thunderstornX/agentic-osint-agent
GitHub: thunderstornX/agentic-osint-agent
基于 LangGraph ReAct 的自主开源情报调查代理,整合五种免费只读工具对公共域名进行被动的、可溯源的情报收集。
Stars: 0 | Forks: 0
# agentic-osint-agent
[](https://doi.org/10.5281/zenodo.20480446)
[](LICENSE)
[](https://github.com/thunderstornX/agentic-osint-agent/actions/workflows/tests.yml)
[](#tools)
[](https://langchain-ai.github.io/langgraph/)
```
___ ____ ___ _ _ _____ . . . . . .
/ _ \/ ___|_ _| \ | |_ _| · ·
| | | \___ \| || \| | | | · .--. ·
| |_| |___) | || |\ | | | · / \ ·
\___/|____/___|_| \_| |_| · | ◯ | ·
· \ / ·
a g e n t i c o s i n t '--'\\
a g e n t \\__
\__
L A N G G R A P H · R E A C T · 5 T O O L S
plan · call · observe · decide
~ AMB · ORCID 0009-0007-2787-943X · v1.0 · 2026 ~
```
一个 LangGraph **ReAct** agent,使用**五个免费的、只读的公开情报源工具**:
WHOIS、DNS、Shodan InternetDB、GitHub code search 以及 Wayback Machine CDX API,
针对公共域名进行被动 OSINT 调查。agent 决定接下来调用什么工具;
而人类决定调查谁。
## 运行截图
`osint investigate` 会打开一个实时终端仪表板:
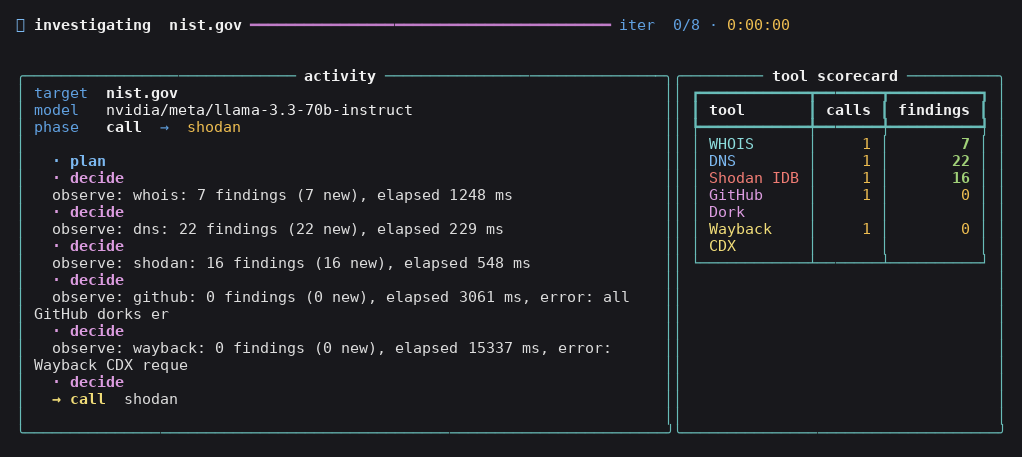
运行完成后,你会得到一份可溯源的简报:
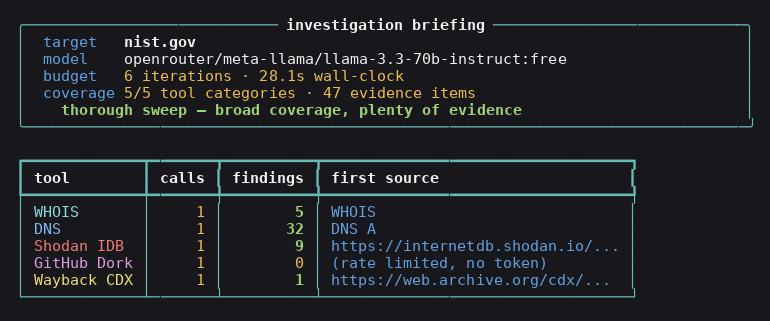
## 快速开始
```
git clone https://github.com/thunderstornX/agentic-osint-agent.git
cd agentic-osint-agent
pip install -r requirements-dev.txt
# 选择一个 provider —— 两者都是 OpenAI 兼容的,并且都有免费额度
export OPENROUTER_API_KEY=sk-or-...
# 或
export NVIDIA_API_KEY=nvapi-...
# 提高 GitHub-search 速率限制(10/min 未认证 -> 30/min)
export GITHUB_TOKEN=ghp_... # optional but recommended
python -m agent.cli investigate \
--target nist.gov \
--provider openrouter \
--authority "Public-interest research; .gov target; passive only"
```
CLI **拒绝在没有授权声明的情况下运行** —— 该字符串将被逐字记录在 JSON 报告中,因此每次调查的法律姿态都是记录在案的产物,而非默认的隐性知识。
### 其他命令
```
python -m agent.cli tools # list the five tools and what each does
python -m agent.cli version # print version
python -m agent.cli investigate --help
```
### 写入内容
对于目标 `nist.gov` 和 `--output-dir results/`:
| File | Content |
|-------------------------------|------------------------------------------------------------|
| `results/nist.gov.json` | Structured intelligence report (schema_version 1) |
| `results/nist.gov.md` | Human-readable briefing with evidence table + trace |
JSON 报告包含:`schema_version`、`generated_at`、
`operator_authority`、运行元数据、证据行(每行均包含
`source` 和 `confidence`)、按时间顺序的 trace,以及
由 LLM 生成的最终简报。
## 五个工具
| Tool | Endpoint | Auth |
|--------------|--------------------------------------------------------|--------------------------|
| **WHOIS** | python-whois library (RDAP-aware fallback) | none |
| **DNS** | dnspython, system resolver, A/AAAA/MX/NS/TXT/CNAME | none |
| **Shodan IDB** | `https://internetdb.shodan.io/{ip}` | **none** (free endpoint) |
| **GitHub Dork** | `https://api.github.com/search/code` | optional `GITHUB_TOKEN` |
| **Wayback CDX** | `http://web.archive.org/cdx/search/cdx` | none |
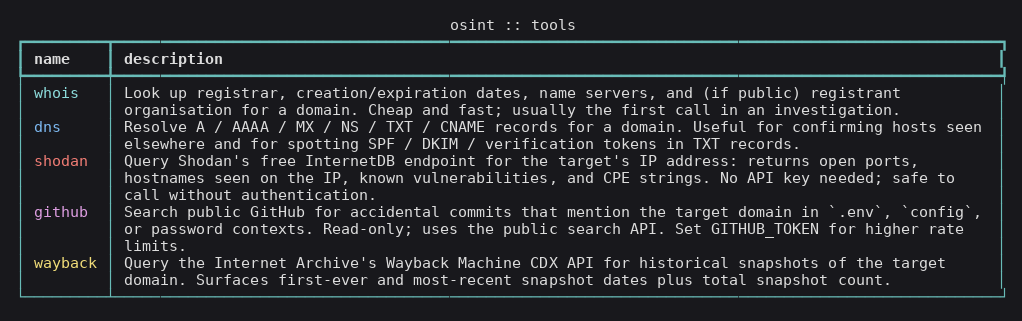
每个工具都会返回一个 `ToolResult`,其 `findings` 是类型化的 `Evidence`
对象,包含 `tool`、`kind`、`value`、`source`、`confidence`,以及
用于去重的稳定 SHA-256 指纹。
## 架构
```
.
├── agent/ # the LangGraph ReAct agent
│ ├── state.py # TypedDict state schema
│ ├── prompts.py # 3 ReAct prompt templates (planner, decider, reporter)
│ ├── llm.py # OpenAI-compat client (OpenRouter + NVIDIA NIM)
│ ├── graph.py # StateGraph: plan -> decide -> {call|done}
│ ├── cli.py # Typer CLI
│ └── tui/ # Rich TUI: banner, theme, live dashboard, briefing
├── tools/ # five OSINT tools, uniform Tool interface
│ ├── whois_tool.py
│ ├── dns_tool.py
│ ├── shodan_tool.py
│ ├── github_dork_tool.py
│ └── wayback_tool.py
├── memory/
│ ├── evidence.py # Evidence dataclass + fingerprint dedup
│ └── scratchpad.py # bounded prompt-shaped memory
├── output/
│ ├── formatter.py # JSON report writer
│ └── markdown.py # Markdown briefing writer
├── eval/
│ ├── test_targets.json # 20 public targets
│ ├── run_tool_smoke.py # tool-only benchmark (no LLM required)
│ └── run_eval.py # full agent eval with hallucination metric
├── results/ # real measured benchmark output
├── tests/ # 31 pytest cases (run in <2s)
├── paper/ # IEEE 3-page paper (paper.pdf)
└── scripts/
├── render_terminal.py # ANSI-to-PNG rasteriser (no webfonts)
└── render_figures.py # paper figures from real numbers
```
## ReAct 循环
```
__start__ ──► plan ──► decide ──► call ──► observe ──┐
│ │
└──► done ──► __end__ ◄──┘
```
| Node | What it does |
|---------|-------------------------------------------------------------------------------|
| plan | LLM writes a one-paragraph plan over the five tools |
| decide | LLM emits `{"tool": ..., "rationale": ...}` JSON; un-parseable → `stop` |
| call | Selected tool runs in a thread; findings deduped into the scratchpad |
| observe | Tool result distilled into a one-line observation appended to the trace |
| done | LLM writes the markdown briefing **strictly cited from the evidence pool** |
终止条件:当决策器返回 `stop` 时,当所有 5 个工具均已
被调用时,或者当消耗完 `--budget`(默认为 12)次迭代时。
## 真实测量基准测试
`results/tool_smoke.csv` 和 `results/tool_smoke_summary.json` 是在 Intel Core i5-8250U / 16 GB RAM 工作站上针对 20 个评估目标运行所有五个工具的输出结果。**100 次工具运行共耗时 562.9 秒**(端到端每个目标约 5.6 秒)。
| Tool | Success | Mean latency | Mean findings | Total findings |
|--------------|------------:|-------------:|--------------:|---------------:|
| WHOIS | 20/20 (100%) | 0.95 s | 5.65 | 113 |
| DNS | 20/20 (100%) | 1.14 s | 32.9 | 658 |
| Shodan IDB | 20/20 (100%) | 0.98 s | 9.85 | 197 |
| GitHub Dork | 0/20 (0%) ¹ | 3.51 s | 0.0 | 0 |
| Wayback CDX | 7/20 (35%) ² | 21.6 s | 1.05 | 21 |
¹ 未经过身份验证的 GitHub 搜索在每个目标的第一次查询时就会触及 10 次请求/分钟的限制。本次运行未对已验证的路径(设置了 `GITHUB_TOKEN`,30 次请求/分钟)进行基准测试;这种速率限制行为是 GitHub API 本身已公布的行为。
² Wayback CDX 在大约三分之二的请求中返回 503 或超时。这是公共服务已知特性,而不是此客户端的 bug;我们将其作为真实的 `error` 字段反馈出来,而不是进行静默重试。
本地复现:
```
python -m eval.run_tool_smoke
```
### 真实测量的 Agent 评估(循环中的 LLM)
`results/eval/*.json` 是针对同样 20 个目标运行完整 agent 后的每个目标输出。有三个目标在 NVIDIA NIM
(`meta/llama-3.3-70b-instruct`)上运行;在 NVIDIA 每日免费额度用尽后,有十七个目标在 OpenRouter
(`openai/gpt-oss-120b:free`)上运行。两者均使用相同的 OpenAI 兼容传输格式,因此记录的格式是统一的。
| Metric | Mean | Median | Min | Max |
|------------------------|------:|-------:|-----:|------:|
| Tool coverage (of 5) | 5.00 | 5.00 | 5 | 5 |
| Iterations consumed | 5.00 | 5 | 5 | 5 |
| Evidence rows / target | 49.2 | 44.5 | 26 | 114 |
| Hallucination rate | 0.305 | 0.250 | 0.10 | 0.625 |
| Wall-clock (s) | 74.9 | 73.6 | 51.8 | 93.3 |
**20/20 的目标均在正好 5 次迭代后达到了 `covered_all_tools` 的终止条件。** 所有目标的 agent 总耗时(Wall-clock):**1498 秒**。
幻觉率是指由 LLM 生成的简报中未提及任何工具标签(`whois`、`dns`、`shodan`、`github`、`wayback`)的句子比例;此比率越低越好。`example.com` 的异常值(0.625)是因为它是 RFC 保留域名,其简报中合理地包含了一些作为背景说明的句子("intended for documentation in examples"),这些句子并未引用任何工具。
复现:
```
export OPENROUTER_API_KEY=sk-or-...
python -m eval.run_eval --provider openrouter --skip-existing
python -m eval.consolidate # rolls per-target JSONs into a single CSV
```
## 为什么不使用 LLM 作为发现的评判者
agent 展示的每一项发现都来自于**工具内部确定性的解析器**,而不是来自 LLM。模型仅用于:
1. **决定**接下来调用五个工具中的哪一个,以及
2. 将证据池**总结**为 markdown 简报,
并被限制只能引用工具标签。
模型绝不会为证据打标签。这使得运行结果可复现(相同的探测 + 相同的响应 = 相同的证据),保持了审计日志的简短(每一项声明都可以追溯到公开来源),并规避了困扰那些带有 LLM 评分循环的 agentic 系统的“更大的模型说没问题”的失败模式。
## 测试
31 个 pytest 用例。完整测试套件运行耗时约 **1.7 秒**。
```
python -m pytest tests/ -v
```
测试覆盖范围:
- **Evidence + Scratchpad** — 默认置信度、指纹确定性、去重不变量、prompt 预算限制(约 6 个测试)
- **OSINT 工具**(使用 mock) — 将 404 视为干净的空数据、完整记录解析、速率限制处理、Wayback 行结构健壮性、无 A 记录路径(约 7 个测试)
- **LLM 适配器** — 正常路径、内容部分列表重组、缺失键、**HTTP 错误绝不回显响应体**、**API 密钥绝不出现在 stdout/stderr 中**(约 5 个测试)
- **Graph 端到端** — 使用 `ScriptedLLM` — 完整的 5 工具扫描、立即停止、预算耗尽(约 5 个测试)
- **报告** — JSON schema、markdown 往返转换、管道符转义(约 3 个测试)
- **TUI** — 横幅特征、仪表板日志截断、简报冒烟测试(约 5 个测试)
## 伦理使用
这是一个**被动侦察**工具。它不会登录系统、扫描端口、主动识别服务指纹或主动联系目标。它查询的是记者或安全分析师手动会查询的相同五个免费公开情报源 —— 只不过是运行在一个严谨的、可溯源的、可复现的循环中。完整策略见 [`ETHICAL_USE.md`](ETHICAL_USE.md)。
CLI **拒绝在未捕获到 `--authority` 字符串并将其记录到 JSON 报告中的情况下运行**。让法律依据成为记录,而不是隐性知识。
## 论文
一篇 3 页的 IEEE 论文描述了其架构、工具基准测试以及不使用 LLM 作为评判者的设计选择,位于 [`paper/paper.pdf`](paper/paper.pdf)。
## 引用此工作
```
@software{bhutto2026osintagent,
author = {Bhutto, Ali Murtaza},
title = {agentic-osint-agent: A LangGraph ReAct agent for
autonomous public-source investigation},
year = {2026},
doi = {10.5281/zenodo.20480446},
url = {https://github.com/thunderstornX/agentic-osint-agent},
orcid = {0009-0007-2787-943X}
}
```
同一作品集中的相关工作:
- [`llm-red-team-toolkit`](https://github.com/thunderstornX/llm-red-team-toolkit)
— OWASP LLM Top 10 对抗性探测,相同的 Python 风格和测试规范。
- [`osint-pipeline-demo`](https://github.com/thunderstornX/osint-pipeline-demo)
— 此 agent 所接入的数据管道对应物。
- [`secure-python-pipeline-template`](https://github.com/thunderstornX/secure-python-pipeline-template)
— 此仓库的 CI 所基于的 DevSecOps 门禁。
## License
MIT © 2026 Ali Murtaza Bhutto
```
. . . . . .
· ·
· .--. ·
· / \ ·
· | ◯ | ·
· \ / ·
'--'\\
\\__
\__
```
~ AMB · ORCID 0009-0007-2787-943X · v1.0 · 2026 ~
标签:AI智能体, ESC4, LangGraph, OSINT, 实时处理, 自动化调查, 逆向工具