Vignesh-Hariharan/fraud-detection-pipeline
GitHub: Vignesh-Hariharan/fraud-detection-pipeline
一个基于 Snowflake、dbt 和 Python 构建的端到端信用卡欺诈检测 ML 流水线,通过特征工程和 XGBoost 模型实现交易风险评分与自动告警。
Stars: 0 | Forks: 0
# 欺诈检测流水线
一个使用 Snowflake、dbt 和 Python 检测信用卡欺诈交易的端到端 ML 流水线。
## 项目背景
用于检测信用卡欺诈交易的端到端 ML 流水线。本项目演示了:
- 从原始数据到预测的完整数据流水线
- 现代数据栈实现(Snowflake、dbt、Python)
- 使用 Snowflake Cortex 的 ML 工作流
- 自动化告警系统
## 流水线功能
1. 将 130 万条来自 Kaggle 的交易记录加载到 Snowflake 中
2. 使用 dbt 构造 15 个特征(金额模式、交易频率、时间、位置)
3. 使用 Snowflake Cortex ML 训练分类模型
4. 对交易进行评分并分配风险等级
5. 针对高风险交易发送 Slack 告警
## 架构
```
Kaggle Dataset (CSV)
↓
Python Data Loader
↓
Snowflake RAW Layer
↓
dbt Transformations
- stg_transactions (clean data)
- int_features (15 engineered features)
- fct_fraud_features (final feature table)
↓
Snowflake Cortex ML
- Train classifier
- Generate predictions
↓
fct_fraud_predictions (scored transactions)
↓
Python Alert Script → Slack
```
## 技术栈
- **数据仓库**:Snowflake
- **数据转换**:dbt
- **开发语言**:Python 3.10+
- **机器学习**:Snowflake Cortex ML
- **告警通知**:Slack webhooks
- **测试**:pytest + dbt tests
## 数据集
使用 **Kaggle 信用卡欺诈检测数据集**:
- **创建者**:[Kartik Shenoy](https://www.kaggle.com/kartik2112)
- **来源**:https://www.kaggle.com/datasets/kartik2112/fraud-detection
- 包含 2019-2020 年间的 130 万笔交易
- 约 0.17% 的欺诈率(数据不平衡)
- 用于教育/研究的模拟数据
- 由 Brandon Harris 使用 [Sparkov Data Generation](https://github.com/namebrandon/Sparkov_Data_Generation) 工具生成
## 特征
### 阶段 1(10 个特征)
- **金额**:transaction_amount, customer_avg_amount, amount_z_score
- **交易频率**:txns_last_24h, txns_last_7d, minutes_since_last_txn
- **时间**:hour_of_day, is_weekend
- **客户**:customer_age, merchant_category
### 阶段 2(5 个特征)
- is_different_city
- is_new_max_amount
- merchant_fraud_rate
- is_late_night
- account_age_days
有关基本原理和实现细节,请参阅 `docs/FEATURE_NOTES.md`。
## 快速开始
### 1. 前置条件
- Python 3.10+
- Snowflake 账户(可使用免费试用版)
- Kaggle 账户
- Slack 工作区(可选)
### 2. 安装
```
git clone https://github.com/Vignesh-Hariharan/fraud-detection-pipeline.git
cd fraud-detection-pipeline
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install -r requirements.txt
```
### 3. 配置
设置 Kaggle 凭证:
```
mkdir -p ~/.kaggle
# 从 https://www.kaggle.com/settings/account 下载 kaggle.json
mv ~/Downloads/kaggle.json ~/.kaggle/
chmod 600 ~/.kaggle/kaggle.json
```
设置环境变量:
```
cp .env.example .env
# 使用你的凭据编辑 .env
```
### 4. 初始化 Snowflake
在 Snowflake 控制台中运行设置脚本:
```
-- Execute sql/01_setup_snowflake.sql
-- Execute sql/02_setup_rbac.sql (optional)
```
### 5. 加载数据
```
python scripts/load_data.py
```
预期结果:加载约 130 万行数据,欺诈率为 0.17%
### 6. 运行 dbt 模型
```
cd dbt_project
cp profiles.yml.example ~/.dbt/profiles.yml
# 如果需要,编辑 ~/.dbt/profiles.yml
dbt run
dbt test
```
### 7. 训练模型(迭代)
```
# 训练基线
# 在 Snowflake 中执行 ml/baseline_model.sql
# 训练实验
# 在 Snowflake 中执行 ml/experiments.sql
# 训练完整模型
# 在 Snowflake 中执行 ml/train_model.sql
# 比较所有模型
python scripts/compare_models.py
```
### 8. 生成预测
```
# 在 Snowflake 中执行 ml/generate_predictions.sql
```
### 9. 评估模型
```
python scripts/evaluate_model.py
```
### 10. 发送告警(可选)
```
# 测试模式
python scripts/slack_alert.py --dry-run
# 发送实际警报
python scripts/slack_alert.py
```
## 模型实验与性能
我通过迭代训练了 4 个不同的模型,并逐步增加特征:
1. **基线模型**(6 个特征):金额模式 + 基础时间
2. **加入频率特征**(9 个特征):+ 交易频率指标
3. **加入客户/时间特征**(13 个特征):+ 客户年龄、账户年龄、时间模式
4. **完整特征**(15 个特征):+ 地理位置、商户风险
### 结果
运行全部 4 个实验后:
```
Model Features Precision Recall F1
--------------------------------------------------------------------------------
BASELINE 6 82.9% 74.7% 78.6% (best)
EXP2 (+ velocity) 9 75.5% 77.2% 76.3%
EXP3 (+ customer/time) 13 76.9% 80.2% 78.5%
FULL (all features) 18 74.2% 76.6% 75.4%
Best Model: BASELINE (6 features)
Why: Highest F1 score + simplest (least prone to overfitting)
```
**关键发现**:更多的特征并没有带来提升!仅使用 6 个核心特征的基线模型表现优于复杂模型。这说明了:
- 简单往往更好(可避免过拟合)
- 特征选择比数量更重要
- 并非所有构造的特征都有价值
## 项目结构
```
fraud-detection-pipeline/
├── config/ # Snowflake config templates
├── data/ # Dataset location
│ ├── sample_transactions.csv # Sample for inspection
│ └── DATA_DICTIONARY.md # Dataset documentation
├── dbt_project/ # dbt transformation layer
│ ├── models/
│ │ ├── staging/ # Clean raw data
│ │ ├── intermediate/ # Feature engineering
│ │ └── marts/ # Final tables
│ └── schema.yml # dbt tests
├── docs/ # Documentation
│ ├── FEATURE_NOTES.md # Feature engineering rationale
│ └── images/ # Screenshots
├── ml/ # ML training and scoring
│ ├── train_model.sql # Cortex ML training
│ ├── generate_predictions.sql # Score test set
│ └── evaluate_model.sql # Performance queries
├── scripts/ # Python utilities
│ ├── load_data.py # Kaggle → Snowflake loader
│ ├── slack_alert.py # Alert system
│ ├── evaluate_model.py # Model evaluation
│ ├── run_pipeline.py # End-to-end orchestration
│ └── utils/ # Shared utilities
├── sql/ # Database setup
│ ├── 01_setup_snowflake.sql # Create database/schemas
│ └── 02_setup_rbac.sql # Role-based access
├── tests/ # Python tests
└── requirements.txt # Dependencies
```
## 运行完整流水线
自动化执行:
```
python scripts/run_pipeline.py
```
该命令会运行:
1. dbt 数据转换
2. 数据质量检查
3. 预测生成
4. 告警系统
可以通过 cron 进行调度:
```
# 每天早上 6 点运行
0 6 * * * cd /path/to/project && ./venv/bin/python scripts/run_pipeline.py
```
## Slack 告警
流水线会自动针对 CRITICAL 风险等级的交易(欺诈置信度 >= 90%)发出告警。
### 告警示例
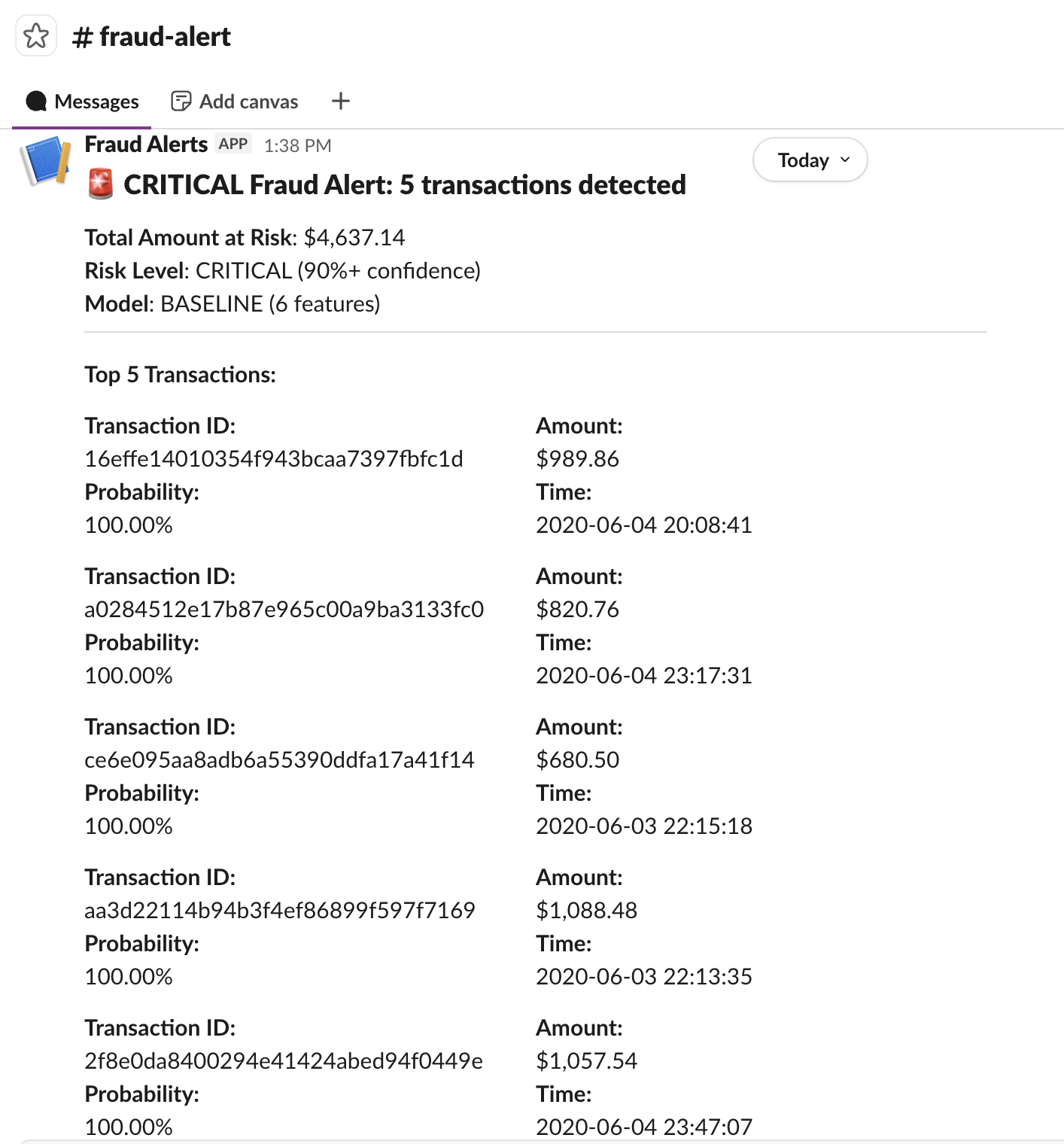
### 工作原理
1. 从 Snowflake **查询高风险交易**
2. 使用交易详情**格式化告警消息**
3. 通过 webhook **发送至 Slack**
4. **包含内容**:交易 ID、金额、概率、时间戳
### 运行告警脚本
```
# 预览将要发送的内容(无实际警报)
python scripts/slack_alert.py --limit 5 --dry-run
# 为前 5 个关键 transactions 发送实际警报
python scripts/slack_alert.py --limit 5
```
### 生产环境注意事项
本演示使用的是针对历史数据的批处理。在生产环境中,您需要:
- 集成流式数据(Kafka、Snowpipe)
- 在交易发生时实时触发告警
- 设置限制以防止发送过多告警(人们可能会开始忽略它们)
- 包含调查链接和操作按钮
## 关键经验
### 成功经验
- **迭代方法**:从简单开始,逐步增加特征
- **基于时间的拆分**:在较早的数据(2020 年 10 月之前)上进行训练,在较新的数据(2020 年 10 月之后)上进行测试,以观察其预测未来交易的效果
- **特征对比**:实际测量哪些特征有帮助,哪些有负面影响
- **寻找合适的阈值**:测试不同的置信度水平,以决定何时将交易标记为欺诈
- **使用 dbt 构造特征**:SQL 快速、易读且可测试
### 面临挑战
- **数据不平衡**:只有 0.17% 的交易是欺诈(绝大多数是合法的),这使得检测罕见的欺诈案件变得更加困难
- **选择测量指标**:研究了常见的欺诈模式并逐一进行测试
- **精确率与召回率的权衡**:在误报和漏报欺诈之间取得平衡
- **Snowflake Cortex 限制**:托管的 ML 服务,比自定义模型控制权更少
### 未来的改进方向
- 测试更多的时间窗口(6 小时、48 小时、30 天)用于频率特征
- 测试哪些测量指标最重要,并移除那些没有帮助的指标
- 使用不同的日期范围进行测试,以确认模型的一致性
- 如果不使用 Snowflake Cortex,则在不同的数据块上进行多轮测试
## 局限性
这是一个作品集项目,尚未达到生产就绪状态。已知局限性:
1. **仅支持批处理** - 无实时评分
2. **无性能监控** - 随着欺诈模式改变,模型准确性可能会下降,而我们无法察觉
3. **ML 调优受限** - 使用 Cortex 默认参数
4. **模拟数据** - 模式可能与真实欺诈不同
5. **无任务编排** - 手动执行或基础调度
6. **测试有限** - 主要关注正常流程
## 安全说明
所有凭证均存储在:
- `.env` 文件中(已通过 .gitignore 忽略)
- 环境变量中
- `config/*.yml` 文件中(已通过 .gitignore 忽略)
切勿提交以下内容:
- `.env`
- `config/snowflake_config.yml`
- `dbt_project/profiles.yml`
- Kaggle 凭证
请使用 `.example` 模板文件进行配置。
## 测试
运行 Python 测试:
```
pytest tests/
```
运行 dbt 测试:
```
cd dbt_project
dbt test
```
## 文档
- `docs/FEATURE_NOTES.md` - 特征工程的基本原理与实现
- 数据集:[Kaggle 信用卡欺诈检测](https://www.kaggle.com/datasets/kartik2112/fraud-detection)
## 未来增强计划
针对生产环境的优先改进项:
1. 使用 Snowpipe 和 Tasks 进行实时评分
2. 自动化模型重训练流水线
3. 随时间追踪模型性能,并在准确性下降时发出告警
4. 交互式欺诈看板
5. 使用 Airflow/Prefect 进行任务编排
## 关于
本项目演示了端到端的数据流水线开发:
- 数据工程:加载、转换、质量检查
- ML 工作流:训练、评估、预测
- 自动化:告警与监控
- 现代工具:Snowflake、dbt、Python
构建本项目旨在作为作品集展示数据工程能力。
## 许可证
本项目用于作品集演示目的。底层的 Kaggle 数据集采用 CC0: Public Domain 许可证。
标签:Apex, dbt, ELT, ETL, JavaCC, Kaggle数据集, ML管道, Modern Data Stack, pytest, Python, Slack集成, Snowflake, Snowflake Cortex, XGBoost, 不平衡数据处理, 代码示例, 信用卡欺诈, 分类模型, 安全规则引擎, 异常检测, 数据仓库, 数据分析, 数据加载, 数据测试, 数据科学, 数据管道, 数据转换, 无后门, 机器学习, 欺诈检测, 特征工程, 端到端机器学习, 自动化预警, 资源验证, 软件工程, 逆向工具, 金融科技