tcorry91/aws-monitoring-incident-response-lab
GitHub: tcorry91/aws-monitoring-incident-response-lab
一个基于 Terraform 的 AWS 监控与事件响应实验室,通过模拟高 CPU 负载场景演示从部署、监控、告警到文档化响应的完整云运维工作流。
Stars: 0 | Forks: 0
# AWS 监控与事件响应实验室
## 概述
本项目演示了一个使用 EC2、CloudWatch、SNS 和 Terraform 的小型 AWS 监控与事件响应工作流。
其目标是模拟一个基础的云运维场景:部署一个简单的 Web 服务器,监控其 CPU 使用率,触发 CloudWatch 警报,接收 SNS 邮件通知,并遵循文档化的事件响应 Runbook。
## 为什么会有这个项目
云支持和云运维角色的要求不仅限于部署基础设施。它们还需要具备监控系统、响应警报、调查事件、记录发现以及提升可靠性的能力。
本实验室演示了围绕以下方面的实际运维思维:
- AWS 基础设施
- 监控与警报
- 事件响应
- 文档编写
- Runbook
- 基础故障排查
- 基础设施即代码
## 架构
本实验室部署了:
- 一个运行简单 Web 服务器的 EC2 实例
- 一个允许 HTTP 访问的安全组
- 用于 EC2 CPU 监控的 CloudWatch 指标
- 一个针对高 CPU 使用率的 CloudWatch 警报
- 一个用于邮件通知的 SNS 主题
- 一份文档化的事件响应 Runbook
架构图将添加在 `/architecture` 中。
## 使用的 AWS 服务
- EC2
- CloudWatch
- SNS
- IAM
- VPC / 安全组
- Terraform
## 仓库结构
```
aws-monitoring-incident-response-lab/
README.md
architecture/
screenshots/
runbooks/
high-cpu-alarm-response.md
terraform/
versions.tf
provider.tf
variables.tf
main.tf
outputs.tf
terraform.tfvars.example
```
## 事件模拟
使用 `stress-ng` 在 EC2 实例上模拟了高 CPU 事件。
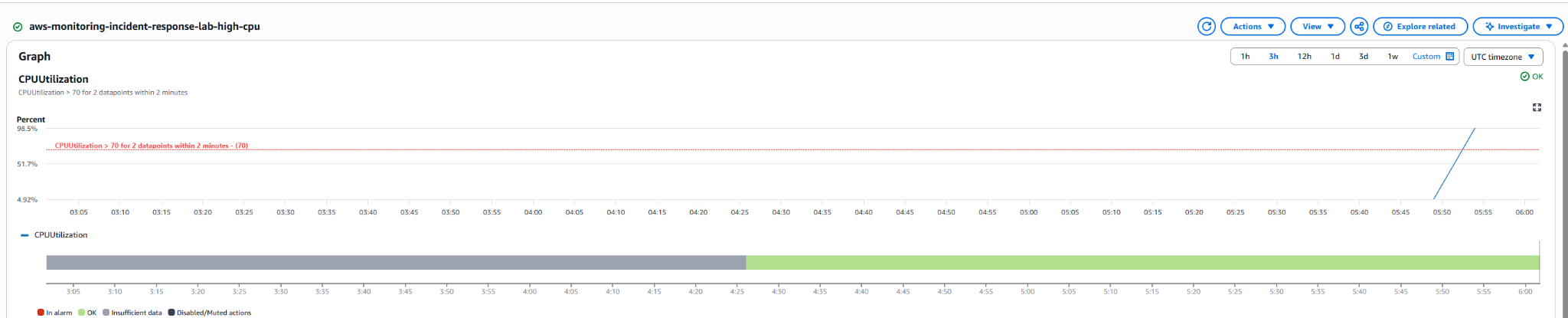
在初始测试期间,CPU 飙升在 CloudWatch 中清晰可见,但原始的 1 分钟警报配置在采用 EC2 基础监控时未能可靠触发。该警报被调整为 5 分钟的评估周期,以匹配标准的 EC2 指标粒度。
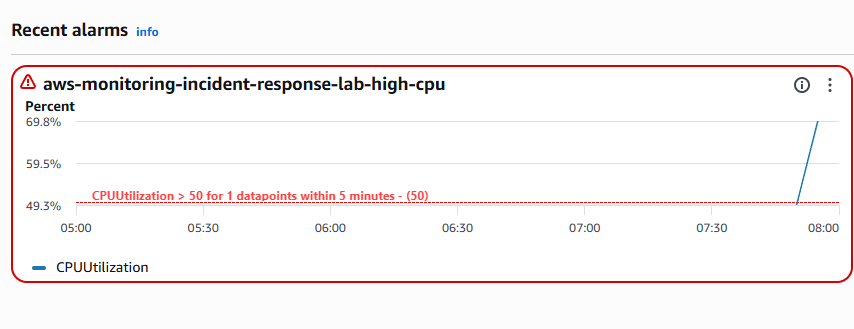
最终的警报配置:
- 指标:`CPUUtilization`
- 命名空间:`AWS/EC2`
- 阈值:大于 `50%`
- 周期:`300 秒`
- 评估周期:`1`
- 报警数据点数:`1`
这使得警报能够进入 `ALARM` 状态并发送 SNS 邮件通知。
## 截图
### Web 服务器运行中
### CloudWatch 中可见的 CPU 飙升
### CloudWatch 警报已触发
### 收到的 SNS 邮件警报

## 事件响应 Runbook
请参阅:
```
runbooks/high-cpu-alarm-response.md
```
## 清理
测试完成后,使用以下命令销毁资源:
```
terraform destroy
```
## 我学到了什么
这个项目强化了一个认识:监控配置必须与底层指标的粒度和行为相匹配。
在这种情况下,EC2 基础监控无法可靠地支持最初的 1 分钟警报评估设置。将 CloudWatch 警报调整为使用 5 分钟周期使得警报工作流能够可靠运行。
该实验室还展示了以下方面的重要性:
- 在真实测试条件下验证警报
- 调优警报阈值和评估周期
- 记录事件响应步骤
- 在使用后销毁测试基础设施
标签:ASM汇编, AWS, CloudWatch, DPI, EC2, EC2, ECS, IaC, IaC, SNS, SRE, stress-ng, Terraform, 云计算, 偏差过滤, 压力测试, 可靠性, 告警通知, 安全运营, 实验室, 扫描框架, 故障排查, 架构图, 监控告警, 规则引擎, 运维手册