aaronphifer/triagewall
GitHub: aaronphifer/triagewall
Triagewall 是一款面向自托管 SOC 的本地 LLM 驱动的 Suricata 告警分诊工具,通过预过滤与本地大语言模型双层架构在不依赖云端的前提下大幅降低告警噪音。
Stars: 3 | Forks: 0
# Triagewall
**适用于家庭实验室的本地 LLM Suricata 告警分诊工具。** 无需将数据发送到云端即可减少告警噪音。完全在您的硬件上运行。无遥测。AGPL-3.0。
## 为什么会有这个项目
如果您在家庭实验室中运行 Suricata,您就会知道问题所在。ET Open 规则集每天会产生数千个告警,其中绝大多数是噪音——TLS SNI 匹配、普通 CDN 的 DNS 查询、您自己的扫描行为、您孩子的游戏流量。有价值的信号就在其中,但您不可能在晚上 11 点通过阅读每一条告警来发现它们。
商业 XDR 产品通过基于云的机器学习和每月 500 美元的账单来解决这个问题。开源 SIEM 技术栈(Wazuh, TheHive, Cortex)为您提供了数据,但缺少分诊层。Triagewall 就是这个缺失的层级,专为那些已经自行托管其安全技术栈并希望继续保持这种方式的人而设计。
## 它的功能
- **实时读取 Suricata `eve.json`**,在程序重启和日志轮转时跟踪读取位置
- **通过可调的 JSON 配置预过滤已知的良性规则**(即“我已经知道什么是 STUN 流量了,别再告诉我了”过滤器)——微秒级查询,零 LLM 成本
- **通过 Ollama 使用本地 LLM 对剩余告警进行分诊**(默认:`mistral:7b`,有关基于 VRAM 的模型选择,请参阅[性能与准确性](#performance--accuracy))
- **记录您的反馈**——每个判定在仪表板中都有“同意”/“标记为不同”按钮,从而构建一个带标签的数据集和可衡量的同意率
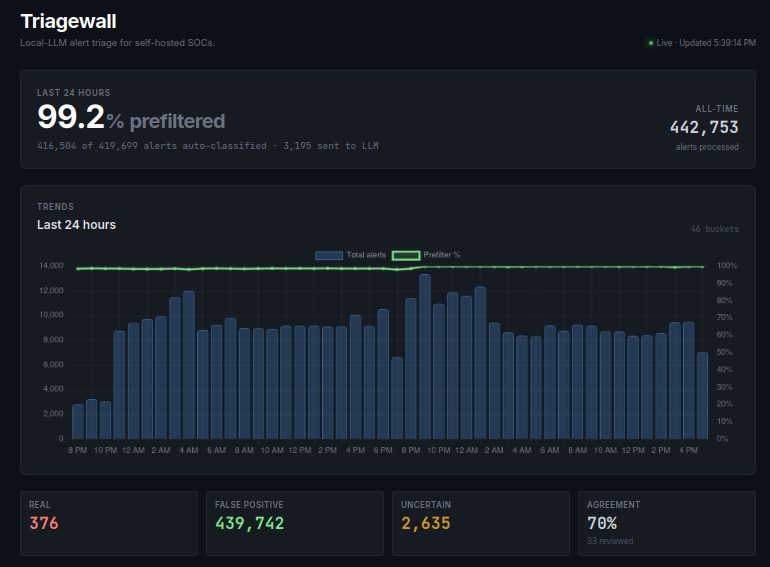
- **在简洁的 Web 仪表板中展示重要信息**,包含每小时的流量趋势
## 前置条件
- **Docker Engine 20.10+** ([安装指南](https://docs.docker.com/engine/install/))
- **Docker Compose v2**(即 `docker compose` 插件,而不是已弃用的 `docker-compose` v1)。在 Ubuntu/Debian/Pop!_OS 上:
```
sudo apt-get install docker-compose-plugin
```
这需要 Docker 的官方 apt 仓库。如果找不到该软件包,请按照 [Docker 安装指南](https://docs.docker.com/engine/install/ubuntu/) 先添加仓库。
- **在本地或网络上另一台可访问的主机上运行 Ollama**([安装](https://ollama.com/download))
- **至少一个 Ollama 模型:** `ollama pull mistral:7b`
- **具有 8+ GB VRAM 的 GPU** 用于 LLM(预过滤器在没有 GPU 的情况下也能工作,但剩余的长尾数据在 CPU 上无法在合理的时间内完成分类)
## 快速开始
```
git clone https://github.com/aaronphifer/triagewall.git
cd triagewall
cp .env.example .env
# 先在不使用真实数据的情况下尝试:
# 在 .env 中设置 DEMO_MODE=true,然后:
docker compose up -d # Docker Compose v2+
# 或者
docker-compose up -d # Older Docker / Compose v1
# 打开 http://localhost:8084 以查看包含示例告警的 dashboard。
# 对于生产环境:编辑 .env 进行以下设置:
# - DEMO_MODE=false
# - HOST_DATA_DIR=./data(或您希望存储 runtime 文件的任何位置)
# - HOST_EVE_DIR=/var/log/suricata(包含您的 eve.json 的目录)
# - OLLAMA_HOST=http://your-ollama-instance:11434
# - OLLAMA_MODEL=mistral:7b
# 然后再次运行 `docker compose up -d`。
```
您需要在网络中可访问的某个地方运行 [Ollama](https://ollama.com),并至少拉取一个模型(`ollama pull mistral:7b`)。Ollama 实例可以在同一主机上,也可以在单独的 GPU 节点上。
## 性能与准确性
Triagewall 已在家庭实验室的生产网络上连续运行多日,针对实时的 OPNsense Suricata 数据进行处理。测量数据如下:
| 指标 | 数值 |
|---|---|
| 源速率(典型值) | 6,000–13,000 条告警/小时 |
| 预过滤比例 | 99%+(调整约 20 个 SID 后) |
| LLM 延迟 | 每次调用 1–3 秒 (RTX 4060 上的 Mistral 7B Q4) |
| 端到端延迟 | 稳态下低于 2 分钟 |
| 守护进程 RAM 占用(不含 Ollama) | ~17 MB |
| 数据库增长 | 7 天后约 1.5 GB |
吞吐量主要随预过滤比例扩展。两层设计意味着预过滤的告警在几微秒内即可处理完毕;只有经过 LLM 分类的告警(调整后通常占 0.3–3%)才会受到 Ollama 延迟的限制。
### 按 VRAM 推荐的模型
| GPU VRAM | 推荐模型 | 推理质量 |
|---|---|---|
| 8 GB (RTX 4060, 3060 Ti) | `num_ctx=4096` 的 `mistral:7b` | 良好 — 能很好地处理长尾数据 |
| 12 GB (RTX 3060, 4070) | `mistral:7b` 或完整上下文的 `llama3.1:8b` | 较好 |
| 24 GB+ (RTX 3090, 4090) | `gemma3:12b`, `llama3.1:70b-q4` | 最佳 |
避免使用超出您 VRAM 容量的模型。CPU 部分卸载会导致推理延迟变慢 10 倍且极不稳定。请通过 `ollama ps` 验证模型是否合适,确保预热后显示 `100% GPU`。
### 调优的工作原理
在新网络上运行 Triagewall 的第一天,主要是用特定站点的噪音数据填充 `prefilter.json`。仪表板会显示哪些签名在您的 LLM 工作负载中占主导地位;将它们添加到预过滤器只需几秒钟,即可提供带有文档说明理由的永久分类。在初始调优之后,LLM 只需处理真正新颖签名的长尾部分。
此仓库生产环境配置中的预过滤器条目示例:
```
{
"signature_ids": [2009205, 2009206, 2009207, 2009208],
"reason": "Legacy ET MALWARE Conficker/KEYPLUG P2P UDP signatures (2009-era) match modern STUN traffic to Microsoft Azure STUN servers (20.202.0.0/16:3478) used by Teams, Xbox Live, Skype. Confirmed false positive — same UDP packet shape, different intent. The LLM consistently misclassifies these because the signature description biases toward 'malware' without port-aware context."
}
```
这些原因字符串同时也可作为文档,记录了*为什么*某个 SID 在您的网络中被抑制——这在几个月后复查预过滤器,或者与他人分享调优心得时非常有用。
## 它不能做什么
- 它不会阻断流量。Triagewall 是只读的——它只进行分诊,不采取行动。如果您想要自动阻断,那是 Wazuh Active Response 或您的防火墙该做的事,而不是这个工具。
- 它不能替代 SOC 分析师。它将每天数千条告警精简为少数几条以供审查。这些告警仍然是您的工作。
- 它绝不调用 OpenAI、Anthropic 或任何云 LLM。这是设计使然。
- 它不能在没有 GPU 的情况下工作。Ollama 可以在 CPU 上运行模型,但推理速度太慢,无法跟上大多数网络的告警速率。
## 路线图
完整计划请参阅 [ROADMAP.md](ROADMAP.md)。重点如下:
**v0.2(下一版本):**
- 判定反馈循环——当用户对某个 SID 持续覆盖 LLM 的判定时,自动建议将其添加到预过滤器中
- 资产标签——为内部主机命名,并包含在 LLM 提示词中以实现上下文感知分类
- 仪表板上的时间范围和 IP 过滤
- Wazuh API 集成,作为第二告警源
- 用于实现更高吞吐量的异步 LLM 管道
**v0.3 及更高版本:** Webhook 通知、CSV/JSON 导出、每日/每周摘要、多源仪表板。
## 参与贡献
我们欢迎各种贡献,但在提交大型 PR 之前,请先开启一个 Issue 进行讨论。
- Bug 报告 → [Issues](https://github.com/aaronphifer/triagewall/issues)
- 功能建议 → [Discussions](https://github.com/aaronphifer/triagewall/discussions)
- 安全漏洞披露 → security@triagewall.io
- 常规联系 → hello@triagewall.io
开发环境设置请参阅 [CONTRIBUTING.md](CONTRIBUTING.md)。
## 许可证
AGPL-3.0。详情请见 [LICENSE](LICENSE)。
为需要分发 Triagewall 但无需遵守 AGPL §13 条款的组织提供商业许可证——请发送邮件至 licensing@triagewall.io。
## 致谢
本项目建立在 [Suricata](https://suricata.io)、[Ollama](https://ollama.com)、[FastAPI](https://fastapi.tiangolo.com) 以及更广泛的自托管安全社区的肩膀上。灵感来源于 [SOCFortress CoPilot](https://github.com/socfortress/CoPilot) 以及社区成员发布的各种 Wazuh+Suricata 分诊实验——所有这些都解决了该问题的相邻部分,并塑造了 Triagewall 解决此问题的方式。
标签:AGPL, AI风险缓解, Apex, C2, Docker, Docker Compose, EVE.JSON, Homelab, IPS, LLM, LLM评估, Metaprompt, ML, Ollama, Suricata, Unmanaged PE, 仪表盘, 告警降噪, 威胁检测与响应, 安全信息与事件管理, 安全运营中心, 安全防御评估, 家庭实验室, 开源, 搜索引擎爬取, 无遥测, 本地大模型, 本地大语言模型, 机器学习, 现代安全运营, 私有化部署, 网络安全, 网络安全, 网络映射, 自托管, 警报分类, 请求拦截, 逆向工具, 防御规避, 隐私保护, 隐私保护