bogdanpricop/MassDownload
GitHub: bogdanpricop/MassDownload
一款 Chrome/Edge 扩展,能够自动翻页抓取 Google、Bing 或 sitemap.xml 上的指定类型文件并批量下载,同时按域名构建可搜索的本地文件库,覆盖从搜索发现到归档管理的完整流程。
Stars: 0 | Forks: 0
# MassDownload
**一款 Chrome/Edge 扩展程序,能够抓取 Google、Bing 或 sitemap.xml 的所有页面内容,并批量下载找到的文件,将其存入可搜索的本地库中。**
[](https://github.com/bogdanpricop/MassDownload/actions/workflows/ci.yml)
[](https://opensource.org/licenses/MIT)
[](https://github.com/bogdanpricop/MassDownload/releases/latest)
[](https://developer.chrome.com/docs/extensions/mv3/intro/)
[](https://www.typescriptlang.org/)
[](https://github.com/bogdanpricop/MassDownload)
[快速入门](#30-second-quickstart) • [安装](#install) • [工作原理](#how-it-works) • [功能对比](#comparison) • [应用场景](#use-cases) • [常见问题](#faq) • [贡献指南](#contributing)
## 30 秒快速入门
[安装](#install)完成后:
1. 点击浏览器工具栏中的 **MassDownload** 图标 —— 侧边栏随即打开
2. 填入 **Site** = `data.gov`(或任意域名),**Filetype** = `pdf`,来源保持默认的 Google
3. 点击 **Search** —— 扩展程序会在一个真实的后台标签页中对 Google 进行翻页抓取
4. 选中所需文件并点击 **Download selected** —— 它们将被保存至 `Downloads/MassDownload/data.gov/`
5. 点击 **Library** 浏览按主机分类的 HTML 索引,其中包含已收集的所有内容,并支持实时搜索
这就是完整的操作循环。本 README 的其余部分涵盖了参数调优、备用来源(Bing、sitemap.xml)以及边缘情况处理。
## 主要功能
当你想在 Google 搜索 `site:example.gov filetype:pdf` 并获取所有结果页面(而不仅是前十条)里的每一份 PDF 时。如果没有 MassDownload,你需要:
1. 打开 Google
2. 输入查询条件
3. 逐个点击 PDF
4. 翻阅 10 页以上的 Google 结果
5. 对下一个站点重复上述操作
使用了 MassDownload 之后:
1. 点击工具栏图标 → 打开侧边栏
2. Site = `example.gov`,filetype = `pdf` → 点击 **Search**
3. 列出所有结果页面上的匹配 PDF(附带标题和摘要)
4. 点击 **Download selected** → 文件将并行下载并保存至 `Downloads/MassDownload/example.gov/`
5. 点击 **Library** → 查看可搜索的 HTML 索引,包含你从该站点下载的所有内容
保存的搜索记录可让你一键重新运行查询。Sitemap 模式可以找到 Google 尚未索引的文件。自动回退到 Bing 可以妥善应对 Google 的验证码(CAPTCHA)。
## 截图
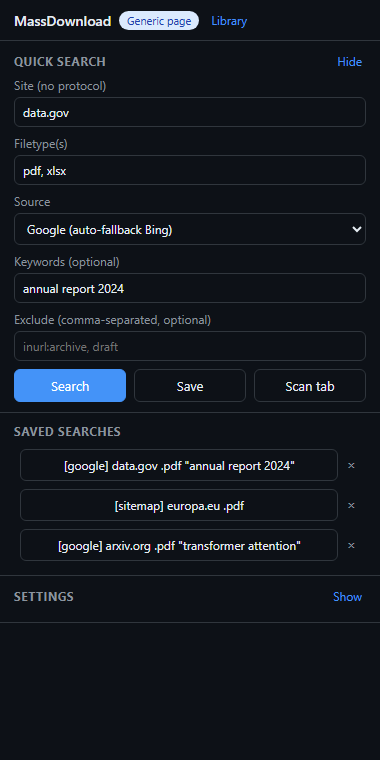
Quick Search — site, filetype, source, keywords. Saved searches re-run in one click.
|
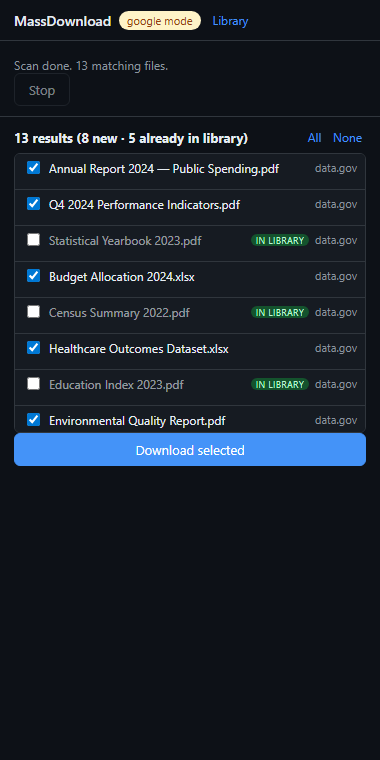
Scan results — counter shows new vs already-downloaded. Files in the library are unchecked by default.
|
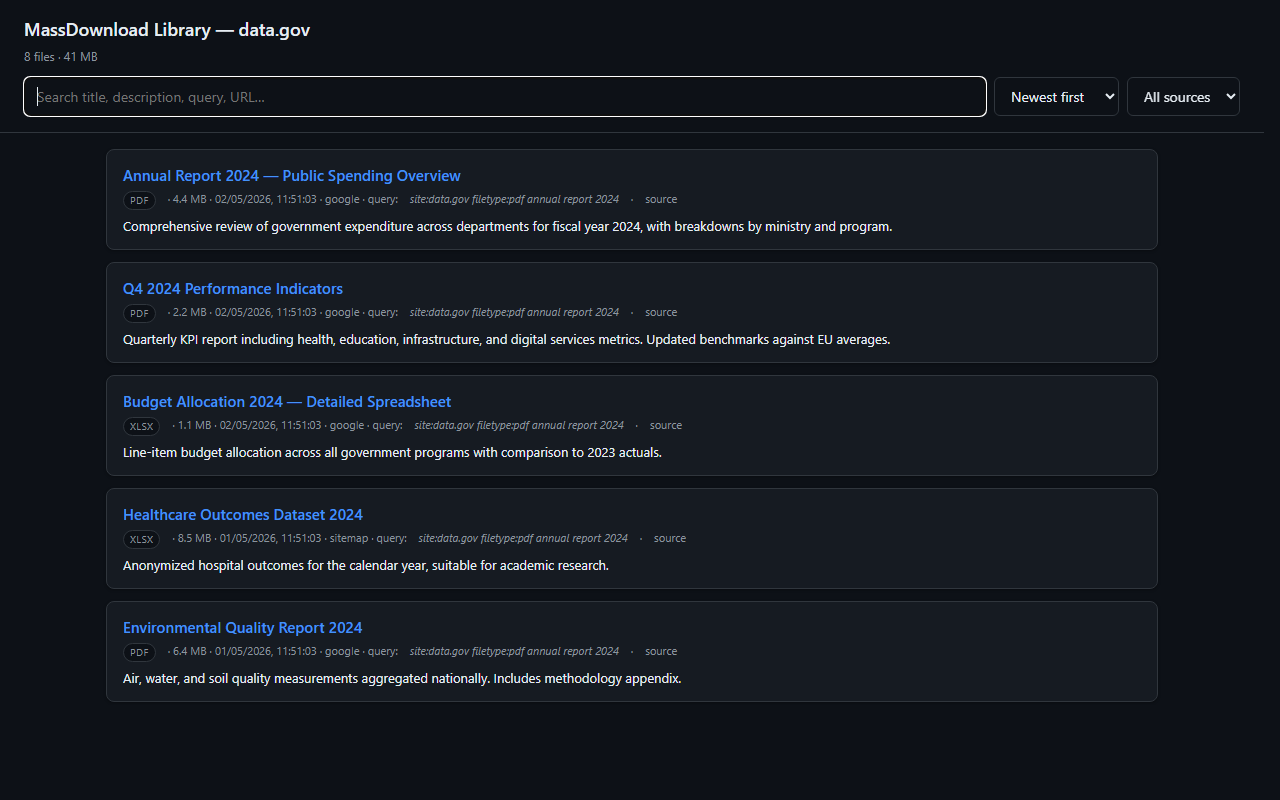
Per-host library — single-file HTML with live search, sort, filter, and file:// links to local downloads.
|
## 安装说明
### 选项 A —— 预构建的 zip 包(无需 Node.js)⭐ 推荐普通用户使用
1. 前往 [最新发布版](https://github.com/bogdanpricop/MassDownload/releases/latest)。
2. 从 Release Assets 中下载 `MassDownload-vX.Y.Z.zip`。
3. 将压缩包解压到一个稳定的位置(例如 `C:\Users\you\Apps\MassDownload\`)。**不要选择临时文件夹** —— 浏览器会从这个路径加载扩展程序,如果之后删除了该文件夹,扩展就会失效。
4. 打开扩展程序管理器:
- Chrome / Brave / Vivaldi:`chrome://extensions`
- Microsoft Edge:`edge://extensions`
5. 开启 **开发者模式 (Developer mode)**。
6. 点击 **加载已解压的扩展程序 (Load unpacked)**,然后选择解压后的文件夹(即包含 `manifest.json` 的那个)。
7. 将 MassDownload 图标固定到工具栏 —— 在任意标签页点击它即可打开侧边栏。
后续如需更新:下载新的 zip 包,替换文件夹中的内容,然后在扩展卡片上点击 **🔄 刷新 (Reload)** 按钮。
### 选项 B —— 从源码构建(开发者)
需要 Node.js 18+ 和 npm。
```
git clone https://github.com/bogdanpricop/MassDownload.git
cd MassDownload
npm install
npm run build # outputs dist/ (Chrome / Edge)
npm run build:firefox # outputs dist-firefox/ (experimental)
```
然后在浏览器中访问:`chrome://extensions` → **开发者模式 (Developer mode)** → **加载已解压的扩展程序 (Load unpacked)** → 选择 `dist/`(如果在 Firefox 上,可通过 `about:debugging` 选择 `dist-firefox/`)。
### 结合 HMR 进行开发
```
npm run dev
```
在首次运行开发环境后重载一次扩展;此后侧边栏将在文件修改时进行热重载。
## 工作原理
### 三种扫描来源
| 来源 | 适用场景 | 工作方式 |
|---|---|---|
| **Google**(默认) | 你想要 Google 索引的内容;网站没有公开的 sitemap | 构建 `site:X filetype:Y` 查询,通过真实的后台标签页翻页抓取(`start=0,10,20…`),带有加载完成循环及随机的 0.8–2 秒延迟(模拟人类行为,而非机器人)。**遇到验证码时会自动回退到 Bing。** |
| **Bing** | 受到 Google 频率限制;或想要不同的结果集 | 使用 `bing.com/search?q=site:X filetype:Y`,按 `first=1,51,101…&count=50` 进行翻页。Bing 极少触发验证码。 |
| **Sitemap.xml** | 网站有 sitemap;你想要**所有内容**,而不仅仅是已索引的页面 | 读取 `robots.txt` 中的 `Sitemap:` 指令,找不到则回退尝试 `/sitemap.xml`、`/sitemap_index.xml`。递归跟踪 sitemap 树(最大深度 3,最多 50 个 sitemap 文件)。支持 `.xml.gz` 格式的 gzip 压缩文件。 |
| **Crawl(抓取)** | 没有 sitemap,Google 索引不全,但网站包含内部链接 | 从主页开始进行 BFS(广度优先搜索),跟随同域名的 `
` 链接直至深度 2 和 100 个页面,并收集任何符合文件类型过滤条件的 URL。 |
侧边栏还提供了一个 **Scan tab** 按钮:如果当前 URL 匹配,则会将其作为 Google 搜索引擎结果页面(SERP)进行解析;否则将提取页面中的所有 `a[href]`(通用模式)。
### 智能文件名
当 Google/Bing 提供了结果标题时,将使用该标题作为文件名,取代 URL 中的路径名:
- URL `https://example.com/cgi-bin/dl.php?id=7821` + 标题 `"Decision 312/2024"` → 文件 `Decision 312_2024.pdf`
- URL `https://example.com/papers/foo.pdf`(无标题) → 文件 `foo.pdf`
### 按主机分类的文件库
每个成功下载的文件都会连同其元数据记录在 `chrome.storage.local` 中:标题、摘要描述、发现该文件的查询语句、来源搜索引擎、主机名、时间戳和大小。文件库有**两种视图**:
1. **扩展内编辑页面**(在侧边栏中点击 **Library**)—— 支持全局搜索、按主机/来源/标签过滤,以及单条编辑功能:自定义标题、标签、备注、从库中移除、在文件夹中显示。支持 JSON / CSV / 便携式 HTML 导出。
2. **独立的 `Downloads/MassDownload/{host}/library.html`** —— 在每次批处理下载后(以及每次编辑时)自动重新生成。支持实时搜索、排序、过滤,以及指向本地文件的 `file://` 链接。**完全自包含** —— 可从 USB 闪存盘打开、通过电子邮件发送给同事,或进行归档。零外部依赖。
保存在磁盘上的 HTML 是只读的;标签/备注/自定义标题只能在扩展内页面中添加,并在保存时同步到磁盘版本中。
### 扫描时去重
已存在于文件库中的结果将显示 **"in library"** 标记,且默认处于未选中状态。你仍可选择重新下载(例如为了刷新内容)。
### 可恢复的下载
下载队列在每完成几个下载项后就会被持久化到 `chrome.storage.local` 中。如果 Service Worker 在批处理过程中被回收(Chrome 会在内存压力较大时频繁执行此操作),打开侧边栏时会出现一个 *"恢复上次的队列?(Resume previous queue?)"* 提示栏,显示待处理的数量和启动时间。点击 **Resume**,系统将仅处理未完成的项目。
### 预检 HEAD 请求
可选设置(默认关闭)。在每次下载之前,发送一个超时为 3 秒的 HEAD 请求。返回 404/410 状态的 URL 会被标记为 `skipped`(已跳过),不会占用下载通道。这对于陈旧 URL 较常见的 sitemap 模式最为有用;在其他情况下,这会为每个文件增加大约 200 毫秒的耗时。
### 定期计划重新扫描
点击保存的搜索旁的 **⌚** 图标,即可设置以天为单位的扫描间隔。扩展程序会通过 `chrome.alarms` 唤醒,并在后台无头运行扫描(无需 UI),仅下载尚未存在于文件库中的文件,并且可选择在新文件下载完成时发送桌面通知。该定时器由浏览器拥有,因此不受 Service Worker 回收的影响。
### JSON / CSV 导出
文件库的 HTML 界面中提供了 **↓ JSON** 和 **↓ CSV** 按钮,可下载当前屏幕上经过过滤/排序显示的所有内容。CSV 采用 RFC 4180 引用规范 + UTF-8 BOM(兼容 Excel);JSON 为格式化打印输出。
### 无需逐个提示即可保存
扩展程序调用 `chrome.downloads.download({ saveAs: false })` 以实现文件自动保存。默认目标位置为 `Downloads/MassDownload/{host}/`。使用 **Pick…** 按钮可通过系统对话框一次性选择不同的子文件夹 —— 此设置将应用于后续的所有下载。
如果你的浏览器仍然针对每个文件询问 *"你想对 X.pdf 进行什么操作?"*,则需要禁用全局设置:
| 浏览器 | 设置路径 | 设置项 |
|---|---|---|
| **Microsoft Edge** | `edge://settings/downloads` | *下载前询问每个文件的保存方式 (Ask me what to do with each download)* |
| **Google Chrome** | `chrome://settings/downloads` | *下载前询问每个文件的保存位置 (Ask where to save each file before downloading)* |
| **Brave / Vivaldi** | `brave://settings/downloads` / `vivaldi://settings/downloads` | 与 Chrome 相同 |
侧边栏中提供了 **Open browser download settings** 链接,可直接跳转到该设置页。
## 功能对比
MassDownload 与同类工具相比如何?
| 工具 | 搜索引擎自动翻页 | 防验证码策略 | Sitemap 回退 | 文件库与搜索 | 浏览器会话 | 免费 |
|---|:-:|:-:|:-:|:-:|:-:|:-:|
| **MassDownload** | ✅ | ✅ 真实标签页 + 延迟 | ✅ | ✅ 按主机分类的 HTML | ✅ | ✅ |
| **DownThemAll!** | ❌ 仅限当前页 | 不适用 | ❌ | ❌ | ✅ | ✅ |
| **Simple Mass Downloader** | ❌ 仅限 URL 模板 | 不适用 | ❌ | ❌ | ✅ | ✅ |
| **Web Scraper.io** | ⚠️ 需自行配置 | ❌ | ⚠️ 需自行配置 | ❌ | ✅ | 免费增值 |
| **wget --recursive** | ❌ | 不适用 | ⚠️ 需手动 | ❌ | ❌ | ✅ |
| **SerpAPI + script** | ✅ 通过 API 实现 | ✅ | ❌ | 需自行搭建 | ❌ | ❌($50+/月) |
**如果你**想要一键实现从“搜索域名”到“将文件保存到磁盘并建立可搜索的文件库”的全流程,且不想付费购买 SaaS 或编写 bash 脚本,**请选择 MassDownload**。
**如果你**只是已经打开了一个页面,想批量提取其中的所有链接,**请选择 DownThemAll**。
**如果你**想在 CLI 中进行完整的递归站点镜像,**请选择 wget**。
**如果你**需要用于工业级规模的操作并且不介意付费,**请选择 SerpAPI**。
## 应用场景
### 📚 科研人员 / 新闻记者
批量收集政府或机构网站上的所有公开 PDF 以供分析。Sitemap 模式可以抓取到搜索引擎未暴露的文档。
⚖️ 法律 / 律师助理
从公共登记处抓取法院判决、执行人通告、公证记录。按主机分类并带有描述摘要的文件库可让你快速找到特定案件。
### 🔍 OSINT(开源情报)
对域名进行快速情报摸底 —— 该网站发布过哪些文档?Sitemap 回退机制适用于 Google 覆盖率较低的小型网站。
### 👨💻 开发者
这是一个开源的 MV3 参考实现:结合了 side panel + offscreen DOMParser + service-worker 下载队列 + 基于标签页的隐蔽抓取。欢迎 Fork 并进行扩展。
## 项目结构
```
src/
├── background.ts # service worker — scan dispatcher + download queue
├── offscreen.html / .ts # DOMParser host (MV3 service workers can't use DOMParser directly)
├── sidepanel/
│ ├── sidepanel.html # Quick Search form, saved list, results, progress
│ ├── sidepanel.ts # UI state + long-lived port to background
│ ├── sidepanel.css
│ └── folderPicker.ts # one-shot Save-As dialog → relative subfolder
├── parsers/
│ ├── google.ts # SERP URL helpers (extraction runs in-tab)
│ ├── bing.ts # SERP parsing + /ck/a?u= base64 redirect unwrap
│ ├── sitemap.ts # urlset / sitemapindex extraction + robots.txt
│ ├── queryBuilder.ts # site/filetype/keywords → search URL
│ └── filters.ts # extension match, canonicalize/dedup, smart filename
├── library/
│ ├── manifest.ts # CRUD on chrome.storage.local['library']
│ └── htmlGenerator.ts # standalone HTML view (search/sort/filter)
├── downloader.ts # parallel queue + cancel + one-shot retry
├── messages.ts # typed messages (sidepanel ↔ background ↔ offscreen)
├── storage.ts # settings + saved searches
└── types.ts # LinkInfo, LibraryEntry, SearchQuery, Settings
```
## 设置
| 字段 | 默认值 | 范围 / 备注 |
|---|---|---|
| Filetype(s) | `pdf` | 以逗号分隔。既作为查询过滤条件(`filetype:pdf`)使用,也用于扫描后的扩展名过滤 |
| Source | Google | google / sitemap / bing |
| Keywords | 空 | 附加到查询中的自由文本 |
| Exclude | 空 | 以逗号分隔,每一项将在查询中变为 `-term` |
| Parallel downloads | 5 | 1 – 20 |
| Max pages | 20 | 1 – 50(同时限制访问的 sitemap 文件数量) |
| Subfolder | `MassDownload/{host}` | 支持 `{host}` 占位符 |
| Saved searches | (通过 UI 管理) | 最多存储 30 条 |
所有设置均通过 `chrome.storage.local` 持久化保存。
## 局限性
- **频繁使用时的 Google CAPTCHA**:真实的标签页导航可以降低触发概率,但无法完全消除。当你触发验证码时,该标签页将被带到前台供你手动解决,随后的扫描将复用该标签页的干净会话。
- **Sitemap 可能不准确**:部分网站在 sitemap 中列出的 URL 实际上返回 404。下载失败的记录将显示在日志中;队列会继续执行。
- **处于登录页面后的文件**:下载过程会使用浏览器现有的 cookies —— 只有在已登录该网站的情况下才有效。
- **纯 JavaScript 渲染的网站**:如果页面完全依靠 JS 渲染链接列表,则 sitemap 模式是唯一可靠的选项。
- **崩溃后的恢复**:暂未实现。如果 Service Worker 在队列执行中途被终止,正在下载的文件会继续(由 Chrome 接管),但队列的进度将会丢失。
## 权限
| 权限 | 为什么需要它 |
|---|---|
| `sidePanel` | 侧边栏 UI |
| `downloads` | 保存文件,重新生成 library.html |
| `activeTab` + `scripting` | 从当前标签页读取链接;页面内的 Google 搜索引擎结果页面(SERP)提取 |
| `storage` | 持久化保存设置、保存的搜索、文件库清单、可恢复的队列 |
| `offscreen` | 在 Bing HTML / sitemap XML / 抓取页面上运行 `DOMParser` |
| `tabs` | 读取活动标签页的 URL,管理扫描用的标签页 |
| `alarms` | 定期唤醒以重新运行计划保存的搜索 |
| `notifications` | 当计划运行下载了新文件时,显示桌面提醒 |
| `` host | 在任意语言区域下请求 Google、Bing,以及任意网站的 robots.txt 和 sitemap |
**无遥测数据。无远程配置。除了获取搜索页面和下载你选定文件所需的 HTTP 请求外,没有任何数据离开你的浏览器**。
## 常见问题
**问:这能在 Firefox 上运行吗?**
答:从 v0.3.0 版本开始,提供了一个**实验性**的 Firefox 构建(`npm run build:firefox`)。它使用 `sidebar_action` 替代了 `chrome.sidePanel`,内联解析 HTML(无离屏文档),并设置了 `browser_specific_settings.gecko` 块。它可以编译并通过 `about:debugging` 加载,但尚未经过日常使用测试。欢迎提交 Bug 报告。
**问:这会让我被 Google 封禁吗?**
答:它使用你真实的浏览器会话来进行搜索引擎结果页面(SERP)抓取(无 API 密钥,无 IP 轮换)。在低频使用下(每天搜索几个网站),你极少会触发验证码。在高频使用下,Google 可能会暂时对你发起验证挑战 —— 在扩展弹出的标签页中解决它,然后继续即可。
**问:它能抓取需要登录的网站吗?**
答:它通过浏览器现有的 cookies 进行下载,所以如果你已经处于登录状态,是可以的。扩展程序本身绝不会主动要求或存储登录凭据。
**问:文件库的数据存放在哪里?**
答:存放在 `chrome.storage.local['library']` 中 —— 这是一个以规范化的 URL 为键的扁平映射。位于 `Downloads/MassDownload/{host}/library.html` 的 HTML 视图会在每次批量下载后根据此数据重新生成。可通过卸载扩展程序或在 DevTools 的存储检查器中手动清除。
**问:我可以在文件库的 HTML 中编辑标题或添加标签吗?**
答:目前还不行 —— HTML 是只读的。将修改同步回扩展的功能已在开发路线图中。
## 贡献指南
欢迎提交 Issue 和 Pull Request。详情请参阅 [CONTRIBUTING.md](CONTRIBUTING.md)。
如果有功能建议或发现了 Bug,请[创建一个 Issue](https://github.com/bogdanpricop/MassDownload/issues/new/choose)。
## 开源许可证
[MIT](LICENSE) © 2026 Bogdan Pricop标签:Edge扩展, ESC4, Manifest V3, MIT协议, OSINT, PDF下载, SEO工具, Sitemap解析, TypeScript, 全文检索, 内容归档, 安全插件, 幻觉缓解, 开源, 批量下载, 搜索引擎, 数据爬虫, 文件下载, 文献下载, 无线安全, 本地存储, 浏览器插件, 离线搜索, 网络调试, 自动化, 自动化攻击, 资源抓取