chayachandana/Incident-response-on-call-agent
GitHub: chayachandana/Incident-response-on-call-agent
基于 LangGraph 和本地 Ollama LLM 的自动化事件响应 Agent,能自主调查日志指标、匹配历史事件和操作手册,并在高置信度时自动执行 kubectl 修复操作。
Stars: 0 | Forks: 0
## 待命值班的事件响应 Agent
## 本项目的作用
现代分布式系统每天会产生数千个告警。当系统在凌晨 3 点发生故障时,被叫醒的工程师通常需要花费 45 分钟来:
- 手动排查日志
- 检查仪表盘
- 寻找合适的操作手册
- 弄清楚下一步该做什么
- 呼叫相关的团队
- 撰写事件报告
**该 Agent 会自动处理初步的响应工作:调查日志、寻找根本原因、尝试修复并呼叫合适的团队。**
## 演示
🚀 **在线 API:** [https://incident-response-on-call-agent-production.up.railway.app/docs]
```
# 开始全部
./start.sh
# 触发 P1 incident
curl -X POST http://localhost:8000/incidents/test/P1
# 在 Terminal 1 中观察 agent 的工作:
# 🚨 [ingest_alert] Severity: P1 | Services: checkout-service
# 🧠 [recall_memory] 找到 INC-2831 (89% 匹配) - 两周前的相同问题
# 🔍 [fetch_evidence] 获取了 12 条 logs,7 条 metrics
# 🧠 [analyze_root_cause] Confidence: 94% - DB pool exhaustion
# ✅ Confidence >= 92% - 继续
# 📖 [fetch_runbook] 匹配到: DB Connection Pool Exhaustion (91%)
# 🤖 [auto_remediate] 回滚 checkout-service deployment
# ✅ 回滚成功
# 📟 [page_oncall] 通知: payments-oncall
# 💬 [notify_slack] 发布到 #incidents
# 🎫 [create_ticket] 创建: INC-3847
# 📋 [generate_report] Postmortem 已生成
# 💾 [save_to_memory] 已存储以备未来调用
```
**打开 Swagger UI:** http://localhost:8000/docs
## 架构
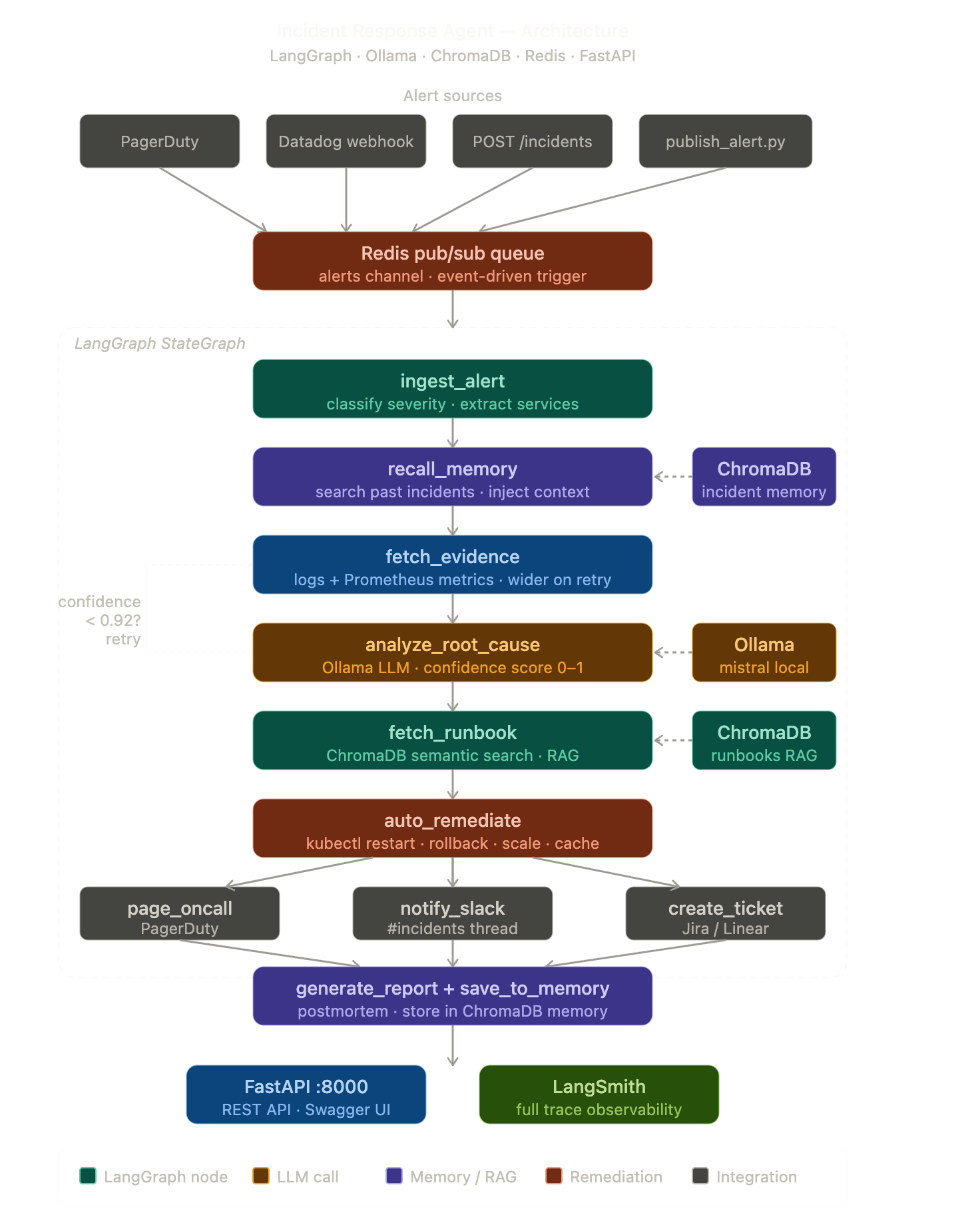
```
Alert Sources (PagerDuty / Datadog / API / CLI)
↓
Redis pub/sub queue
↓
┌───────────────────────────────┐
│ LangGraph Agent │
│ │
│ 1. ingest_alert │
│ classify P0/P1/P2/P3 │
│ │
│ 2. recall_memory │◄──── ChromaDB (past incidents)
│ find similar past events │
│ │
│ 3. fetch_evidence │
│ logs + Prometheus metrics │
│ │
│ 4. analyze_root_cause │◄──── Ollama (mistral - local LLM)
│ confidence loop: │
│ while confidence < 0.92: │
│ re-fetch wider window │
│ re-reason │
│ │
│ 5. fetch_runbook │◄──── ChromaDB (runbook RAG)
│ semantic search │
│ │
│ 6. auto_remediate │
│ if confidence >= 0.92: │
│ kubectl restart/rollback│
│ scale pods / clear cache│
│ │
│ 7. page_oncall (PagerDuty)│
│ 8. notify_slack (#incidents│
│ 9. create_ticket (Jira) │
│ 10. generate_report │
│ 11. save_to_memory │◄──── ChromaDB (stores for future)
└───────────────────────────────┘
↓
FastAPI REST API · LangSmith Traces
```
## 核心特性
### 1. 事件驱动架构
告警通过 Redis pub/sub 到达 - Agent 会自动订阅并触发。在生产环境中无需轮询,也无需手动触发。
### 2. 基于置信度的推理循环
```
while confidence < 0.92:
logs = query_logs(window=wider_each_retry)
metrics = query_prometheus()
hypothesis = ollama_reason(logs, metrics, past_incidents)
confidence = hypothesis["confidence"]
if confidence >= 0.92:
auto_remediate()
else:
escalate_to_human()
```
Agent 在不确定时绝不会采取行动。它会持续收集证据,直到有把握为止,否则就会向上升级事件。
### 3. RAG 操作手册检索
所有的操作手册都以 markdown 文件的形式存储,并使用 `sentence-transformers` 嵌入到 ChromaDB 中。当事件发生时,Agent 会进行语义搜索(而不是关键字匹配),以找到最相关的操作指南。
### 4. 事件记忆
每一个已解决的事件都会存储在一个单独的 ChromaDB 集合中。当新事件发生时,Agent 会回忆过去相似的事件,并将其注入到推理提示中 - 随着时间的推移,它会变得越来越快、越来越准确。
### 5. 自动修复
```
if confidence >= 0.92 and rule_matched:
restart_service() # kubectl rollout restart
rollback_deployment() # kubectl rollout undo
scale_pods(replicas=6) # kubectl scale
clear_cache() # redis-cli FLUSHDB
```
这是真实的 `kubectl` 调用 - 而非模拟。在 mock 模式下,它们会返回逼真的响应。
### 6. 完全在本地运行
使用 Ollama 在本地运行 Mistral - 无需 OpenAI API 密钥,数据也不会离开您的网络,规模扩展时成本为零。这对于日志和事件包含敏感数据的企业级用例至关重要。
## 技术栈
| 层级 | 技术 |
|---|---|
| Agent 编排 | LangGraph (StateGraph) |
| 本地 LLM | Ollama - Mistral / Llama 3.1 / DeepSeek |
| 向量数据库 | ChromaDB + sentence-transformers |
| 队列 | Redis pub/sub |
| API | FastAPI + Uvicorn |
| 可观测性 | LangSmith |
| 基础设施 | Docker Compose |
| 故障修复 | kubectl + Docker SDK |
## 项目结构
```
incident-response-agent-v2/
├── agent/
│ ├── state.py # TypedDict - shared agent brain
│ ├── graph.py # LangGraph - 10 nodes + confidence loop
│ ├── tools.py # External integrations (logs, PD, Slack, Jira)
│ ├── llm.py # Ollama setup + MockLLM
│ ├── reasoner.py # Confidence scoring + prompt engineering
│ ├── metrics.py # Prometheus / Grafana queries
│ ├── remediation.py # kubectl restart / rollback / scale / cache
│ ├── rag.py # ChromaDB runbook ingestion + retrieval
│ ├── memory.py # ChromaDB incident memory store
│ ├── redis_queue.py # Redis pub/sub listener (auto-reconnect)
│ └── listener.py # Main entrypoint
├── api/
│ └── main.py # FastAPI REST API
├── runbooks/ # Markdown runbooks (embedded into ChromaDB)
│ ├── db_connection_pool.md
│ ├── redis_connection_failure.md
│ ├── elasticsearch_rebalancing.md
│ ├── high_error_rate.md
│ └── memory_leak.md
├── infra/
│ ├── docker-compose.yml
│ └── Dockerfile
├── scripts/
│ └── publish_alert.py # Test: push alert to Redis
├── .env.example
├── requirements.txt
├── start.sh
└── README.md
```
## 设置与运行
### 前提条件
- Python 3.11+
- Redis (`brew install redis`)
- Ollama (`brew install ollama`) - 可选,USE_MOCK_LLM=1 可跳过此项
### 快速开始
```
# 1. Clone 并安装
git clone https://github.com/chayachandana/incident-response-agent-v2
cd incident-response-agent-v2
pip install -r requirements.txt
# 2. Configure
cp .env.example .env
# 编辑 .env - 设置 USE_MOCK_LLM=1 以在没有 Ollama 的情况下进行演示
# 3. 将 runbooks 导入 ChromaDB
python -m agent.rag
# 4. 填充 incident memory
python -m agent.memory
# 5. 启动 Redis
brew services start redis
# 6. 启动全部 - 需要 3 个 terminals
# Terminal 1 - API server
uvicorn api.main:app --reload --port 8000
# Terminal 2 - Agent listener (等待 alerts)
python -m agent.listener
# Terminal 3 - 触发测试 alert (在 Terminal 2 显示 "Waiting for alerts..." 之后)
python scripts/publish_alert.py --sev P1
# 或者通过 curl 触发,而不是使用 Terminal 3:
curl -X POST http://localhost:8000/incidents/test/P1
```
### 或者使用单条命令
```
chmod +x start.sh
./start.sh
```
### 或者使用 Docker
```
cd infra
docker compose up --build
```
## API 接口
| 方法 | 接口 | 描述 |
|---|---|---|
| `GET` | `/health` | Redis + 内存健康检查 |
| `GET` | `/stats` | Agent 性能统计 |
| `POST` | `/incidents` | 使用告警 payload 触发 Agent |
| `GET` | `/incidents` | 列出所有事件 |
| `GET` | `/incidents/{id}` | 获取特定事件的结果 |
| `POST` | `/incidents/test/P1` | 发送测试 P1 告警 (演示) |
**Swagger UI:** http://localhost:8000/docs
## LangSmith 追踪
每一次 Agent 运行都会被完整追踪 - 包括每一个节点、每一次 LLM 调用以及每一次工具调用。
```
# 添加到 .env:
LANGCHAIN_API_KEY=ls__your_key_here
LANGCHAIN_TRACING_V2=true
LANGCHAIN_PROJECT=incident-response-agent
```
请在 https://smith.langchain.com 获取免费的密钥
## 处理的事件
该 Agent 开箱即用,可以处理三种真实场景:
**P0 - auth-service 宕机**
- Redis pod 发生 OOMKilled → 所有登录失败
- Agent 操作:重启 Redis + auth-service
**P1 - checkout-service 高错误率**
- 部署后缺失数据库索引 → 连接池耗尽
- Agent 操作:回滚部署
**P2 - search 延迟升高**
- Elasticsearch 分片重新平衡
- Agent 操作:持续监控,15 分钟内自行恢复
## 将模拟替换为真实集成
`agent/tools.py` 中的每个工具都在 mock 旁边注释了真实的生产环境实现:
```
# 生产环境 - 交换一个 env var:
DATADOG_API_KEY=... # real log queries
PAGERDUTY_API_KEY=... # real pages
SLACK_BOT_TOKEN=... # real Slack messages
JIRA_URL + JIRA_TOKEN=... # real tickets
PROMETHEUS_URL=... # real metrics
```
## 使用真实的 Ollama 运行
```
# 安装并拉取模型
brew install ollama
ollama pull mistral # recommended
# 或者: ollama pull llama3.1
# 或者: ollama pull deepseek-coder
# 启动 Ollama
ollama serve
# 从 .env 中移除 mock flag
USE_MOCK_LLM= # leave empty
# 运行 agent
python -m agent.listener
```
## 本项目不是什么
它不是一个你可以询问“我的服务出了什么问题”的聊天机器人。
该 Agent 在接收到告警后,会主动去查看实际的日志和指标,
找出故障点及其原因,然后在无需人工干预的情况下采取行动 - 例如回滚、重启、扩容。
这才是值得我们为之构建的核心部分。
## 已知的局限性
- 默认情况下,所有集成的交互都是模拟的 - 真实的 Datadog、PagerDuty 和 Slack 需要将 API 密钥配置到 `.env` 中
- 置信度阈值 (0.92) 是针对 MockLLM 调整的 - 在使用真实的 Ollama 对生产日志进行分析时需要重新校准
- 事件记忆存储在本地 ChromaDB 中,目前尚无法在多个 Agent 实例之间共享
- kubectl 修复操作需要一个真实的集群,并且要指向 `~/.kube/config`
## 下一步计划
- [ ] 接入真实的 Datadog 日志查询
- [ ] 添加 Slack 斜杠命令以手动触发调查
- [ ] 根据真实的 Ollama 响应校准置信度评分
- [ ] 针对本地 kind 集群进行 Kubernetes 集成测试
- [ ] 多 Agent 并行 - 每个服务配备独立的 Agent
## 许可证
MIT
标签:Agentic Workflow, AIOps, AI风险缓解, API, AV绕过, ChromaDB, DLL 劫持, Docker, FastAPI, LangGraph, LLM评估, LLM运维Agent, Ollama, On-Call代理, Pandas, Python, Railway部署, Redis, RestAPI, Runbook匹配, SRE, 事后报告, 偏差过滤, 分布式系统, 发布订阅, 向量数据库, 告警分类, 响应大小分析, 大语言模型, 安全防御评估, 工单创建, 搜索引擎查询, 无后门, 智能运维, 本地大模型, 根因分析, 模块化设计, 自动化修复, 请求拦截, 运维机器人, 运维自动化, 逆向工具