NeeharSatti1998/incident-response-agent
GitHub: NeeharSatti1998/incident-response-agent
一个基于Claude AI和LangGraph的自主事件响应系统,能够自动检测基础设施异常、诊断根因、执行靶向修复并通知工程师,实现无需人工干预的分钟级故障处理闭环。
Stars: 0 | Forks: 0
# AI 驱动的事件响应智能体
一个自主事件响应系统,能够检测基础设施异常,使用 Claude AI 诊断根本原因,自动执行针对性修复,并通过 Slack 通知工程师——全程无需人工干预。
## 演示
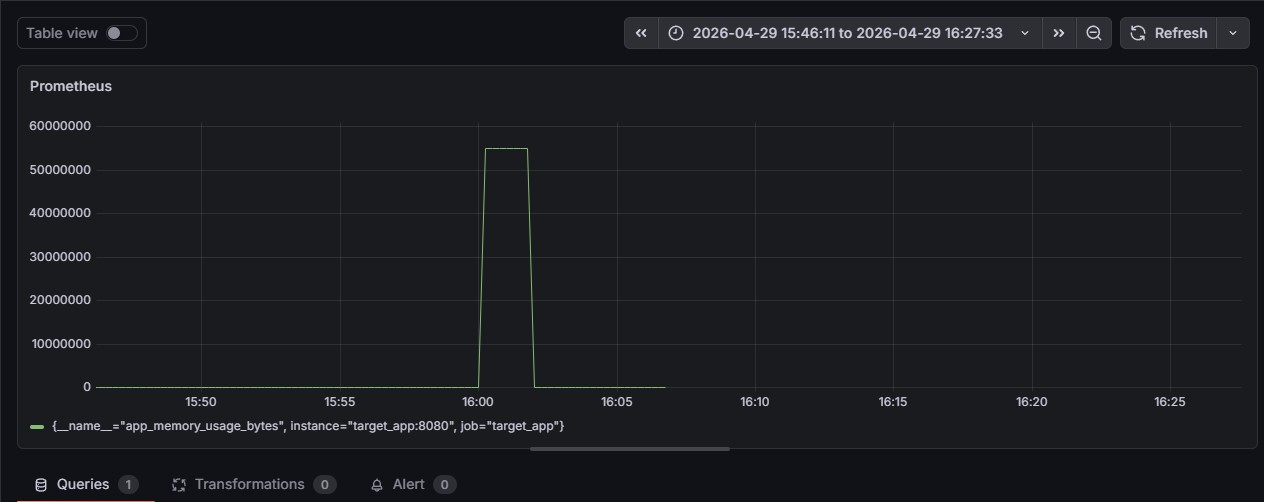
注入 55MB 的内存泄漏。AI 智能体通过 Prometheus 检测到异常,通过读取容器日志诊断根本原因,调用针对性修复端点,验证指标降至 0,并发送 Slack 通知——全程在 2 分钟内完成,零人工干预。
## 架构
系统运行 6 个 Docker 服务,这些服务自主协同工作。目标应用暴露 Prometheus 每 15 秒抓取一次的指标。当指标越过阈值时,Prometheus 向 Alertmanager 触发告警,Alertmanager 通过 webhook 将其路由到智能体。智能体运行由 Claude 驱动的 6 节点 LangGraph 流水线来诊断问题、执行针对性修复、验证修复效果,并在 Slack 上通知团队。每个事件都存储在 PostgreSQL 中用于历史分析,Grafana 实时可视化所有指标。
**6 节点 LangGraph 流水线:**
| 节点 | 职责 |
|---|---|
| Detect | 接收告警,将初始事件记录保存到 PostgreSQL |
| Diagnose | 获取容器日志,调用 Claude 识别根本原因并选择修复工具 |
| Fix | 执行 Claude 从注册表中选择的方法 |
| Verify | 重新抓取指标以确认修复实际有效 |
| Notify | 发送包含完整事件摘要的 Slack 消息 |
| Remember | 使用诊断信息、采取的操作和验证结果更新 PostgreSQL |
**Claude 可从中选择的 9 项修复工具注册表:**
| 工具 | Claude 何时使用它 |
|---|---|
| fix_memory | 内存消耗过高 |
| fix_cpu | 检测到 CPU 飙升 |
| fix_disk | 磁盘使用量过高 |
| fix_connections | 连接池耗尽 |
| fix_errors | 高错误率 |
| restart_container | 应用完全无响应 |
| scale_service | 单实例负载过高 |
| notify_human | 根本原因不明确,需要人工调查 |
| log_only | 问题似乎已自行解决 |
## 工作原理
当告警触发时,Alertmanager 会自动将其发送到智能体的 webhook 端点。智能体会将其通过一个 6 节点的 LangGraph 流水线,其中每个节点都有特定的职责。
Detect 节点接收告警并将初始事件记录保存到 PostgreSQL。Diagnose 节点获取容器日志的最后 30 行,并将其与告警详细信息一起发送给 Claude——Claude 读取日志,识别可能的根本原因,并从注册表中选择适当的修复工具。Fix 节点执行 Claude 选择的任何工具,无论是清理内存、停止 CPU 线程、释放连接还是上报给人工。Verify 节点在修复后重新抓取实际指标以确认问题已解决——如果数值仍高于阈值,它会向 Slack 发送未验证警告。Notify 节点发送包含完整事件摘要的清晰 Slack 消息。Remember 节点使用诊断信息、采取的操作和验证结果更新 PostgreSQL 记录。
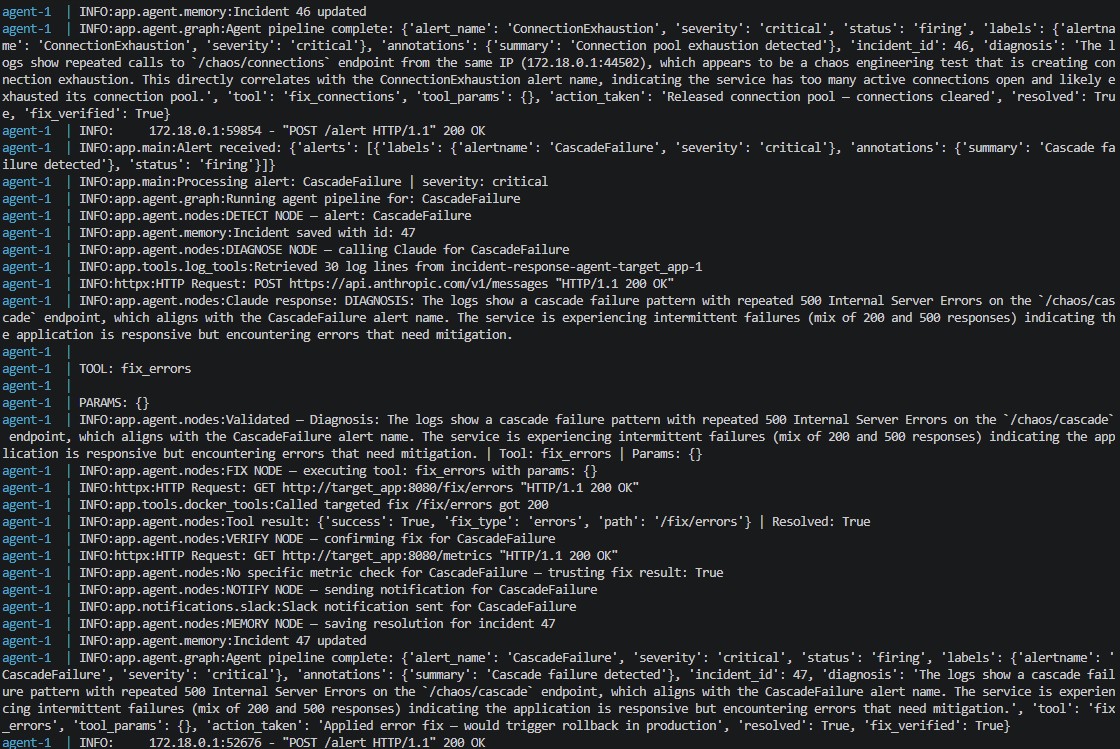
## Prometheus 告警生命周期
Prometheus 检测到阈值违规并进入 PENDING 状态,等待 1 分钟以确认这不是突发峰值。
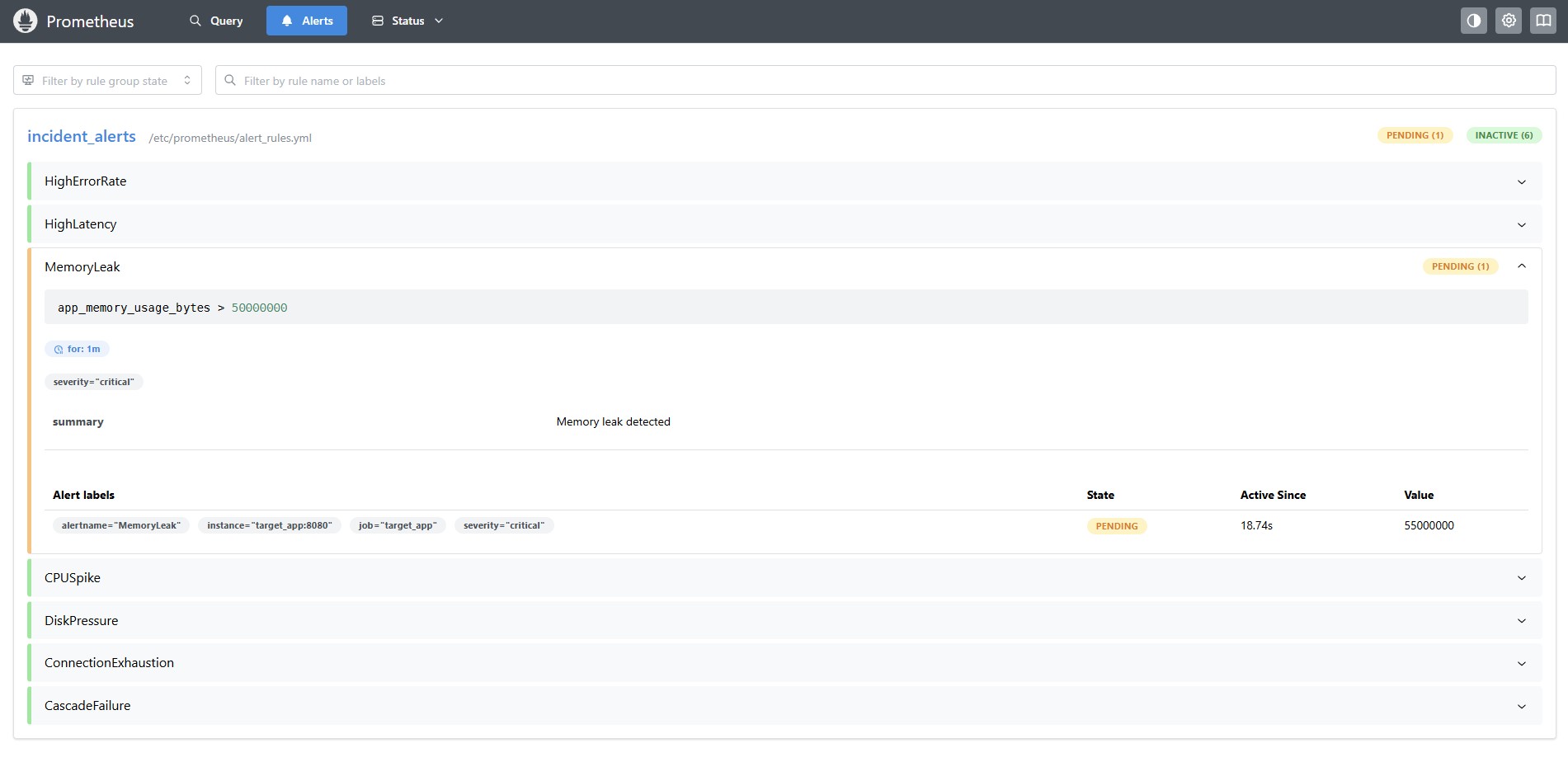
持续违规 1 分钟后,告警进入 FIRING 状态,Alertmanager 会自动将其路由到智能体。
## 处理的事件类型
每种告警类型都会触发不同的针对性修复——Claude 读取容器日志,并根据其观察到的情况从注册表中选择最合适的工具。
| 告警 | 触发条件 | Claude 的操作 |
|---|---|---|
| MemoryLeak | memory > 50MB | 通过 `/fix/memory` 清理内存泄漏存储 |
| HighErrorRate | 500 errors > 50% | 通过 `/fix/errors` 应用错误缓解 |
| HighLatency | p99 latency > 3s | 记录事件,无可用自动化修复 |
| CPUSpike | CPU > 80% | 通过 `/fix/cpu` 停止 CPU 消耗线程 |
| DiskPressure | disk > 50MB | 通过 `/fix/disk` 删除临时文件 |
| ConnectionExhaustion | connections > 20 | 通过 `/fix/connections` 释放连接池 |
| CascadeFailure | errors + memory high | 应用错误修复或上报给人工 |
## Slack 通知
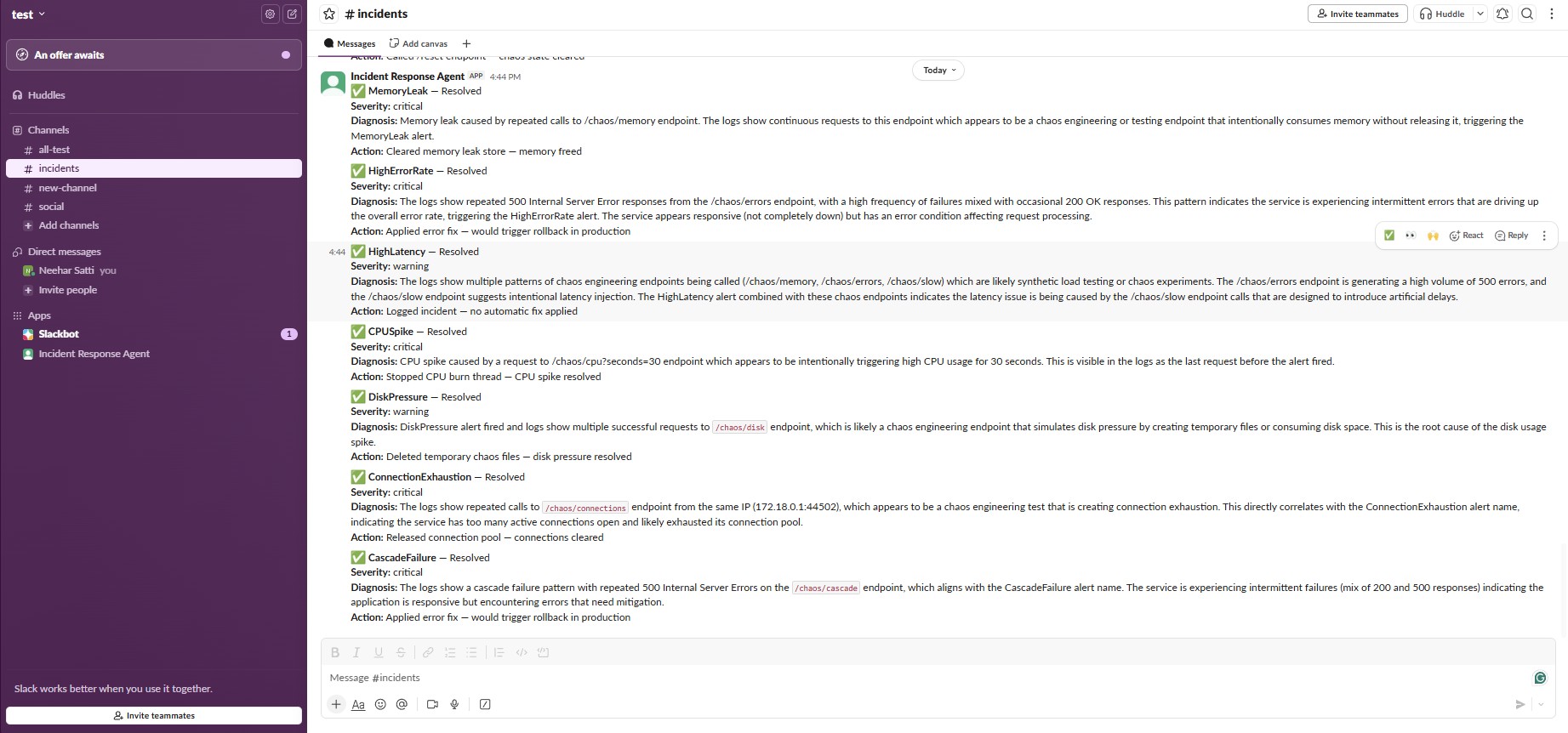
每个事件都会生成一条 Slack 通知,包含告警名称、严重程度、基于真实日志分析的 Claude 诊断、采取的具体操作,以及修复是否已通过实际指标验证。
## 事件历史
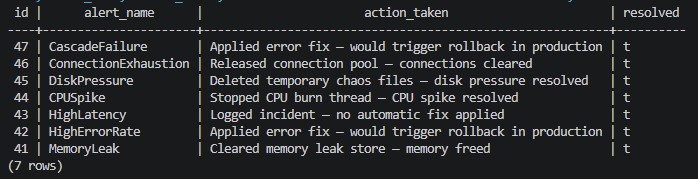
每个事件及其完整的解决细节都存储在 PostgreSQL 中。该表显示了 7 个不同的事件,每个事件都采取了完全不同的针对性操作——这证明了 Claude 是根据日志进行推理的,而不是应用通用修复。
## 生产级特性
**针对性修复注册表** —— 不采用通用的重置,而是为每种事件类型提供特定的修复。Claude 读取日志并从 9 个可用操作的注册表中选择最具针对性的工具。这意味着 MemoryLeak 只清理内存,CPUSpike 只停止 CPU 线程,而 DiskPressure 只删除临时文件。
**修复验证** —— 在每次修复后,智能体会重新抓取实际指标以确认问题已解决。如果数值仍高于阈值,它会向 Slack 发送未验证警告,而不是将事件标记为已解决。
**告警去重** —— 智能体在 PostgreSQL 中跟踪最近解决的事件。如果在成功解决后的 5 分钟内再次触发相同的告警,它将被跳过,从而防止同一事件触发重复的流水线运行。
**Webhook 认证** —— 在处理之前,来自 Alertmanager 的每个告警负载都会根据共享密钥进行验证。未经授权的请求将在流水线运行前以 401 状态码被拒绝。
**Claude 响应验证** —— Claude 返回的所有工具名称和端点路径在执行前都会根据白名单进行验证。幻觉或未知的工具将被拒绝,并回退到 log_only 同时记录警告日志。
## 技术栈
| 层级 | 技术 |
|---|---|
| 智能体框架 | LangGraph |
| AI 模型 | Claude Sonnet (Anthropic) |
| 指标 | Prometheus |
| 告警 | Alertmanager |
| 仪表盘 | Grafana |
| API | FastAPI |
| 存储 | PostgreSQL |
| 通知 | Slack SDK |
| 基础设施 | Docker Compose |
## 项目结构
```
incident-response-agent/
├── app/
│ ├── main.py # FastAPI entry point, webhook receiver, deduplication
│ ├── agent/
│ │ ├── graph.py # LangGraph 6-node pipeline definition
│ │ ├── nodes.py # Detect, Diagnose, Fix, Verify, Notify, Remember
│ │ └── memory.py # PostgreSQL operations
│ ├── tools/
│ │ ├── docker_tools.py # restart_container, call_endpoint, scale_service, clear_chaos_state
│ │ └── log_tools.py # container log fetching
│ └── notifications/
│ └── slack.py # Slack webhook integration
├── target_app/
│ ├── app.py # Fake production app with 7 chaos + 5 targeted fix endpoints
│ └── Dockerfile
├── prometheus/
│ ├── prometheus.yml # Scrape config + Alertmanager routing
│ └── alert_rules.yml # 7 alert rules with thresholds
├── alertmanager/
│ └── alertmanager.yml # Webhook routing to agent with auth
├── Dockerfile # Agent container
├── docker-compose.yml # 6-service stack
└── .env # API keys (not committed)
```
## 开始使用
**前置条件:** Docker Desktop、Anthropic API 密钥、Slack 机器人令牌
**1. 克隆仓库:**
```
git clone https://github.com/NeeharSatti1998/incident-response-agent
cd incident-response-agent
```
**2. 设置环境变量:**
```
cp .env.example .env
# 添加你的 ANTHROPIC_API_KEY、SLACK_BOT_TOKEN、SLACK_CHANNEL_ID、WEBHOOK_SECRET
```
**3. 启动技术栈:**
```
docker compose up --build
```
**4. 触发真实事件:**
```
# 引发 memory leak
for i in {1..55}; do curl http://localhost:8080/chaos/memory; done
# 等待约 2 分钟 — agent 会自动修复它
docker compose logs agent -f
```
**5. 查看仪表盘:**
- Grafana: http://localhost:3000 (admin / admin)
- Prometheus: http://localhost:9090
- Alertmanager: http://localhost:9093
- Agent 运行状况: http://localhost:8000/health
## 环境变量
```
ANTHROPIC_API_KEY=your_anthropic_api_key
SLACK_BOT_TOKEN=xoxb-your-slack-bot-token
SLACK_CHANNEL_ID=your_slack_channel_id
WEBHOOK_SECRET=your_webhook_secret
POSTGRES_CONNECTION_STRING=postgresql://agent:agentpass@postgres:5432/incidents
TARGET_APP_URL=http://target_app:8080
```
## 工程路线图 — 后续计划
本项目实现了正确的生产架构。计划的改进包括:
- 修复重试逻辑 —— 在上报给人工前重试 3 次
- 智能体冗余 —— 负载均衡器后的多副本
- 密钥管理 —— 使用 Vault 或 AWS Secrets Manager 替代 .env
- 自动化测试套件 —— 每个节点的 pytest 覆盖
- 多服务感知 —— 扩展以监控 50+ 微服务
## 作者
Neehar Satti — [LinkedIn](https://linkedin.com/in/neeharsatti)
标签:AIOps, AI智能体, Alertmanager, API集成, Claude AI, CPU飙升处理, DLL 劫持, Docker, Grafana, IT运维自动化, LangGraph, NIDS, PE 加载器, PostgreSQL, Python, Ruby, Slack集成, SRE, Webhook, 偏差过滤, 内存泄漏修复, 力导向图, 可观测性, 告警路由, 基础设施异常检测, 大语言模型, 安全防御评估, 容器化, 指标监控, 数据库, 无后门, 智能告警, 智能运维, 机器人, 根因分析, 测试用例, 版权保护, 知识库, 磁盘使用率处理, 站点可靠性工程, 自主修复, 自动化事件响应, 自动化诊断, 自定义请求头, 运维自动化, 连接池耗尽, 逆向工具, 零人工干预