ism4il-04/github-repo-activity-classifier
GitHub: ism4il-04/github-repo-activity-classifier
基于梯度提升算法的机器学习系统,通过分析 GitHub 仓库公开元数据预测其是否会停止维护,帮助团队在供应链安全审计中主动识别可能被废弃的依赖项。
Stars: 0 | Forks: 0
# 🐙 GitHub 仓库活跃度分类器
**ENSA Tétouan | Machine Learning 模块结业项目 2025-2026**
*指导教师:Pr. Y. EL YOUNOUSSI*
*作者:Ismail LYAMANI, Abdellatif OUMHELLA, Mohammed Aymane SABER*
## 📌 项目简介
本项目实现了一个二分类监督机器学习模型,用于根据公开特征预测 GitHub 仓库(通常作为软件项目的依赖项)是否会变得**不活跃或被废弃**(过去 180 天内没有任何修改/push)。该解决方案允许安全和软件依赖管理团队(例如:Dependabot, Snyk)主动检测存在安全风险(如未修复的依赖项漏洞)的废弃库。
### 整体架构
```
github-repo-activity-classifier/
├── app/
│ ├── api.py # API REST FastAPI (Endpoints et Preprocessing)
│ └── ui.py # Interface Utilisateur Streamlit (Formulaire et Mode Batch)
├── data/
│ ├── processed/ # Splits de données (train.csv, validation.csv, test.csv)
│ └── dataset.csv # Dataset complet (~15 000 lignes)
├── docs/
│ ├── screenshots/ # Captures d'écran de l'interface Streamlit
│ │ ├── tab1_single.png
│ │ ├── tab2_batch.png
│ │ └── tab3_info.png
│ ├── ensate_logo.png # Logo ENSA Tétouan
│ └── main.tex # Rapport LaTeX du projet
├── models/
│ ├── final_model.joblib # Pipeline complet (preprocessor + GradientBoosting)
│ └── final_model_metadata.json # Seuil critique (0.05) et métriques de performance
├── notebooks/
│ ├── 01_discovery.ipynb # Phase 1: EDA Initiale
│ ├── 02_eda.ipynb # Phase 2: EDA Avancée
│ ├── 03_preprocessing.ipynb # Phase 2: Nettoyage et Pipeline
│ ├── 04_modeling.ipynb # Phase 3: Modélisation et CV
│ ├── 05_tuning.ipynb # Phase 3: GridSearch/RandomSearch
│ └── 06_evaluation.ipynb # Phase 3: Évaluation et Seuil Optimal
├── src/
│ └── data_collection.py # Script de collecte via l'API GitHub
├── tests/
│ └── test_api.py # Tests unitaires Pytest pour l'API REST
├── .dockerignore
├── docker-compose.yml # Orchestration multi-conteneur (API et UI)
├── .env.example # Exemple de variables d'environnement (GITHUB_TOKEN, etc.)
├── Dockerfile # Conteneurisation de l'API et de l'UI (python:3.11-slim)
├── requirements.txt # Dépendances figées du projet
└── README.md
```
## 🖥️ Streamlit 用户界面
用户界面包含三个主要部分,方便与模型进行交互:
1. **单条预测**:手动输入所有特征以对仓库进行分类。
2. **批量预测**:上传 CSV 文件,通过统计可视化即时获取大规模预测结果。
3. **模型与业务背景信息**:解释非对称成本矩阵以及 0.05 的最优决策阈值。
### 界面截图
#### 🔍 单条预测表单
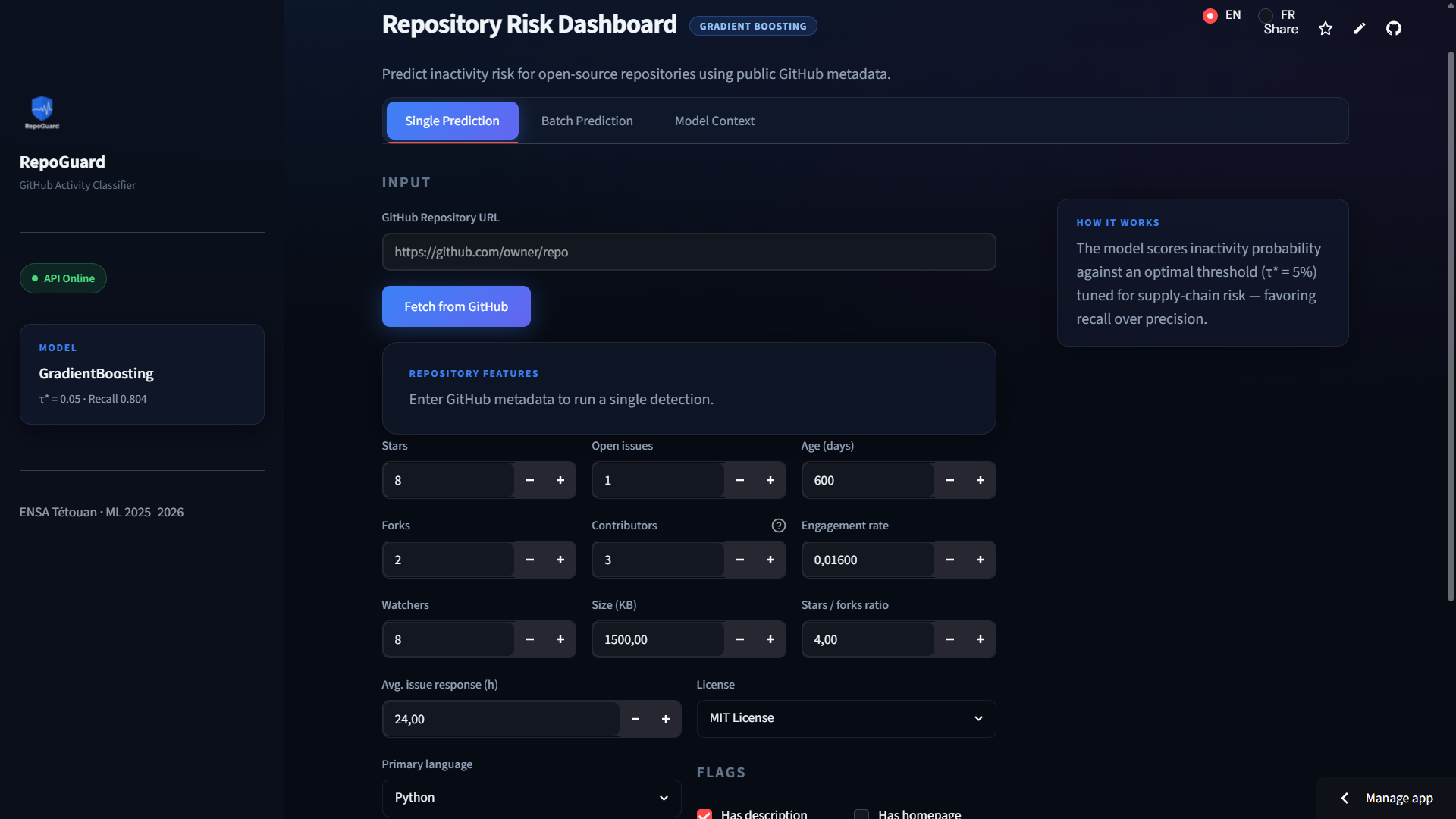
#### 📁 批量处理统计摘要
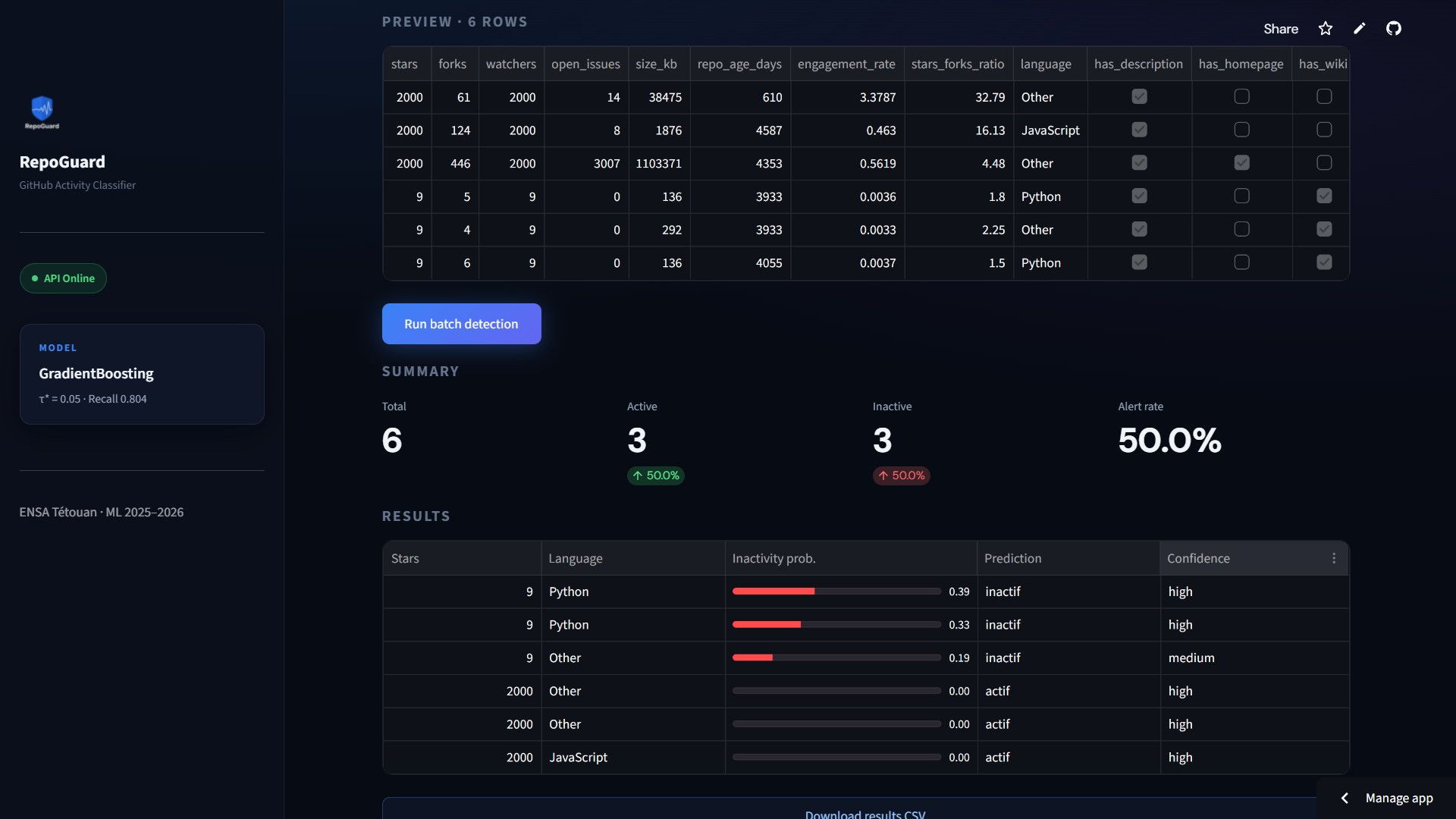
### 📊 模型信息
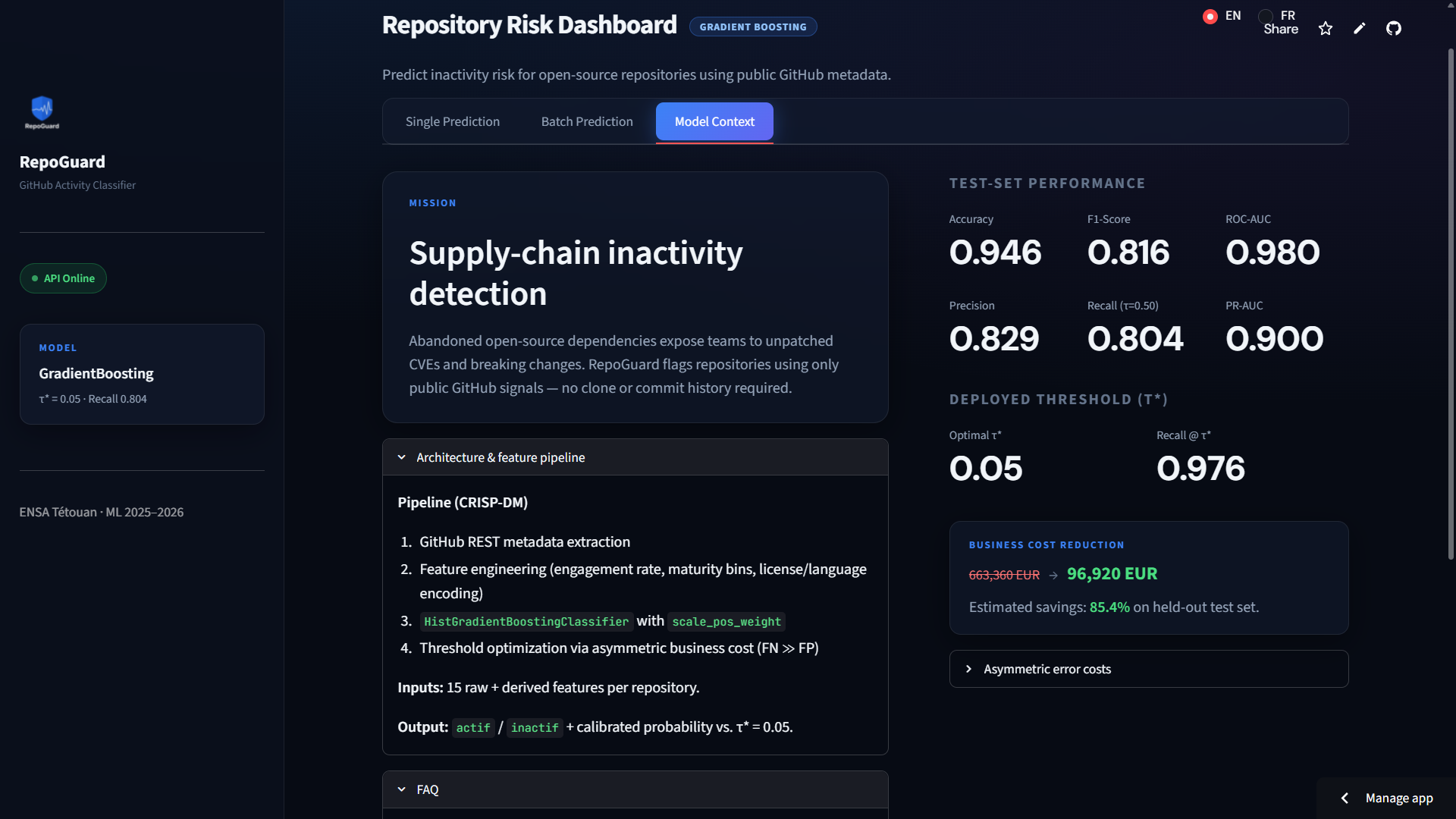
## 🚀 快速入门指南
### 🐳 选项 A:使用 Docker 启动(推荐)
Docker Compose 会在同一个虚拟网络上自动编排 FastAPI 容器(端口 8000)和 Streamlit UI 容器(端口 8500)。
1. 安装 Docker 和 Docker Compose。
2. 复制示例文件并配置您的环境变量(特别是 `GITHUB_TOKEN`):
cp .env.example .env
3. 在项目根目录下运行以下命令:
docker compose up --build
4. 访问各项服务:
- **用户界面 (Streamlit) :** [http://localhost:8500](http://localhost:8500)
- **REST API (Swagger 文档) :** [http://localhost:8000/docs](http://localhost:8000/docs)
- **健康检查 (Healthcheck) :** [http://localhost:8000/health](http://localhost:8000/health)
### 💻 选项 B:本地启动(不使用 Docker)
1. 创建虚拟环境并安装依赖项:
python -m venv venv
source venv/Scripts/activate # 在 Windows 上: venv\Scripts\activate
pip install -r requirements.txt
2. 配置您的环境变量:
cp .env.example .env
3. **启动 REST API:**
uvicorn app.api:app --host 127.0.0.1 --port 8000 --reload
4. **启动用户界面:**
streamlit run app/ui.py --server.port 8500 --server.address 127.0.0.1
## 🧪 运行单元测试
单元测试用于验证 Pydantic schema 的稳健性、Feature Engineering 逻辑以及 API 的概率计算。
```
python -m pytest tests/
```
## 📖 REST Endpoints 与使用示例
### 可用 Endpoints
- `GET /`:包含 API 元数据的欢迎页。
- `GET /health`:检查模型状态。
- `GET /model/info`:包含 Gradient Boosting 及第 3 阶段指标的信息。
- `POST /predict`:接收原始特征并返回分类结果。
- `POST /predict/batch`:接收一个 CSV 文件并返回附带预测结果的增强文件。
### 单条请求示例 (Curl)
```
curl -X POST http://localhost:8000/predict \
-H "Content-Type: application/json" \
-d '{
"stars": 12,
"forks": 4,
"open_issues": 1,
"watchers": 12,
"size_kb": 1500.0,
"repo_age_days": 800,
"contributor_count": 5,
"avg_issue_response_hours": 24.0,
"engagement_rate": 0.02,
"stars_forks_ratio": 3.0,
"language": "Python",
"license": "MIT License",
"has_description": true,
"has_homepage": false,
"has_wiki": true,
"has_projects": true,
"is_fork": false
}'
```
#### API 响应
```
{
"prediction": "inactif",
"probability": 0.1624,
"threshold": 0.05,
"confidence": "medium"
}
```
## ⚠️ 模型局限性
1. **对噪声敏感**:由于 GitHub 搜索 API 的限制,贡献者数量上限设定为 100。
2. **响应时间估算**:Issue 的响应延迟是基于 20 个已关闭 issue 的受限历史记录计算得出的,这可能会掩盖近期的变化趋势。
3. **高误报率**:当阈值为 **0.05** 时(旨在最大化检测安全漏洞而设定,因为一个漏报 (Faux Négatif) 的业务成本高达 10,000 欧元),大约有一半的警报最终被证明是活跃的项目。这一业务决策倾向于宁可错杀也不可漏报的安全保守原则。
## 📜 许可证
本项目基于 **MIT License** 开源。获取更多详情,请查看源代码。
标签:Apex, Kubernetes, REST API, 代码示例, 数据分析, 机器学习, 版权保护, 请求拦截, 软件依赖管理, 逆向工具