sonusuhana754-ui/crowdsense-ai
GitHub: sonusuhana754-ui/crowdsense-ai
CrowdSense AI 是一个利用多模态 AI(视觉+音频)进行实时人群安全监控、风险评估与应急响应调度的系统。
Stars: 0 | Forks: 0
# CrowdSense AI — 实时人群安全智能系统
CrowdSense AI 是一个实时人群安全平台,它使用多模态 AI(视觉 + 音频)来分析实时摄像头画面,检测人群拥挤风险,并生成可操作的监督员指令——整个过程在 10 秒内完成。
## 截图
| 仪表盘概览 | 风险升级 | 监督员指令 |
|---|---|---|
| 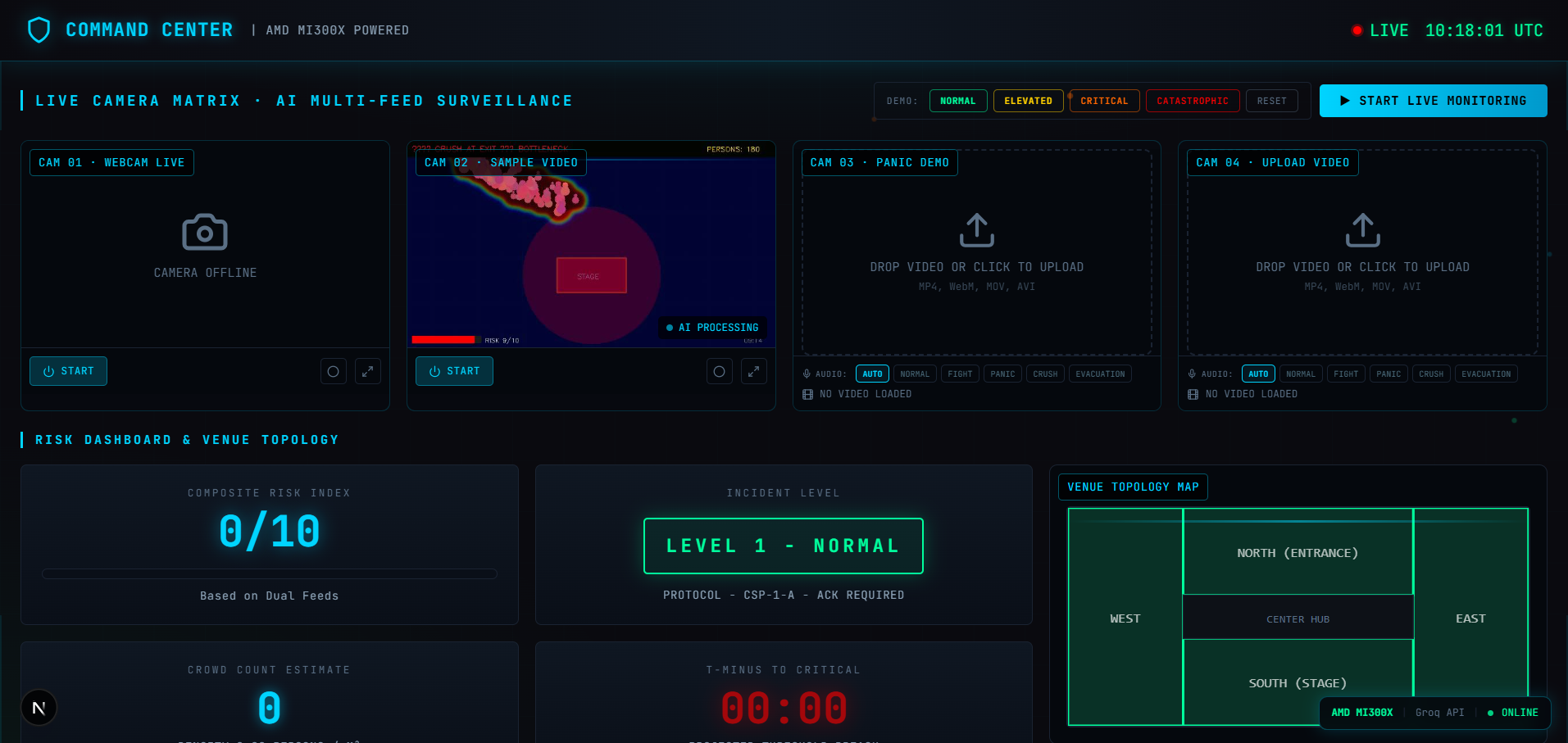 | 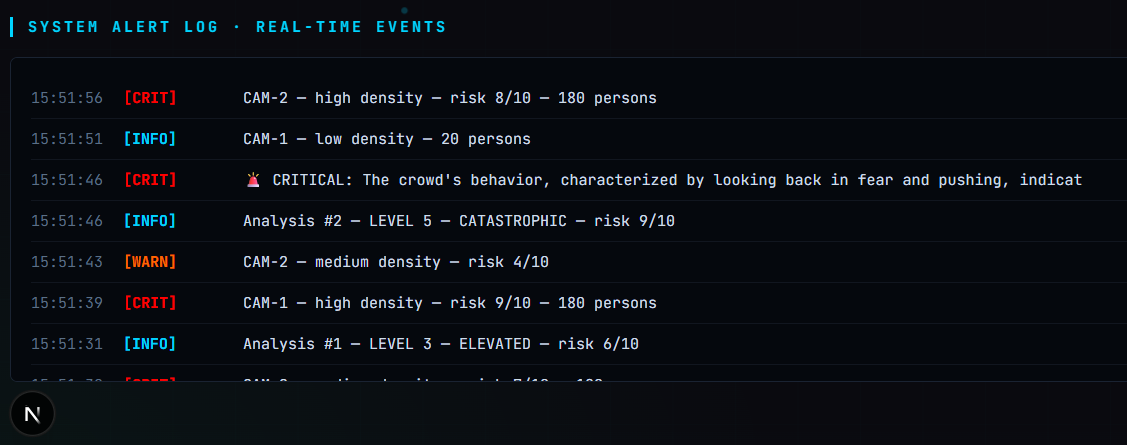 | 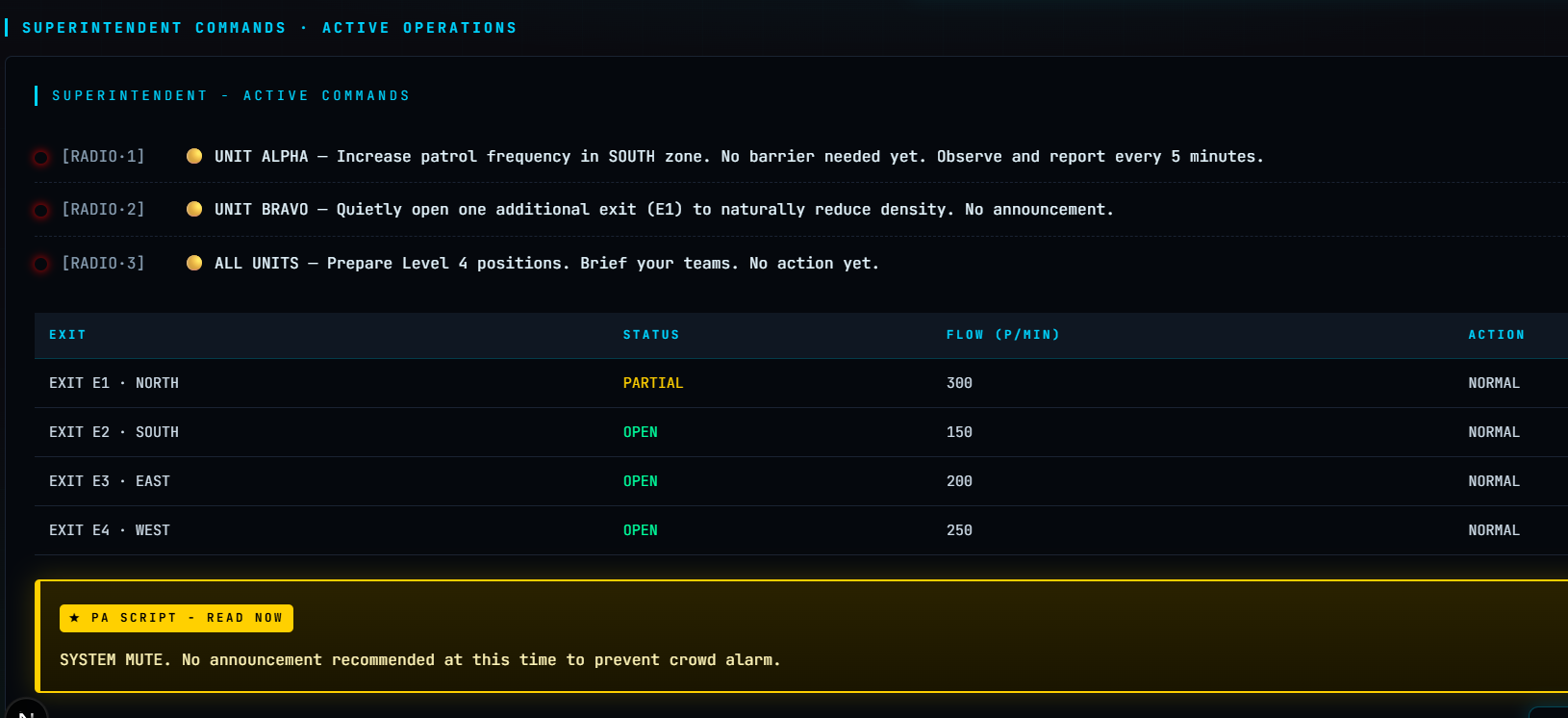 |
## 功能说明
- **实时人群分析** — Llama 4 Scout 17B 视觉模型读取摄像头帧并统计人数,检测密度、移动模式、瓶颈和求救信号
- **音频智能** — OpenAI Whisper 实时转录人群音频,检测恐慌词汇(“help”、“crush”、“stop pushing”)和尖叫声
- **双模型推理** — 初级分析师(Llama 3.1 8B)进行初步风险评估,高级审查员提出质疑并完善评估
- **监督员指令** — 根据场地布局和人群物理特性,为安保人员(Alpha、Bravo、Charlie 等单位)生成具体的对讲机指令
- **5 级事件预案** — 从 1 级(正常)升级到 5 级(灾难性疏散),并配备相应的广播(PA)脚本和紧急服务呼叫
- **演示场景** — 一键注入正常 / 升高 / 危急 / 灾难性人群场景,用于现场演示
## 技术栈
| 层级 | 技术 |
|---|---|
| **前端** | Next.js 15, TypeScript, Tailwind CSS, Framer Motion |
| **后端** | Python 3.13, FastAPI, Uvicorn |
| **视觉 AI** | Llama 4 Scout 17B (Groq) — 多模态人群画面分析 |
| **推理 AI** | Llama 3.1 8B Instant (Groq) — 初级分析师 + 高级审查员 |
| **音频 AI** | OpenAI Whisper (本地 CPU) — 语音转录 |
| **视频处理** | OpenCV, imageio-ffmpeg |
| **GPU 支持** | AMD MI300X — 通过 `.env` 中的 `AI_PROVIDER=amd` 切换 |
## 架构
```
Camera Feeds (4x)
│
▼
Vision Layer ──────────────────────────────────────────────┐
(Llama 4 Scout 17B) │
│ │
▼ ▼
Audio Layer Fusion Layer
(Whisper small) (Vision + Audio)
│ │
└───────────────────────────────────────────────────────┘
│
▼
Junior Analyst
(Llama 3.1 8B — initial risk)
│
▼
Senior Critic
(Llama 3.1 8B — refines & challenges)
│
▼
Superintendent Commands
(Unit orders, exit routing, PA script)
│
▼
Next.js Dashboard
(Real-time polling every 2s)
```
## 设置
### 前置条件
- Python 3.10+
- Node.js 18+
- 一个免费的 [Groq API 密钥](https://console.groq.com)(无需信用卡)
### 1. 克隆仓库
```
git clone https://github.com/sonusuhana754-ui/crowdsense-ai.git
cd crowdsense-ai
```
### 2. 安装后端依赖
```
pip install fastapi uvicorn python-multipart opencv-python-headless requests python-dotenv openai-whisper "imageio[ffmpeg]" numpy scipy pyttsx3
```
### 3. 配置 API 密钥
在项目根目录创建一个 `.env` 文件:
```
AI_PROVIDER=groq
GROQ_API_KEY=your_groq_api_key_here
WHISPER_MODEL=small
```
在 [console.groq.com](https://console.groq.com) → API Keys → Create API Key 获取您的免费密钥。
### 4. 生成演示恐慌视频
```
python demo/generate_panic_sample.py
```
这将创建 `demo/panic_crowd.mp4` —— 这是一个 12 秒的合成人群视频,展示了平静 → 聚集 → 恐慌 → 挤压的过程,并嵌入了真实的 TTS 恐慌音频。
### 5. 启动后端
```
uvicorn backend.main:app --host 127.0.0.1 --port 8080 --reload
```
### 6. 安装并启动前端
```
cd frontend
npm install
npm run dev
```
### 7. 打开仪表盘
导航到 [http://localhost:3000/dashboard](http://localhost:3000/dashboard)
## ⚡ 演示模式 — 无需后端
点击 **“▶ Run Demo”** 按钮(金/橙色,位于仪表盘顶部)。整个系统 **100% 在浏览器中运行** —— 无需后端、API 密钥或设置。
演示将自动运行 4 个步骤的升级序列(每步 7 秒):
| 步骤 | 场景 | 人群 | 风险 | 级别 | 视觉呈现 |
|------|----------|-------|------|-------|--------------|
| 1 | 正常运行 | 124 人 | 3/10 | 2 级 | 平静的指令,所有出口开放,低音频 |
| 2 | 风险升高 | 387 人 | 6/10 | 3 级 | 检测到瓶颈,西门悄悄开放 |
| 3 | 紧急事件 | 652 人 | 8/10 | 4 级 | 检测到尖叫,即将发生挤压,广播已启动 |
| 4 | 灾难性 | 1247 人 | 10/10 | 5 级 | 大规模恐慌,所有单位已部署,紧急服务已呼叫 |
**每个面板都会更新真实数据:**
- 风险指数、事件级别徽章、人群计数、密度、T-Minus 倒计时
- AI 推理流 —— 按步骤展示 Llama 分析事件
- 初级分析师 vs 高级审查员 —— 风险评分、初级遗漏的内容、已确认的内容
- 监督员对讲机指令 —— 特定的单位命令(Alpha、Bravo、Charlie...)
- 出口状态表 —— 随着危险区域的变化,出口状态从 OPEN 变为 BLOCKED
- 广播通知脚本 —— 从静默升级为紧急疏散
- 音频智能 —— 恐慌关键词、尖叫检测、转录
- 警报日志 —— 填满 INFO → WARN → CRIT 事件
**使用场景按钮可跳至任意步骤**,这些按钮在演示模式激活后即会出现。
## 🔴 真实数据模式 vs 演示模式
| | 真实数据模式 | 演示模式 |
|---|---|---|
| **激活方式** | 点击 “▶ Start Live Monitoring” 或上传视频 | 点击 “▶ Run Demo” |
| **是否需要后端** | ✅ 是 —— `uvicorn backend.main:app` | ❌ 否 —— 完全在浏览器中运行 |
| **视觉 AI** | Llama 4 Scout 17B 分析真实的摄像头画面 | 预计算的真实人群分析 |
| **音频 AI** | Whisper 转录真实的麦克风/视频音频 | 预设的恐慌音频场景 |
| **推理** | 对真实场景数据进行真实的 Groq API 调用 | 硬编码的专家级 AI 推理文本 |
| **指令** | 根据 AI 实际看到的内容生成 | 根据场景生成真实的监督员指令 |
| **横幅** | 无 | 黄色的 “⚡ DEMO MODE” 横幅 |
一旦后端运行,点击仪表盘顶部的 **“▶ Run Full Demo”** 按钮。
演示将运行 4 个步骤的升级序列 —— 每一步都会使用合成人群数据调用真实的 AI pipeline:
| 步骤 | 场景 | 人群 | 风险 | 事件级别 |
|------|----------|-------|------|----------------|
| 1 | 正常运行 | 120 人 | 3/10 | 1-2 级 |
| 2 | 风险升高 | 380 人,出现瓶颈 | 6/10 | 3 级 |
| 3 | 紧急事件 | 650 人,即将发生挤压 | 8/10 | 4-5 级 |
| 4 | 灾难性 | 1200 人,大规模恐慌 | 10/10 | 5 级 |
**演示过程中您将看到:**
- 风险指数从 3 攀升至 10
- 事件级别徽章从绿色升级为红色
- AI 推理流展示真实的 Llama 3.1 对人群数据的分析
- 初级分析师与高级审查员产生分歧并完善评估
- 监督员对讲机指令从“标准巡逻”变为“EVACUATE NOW”
- 出口状态从 OPEN 翻转为 BLOCKED
- 广播脚本从静默变为紧急疏散通知
- 警报日志填满 WARN 和 CRIT 事件
- T-Minus 倒计时向零逼近
## 🔴 真实数据模式 vs 演示模式
| | 真实数据模式 | 演示模式 |
|---|---|---|
| **如何激活** | 点击 “▶ Start Live Monitoring” 或上传视频 | 点击 “▶ Run Full Demo” |
| **视觉 AI** | 通过 Llama 4 Scout 17B 分析实际摄像头画面 | 将合成人群数据输入给 Llama 3.1 8B |
| **音频 AI** | 来自麦克风或视频文件的真实 Whisper 转录 | 预设的恐慌音频场景 |
| **推理** | 对真实场景数据进行真实的 Groq API 调用 | 对合成场景数据进行真实的 Groq API 调用 |
| **指令** | 基于 AI 实际看到的内容 | 基于真实的人群场景 |
| **横幅** | 无(实时数据) | 黄色的 “DEMO MODE ACTIVE” 横幅 |
**两种模式均使用真实的 AI pipeline** —— 唯一的区别在于输入数据源。演示模式将真实的人群合成场景输入给分析真实视频的同一个 Llama 模型。
### 演示模式(无需视频)
点击仪表盘顶部的 **Demo** 按钮:
- **NORMAL** —— 120 人,平静移动,1-2 级
- **ELEVATED** —— 380 人,正在形成瓶颈,3 级
- **CRITICAL** —— 650 人,人群挤压迫在眉睫,4-5 级
- **CATASTROPHIC** —— 1200 人,大规模恐慌,5 级
### 视频上传
1. 将任意人群视频上传至 **CAM 03** 或 **CAM 04**
2. 选择音频场景(AUTO 使用真实的 Whisper 转录)
3. 点击 **ANALYZE**
4. 观察整个 AI pipeline 在约 10 秒内运行
### 实时监控
1. 点击 **▶ Start Live Monitoring**
2. 出现提示时允许访问网络摄像头
3. CAM 01 显示您的实时网络摄像头画面
4. CAM 02 循环播放恐慌演示视频
5. 仪表盘每 2 秒更新一次真实的 AI 分析结果
## AI Pipeline 详情
### 视觉分析
Llama 4 Scout 17B 多模态模型接收压缩的 JPEG 图像帧并返回:
- 人群密度(空/低/中/高/危险)
- 人数估计
- 移动模式(静止/聚集/ rush/混乱)
- 按区域划分的详细情况(北/南/东/西)
- 瓶颈检测及位置
- 带有校准阈值的 1-10 风险评分
### 双模型推理
**初级分析师** —— 对人群动态进行初步评估,预测 5-15 分钟内会发生什么,并估计到达危险阈值的时间。
**高级审查员** —— 质疑初级分析师的评估。寻找被低估的风险、遗漏的人群物理特性(压缩波、出口阻塞、羊群行为)。可以提高或降低风险评分。
### 监督员指令
根据最终的风险等级,为 6 个警官单位(Alpha 到 Foxtrot)生成具体命令,包括:
- 准确的移动位置
- 打开/关闭哪些出口
- 人群引导指令
- 广播通知脚本
- 紧急服务呼叫决定
## 项目结构
```
crowdsense-ai/
├── backend/
│ ├── main.py # FastAPI server, all routes
│ ├── vision_layer.py # Llama 4 Scout vision analysis
│ ├── audio_layer.py # Whisper audio transcription
│ ├── fusion.py # Combines vision + audio
│ ├── reasoning.py # Junior analyst (Llama 3.1)
│ ├── critic.py # Senior critic (Llama 3.1)
│ ├── action_agent.py # Superintendent command generator
│ └── live_monitor.py # 4-thread continuous monitoring
├── frontend/
│ ├── app/dashboard/ # Main dashboard page
│ └── components/dashboard/
│ ├── live-reasoning-stream.tsx # Real-time AI thought stream
│ ├── webcam-feed.tsx # Live camera display
│ ├── video-upload.tsx # Video upload + analysis
│ ├── superintendent-panel.tsx # Commands + exit status
│ ├── alert-log.tsx # Real-time event log
│ └── floor-plan.tsx # Venue topology map
├── demo/
│ ├── panic_crowd.mp4 # Generated panic scenario video
│ ├── generate_panic_sample.py # Video generator script
│ └── test_pipeline.py # Full pipeline test
├── .env # API keys (not committed)
└── README.md
```
## API 端点
| 方法 | Endpoint | 描述 |
|--------|----------|-------------|
| `GET` | `/` | 健康检查 |
| `POST` | `/analyze?audio_scenario=auto` | 单次视频分析 |
| `POST` | `/live/start` | 启动双摄像头监控 |
| `POST` | `/live/stop` | 停止监控 |
| `GET` | `/live/status` | 当前系统状态(每 2 秒轮询一次) |
| `POST` | `/demo/scenario?scenario=critical` | 注入演示场景 |
| `POST` | `/demo/reset` | 重置为空闲状态 |
## AMD GPU 支持
该系统已支持 AMD。要从 Groq 云切换到本地 AMD 推理:
1. 在您的 AMD 机器上启动 vLLM 服务器:
```
python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen2-VL-7B-Instruct --port 8000
python -m vllm.entrypoints.openai.api_server --model meta-llama/Llama-3.1-8B-Instruct --port 8001
```
2. 更新 `.env`:
```
AI_PROVIDER=amd
AMD_VISION_URL=http://YOUR_AMD_IP:8000/v1/chat/completions
AMD_TEXT_URL=http://YOUR_AMD_IP:8001/v1/chat/completions
AMD_API_KEY=your_key
WHISPER_MODEL=large
```
无需更改代码 —— 提供商的切换完全由配置处理。
## License
MIT
标签:AV绕过, FastAPI, 人工智能, 公共安全, 多模odal AI, 用户模式Hook绕过, 自动化攻击, 计算机视觉, 逆向工具, 音频识别