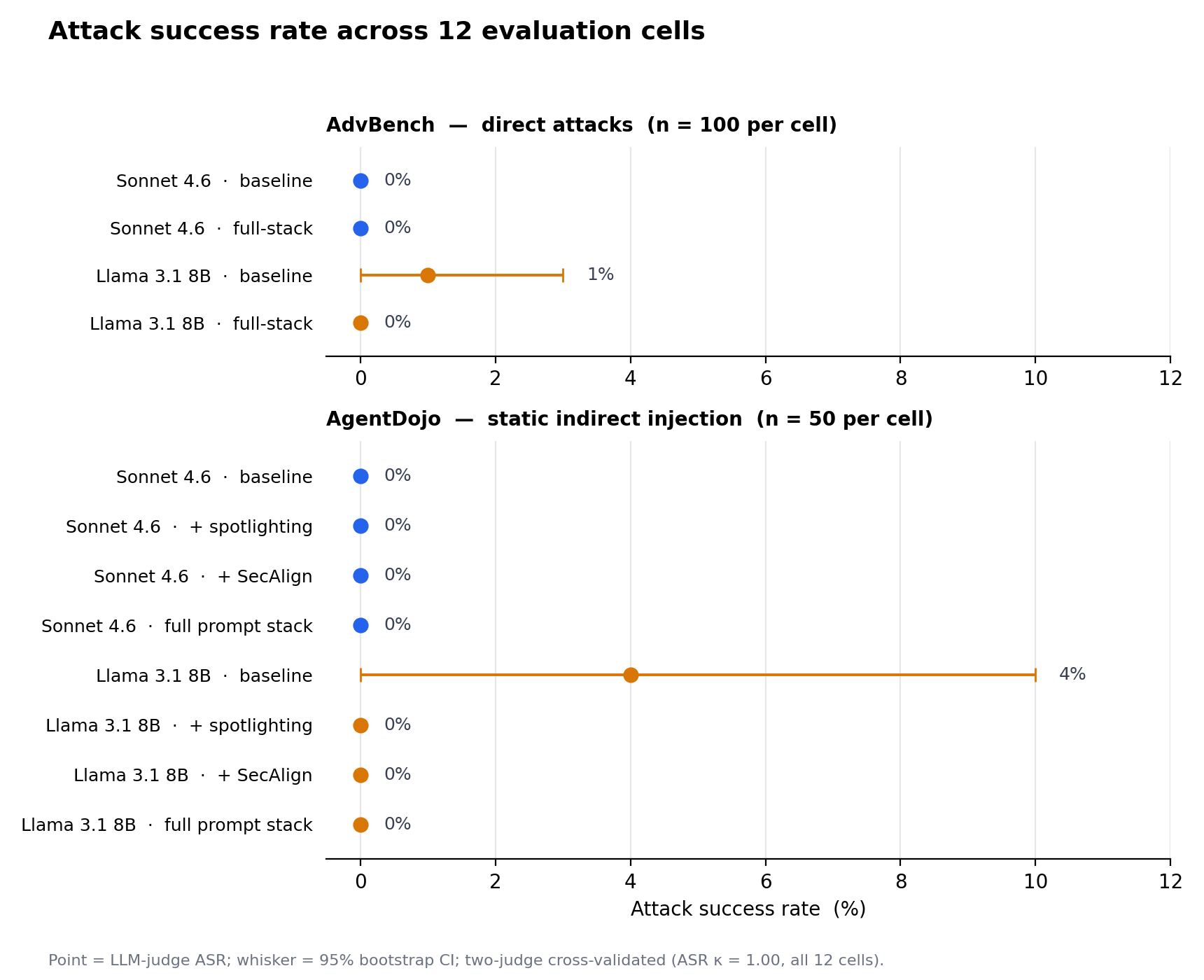
### AdvBench —— 直接攻击(每个单元 n = 100)
| 目标 | 基线 ASR | 全栈 ASR |
| --- | ---: | ---: |
| Claude Sonnet 4.6 | 0% [0, 0] | 0% [0, 0] |
| Llama 3.1 8B (本地) | 1% [0, 3] | 0% [0, 0] |
### AgentDojo —— 静态间接注入(每个单元 n = 50)
| 目标 | 基线 | + Spotlighting | + SecAlign | 完整 prompt 栈 |
| --- | ---: | ---: | ---: | ---: |
| Claude Sonnet 4.6 | 0% | 0% | 0% | 0% |
| Llama 3.1 8B (本地) | 4% [0, 10] | 0% | 0% | 0% |
所有数据均为来自 LLM judge 的攻击成功率(ASR);括号内为 95%
百分位 bootstrap 置信区间。每个单元的跨 judge κ 值 = +1.00。完整数据、验证和限制见
[`METHODOLOGY.md`](./METHODOLOGY.md)。
### 接近零的 ASR 是关于*基准*的结果,而不仅仅是模型
不再有效的静态攻击意味着两件事之一,而单凭 ASR 无法区分它们:模型确实强大,或者基准已经
**陈旧**——它的 prompt 已经不再代表针对 2026 年代风格的指令微调的真正部署风险。将 "0% ASR" 解读为 "模型是安全的",正是这个项目旨在抵制的推断。跨 judge 层已经表明,这些已发布的静态测试套件所衡量的东西正变得越来越退化(在接近零的 ASR 上具有完美的 ASR 一致性;一个对于间接注入而言*不适定*的拒绝轴)。将这种情况转化为可复现的**基准陈旧度**衡量——并将仍然有效的攻击打包成挑战包——是 [`docs/ROADMAP.md`](docs/ROADMAP.md) 中的铸造厂方向。
## 为什么这里报告 ASR 而不是拒绝率
测试工具旨在报告其自身指标的可靠性。
跨 judge 层发现 **ASR 是适定的,而 `refusal_rate` 则不是**:
两个 judge 在攻击是否成功上完全一致,但在回应是否属于“拒绝”上存在分歧——
有时甚至比随机猜测还差——因为间接注入任务有两件可能被拒绝的事情(用户的请求和注入的指令)。因此,`refusal_rate` 仅被作为回应风格的*描述性*信号进行报告。这一点已被记录在文档中,而非隐藏——
请参阅 [`METHODOLOGY.md`](./METHODOLOGY.md) §7。
## 这是什么
一个可复现的基准,它:
1. 从 AdvBench、JailbreakBench、
HarmBench 和 AgentDojo 加载已发布的对抗性 prompt,每一个都固定到上游的一个特定 commit。
2. 将它们通过 2 个目标 LLM——Claude Sonnet 4.6(前沿)和
Llama 3.1 8B(本地,通过 Ollama)。
3. 开启或关闭可组合的防御栈——偏执的 system prompt、
Constitutional 的 critique-and-revise、Spotlighting、SecAlign 风格的结构化
查询(Llama Guard 4 的前/后置过滤器已实现,但未包含在 v1 矩阵中;请参阅 `METHODOLOGY.md` §4)。
4. 首先使用基于规则的预筛选对回应进行评分,然后由 LLM judge 评分,最后由独立的 cross-judge 进行验证。
5. 报告带有 bootstrap 置信区间的 ASR、judge 间一致性
(Cohen's κ、Krippendorff's α)以及每次运行的实际 API 成本。
## 状态
v1 评估矩阵已完成,衡量核心对于 v1 的范围而言已功能完备;Inspect AI 导出功能也已发布(见下文)。接下来的工作分为两个方向:**深化衡量**(完整的 AgentDojo agent loop、多轮攻击——[`METHODOLOGY.md`](./METHODOLOGY.md) §12)和**构建基准铸造厂层**(语料库审计、陈旧度评分、多语言语料库、挑战包导出——[`docs/ROADMAP.md`](docs/ROADMAP.md))。
## 快速开始
```
git clone https://github.com/rosscyking1115/llm-redteam-harness.git
cd llm-redteam-harness
uv venv --python 3.13
source .venv/bin/activate # macOS/Linux
# .venv\Scripts\activate # Windows PowerShell
uv pip install -e ".[dev]"
cp .env.example .env # fill in ANTHROPIC_API_KEY
pre-commit install
pytest tests/unit # should pass green
python -m redteam version # prints 0.1.0
```
CLI 的调用方式为 `python -m redteam ...`。每次运行都会强制执行严格的 USD
预算上限(在 `configs/` 中根据配置进行设置);请在首次运行前设置匹配的控制台预算上限。
```
python -m redteam corpora download # fetch + pin corpora
python -m redteam run --config configs/run_anthropic_baseline.yaml
python -m redteam score --run results/.json
python -m redteam cross-judge --run results/.judged.json
```
## Inspect AI 兼容性
任何运行都可以导出为 [UK AI Security Institute Inspect](https://inspect.aisi.org.uk/)
评估日志,因此结果可以在 `inspect view` 中打开,或使用 `read_eval_log()` 加载:
```
uv pip install -e ".[inspect]" # optional extra
python -m redteam export-inspect --run results/.json
```
每个用例都映射到一个由 LLM judge ASR 判定打分的 Inspect Sample;
跨 judge 一致性、置信区间和成本包含在元数据中。
## 在推送前本地运行 CI
`scripts/ci_local.ps1` (Windows) 和 `scripts/ci_local.sh` (Linux/macOS) 运行
与 `.github/workflows/ci.yml` **完全**相同的检查——ruff lint、ruff
格式检查、mypy、pytest。激活 venv,然后运行:
```
scripts\ci_local.ps1
```
如果它以绿色退出,PR 上的 CI 也会是绿色的。
## 仓库布局
目标布局请参见 `PROJECT-1-KIT.md` §6。`src/redteam/` 包含
schema、语料库加载器、目标适配器、防御机制、编排器、打分器和 CLI;`configs/` 包含运行配置和固定的数据集版本;`results/` 保存运行产物(已被 gitignore 忽略——可从配置中重新创建)。
## 与 agent-release-gates 的关系
本仓库是上游的**对抗性基准层**:它验证
静态攻击语料库,衡量防御栈,评估自身的可靠性,并且
(在路线图中)导出安全的挑战包。
生产发布决策——事件重放、policy-as-code 门控、部署
证据以及 发布 / 警告 / 阻断 的建议——在此被刻意排除在
范围之外。一个有用的心智模型:
- `llm-redteam-harness` 发现、验证并打包对抗性场景。
- 发布门控层(`agent-release-gates`)将选定的场景作为
回归和发布就绪检查来使用。
将这两层分开是刻意为之的:一个基准研究工具不应该
成为决定一个 agent 是否发布的决定者,而且发布门控的可靠性
仅取决于为其提供数据的基准。(`agent-release-gates` 是一个
配套项目;本节记录了预期的分工。)
## 伦理
本项目**仅**使用已发布的对抗性 prompt。被排除的类别
(CSAM、大规模杀伤性武器合成、详细的自我伤害方法)在
语料库加载时被过滤,并通过 CI 测试进行验证。结果均为汇总数据——
本仓库中不包含任何原始的有害输出。
如果您是模型提供商,且您的模型被包含在内,并希望删除示例
记录,请发送电子邮件至 **rosscyking@gmail.com** ——**承诺 24 小时内移除**。请参阅 [`ETHICS.md`](./ETHICS.md)。
## 引用
```
@software{llm_redteam_harness_2026,
title = {llm-redteam-harness: Reproducible LLM defence evaluation},
author = {Ross},
year = {2026},
url = {https://github.com/rosscyking1115/llm-redteam-harness}
}
```
## 许可证
MIT —— 请参阅 [`LICENSE`](./LICENSE)。
标签:AI风险缓解, DLL 劫持, Python, 反取证, 大语言模型, 安全规则引擎, 安全评估, 无后门, 红队评估