phredreeq/anomaly-detection-login-behaviour
GitHub: phredreeq/anomaly-detection-login-behaviour
使用 Isolation Forest 机器学习算法对登录行为进行无监督异常检测,自动标记可疑登录活动。
Stars: 0 | Forks: 0
# 可疑登录行为的异常检测
## 在机器学习中使用 Isolation Forest 算法
## 问题
传统的基于规则的检测需要预先了解
攻击的特征。本项目使用机器学习通过学习
正常行为的特征来自动检测可疑登录行为,
而无需显式告知何为攻击。
## 目标
- 生成真实的登录行为数据集
- 在正常行为上训练 Isolation Forest 模型
- 自动标记异常的登录活动
- 可视化结果以识别攻击模式
## 使用工具
| 工具 | 用途 |
|---|---|
| **Python** | 核心编程语言 |
| **Pandas** | 数据组织和处理 |
| **Scikit-learn** | Isolation Forest 机器学习算法 |
| **Matplotlib** | 数据可视化与图表绘制 |
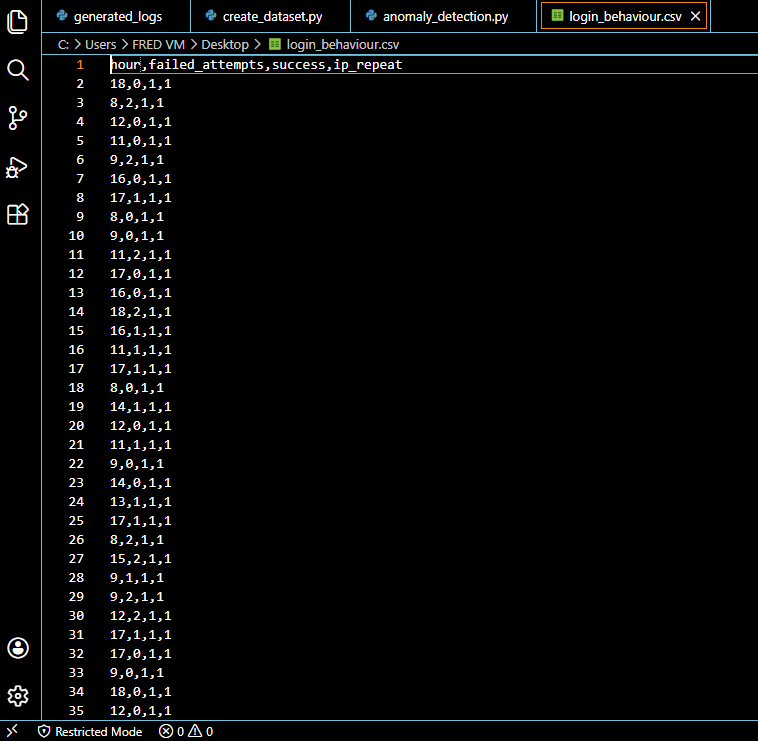
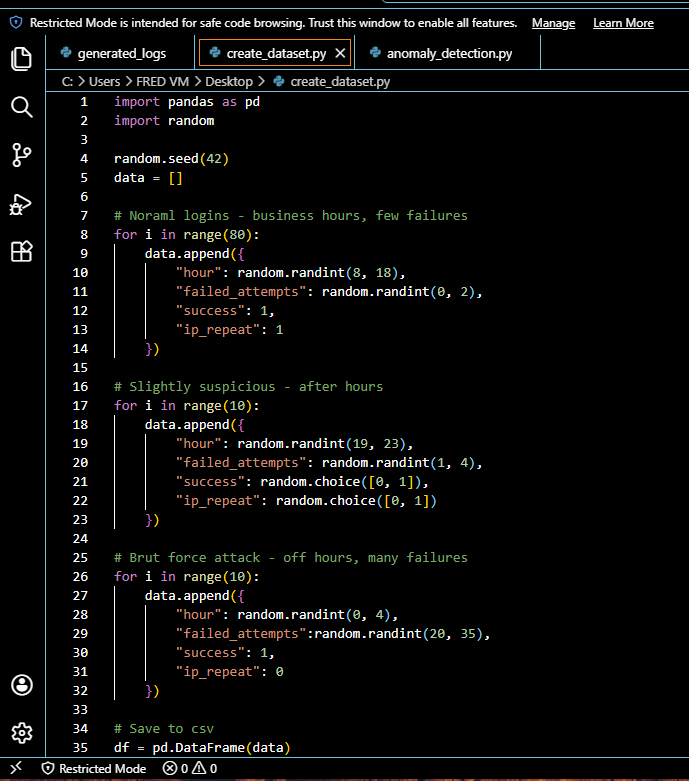
## 数据集
包含 100 条记录的合成登录数据集,
涵盖三种行为类别:
| 类别 | 数量 | 特征 |
|---|---|---|
| Normal(正常) | 80 | 工作时间 (8-18),0-2 次失败,已知 IP |
| Suspicious(可疑) | 10 | 下班时间 (19-23),1-4 次失败,混合 IP |
| Attack(攻击) | 10 | 非工作时间 (0-4),20-35 次失败,未知 IP |
**使用的特征:**
- `hour` — 登录尝试的小时
- `failed_attempts` — 失败登录的次数
- `success` — 登录是否成功
- `ip_repeat` — IP 是否曾出现过
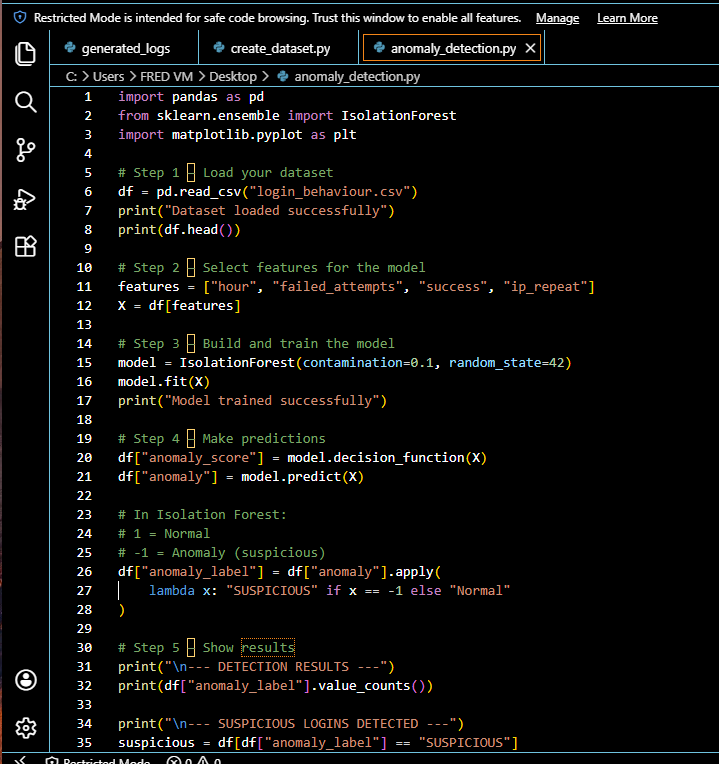
## 模型 — Isolation Forest
Isolation Forest 通过隔离与大多数
不同的数据点来检测异常。这意味着该算法通过隔离不寻常的数据点来发现异常值。
核心原则:
- 正常数据点很难被隔离,因为
它们与相似的点混在一起
- 异常很容易被隔离,因为
它们在其他点中显得与众不同
**模型参数:**
- `contamination=0.1` — 预期约 10% 的异常
- `random_state=42` — 确保结果一致
- 特征:hour,failed_attempts,success,ip_repeat
## 结果
### 检测摘要
| 标签 | 数量 |
|---|---|
| ✅ Normal(正常) | 90 |
| 🚨 Suspicious(可疑) | 10 |
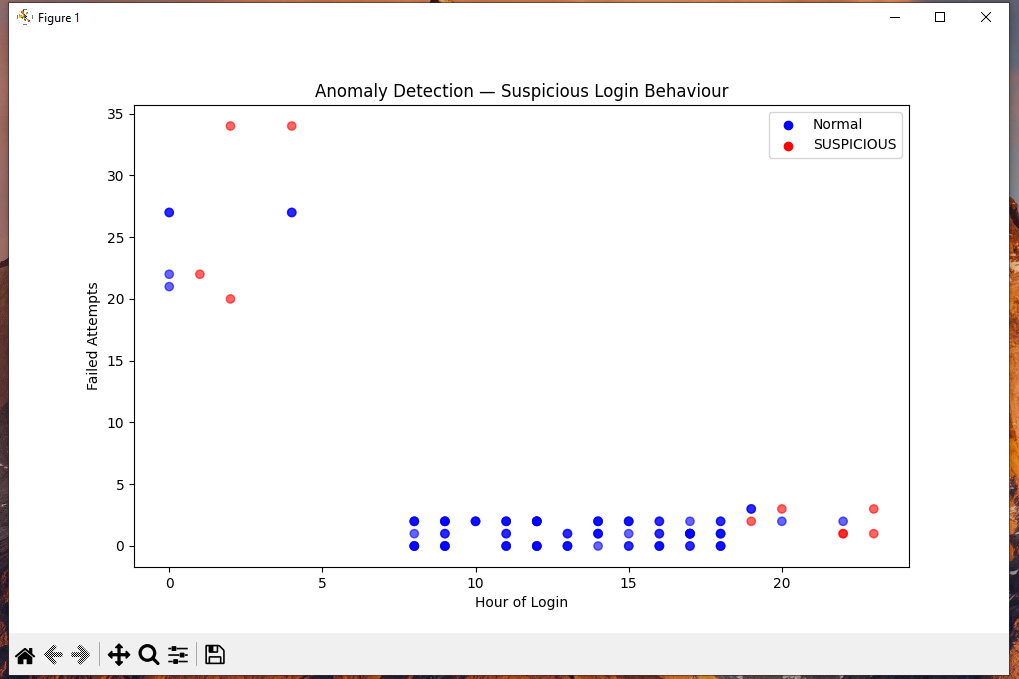
### 异常检测图表
### 数据集预览
### 数据集生成脚本
### 异常检测脚本
### 命令提示符结果
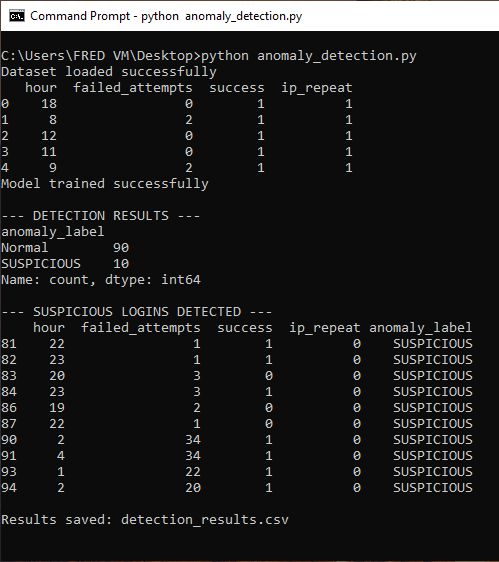
## 分析
### 模型检测到了什么
Isolation Forest 模型成功标记了 10 条
可疑登录记录,包括:
**明确的暴力破解攻击:**
- 小时:0-4(非工作时间)
- 失败尝试:20-35 次
- 未知 IP 地址
- 最终成功登录
**下班时间的可疑活动:**
- 小时:19-23
- 未知 IP 地址
- 多次失败尝试
### 为什么有些正常点显示较高
模型使用多变量分析,这意味着它将
所有 4 个特征综合考虑,而不仅仅是失败的尝试。
在工作时间具有高失败次数但 IP 已知的登录
可能仍被归类为正常,
因为多个因素被综合权衡。
这反映了真实世界的复杂性,因为异常
检测从来不是二元的,人类分析师
总是需要审查标记的项目以做出最终
决定。
## ⚠️ 局限性
| 局限性 | 说明 |
|---|---|
| **误报** | 正常行为偶尔会被标记为可疑 |
| **漏报** | 某些攻击可能未被标记 |
| **合成数据** | 真实世界的日志需要重新训练模型 |
| **人工审查** | 机器学习只能标记候选项,而分析师做出最终决定 |
## 结论
Isolation Forest 模型成功检测了
可疑登录行为,而无需被显式
告知攻击的特征。它学习了正常
模式并自动标记了偏差。
在真实的 SOC 环境中,此模型将:
- 针对实时的身份验证日志持续运行
- 标记可疑登录供分析师审查
- 补充基于规则的 SIEM 检测(如 Splunk)
- 通过过滤噪音减少分析师的工作量
## 🔗 相关项目
- [使用 Splunk 进行暴力破解检测](https://github.com/phredreeq/brute-force-detection)
- [事件调查报告](https://github.com/phredreeq/incident-investigation-report)
## 👤 作者
Fredrick Agufenwa
网络安全学生 | SOC 与威胁检测
标签:AMSI绕过, Apex, BSD, Isolation Forest, Matplotlib, PE 加载器, Python, Scikit-learn, 可疑登录检测, 合成数据集, 威胁检测, 孤立森林, 异常检测, 异常行为识别, 数据挖掘, 数据科学, 无后门, 无监督学习, 机器学习, 欺诈预防, 用户实体行为分析(UEBA), 登录风控, 离群点检测, 算法, 网络安全, 账号安全, 资源验证, 身份验证安全, 逆向工具, 降维与隔离, 隐私保护